01 | Java代码是怎么运行的?
作者: 郑雨迪

我们学院的一位教授之前去美国开会,入境的时候海关官员就问他:既然你会计算机,那你说说你用的都是什么语言吧?
教授随口就答了个Java。海关一看是懂行的,也就放行了,边敲章还边说他们上学那会学的是C+。我还特意去查了下,真有叫C+的语言,但是这里海关官员应该指的是C++。
事后教授告诉我们,他当时差点就问海关,是否知道Java和C++在运行方式上的区别。但是又担心海关官员拿他的问题来考别人,也就没问出口。那么,下次你去美国,不幸地被海关官员问这个问题,你懂得如何回答吗?
作为一名Java程序员,你应该知道,Java代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行jar文件运行,也可以在命令行中运行,甚至可以在网页中运行。当然,这些执行方式都离不开JRE,也就是Java运行时环境。
实际上,JRE仅包含运行Java程序的必需组件,包括Java虚拟机以及Java核心类库等。我们Java程序员经常接触到的JDK(Java开发工具包)同样包含了JRE,并且还附带了一系列开发、诊断工具。
然而,运行C++代码则无需额外的运行时。我们往往把这些代码直接编译成CPU所能理解的代码格式,也就是机器码。
比如下图的中间列,就是用C语言写的Helloworld程序的编译结果。可以看到,C程序编译而成的机器码就是一个个的字节,它们是给机器读的。那么为了让开发人员也能够理解,我们可以用反汇编器将其转换成汇编代码(如下图的最右列所示)。
1 | ; 最左列是偏移;中间列是给机器读的机器码;最右列是给人读的汇编代码 |
既然C++的运行方式如此成熟,那么你有没有想过,为什么Java要在虚拟机中运行呢,Java虚拟机具体又是怎样运行Java代码的呢,它的运行效率又如何呢?
今天我便从这几个问题入手,和你探讨一下,Java执行系统的主流实现以及设计决策。
为什么Java要在虚拟机里运行?
Java作为一门高级程序语言,它的语法非常复杂,抽象程度也很高。因此,直接在硬件上运行这种复杂的程序并不现实。所以呢,在运行Java程序之前,我们需要对其进行一番转换。
这个转换具体是怎么操作的呢?当前的主流思路是这样子的,设计一个面向Java语言特性的虚拟机,并通过编译器将Java程序转换成该虚拟机所能识别的指令序列,也称Java字节码。这里顺便说一句,之所以这么取名,是因为Java字节码指令的操作码(opcode)被固定为一个字节。
举例来说,下图的中间列,正是用Java写的Helloworld程序编译而成的字节码。可以看到,它与C版本的编译结果一样,都是由一个个字节组成的。
并且,我们同样可以将其反汇编为人类可读的代码格式(如下图的最右列所示)。不同的是,Java版本的编译结果相对精简一些。这是因为Java虚拟机相对于物理机而言,抽象程度更高。
1 | # 最左列是偏移;中间列是给虚拟机读的机器码;最右列是给人读的代码 |
Java虚拟机可以由硬件实现[1],但更为常见的是在各个现有平台(如Windows_x64、Linux_aarch64)上提供软件实现。这么做的意义在于,一旦一个程序被转换成Java字节码,那么它便可以在不同平台上的虚拟机实现里运行。这也就是我们经常说的“一次编写,到处运行”。
虚拟机的另外一个好处是它带来了一个托管环境(Managed Runtime)。这个托管环境能够代替我们处理一些代码中冗长而且容易出错的部分。其中最广为人知的当属自动内存管理与垃圾回收,这部分内容甚至催生了一波垃圾回收调优的业务。
除此之外,托管环境还提供了诸如数组越界、动态类型、安全权限等等的动态检测,使我们免于书写这些无关业务逻辑的代码。
Java虚拟机具体是怎样运行Java字节码的?
下面我将以标准JDK中的HotSpot虚拟机为例,从虚拟机以及底层硬件两个角度,给你讲一讲Java虚拟机具体是怎么运行Java字节码的。
从虚拟机视角来看,执行Java代码首先需要将它编译而成的class文件加载到Java虚拟机中。加载后的Java类会被存放于方法区(Method Area)中。实际运行时,虚拟机会执行方法区内的代码。
如果你熟悉X86的话,你会发现这和段式内存管理中的代码段类似。而且,Java虚拟机同样也在内存中划分出堆和栈来存储运行时数据。
不同的是,Java虚拟机会将栈细分为面向Java方法的Java方法栈,面向本地方法(用C++写的native方法)的本地方法栈,以及存放各个线程执行位置的PC寄存器。

在运行过程中,每当调用进入一个Java方法,Java虚拟机会在当前线程的Java方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且Java虚拟机不要求栈帧在内存空间里连续分布。
当退出当前执行的方法时,不管是正常返回还是异常返回,Java虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
从硬件视角来看,Java字节码无法直接执行。因此,Java虚拟机需要将字节码翻译成机器码。
在HotSpot里面,上述翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。

前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。HotSpot默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
Java虚拟机的运行效率究竟是怎么样的?
HotSpot采用了多种技术来提升启动性能以及峰值性能,刚刚提到的即时编译便是其中最重要的技术之一。
即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。
理论上讲,即时编译后的Java程序的执行效率,是可能超过C++程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。
举个例子,我们知道虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管它有很多个目标方法,但在实际运行过程中它可能只调用其中的一个。
这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的C++程序更高的性能。
为了满足不同用户场景的需要,HotSpot内置了多个即时编译器:C1、C2和Graal。Graal是Java 10正式引入的实验性即时编译器,在专栏的第四部分我会详细介绍,这里暂不做讨论。
之所以引入多个即时编译器,是为了在编译时间和生成代码的执行效率之间进行取舍。C1又叫做Client编译器,面向的是对启动性能有要求的客户端GUI程序,采用的优化手段相对简单,因此编译时间较短。
C2又叫做Server编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
从Java 7开始,HotSpot默认采用分层编译的方式:热点方法首先会被C1编译,而后热点方法中的热点会进一步被C2编译。
为了不干扰应用的正常运行,HotSpot的即时编译是放在额外的编译线程中进行的。HotSpot会根据CPU的数量设置编译线程的数目,并且按1:2的比例配置给C1及C2编译器。
在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
总结与实践
今天我简单介绍了Java代码为何在虚拟机中运行,以及如何在虚拟机中运行。
之所以要在虚拟机中运行,是因为它提供了可移植性。一旦Java代码被编译为Java字节码,便可以在不同平台上的Java虚拟机实现上运行。此外,虚拟机还提供了一个代码托管的环境,代替我们处理部分冗长而且容易出错的事务,例如内存管理。
Java虚拟机将运行时内存区域划分为五个部分,分别为方法区、堆、PC寄存器、Java方法栈和本地方法栈。Java程序编译而成的class文件,需要先加载至方法区中,方能在Java虚拟机中运行。
为了提高运行效率,标准JDK中的HotSpot虚拟机采用的是一种混合执行的策略。
它会解释执行Java字节码,然后会将其中反复执行的热点代码,以方法为单位进行即时编译,翻译成机器码后直接运行在底层硬件之上。
HotSpot装载了多个不同的即时编译器,以便在编译时间和生成代码的执行效率之间做取舍。
下面我给你留一个小作业,通过观察两个条件判断语句的运行结果,来思考Java语言和Java虚拟机看待boolean类型的方式是否不同。
下载asmtools.jar [2] ,并在命令行中运行下述指令(不包含提示符$):
1 | $ echo ' |
[1] : https://en.wikipedia.org/wiki/Java_processor
[2]: https://wiki.openjdk.java.net/display/CodeTools/asmtools
02 | Java的基本类型
作者: 郑雨迪

如果你了解面向对象语言的发展史,那你可能听说过Smalltalk这门语言。它的影响力之大,以至于之后诞生的面向对象语言,或多或少都借鉴了它的设计和实现。
在Smalltalk中,所有的值都是对象。因此,许多人认为它是一门纯粹的面向对象语言。
Java则不同,它引进了八个基本类型,来支持数值计算。Java这么做的原因主要是工程上的考虑,因为使用基本类型能够在执行效率以及内存使用两方面提升软件性能。
今天,我们就来了解一下基本类型在Java虚拟机中的实现。
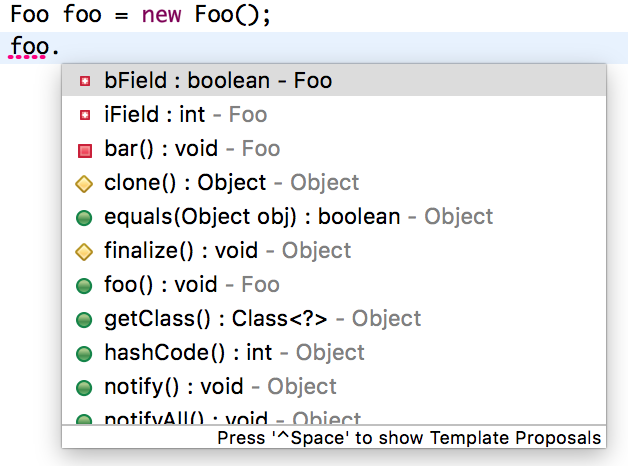
1 | public class Foo { |
在上一篇结尾的小作业里,我构造了这么一段代码,它将一个boolean类型的局部变量赋值为2。为了方便记忆,我们给这个变量起个名字,就叫“吃过饭没”。
赋值语句后边我设置了两个看似一样的if语句。第一个if语句,也就是直接判断“吃过饭没”,在它成立的情况下,代码会打印“吃了”。
第二个if语句,也就是判断“吃过饭没”和true是否相等,在它成立的情况下,代码会打印“真吃了”。
当然,直接编译这段代码,编译器是会报错的。所以,我迂回了一下,采用一个Java字节码的汇编工具,直接对字节码进行更改。
那么问题就来了:当一个boolean变量的值是2时,它究竟是true还是false呢?
如果你跑过这段代码,你会发现,问虚拟机“吃过饭没”,它会回答“吃了”,而问虚拟机“真(==)吃过饭没”,虚拟机则不会回答“真吃了”。
那么虚拟机到底吃过没,下面我们来一起分析一下这背后的细节。
Java虚拟机的boolean类型
首先,我们来看看Java语言规范以及Java虚拟机规范是怎么定义boolean类型的。
在Java语言规范中,boolean类型的值只有两种可能,它们分别用符号“true”和“false”来表示。显然,这两个符号是不能被虚拟机直接使用的。
在Java虚拟机规范中,boolean类型则被映射成int类型。具体来说,“true”被映射为整数1,而“false”被映射为整数0。这个编码规则约束了Java字节码的具体实现。
举个例子,对于存储boolean数组的字节码,Java虚拟机需保证实际存入的值是整数1或者0。
Java虚拟机规范同时也要求Java编译器遵守这个编码规则,并且用整数相关的字节码来实现逻辑运算,以及基于boolean类型的条件跳转。这样一来,在编译而成的class文件中,除了字段和传入参数外,基本看不出boolean类型的痕迹了。
1 | # Foo.main编译后的字节码 |
在前面的例子中,第一个if语句会被编译成条件跳转字节码ifeq,翻译成人话就是说,如果局部变量“吃过饭没”的值为0,那么跳过打印“吃了”的语句。
而第二个if语句则会被编译成条件跳转字节码if_icmpne,也就是说,如果局部变量的值和整数1不相等,那么跳过打印“真吃了”的语句。
可以看到,Java编译器的确遵守了相同的编码规则。当然,这个约束很容易绕开。除了我们小作业中用到的汇编工具AsmTools外,还有许多可以修改字节码的Java库,比如说ASM [1] 等。
对于Java虚拟机来说,它看到的boolean类型,早已被映射为整数类型。因此,将原本声明为boolean类型的局部变量,赋值为除了0、1之外的整数值,在Java虚拟机看来是“合法”的。
在我们的例子中,经过编译器编译之后,Java虚拟机看到的不是在问“吃过饭没”,而是在问“吃过几碗饭”。也就是说,第一个if语句变成:你不会一碗饭都没吃吧。第二个if语句则变成:你吃过一碗饭了吗。
如果我们约定俗成,每人每顿只吃一碗,那么第二个if语句还是有意义的。但如果我们打破常规,吃了两碗,那么较真的Java虚拟机就会将第二个if语句判定为假了。
Java的基本类型
除了上面提到的boolean类型外,Java的基本类型还包括整数类型byte、short、char、int和long,以及浮点类型float和double。

Java的基本类型都有对应的值域和默认值。可以看到,byte、short、int、long、float以及double的值域依次扩大,而且前面的值域被后面的值域所包含。因此,从前面的基本类型转换至后面的基本类型,无需强制转换。另外一点值得注意的是,尽管他们的默认值看起来不一样,但在内存中都是0。
在这些基本类型中,boolean和char是唯二的无符号类型。在不考虑违反规范的情况下,boolean类型的取值范围是0或者1。char类型的取值范围则是[0, 65535]。通常我们可以认定char类型的值为非负数。这种特性十分有用,比如说作为数组索引等。
在前面的例子中,我们能够将整数2存储到一个声明为boolean类型的局部变量中。那么,声明为byte、char以及short的局部变量,是否也能够存储超出它们取值范围的数值呢?
答案是可以的。而且,这些超出取值范围的数值同样会带来一些麻烦。比如说,声明为char类型的局部变量实际上有可能为负数。当然,在正常使用Java编译器的情况下,生成的字节码会遵守Java虚拟机规范对编译器的约束,因此你无须过分担心局部变量会超出它们的取值范围。
Java的浮点类型采用IEEE 754浮点数格式。以float为例,浮点类型通常有两个0,+0.0F以及-0.0F。
前者在Java里是0,后者是符号位为1、其他位均为0的浮点数,在内存中等同于十六进制整数0x8000000(即-0.0F可通过Float.intBitsToFloat(0x8000000)求得)。尽管它们的内存数值不同,但是在Java中+0.0F == -0.0F会返回真。
在有了+0.0F和-0.0F这两个定义后,我们便可以定义浮点数中的正无穷及负无穷。正无穷就是任意正浮点数(不包括+0.0F)除以+0.0F得到的值,而负无穷是任意正浮点数除以-0.0F得到的值。在Java中,正无穷和负无穷是有确切的值,在内存中分别等同于十六进制整数0x7F800000和0xFF800000。
你也许会好奇,既然整数0x7F800000等同于正无穷,那么0x7F800001又对应什么浮点数呢?
这个数字对应的浮点数是NaN(Not-a-Number)。
不仅如此,[0x7F800001, 0x7FFFFFFF]和[0xFF800001, 0xFFFFFFFF]对应的都是NaN。当然,一般我们计算得出的NaN,比如说通过+0.0F/+0.0F,在内存中应为0x7FC00000。这个数值,我们称之为标准的NaN,而其他的我们称之为不标准的NaN。
NaN有一个有趣的特性:除了“!=”始终返回true之外,所有其他比较结果都会返回false。
举例来说,“NaN<1.0F”返回false,而“NaN>=1.0F”同样返回false。对于任意浮点数f,不管它是0还是NaN,“f!=NaN”始终会返回true,而“f==NaN”始终会返回false。
因此,我们在程序里做浮点数比较的时候,需要考虑上述特性。在本专栏的第二部分,我会介绍这个特性给向量化比较带来什么麻烦。
Java基本类型的大小
在第一篇中我曾经提到,Java虚拟机每调用一个Java方法,便会创建一个栈帧。为了方便理解,这里我只讨论供解释器使用的解释栈帧(interpreted frame)。
这种栈帧有两个主要的组成部分,分别是局部变量区,以及字节码的操作数栈。这里的局部变量是广义的,除了普遍意义下的局部变量之外,它还包含实例方法的“this指针”以及方法所接收的参数。
在Java虚拟机规范中,局部变量区等价于一个数组,并且可以用正整数来索引。除了long、double值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。
也就是说,boolean、byte、char、short这四种类型,在栈上占用的空间和int是一样的,和引用类型也是一样的。因此,在32位的HotSpot中,这些类型在栈上将占用4个字节;而在64位的HotSpot中,他们将占8个字节。
当然,这种情况仅存在于局部变量,而并不会出现在存储于堆中的字段或者数组元素上。对于byte、char以及short这三种类型的字段或者数组单元,它们在堆上占用的空间分别为一字节、两字节,以及两字节,也就是说,跟这些类型的值域相吻合。
因此,当我们将一个int类型的值,存储到这些类型的字段或数组时,相当于做了一次隐式的掩码操作。举例来说,当我们把0xFFFFFFFF(-1)存储到一个声明为char类型的字段里时,由于该字段仅占两字节,所以高两位的字节便会被截取掉,最终存入“\uFFFF”。
boolean字段和boolean数组则比较特殊。在HotSpot中,boolean字段占用一字节,而boolean数组则直接用byte数组来实现。为了保证堆中的boolean值是合法的,HotSpot在存储时显式地进行掩码操作,也就是说,只取最后一位的值存入boolean字段或数组中。
讲完了存储,现在我来讲讲加载。Java虚拟机的算数运算几乎全部依赖于操作数栈。也就是说,我们需要将堆中的boolean、byte、char以及short加载到操作数栈上,而后将栈上的值当成int类型来运算。
对于boolean、char这两个无符号类型来说,加载伴随着零扩展。举个例子,char的大小为两个字节。在加载时char的值会被复制到int类型的低二字节,而高二字节则会用0来填充。
对于byte、short这两个类型来说,加载伴随着符号扩展。举个例子,short的大小为两个字节。在加载时short的值同样会被复制到int类型的低二字节。如果该short值为非负数,即最高位为0,那么该int类型的值的高二字节会用0来填充,否则用1来填充。
总结与实践
今天我介绍了Java里的基本类型。
其中,boolean类型在Java虚拟机中被映射为整数类型:“true”被映射为1,而“false”被映射为0。Java代码中的逻辑运算以及条件跳转,都是用整数相关的字节码来实现的。
除boolean类型之外,Java还有另外7个基本类型。它们拥有不同的值域,但默认值在内存中均为0。这些基本类型之中,浮点类型比较特殊。基于它的运算或比较,需要考虑+0.0F、-0.0F以及NaN的情况。
除long和double外,其他基本类型与引用类型在解释执行的方法栈帧中占用的大小是一致的,但它们在堆中占用的大小确不同。在将boolean、byte、char以及short的值存入字段或者数组单元时,Java虚拟机会进行掩码操作。在读取时,Java虚拟机则会将其扩展为int类型。
今天的动手环节,你可以观测一下,将boolean类型的值存入字段中时,Java虚拟机所做的掩码操作。
你可以将下面代码中boolValue = true里的true换为2或者3,看看打印结果与你的猜测是否相符合。
熟悉Unsafe的同学,可以使用Unsafe.putBoolean和Unsafe.putByte方法,看看还会不会做掩码操作。
1 | public class Foo { |
03 | Java虚拟机是如何加载Java类的?
作者: 郑雨迪

听我的意大利同事说,他们那边有个习俗,就是父亲要帮儿子盖栋房子。
这事要放在以前还挺简单,亲朋好友搭把手,盖个小砖房就可以住人了。现在呢,整个过程要耗费好久的时间。首先你要请建筑师出个方案,然后去市政部门报备、验证,通过后才可以开始盖房子。盖好房子还要装修,之后才能住人。
盖房子这个事,和Java虚拟机中的类加载还是挺像的。从class文件到内存中的类,按先后顺序需要经过加载、链接以及初始化三大步骤。其中,链接过程中同样需要验证;而内存中的类没有经过初始化,同样不能使用。那么,是否所有的Java类都需要经过这几步呢?
我们知道Java语言的类型可以分为两大类:基本类型(primitive types)和引用类型(reference types)。在上一篇中,我已经详细介绍过了Java的基本类型,它们是由Java虚拟机预先定义好的。
至于另一大类引用类型,Java将其细分为四种:类、接口、数组类和泛型参数。由于泛型参数会在编译过程中被擦除(我会在专栏的第二部分详细介绍),因此Java虚拟机实际上只有前三种。在类、接口和数组类中,数组类是由Java虚拟机直接生成的,其他两种则有对应的字节流。
说到字节流,最常见的形式要属由Java编译器生成的class文件。除此之外,我们也可以在程序内部直接生成,或者从网络中获取(例如网页中内嵌的小程序Java applet)字节流。这些不同形式的字节流,都会被加载到Java虚拟机中,成为类或接口。为了叙述方便,下面我就用“类”来统称它们。
无论是直接生成的数组类,还是加载的类,Java虚拟机都需要对其进行链接和初始化。接下来,我会详细给你介绍一下每个步骤具体都在干些什么。
加载
加载,是指查找字节流,并且据此创建类的过程。前面提到,对于数组类来说,它并没有对应的字节流,而是由Java虚拟机直接生成的。对于其他的类来说,Java虚拟机则需要借助类加载器来完成查找字节流的过程。
以盖房子为例,村里的Tony要盖个房子,那么按照流程他得先找个建筑师,跟他说想要设计一个房型,比如说“一房、一厅、四卫”。你或许已经听出来了,这里的房型相当于类,而建筑师,就相当于类加载器。
村里有许多建筑师,他们等级森严,但有着共同的祖师爷,叫启动类加载器(bootstrap class loader)。启动类加载器是由C++实现的,没有对应的Java对象,因此在Java中只能用null来指代。换句话说,祖师爷不喜欢像Tony这样的小角色来打扰他,所以谁也没有祖师爷的联系方式。
除了启动类加载器之外,其他的类加载器都是java.lang.ClassLoader的子类,因此有对应的Java对象。这些类加载器需要先由另一个类加载器,比如说启动类加载器,加载至Java虚拟机中,方能执行类加载。
村里的建筑师有一个潜规则,就是接到单子自己不能着手干,得先给师傅过过目。师傅不接手的情况下,才能自己来。在Java虚拟机中,这个潜规则有个特别的名字,叫双亲委派模型。每当一个类加载器接收到加载请求时,它会先将请求转发给父类加载器。在父类加载器没有找到所请求的类的情况下,该类加载器才会尝试去加载。
在Java 9之前,启动类加载器负责加载最为基础、最为重要的类,比如存放在JRE的lib目录下jar包中的类(以及由虚拟机参数-Xbootclasspath指定的类)。除了启动类加载器之外,另外两个重要的类加载器是扩展类加载器(extension class loader)和应用类加载器(application class loader),均由Java核心类库提供。
扩展类加载器的父类加载器是启动类加载器。它负责加载相对次要、但又通用的类,比如存放在JRE的lib/ext目录下jar包中的类(以及由系统变量java.ext.dirs指定的类)。
应用类加载器的父类加载器则是扩展类加载器。它负责加载应用程序路径下的类。(这里的应用程序路径,便是指虚拟机参数-cp/-classpath、系统变量java.class.path或环境变量CLASSPATH所指定的路径。)默认情况下,应用程序中包含的类便是由应用类加载器加载的。
Java 9引入了模块系统,并且略微更改了上述的类加载器1。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE中除了少数几个关键模块,比如说java.base 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
除了由Java核心类库提供的类加载器外,我们还可以加入自定义的类加载器,来实现特殊的加载方式。举例来说,我们可以对class文件进行加密,加载时再利用自定义的类加载器对其解密。
除了加载功能之外,类加载器还提供了命名空间的作用。这个很好理解,打个比方,咱们这个村不讲究版权,如果你剽窃了另一个建筑师的设计作品,那么只要你标上自己的名字,这两个房型就是不同的。
在Java虚拟机中,类的唯一性是由类加载器实例以及类的全名一同确定的。即便是同一串字节流,经由不同的类加载器加载,也会得到两个不同的类。在大型应用中,我们往往借助这一特性,来运行同一个类的不同版本。
链接
链接,是指将创建成的类合并至Java虚拟机中,使之能够执行的过程。它可分为验证、准备以及解析三个阶段。
验证阶段的目的,在于确保被加载类能够满足Java虚拟机的约束条件。这就好比Tony需要将设计好的房型提交给市政部门审核。只有当审核通过,才能继续下面的建造工作。
通常而言,Java编译器生成的类文件必然满足Java虚拟机的约束条件。因此,这部分我留到讲解字节码注入时再详细介绍。
准备阶段的目的,则是为被加载类的静态字段分配内存。Java代码中对静态字段的具体初始化,则会在稍后的初始化阶段中进行。过了这个阶段,咱们算是盖好了毛坯房。虽然结构已经完整,但是在没有装修之前是不能住人的。
除了分配内存外,部分Java虚拟机还会在此阶段构造其他跟类层次相关的数据结构,比如说用来实现虚方法的动态绑定的方法表。
在class文件被加载至Java虚拟机之前,这个类无法知道其他类及其方法、字段所对应的具体地址,甚至不知道自己方法、字段的地址。因此,每当需要引用这些成员时,Java编译器会生成一个符号引用。在运行阶段,这个符号引用一般都能够无歧义地定位到具体目标上。
举例来说,对于一个方法调用,编译器会生成一个包含目标方法所在类的名字、目标方法的名字、接收参数类型以及返回值类型的符号引用,来指代所要调用的方法。
解析阶段的目的,正是将这些符号引用解析成为实际引用。如果符号引用指向一个未被加载的类,或者未被加载类的字段或方法,那么解析将触发这个类的加载(但未必触发这个类的链接以及初始化。)
如果将这段话放在盖房子的语境下,那么符号引用就好比“Tony的房子”这种说法,不管它存在不存在,我们都可以用这种说法来指代Tony的房子。实际引用则好比实际的通讯地址,如果我们想要与Tony通信,则需要启动盖房子的过程。
Java虚拟机规范并没有要求在链接过程中完成解析。它仅规定了:如果某些字节码使用了符号引用,那么在执行这些字节码之前,需要完成对这些符号引用的解析。
初始化
在Java代码中,如果要初始化一个静态字段,我们可以在声明时直接赋值,也可以在静态代码块中对其赋值。
如果直接赋值的静态字段被final所修饰,并且它的类型是基本类型或字符串时,那么该字段便会被Java编译器标记成常量值(ConstantValue),其初始化直接由Java虚拟机完成。除此之外的直接赋值操作,以及所有静态代码块中的代码,则会被Java编译器置于同一方法中,并把它命名为< clinit >。
类加载的最后一步是初始化,便是为标记为常量值的字段赋值,以及执行< clinit >方法的过程。Java虚拟机会通过加锁来确保类的< clinit >方法仅被执行一次。
只有当初始化完成之后,类才正式成为可执行的状态。这放在我们盖房子的例子中就是,只有当房子装修过后,Tony才能真正地住进去。
那么,类的初始化何时会被触发呢?JVM规范枚举了下述多种触发情况:
- 当虚拟机启动时,初始化用户指定的主类;
- 当遇到用以新建目标类实例的new指令时,初始化new指令的目标类;
- 当遇到调用静态方法的指令时,初始化该静态方法所在的类;
- 当遇到访问静态字段的指令时,初始化该静态字段所在的类;
- 子类的初始化会触发父类的初始化;
- 如果一个接口定义了default方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
- 使用反射API对某个类进行反射调用时,初始化这个类;
- 当初次调用MethodHandle实例时,初始化该MethodHandle指向的方法所在的类。
1 | public class Singleton { |
我在文章中贴了一段代码,这段代码是在著名的单例延迟初始化例子中2,只有当调用Singleton.getInstance时,程序才会访问LazyHolder.INSTANCE,才会触发对LazyHolder的初始化(对应第4种情况),继而新建一个Singleton的实例。
由于类初始化是线程安全的,并且仅被执行一次,因此程序可以确保多线程环境下有且仅有一个Singleton实例。
总结与实践
今天我介绍了Java虚拟机将字节流转化为Java类的过程。这个过程可分为加载、链接以及初始化三大步骤。
加载是指查找字节流,并且据此创建类的过程。加载需要借助类加载器,在Java虚拟机中,类加载器使用了双亲委派模型,即接收到加载请求时,会先将请求转发给父类加载器。
链接,是指将创建成的类合并至Java虚拟机中,使之能够执行的过程。链接还分验证、准备和解析三个阶段。其中,解析阶段为非必须的。
初始化,则是为标记为常量值的字段赋值,以及执行< clinit >方法的过程。类的初始化仅会被执行一次,这个特性被用来实现单例的延迟初始化。
今天的实践环节,你可以来验证一下本篇中的理论知识。
通过JVM参数-verbose:class来打印类加载的先后顺序,并且在LazyHolder的初始化方法中打印特定字样。在命令行中运行下述指令(不包含提示符$):
1 | $ echo ' |
问题1:新建数组(第11行)会导致LazyHolder的加载吗?会导致它的初始化吗?
在命令行中运行下述指令(不包含提示符$):
1 | $ java -cp /path/to/asmtools.jar org.openjdk.asmtools.jdis.Main Singleton\$LazyHolder.class > Singleton\$LazyHolder.jasm.1 |
问题2:新建数组会导致LazyHolder的链接吗?
04 | JVM是如何执行方法调用的?(上)
作者: 郑雨迪

前不久在写代码的时候,我不小心踩到一个可变长参数的坑。你或许已经猜到了,它正是可变长参数方法的重载造成的。(注:官方文档建议避免重载可变长参数方法,见[1]的最后一段。)
我把踩坑的过程放在了文稿里,你可以点击查看。
1 | void invoke(Object obj, Object... args) { ... } |
当时情况是这样子的,某个API定义了两个同名的重载方法。其中,第一个接收一个Object,以及声明为Object…的变长参数;而第二个则接收一个String、一个Object,以及声明为Object…的变长参数。
这里我想调用第一个方法,传入的参数为(null, 1)。也就是说,声明为Object的形式参数所对应的实际参数为null,而变长参数则对应1。
通常来说,之所以不提倡可变长参数方法的重载,是因为Java编译器可能无法决定应该调用哪个目标方法。
在这种情况下,编译器会报错,并且提示这个方法调用有二义性。然而,Java编译器直接将我的方法调用识别为调用第二个方法,这究竟是为什么呢?
带着这个问题,我们来看一看Java虚拟机是怎么识别目标方法的。
重载与重写
在Java程序里,如果同一个类中出现多个名字相同,并且参数类型相同的方法,那么它无法通过编译。也就是说,在正常情况下,如果我们想要在同一个类中定义名字相同的方法,那么它们的参数类型必须不同。这些方法之间的关系,我们称之为重载。
1 | 小知识:这个限制可以通过字节码工具绕开。也就是说,在编译完成之后,我们可以再向class文件中添加方法名和参数类型相同,而返回类型不同的方法。当这种包括多个方法名相同、参数类型相同,而返回类型不同的方法的类,出现在Java编译器的用户类路径上时,它是怎么确定需要调用哪个方法的呢?当前版本的Java编译器会直接选取第一个方法名以及参数类型匹配的方法。并且,它会根据所选取方法的返回类型来决定可不可以通过编译,以及需不需要进行值转换等。 |
重载的方法在编译过程中即可完成识别。具体到每一个方法调用,Java编译器会根据所传入参数的声明类型(注意与实际类型区分)来选取重载方法。选取的过程共分为三个阶段:
- 在不考虑对基本类型自动装拆箱(auto-boxing,auto-unboxing),以及可变长参数的情况下选取重载方法;
- 如果在第1个阶段中没有找到适配的方法,那么在允许自动装拆箱,但不允许可变长参数的情况下选取重载方法;
- 如果在第2个阶段中没有找到适配的方法,那么在允许自动装拆箱以及可变长参数的情况下选取重载方法。
如果Java编译器在同一个阶段中找到了多个适配的方法,那么它会在其中选择一个最为贴切的,而决定贴切程度的一个关键就是形式参数类型的继承关系。
在开头的例子中,当传入null时,它既可以匹配第一个方法中声明为Object的形式参数,也可以匹配第二个方法中声明为String的形式参数。由于String是Object的子类,因此Java编译器会认为第二个方法更为贴切。
除了同一个类中的方法,重载也可以作用于这个类所继承而来的方法。也就是说,如果子类定义了与父类中非私有方法同名的方法,而且这两个方法的参数类型不同,那么在子类中,这两个方法同样构成了重载。
那么,如果子类定义了与父类中非私有方法同名的方法,而且这两个方法的参数类型相同,那么这两个方法之间又是什么关系呢?
如果这两个方法都是静态的,那么子类中的方法隐藏了父类中的方法。如果这两个方法都不是静态的,且都不是私有的,那么子类的方法重写了父类中的方法。
众所周知,Java是一门面向对象的编程语言,它的一个重要特性便是多态。而方法重写,正是多态最重要的一种体现方式:它允许子类在继承父类部分功能的同时,拥有自己独特的行为。
打个比方,如果你经常漫游,那么你可能知道,拨打10086会根据你当前所在地,连接到当地的客服。重写调用也是如此:它会根据调用者的动态类型,来选取实际的目标方法。
JVM的静态绑定和动态绑定
接下来,我们来看看Java虚拟机是怎么识别方法的。
Java虚拟机识别方法的关键在于类名、方法名以及方法描述符(method descriptor)。前面两个就不做过多的解释了。至于方法描述符,它是由方法的参数类型以及返回类型所构成。在同一个类中,如果同时出现多个名字相同且描述符也相同的方法,那么Java虚拟机会在类的验证阶段报错。
可以看到,Java虚拟机与Java语言不同,它并不限制名字与参数类型相同,但返回类型不同的方法出现在同一个类中,对于调用这些方法的字节码来说,由于字节码所附带的方法描述符包含了返回类型,因此Java虚拟机能够准确地识别目标方法。
Java虚拟机中关于方法重写的判定同样基于方法描述符。也就是说,如果子类定义了与父类中非私有、非静态方法同名的方法,那么只有当这两个方法的参数类型以及返回类型一致,Java虚拟机才会判定为重写。
对于Java语言中重写而Java虚拟机中非重写的情况,编译器会通过生成桥接方法[2]来实现Java中的重写语义。
由于对重载方法的区分在编译阶段已经完成,我们可以认为Java虚拟机不存在重载这一概念。因此,在某些文章中,重载也被称为静态绑定(static binding),或者编译时多态(compile-time polymorphism);而重写则被称为动态绑定(dynamic binding)。
这个说法在Java虚拟机语境下并非完全正确。这是因为某个类中的重载方法可能被它的子类所重写,因此Java编译器会将所有对非私有实例方法的调用编译为需要动态绑定的类型。
确切地说,Java虚拟机中的静态绑定指的是在解析时便能够直接识别目标方法的情况,而动态绑定则指的是需要在运行过程中根据调用者的动态类型来识别目标方法的情况。
具体来说,Java字节码中与调用相关的指令共有五种。
- invokestatic:用于调用静态方法。
- invokespecial:用于调用私有实例方法、构造器,以及使用super关键字调用父类的实例方法或构造器,和所实现接口的默认方法。
- invokevirtual:用于调用非私有实例方法。
- invokeinterface:用于调用接口方法。
- invokedynamic:用于调用动态方法。
由于invokedynamic指令较为复杂,我将在后面的篇章中单独介绍。这里我们只讨论前四种。
我在文章中贴了一段代码,展示了编译生成这四种调用指令的情况。
1 | interface 客户 { |
在代码中,“商户”类定义了一个成员方法,叫做“折后价格”,它将接收一个double类型的参数,以及一个“客户”类型的参数。这里“客户”是一个接口,它定义了一个接口方法,叫“isVIP”。
我们还定义了另一个叫做“奸商”的类,它继承了“商户”类,并且重写了“折后价格”这个方法。如果客户是VIP,那么它会被给到一个更低的折扣。
在这个方法中,我们首先会调用“客户”接口的”isVIP“方法。该调用会被编译为invokeinterface指令。
如果客户是VIP,那么我们会调用奸商类的一个名叫“价格歧视”的静态方法。该调用会被编译为invokestatic指令。如果客户不是VIP,那么我们会通过super关键字调用父类的“折后价格”方法。该调用会被编译为invokespecial指令。
在静态方法“价格歧视”中,我们会调用Random类的构造器。该调用会被编译为invokespecial指令。然后我们会以这个新建的Random对象为调用者,调用Random类中的nextDouble方法。该调用会被编译为invokevirutal指令。
对于invokestatic以及invokespecial而言,Java虚拟机能够直接识别具体的目标方法。
而对于invokevirtual以及invokeinterface而言,在绝大部分情况下,虚拟机需要在执行过程中,根据调用者的动态类型,来确定具体的目标方法。
唯一的例外在于,如果虚拟机能够确定目标方法有且仅有一个,比如说目标方法被标记为final[3][4],那么它可以不通过动态类型,直接确定目标方法。
调用指令的符号引用
在编译过程中,我们并不知道目标方法的具体内存地址。因此,Java编译器会暂时用符号引用来表示该目标方法。这一符号引用包括目标方法所在的类或接口的名字,以及目标方法的方法名和方法描述符。
符号引用存储在class文件的常量池之中。根据目标方法是否为接口方法,这些引用可分为接口符号引用和非接口符号引用。我在文章中贴了一个例子,利用“javap -v”打印某个类的常量池,如果你感兴趣的话可以到文章中查看。
1 | // 在奸商.class的常量池中,#16为接口符号引用,指向接口方法"客户.isVIP()"。而#22为非接口符号引用,指向静态方法"奸商.价格歧视()"。 |
上一篇中我曾提到过,在执行使用了符号引用的字节码前,Java虚拟机需要解析这些符号引用,并替换为实际引用。
对于非接口符号引用,假定该符号引用所指向的类为C,则Java虚拟机会按照如下步骤进行查找。
- 在C中查找符合名字及描述符的方法。
- 如果没有找到,在C的父类中继续搜索,直至Object类。
- 如果没有找到,在C所直接实现或间接实现的接口中搜索,这一步搜索得到的目标方法必须是非私有、非静态的。并且,如果目标方法在间接实现的接口中,则需满足C与该接口之间没有其他符合条件的目标方法。如果有多个符合条件的目标方法,则任意返回其中一个。
从这个解析算法可以看出,静态方法也可以通过子类来调用。此外,子类的静态方法会隐藏(注意与重写区分)父类中的同名、同描述符的静态方法。
对于接口符号引用,假定该符号引用所指向的接口为I,则Java虚拟机会按照如下步骤进行查找。
- 在I中查找符合名字及描述符的方法。
- 如果没有找到,在Object类中的公有实例方法中搜索。
- 如果没有找到,则在I的超接口中搜索。这一步的搜索结果的要求与非接口符号引用步骤3的要求一致。
经过上述的解析步骤之后,符号引用会被解析成实际引用。对于可以静态绑定的方法调用而言,实际引用是一个指向方法的指针。对于需要动态绑定的方法调用而言,实际引用则是一个方法表的索引。具体什么是方法表,我会在下一篇中做出解答。
总结与实践
今天我介绍了Java以及Java虚拟机是如何识别目标方法的。
在Java中,方法存在重载以及重写的概念,重载指的是方法名相同而参数类型不相同的方法之间的关系,重写指的是方法名相同并且参数类型也相同的方法之间的关系。
Java虚拟机识别方法的方式略有不同,除了方法名和参数类型之外,它还会考虑返回类型。
在Java虚拟机中,静态绑定指的是在解析时便能够直接识别目标方法的情况,而动态绑定则指的是需要在运行过程中根据调用者的动态类型来识别目标方法的情况。由于Java编译器已经区分了重载的方法,因此可以认为Java虚拟机中不存在重载。
在class文件中,Java编译器会用符号引用指代目标方法。在执行调用指令前,它所附带的符号引用需要被解析成实际引用。对于可以静态绑定的方法调用而言,实际引用为目标方法的指针。对于需要动态绑定的方法调用而言,实际引用为辅助动态绑定的信息。
在文中我曾提到,Java的重写与Java虚拟机中的重写并不一致,但是编译器会通过生成桥接方法来弥补。今天的实践环节,我们来看一下两个生成桥接方法的例子。你可以通过“javap -v”来查看class文件所包含的方法。
- 重写方法的返回类型不一致:
1 | interface Customer { |
- 范型参数类型造成的方法参数类型不一致:
1 | interface Customer { |
[1] https://docs.oracle.com/javase/8/docs/technotes/guides/language/varargs.html
[2]
https://docs.oracle.com/javase/tutorial/java/generics/bridgeMethods.html
[3]
https://wiki.openjdk.java.net/display/HotSpot/VirtualCalls
[4]
https://wiki.openjdk.java.net/display/HotSpot/InterfaceCalls
05 | JVM是如何执行方法调用的?(下)
作者: 郑雨迪

我在读博士的时候,最怕的事情就是被问有没有新的Idea。有一次我被老板问急了,就随口说了一个。
这个Idea究竟是什么呢,我们知道,设计模式大量使用了虚方法来实现多态。但是虚方法的性能效率并不高,所以我就说,是否能够在此基础上写篇文章,评估每一种设计模式因为虚方法调用而造成的性能开销,并且在文章中强烈谴责一下?
当时呢,我老板教的是一门高级程序设计的课,其中有好几节课刚好在讲设计模式的各种好处。所以,我说完这个Idea,就看到老板的神色略有不悦了,脸上写满了“小郑啊,你这是舍本逐末啊”,于是,我就连忙挽尊,说我是开玩笑的。
在这里呢,我犯的错误其实有两个。第一,我不应该因为虚方法的性能效率,而放弃良好的设计。第二,通常来说,Java虚拟机中虚方法调用的性能开销并不大,有些时候甚至可以完全消除。第一个错误是原则上的,这里就不展开了。至于第二个错误,我们今天便来聊一聊Java虚拟机中虚方法调用的具体实现。
首先,我们来看一个模拟出国边检的小例子。
1 | abstract class Passenger { |
这里我定义了一个抽象类,叫做Passenger,这个类中有一个名为passThroughImmigration的抽象方法,以及重写自Object类的toString方法。
然后,我将Passenger粗暴地分为两种:ChinesePassenger和ForeignerPassenger。
两个类分别实现了passThroughImmigration这个方法,具体来说,就是中国人走中国人通道,外国人走外国人通道。由于咱们储蓄较多,所以我在ChinesePassenger这个类中,还特意添加了一个叫做visitDutyFreeShops的方法。
那么在实际运行过程中,Java虚拟机是如何高效地确定每个Passenger实例应该去哪条通道的呢?我们一起来看一下。
1.虚方法调用
在上一篇中我曾经提到,Java里所有非私有实例方法调用都会被编译成invokevirtual指令,而接口方法调用都会被编译成invokeinterface指令。这两种指令,均属于Java虚拟机中的虚方法调用。
在绝大多数情况下,Java虚拟机需要根据调用者的动态类型,来确定虚方法调用的目标方法。这个过程我们称之为动态绑定。那么,相对于静态绑定的非虚方法调用来说,虚方法调用更加耗时。
在Java虚拟机中,静态绑定包括用于调用静态方法的invokestatic指令,和用于调用构造器、私有实例方法以及超类非私有实例方法的invokespecial指令。如果虚方法调用指向一个标记为final的方法,那么Java虚拟机也可以静态绑定该虚方法调用的目标方法。
Java虚拟机中采取了一种用空间换取时间的策略来实现动态绑定。它为每个类生成一张方法表,用以快速定位目标方法。那么方法表具体是怎样实现的呢?
2.方法表
在介绍那篇类加载机制的链接部分中,我曾提到类加载的准备阶段,它除了为静态字段分配内存之外,还会构造与该类相关联的方法表。
这个数据结构,便是Java虚拟机实现动态绑定的关键所在。下面我将以invokevirtual所使用的虚方法表(virtual method table,vtable)为例介绍方法表的用法。invokeinterface所使用的接口方法表(interface method table,itable)稍微复杂些,但是原理其实是类似的。
方法表本质上是一个数组,每个数组元素指向一个当前类及其祖先类中非私有的实例方法。
这些方法可能是具体的、可执行的方法,也可能是没有相应字节码的抽象方法。方法表满足两个特质:其一,子类方法表中包含父类方法表中的所有方法;其二,子类方法在方法表中的索引值,与它所重写的父类方法的索引值相同。
我们知道,方法调用指令中的符号引用会在执行之前解析成实际引用。对于静态绑定的方法调用而言,实际引用将指向具体的目标方法。对于动态绑定的方法调用而言,实际引用则是方法表的索引值(实际上并不仅是索引值)。
在执行过程中,Java虚拟机将获取调用者的实际类型,并在该实际类型的虚方法表中,根据索引值获得目标方法。这个过程便是动态绑定。

在我们的例子中,Passenger类的方法表包括两个方法:
- toString
- passThroughImmigration,
它们分别对应0号和1号。之所以方法表调换了toString方法和passThroughImmigration方法的位置,是因为toString方法的索引值需要与Object类中同名方法的索引值一致。为了保持简洁,这里我就不考虑Object类中的其他方法。
ForeignerPassenger的方法表同样有两行。其中,0号方法指向继承而来的Passenger类的toString方法。1号方法则指向自己重写的passThroughImmigration方法。
ChinesePassenger的方法表则包括三个方法,除了继承而来的Passenger类的toString方法,自己重写的passThroughImmigration方法之外,还包括独有的visitDutyFreeShops方法。
1 | Passenger passenger = ... |
这里,Java虚拟机的工作可以想象为导航员。每当来了一个乘客需要出境,导航员会先问是中国人还是外国人(获取动态类型),然后翻出中国人/外国人对应的小册子(获取动态类型的方法表),小册子的第1页便写着应该到哪条通道办理出境手续(用1作为索引来查找方法表所对应的目标方法)。
实际上,使用了方法表的动态绑定与静态绑定相比,仅仅多出几个内存解引用操作:访问栈上的调用者,读取调用者的动态类型,读取该类型的方法表,读取方法表中某个索引值所对应的目标方法。相对于创建并初始化Java栈帧来说,这几个内存解引用操作的开销简直可以忽略不计。
那么我们是否可以认为虚方法调用对性能没有太大影响呢?
其实是不能的,上述优化的效果看上去十分美好,但实际上仅存在于解释执行中,或者即时编译代码的最坏情况中。这是因为即时编译还拥有另外两种性能更好的优化手段:内联缓存(inlining cache)和方法内联(method inlining)。下面我便来介绍第一种内联缓存。
3.内联缓存
内联缓存是一种加快动态绑定的优化技术。它能够缓存虚方法调用中调用者的动态类型,以及该类型所对应的目标方法。在之后的执行过程中,如果碰到已缓存的类型,内联缓存便会直接调用该类型所对应的目标方法。如果没有碰到已缓存的类型,内联缓存则会退化至使用基于方法表的动态绑定。
在我们的例子中,这相当于导航员记住了上一个出境乘客的国籍和对应的通道,例如中国人,走了左边通道出境。那么下一个乘客想要出境的时候,导航员会先问是不是中国人,是的话就走左边通道。如果不是的话,只好拿出外国人的小册子,翻到第1页,再告知查询结果:右边。
在针对多态的优化手段中,我们通常会提及以下三个术语。
- 单态(monomorphic)指的是仅有一种状态的情况。
- 多态(polymorphic)指的是有限数量种状态的情况。二态(bimorphic)是多态的其中一种。
- 超多态(megamorphic)指的是更多种状态的情况。通常我们用一个具体数值来区分多态和超多态。在这个数值之下,我们称之为多态。否则,我们称之为超多态。
对于内联缓存来说,我们也有对应的单态内联缓存、多态内联缓存和超多态内联缓存。单态内联缓存,顾名思义,便是只缓存了一种动态类型以及它所对应的目标方法。它的实现非常简单:比较所缓存的动态类型,如果命中,则直接调用对应的目标方法。
多态内联缓存则缓存了多个动态类型及其目标方法。它需要逐个将所缓存的动态类型与当前动态类型进行比较,如果命中,则调用对应的目标方法。
一般来说,我们会将更加热门的动态类型放在前面。在实践中,大部分的虚方法调用均是单态的,也就是只有一种动态类型。为了节省内存空间,Java虚拟机只采用单态内联缓存。
前面提到,当内联缓存没有命中的情况下,Java虚拟机需要重新使用方法表进行动态绑定。对于内联缓存中的内容,我们有两种选择。一是替换单态内联缓存中的纪录。这种做法就好比CPU中的数据缓存,它对数据的局部性有要求,即在替换内联缓存之后的一段时间内,方法调用的调用者的动态类型应当保持一致,从而能够有效地利用内联缓存。
因此,在最坏情况下,我们用两种不同类型的调用者,轮流执行该方法调用,那么每次进行方法调用都将替换内联缓存。也就是说,只有写缓存的额外开销,而没有用缓存的性能提升。
另外一种选择则是劣化为超多态状态。这也是Java虚拟机的具体实现方式。处于这种状态下的内联缓存,实际上放弃了优化的机会。它将直接访问方法表,来动态绑定目标方法。与替换内联缓存纪录的做法相比,它牺牲了优化的机会,但是节省了写缓存的额外开销。
具体到我们的例子,如果来了一队乘客,其中外国人和中国人依次隔开,那么在重复使用的单态内联缓存中,导航员需要反复记住上个出境的乘客,而且记住的信息在处理下一乘客时又会被替换掉。因此,倒不如一直不记,以此来节省脑细胞。
虽然内联缓存附带内联二字,但是它并没有内联目标方法。这里需要明确的是,任何方法调用除非被内联,否则都会有固定开销。这些开销来源于保存程序在该方法中的执行位置,以及新建、压入和弹出新方法所使用的栈帧。
对于极其简单的方法而言,比如说getter/setter,这部分固定开销占据的CPU时间甚至超过了方法本身。此外,在即时编译中,方法内联不仅仅能够消除方法调用的固定开销,而且还增加了进一步优化的可能性,我们会在专栏的第二部分详细介绍方法内联的内容。
总结与实践
今天我介绍了虚方法调用在Java虚拟机中的实现方式。
虚方法调用包括invokevirtual指令和invokeinterface指令。如果这两种指令所声明的目标方法被标记为final,那么Java虚拟机会采用静态绑定。
否则,Java虚拟机将采用动态绑定,在运行过程中根据调用者的动态类型,来决定具体的目标方法。
Java虚拟机的动态绑定是通过方法表这一数据结构来实现的。方法表中每一个重写方法的索引值,与父类方法表中被重写的方法的索引值一致。
在解析虚方法调用时,Java虚拟机会纪录下所声明的目标方法的索引值,并且在运行过程中根据这个索引值查找具体的目标方法。
Java虚拟机中的即时编译器会使用内联缓存来加速动态绑定。Java虚拟机所采用的单态内联缓存将纪录调用者的动态类型,以及它所对应的目标方法。
当碰到新的调用者时,如果其动态类型与缓存中的类型匹配,则直接调用缓存的目标方法。
否则,Java虚拟机将该内联缓存劣化为超多态内联缓存,在今后的执行过程中直接使用方法表进行动态绑定。
在今天的实践环节,我们来观测一下单态内联缓存和超多态内联缓存的性能差距。为了消除方法内联的影响,请使用如下的命令。
1 | // Run with: java -XX:CompileCommand='dontinline,*.passThroughImmigration' Passenger |
06 | JVM是如何处理异常的?
作者: 郑雨迪

你好,我是郑雨迪。今天我们来讲讲Java虚拟机的异常处理。
众所周知,异常处理的两大组成要素是抛出异常和捕获异常。这两大要素共同实现程序控制流的非正常转移。
抛出异常可分为显式和隐式两种。显式抛异常的主体是应用程序,它指的是在程序中使用“throw”关键字,手动将异常实例抛出。隐式抛异常的主体则是Java虚拟机,它指的是Java虚拟机在执行过程中,碰到无法继续执行的异常状态,自动抛出异常。举例来说,Java虚拟机在执行读取数组操作时,发现输入的索引值是负数,故而抛出数组索引越界异常(ArrayIndexOutOfBoundsException)。
捕获异常则涉及了如下三种代码块。
try代码块:用来标记需要进行异常监控的代码。
catch代码块:跟在try代码块之后,用来捕获在try代码块中触发的某种指定类型的异常。除了声明所捕获异常的类型之外,catch代码块还定义了针对该异常类型的异常处理器。在Java中,try代码块后面可以跟着多个catch代码块,来捕获不同类型的异常。Java虚拟机会从上至下匹配异常处理器。因此,前面的catch代码块所捕获的异常类型不能覆盖后边的,否则编译器会报错。
finally代码块:跟在try代码块和catch代码块之后,用来声明一段必定运行的代码。它的设计初衷是为了避免跳过某些关键的清理代码,例如关闭已打开的系统资源。
在程序正常执行的情况下,这段代码会在try代码块之后运行。否则,也就是try代码块触发异常的情况下,如果该异常没有被捕获,finally代码块会直接运行,并且在运行之后重新抛出该异常。如果该异常被catch代码块捕获,finally代码块则在catch代码块之后运行。在某些不幸的情况下,catch代码块也触发了异常,那么finally代码块同样会运行,并会抛出catch代码块触发的异常。在某些极端不幸的情况下,finally代码块也触发了异常,那么只好中断当前finally代码块的执行,并往外抛异常。
上面这段听起来有点绕,但是等我讲完Java虚拟机的异常处理机制之后,你便会明白这其中的道理。
异常的基本概念
在Java语言规范中,所有异常都是Throwable类或者其子类的实例。Throwable有两大直接子类。第一个是Error,涵盖程序不应捕获的异常。当程序触发Error时,它的执行状态已经无法恢复,需要中止线程甚至是中止虚拟机。第二子类则是Exception,涵盖程序可能需要捕获并且处理的异常。Exception有一个特殊的子类RuntimeException,用来表示“程序虽然无法继续执行,但是还能抢救一下”的情况。前边提到的数组索引越界便是其中的一种。

RuntimeException和Error属于Java里的非检查异常(unchecked exception)。其他异常则属于检查异常(checked exception)。在Java语法中,所有的检查异常都需要程序显式地捕获,或者在方法声明中用throws关键字标注。通常情况下,程序中自定义的异常应为检查异常,以便最大化利用Java编译器的编译时检查。
异常实例的构造十分昂贵。这是由于在构造异常实例时,Java虚拟机便需要生成该异常的栈轨迹(stack trace)。该操作会逐一访问当前线程的Java栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常。
当然,在生成栈轨迹时,Java虚拟机会忽略掉异常构造器以及填充栈帧的Java方法(Throwable.fillInStackTrace),直接从新建异常位置开始算起。此外,Java虚拟机还会忽略标记为不可见的Java方法栈帧。我们在介绍Lambda的时候会看到具体的例子。
既然异常实例的构造十分昂贵,我们是否可以缓存异常实例,在需要用到的时候直接抛出呢?从语法角度上来看,这是允许的。然而,该异常对应的栈轨迹并非throw语句的位置,而是新建异常的位置。因此,这种做法可能会误导开发人员,使其定位到错误的位置。这也是为什么在实践中,我们往往选择抛出新建异常实例的原因。
Java虚拟机是如何捕获异常的?
在编译生成的字节码中,每个方法都附带一个异常表。异常表中的每一个条目代表一个异常处理器,并且由from指针、to指针、target指针以及所捕获的异常类型构成。这些指针的值是字节码索引(bytecode index,bci),用以定位字节码。
其中,from指针和to指针标示了该异常处理器所监控的范围,例如try代码块所覆盖的范围。target指针则指向异常处理器的起始位置,例如catch代码块的起始位置。
1 | public static void main(String[] args) { |
举个例子,在上面这段代码的main方法中,我定义了一段try-catch代码。其中,catch代码块所捕获的异常类型为Exception。
编译过后,该方法的异常表拥有一个条目。其from指针和to指针分别为0和3,代表它的监控范围从索引为0的字节码开始,到索引为3的字节码结束(不包括3)。该条目的target指针是6,代表这个异常处理器从索引为6的字节码开始。条目的最后一列,代表该异常处理器所捕获的异常类型正是Exception。
当程序触发异常时,Java虚拟机会从上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某个异常表条目的监控范围内,Java虚拟机会判断所抛出的异常和该条目想要捕获的异常是否匹配。
如果匹配,Java虚拟机会将控制流转移至该条目target指针指向的字节码。如果遍历完所有异常表条目,Java虚拟机仍未匹配到异常处理器,那么它会弹出当前方法对应的Java栈帧,并且在调用者(caller)中重复上述操作。在最坏情况下,Java虚拟机需要遍历当前线程Java栈上所有方法的异常表。
finally代码块的编译比较复杂。当前版本Java编译器的做法,是复制finally代码块的内容,分别放在try-catch代码块所有正常执行路径以及异常执行路径的出口中。

针对异常执行路径,Java编译器会生成一个或多个异常表条目,监控整个try-catch代码块,并且捕获所有种类的异常(在javap中以any指代)。这些异常表条目的target指针将指向另一份复制的finally代码块。并且,在这个finally代码块的最后,Java编译器会重新抛出所捕获的异常。
如果你感兴趣的话,可以用javap工具来查看下面这段包含了try-catch-finally代码块的编译结果。为了更好地区分每个代码块,我定义了四个实例字段:tryBlock、catchBlock、finallyBlock、以及methodExit,并且仅在对应的代码块中访问这些字段。
1 | public class Foo { |
可以看到,编译结果包含三份finally代码块。其中,前两份分别位于try代码块和catch代码块的正常执行路径出口。最后一份则作为异常处理器,监控try代码块以及catch代码块。它将捕获try代码块触发的、未被catch代码块捕获的异常,以及catch代码块触发的异常。
这里有一个小问题,如果catch代码块捕获了异常,并且触发了另一个异常,那么finally捕获并且重抛的异常是哪个呢?答案是后者。也就是说原本的异常便会被忽略掉,这对于代码调试来说十分不利。
Java 7的Suppressed异常以及语法糖
Java 7引入了Suppressed异常来解决这个问题。这个新特性允许开发人员将一个异常附于另一个异常之上。因此,抛出的异常可以附带多个异常的信息。然而,Java层面的finally代码块缺少指向所捕获异常的引用,所以这个新特性使用起来非常繁琐。
为此,Java 7专门构造了一个名为try-with-resources的语法糖,在字节码层面自动使用Suppressed异常。当然,该语法糖的主要目的并不是使用Suppressed异常,而是精简资源打开关闭的用法。
在Java 7之前,对于打开的资源,我们需要定义一个finally代码块,来确保该资源在正常或者异常执行状况下都能关闭。资源的关闭操作本身容易触发异常。因此,如果同时打开多个资源,那么每一个资源都要对应一个独立的try-finally代码块,以保证每个资源都能够关闭。这样一来,代码将会变得十分繁琐。
1 | FileInputStream in0 = null; |
Java 7的try-with-resources语法糖,极大地简化了上述代码。程序可以在try关键字后声明并实例化实现了AutoCloseable接口的类,编译器将自动添加对应的close()操作。在声明多个AutoCloseable实例的情况下,编译生成的字节码类似于上面手工编写代码的编译结果。与手工代码相比,try-with-resources还会使用Suppressed异常的功能,来避免原异常“被消失”。
1 | public class Foo implements AutoCloseable { |
除了try-with-resources语法糖之外,Java 7还支持在同一catch代码块中捕获多种异常。实际实现非常简单,生成多个异常表条目即可。
1 | // 在同一catch代码块中捕获多种异常 |
总结与实践
今天我介绍了Java虚拟机的异常处理机制。
Java的异常分为Exception和Error两种,而Exception又分为RuntimeException和其他类型。RuntimeException和Error属于非检查异常。其他的Exception皆属于检查异常,在触发时需要显式捕获,或者在方法头用throws关键字声明。
Java字节码中,每个方法对应一个异常表。当程序触发异常时,Java虚拟机将查找异常表,并依此决定需要将控制流转移至哪个异常处理器之中。Java代码中的catch代码块和finally代码块都会生成异常表条目。
Java 7引入了Suppressed异常、try-with-resources,以及多异常捕获。后两者属于语法糖,能够极大地精简我们的代码。
那么今天的实践环节,你可以看看其他控制流语句与finally代码块之间的协作。
1 | // 编译并用javap -c查看编译后的字节码 |
07 | JVM是如何实现反射的?
作者: 郑雨迪

今天我们来聊聊Java里的反射机制。
反射是Java语言中一个相当重要的特性,它允许正在运行的Java程序观测,甚至是修改程序的动态行为。
举例来说,我们可以通过Class对象枚举该类中的所有方法,我们还可以通过Method.setAccessible(位于java.lang.reflect包,该方法继承自AccessibleObject)绕过Java语言的访问权限,在私有方法所在类之外的地方调用该方法。
反射在Java中的应用十分广泛。开发人员日常接触到的Java集成开发环境(IDE)便运用了这一功能:每当我们敲入点号时,IDE便会根据点号前的内容,动态展示可以访问的字段或者方法。
另一个日常应用则是Java调试器,它能够在调试过程中枚举某一对象所有字段的值。
(图中eclipse的自动提示使用了反射)
在Web开发中,我们经常能够接触到各种可配置的通用框架。为了保证框架的可扩展性,它们往往借助Java的反射机制,根据配置文件来加载不同的类。举例来说,Spring框架的依赖反转(IoC),便是依赖于反射机制。
然而,我相信不少开发人员都嫌弃反射机制比较慢。甚至是甲骨文关于反射的教学网页[1],也强调了反射性能开销大的缺点。
今天我们便来了解一下反射的实现机制,以及它性能糟糕的原因。如果你对反射API不是特别熟悉的话,你可以查阅我放在文稿末尾的附录。
反射调用的实现
首先,我们来看看方法的反射调用,也就是Method.invoke,是怎么实现的。
1 | public final class Method extends Executable { |
如果你查阅Method.invoke的源代码,那么你会发现,它实际上委派给MethodAccessor来处理。MethodAccessor是一个接口,它有两个已有的具体实现:一个通过本地方法来实现反射调用,另一个则使用了委派模式。为了方便记忆,我便用“本地实现”和“委派实现”来指代这两者。
每个Method实例的第一次反射调用都会生成一个委派实现,它所委派的具体实现便是一个本地实现。本地实现非常容易理解。当进入了Java虚拟机内部之后,我们便拥有了Method实例所指向方法的具体地址。这时候,反射调用无非就是将传入的参数准备好,然后调用进入目标方法。
1 | // v0版本 |
为了方便理解,我们可以打印一下反射调用到目标方法时的栈轨迹。在上面的v0版本代码中,我们获取了一个指向Test.target方法的Method对象,并且用它来进行反射调用。在Test.target中,我会打印出栈轨迹。
可以看到,反射调用先是调用了Method.invoke,然后进入委派实现(DelegatingMethodAccessorImpl),再然后进入本地实现(NativeMethodAccessorImpl),最后到达目标方法。
这里你可能会疑问,为什么反射调用还要采取委派实现作为中间层?直接交给本地实现不可以么?
其实,Java的反射调用机制还设立了另一种动态生成字节码的实现(下称动态实现),直接使用invoke指令来调用目标方法。之所以采用委派实现,便是为了能够在本地实现以及动态实现中切换。
1 | // 动态实现的伪代码,这里只列举了关键的调用逻辑,其实它还包括调用者检测、参数检测的字节码。 |
动态实现和本地实现相比,其运行效率要快上20倍 [2] 。这是因为动态实现无需经过Java到C++再到Java的切换,但由于生成字节码十分耗时,仅调用一次的话,反而是本地实现要快上3到4倍 [3]。
考虑到许多反射调用仅会执行一次,Java虚拟机设置了一个阈值15(可以通过-Dsun.reflect.inflationThreshold=来调整),当某个反射调用的调用次数在15之下时,采用本地实现;当达到15时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为Inflation。
为了观察这个过程,我将刚才的例子更改为下面的v1版本。它会将反射调用循环20次。
1 | // v1版本 |
可以看到,在第15次(从0开始数)反射调用时,我们便触发了动态实现的生成。这时候,Java虚拟机额外加载了不少类。其中,最重要的当属GeneratedMethodAccessor1(第30行)。并且,从第16次反射调用开始,我们便切换至这个刚刚生成的动态实现(第40行)。
反射调用的Inflation机制是可以通过参数(-Dsun.reflect.noInflation=true)来关闭的。这样一来,在反射调用一开始便会直接生成动态实现,而不会使用委派实现或者本地实现。
反射调用的开销
下面,我们便来拆解反射调用的性能开销。
在刚才的例子中,我们先后进行了Class.forName,Class.getMethod以及Method.invoke三个操作。其中,Class.forName会调用本地方法,Class.getMethod则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法。可想而知,这两个操作都非常费时。
值得注意的是,以getMethod为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回Method数组的getMethods或者getDeclaredMethods方法,以减少不必要的堆空间消耗。
在实践中,我们往往会在应用程序中缓存Class.forName和Class.getMethod的结果。因此,下面我就只关注反射调用本身的性能开销。
为了比较直接调用和反射调用的性能差距,我将前面的例子改为下面的v2版本。它会将反射调用循环二十亿次。此外,它还将记录下每跑一亿次的时间。
我将取最后五个记录的平均值,作为预热后的峰值性能。(注:这种性能评估方式并不严谨,我会在专栏的第三部分介绍如何用JMH来测性能。)
在我这个老笔记本上,一亿次直接调用耗费的时间大约在120ms。这和不调用的时间是一致的。其原因在于这段代码属于热循环,同样会触发即时编译。并且,即时编译会将对Test.target的调用内联进来,从而消除了调用的开销。
1 | // v2版本 |
下面我将以120ms作为基准,来比较反射调用的性能开销。
由于目标方法Test.target接收一个int类型的参数,因此我传入128作为反射调用的参数,测得的结果约为基准的2.7倍。我们暂且不管这个数字是高是低,先来看看在反射调用之前字节码都做了什么。
1 | 59: aload_2 // 加载Method对象 |
这里我截取了循环中反射调用编译而成的字节码。可以看到,这段字节码除了反射调用外,还额外做了两个操作。
第一,由于Method.invoke是一个变长参数方法,在字节码层面它的最后一个参数会是Object数组(感兴趣的同学私下可以用javap查看)。Java编译器会在方法调用处生成一个长度为传入参数数量的Object数组,并将传入参数一一存储进该数组中。
第二,由于Object数组不能存储基本类型,Java编译器会对传入的基本类型参数进行自动装箱。
这两个操作除了带来性能开销外,还可能占用堆内存,使得GC更加频繁。(如果你感兴趣的话,可以用虚拟机参数-XX:+PrintGC试试。)那么,如何消除这部分开销呢?
关于第二个自动装箱,Java缓存了[-128, 127]中所有整数所对应的Integer对象。当需要自动装箱的整数在这个范围之内时,便返回缓存的Integer,否则需要新建一个Integer对象。
因此,我们可以将这个缓存的范围扩大至覆盖128(对应参数
-Djava.lang.Integer.IntegerCache.high=128),便可以避免需要新建Integer对象的场景。
或者,我们可以在循环外缓存128自动装箱得到的Integer对象,并且直接传入反射调用中。这两种方法测得的结果差不多,约为基准的1.8倍。
现在我们再回来看看第一个因变长参数而自动生成的Object数组。既然每个反射调用对应的参数个数是固定的,那么我们可以选择在循环外新建一个Object数组,设置好参数,并直接交给反射调用。改好的代码可以参照文稿中的v3版本。
1 | // v3版本 |
测得的结果反而更糟糕了,为基准的2.9倍。这是为什么呢?
如果你在上一步解决了自动装箱之后查看运行时的GC状况,你会发现这段程序并不会触发GC。其原因在于,原本的反射调用被内联了,从而使得即时编译器中的逃逸分析将原本新建的Object数组判定为不逃逸的对象。
如果一个对象不逃逸,那么即时编译器可以选择栈分配甚至是虚拟分配,也就是不占用堆空间。具体我会在本专栏的第二部分详细解释。
如果在循环外新建数组,即时编译器无法确定这个数组会不会中途被更改,因此无法优化掉访问数组的操作,可谓是得不偿失。
到目前为止,我们的最好记录是1.8倍。那能不能再进一步提升呢?
刚才我曾提到,可以关闭反射调用的Inflation机制,从而取消委派实现,并且直接使用动态实现。此外,每次反射调用都会检查目标方法的权限,而这个检查同样可以在Java代码里关闭,在关闭了这两项机制之后,也就得到了我们的v4版本,它测得的结果约为基准的1.3倍。
1 | // v4版本 |
到这里,我们基本上把反射调用的水分都榨干了。接下来,我来把反射调用的性能开销给提回去。
首先,在这个例子中,之所以反射调用能够变得这么快,主要是因为即时编译器中的方法内联。在关闭了Inflation的情况下,内联的瓶颈在于Method.invoke方法中对MethodAccessor.invoke方法的调用。

我会在后面的文章中介绍方法内联的具体实现,这里先说个结论:在生产环境中,我们往往拥有多个不同的反射调用,对应多个GeneratedMethodAccessor,也就是动态实现。
由于Java虚拟机的关于上述调用点的类型profile(注:对于invokevirtual或者invokeinterface,Java虚拟机会记录下调用者的具体类型,我们称之为类型profile)无法同时记录这么多个类,因此可能造成所测试的反射调用没有被内联的情况。
1 | // v5版本 |
在上面的v5版本中,我在测试循环之前调用了polluteProfile的方法。该方法将反射调用另外两个方法,并且循环上2000遍。
而测试循环则保持不变。测得的结果约为基准的6.7倍。也就是说,只要误扰了Method.invoke方法的类型profile,性能开销便会从1.3倍上升至6.7倍。
之所以这么慢,除了没有内联之外,另外一个原因是逃逸分析不再起效。这时候,我们便可以采用刚才v3版本中的解决方案,在循环外构造参数数组,并直接传递给反射调用。这样子测得的结果约为基准的5.2倍。
除此之外,我们还可以提高Java虚拟机关于每个调用能够记录的类型数目(对应虚拟机参数-XX:TypeProfileWidth,默认值为2,这里设置为3)。最终测得的结果约为基准的2.8倍,尽管它和原本的1.3倍还有一定的差距,但总算是比6.7倍好多了。
总结与实践
今天我介绍了Java里的反射机制。
在默认情况下,方法的反射调用为委派实现,委派给本地实现来进行方法调用。在调用超过15次之后,委派实现便会将委派对象切换至动态实现。这个动态实现的字节码是自动生成的,它将直接使用invoke指令来调用目标方法。
方法的反射调用会带来不少性能开销,原因主要有三个:变长参数方法导致的Object数组,基本类型的自动装箱、拆箱,还有最重要的方法内联。
今天的实践环节,你可以将最后一段代码中polluteProfile方法的两个Method对象,都改成获取名字为“target”的方法。请问这两个获得的Method对象是同一个吗(==)?他们equal吗(.equals(…))?对我们的运行结果有什么影响?
1 | import java.lang.reflect.Method; |
附录:反射API简介
通常来说,使用反射API的第一步便是获取Class对象。在Java中常见的有这么三种。
- 使用静态方法Class.forName来获取。
- 调用对象的getClass()方法。
- 直接用类名+“.class”访问。对于基本类型来说,它们的包装类型(wrapper classes)拥有一个名为“TYPE”的final静态字段,指向该基本类型对应的Class对象。
例如,Integer.TYPE指向int.class。对于数组类型来说,可以使用类名+“[ ].class”来访问,如int[ ].class。
除此之外,Class类和java.lang.reflect包中还提供了许多返回Class对象的方法。例如,对于数组类的Class对象,调用Class.getComponentType()方法可以获得数组元素的类型。
一旦得到了Class对象,我们便可以正式地使用反射功能了。下面我列举了较为常用的几项。
使用newInstance()来生成一个该类的实例。它要求该类中拥有一个无参数的构造器。
使用isInstance(Object)来判断一个对象是否该类的实例,语法上等同于instanceof关键字(JIT优化时会有差别,我会在本专栏的第二部分详细介绍)。
使用Array.newInstance(Class,int)来构造该类型的数组。
使用getFields()/getConstructors()/getMethods()来访问该类的成员。除了这三个之外,Class类还提供了许多其他方法,详见[4]。需要注意的是,方法名中带Declared的不会返回父类的成员,但是会返回私有成员;而不带Declared的则相反。
当获得了类成员之后,我们可以进一步做如下操作。
- 使用Constructor/Field/Method.setAccessible(true)来绕开Java语言的访问限制。
- 使用Constructor.newInstance(Object[])来生成该类的实例。
- 使用Field.get/set(Object)来访问字段的值。
- 使用Method.invoke(Object, Object[])来调用方法。
有关反射API的其他用法,可以参考reflect包的javadoc [5] ,这里就不详细展开了。
[1] : https://docs.oracle.com/javase/tutorial/reflect/
[4]: https://docs.oracle.com/javase/tutorial/reflect/class/classMembers.html
[5]: https://docs.oracle.com/javase/10/docs/api/java/lang/reflect/package-summary.html
08 | JVM是怎么实现invokedynamic的?(上)
作者: 郑雨迪

前不久,“虚拟机”赛马俱乐部来了个年轻人,标榜自己是动态语言,是先进分子。
这一天,先进分子牵着一头鹿进来,说要参加赛马。咱部里的老学究Java就不同意了呀,鹿又不是马,哪能参加赛马。
当然了,这种墨守成规的调用方式,自然是先进分子所不齿的。现在年轻人里流行的是鸭子类型(duck typing)[1],只要是跑起来像只马的,它就是一只马,也就能够参加赛马比赛。
1 | class Horse { |
(如何用同一种方式调用他们的赛跑方法?)
说到了这里,如果我们将赛跑定义为对赛跑方法(对应上述代码中的race())的调用的话,那么这个故事的关键,就在于能不能在马场中调用非马类型的赛跑方法。
为了解答这个问题,我们先来回顾一下Java里的方法调用。在Java中,方法调用会被编译为invokestatic,invokespecial,invokevirtual以及invokeinterface四种指令。这些指令与包含目标方法类名、方法名以及方法描述符的符号引用捆绑。在实际运行之前,Java虚拟机将根据这个符号引用链接到具体的目标方法。
可以看到,在这四种调用指令中,Java虚拟机明确要求方法调用需要提供目标方法的类名。在这种体系下,我们有两个解决方案。一是调用其中一种类型的赛跑方法,比如说马类的赛跑方法。对于非马的类型,则给它套一层马甲,当成马来赛跑。
另外一种解决方式,是通过反射机制,来查找并且调用各个类型中的赛跑方法,以此模拟真正的赛跑。
显然,比起直接调用,这两种方法都相当复杂,执行效率也可想而知。为了解决这个问题,Java 7引入了一条新的指令invokedynamic。该指令的调用机制抽象出调用点这一个概念,并允许应用程序将调用点链接至任意符合条件的方法上。
1 | public static void startRace(java.lang.Object) |
(理想的调用方式)
作为invokedynamic的准备工作,Java 7引入了更加底层、更加灵活的方法抽象 :方法句柄(MethodHandle)。
方法句柄的概念
方法句柄是一个强类型的,能够被直接执行的引用[2]。该引用可以指向常规的静态方法或者实例方法,也可以指向构造器或者字段。当指向字段时,方法句柄实则指向包含字段访问字节码的虚构方法,语义上等价于目标字段的getter或者setter方法。
这里需要注意的是,它并不会直接指向目标字段所在类中的getter/setter,毕竟你无法保证已有的getter/setter方法就是在访问目标字段。
方法句柄的类型(MethodType)是由所指向方法的参数类型以及返回类型组成的。它是用来确认方法句柄是否适配的唯一关键。当使用方法句柄时,我们其实并不关心方法句柄所指向方法的类名或者方法名。
打个比方,如果兔子的“赛跑”方法和“睡觉”方法的参数类型以及返回类型一致,那么对于兔子递过来的一个方法句柄,我们并不知道会是哪一个方法。
方法句柄的创建是通过MethodHandles.Lookup类来完成的。它提供了多个API,既可以使用反射API中的Method来查找,也可以根据类、方法名以及方法句柄类型来查找。
当使用后者这种查找方式时,用户需要区分具体的调用类型,比如说对于用invokestatic调用的静态方法,我们需要使用Lookup.findStatic方法;对于用invokevirtual调用的实例方法,以及用invokeinterface调用的接口方法,我们需要使用findVirtual方法;对于用invokespecial调用的实例方法,我们则需要使用findSpecial方法。
调用方法句柄,和原本对应的调用指令是一致的。也就是说,对于原本用invokevirtual调用的方法句柄,它也会采用动态绑定;而对于原本用invokespecial调用的方法句柄,它会采用静态绑定。
1 | class Foo { |
方法句柄同样也有权限问题。但它与反射API不同,其权限检查是在句柄的创建阶段完成的。在实际调用过程中,Java虚拟机并不会检查方法句柄的权限。如果该句柄被多次调用的话,那么与反射调用相比,它将省下重复权限检查的开销。
需要注意的是,方法句柄的访问权限不取决于方法句柄的创建位置,而是取决于Lookup对象的创建位置。
举个例子,对于一个私有字段,如果Lookup对象是在私有字段所在类中获取的,那么这个Lookup对象便拥有对该私有字段的访问权限,即使是在所在类的外边,也能够通过该Lookup对象创建该私有字段的getter或者setter。
由于方法句柄没有运行时权限检查,因此,应用程序需要负责方法句柄的管理。一旦它发布了某些指向私有方法的方法句柄,那么这些私有方法便被暴露出去了。
方法句柄的操作
方法句柄的调用可分为两种,一是需要严格匹配参数类型的invokeExact。它有多严格呢?假设一个方法句柄将接收一个Object类型的参数,如果你直接传入String作为实际参数,那么方法句柄的调用会在运行时抛出方法类型不匹配的异常。正确的调用方式是将该String显式转化为Object类型。
在普通Java方法调用中,我们只有在选择重载方法时,才会用到这种显式转化。这是因为经过显式转化后,参数的声明类型发生了改变,因此有可能匹配到不同的方法描述符,从而选取不同的目标方法。调用方法句柄也是利用同样的原理,并且涉及了一个签名多态性(signature polymorphism)的概念。(在这里我们暂且认为签名等同于方法描述符。)
1 | public final native @PolymorphicSignature Object invokeExact(Object... args) throws Throwable; |
方法句柄API有一个特殊的注解类@PolymorphicSignature。在碰到被它注解的方法调用时,Java编译器会根据所传入参数的声明类型来生成方法描述符,而不是采用目标方法所声明的描述符。
在刚才的例子中,当传入的参数是String时,对应的方法描述符包含String类;而当我们转化为Object时,对应的方法描述符则包含Object类。
1 | public void test(MethodHandle mh, String s) throws Throwable { |
invokeExact会确认该invokevirtual指令对应的方法描述符,和该方法句柄的类型是否严格匹配。在不匹配的情况下,便会在运行时抛出异常。
如果你需要自动适配参数类型,那么你可以选取方法句柄的第二种调用方式invoke。它同样是一个签名多态性的方法。invoke会调用MethodHandle.asType方法,生成一个适配器方法句柄,对传入的参数进行适配,再调用原方法句柄。调用原方法句柄的返回值同样也会先进行适配,然后再返回给调用者。
方法句柄还支持增删改参数的操作,这些操作都是通过生成另一个方法句柄来实现的。这其中,改操作就是刚刚介绍的MethodHandle.asType方法。删操作指的是将传入的部分参数就地抛弃,再调用另一个方法句柄。它对应的API是MethodHandles.dropArguments方法。
增操作则非常有意思。它会往传入的参数中插入额外的参数,再调用另一个方法句柄,它对应的API是MethodHandle.bindTo方法。Java 8中捕获类型的Lambda表达式便是用这种操作来实现的,下一篇我会详细进行解释。
增操作还可以用来实现方法的柯里化[3]。举个例子,有一个指向f(x, y)的方法句柄,我们可以通过将x绑定为4,生成另一个方法句柄g(y) = f(4, y)。在执行过程中,每当调用g(y)的方法句柄,它会在参数列表最前面插入一个4,再调用指向f(x, y)的方法句柄。
方法句柄的实现
下面我们来看看HotSpot虚拟机中方法句柄调用的具体实现。(由于篇幅原因,这里只讨论DirectMethodHandle。)
前面提到,调用方法句柄所使用的invokeExact或者invoke方法具备签名多态性的特性。它们会根据具体的传入参数来生成方法描述符。那么,拥有这个描述符的方法实际存在吗?对invokeExact或者invoke的调用具体会进入哪个方法呢?
1 | import java.lang.invoke.*; |
和查阅反射调用的方式一样,我们可以通过新建异常实例来查看栈轨迹。打印出来的占轨迹如下所示:
1 | $ java Foo |
也就是说,invokeExact的目标方法竟然就是方法句柄指向的方法。
先别高兴太早。我刚刚提到过,invokeExact会对参数的类型进行校验,并在不匹配的情况下抛出异常。如果它直接调用了方法句柄所指向的方法,那么这部分参数类型校验的逻辑将无处安放。因此,唯一的可能便是Java虚拟机隐藏了部分栈信息。
当我们启用了-XX:+ShowHiddenFrames这个参数来打印被Java虚拟机隐藏了的栈信息时,你会发现main方法和目标方法中间隔着两个貌似是生成的方法。
1 | $ java -XX:+UnlockDiagnosticVMOptions -XX:+ShowHiddenFrames Foo |
实际上,Java虚拟机会对invokeExact调用做特殊处理,调用至一个共享的、与方法句柄类型相关的特殊适配器中。这个适配器是一个LambdaForm,我们可以通过添加虚拟机参数将之导出成class文件(-Djava.lang.invoke.MethodHandle.DUMP_CLASS_FILES=true)。
1 | final class java.lang.invoke.LambdaForm$MH000 { static void invokeExact_MT000_LLLLV(jeava.lang.bject, jjava.lang.bject, jjava.lang.bject); |
可以看到,在这个适配器中,它会调用Invokers.checkExactType方法来检查参数类型,然后调用Invokers.checkCustomized方法。后者会在方法句柄的执行次数超过一个阈值时进行优化(对应参数-Djava.lang.invoke.MethodHandle.CUSTOMIZE_THRESHOLD,默认值为127)。最后,它会调用方法句柄的invokeBasic方法。
Java虚拟机同样会对invokeBasic调用做特殊处理,这会将调用至方法句柄本身所持有的适配器中。这个适配器同样是一个LambdaForm,你可以通过反射机制将其打印出来。
1 | // 该方法句柄持有的LambdaForm实例的toString()结果 |
这个适配器将获取方法句柄中的MemberName类型的字段,并且以它为参数调用linkToStatic方法。估计你已经猜到了,Java虚拟机也会对linkToStatic调用做特殊处理,它将根据传入的MemberName参数所存储的方法地址或者方法表索引,直接跳转至目标方法。
1 | final class MemberName implements Member, Cloneable { |
那么前面那个适配器中的优化又是怎么回事?实际上,方法句柄一开始持有的适配器是共享的。当它被多次调用之后,Invokers.checkCustomized方法会为该方法句柄生成一个特有的适配器。这个特有的适配器会将方法句柄作为常量,直接获取其MemberName类型的字段,并继续后面的linkToStatic调用。
1 | final class java.lang.invoke.LambdaForm$DMH000 { |
可以看到,方法句柄的调用和反射调用一样,都是间接调用。因此,它也会面临无法内联的问题。不过,与反射调用不同的是,方法句柄的内联瓶颈在于即时编译器能否将该方法句柄识别为常量。具体内容我会在下一篇中进行详细的解释。
总结与实践
今天我介绍了invokedynamic底层机制的基石:方法句柄。
方法句柄是一个强类型的、能够被直接执行的引用。它仅关心所指向方法的参数类型以及返回类型,而不关心方法所在的类以及方法名。方法句柄的权限检查发生在创建过程中,相较于反射调用节省了调用时反复权限检查的开销。
方法句柄可以通过invokeExact以及invoke来调用。其中,invokeExact要求传入的参数和所指向方法的描述符严格匹配。方法句柄还支持增删改参数的操作,这些操作是通过生成另一个充当适配器的方法句柄来实现的。
方法句柄的调用和反射调用一样,都是间接调用,同样会面临无法内联的问题。
今天的实践环节,我们来测量一下方法句柄的性能。你可以尝试通过重构代码,将方法句柄变成常量,来提升方法句柄调用的性能。
1 | public class Foo { |
[1] https://en.wikipedia.org/wiki/Duck_typing
[2]
https://docs.oracle.com/javase/10/docs/api/java/lang/invoke/MethodHandle.html
[3]
https://en.wikipedia.org/wiki/Currying
09 | JVM是怎么实现invokedynamic的?(下)
作者: 郑雨迪

上回讲到,为了让所有的动物都能参加赛马,Java 7引入了invokedynamic机制,允许调用任意类的“赛跑”方法。不过,我们并没有讲解invokedynamic,而是深入地探讨了它所依赖的方法句柄。
今天,我便来正式地介绍invokedynamic指令,讲讲它是如何生成调用点,并且允许应用程序自己决定链接至哪一个方法中的。
invokedynamic指令
invokedynamic是Java 7引入的一条新指令,用以支持动态语言的方法调用。具体来说,它将调用点(CallSite)抽象成一个Java类,并且将原本由Java虚拟机控制的方法调用以及方法链接暴露给了应用程序。在运行过程中,每一条invokedynamic指令将捆绑一个调用点,并且会调用该调用点所链接的方法句柄。
在第一次执行invokedynamic指令时,Java虚拟机会调用该指令所对应的启动方法(BootStrap Method),来生成前面提到的调用点,并且将之绑定至该invokedynamic指令中。在之后的运行过程中,Java虚拟机则会直接调用绑定的调用点所链接的方法句柄。
在字节码中,启动方法是用方法句柄来指定的。这个方法句柄指向一个返回类型为调用点的静态方法。该方法必须接收三个固定的参数,分别为一个Lookup类实例,一个用来指代目标方法名字的字符串,以及该调用点能够链接的方法句柄的类型。
除了这三个必需参数之外,启动方法还可以接收若干个其他的参数,用来辅助生成调用点,或者定位所要链接的目标方法。
1 | import java.lang.invoke.*; |
我在文稿中贴了一段代码,其中便包含一个启动方法。它将接收前面提到的三个固定参数,并且返回一个链接至Horse.race方法的ConstantCallSite。
这里的ConstantCallSite是一种不可以更改链接对象的调用点。除此之外,Java核心类库还提供多种可以更改链接对象的调用点,比如MutableCallSite和VolatileCallSite。
这两者的区别就好比正常字段和volatile字段之间的区别。此外,应用程序还可以自定义调用点类,来满足特定的重链接需求。
由于Java暂不支持直接生成invokedynamic指令[1],所以接下来我会借助之前介绍过的字节码工具ASM来实现这一目的。
1 | import java.io.IOException; |
你无需理解上面这段代码的具体含义,只须了解它会更改同一目录下Circuit类的startRace(Object)方法,使之包含invokedynamic指令,执行所谓的赛跑方法。
1 | public static void startRace(java.lang.Object); |
如果你足够细心的话,你会发现该指令所调用的赛跑方法的描述符,和Horse.race方法或者Deer.race方法的描述符并不一致。这是因为invokedynamic指令最终调用的是方法句柄,而方法句柄会将调用者当成第一个参数。因此,刚刚提到的那两个方法恰恰符合这个描述符所对应的方法句柄类型。
到目前为止,我们已经可以通过invokedynamic调用Horse.race方法了。为了支持调用任意类的race方法,我实现了一个简单的单态内联缓存。如果调用者的类型命中缓存中的类型,便直接调用缓存中的方法句柄,否则便更新缓存。
1 | // 需要更改ASMHelper.MyMethodVisitor中的BOOTSTRAP_CLASS_NAME |
可以看到,尽管invokedynamic指令调用的是所谓的race方法,但是实际上我返回了一个链接至名为“invoke”的方法的调用点。由于调用点仅要求方法句柄的类型能够匹配,因此这个链接是合法的。
不过,这正是invokedynamic的目的,也就是将调用点与目标方法的链接交由应用程序来做,并且依赖于应用程序对目标方法进行验证。所以,如果应用程序将赛跑方法链接至兔子的睡觉方法,那也只能怪应用程序自己了。
Java 8的Lambda表达式
在Java 8中,Lambda表达式也是借助invokedynamic来实现的。
具体来说,Java编译器利用invokedynamic指令来生成实现了函数式接口的适配器。这里的函数式接口指的是仅包括一个非default接口方法的接口,一般通过@FunctionalInterface注解。不过就算是没有使用该注解,Java编译器也会将符合条件的接口辨认为函数式接口。
1 | int x = .. |
举个例子,上面这段代码会对IntStream中的元素进行两次映射。我们知道,映射方法map所接收的参数是IntUnaryOperator(这是一个函数式接口)。也就是说,在运行过程中我们需要将i->i2和i->ix 这两个Lambda表达式转化成IntUnaryOperator的实例。这个转化过程便是由invokedynamic来实现的。
在编译过程中,Java编译器会对Lambda表达式进行解语法糖(desugar),生成一个方法来保存Lambda表达式的内容。该方法的参数列表不仅包含原本Lambda表达式的参数,还包含它所捕获的变量。(注:方法引用,如Horse::race,则不会生成生成额外的方法。)
在上面那个例子中,第一个Lambda表达式没有捕获其他变量,而第二个Lambda表达式(也就是i->i*x)则会捕获局部变量x。这两个Lambda表达式对应的方法如下所示。可以看到,所捕获的变量同样也会作为参数传入生成的方法之中。
1 | // i -> i * 2 |
第一次执行invokedynamic指令时,它所对应的启动方法会通过ASM来生成一个适配器类。这个适配器类实现了对应的函数式接口,在我们的例子中,也就是IntUnaryOperator。启动方法的返回值是一个ConstantCallSite,其链接对象为一个返回适配器类实例的方法句柄。
根据Lambda表达式是否捕获其他变量,启动方法生成的适配器类以及所链接的方法句柄皆不同。
如果该Lambda表达式没有捕获其他变量,那么可以认为它是上下文无关的。因此,启动方法将新建一个适配器类的实例,并且生成一个特殊的方法句柄,始终返回该实例。
如果该Lambda表达式捕获了其他变量,那么每次执行该invokedynamic指令,我们都要更新这些捕获了的变量,以防止它们发生了变化。
另外,为了保证Lambda表达式的线程安全,我们无法共享同一个适配器类的实例。因此,在每次执行invokedynamic指令时,所调用的方法句柄都需要新建一个适配器类实例。
在这种情况下,启动方法生成的适配器类将包含一个额外的静态方法,来构造适配器类的实例。该方法将接收这些捕获的参数,并且将它们保存为适配器类实例的实例字段。
你可以通过虚拟机参数-Djdk.internal.lambda.dumpProxyClasses=/DUMP/PATH导出这些具体的适配器类。这里我导出了上面这个例子中两个Lambda表达式对应的适配器类。
1 | // i->i*2 对应的适配器类 |
可以看到,捕获了局部变量的Lambda表达式多出了一个get$Lambda的方法。启动方法便会所返回的调用点链接至指向该方法的方法句柄。也就是说,每次执行invokedynamic指令时,都会调用至这个方法中,并构造一个新的适配器类实例。
这个多出来的新建实例会对程序性能造成影响吗?
Lambda以及方法句柄的性能分析
我再次请出测试反射调用性能开销的那段代码,并将其改造成使用Lambda表达式的v6版本。
1 | // v6版本 |
测量结果显示,它与直接调用的性能并无太大的区别。也就是说,即时编译器能够将转换Lambda表达式所使用的invokedynamic,以及对IntConsumer.accept方法的调用统统内联进来,最终优化为空操作。
这个其实不难理解:Lambda表达式所使用的invokedynamic将绑定一个ConstantCallSite,其链接的目标方法无法改变。因此,即时编译器会将该目标方法直接内联进来。对于这类没有捕获变量的Lambda表达式而言,目标方法只完成了一个动作,便是加载缓存的适配器类常量。
另一方面,对IntConsumer.accept方法的调用实则是对适配器类的accept方法的调用。
如果你查看了accept方法对应的字节码的话,你会发现它仅包含一个方法调用,调用至Java编译器在解Lambda语法糖时生成的方法。
该方法的内容便是Lambda表达式的内容,也就是直接调用目标方法Test.target。将这几个方法调用内联进来之后,原本对accept方法的调用则会被优化为空操作。
下面我将之前的代码更改为带捕获变量的v7版本。理论上,每次调用invokedynamic指令,Java虚拟机都会新建一个适配器类的实例。然而,实际运行结果还是与直接调用的性能一致。
1 | // v7版本 |
显然,即时编译器的逃逸分析又将该新建实例给优化掉了。我们可以通过虚拟机参数-XX:-DoEscapeAnalysis来关闭逃逸分析。果然,这时候测得的值约为直接调用的2.5倍。
尽管逃逸分析能够去除这些额外的新建实例开销,但是它也不是时时奏效。它需要同时满足两件事:invokedynamic指令所执行的方法句柄能够内联,和接下来的对accept方法的调用也能内联。
只有这样,逃逸分析才能判定该适配器实例不逃逸。否则,我们会在运行过程中不停地生成适配器类实例。所以,我们应当尽量使用非捕获的Lambda表达式。
总结与实践
今天我介绍了invokedynamic指令以及Lambda表达式的实现。
invokedymaic指令抽象出调用点的概念,并且将调用该调用点所链接的方法句柄。在第一次执行invokedynamic指令时,Java虚拟机将执行它所对应的启动方法,生成并且绑定一个调用点。之后如果再次执行该指令,Java虚拟机则直接调用已经绑定了的调用点所链接的方法。
Lambda表达式到函数式接口的转换是通过invokedynamic指令来实现的。该invokedynamic指令对应的启动方法将通过ASM生成一个适配器类。
对于没有捕获其他变量的Lambda表达式,该invokedynamic指令始终返回同一个适配器类的实例。对于捕获了其他变量的Lambda表达式,每次执行invokedynamic指令将新建一个适配器类实例。
不管是捕获型的还是未捕获型的Lambda表达式,它们的性能上限皆可以达到直接调用的性能。其中,捕获型Lambda表达式借助了即时编译器中的逃逸分析,来避免实际的新建适配器类实例的操作。
在上一篇的课后实践中,你应该测过这一段代码的性能开销了。我这边测得的结果约为直接调用的3.5倍。
1 | // v8版本 |
实际上,它与使用Lambda表达式或者方法引用的差别在于,即时编译器无法将该方法句柄识别为常量,从而无法进行内联。那么如果将它变成常量行不行呢?
一种方法便是将其赋值给final的静态变量,如下面的v9版本所示:
1 | // v9版本 |
这个版本测得的数据和直接调用的性能数据一致。也就是说,即时编译器能够将该方法句柄完全内联进来,成为空操作。
今天的实践环节,我们来继续探索方法句柄的性能。运行下面的v10版本以及v11版本,比较它们的性能并思考为什么。
1 | // v10版本 |
感谢你的收听,我们下次再见。
[1] http://openjdk.java.net/jeps/303
10 | Java对象的内存布局
作者: 郑雨迪

在Java程序中,我们拥有多种新建对象的方式。除了最为常见的new语句之外,我们还可以通过反射机制、Object.clone方法、反序列化以及Unsafe.allocateInstance方法来新建对象。
其中,Object.clone方法和反序列化通过直接复制已有的数据,来初始化新建对象的实例字段。Unsafe.allocateInstance方法则没有初始化实例字段,而new语句和反射机制,则是通过调用构造器来初始化实例字段。
以new语句为例,它编译而成的字节码将包含用来请求内存的new指令,以及用来调用构造器的invokespecial指令。
1 | // Foo foo = new Foo(); 编译而成的字节码 |
提到构造器,就不得不提到Java对构造器的诸多约束。首先,如果一个类没有定义任何构造器的话, Java编译器会自动添加一个无参数的构造器。
1 | // Foo类构造器会调用其父类Object的构造器 |
然后,子类的构造器需要调用父类的构造器。如果父类存在无参数构造器的话,该调用可以是隐式的,也就是说Java编译器会自动添加对父类构造器的调用。但是,如果父类没有无参数构造器,那么子类的构造器则需要显式地调用父类带参数的构造器。
显式调用又可分为两种,一是直接使用“super”关键字调用父类构造器,二是使用“this”关键字调用同一个类中的其他构造器。无论是直接的显式调用,还是间接的显式调用,都需要作为构造器的第一条语句,以便优先初始化继承而来的父类字段。(不过这可以通过调用其他生成参数的方法,或者字节码注入来绕开。)
总而言之,当我们调用一个构造器时,它将优先调用父类的构造器,直至Object类。这些构造器的调用者皆为同一对象,也就是通过new指令新建而来的对象。
你应该已经发现了其中的玄机:通过new指令新建出来的对象,它的内存其实涵盖了所有父类中的实例字段。也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
这些字段在内存中的具体分布是怎么样的呢?今天我们就来看看对象的内存布局。
压缩指针
在Java虚拟机中,每个Java对象都有一个对象头(object header),这个由标记字段和类型指针所构成。其中,标记字段用以存储Java虚拟机有关该对象的运行数据,如哈希码、GC信息以及锁信息,而类型指针则指向该对象的类。
在64位的Java虚拟机中,对象头的标记字段占64位,而类型指针又占了64位。也就是说,每一个Java对象在内存中的额外开销就是16个字节。以Integer类为例,它仅有一个int类型的私有字段,占4个字节。因此,每一个Integer对象的额外内存开销至少是400%。这也是为什么Java要引入基本类型的原因之一。
为了尽量较少对象的内存使用量,64位Java虚拟机引入了压缩指针[1]的概念(对应虚拟机选项-XX:+UseCompressedOops,默认开启),将堆中原本64位的Java对象指针压缩成32位的。
这样一来,对象头中的类型指针也会被压缩成32位,使得对象头的大小从16字节降至12字节。当然,压缩指针不仅可以作用于对象头的类型指针,还可以作用于引用类型的字段,以及引用类型数组。
那么压缩指针是什么原理呢?
打个比方,路上停着的全是房车,而且每辆房车恰好占据两个停车位。现在,我们按照顺序给它们编号。也就是说,停在0号和1号停车位上的叫0号车,停在2号和3号停车位上的叫1号车,依次类推。
原本的内存寻址用的是车位号。比如说我有一个值为6的指针,代表第6个车位,那么沿着这个指针可以找到3号车。现在我们规定指针里存的值是车号,比如3指代3号车。当需要查找3号车时,我便可以将该指针的值乘以2,再沿着6号车位找到3号车。
这样一来,32位压缩指针最多可以标记2的32次方辆车,对应着2的33次方个车位。当然,房车也有大小之分。大房车占据的车位可能是三个甚至是更多。不过这并不会影响我们的寻址算法:我们只需跳过部分车号,便可以保持原本车号*2的寻址系统。
上述模型有一个前提,你应该已经想到了,就是每辆车都从偶数号车位停起。这个概念我们称之为内存对齐(对应虚拟机选项-XX:ObjectAlignmentInBytes,默认值为8)。
默认情况下,Java虚拟机堆中对象的起始地址需要对齐至8的倍数。如果一个对象用不到8N个字节,那么空白的那部分空间就浪费掉了。这些浪费掉的空间我们称之为对象间的填充(padding)。
在默认情况下,Java虚拟机中的32位压缩指针可以寻址到2的35次方个字节,也就是32GB的地址空间(超过32GB则会关闭压缩指针)。
在对压缩指针解引用时,我们需要将其左移3位,再加上一个固定偏移量,便可以得到能够寻址32GB地址空间的伪64位指针了。
此外,我们可以通过配置刚刚提到的内存对齐选项(-XX:ObjectAlignmentInBytes)来进一步提升寻址范围。但是,这同时也可能增加对象间填充,导致压缩指针没有达到原本节省空间的效果。
举例来说,如果规定每辆车都需要从偶数车位号停起,那么对于占据两个车位的小房车来说刚刚好,而对于需要三个车位的大房车来说,也仅是浪费一个车位。
但是如果规定需要从4的倍数号车位停起,那么小房车则会浪费两个车位,而大房车至多可能浪费三个车位。
当然,就算是关闭了压缩指针,Java虚拟机还是会进行内存对齐。此外,内存对齐不仅存在于对象与对象之间,也存在于对象中的字段之间。比如说,Java虚拟机要求long字段、double字段,以及非压缩指针状态下的引用字段地址为8的倍数。
字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。
下面我来介绍一下对象内存布局另一个有趣的特性:字段重排列。
字段重排列
字段重排列,顾名思义,就是Java虚拟机重新分配字段的先后顺序,以达到内存对齐的目的。Java虚拟机中有三种排列方法(对应Java虚拟机选项-XX:FieldsAllocationStyle,默认值为1),但都会遵循如下两个规则。
其一,如果一个字段占据C个字节,那么该字段的偏移量需要对齐至NC。这里偏移量指的是字段地址与对象的起始地址差值。
以long类为例,它仅有一个long类型的实例字段。在使用了压缩指针的64位虚拟机中,尽管对象头的大小为12个字节,该long类型字段的偏移量也只能是16,而中间空着的4个字节便会被浪费掉。
其二,子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
在具体实现中,Java虚拟机还会对齐子类字段的起始位置。对于使用了压缩指针的64位虚拟机,子类第一个字段需要对齐至4N;而对于关闭了压缩指针的64位虚拟机,子类第一个字段则需要对齐至8N。
1 | class A { |
我在文中贴了一段代码,里边定义了两个类A和B,其中B继承A。A和B各自定义了一个long类型的实例字段和一个int类型的实例字段。下面我分别打印了B类在启用压缩指针和未启用压缩指针时,各个字段的偏移量。
1 | # 启用压缩指针时,B类的字段分布 |
当启用压缩指针时,可以看到Java虚拟机将A类的int字段放置于long字段之前,以填充因为long字段对齐造成的4字节缺口。由于对象整体大小需要对齐至8N,因此对象的最后会有4字节的空白填充。
1 | # 关闭压缩指针时,B类的字段分布 |
当关闭压缩指针时,B类字段的起始位置需对齐至8N。这么一来,B类字段的前后各有4字节的空白。那么我们可不可以将B类的int字段移至前面的空白中,从而节省这8字节呢?
我认为是可以的,并且我修改过后的Java虚拟机也没有跑崩。由于HotSpot中的这块代码年久失修,公司的同事也已经记不得是什么原因了,那么姑且先认为是一些历史遗留问题吧。
Java 8还引入了一个新的注释@Contended,用来解决对象字段之间的虚共享(false sharing)问题[2]。这个注释也会影响到字段的排列。
虚共享是怎么回事呢?假设两个线程分别访问同一对象中不同的volatile字段,逻辑上它们并没有共享内容,因此不需要同步。
然而,如果这两个字段恰好在同一个缓存行中,那么对这些字段的写操作会导致缓存行的写回,也就造成了实质上的共享。(volatile字段和缓存行的故事我会在之后的篇章中详细介绍。)
Java虚拟机会让不同的@Contended字段处于独立的缓存行中,因此你会看到大量的空间被浪费掉。具体的分布算法属于实现细节,随着Java版本的变动也比较大,因此这里就不做阐述了。
如果你感兴趣,可以利用实践环节的工具,来查阅Contended字段的内存布局。注意使用虚拟机选项-XX:-RestrictContended。如果你在Java 9以上版本试验的话,在使用javac编译时需要添加 –add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAME
总结和实践
今天我介绍了Java虚拟机构造对象的方式,所构造对象的大小,以及对象的内存布局。
常见的new语句会被编译为new指令,以及对构造器的调用。每个类的构造器皆会直接或者间接调用父类的构造器,并且在同一个实例中初始化相应的字段。
Java虚拟机引入了压缩指针的概念,将原本的64位指针压缩成32位。压缩指针要求Java虚拟机堆中对象的起始地址要对齐至8的倍数。Java虚拟机还会对每个类的字段进行重排列,使得字段也能够内存对齐。
今天的实践环节比较简单,你可以使用我在工具篇中介绍过的JOL工具,来打印你工程中的类的字段分布情况。
1 | curl -L -O http://central.maven.org/maven2/org/openjdk/jol/jol-cli/0.9/jol-cli-0.9-full.jar |
[1] https://wiki.openjdk.java.net/display/HotSpot/CompressedOops
[2] http://openjdk.java.net/jeps/142
11 | 垃圾回收(上)
作者: 郑雨迪

你应该听说过这么一句话:免费的其实是最贵的。
Java虚拟机的自动内存管理,将原本需要由开发人员手动回收的内存,交给垃圾回收器来自动回收。不过既然是自动机制,肯定没法做到像手动回收那般精准高效[1] ,而且还会带来不少与垃圾回收实现相关的问题。
接下来的两篇,我们会深入探索Java虚拟机中的垃圾回收器。今天这一篇,我们来回顾一下垃圾回收的基础知识。
引用计数法与可达性分析
垃圾回收,顾名思义,便是将已经分配出去的,但却不再使用的内存回收回来,以便能够再次分配。在Java虚拟机的语境下,垃圾指的是死亡的对象所占据的堆空间。这里便涉及了一个关键的问题:如何辨别一个对象是存是亡?
我们先来讲一种古老的辨别方法:引用计数法(reference counting)。它的做法是为每个对象添加一个引用计数器,用来统计指向该对象的引用个数。一旦某个对象的引用计数器为0,则说明该对象已经死亡,便可以被回收了。
它的具体实现是这样子的:如果有一个引用,被赋值为某一对象,那么将该对象的引用计数器+1。如果一个指向某一对象的引用,被赋值为其他值,那么将该对象的引用计数器-1。也就是说,我们需要截获所有的引用更新操作,并且相应地增减目标对象的引用计数器。
除了需要额外的空间来存储计数器,以及繁琐的更新操作,引用计数法还有一个重大的漏洞,那便是无法处理循环引用对象。
举个例子,假设对象a与b相互引用,除此之外没有其他引用指向a或者b。在这种情况下,a和b实际上已经死了,但由于它们的引用计数器皆不为0,在引用计数法的心中,这两个对象还活着。因此,这些循环引用对象所占据的空间将不可回收,从而造成了内存泄露。

目前Java虚拟机的主流垃圾回收器采取的是可达性分析算法。这个算法的实质在于将一系列GC Roots作为初始的存活对象合集(live set),然后从该合集出发,探索所有能够被该集合引用到的对象,并将其加入到该集合中,这个过程我们也称之为标记(mark)。最终,未被探索到的对象便是死亡的,是可以回收的。
那么什么是GC Roots呢?我们可以暂时理解为由堆外指向堆内的引用,一般而言,GC Roots包括(但不限于)如下几种:
- Java方法栈桢中的局部变量;
- 已加载类的静态变量;
- JNI handles;
- 已启动且未停止的Java线程。
可达性分析可以解决引用计数法所不能解决的循环引用问题。举例来说,即便对象a和b相互引用,只要从GC Roots出发无法到达a或者b,那么可达性分析便不会将它们加入存活对象合集之中。
虽然可达性分析的算法本身很简明,但是在实践中还是有不少其他问题需要解决的。
比如说,在多线程环境下,其他线程可能会更新已经访问过的对象中的引用,从而造成误报(将引用设置为null)或者漏报(将引用设置为未被访问过的对象)。
误报并没有什么伤害,Java虚拟机至多损失了部分垃圾回收的机会。漏报则比较麻烦,因为垃圾回收器可能回收事实上仍被引用的对象内存。一旦从原引用访问已经被回收了的对象,则很有可能会直接导致Java虚拟机崩溃。
Stop-the-world以及安全点
怎么解决这个问题呢?在Java虚拟机里,传统的垃圾回收算法采用的是一种简单粗暴的方式,那便是Stop-the-world,停止其他非垃圾回收线程的工作,直到完成垃圾回收。这也就造成了垃圾回收所谓的暂停时间(GC pause)。
Java虚拟机中的Stop-the-world是通过安全点(safepoint)机制来实现的。当Java虚拟机收到Stop-the-world请求,它便会等待所有的线程都到达安全点,才允许请求Stop-the-world的线程进行独占的工作。
这篇博客[2]还提到了一种比较另类的解释:安全词。一旦垃圾回收线程喊出了安全词,其他非垃圾回收线程便会一一停下。
当然,安全点的初始目的并不是让其他线程停下,而是找到一个稳定的执行状态。在这个执行状态下,Java虚拟机的堆栈不会发生变化。这么一来,垃圾回收器便能够“安全”地执行可达性分析。
举个例子,当Java程序通过JNI执行本地代码时,如果这段代码不访问Java对象、调用Java方法或者返回至原Java方法,那么Java虚拟机的堆栈不会发生改变,也就代表着这段本地代码可以作为同一个安全点。
只要不离开这个安全点,Java虚拟机便能够在垃圾回收的同时,继续运行这段本地代码。
由于本地代码需要通过JNI的API来完成上述三个操作,因此Java虚拟机仅需在API的入口处进行安全点检测(safepoint poll),测试是否有其他线程请求停留在安全点里,便可以在必要的时候挂起当前线程。
除了执行JNI本地代码外,Java线程还有其他几种状态:解释执行字节码、执行即时编译器生成的机器码和线程阻塞。阻塞的线程由于处于Java虚拟机线程调度器的掌控之下,因此属于安全点。
其他几种状态则是运行状态,需要虚拟机保证在可预见的时间内进入安全点。否则,垃圾回收线程可能长期处于等待所有线程进入安全点的状态,从而变相地提高了垃圾回收的暂停时间。
对于解释执行来说,字节码与字节码之间皆可作为安全点。Java虚拟机采取的做法是,当有安全点请求时,执行一条字节码便进行一次安全点检测。
执行即时编译器生成的机器码则比较复杂。由于这些代码直接运行在底层硬件之上,不受Java虚拟机掌控,因此在生成机器码时,即时编译器需要插入安全点检测,以避免机器码长时间没有安全点检测的情况。HotSpot虚拟机的做法便是在生成代码的方法出口以及非计数循环的循环回边(back-edge)处插入安全点检测。
那么为什么不在每一条机器码或者每一个机器码基本块处插入安全点检测呢?原因主要有两个。
第一,安全点检测本身也有一定的开销。不过HotSpot虚拟机已经将机器码中安全点检测简化为一个内存访问操作。在有安全点请求的情况下,Java虚拟机会将安全点检测访问的内存所在的页设置为不可读,并且定义一个segfault处理器,来截获因访问该不可读内存而触发segfault的线程,并将它们挂起。
第二,即时编译器生成的机器码打乱了原本栈桢上的对象分布状况。在进入安全点时,机器码还需提供一些额外的信息,来表明哪些寄存器,或者当前栈帧上的哪些内存空间存放着指向对象的引用,以便垃圾回收器能够枚举GC Roots。
由于这些信息需要不少空间来存储,因此即时编译器会尽量避免过多的安全点检测。
不过,不同的即时编译器插入安全点检测的位置也可能不同。以Graal为例,除了上述位置外,它还会在计数循环的循环回边处插入安全点检测。其他的虚拟机也可能选取方法入口而非方法出口来插入安全点检测。
不管如何,其目的都是在可接受的性能开销以及内存开销之内,避免机器码长时间不进入安全点的情况,间接地减少垃圾回收的暂停时间。
除了垃圾回收之外,Java虚拟机其他一些对堆栈内容的一致性有要求的操作也会用到安全点这一机制。我会在涉及的时侯再进行具体的讲解。
垃圾回收的三种方式
当标记完所有的存活对象时,我们便可以进行死亡对象的回收工作了。主流的基础回收方式可分为三种。
第一种是清除(sweep),即把死亡对象所占据的内存标记为空闲内存,并记录在一个空闲列表(free list)之中。当需要新建对象时,内存管理模块便会从该空闲列表中寻找空闲内存,并划分给新建的对象。

清除这种回收方式的原理及其简单,但是有两个缺点。一是会造成内存碎片。由于Java虚拟机的堆中对象必须是连续分布的,因此可能出现总空闲内存足够,但是无法分配的极端情况。
另一个则是分配效率较低。如果是一块连续的内存空间,那么我们可以通过指针加法(pointer bumping)来做分配。而对于空闲列表,Java虚拟机则需要逐个访问列表中的项,来查找能够放入新建对象的空闲内存。
第二种是压缩(compact),即把存活的对象聚集到内存区域的起始位置,从而留下一段连续的内存空间。这种做法能够解决内存碎片化的问题,但代价是压缩算法的性能开销。

第三种则是复制(copy),即把内存区域分为两等分,分别用两个指针from和to来维护,并且只是用from指针指向的内存区域来分配内存。当发生垃圾回收时,便把存活的对象复制到to指针指向的内存区域中,并且交换from指针和to指针的内容。复制这种回收方式同样能够解决内存碎片化的问题,但是它的缺点也极其明显,即堆空间的使用效率极其低下。

当然,现代的垃圾回收器往往会综合上述几种回收方式,综合它们优点的同时规避它们的缺点。在下一篇中我们会详细介绍Java虚拟机中垃圾回收算法的具体实现。
总结与实践
今天我介绍了垃圾回收的一些基础知识。
Java虚拟机中的垃圾回收器采用可达性分析来探索所有存活的对象。它从一系列GC Roots出发,边标记边探索所有被引用的对象。
为了防止在标记过程中堆栈的状态发生改变,Java虚拟机采取安全点机制来实现Stop-the-world操作,暂停其他非垃圾回收线程。
回收死亡对象的内存共有三种方式,分别为:会造成内存碎片的清除、性能开销较大的压缩、以及堆使用效率较低的复制。
今天的实践环节,你可以体验一下无安全点检测的计数循环带来的长暂停。你可以分别测单独跑foo方法或者bar方法的时间,然后与合起来跑的时间比较一下。
1 | // time java SafepointTestp |
[1] https://media.giphy.com/media/EZ8QO0myvsSk/giphy.gif
[2] http://psy-lob-saw.blogspot.com/2015/12/safepoints.html
12 | 垃圾回收(下)
作者: 郑雨迪
在读博士的时候,我曾经写过一个统计Java对象生命周期的动态分析,并且用它来跑了一些基准测试。
其中一些程序的结果,恰好验证了许多研究人员的假设,即大部分的Java对象只存活一小段时间,而存活下来的小部分Java对象则会存活很长一段时间。
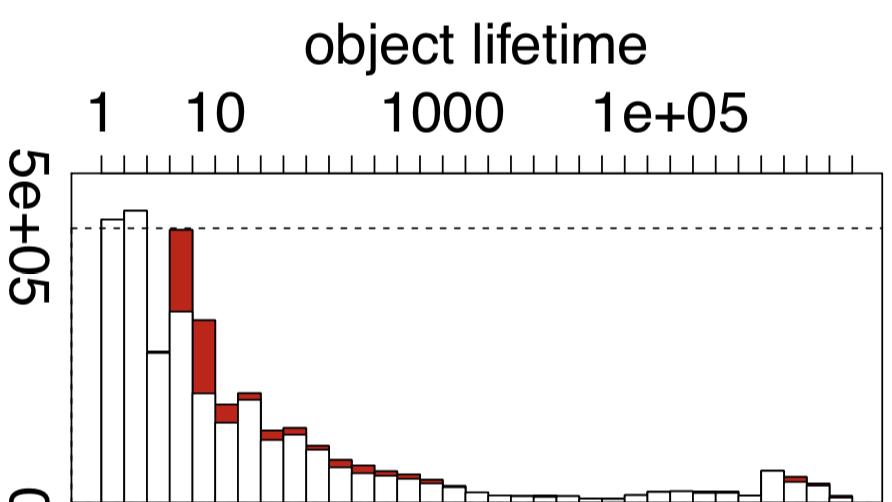
(pmd中Java对象生命周期的直方图,红色的表示被逃逸分析优化掉的对象)
之所以要提到这个假设,是因为它造就了Java虚拟机的分代回收思想。简单来说,就是将堆空间划分为两代,分别叫做新生代和老年代。新生代用来存储新建的对象。当对象存活时间够长时,则将其移动到老年代。
Java虚拟机可以给不同代使用不同的回收算法。对于新生代,我们猜测大部分的Java对象只存活一小段时间,那么便可以频繁地采用耗时较短的垃圾回收算法,让大部分的垃圾都能够在新生代被回收掉。
对于老年代,我们猜测大部分的垃圾已经在新生代中被回收了,而在老年代中的对象有大概率会继续存活。当真正触发针对老年代的回收时,则代表这个假设出错了,或者堆的空间已经耗尽了。
这时候,Java虚拟机往往需要做一次全堆扫描,耗时也将不计成本。(当然,现代的垃圾回收器都在并发收集的道路上发展,来避免这种全堆扫描的情况。)
今天这一篇我们来关注一下针对新生代的Minor GC。首先,我们来看看Java虚拟机中的堆具体是怎么划分的。
Java虚拟机的堆划分
前面提到,Java虚拟机将堆划分为新生代和老年代。其中,新生代又被划分为Eden区,以及两个大小相同的Survivor区。
默认情况下,Java虚拟机采取的是一种动态分配的策略(对应Java虚拟机参数-XX:+UsePSAdaptiveSurvivorSizePolicy),根据生成对象的速率,以及Survivor区的使用情况动态调整Eden区和Survivor区的比例。
当然,你也可以通过参数-XX:SurvivorRatio来固定这个比例。但是需要注意的是,其中一个Survivor区会一直为空,因此比例越低浪费的堆空间将越高。

通常来说,当我们调用new指令时,它会在Eden区中划出一块作为存储对象的内存。由于堆空间是线程共享的,因此直接在这里边划空间是需要进行同步的。
否则,将有可能出现两个对象共用一段内存的事故。如果你还记得前两篇我用“停车位”打的比方的话,这里就相当于两个司机(线程)同时将车停入同一个停车位,因而发生剐蹭事故。
Java虚拟机的解决方法是为每个司机预先申请多个停车位,并且只允许该司机停在自己的停车位上。那么当司机的停车位用完了该怎么办呢(假设这个司机代客泊车)?
答案是:再申请多个停车位便可以了。这项技术被称之为TLAB(Thread Local Allocation Buffer,对应虚拟机参数-XX:+UseTLAB,默认开启)。
具体来说,每个线程可以向Java虚拟机申请一段连续的内存,比如2048字节,作为线程私有的TLAB。
这个操作需要加锁,线程需要维护两个指针(实际上可能更多,但重要也就两个),一个指向TLAB中空余内存的起始位置,一个则指向TLAB末尾。
接下来的new指令,便可以直接通过指针加法(bump the pointer)来实现,即把指向空余内存位置的指针加上所请求的字节数。
我猜测会有留言问为什么不把bump the pointer翻译成指针碰撞。这里先解释一下,在英语中我们通常省略了bump up the pointer中的up。在这个上下文中bump的含义应为“提高”。另外一个例子是当我们发布软件的新版本时,也会说bump the version number。
如果加法后空余内存指针的值仍小于或等于指向末尾的指针,则代表分配成功。否则,TLAB已经没有足够的空间来满足本次新建操作。这个时候,便需要当前线程重新申请新的TLAB。
当Eden区的空间耗尽了怎么办?这个时候Java虚拟机便会触发一次Minor GC,来收集新生代的垃圾。存活下来的对象,则会被送到Survivor区。
前面提到,新生代共有两个Survivor区,我们分别用from和to来指代。其中to指向的Survivior区是空的。
当发生Minor GC时,Eden区和from指向的Survivor区中的存活对象会被复制到to指向的Survivor区中,然后交换from和to指针,以保证下一次Minor GC时,to指向的Survivor区还是空的。
Java虚拟机会记录Survivor区中的对象一共被来回复制了几次。如果一个对象被复制的次数为15(对应虚拟机参数-XX:+MaxTenuringThreshold),那么该对象将被晋升(promote)至老年代。另外,如果单个Survivor区已经被占用了50%(对应虚拟机参数-XX:TargetSurvivorRatio),那么较高复制次数的对象也会被晋升至老年代。
总而言之,当发生Minor GC时,我们应用了标记-复制算法,将Survivor区中的老存活对象晋升到老年代,然后将剩下的存活对象和Eden区的存活对象复制到另一个Survivor区中。理想情况下,Eden区中的对象基本都死亡了,那么需要复制的数据将非常少,因此采用这种标记-复制算法的效果极好。
Minor GC的另外一个好处是不用对整个堆进行垃圾回收。但是,它却有一个问题,那就是老年代的对象可能引用新生代的对象。也就是说,在标记存活对象的时候,我们需要扫描老年代中的对象。如果该对象拥有对新生代对象的引用,那么这个引用也会被作为GC Roots。
这样一来,岂不是又做了一次全堆扫描呢?
卡表
HotSpot给出的解决方案是一项叫做卡表(Card Table)的技术。该技术将整个堆划分为一个个大小为512字节的卡,并且维护一个卡表,用来存储每张卡的一个标识位。这个标识位代表对应的卡是否可能存有指向新生代对象的引用。如果可能存在,那么我们就认为这张卡是脏的。
在进行Minor GC的时候,我们便可以不用扫描整个老年代,而是在卡表中寻找脏卡,并将脏卡中的对象加入到Minor GC的GC Roots里。当完成所有脏卡的扫描之后,Java虚拟机便会将所有脏卡的标识位清零。
由于Minor GC伴随着存活对象的复制,而复制需要更新指向该对象的引用。因此,在更新引用的同时,我们又会设置引用所在的卡的标识位。这个时候,我们可以确保脏卡中必定包含指向新生代对象的引用。
在Minor GC之前,我们并不能确保脏卡中包含指向新生代对象的引用。其原因和如何设置卡的标识位有关。
首先,如果想要保证每个可能有指向新生代对象引用的卡都被标记为脏卡,那么Java虚拟机需要截获每个引用型实例变量的写操作,并作出对应的写标识位操作。
这个操作在解释执行器中比较容易实现。但是在即时编译器生成的机器码中,则需要插入额外的逻辑。这也就是所谓的写屏障(write barrier,注意不要和volatile字段的写屏障混淆)。
写屏障需要尽可能地保持简洁。这是因为我们并不希望在每条引用型实例变量的写指令后跟着一大串注入的指令。
因此,写屏障并不会判断更新后的引用是否指向新生代中的对象,而是宁可错杀,不可放过,一律当成可能指向新生代对象的引用。
这么一来,写屏障便可精简为下面的伪代码[1]。这里右移9位相当于除以512,Java虚拟机便是通过这种方式来从地址映射到卡表中的索引的。最终,这段代码会被编译成一条移位指令和一条存储指令。
1 | CARD_TABLE [this address >> 9] = DIRTY; |
虽然写屏障不可避免地带来一些开销,但是它能够加大Minor GC的吞吐率( 应用运行时间/(应用运行时间+垃圾回收时间) )。总的来说还是值得的。不过,在高并发环境下,写屏障又带来了虚共享(false sharing)问题[2]。
在介绍对象内存布局中我曾提到虚共享问题,讲的是几个volatile字段出现在同一缓存行里造成的虚共享。这里的虚共享则是卡表中不同卡的标识位之间的虚共享问题。
在HotSpot中,卡表是通过byte数组来实现的。对于一个64字节的缓存行来说,如果用它来加载部分卡表,那么它将对应64张卡,也就是32KB的内存。
如果同时有两个Java线程,在这32KB内存中进行引用更新操作,那么也将造成存储卡表的同一部分的缓存行的写回、无效化或者同步操作,因而间接影响程序性能。
为此,HotSpot引入了一个新的参数-XX:+UseCondCardMark,来尽量减少写卡表的操作。其伪代码如下所示:
1 | if (CARD_TABLE [this address >> 9] != DIRTY) |
总结与实践
今天我介绍了Java虚拟机中垃圾回收具体实现的一些通用知识。
Java虚拟机将堆分为新生代和老年代,并且对不同代采用不同的垃圾回收算法。其中,新生代分为Eden区和两个大小一致的Survivor区,并且其中一个Survivor区是空的。
在只针对新生代的Minor GC中,Eden区和非空Survivor区的存活对象会被复制到空的Survivor区中,当Survivor区中的存活对象复制次数超过一定数值时,它将被晋升至老年代。
因为Minor GC只针对新生代进行垃圾回收,所以在枚举GC Roots的时候,它需要考虑从老年代到新生代的引用。为了避免扫描整个老年代,Java虚拟机引入了名为卡表的技术,大致地标出可能存在老年代到新生代引用的内存区域。
由于篇幅的原因,我没有讲解Java虚拟机中具体的垃圾回收器。我在文章的末尾附了一段简单的介绍,如果你有兴趣的话可以参阅一下。
今天的实践环节,我们来看看Java对象的生命周期对垃圾回收的影响。
前面提到,Java虚拟机的分代垃圾回收是基于大部分对象只存活一小段时间,小部分对象却存活一大段时间的假设的。
然而,现实情况中并非每个程序都符合前面提到的假设。如果一个程序拥有中等生命周期的对象,并且刚移动到老年代便不再使用,那么将给默认的垃圾回收策略造成极大的麻烦。
下面这段程序将生成64G的Java对象。并且,我通过ALIVE_OBJECT_SIZE这一变量来定义同时存活的Java对象的大小。这也是一种对于垃圾回收器来说比较直观的生命周期。
当我们使用Java 8的默认GC,并且将新生代的空间限制在100M时,试着估算当ALIVE_OBJECT_SIZE为多少时,这段程序不会触发Full GC(提示一下,如果Survivor区没法存储所有存活对象,将发生什么。)。实际运行情况又是怎么样的?
1 | // Run with java -XX:+PrintGC -Xmn100M -XX:PretenureSizeThreshold=10000 LifetimeTest |
附录:Java虚拟机中的垃圾回收器
针对新生代的垃圾回收器共有三个:Serial,Parallel Scavenge和Parallel New。这三个采用的都是标记-复制算法。其中,Serial是一个单线程的,Parallel New可以看成Serial的多线程版本。Parallel Scavenge和Parallel New类似,但更加注重吞吐率。此外,Parallel Scavenge不能与CMS一起使用。
针对老年代的垃圾回收器也有三个:刚刚提到的Serial Old和Parallel Old,以及CMS。Serial Old和Parallel Old都是标记-压缩算法。同样,前者是单线程的,而后者可以看成前者的多线程版本。
CMS采用的是标记-清除算法,并且是并发的。除了少数几个操作需要Stop-the-world之外,它可以在应用程序运行过程中进行垃圾回收。在并发收集失败的情况下,Java虚拟机会使用其他两个压缩型垃圾回收器进行一次垃圾回收。由于G1的出现,CMS在Java 9中已被废弃[3]。
G1(Garbage First)是一个横跨新生代和老年代的垃圾回收器。实际上,它已经打乱了前面所说的堆结构,直接将堆分成极其多个区域。每个区域都可以充当Eden区、Survivor区或者老年代中的一个。它采用的是标记-压缩算法,而且和CMS一样都能够在应用程序运行过程中并发地进行垃圾回收。
G1能够针对每个细分的区域来进行垃圾回收。在选择进行垃圾回收的区域时,它会优先回收死亡对象较多的区域。这也是G1名字的由来。
即将到来的Java 11引入了ZGC,宣称暂停时间不超过10ms。如果你感兴趣的话,可参考R大的这篇文章[4]。
[1]
http://psy-lob-saw.blogspot.com/2014/10/the-jvm-write-barrier-card-marking.html
[2]
https://blogs.oracle.com/dave/false-sharing-induced-by-card-table-marking
[3]
http://openjdk.java.net/jeps/291
[4] https://www.zhihu.com/question/287945354/answer/458761494
13 | Java内存模型
作者: 郑雨迪

我们先来看一个反常识的例子。
1 | int a=0, b=0; |
这里我定义了两个共享变量a和b,以及两个方法。第一个方法将局部变量r2赋值为a,然后将共享变量b赋值为1。第二个方法将局部变量r1赋值为b,然后将共享变量a赋值为2。请问(r1,r2)的可能值都有哪些?
在单线程环境下,我们可以先调用第一个方法,最终(r1,r2)为(1,0);也可以先调用第二个方法,最终为(0,2)。
在多线程环境下,假设这两个方法分别跑在两个不同的线程之上,如果Java虚拟机在执行了任一方法的第一条赋值语句之后便切换线程,那么最终结果将可能出现(0,0)的情况。
除上述三种情况之外,Java语言规范第17.4小节[1]还介绍了一种看似不可能的情况(1,2)。
造成这一情况的原因有三个,分别为即时编译器的重排序,处理器的乱序执行,以及内存系统的重排序。由于后两种原因涉及具体的体系架构,我们暂且放到一边。下面我先来讲一下编译器优化的重排序是怎么一回事。
首先需要说明一点,即时编译器(和处理器)需要保证程序能够遵守as-if-serial属性。通俗地说,就是在单线程情况下,要给程序一个顺序执行的假象。即经过重排序的执行结果要与顺序执行的结果保持一致。
另外,如果两个操作之间存在数据依赖,那么即时编译器(和处理器)不能调整它们的顺序,否则将会造成程序语义的改变。
1 | int a=0, b=0; |
在上面这段代码中,我扩展了先前例子中的第一个方法。新增的代码会先使用共享变量b的值,然后再使用局部变量r2的值。
此时,即时编译器有两种选择。
第一,在一开始便将a加载至某一寄存器中,并且在接下来b的赋值操作以及使用b的代码中避免使用该寄存器。第二,在真正使用r2时才将a加载至寄存器中。这么一来,在执行使用b的代码时,我们不再霸占一个通用寄存器,从而减少需要借助栈空间的情况。
1 | int a=0, b=0; |
另一个例子则是将第一个方法的代码放入一个循环中。除了原本的两条赋值语句之外,我只在循环中添加了使用r2,并且更新a的代码。由于对b的赋值是循环无关的,即时编译器很有可能将其移出循环之前,而对r2的赋值语句还停留在循环之中。
如果想要复现这两个场景,你可能需要添加大量有意义的局部变量,来给寄存器分配算法施加压力。
可以看到,即时编译器的优化可能将原本字段访问的执行顺序打乱。在单线程环境下,由于as-if-serial的保证,我们无须担心顺序执行不可能发生的情况,如(r1,r2)=(1,2)。
然而,在多线程情况下,这种数据竞争(data race)的情况是有可能发生的。而且,Java语言规范将其归咎于应用程序没有作出恰当的同步操作。
Java内存模型与happens-before关系
为了让应用程序能够免于数据竞争的干扰,Java 5引入了明确定义的Java内存模型。其中最为重要的一个概念便是happens-before关系。happens-before关系是用来描述两个操作的内存可见性的。如果操作X happens-before操作Y,那么X的结果对于Y可见。
在同一个线程中,字节码的先后顺序(program order)也暗含了happens-before关系:在程序控制流路径中靠前的字节码happens-before靠后的字节码。然而,这并不意味着前者一定在后者之前执行。实际上,如果后者没有观测前者的运行结果,即后者没有数据依赖于前者,那么它们可能会被重排序。
除了线程内的happens-before关系之外,Java内存模型还定义了下述线程间的happens-before关系。
- 解锁操作 happens-before 之后(这里指时钟顺序先后)对同一把锁的加锁操作。
- volatile字段的写操作 happens-before 之后(这里指时钟顺序先后)对同一字段的读操作。
- 线程的启动操作(即Thread.starts()) happens-before 该线程的第一个操作。
- 线程的最后一个操作 happens-before 它的终止事件(即其他线程通过Thread.isAlive()或Thread.join()判断该线程是否中止)。
- 线程对其他线程的中断操作 happens-before 被中断线程所收到的中断事件(即被中断线程的InterruptedException异常,或者第三个线程针对被中断线程的Thread.interrupted或者Thread.isInterrupted调用)。
- 构造器中的最后一个操作 happens-before 析构器的第一个操作。
happens-before关系还具备传递性。如果操作X happens-before操作Y,而操作Y happens-before操作Z,那么操作X happens-before操作Z。
在文章开头的例子中,程序没有定义任何happens-before关系,仅拥有默认的线程内happens-before关系。也就是r2的赋值操作happens-before b的赋值操作,r1的赋值操作happens-before a的赋值操作。
1 | Thread1 Thread2 |
拥有happens-before关系的两对赋值操作之间没有数据依赖,因此即时编译器、处理器都可能对其进行重排序。举例来说,只要将b的赋值操作排在r2的赋值操作之前,那么便可以按照赋值b,赋值r1,赋值a,赋值r2的顺序得到(1,2)的结果。
那么如何解决这个问题呢?答案是,将a或者b设置为volatile字段。
比如说将b设置为volatile字段。假设r1能够观测到b的赋值结果1。显然,这需要b的赋值操作在时钟顺序上先于r1的赋值操作。根据volatile字段的happens-before关系,我们知道b的赋值操作happens-before r1的赋值操作。
1 | int a=0; |
根据同一个线程中,字节码顺序所暗含的happens-before关系,以及happens-before关系的传递性,我们可以轻易得出r2的赋值操作happens-before a的赋值操作。
这也就意味着,当对a进行赋值时,对r2的赋值操作已经完成了。因此,在b为volatile字段的情况下,程序不可能出现(r1,r2)为(1,2)的情况。
由此可以看出,解决这种数据竞争问题的关键在于构造一个跨线程的happens-before关系 :操作X happens-before 操作Y,使得操作X之前的字节码的结果对操作Y之后的字节码可见。
Java内存模型的底层实现
在理解了Java内存模型的概念之后,我们现在来看看它的底层实现。Java内存模型是通过内存屏障(memory barrier)来禁止重排序的。
对于即时编译器来说,它会针对前面提到的每一个happens-before关系,向正在编译的目标方法中插入相应的读读、读写、写读以及写写内存屏障。
这些内存屏障会限制即时编译器的重排序操作。以volatile字段访问为例,所插入的内存屏障将不允许volatile字段写操作之前的内存访问被重排序至其之后;也将不允许volatile字段读操作之后的内存访问被重排序至其之前。
然后,即时编译器将根据具体的底层体系架构,将这些内存屏障替换成具体的CPU指令。以我们日常接触的X86_64架构来说,读读、读写以及写写内存屏障是空操作(no-op),只有写读内存屏障会被替换成具体指令[2]。
在文章开头的例子中,method1和method2之中的代码均属于先读后写(假设r1和r2被存储在寄存器之中)。X86_64架构的处理器并不能将读操作重排序至写操作之后,具体可参考Intel Software Developer Manual Volumn 3,8.2.3.3小节。因此,我认为例子中的重排序必然是即时编译器造成的。
举例来说,对于volatile字段,即时编译器将在volatile字段的读写操作前后各插入一些内存屏障。
然而,在X86_64架构上,只有volatile字段写操作之后的写读内存屏障需要用具体指令来替代。(HotSpot所选取的具体指令是lock add DWORD PTR [rsp],0x0,而非mfence[3]。)
该具体指令的效果,可以简单理解为强制刷新处理器的写缓存。写缓存是处理器用来加速内存存储效率的一项技术。
在碰到内存写操作时,处理器并不会等待该指令结束,而是直接开始下一指令,并且依赖于写缓存将更改的数据同步至主内存(main memory)之中。
强制刷新写缓存,将使得当前线程写入volatile字段的值(以及写缓存中已有的其他内存修改),同步至主内存之中。
由于内存写操作同时会无效化其他处理器所持有的、指向同一内存地址的缓存行,因此可以认为其他处理器能够立即见到该volatile字段的最新值。
锁,volatile字段,final字段与安全发布
下面我来讲讲Java内存模型涉及的几个关键词。
前面提到,锁操作同样具备happens-before关系。具体来说,解锁操作 happens-before 之后对同一把锁的加锁操作。实际上,在解锁时,Java虚拟机同样需要强制刷新缓存,使得当前线程所修改的内存对其他线程可见。
需要注意的是,锁操作的happens-before规则的关键字是同一把锁。也就意味着,如果编译器能够(通过逃逸分析)证明某把锁仅被同一线程持有,那么它可以移除相应的加锁解锁操作。
因此也就不再强制刷新缓存。举个例子,即时编译后的synchronized (new Object()) {},可能等同于空操作,而不会强制刷新缓存。
volatile字段可以看成一种轻量级的、不保证原子性的同步,其性能往往优于(至少不亚于)锁操作。然而,频繁地访问volatile字段也会因为不断地强制刷新缓存而严重影响程序的性能。
在X86_64平台上,只有volatile字段的写操作会强制刷新缓存。因此,理想情况下对volatile字段的使用应当多读少写,并且应当只有一个线程进行写操作。
volatile字段的另一个特性是即时编译器无法将其分配到寄存器里。换句话说,volatile字段的每次访问均需要直接从内存中读写。
final实例字段则涉及新建对象的发布问题。当一个对象包含final实例字段时,我们希望其他线程只能看到已初始化的final实例字段。
因此,即时编译器会在final字段的写操作后插入一个写写屏障,以防某些优化将新建对象的发布(即将实例对象写入一个共享引用中)重排序至final字段的写操作之前。在X86_64平台上,写写屏障是空操作。
新建对象的安全发布(safe publication)问题不仅仅包括final实例字段的可见性,还包括其他实例字段的可见性。
当发布一个已初始化的对象时,我们希望所有已初始化的实例字段对其他线程可见。否则,其他线程可能见到一个仅部分初始化的新建对象,从而造成程序错误。这里我就不展开了。如果你感兴趣的话,可以参考这篇博客[4]。
总结与实践
今天我主要介绍了Java的内存模型。
Java内存模型通过定义了一系列的happens-before操作,让应用程序开发者能够轻易地表达不同线程的操作之间的内存可见性。
在遵守Java内存模型的前提下,即时编译器以及底层体系架构能够调整内存访问操作,以达到性能优化的效果。如果开发者没有正确地利用happens-before规则,那么将可能导致数据竞争。
Java内存模型是通过内存屏障来禁止重排序的。对于即时编译器来说,内存屏障将限制它所能做的重排序优化。对于处理器来说,内存屏障会导致缓存的刷新操作。
今天的实践环节,我们来复现文章初始的例子。由于复现需要大量的线程切换事件,因此我借助了OpenJDK CodeTools项目的jcstress工具[5],来对该例子进行并发情况下的压力测试。具体的命令如下所示:
1 | $ mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jcstress -DarchetypeArtifactId=jcstress-java-test-archetype -DarchetypeVersion=0.1.1 -DgroupId=org.sample -DartifactId=test -Dversion=1.0 |
如果你想要复现非安全发布的情形,那么你可以试试这一测试用例[6]。
[1] https://docs.oracle.com/javase/specs/jls/se10/html/jls-17.html#jls-17.4
[2] http://gee.cs.oswego.edu/dl/jmm/cookbook.html
[3] https://blogs.oracle.com/dave/instruction-selection-for-volatile-fences-:-mfence-vs-lock:add
[4] http://vlkan.com/blog/post/2014/02/14/java-safe-publication/
[5] https://wiki.openjdk.java.net/display/CodeTools/jcstress
14 | Java虚拟机是怎么实现synchronized的?
作者: 郑雨迪

在Java程序中,我们可以利用synchronized关键字来对程序进行加锁。它既可以用来声明一个synchronized代码块,也可以直接标记静态方法或者实例方法。
当声明synchronized代码块时,编译而成的字节码将包含monitorenter和monitorexit指令。这两种指令均会消耗操作数栈上的一个引用类型的元素(也就是synchronized关键字括号里的引用),作为所要加锁解锁的锁对象。
1 | public void foo(Object lock) { |
我在文稿中贴了一段包含synchronized代码块的Java代码,以及它所编译而成的字节码。你可能会留意到,上面的字节码中包含一个monitorenter指令以及多个monitorexit指令。这是因为Java虚拟机需要确保所获得的锁在正常执行路径,以及异常执行路径上都能够被解锁。
你可以根据我在介绍异常处理时介绍过的知识,对照字节码和异常处理表来构造所有可能的执行路径,看看在执行了monitorenter指令之后,是否都有执行monitorexit指令。
当用synchronized标记方法时,你会看到字节码中方法的访问标记包括ACC_SYNCHRONIZED。该标记表示在进入该方法时,Java虚拟机需要进行monitorenter操作。而在退出该方法时,不管是正常返回,还是向调用者抛异常,Java虚拟机均需要进行monitorexit操作。
1 | public synchronized void foo(Object lock) { |
这里monitorenter和monitorexit操作所对应的锁对象是隐式的。对于实例方法来说,这两个操作对应的锁对象是this;对于静态方法来说,这两个操作对应的锁对象则是所在类的Class实例。
关于monitorenter和monitorexit的作用,我们可以抽象地理解为每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
当执行monitorenter时,如果目标锁对象的计数器为0,那么说明它没有被其他线程所持有。在这个情况下,Java虚拟机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。
在目标锁对象的计数器不为0的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其计数器加1,否则需要等待,直至持有线程释放该锁。
当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。当计数器减为0时,那便代表该锁已经被释放掉了。
之所以采用这种计数器的方式,是为了允许同一个线程重复获取同一把锁。举个例子,如果一个Java类中拥有多个synchronized方法,那么这些方法之间的相互调用,不管是直接的还是间接的,都会涉及对同一把锁的重复加锁操作。因此,我们需要设计这么一个可重入的特性,来避免编程里的隐式约束。
说完抽象的锁算法,下面我们便来介绍HotSpot虚拟机中具体的锁实现。
重量级锁
重量级锁是Java虚拟机中最为基础的锁实现。在这种状态下,Java虚拟机会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程。
Java线程的阻塞以及唤醒,都是依靠操作系统来完成的。举例来说,对于符合posix接口的操作系统(如macOS和绝大部分的Linux),上述操作是通过pthread的互斥锁(mutex)来实现的。此外,这些操作将涉及系统调用,需要从操作系统的用户态切换至内核态,其开销非常之大。
为了尽量避免昂贵的线程阻塞、唤醒操作,Java虚拟机会在线程进入阻塞状态之前,以及被唤醒后竞争不到锁的情况下,进入自旋状态,在处理器上空跑并且轮询锁是否被释放。如果此时锁恰好被释放了,那么当前线程便无须进入阻塞状态,而是直接获得这把锁。
与线程阻塞相比,自旋状态可能会浪费大量的处理器资源。这是因为当前线程仍处于运行状况,只不过跑的是无用指令。它期望在运行无用指令的过程中,锁能够被释放出来。
我们可以用等红绿灯作为例子。Java线程的阻塞相当于熄火停车,而自旋状态相当于怠速停车。如果红灯的等待时间非常长,那么熄火停车相对省油一些;如果红灯的等待时间非常短,比如说我们在synchronized代码块里只做了一个整型加法,那么在短时间内锁肯定会被释放出来,因此怠速停车更加合适。
然而,对于Java虚拟机来说,它并不能看到红灯的剩余时间,也就没办法根据等待时间的长短来选择自旋还是阻塞。Java虚拟机给出的方案是自适应自旋,根据以往自旋等待时是否能够获得锁,来动态调整自旋的时间(循环数目)。
就我们的例子来说,如果之前不熄火等到了绿灯,那么这次不熄火的时间就长一点;如果之前不熄火没等到绿灯,那么这次不熄火的时间就短一点。
自旋状态还带来另外一个副作用,那便是不公平的锁机制。处于阻塞状态的线程,并没有办法立刻竞争被释放的锁。然而,处于自旋状态的线程,则很有可能优先获得这把锁。
轻量级锁
你可能见到过深夜的十字路口,四个方向都闪黄灯的情况。由于深夜十字路口的车辆来往可能比较少,如果还设置红绿灯交替,那么很有可能出现四个方向仅有一辆车在等红灯的情况。
因此,红绿灯可能被设置为闪黄灯的情况,代表车辆可以自由通过,但是司机需要注意观察(个人理解,实际意义请咨询交警部门)。
Java虚拟机也存在着类似的情形:多个线程在不同的时间段请求同一把锁,也就是说没有锁竞争。针对这种情形,Java虚拟机采用了轻量级锁,来避免重量级锁的阻塞以及唤醒。
在介绍轻量级锁的原理之前,我们先来了解一下Java虚拟机是怎么区分轻量级锁和重量级锁的。
(你可以参照HotSpot Wiki里这张图阅读。)
在对象内存布局那一篇中我曾经介绍了对象头中的标记字段(mark word)。它的最后两位便被用来表示该对象的锁状态。其中,00代表轻量级锁,01代表无锁(或偏向锁),10代表重量级锁,11则跟垃圾回收算法的标记有关。
当进行加锁操作时,Java虚拟机会判断是否已经是重量级锁。如果不是,它会在当前线程的当前栈桢中划出一块空间,作为该锁的锁记录,并且将锁对象的标记字段复制到该锁记录中。
然后,Java虚拟机会尝试用CAS(compare-and-swap)操作替换锁对象的标记字段。这里解释一下,CAS是一个原子操作,它会比较目标地址的值是否和期望值相等,如果相等,则替换为一个新的值。
假设当前锁对象的标记字段为X…XYZ,Java虚拟机会比较该字段是否为X…X01。如果是,则替换为刚才分配的锁记录的地址。由于内存对齐的缘故,它的最后两位为00。此时,该线程已成功获得这把锁,可以继续执行了。
如果不是X…X01,那么有两种可能。第一,该线程重复获取同一把锁。此时,Java虚拟机会将锁记录清零,以代表该锁被重复获取。第二,其他线程持有该锁。此时,Java虚拟机会将这把锁膨胀为重量级锁,并且阻塞当前线程。
当进行解锁操作时,如果当前锁记录(你可以将一个线程的所有锁记录想象成一个栈结构,每次加锁压入一条锁记录,解锁弹出一条锁记录,当前锁记录指的便是栈顶的锁记录)的值为0,则代表重复进入同一把锁,直接返回即可。
否则,Java虚拟机会尝试用CAS操作,比较锁对象的标记字段的值是否为当前锁记录的地址。如果是,则替换为锁记录中的值,也就是锁对象原本的标记字段。此时,该线程已经成功释放这把锁。
如果不是,则意味着这把锁已经被膨胀为重量级锁。此时,Java虚拟机会进入重量级锁的释放过程,唤醒因竞争该锁而被阻塞了的线程。
偏向锁
如果说轻量级锁针对的情况很乐观,那么接下来的偏向锁针对的情况则更加乐观:从始至终只有一个线程请求某一把锁。
这就好比你在私家庄园里装了个红绿灯,并且庄园里只有你在开车。偏向锁的做法便是在红绿灯处识别来车的车牌号。如果匹配到你的车牌号,那么直接亮绿灯。
具体来说,在线程进行加锁时,如果该锁对象支持偏向锁,那么Java虚拟机会通过CAS操作,将当前线程的地址记录在锁对象的标记字段之中,并且将标记字段的最后三位设置为101。
在接下来的运行过程中,每当有线程请求这把锁,Java虚拟机只需判断锁对象标记字段中:最后三位是否为101,是否包含当前线程的地址,以及epoch值是否和锁对象的类的epoch值相同。如果都满足,那么当前线程持有该偏向锁,可以直接返回。
这里的epoch值是一个什么概念呢?
我们先从偏向锁的撤销讲起。当请求加锁的线程和锁对象标记字段保持的线程地址不匹配时(而且epoch值相等,如若不等,那么当前线程可以将该锁重偏向至自己),Java虚拟机需要撤销该偏向锁。这个撤销过程非常麻烦,它要求持有偏向锁的线程到达安全点,再将偏向锁替换成轻量级锁。
如果某一类锁对象的总撤销数超过了一个阈值(对应Java虚拟机参数-XX:BiasedLockingBulkRebiasThreshold,默认为20),那么Java虚拟机会宣布这个类的偏向锁失效。
具体的做法便是在每个类中维护一个epoch值,你可以理解为第几代偏向锁。当设置偏向锁时,Java虚拟机需要将该epoch值复制到锁对象的标记字段中。
在宣布某个类的偏向锁失效时,Java虚拟机实则将该类的epoch值加1,表示之前那一代的偏向锁已经失效。而新设置的偏向锁则需要复制新的epoch值。
为了保证当前持有偏向锁并且已加锁的线程不至于因此丢锁,Java虚拟机需要遍历所有线程的Java栈,找出该类已加锁的实例,并且将它们标记字段中的epoch值加1。该操作需要所有线程处于安全点状态。
如果总撤销数超过另一个阈值(对应Java虚拟机参数 -XX:BiasedLockingBulkRevokeThreshold,默认值为40),那么Java虚拟机会认为这个类已经不再适合偏向锁。此时,Java虚拟机会撤销该类实例的偏向锁,并且在之后的加锁过程中直接为该类实例设置轻量级锁。
总结与实践
今天我介绍了Java虚拟机中synchronized关键字的实现,按照代价由高至低可分为重量级锁、轻量级锁和偏向锁三种。
重量级锁会阻塞、唤醒请求加锁的线程。它针对的是多个线程同时竞争同一把锁的情况。Java虚拟机采取了自适应自旋,来避免线程在面对非常小的synchronized代码块时,仍会被阻塞、唤醒的情况。
轻量级锁采用CAS操作,将锁对象的标记字段替换为一个指针,指向当前线程栈上的一块空间,存储着锁对象原本的标记字段。它针对的是多个线程在不同时间段申请同一把锁的情况。
偏向锁只会在第一次请求时采用CAS操作,在锁对象的标记字段中记录下当前线程的地址。在之后的运行过程中,持有该偏向锁的线程的加锁操作将直接返回。它针对的是锁仅会被同一线程持有的情况。
今天的实践环节,我们来验证一个坊间传闻:调用Object.hashCode()会关闭该对象的偏向锁[1]。
你可以采用参数-XX:+PrintBiasedLockingStatistics来打印各类锁的个数。由于C2使用的是另外一个参数-XX:+PrintPreciseBiasedLockingStatistics,因此你可以限制Java虚拟机仅使用C1来即时编译(对应参数-XX:TieredStopAtLevel=1)。
- 通过参数-XX:+UseBiasedLocking,比较开关偏向锁时的输出结果。
- 在main方法的循环前添加lock.hashCode调用,并查看输出结果。
- 在Lock类中复写hashCode方法,并查看输出结果。
- 在main方法的循环前添加System.identityHashCode调用,并查看输出结果。
1 | // Run with -XX:+UnlockDiagnosticVMOptions -XX:+PrintBiasedLockingStatistics -XX:TieredStopAtLevel=1 |
[1] https://blogs.oracle.com/dave/biased-locking-in-hotspot
15 | Java语法糖与Java编译器
作者: 郑雨迪

在前面的篇章中,我们多次提到了Java语法和Java字节码的差异之处。这些差异之处都是通过Java编译器来协调的。今天我们便来列举一下Java编译器的协调工作。
自动装箱与自动拆箱
首先要提到的便是Java的自动装箱(auto-boxing)和自动拆箱(auto-unboxing)。
我们知道,Java语言拥有8个基本类型,每个基本类型都有对应的包装(wrapper)类型。
之所以需要包装类型,是因为许多Java核心类库的API都是面向对象的。举个例子,Java核心类库中的容器类,就只支持引用类型。
当需要一个能够存储数值的容器类时,我们往往定义一个存储包装类对象的容器。
对于基本类型的数值来说,我们需要先将其转换为对应的包装类,再存入容器之中。在Java程序中,这个转换可以是显式,也可以是隐式的,后者正是Java中的自动装箱。
1 | public int foo() { |
以上图中的Java代码为例。我构造了一个Integer类型的ArrayList,并且向其中添加一个int值0。然后,我会获取该ArrayList的第0个元素,并作为int值返回给调用者。这段代码对应的Java字节码如下所示:
1 | public int foo(); |
当向泛型参数为Integer的ArrayList添加int值时,便需要用到自动装箱了。在上面字节码偏移量为10的指令中,我们调用了Integer.valueOf方法,将int类型的值转换为Integer类型,再存储至容器类中。
1 | public static Integer valueOf(int i) { |
这是Integer.valueOf的源代码。可以看到,当请求的int值在某个范围内时,我们会返回缓存了的Integer对象;而当所请求的int值在范围之外时,我们则会新建一个Integer对象。
在介绍反射的那一篇中,我曾经提到参数java.lang.Integer.IntegerCache.high。这个参数将影响这里面的IntegerCache.high。
也就是说,我们可以通过配置该参数,扩大Integer缓存的范围。Java虚拟机参数-XX:+AggressiveOpts也会将IntegerCache.high调整至20000。
奇怪的是,Java并不支持对IntegerCache.low的更改,也就是说,对于小于-128的整数,我们无法直接使用由Java核心类库所缓存的Integer对象。
1 | 25: invokevirtual java/lang/Integer.intValue:()I |
当从泛型参数为Integer的ArrayList取出元素时,我们得到的实际上也是Integer对象。如果应用程序期待的是一个int值,那么就会发生自动拆箱。
在我们的例子中,自动拆箱对应的是字节码偏移量为25的指令。该指令将调用Integer.intValue方法。这是一个实例方法,直接返回Integer对象所存储的int值。
泛型与类型擦除
你可能已经留意到了,在前面例子生成的字节码中,往ArrayList中添加元素的add方法,所接受的参数类型是Object;而从ArrayList中获取元素的get方法,其返回类型同样也是Object。
前者还好,但是对于后者,在字节码中我们需要进行向下转换,将所返回的Object强制转换为Integer,方能进行接下来的自动拆箱。
1 | 13: invokevirtual java/util/ArrayList.add:(Ljava/lang/Object;)Z |
之所以会出现这种情况,是因为Java泛型的类型擦除。这是个什么概念呢?简单地说,那便是Java程序里的泛型信息,在Java虚拟机里全部都丢失了。这么做主要是为了兼容引入泛型之前的代码。
当然,并不是每一个泛型参数被擦除类型后都会变成Object类。对于限定了继承类的泛型参数,经过类型擦除后,所有的泛型参数都将变成所限定的继承类。也就是说,Java编译器将选取该泛型所能指代的所有类中层次最高的那个,作为替换泛型的类。
1 | class GenericTest<T extends Number> { |
举个例子,在上面这段Java代码中,我定义了一个T extends Number的泛型参数。它所对应的字节码如下所示。可以看到,foo方法的方法描述符所接收参数的类型以及返回类型都为Number。方法描述符是Java虚拟机识别方法调用的目标方法的关键。
1 | T foo(T); |
不过,字节码中仍存在泛型参数的信息,如方法声明里的T foo(T),以及方法签名(Signature)中的“(TT;)TT;”。这类信息主要由Java编译器在编译他类时使用。
既然泛型会被类型擦除,那么我们还有必要用它吗?
我认为是有必要的。Java编译器可以根据泛型参数判断程序中的语法是否正确。举例来说,尽管经过类型擦除后,ArrayList.add方法所接收的参数是Object类型,但是往泛型参数为Integer类型的ArrayList中添加字符串对象,Java编译器是会报错的。
1 | ArrayList<Integer> list = new ArrayList<>(); |
桥接方法
泛型的类型擦除带来了不少问题。其中一个便是方法重写。在第四篇的课后实践中,我留了这么一段代码:
1 | class Merchant<T extends Customer> { |
VIPOnlyMerchant中的actionPrice方法是符合Java语言的方法重写的,毕竟都使用@Override来注解了。然而,经过类型擦除后,父类的方法描述符为(LCustomer;)D,而子类的方法描述符为(LVIP;)D。这显然不符合Java虚拟机关于方法重写的定义。
为了保证编译而成的Java字节码能够保留重写的语义,Java编译器额外添加了一个桥接方法。该桥接方法在字节码层面重写了父类的方法,并将调用子类的方法。
1 | class VIPOnlyMerchant extends Merchant<VIP> |
在我们的例子中,VIPOnlyMerchant类将包含一个桥接方法actionPrice(Customer),它重写了父类的同名同方法描述符的方法。该桥接方法将传入的Customer参数强制转换为VIP类型,再调用原本的actionPrice(VIP)方法。
当一个声明类型为Merchant,实际类型为VIPOnlyMerchant的对象,调用actionPrice方法时,字节码里的符号引用指向的是Merchant.actionPrice(Customer)方法。Java虚拟机将动态绑定至VIPOnlyMerchant类的桥接方法之中,并且调用其actionPrice(VIP)方法。
需要注意的是,在javap的输出中,该桥接方法的访问标识符除了代表桥接方法的ACC_BRIDGE之外,还有ACC_SYNTHETIC。它表示该方法对于Java源代码来说是不可见的。当你尝试通过传入一个声明类型为Customer的对象作为参数,调用VIPOnlyMerchant类的actionPrice方法时,Java编译器会报错,并且提示参数类型不匹配。
1 | Customer customer = new VIP(); |
当然,如果你实在想要调用这个桥接方法,那么你可以选择使用反射机制。
1 | class Merchant { |
除了前面介绍的泛型重写会生成桥接方法之外,如果子类定义了一个与父类参数类型相同的方法,其返回类型为父类方法返回类型的子类,那么Java编译器也会为其生成桥接方法。
1 | class NaiveMerchant extends Merchant |
我之前曾提到过,class文件里允许出现两个同名、同参数类型但是不同返回类型的方法。这里的原方法和桥接方法便是其中一个例子。由于该桥接方法同样标注了ACC_SYNTHETIC,因此,当在Java程序中调用NaiveMerchant.actionPrice时,我们只会调用到原方法。
其他语法糖
在前面的篇章中,我已经介绍过了变长参数、try-with-resources以及在同一catch代码块中捕获多种异常等语法糖。下面我将列举另外两个常见的语法糖。
foreach循环允许Java程序在for循环里遍历数组或者Iterable对象。对于数组来说,foreach循环将从0开始逐一访问数组中的元素,直至数组的末尾。其等价的代码如下面所示:
1 | public void foo(int[] array) { |
对于Iterable对象来说,foreach循环将调用其iterator方法,并且用它的hasNext以及next方法来遍历该Iterable对象中的元素。其等价的代码如下面所示:
1 | public void foo(ArrayList<Integer> list) { |
字符串switch编译而成的字节码看起来非常复杂,但实际上就是一个哈希桶。由于每个case所截获的字符串都是常量值,因此,Java编译器会将原来的字符串switch转换为int值switch,比较所输入的字符串的哈希值。
由于字符串哈希值很容易发生碰撞,因此,我们还需要用String.equals逐个比较相同哈希值的字符串。
如果你感兴趣的话,可以自己利用javap分析字符串switch编译而成的字节码。
总结与实践
今天我主要介绍了Java编译器对几个语法糖的处理。
基本类型和其包装类型之间的自动转换,也就是自动装箱、自动拆箱,是通过加入[Wrapper].valueOf(如Integer.valueOf)以及[Wrapper].[primitive]Value(如Integer.intValue)方法调用来实现的。
Java程序中的泛型信息会被擦除。具体来说,Java编译器将选取该泛型所能指代的所有类中层次最高的那个,作为替换泛型的具体类。
由于Java语义与Java字节码中关于重写的定义并不一致,因此Java编译器会生成桥接方法作为适配器。此外,我还介绍了foreach循环以及字符串switch的编译。
今天的实践环节,你可以探索一下Java 10的var关键字,是否保存了泛型信息?是否支持自动装拆箱?
1 | public void foo() { |
16 | 即时编译(上)
作者: 郑雨迪

在专栏的第一篇中,我曾经简单地介绍过即时编译。这是一项用来提升应用程序运行效率的技术。通常而言,代码会先被Java虚拟机解释执行,之后反复执行的热点代码则会被即时编译成为机器码,直接运行在底层硬件之上。
今天我们便来详细剖析一下Java虚拟机中的即时编译。
分层编译模式
HotSpot虚拟机包含多个即时编译器C1、C2和Graal。
其中,Graal是一个实验性质的即时编译器,可以通过参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用,并且替换C2。
在Java 7以前,我们需要根据程序的特性选择对应的即时编译器。对于执行时间较短的,或者对启动性能有要求的程序,我们采用编译效率较快的C1,对应参数-client。
对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的C2,对应参数-server。
Java 7引入了分层编译(对应参数-XX:+TieredCompilation)的概念,综合了C1的启动性能优势和C2的峰值性能优势。
分层编译将Java虚拟机的执行状态分为了五个层次。为了方便阐述,我用“C1代码”来指代由C1生成的机器码,“C2代码”来指代由C2生成的机器码。五个层级分别是:
- 解释执行;
- 执行不带profiling的C1代码;
- 执行仅带方法调用次数以及循环回边执行次数profiling的C1代码;
- 执行带所有profiling的C1代码;
- 执行C2代码。
通常情况下,C2代码的执行效率要比C1代码的高出30%以上。然而,对于C1代码的三种状态,按执行效率从高至低则是1层 > 2层 > 3层。
其中1层的性能比2层的稍微高一些,而2层的性能又比3层高出30%。这是因为profiling越多,其额外的性能开销越大。
这里解释一下,profiling是指在程序执行过程中,收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的profile。
你可能已经接触过许许多多的profiler,例如JDK附带的hprof。这些profiler大多通过注入(instrumentation)或者JVMTI事件来实现的。Java虚拟机也内置了profiling。我会在下一篇中具体介绍Java虚拟机的profiling都在做些什么。
在5个层次的执行状态中,1层和4层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么Java虚拟机是不会再次发出该方法的编译请求的。

不同的编译路径,图片来源于我之前一篇介绍Graal的博客。
这里我列举了4个不同的编译路径(Igor的演讲列举了更多的编译路径)。通常情况下,热点方法会被3层的C1编译,然后再被4层的C2编译。
如果方法的字节码数目比较少(如getter/setter),而且3层的profiling没有可收集的数据。
那么,Java虚拟机断定该方法对于C1代码和C2代码的执行效率相同。在这种情况下,Java虚拟机会在3层编译之后,直接选择用1层的C1编译。由于这是一个终止状态,因此Java虚拟机不会继续用4层的C2编译。
在C1忙碌的情况下,Java虚拟机在解释执行过程中对程序进行profiling,而后直接由4层的C2编译。在C2忙碌的情况下,方法会被2层的C1编译,然后再被3层的C1编译,以减少方法在3层的执行时间。
Java 8默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数-client和-server都是无效的。当关闭分层编译的情况下,Java虚拟机将直接采用C2。
如果你希望只是用C1,那么你可以在打开分层编译的情况下使用参数-XX:TieredStopAtLevel=1。在这种情况下,Java虚拟机会在解释执行之后直接由1层的C1进行编译。
即时编译的触发
Java虚拟机是根据方法的调用次数以及循环回边的执行次数来触发即时编译的。前面提到,Java虚拟机在0层、2层和3层执行状态时进行profiling,其中就包含方法的调用次数和循环回边的执行次数。
这里的循环回边是一个控制流图中的概念。在字节码中,我们可以简单理解为往回跳转的指令。(注意,这并不一定符合循环回边的定义。)
1 | public static void foo(Object obj) { |
举例来说,上面这段代码将被编译为下面的字节码。其中,偏移量为18的字节码将往回跳至偏移量为7的字节码中。在解释执行时,每当运行一次该指令,Java虚拟机便会将该方法的循环回边计数器加1。
1 | public static void foo(java.lang.Object); |
在即时编译过程中,我们会识别循环的头部和尾部。在上面这段字节码中,循环的头部是偏移量为14的字节码,尾部为偏移量为11的字节码。
循环尾部到循环头部的控制流边就是真正意义上的循环回边。也就是说,C1将在这个位置插入增加循环回边计数器的代码。
解释执行和C1代码中增加循环回边计数器的位置并不相同,但这并不会对程序造成影响。
实际上,Java虚拟机并不会对这些计数器进行同步操作,因此收集而来的执行次数也并非精确值。不管如何,即时编译的触发并不需要非常精确的数值。只要该数值足够大,就能说明对应的方法包含热点代码。
具体来说,在不启用分层编译的情况下,当方法的调用次数和循环回边的次数的和,超过由参数-XX:CompileThreshold指定的阈值时(使用C1时,该值为1500;使用C2时,该值为10000),便会触发即时编译。
当启用分层编译时,Java虚拟机将不再采用由参数-XX:CompileThreshold指定的阈值(该参数失效),而是使用另一套阈值系统。在这套系统中,阈值的大小是动态调整的。
所谓的动态调整其实并不复杂:在比较阈值时,Java虚拟机会将阈值与某个系数s相乘。该系数与当前待编译的方法数目成正相关,与编译线程的数目成负相关。
1 | 系数的计算方法为: |
在64位Java虚拟机中,默认情况下编译线程的总数目是根据处理器数量来调整的(对应参数-XX:+CICompilerCountPerCPU,默认为true;当通过参数-XX:+CICompilerCount=N强制设定总编译线程数目时,CICompilerCountPerCPU将被设置为false)。
Java虚拟机会将这些编译线程按照1:2的比例分配给C1和C2(至少各为1个)。举个例子,对于一个四核机器来说,总的编译线程数目为3,其中包含一个C1编译线程和两个C2编译线程。
1 | 对于四核及以上的机器,总的编译线程的数目为: |
当启用分层编译时,即时编译具体的触发条件如下。
1 | 当方法调用次数大于由参数-XX:TierXInvocationThreshold指定的阈值乘以系数,或者当方法调用次数大于由参数-XX:TierXMINInvocationThreshold指定的阈值乘以系数,并且方法调用次数和循环回边次数之和大于由参数-XX:TierXCompileThreshold指定的阈值乘以系数时,便会触发X层即时编译。 |
其中i为调用次数,b为循环回边次数。
OSR编译
可以看到,决定一个方法是否为热点代码的因素有两个:方法的调用次数、循环回边的执行次数。即时编译便是根据这两个计数器的和来触发的。为什么Java虚拟机需要维护两个不同的计数器呢?
实际上,除了以方法为单位的即时编译之外,Java虚拟机还存在着另一种以循环为单位的即时编译,叫做On-Stack-Replacement(OSR)编译。循环回边计数器便是用来触发这种类型的编译的。
OSR实际上是一种技术,它指的是在程序执行过程中,动态地替换掉Java方法栈桢,从而使得程序能够在非方法入口处进行解释执行和编译后的代码之间的切换。事实上,去优化(deoptimization)采用的技术也可以称之为OSR。
在不启用分层编译的情况下,触发OSR编译的阈值是由参数-XX:CompileThreshold指定的阈值的倍数。
该倍数的计算方法为:
1 | (OnStackReplacePercentage - InterpreterProfilePercentage)/100 |
也就是说,默认情况下,C1的OSR编译的阈值为13500,而C2的为10700。
在启用分层编译的情况下,触发OSR编译的阈值则是由参数-XX:TierXBackEdgeThreshold指定的阈值乘以系数。
OSR编译在正常的应用程序中并不多见。它只在基准测试时比较常见,因此并不需要过多了解。
总结与实践
今天我详细地介绍了Java虚拟机中的即时编译。
从Java 8开始,Java虚拟机默认采用分层编译的方式。它将执行分为五个层次,分为为0层解释执行,1层执行没有profiling的C1代码,2层执行部分profiling的C1代码,3层执行全部profiling的C1代码,和4层执行C2代码。
通常情况下,方法会首先被解释执行,然后被3层的C1编译,最后被4层的C2编译。
即时编译是由方法调用计数器和循环回边计数器触发的。在使用分层编译的情况下,触发编译的阈值是根据当前待编译的方法数目动态调整的。
OSR是一种能够在非方法入口处进行解释执行和编译后代码之间切换的技术。OSR编译可以用来解决单次调用方法包含热循环的性能优化问题。
今天的实践环节,你可以使用参数-XX:+PrintCompilation来打印你项目中的即时编译情况。
1 | 88 15 3 CompilationTest::foo (16 bytes) |
简单解释一下该参数的输出:第一列是时间,第二列是Java虚拟机维护的编译ID。
接下来是一系列标识,包括%(是否OSR编译),s(是否synchronized方法),!(是否包含异常处理器),b(是否阻塞了应用线程,可了解一下参数-Xbatch),n(是否为native方法)。再接下来则是编译层次,以及方法名。如果是OSR编译,那么方法名后面还会跟着@以及循环所在的字节码。
当发生去优化时,你将看到之前出现过的编译,不过被标记了“made not entrant”。它表示该方法不能再被进入。
当Java虚拟机检测到所有的线程都退出该编译后的“made not entrant”时,会将该方法标记为“made zombie”,此时可以回收这块代码所占据的空间了。
17 | 即时编译(下)
作者: 郑雨迪

今天我们来继续讲解Java虚拟机中的即时编译。
Profiling
上篇提到,分层编译中的0层、2层和3层都会进行profiling,收集能够反映程序执行状态的数据。其中,最为基础的便是方法的调用次数以及循环回边的执行次数。它们被用于触发即时编译。
此外,0层和3层还会收集用于4层C2编译的数据,比如说分支跳转字节码的分支profile(branch profile),包括跳转次数和不跳转次数,以及非私有实例方法调用指令、强制类型转换checkcast指令、类型测试instanceof指令,和引用类型的数组存储aastore指令的类型profile(receiver type profile)。
分支profile和类型profile的收集将给应用程序带来不少的性能开销。据统计,正是因为这部分额外的profiling,使得3层C1代码的性能比2层C1代码的低30%。
在通常情况下,我们不会在解释执行过程中收集分支profile以及类型profile。只有在方法触发C1编译后,Java虚拟机认为该方法有可能被C2编译,方才在该方法的C1代码中收集这些profile。
只要在比较极端的情况下,例如等待C1编译的方法数目太多时,Java虚拟机才会开始在解释执行过程中收集这些profile。
那么这些耗费巨大代价收集而来的profile具体有什么作用呢?
答案是,C2可以根据收集得到的数据进行猜测,假设接下来的执行同样会按照所收集的profile进行,从而作出比较激进的优化。
基于分支profile的优化
举个例子,下面这段代码中包含两个条件判断。第一个条件判断将测试所输入的boolean值。
如果为true,则将局部变量v设置为所输入的int值。如果为false,则将所输入的int值经过一番运算之后,再存入局部变量v之中。
第二个条件判断则测试局部变量v是否和所输入的int值相等。如果相等,则返回0。如果不等,则将局部变量v经过一番运算之后,再将之返回。显然,当所输入的boolean值为true的情况下,这段代码将返回0。
1 | public static int foo(boolean f, int in) { |

假设应用程序调用该方法时,所传入的boolean值皆为true。那么,偏移量为1以及偏移量为18的条件跳转指令所对应的分支profile中,跳转的次数都为0。

C2可以根据这两个分支profile作出假设,在接下来的执行过程中,这两个条件跳转指令仍旧不会发生跳转。基于这个假设,C2便不再编译这两个条件跳转语句所对应的false分支了。
我们暂且不管当假设错误的时候会发生什么,先来看一看剩下来的代码。经过“剪枝”之后,在第二个条件跳转处,v的值只有可能为所输入的int值。因此,该条件跳转可以进一步被优化掉。最终的结果是,在第一个条件跳转之后,C2代码将直接返回0。

这里我打印了C2的编译结果。可以看到,在地址为2cee的指令处进行过一次比较之后,该机器码便直接返回0。
1 | Compiled method (c2) 95 16 4 CompilationTest::foo (30 bytes) |
总结一下,根据条件跳转指令的分支profile,即时编译器可以将从未执行过的分支剪掉,以避免编译这些很有可能不会用到的代码,从而节省编译时间以及部署代码所要消耗的内存空间。此外,“剪枝”将精简程序的数据流,从而触发更多的优化。
在现实中,分支profile出现仅跳转或者仅不跳转的情况并不多见。当然,即时编译器对分支profile的利用也不仅限于“剪枝”。它还会根据分支profile,计算每一条程序执行路径的概率,以便某些编译器优化优先处理概率较高的路径。
基于类型profile的优化
另外一个例子则是关于instanceof以及方法调用的类型profile。下面这段代码将测试所传入的对象是否为Exception的实例,如果是,则返回它的系统哈希值;如果不是,则返回它的哈希值。
1 | public static int hash(Object in) { |
假设应用程序调用该方法时,所传入的Object皆为Integer实例。那么,偏移量为1的instanceof指令的类型profile仅包含Integer,偏移量为4的分支跳转语句的分支profile中不跳转的次数为0,偏移量为13的方法调用指令的类型profile仅包含Integer。

在Java虚拟机中,instanceof测试并不简单。如果instanceof的目标类型是final类型,那么Java虚拟机仅需比较测试对象的动态类型是否为该final类型。
在讲解对象的内存分布那一篇中,我曾经提到过,对象头存有该对象的动态类型。因此,获取对象的动态类型仅为单一的内存读指令。
如果目标类型不是final类型,比如说我们例子中的Exception,那么Java虚拟机需要从测试对象的动态类型开始,依次测试该类,该类的父类、祖先类,该类所直接实现或者间接实现的接口是否与目标类型一致。
不过,在我们的例子中,instanceof指令的类型profile仅包含Integer。根据这个信息,即时编译器可以假设,在接下来的执行过程中,所输入的Object对象仍为Integer实例。
因此,生成的代码将测试所输入的对象的动态类型是否为Integer。如果是的话,则继续执行接下来的代码。(该优化源自Graal,采用C2可能无法复现。)
然后,即时编译器会采用和第一个例子中一致的针对分支profile的优化,以及对方法调用的条件去虚化内联。
我会在接下来的篇章中详细介绍内联,这里先说结果:生成的代码将测试所输入的对象动态类型是否为Integer。如果是的话,则执行Integer.hashCode()方法的实质内容,也就是返回该Integer实例的value字段。
1 | public final class Integer ... { |

和第一个例子一样,根据数据流分析,上述代码可以最终优化为极其简单的形式。

这里我打印了Graal的编译结果。可以看到,在地址为1ab7的指令处进行过一次比较之后,该机器码便直接返回所传入的Integer对象的value字段。
1 | Compiled method (JVMCI) 600 23 4 |
和基于分支profile的优化一样,基于类型profile的优化同样也是作出假设,从而精简控制流以及数据流。这两者的核心都是假设。
对于分支profile,即时编译器假设的是仅执行某一分支;对于类型profile,即时编译器假设的是对象的动态类型仅为类型profile中的那几个。
那么,当假设失败的情况下,程序将何去何从?我们继续往下看。
去优化
Java虚拟机给出的解决方案便是去优化,即从执行即时编译生成的机器码切换回解释执行。
在生成的机器码中,即时编译器将在假设失败的位置上插入一个陷阱(trap)。该陷阱实际上是一条call指令,调用至Java虚拟机里专门负责去优化的方法。与普通的call指令不一样的是,去优化方法将更改栈上的返回地址,并不再返回即时编译器生成的机器码中。
在上面的程序控制流图中,我画了很多红色方框的问号。这些问号便代表着一个个的陷阱。一旦踏入这些陷阱,便将发生去优化,并切换至解释执行。
去优化的过程相当复杂。由于即时编译器采用了许多优化方式,其生成的代码和原本的字节码的差异非常之大。
在去优化的过程中,需要将当前机器码的执行状态转换至某一字节码之前的执行状态,并从该字节码开始执行。这便要求即时编译器在编译过程中记录好这两种执行状态的映射。
举例来说,经过逃逸分析之后,机器码可能并没有实际分配对象,而是在各个寄存器中存储该对象的各个字段(标量替换,具体我会在之后的篇章中进行介绍)。在去优化过程中,Java虚拟机需要还原出这个对象,以便解释执行时能够使用该对象。
当根据映射关系创建好对应的解释执行栈桢后,Java虚拟机便会采用OSR技术,动态替换栈上的内容,并在目标字节码处开始解释执行。
此外,在调用Java虚拟机的去优化方法时,即时编译器生成的机器码可以根据产生去优化的原因来决定是否保留这一份机器码,以及何时重新编译对应的Java方法。
如果去优化的原因与优化无关,即使重新编译也不会改变生成的机器码,那么生成的机器码可以在调用去优化方法时传入Action_None,表示保留这一份机器码,在下一次调用该方法时重新进入这一份机器码。
如果去优化的原因与静态分析的结果有关,例如类层次分析,那么生成的机器码可以在调用去优化方法时传入Action_Recompile,表示不保留这一份机器码,但是可以不经过重新profile,直接重新编译。
如果去优化的原因与基于profile的激进优化有关,那么生成的机器码需要在调用去优化方法时传入Action_Reinterpret,表示不保留这一份机器码,而且需要重新收集程序的profile。
这是因为基于profile的优化失败的时候,往往代表这程序的执行状态发生改变,因此需要更正已收集的profile,以更好地反映新的程序执行状态。
总结与实践
今天我介绍了Java虚拟机的profiling以及基于所收集的数据的优化和去优化。
通常情况下,解释执行过程中仅收集方法的调用次数以及循环回边的执行次数。
当方法被3层C1所编译时,生成的C1代码将收集条件跳转指令的分支profile,以及类型相关指令的类型profile。在部分极端情况下,Java虚拟机也会在解释执行过程中收集这些profile。
基于分支profile的优化以及基于类型profile的优化都将对程序今后的执行作出假设。这些假设将精简所要编译的代码的控制流以及数据流。在假设失败的情况下,Java虚拟机将采取去优化,退回至解释执行并重新收集相关的profile。
今天的实践环节,你可以使用参数
1 | -XX:CompileCommand='print,*ClassName.methodName' |
来打印程序运行过程中即时编译器生成的机器码。官方的JDK可能不包含反汇编器动态链接库,如hsdis-amd64.dylib。你可能需要另外下载。
1 | // java -XX:CompileCommand='print,CompilationTest.foo' CompilationTestjava -XX:CompileCommand='print,CompilationTest.foo' CompilationTest |
18 | 即时编译器的中间表达形式
作者: 郑雨迪

在上一章中,我利用了程序控制流图以及伪代码,来展示即时编译器中基于profile的优化。不过,这并非实际的优化过程。
1. 中间表达形式(IR)
在编译原理课程中,我们通常将编译器分为前端和后端。其中,前端会对所输入的程序进行词法分析、语法分析、语义分析,然后生成中间表达形式,也就是IR(Intermediate Representation )。后端会对IR进行优化,然后生成目标代码。
如果不考虑解释执行的话,从Java源代码到最终的机器码实际上经过了两轮编译:Java编译器将Java源代码编译成Java字节码,而即时编译器则将Java字节码编译成机器码。
对于即时编译器来说,所输入的Java字节码剥离了很多高级的Java语法,而且其采用的基于栈的计算模型非常容易建模。因此,即时编译器并不需要重新进行词法分析、语法分析以及语义分析,而是直接将Java字节码作为一种IR。
不过,Java字节码本身并不适合直接作为可供优化的IR。这是因为现代编译器一般采用静态单赋值(Static Single Assignment,SSA)IR。这种IR的特点是每个变量只能被赋值一次,而且只有当变量被赋值之后才能使用。
1 | y = 1; |
举个例子(来源),上面这段代码所对应的SSA形式伪代码是下面这段:
1 | y1 = 1; |
在源代码中,我们可以轻易地发现第一个对y的赋值是冗余的,但是编译器不能。传统的编译器需要借助数据流分析(具体的优化叫reaching definition),从后至前依次确认哪些变量的值被覆盖(kill)掉。
不过,如果借助了SSA IR,编译器则可以通过查找赋值了但是没有使用的变量,来识别冗余赋值。
除此之外,SSA IR对其他优化方式也有很大的帮助,例如常量折叠(constant folding)、常量传播(constant propagation)、强度削减(strength reduction)以及死代码删除(dead code elimination)等。
1 | 示例: |
部分同学可能会手动进行上述优化,以期望能够达到更高的运行效率。实际上,对于这些简单的优化,编译器会代为执行,以便程序员专注于代码的可读性。
SSA IR会带来一个问题,那便是不同执行路径可能会对同一变量设置不同的值。例如下面这段代码if语句的两个分支中,变量y分别被赋值为0或1,并且在接下来的代码中读取y的值。此时,根据不同的执行路径,所读取到的值也很有可能不同。
1 | x = ..; |
为了解决这个问题,我们需要引入一个Phi函数的概念,能够根据不同的执行路径选择不同的值。于是,上面这段代码便可以转换为下面这段SSA伪代码。这里的Phi函数将根据前面两个分支分别选择y1、y2的值,并赋值给y3。
1 | x1 = ..; |
总之,即时编译器会将Java字节码转换成SSA IR。更确切的说,是一张包含控制流和数据流的IR图,每个字节码对应其中的若干个节点(注意,有些字节码并没有对应的IR节点)。然后,即时编译器在IR图上面进行优化。
我们可以将每一种优化看成一个独立的图算法,它接收一个IR图,并输出经过转换后的IR图。整个编译器优化过程便是一个个优化串联起来的。
2. Sea-of-nodes
HotSpot里的C2采用的是一种名为Sea-of-Nodes的SSA IR。它的最大特点,便是去除了变量的概念,直接采用变量所指向的值,来进行运算。
在上面这段SSA伪代码中,我们使用了多个变量名x1、x2、y1和y2。这在Sea-of-Nodes将不复存在。
取而代之的则是对应的值,比如说Phi(y1, y2)变成Phi(0, 1),后者本身也是一个值,被其他IR节点所依赖。正因如此,常量传播在Sea-of-Nodes中变成了一个no-op。
Graal的IR同样也是Sea-of-Nodes类型的,并且可以认为是C2 IR的精简版本。由于Graal的IR系统更加容易理解,而且工具支持相对来说也比较全、比较新,所以下面我将围绕着Graal的IR系统来讲解。
尽管IR系统不同,C2和Graal所实现的优化大同小异。对于那小部分不同的地方,它们也在不停地相互“借鉴”。所以你无须担心不通用的问题。
为了方便你理解今天的内容,我将利用IR可视化工具Ideal Graph Visualizer(IGV),来展示具体的IR图。(这里Ideal是C2中IR的名字。)
1 | public static int foo(int count) { |
上面这段代码所对应的IR图如下所示:

IR图
这里面,0号Start节点是方法入口,21号Return节点是方法出口。红色加粗线条为控制流,蓝色线条为数据流,而其他颜色的线条则是特殊的控制流或数据流。被控制流边所连接的是固定节点,其他的皆属于浮动节点。若干个顺序执行的节点将被包含在同一个基本块之中,如图中的B0、B1等。

基本块直接的控制流关系
基本块是仅有一个入口和一个出口的指令序列(IR节点序列)。一个基本块的出口可以和若干个基本块的入口相连接,反之亦然。
在我们的例子中,B0和B2的出口与B1的入口连接,代表在执行完B0或B2后可以跳转至B1,并继续执行B1中的内容。而B1的出口则与B2和B3的入口连接。
可以看到,上面的IR图已经没有sum或者i这样的变量名了,取而代之的是一个个的值,例如源程序中的i<count被转换为10号<节点,其接收两个值,分别为代表i的8号Phi节点,以及代表输入第0个参数的1号P(0)节点。
关于8号Phi节点,前面讲过,它将根据不同的执行路径选择不同的值。如果是从5号End节点进入的,则选择常量0;如果是从20号LoopEnd节点跳转进入的,则选择19号+节点。
你可以自己分析一下代表sum的7号Phi节点,根据不同的执行路径都选择了哪些值。
浮动节点的位置并不固定。在编译过程中,编译器需要(多次)计算浮动节点具体的排布位置。这个过程我们称之为节点调度(node scheduling)。
节点调度是根据节点之间的依赖关系来进行的。举个例子,在前面的IR图中,10号<节点是16号if节点用来判断是否跳转的条件,因此它需要排布在16号if节点(注意这是一个固定节点)之前。同时它又依赖于8号Phi节点的值以及1号P(0)节点的值,因此它需要排布在这两个节点之后。
需要注意的是,C2没有固定节点这一概念,所有的IR节点都是浮动节点。它将根据各个基本块头尾之间的控制依赖,以及数据依赖和内存依赖,来进行节点调度。
这里的内存依赖是什么一个概念呢?假设一段程序往内存中存储了一个值,而后又读取同一内存,那么显然程序希望读取到的是所存储的值。即时编译器不能任意调度对同一内存地址的读写,因为它们之间存在依赖关系。
C2的做法便是将这种时序上的先后记录为内存依赖,并让节点调度算法在进行调度时考虑这些内存依赖关系。Graal则将内存读写转换成固定节点。由于固定节点存在先后关系,因此无须额外记录内存依赖。
3. Global Value Numbering
下面介绍一种因Sea-of-Nodes而变得非常容易的优化技术 —— Global Value Numbering(GVN)。
GVN是一种发现并消除等价计算的优化技术。举例来说,如果一段程序中出现了多次操作数相同的乘法,那么即时编译器可以将这些乘法并为一个,从而降低输出机器码的大小。如果这些乘法出现在同一执行路径上,那么GVN还将省下冗余的乘法操作。
在Sea-of-Nodes中,由于只存在值的概念,因此GVN算法将非常简单:如果一个浮动节点本身不存在内存副作用(由于GVN可能影响节点调度,如果有内存副作用的话,那么将引发一些源代码中不可能出现的情况) ,那么即时编译器只需判断该浮动节点是否与已存在的浮动节点的类型相同,所输入的IR节点是否一致,便可以将这两个浮动节点归并成一个。
1 | public static int foo(int a, int b) { |
我们来看一个实际的案例。在上面这段代码中,如果a和b都大于0,那么我们需要做三次乘法。通过GVN之后,我们只会在B0中做一次乘法,并且在接下来的代码中直接使用乘法的结果,也就是4号*节点所代表的值。

我们可以将GVN理解为在IR图上的公共子表达式消除(Common Subexpression Elimination,CSE)。
这两者的区别在于,GVN直接比较值的相同与否,而CSE则是借助词法分析器来判断两个表达式相同与否。因此,在不少情况下,CSE还需借助常量传播来达到消除的效果。
总结与实践
今天我介绍了即时编译器的内部构造。
即时编译器将所输入的Java字节码转换成SSA IR,以便更好地进行优化。
具体来说,C2和Graal采用的是一种名为Sea-of-Nodes的IR,其特点用IR节点来代表程序中的值,并且将源程序中基于变量的计算转换为基于值的计算。
此外,我还介绍了C2和Graal的IR的可视化工具IGV,以及基于IR的优化GVN。
今天的实践环节,你可以尝试使用IGV来查看上一篇实践环节中的代码的具体编译过程。
你可以通过该页面下载当前版本的IGV。解压后,可运行脚本位于bin/idealgraphvisualizer中。IGV启动完成后,你可以通过下述指令将IR图打印至IGV中。(需附带Graal编译器的Java 10或以上版本。)
1 | // java -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler -XX:CompileCommand='dontinline,CompilationTest::hash' -Dgraal.Dump=:3 -Dgraal.MethodFilter='CompilationTest.hash' -Dgraal.OptDeoptimizationGrouping=false CompilationTest |
19 | Java字节码(基础篇)
作者: 郑雨迪

在前面的篇章中,有不少同学反馈对Java字节码并不是特别熟悉。那么今天我便来系统性地介绍一遍Java字节码。
操作数栈
我们知道,Java字节码是Java虚拟机所使用的指令集。因此,它与Java虚拟机基于栈的计算模型是密不可分的。
在解释执行过程中,每当为Java方法分配栈桢时,Java虚拟机往往需要开辟一块额外的空间作为操作数栈,来存放计算的操作数以及返回结果。
具体来说便是:执行每一条指令之前,Java虚拟机要求该指令的操作数已被压入操作数栈中。在执行指令时,Java虚拟机会将该指令所需的操作数弹出,并且将指令的结果重新压入栈中。
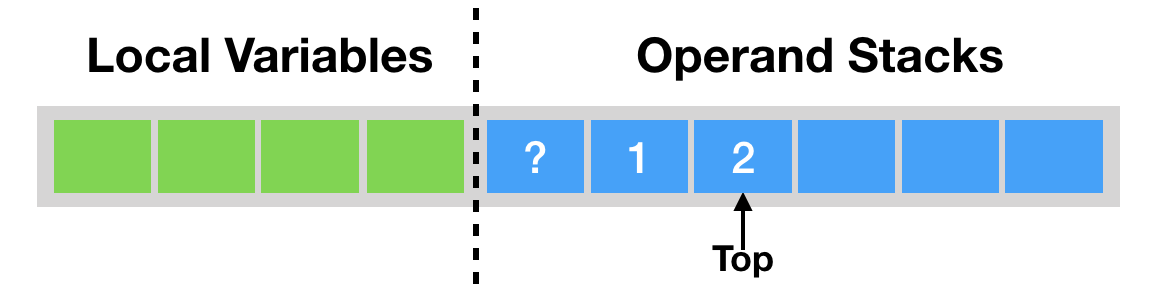
以加法指令iadd为例。假设在执行该指令前,栈顶的两个元素分别为int值1和int值2,那么iadd指令将弹出这两个int,并将求得的和int值3压入栈中。

由于iadd指令只消耗栈顶的两个元素,因此,对于离栈顶距离为2的元素,即图中的问号,iadd指令并不关心它是否存在,更加不会对其进行修改。
Java字节码中有好几条指令是直接作用在操作数栈上的。最为常见的便是dup: 复制栈顶元素,以及pop:舍弃栈顶元素。
dup指令常用于复制new指令所生成的未经初始化的引用。例如在下面这段代码的foo方法中,当执行new指令时,Java虚拟机将指向一块已分配的、未初始化的内存的引用压入操作数栈中。
1 | public void foo() { |
接下来,我们需要以这个引用为调用者,调用其构造器,也就是上面字节码中的invokespecial指令。要注意,该指令将消耗操作数栈上的元素,作为它的调用者以及参数(不过Object的构造器不需要参数)。
因此,我们需要利用dup指令复制一份new指令的结果,并用来调用构造器。当调用返回之后,操作数栈上仍有原本由new指令生成的引用,可用于接下来的操作(即偏移量为7的字节码,下面会介绍到)。
pop指令则常用于舍弃调用指令的返回结果。例如在下面这段代码的foo方法中,我将调用静态方法bar,但是却不用其返回值。
由于对应的invokestatic指令仍旧会将返回值压入foo方法的操作数栈中,因此Java虚拟机需要额外执行pop指令,将返回值舍弃。
1 | public static boolean bar() { |
需要注意的是,上述两条指令只能处理非long或者非double类型的值,这是因为long类型或者double类型的值,需要占据两个栈单元。当遇到这些值时,我们需要同时复制栈顶两个单元的dup2指令,以及弹出栈顶两个单元的pop2指令。
除此之外,不算常见但也是直接作用于操作数栈的还有swap指令,它将交换栈顶两个元素的值。
在Java字节码中,有一部分指令可以直接将常量加载到操作数栈上。以int类型为例,Java虚拟机既可以通过iconst指令加载-1至5之间的int值,也可以通过bipush、sipush加载一个字节、两个字节所能代表的int值。
Java虚拟机还可以通过ldc加载常量池中的常量值,例如ldc #18将加载常量池中的第18项。
这些常量包括int类型、long类型、float类型、double类型、String类型以及Class类型的常量。
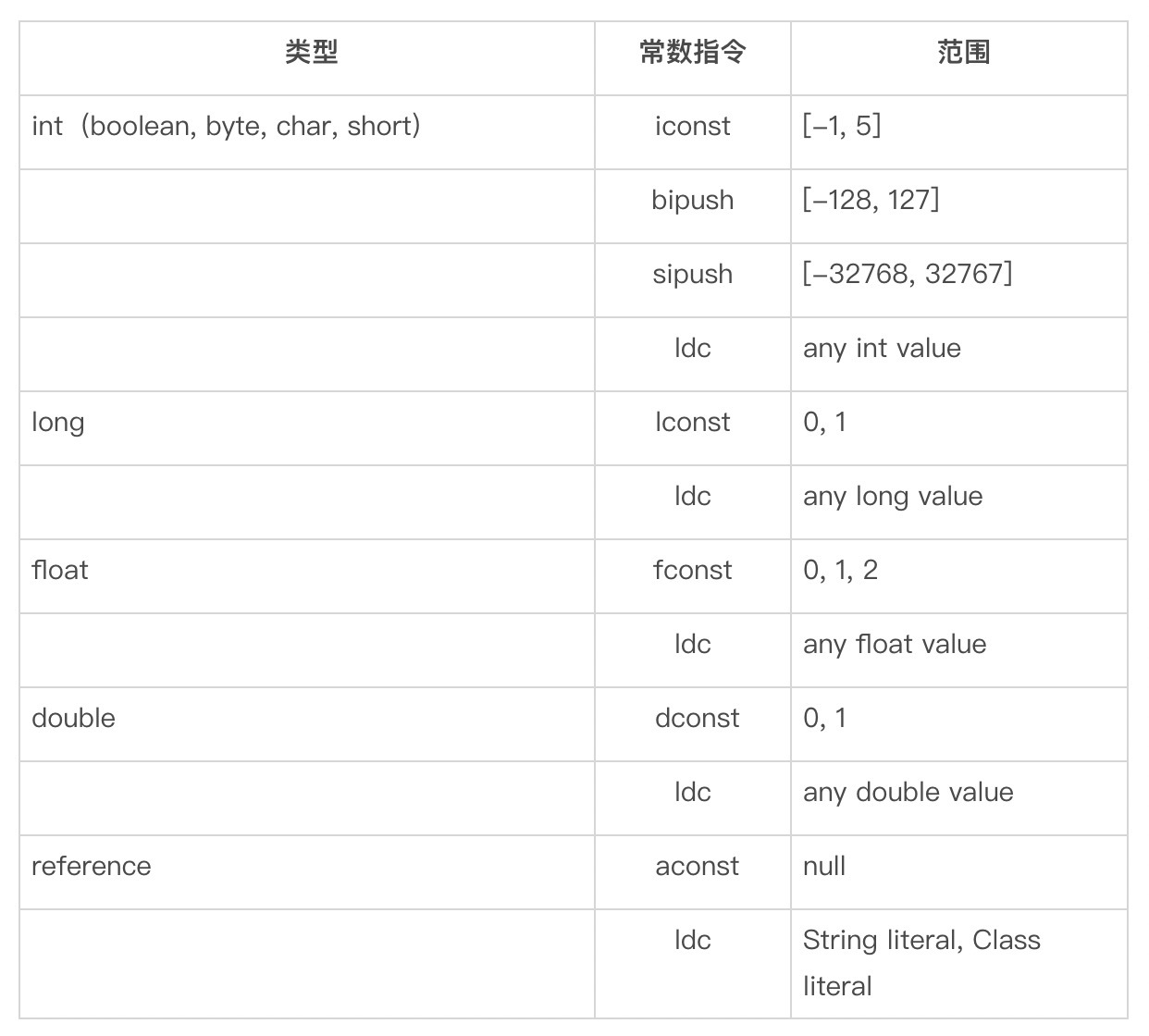
常数加载指令表
正常情况下,操作数栈的压入弹出都是一条条指令完成的。唯一的例外情况是在抛异常时,Java虚拟机会清除操作数栈上的所有内容,而后将异常实例压入操作数栈上。
局部变量区
Java方法栈桢的另外一个重要组成部分则是局部变量区,字节码程序可以将计算的结果缓存在局部变量区之中。
实际上,Java虚拟机将局部变量区当成一个数组,依次存放this指针(仅非静态方法),所传入的参数,以及字节码中的局部变量。
和操作数栈一样,long类型以及double类型的值将占据两个单元,其余类型仅占据一个单元。
1 | public void foo(long l, float f) { |
以上面这段代码中的foo方法为例,由于它是一个实例方法,因此局部变量数组的第0个单元存放着this指针。
第一个参数为long类型,于是数组的1、2两个单元存放着所传入的long类型参数的值。第二个参数则是float类型,于是数组的第3个单元存放着所传入的float类型参数的值。

在方法体里的两个代码块中,我分别定义了两个局部变量i和s。由于这两个局部变量的生命周期没有重合之处,因此,Java编译器可以将它们编排至同一单元中。也就是说,局部变量数组的第4个单元将为i或者s。
存储在局部变量区的值,通常需要加载至操作数栈中,方能进行计算,得到计算结果后再存储至局部变量数组中。这些加载、存储指令是区分类型的。例如,int类型的加载指令为iload,存储指令为istore。
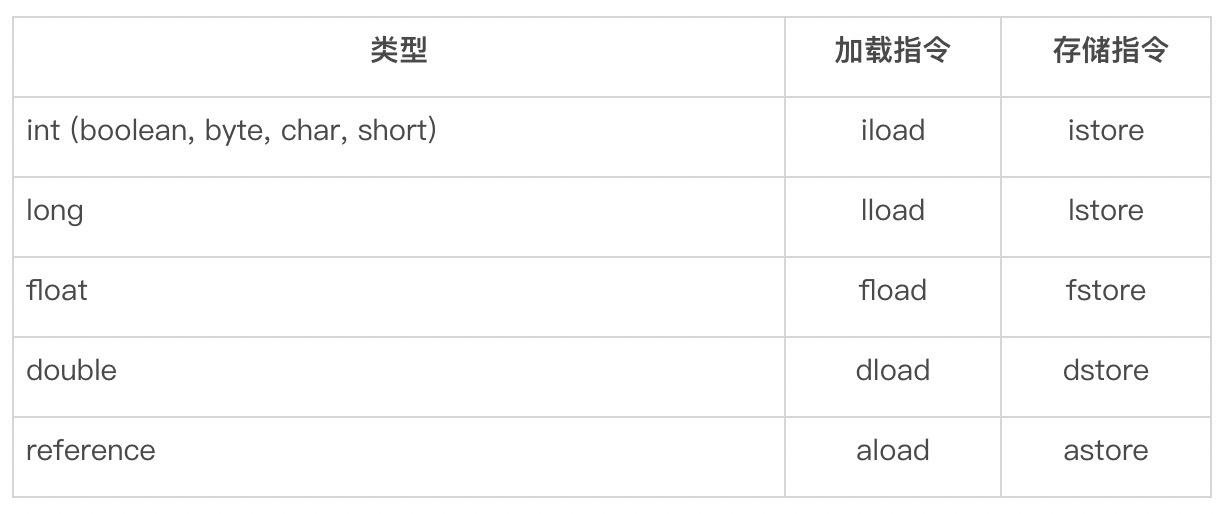
局部变量区访问指令表
局部变量数组的加载、存储指令都需要指明所加载单元的下标。举例来说,aload 0指的是加载第0个单元所存储的引用,在前面示例中的foo方法里指的便是加载this指针。
在我印象中,Java字节码中唯一能够直接作用于局部变量区的指令是iinc M N(M为非负整数,N为整数)。该指令指的是将局部变量数组的第M个单元中的int值增加N,常用于for循环中自增量的更新。
1 | public void foo() { |
综合示例
下面我们来看一个综合的例子:
1 | public static int bar(int i) { |
这里我定义了一个bar方法。它将接收一个int类型的参数,进行一系列计算之后再返回。
对应的字节码中的stack=2, locals=1代表该方法需要的操作数栈空间为2,局部变量数组空间为1。当调用bar(5)时,每条指令执行前后局部变量数组空间以及操作数栈的分布如下:

Java字节码简介
前面我已经介绍了加载常量指令、操作数栈专用指令以及局部变量区访问指令。下面我们来看看其他的类别。
Java相关指令,包括各类具备高层语义的字节码,即new(后跟目标类,生成该类的未初始化的对象),instanceof(后跟目标类,判断栈顶元素是否为目标类/接口的实例。是则压入1,否则压入0),checkcast(后跟目标类,判断栈顶元素是否为目标类/接口的实例。如果不是便抛出异常),athrow(将栈顶异常抛出),以及monitorenter(为栈顶对象加锁)和monitorexit(为栈顶对象解锁)。
此外,该类型的指令还包括字段访问指令,即静态字段访问指令getstatic、putstatic,和实例字段访问指令getfield、putfield。这四条指令均附带用以定位目标字段的信息,但所消耗的操作数栈元素皆不同。

以putfield为例,在上图中,它会把值v存储至对象obj的目标字段之中。
方法调用指令,包括invokestatic,invokespecial,invokevirtual,invokeinterface以及invokedynamic。这几条字节码我们已经反反复复提及了,就不再具体介绍各自的含义了。
除invokedynamic外,其他的方法调用指令所消耗的操作数栈元素是根据调用类型以及目标方法描述符来确定的。在进行方法调用之前,程序需要依次压入调用者(invokestatic不需要),以及各个参数。
1 | public int neg(int i) { |
以上面这段代码为例,当调用foo(2)时,每条指令执行前后局部变量数组空间以及操作数栈的分布如下所示:

数组相关指令,包括新建基本类型数组的newarray,新建引用类型数组的anewarray,生成多维数组的multianewarray,以及求数组长度的arraylength。另外,它还包括数组的加载指令以及存储指令。这些指令是区分类型的。例如,int数组的加载指令为iaload,存储指令为iastore。
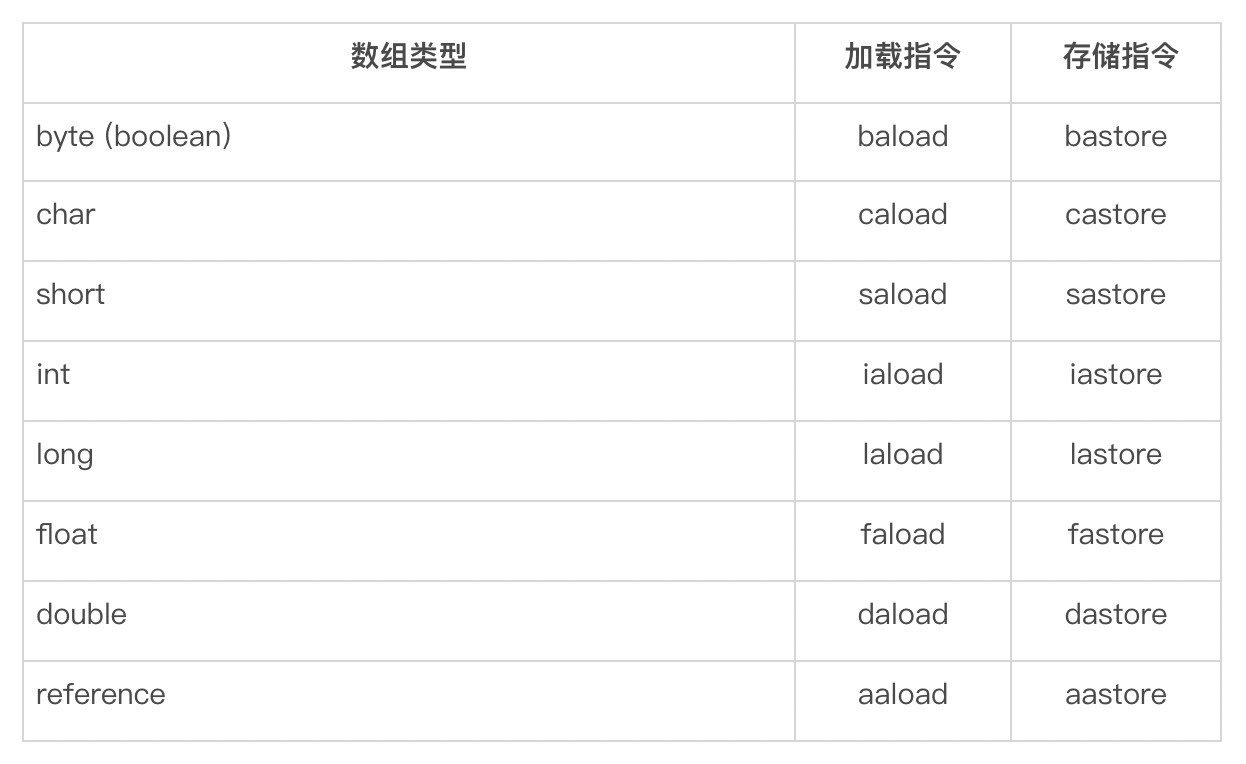
数组访问指令表
控制流指令,包括无条件跳转goto,条件跳转指令,tableswitch和lookupswtich(前者针对密集的cases,后者针对稀疏的cases),返回指令,以及被废弃的jsr,ret指令。其中返回指令是区分类型的。例如,返回int值的指令为ireturn。

返回指令表
除返回指令外,其他的控制流指令均附带一个或者多个字节码偏移量,代表需要跳转到的位置。例如下面的abs方法中偏移量为1的条件跳转指令,当栈顶元素小于0时,跳转至偏移量为6的字节码。
1 | public int abs(int i) { |
剩余的Java字节码几乎都和计算相关,这里就不再详细阐述了。
总结与实践
今天我简单介绍了各种类型的Java字节码。
Java方法的栈桢分为操作数栈和局部变量区。通常来说,程序需要将变量从局部变量区加载至操作数栈中,进行一番运算之后再存储回局部变量区中。
Java字节码可以划分为很多种类型,如加载常量指令,操作数栈专用指令,局部变量区访问指令,Java相关指令,方法调用指令,数组相关指令,控制流指令,以及计算相关指令。
今天的实践环节,你可以尝试自己分析一段较为复杂的字节码,在草稿上画出局部变量数组以及操作数栈分布图。当碰到不熟悉的指令时,你可以查阅Java虚拟机规范第6.5小节 ,或者此链接。
20 | 方法内联(上)
作者: 郑雨迪

在前面的篇章中,我多次提到了方法内联这项技术。它指的是:在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
方法内联不仅可以消除调用本身带来的性能开销,还可以进一步触发更多的优化。因此,它可以算是编译优化里最为重要的一环。
以getter/setter为例,如果没有方法内联,在调用getter/setter时,程序需要保存当前方法的执行位置,创建并压入用于getter/setter的栈帧、访问字段、弹出栈帧,最后再恢复当前方法的执行。而当内联了对getter/setter的方法调用后,上述操作仅剩字段访问。
在C2中,方法内联是在解析字节码的过程中完成的。每当碰到方法调用字节码时,C2将决定是否需要内联该方法调用。如果需要内联,则开始解析目标方法的字节码。
复习一下:即时编译器首先解析字节码,并生成IR图,然后在该IR图上进行优化。优化是由一个个独立的优化阶段(optimization phase)串联起来的。每个优化阶段都会对IR图进行转换。最后即时编译器根据IR图的节点以及调度顺序生成机器码。
同C2一样,Graal也会在解析字节码的过程中进行方法调用的内联。此外,Graal还拥有一个独立的优化阶段,来寻找指代方法调用的IR节点,并将之替换为目标方法的IR图。这个过程相对来说比较形象一些,因此,今天我就利用它来给你讲解一下方法内联。
1 | 方法内联的过程 |
上面这段代码中的foo方法将接收一个int类型的参数,而bar方法将接收一个boolean类型的参数。其中,foo方法会读取静态字段flag的值,并作为参数调用bar方法。

foo方法的IR图(内联前)
在编译foo方法时,其对应的IR图中将出现对bar方法的调用,即上图中的5号Invoke节点。如果内联算法判定应当内联对bar方法的调用时,那么即时编译器将开始解析bar方法的字节码,并生成对应的IR图,如下图所示。

bar方法的IR图
接下来,即时编译器便可以进行方法内联,把bar方法所对应的IR图纳入到对foo方法的编译中。具体的操作便是将foo方法的IR图中5号Invoke节点替换为bar方法的IR图。

foo方法的IR图(内联后)
除了将被调用方法的IR图节点复制到调用者方法的IR图中,即时编译器还需额外完成下述三项操作。
第一,被调用方法的传入参数节点,将被替换为调用者方法进行方法调用时所传入参数对应的节点。在我们的例子中,就是将bar方法IR图中的1号P(0)节点替换为foo方法IR图中的3号LoadField节点。
第二,在调用者方法的IR图中,所有指向原方法调用节点的数据依赖将重新指向被调用方法的返回节点。如果被调用方法存在多个返回节点,则生成一个Phi节点,将这些返回值聚合起来,并作为原方法调用节点的替换对象。
在我们的例子中,就是将8号==节点,以及12号Return节点连接到原5号Invoke节点的边,重新指向新生成的24号Phi节点中。
第三,如果被调用方法将抛出某种类型的异常,而调用者方法恰好有该异常类型的处理器,并且该异常处理器覆盖这一方法调用,那么即时编译器需要将被调用方法抛出异常的路径,与调用者方法的异常处理器相连接。
经过方法内联之后,即时编译器将得到一个新的IR图,并且在接下来的编译过程中对这个新的IR图进行进一步的优化。不过在上面这个例子中,方法内联后的IR图并没有能够进一步优化的地方。
1 | public final static boolean flag = true; |
不过,如果我们将代码中的三个静态字段标记为final,那么Java编译器(注意不是即时编译器)会将它们编译为常量值(ConstantValue),并且在字节码中直接使用这些常量值,而非读取静态字段。举例来说,bar方法对应的字节码如下所示。
1 | public static int bar(boolean); |
在编译foo方法时,一旦即时编译器决定要内联对bar方法的调用,那么它会将调用bar方法所使用的参数,也就是常数1,替换bar方法IR图中的参数。经过死代码消除之后,bar方法将直接返回常数0,所需复制的IR图也只有常数0这么一个节点。
经过方法内联之后,foo方法的IR图将变成如下所示:

该IR图可以进一步优化(死代码消除),并最终得到这张极为简单的IR图:

方法内联的条件
方法内联能够触发更多的优化。通常而言,内联越多,生成代码的执行效率越高。然而,对于即时编译器来说,内联越多,编译时间也就越长,而程序达到峰值性能的时刻也将被推迟。
此外,内联越多也将导致生成的机器码越长。在Java虚拟机里,编译生成的机器码会被部署到Code Cache之中。这个Code Cache是有大小限制的(由Java虚拟机参数-XX:ReservedCodeCacheSize控制)。
这就意味着,生成的机器码越长,越容易填满Code Cache,从而出现Code Cache已满,即时编译已被关闭的警告信息(CodeCache is full. Compiler has been disabled)。
因此,即时编译器不会无限制地进行方法内联。下面我便列举即时编译器的部分内联规则。(其他的特殊规则,如自动拆箱总会被内联、Throwable类的方法不能被其他类中的方法所内联,你可以直接参考JDK的源代码。)
首先,由-XX:CompileCommand中的inline指令指定的方法,以及由@ForceInline注解的方法(仅限于JDK内部方法),会被强制内联。 而由-XX:CompileCommand中的dontinline指令或exclude指令(表示不编译)指定的方法,以及由@DontInline注解的方法(仅限于JDK内部方法),则始终不会被内联。
其次,如果调用字节码对应的符号引用未被解析、目标方法所在的类未被初始化,或者目标方法是native方法,都将导致方法调用无法内联。
再次,C2不支持内联超过9层的调用(可以通过虚拟机参数-XX:MaxInlineLevel调整),以及1层的直接递归调用(可以通过虚拟机参数-XX:MaxRecursiveInlineLevel调整)。
如果方法a调用了方法b,而方法b调用了方法c,那么我们称b为a的1层调用,而c为a的2层调用。
最后,即时编译器将根据方法调用指令所在的程序路径的热度,目标方法的调用次数及大小,以及当前IR图的大小来决定方法调用能否被内联。

我在上面的表格列举了一些C2相关的虚拟机参数。总体来说,即时编译器中的内联算法更青睐于小方法。
总结与实践
今天我介绍了方法内联的过程以及条件。
方法内联是指,在编译过程中,当遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
即时编译器既可以在解析过程中替换方法调用字节码,也可以在IR图中替换方法调用IR节点。这两者都需要将目标方法的参数以及返回值映射到当前方法来。
方法内联有许多规则。除了一些强制内联以及强制不内联的规则外,即时编译器会根据方法调用的层数、方法调用指令所在的程序路径的热度、目标方法的调用次数及大小,以及当前IR图的大小来决定方法调用能否被内联。
今天的实践环节,你可以利用虚拟机参数-XX:+PrintInlining来打印编译过程中的内联情况。具体每项内联信息所代表的意思,你可以参考这一网页。
21 | 方法内联(下)
作者: 郑雨迪

在上一篇中,我举的例子都是静态方法调用,即时编译器可以轻易地确定唯一的目标方法。
然而,对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化(devirtualize),即转换为一个或多个直接调用,然后才能进行方法内联。
即时编译器的去虚化方式可分为完全去虚化以及条件去虚化(guarded devirtualization)。
完全去虚化是通过类型推导或者类层次分析(class hierarchy analysis),识别虚方法调用的唯一目标方法,从而将其转换为直接调用的一种优化手段。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化则是将虚方法调用转换为若干个类型测试以及直接调用的一种优化手段。它的关键在于找出需要进行比较的类型。
在介绍具体的去虚化方式之前,我们先来看一段代码。这里我定义了一个抽象类BinaryOp,其中包含一个抽象方法apply。BinaryOp类有两个子类Add和Sub,均实现了apply方法。
1 | abstract class BinaryOp { |
下面我便用这个例子来逐一讲解这几种去虚化方式。
基于类型推导的完全去虚化
基于类型推导的完全去虚化将通过数据流分析推导出调用者的动态类型,从而确定具体的目标方法。
1 | public static int foo() { |
举个例子,上面这段代码中的foo方法和bar方法均会调用apply方法,且调用者的声明类型皆为BinaryOp。这意味着Java编译器会将其编译为invokevirtual指令,调用BinaryOp.apply方法。
前两篇中我曾提到过,在Sea-of-Nodes的IR系统中,变量不复存在,取而代之的是具体值。这些具体值的类型往往要比变量的声明类型精确。

foo方法的IR图(方法内联前)

bar方法的IR图(方法内联前)
在上面两张IR图中,方法调用的调用者(即8号CallTarget节点的第一个依赖值)分别为2号New节点,以及5号Pi节点。后者可以简单看成强制转换后的精确类型。由于这两个节点的类型均被精确为Add类,因此,原invokevirtual指令对应的9号invoke节点都被识别对Add.apply方法的调用。
经过对该具体方法的内联之后,对应的IR图如下所示:

foo方法的IR图(方法内联及逃逸分析后)

bar方法的IR图(方法内联后)
可以看到,通过将字节码转换为Sea-of-Nodes IR之后,即时编译器便可以直接去虚化,并将唯一的目标方法进一步内联进来。
1 | public static int notInlined(BinaryOp op) { |
不过,对于上面这段代码中的notInlined方法,尽管理论上即时编译器能够推导出调用者的动态类型为Add,但是C2和Graal都没有这么做。
其原因在于类型推导属于全局优化,本身比较浪费时间;另一方面,就算不进行基于类型推导的完全去虚化,也有接下来的基于类层次分析的去虚化,以及条件去虚化兜底,覆盖大部分的代码情况。

notInlined方法的IR图(方法内联失败后)
因此,C2和Graal决定,如果生成Sea-of-Nodes IR后,调用者的动态类型已能够直接确定,那么就进行这项去虚化。如果需要额外的数据流分析方能确定,那么干脆不做,以节省编译时间,并依赖接下来的去虚化手段进行优化。
基于类层次分析的完全去虚化
基于类层次分析的完全去虚化通过分析Java虚拟机中所有已被加载的类,判断某个抽象方法或者接口方法是否仅有一个实现。如果是,那么对这些方法的调用将只能调用至该具体实现中。
在上面的例子中,假设在编译foo、bar或notInlined方法时,Java虚拟机仅加载了Add。那么,BinaryOp.apply方法只有Add.apply这么一个具体实现。因此,当即时编译器碰到对BinaryOp.apply的调用时,便可直接内联Add.apply的内容。
那么问题来了,即时编译器如何保证在今后的执行过程中,BinaryOp.apply方法还是只有Add.apply这么一个具体实现呢?
事实上,它无法保证。因为Java虚拟机有可能在上述编译完成之后加载Sub类,从而引入另一个BinaryOp.apply方法的具体实现Sub.apply。
Java虚拟机的做法是为当前编译结果注册若干个假设(assumption),假定某抽象类只有一个子类,或者某抽象方法只有一个具体实现,又或者某类没有子类等。
之后,每当新的类被加载,Java虚拟机便会重新验证这些假设。如果某个假设不再成立,那么Java虚拟机便会对其所属的编译结果进行去优化。
1 | public static int test(BinaryOp op) { |
以上面这段代码中的test方法为例。假设即时编译的时候,如果类层次分析得出BinaryOp类只有Add一个子类的结论,那么即时编译器可以注册一个假设,假定抽象方法BinaryOp.apply有且仅有Add.apply这个具体实现。
基于这个假设,原虚方法调用便可直接被去虚化为对Add.apply方法的调用。如果在之后的运行过程中,Java虚拟机又加载了Sub类,那么该假设失效,Java虚拟机需要触发test方法编译结果的去优化。
1 | public static int test(Add op) { |
事实上,即便调用者的声明类型为Add,即时编译器仍需为之添加假设。这是因为Java虚拟机不能保证没有重写了apply方法的Add类的子类。
为了保证这里apply方法的语义,即时编译器需要假设Add类没有子类。当然,通过将Add类标注为final,可以避开这个问题。
可以看到,即时编译器并不要求目标方法使用final修饰符。只要目标方法事实上是final的(effective final),便可以进行相应的去虚化以及内联。
不过,如果使用了final修饰符,即时编译器便可以不用生成对应的假设。这将使编译结果更加精简,并减少类加载时所需验证的内容。

test方法的IR图(方法内联后)
让我们回到原本的例子中。从test方法的IR图可以看出,生成的代码无须检测调用者的动态类型是否为Add,便直接执行内联之后的Add.apply方法中的内容(2+1经过常量折叠之后得到3,对应13号常数节点)。这是因为动态类型检测已被移至假设之中了。
然而,对于接口方法调用,该去虚化手段则不能移除动态类型检测。这是因为在执行invokeinterface指令时,Java虚拟机必须对调用者的动态类型进行测试,看它是否实现了目标接口方法所在的接口。
Java类验证器将接口类型直接看成Object类型,所以有可能出现声明类型为接口,实际类型没有继承该接口的情况,如下例所示。
1 | // A.java |
既然这一类型测试无法避免,C2干脆就不对接口方法调用进行基于类层次分析的完全去虚化,而是依赖于接下来的条件去虚化。
条件去虚化
前面提到,条件去虚化通过向代码中添加若干个类型比较,将虚方法调用转换为若干个直接调用。
具体的原理非常简单,是将调用者的动态类型,依次与Java虚拟机所收集的类型Profile中记录的类型相比较。如果匹配,则直接调用该记录类型所对应的目标方法。
1 | public static int test(BinaryOp op) { |
我们继续使用前面的例子。假设编译时类型Profile记录了调用者的两个类型Sub和Add,那么即时编译器可以据此进行条件去虚化,依次比较调用者的动态类型是否为Sub或者Add,并内联相应的方法。其伪代码如下所示:
1 | public static int test(BinaryOp op) { |
如果遍历完类型Profile中的所有记录,仍旧匹配不到调用者的动态类型,那么即时编译器有两种选择。
第一,如果类型Profile是完整的,也就是说,所有出现过的动态类型都被记录至类型Profile之中,那么即时编译器可以让程序进行去优化,重新收集类型Profile,对应的IR图如下所示(这里27号TypeSwitch节点等价于前面伪代码中的多个if语句):

当匹配不到动态类型时进行去优化
第二,如果类型Profile是不完整的,也就是说,某些出现过的动态类型并没有记录至类型Profile之中,那么重新收集并没有多大作用。此时,即时编译器可以让程序进行原本的虚调用,通过内联缓存进行调用,或者通过方法表进行动态绑定。对应的IR图如下所示:

当匹配不到动态类型时进行虚调用(仅在Graal中使用。)
在C2中,如果类型Profile是不完整的,即时编译器压根不会进行条件去虚化,而是直接使用内联缓存或者方法表。
总结与实践
今天我介绍了即时编译器去虚化的几种方法。
完全去虚化通过类型推导或者类层次分析,将虚方法调用转换为直接调用。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化通过向代码中增添类型比较,将虚方法调用转换为一个个的类型测试以及对应该类型的直接调用。它将借助Java虚拟机所收集的类型Profile。
今天的实践环节,我们来重现因类加载导致去优化的过程。
1 | // Run with java -XX:CompileCommand='dontinline JITTest.test' -XX:+PrintCompilation JITTest |
22 | HotSpot虚拟机的intrinsic
作者: 郑雨迪

前不久,有同学问我,String.indexOf方法和自己实现的indexOf方法在字节码层面上差不多,为什么执行效率却有天壤之别呢?今天我们就来看一看。
1 | public int indexOf(String str) { |
为了解答这个问题,我们来读一下String.indexOf方法的源代码(上面的代码截取自Java 10.0.2)。
在Java 9之前,字符串是用char数组来存储的,主要为了支持非英文字符。然而,大多数Java程序中的字符串都是由Latin1字符组成的。也就是说每个字符仅需占据一个字节,而使用char数组的存储方式将极大地浪费内存空间。
Java 9引入了Compact Strings[1]的概念,当字符串仅包含Latin1字符时,使用一个字节代表一个字符的编码格式,使得内存使用效率大大提高。
假设我们调用String.indexOf方法的调用者以及参数均为只包含Latin1字符的字符串,那么该方法的关键在于对StringLatin1.indexOf方法的调用。
下面我列举了StringLatin1.indexOf方法的源代码。你会发现,它并没有使用特别高明的算法,唯一值得注意的便是方法声明前的@HotSpotIntrinsicCandidate注解。
1 | @HotSpotIntrinsicCandidate |
在HotSpot虚拟机中,所有被该注解标注的方法都是HotSpot intrinsic。对这些方法的调用,会被HotSpot虚拟机替换成高效的指令序列。而原本的方法实现则会被忽略掉。
换句话说,HotSpot虚拟机将为标注了@HotSpotIntrinsicCandidate注解的方法额外维护一套高效实现。如果Java核心类库的开发者更改了原本的实现,那么虚拟机中的高效实现也需要进行相应的修改,以保证程序语义一致。
需要注意的是,其他虚拟机未必维护了这些intrinsic的高效实现,它们可以直接使用原本的较为低效的JDK代码。同样,不同版本的HotSpot虚拟机所实现的intrinsic数量也大不相同。通常越新版本的Java,其intrinsic数量越多。
你或许会产生这么一个疑问:为什么不直接在源代码中使用这些高效实现呢?
这是因为高效实现通常依赖于具体的CPU指令,而这些CPU指令不好在Java源程序中表达。再者,换了一个体系架构,说不定就没有对应的CPU指令,也就无法进行intrinsic优化了。
下面我们便来看几个具体的例子。
intrinsic与CPU指令
在文章开头的例子中,StringLatin1.indexOf方法将在一个字符串(byte数组)中查找另一个字符串(byte数组),并且返回命中时的索引值,或者-1(未命中)。
“恰巧”的是,X86_64体系架构的SSE4.2指令集就包含一条指令PCMPESTRI,让它能够在16字节以下的字符串中,查找另一个16字节以下的字符串,并且返回命中时的索引值。
因此,HotSpot虚拟机便围绕着这一指令,开发出X86_64体系架构上的高效实现,并替换原本对StringLatin1.indexOf方法的调用。
另外一个例子则是整数加法的溢出处理。一般我们在做整数加法时,需要考虑结果是否会溢出,并且在溢出的情况下作出相应的处理,以保证程序的正确性。
Java核心类库提供了一个Math.addExact方法。它将接收两个int值(或long值)作为参数,并返回这两个int值的和。当这两个int值之和溢出时,该方法将抛出ArithmeticException异常。
1 | @HotSpotIntrinsicCandidate |
在Java层面判断int值之和是否溢出比较费事。我们需要分别比较两个int值与它们的和的符号是否不同。如果都不同,那么我们便认为这两个int值之和溢出。对应的实现便是两个异或操作,一个与操作,以及一个比较操作。
在X86_64体系架构中,大部分计算指令都会更新状态寄存器(FLAGS register),其中就有表示指令结果是否溢出的溢出标识位(overflow flag)。因此,我们只需在加法指令之后比较溢出标志位,便可以知道int值之和是否溢出了。对应的伪代码如下所示:
1 | public static int addExact(int x, int y) { |
最后一个例子则是Integer.bitCount方法,它将统计所输入的int值的二进制形式中有多少个1。
1 | @HotSpotIntrinsicCandidate |
我们可以看到,Integer.bitCount方法的实现还是很巧妙的,但是它需要的计算步骤也比较多。在X86_64体系架构中,我们仅需要一条指令popcnt,便可以直接统计出int值中1的个数。
intrinsic与方法内联
HotSpot虚拟机中,intrinsic的实现方式分为两种。
一种是独立的桩程序。它既可以被解释执行器利用,直接替换对原方法的调用;也可以被即时编译器所利用,它把代表对原方法的调用的IR节点,替换为对这些桩程序的调用的IR节点。以这种形式实现的intrinsic比较少,主要包括Math类中的一些方法。
另一种则是特殊的编译器IR节点。显然,这种实现方式仅能够被即时编译器所利用。
在编译过程中,即时编译器会将对原方法的调用的IR节点,替换成特殊的IR节点,并参与接下来的优化过程。最终,即时编译器的后端将根据这些特殊的IR节点,生成指定的CPU指令。大部分的intrinsic都是通过这种方式实现的。
这个替换过程是在方法内联时进行的。当即时编译器碰到方法调用节点时,它将查询目标方法是不是intrinsic。
如果是,则插入相应的特殊IR节点;如果不是,则进行原本的内联工作。(即判断是否需要内联目标方法的方法体,并在需要内联的情况下,将目标方法的IR图纳入当前的编译范围之中。)
也就是说,如果方法调用的目标方法是intrinsic,那么即时编译器会直接忽略原目标方法的字节码,甚至根本不在乎原目标方法是否有字节码。即便是native方法,只要它被标记为intrinsic,即时编译器便能够将之”内联”进来,并插入特殊的IR节点。
事实上,不少被标记为intrinsic的方法都是native方法。原本对这些native方法的调用需要经过JNI(Java Native Interface),其性能开销十分巨大。但是,经过即时编译器的intrinsic优化之后,这部分JNI开销便直接消失不见,并且最终的结果也十分高效。
举个例子,我们可以通过Thread.currentThread方法来获取当前线程。这是一个native方法,同时也是一个HotSpot intrinsic。在X86_64体系架构中,R13寄存器存放着当前线程的指针。因此,对该方法的调用将被即时编译器替换为一个特殊IR节点,并最终生成读取R13寄存器指令。
已有intrinsic简介
最新版本的HotSpot虚拟机定义了三百多个intrinsic。
在这三百多个intrinsic中,有三成以上是Unsafe类的方法。不过,我们一般不会直接使用Unsafe类的方法,而是通过java.util.concurrent包来间接使用。
举个例子,Unsafe类中经常会被用到的便是compareAndSwap方法(Java 9+更名为compareAndSet或compareAndExchange方法)。在X86_64体系架构中,对这些方法的调用将被替换为lock cmpxchg指令,也就是原子性更新指令。
除了Unsafe类的方法之外,HotSpot虚拟机中的intrinsic还包括下面的几种。
StringBuilder和StringBuffer类的方法。HotSpot虚拟机将优化利用这些方法构造字符串的方式,以尽量减少需要复制内存的情况。String类、StringLatin1类、StringUTF16类和Arrays类的方法。HotSpot虚拟机将使用SIMD指令(single instruction multiple data,即用一条指令处理多个数据)对这些方法进行优化。
举个例子,Arrays.equals(byte[], byte[])方法原本是逐个字节比较,在使用了SIMD指令之后,可以放入16字节的XMM寄存器中(甚至是64字节的ZMM寄存器中)批量比较。
3. 基本类型的包装类、Object类、Math类、System类中各个功能性方法,反射API、MethodHandle类中与调用机制相关的方法,压缩、加密相关方法。这部分intrinsic则比较简单,这里就不详细展开了。如果你有感兴趣的,可以自行查阅资料,或者在文末留言。
如果你想知道HotSpot虚拟机定义的所有intrinsic,那么你可以直接查阅OpenJDK代码[2]。(该链接是Java 12的intrinsic列表。Java 8的intrinsic列表可以查阅这一链接[3]。)
总结与实践
今天我介绍了HotSpot虚拟机中的intrinsic。
HotSpot虚拟机将对标注了@HotSpotIntrinsicCandidate注解的方法的调用,替换为直接使用基于特定CPU指令的高效实现。这些方法我们便称之为intrinsic。
具体来说,intrinsic的实现有两种。一是不大常见的桩程序,可以在解释执行或者即时编译生成的代码中使用。二是特殊的IR节点。即时编译器将在方法内联过程中,将对intrinsic的调用替换为这些特殊的IR节点,并最终生成指定的CPU指令。
HotSpot虚拟机定义了三百多个intrinsic。其中比较特殊的有Unsafe类的方法,基本上使用java.util.concurrent包便会间接使用到Unsafe类的intrinsic。除此之外,String类和Arrays类中的intrinsic也比较特殊。即时编译器将为之生成非常高效的SIMD指令。
今天的实践环节,你可以体验一下Integer.bitCount intrinsic带来的性能提升。
1 | // time java Foo |
[1] http://openjdk.java.net/jeps/254
[2] http://hg.openjdk.java.net/jdk/hs/file/46dc568d6804/src/hotspot/share/classfile/vmSymbols.hpp#l727
23 | 逃逸分析
作者: 郑雨迪

我们知道,Java中Iterable对象的foreach循环遍历是一个语法糖,Java编译器会将该语法糖编译为调用Iterable对象的iterator方法,并用所返回的Iterator对象的hasNext以及next方法,来完成遍历。
1 | public void forEach(ArrayList<Object> list, Consumer<Object> f) { |
举个例子,上面的Java代码将使用foreach循环来遍历一个ArrayList对象,其等价的代码如下所示:
1 | public void forEach(ArrayList<Object> list, Consumer<Object> f) { |
这里我也列举了所涉及的ArrayList代码。我们可以看到,ArrayList.iterator方法将创建一个ArrayList$Itr实例。
1 | public class ArrayList ... { |
因此,有同学认为我们应当避免在热点代码中使用foreach循环,并且直接使用基于ArrayList.size以及ArrayList.get的循环方式(如下所示),以减少对Java堆的压力。
1 | public void forEach(ArrayList<Object> list, Consumer<Object> f) { |
实际上,Java虚拟机中的即时编译器可以将ArrayList.iterator方法中的实例创建操作给优化掉。不过,这需要方法内联以及逃逸分析的协作。
在前面几篇中我们已经深入学习了方法内联,今天我便来介绍一下逃逸分析。
逃逸分析
逃逸分析是“一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针”(出处参见[1])。
在Java虚拟机的即时编译语境下,逃逸分析将判断新建的对象是否逃逸。即时编译器判断对象是否逃逸的依据,一是对象是否被存入堆中(静态字段或者堆中对象的实例字段),二是对象是否被传入未知代码中。
前者很好理解:一旦对象被存入堆中,其他线程便能获得该对象的引用。即时编译器也因此无法追踪所有使用该对象的代码位置。
关于后者,由于Java虚拟机的即时编译器是以方法为单位的,对于方法中未被内联的方法调用,即时编译器会将其当成未知代码,毕竟它无法确认该方法调用会不会将调用者或所传入的参数存储至堆中。因此,我们可以认为方法调用的调用者以及参数是逃逸的。
通常来说,即时编译器里的逃逸分析是放在方法内联之后的,以便消除这些“未知代码”入口。
回到文章开头的例子。理想情况下,即时编译器能够内联对ArrayList$Itr构造器的调用,对hasNext以及next方法的调用,以及当内联了Itr.next方法后,对checkForComodification方法的调用。
如果这些方法调用均能够被内联,那么结果将近似于下面这段伪代码:
1 | public void forEach(ArrayList<Object> list, Consumer<Object> f) { |
可以看到,这段代码所新建的ArrayList$Itr实例既没有被存入任何字段之中,也没有作为任何方法调用的调用者或者参数。因此,逃逸分析将断定该实例不逃逸。
基于逃逸分析的优化
即时编译器可以根据逃逸分析的结果进行诸如锁消除、栈上分配以及标量替换的优化。
我们先来看一下锁消除。如果即时编译器能够证明锁对象不逃逸,那么对该锁对象的加锁、解锁操作没有意义。这是因为其他线程并不能获得该锁对象,因此也不可能对其进行加锁。在这种情况下,即时编译器可以消除对该不逃逸锁对象的加锁、解锁操作。
实际上,传统编译器仅需证明锁对象不逃逸出线程,便可以进行锁消除。由于Java虚拟机即时编译的限制,上述条件被强化为证明锁对象不逃逸出当前编译的方法。
在介绍Java内存模型时,我曾提过synchronized (new Object()) {}会被完全优化掉。这正是因为基于逃逸分析的锁消除。由于其他线程不能获得该锁对象,因此也无法基于该锁对象构造两个线程之间的happens-before规则。
synchronized (escapedObject) {}则不然。由于其他线程可能会对逃逸了的对象escapedObject进行加锁操作,从而构造了两个线程之间的happens-before关系。因此即时编译器至少需要为这段代码生成一条刷新缓存的内存屏障指令。
不过,基于逃逸分析的锁消除实际上并不多见。一般来说,开发人员不会直接对方法中新构造的对象进行加锁。事实上,逃逸分析的结果更多被用于将新建对象操作转换成栈上分配或者标量替换。
我们知道,Java虚拟机中对象都是在堆上分配的,而堆上的内容对任何线程都是可见的。与此同时,Java虚拟机需要对所分配的堆内存进行管理,并且在对象不再被引用时回收其所占据的内存。
如果逃逸分析能够证明某些新建的对象不逃逸,那么Java虚拟机完全可以将其分配至栈上,并且在new语句所在的方法退出时,通过弹出当前方法的栈桢来自动回收所分配的内存空间。这样一来,我们便无须借助垃圾回收器来处理不再被引用的对象。
不过,由于实现起来需要更改大量假设了“对象只能堆分配”的代码,因此HotSpot虚拟机并没有采用栈上分配,而是使用了标量替换这么一项技术。
所谓的标量,就是仅能存储一个值的变量,比如Java代码中的局部变量。与之相反,聚合量则可能同时存储多个值,其中一个典型的例子便是Java对象。
标量替换这项优化技术,可以看成将原本对对象的字段的访问,替换为一个个局部变量的访问。举例来说,前面经过内联之后的forEach代码可以被转换为如下代码:
1 | public void forEach(ArrayList<Object> list, Consumer<Object> f) { |
可以看到,原本需要在内存中连续分布的对象,现已被拆散为一个个单独的字段cursor,lastRet,以及expectedModCount。这些字段既可以存储在栈上,也可以直接存储在寄存器中。而该对象的对象头信息则直接消失了,不再被保存至内存之中。
由于该对象没有被实际分配,因此和栈上分配一样,它同样可以减轻垃圾回收的压力。与栈上分配相比,它对字段的内存连续性不做要求,而且,这些字段甚至可以直接在寄存器中维护,无须浪费任何内存空间。
部分逃逸分析
C2的逃逸分析与控制流无关,相对来说比较简单。Graal则引入了一个与控制流有关的逃逸分析,名为部分逃逸分析(partial escape analysis)[2]。它解决了所新建的实例仅在部分程序路径中逃逸的情况。
举个例子,在下面这段代码中,新建实例只会在进入if-then分支时逃逸。(对hashCode方法的调用是一个HotSpot intrinsic,将被替换为一个无法内联的本地方法调用。)
1 | public static void bar(boolean cond) { |
假设if语句的条件成立的可能性只有1%,那么在99%的情况下,程序没有必要新建对象。其手工优化的版本正是部分逃逸分析想要自动达到的成果。
部分逃逸分析将根据控制流信息,判断出新建对象仅在部分分支中逃逸,并且将对象的新建操作推延至对象逃逸的分支中。这将使得原本因对象逃逸而无法避免的新建对象操作,不再出现在只执行if-else分支的程序路径之中。
综上,与C2所使用的逃逸分析相比,Graal所使用的部分逃逸分析能够优化更多的情况,不过它编译时间也更长一些。
总结与实践
今天我介绍了Java虚拟机中即时编译器的逃逸分析,以及基于逃逸分析的优化。
在Java虚拟机的即时编译语境下,逃逸分析将判断新建的对象是否会逃逸。即时编译器判断对象逃逸的依据有两个:一是看对象是否被存入堆中,二是看对象是否作为方法调用的调用者或者参数。
即时编译器会根据逃逸分析的结果进行优化,如锁消除以及标量替换。后者指的是将原本连续分配的对象拆散为一个个单独的字段,分布在栈上或者寄存器中。
部分逃逸分析是一种附带了控制流信息的逃逸分析。它将判断新建对象真正逃逸的分支,并且支持将新建操作推延至逃逸分支。
今天的实践环节有两项内容。
第一项内容,我们来验证一下ArrayList.iterator中的新建对象能否被逃逸分析所优化。运行下述代码并观察GC的情况。你可以通过虚拟机参数-XX:-DoEscapeAnalysis来关闭默认开启的逃逸分析。
1 | // Run with |
第二项内容,我们来看一看部分逃逸分析的效果。你需要使用附带Graal编译器的Java版本,如Java 10,来运行下述代码,并且观察GC的情况。你可以通过虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler来启用Graal。
1 | // Run with |
[1] https://zh.wikipedia.org/wiki/逃逸分析
[2] http://www.ssw.uni-linz.ac.at/Research/Papers/Stadler14/Stadler2014-CGO-PEA.pdf
24 | 字段访问相关优化
作者: 郑雨迪

在上一篇文章中,我介绍了逃逸分析,也介绍了基于逃逸分析的优化方式锁消除、栈上分配以及标量替换等内容。
其中的标量替换,可以看成将对象本身拆散为一个个字段,并把原本对对象字段的访问,替换为对一个个局部变量的访问。
1 | class Foo { |
举个例子,上面这段代码中的bar方法,经过逃逸分析以及标量替换后,其优化结果如下所示。(确切地说,是指所生成的IR图与下述代码所生成的IR图类似。之后不再重复解释。)
1 | static int bar(int x) { |
由于Sea-of-Nodes IR的特性,局部变量不复存在,取而代之的是一个个值。在例子对应的IR图中,返回节点将直接返回所输入的参数。
经过标量替换的bar方法
下面我列举了bar方法经由C2即时编译生成的机器码(这里略去了指令地址的前48位)。
1 | # {method} 'bar' '(I)I' in 'FieldAccessTest' |
在X86_64的机器码中,每当使用call指令进入目标方法的方法体中时,我们需要在栈上为当前方法分配一块内存作为其栈桢。而在退出该方法时,我们需要弹出当前方法所使用的栈桢。
由于寄存器rsp维护着当前线程的栈顶指针,因此这些操作都是通过增减寄存器rsp来实现的,即上面这段机器码中偏移量为0x06a0以及0x06ae的指令。
在介绍安全点(safepoint)时我曾介绍过,HotSpot虚拟机的即时编译器将在方法返回时插入安全点测试指令,即图中偏移量为0x06b3以及0x06ba的指令。其中真正的安全点测试是0x06b7指令。
如果虚拟机需要所有线程都到达安全点,那么该test指令所访问的内存地址所在的页将被标记为不可访问,而该指令也将触发segfault,并借由segfault处理器进入安全点之中。通常,该指令会附带
; {poll_return}这样子的注释,这里被我略去了。
在X8_64中,前几个传入参数会被放置于寄存器中,而返回值则需要存放在rax寄存器中。有时候你会看到返回值被存入eax寄存器中,这其实是同一个寄存器,只不过rax表示64位寄存器,而eax表示32位寄存器。具体可以参考x86 calling conventions[1]。
当忽略掉创建、弹出方法栈桢,安全点测试以及其他无关指令之后,所剩下的方法体就只剩下偏移量为0x06ac的mov指令,以及0x06ba的ret指令。前者将所传入的int型参数x移至代表返回值的eax寄存器中,后者是退出当前方法并返回至调用者中。
虽然在部分情况下,逃逸分析以及基于逃逸分析的优化已经十分高效了,能够将代码优化到极其简单的地步,但是逃逸分析毕竟不是Java虚拟机的银色子弹。
在现实中,Java程序中的对象或许本身便是逃逸的,或许因为方法内联不够彻底而被即时编译器当成是逃逸的。这两种情况都将导致即时编译器无法进行标量替换。这时候,针对对象字段访问的优化也变得格外重要起来。
1 | static int bar(Foo o, int x) { |
在上面这段代码中,对象o是传入参数,不属于逃逸分析的范围(Java虚拟机中的逃逸分析针对的是新建对象)。该方法会将所传入的int型参数x的值存储至实例字段Foo.a中,然后再读取并返回同一字段的值。
这段代码将涉及两次内存访问操作:存储以及读取实例字段Foo.a。我们可以轻易地将其手工优化为直接读取并返回传入参数x的值。由于这段代码较为简单,因此它极大可能被编译为寄存器之间的移动指令(即将输入参数x的值移至寄存器eax中)。这与原本的内存访问指令相比,显然要高效得多。
1 | static int bar(Foo o, int x) { |
那么即时编译器是否能够作出类似的自动优化呢?
字段读取优化
答案是可以的。即时编译器会优化实例字段以及静态字段访问,以减少总的内存访问数目。具体来说,它将沿着控制流,缓存各个字段存储节点将要存储的值,或者字段读取节点所得到的值。
当即时编译器遇到对同一字段的读取节点时,如果缓存值还没有失效,那么它会将读取节点替换为该缓存值。
当即时编译器遇到对同一字段的存储节点时,它会更新所缓存的值。当即时编译器遇到可能更新字段的节点时,如方法调用节点(在即时编译器看来,方法调用会执行未知代码),或者内存屏障节点(其他线程可能异步更新了字段),那么它会采取保守的策略,舍弃所有缓存值。
在前面的例子中,我们见识了缓存字段存储节点的情况。下面我们来看一下缓存字段读取节点的情况。
1 | static int bar(Foo o, int x) { |
在上面这段代码中,实例字段Foo.a将被读取两次。即时编译器会将第一次读取的值缓存起来,并且替换第二次字段读取操作,以节省一次内存访问。
1 | static int bar(Foo o, int x) { |
如果字段读取节点被替换成一个常量,那么它将进一步触发更多优化。
1 | static int bar(Foo o, int x) { |
例如在上面这段代码中,实例字段Foo.a会被赋值为1。接下来的if语句将判断同一实例字段是否不小于0。经过字段读取优化之后,>=节点的两个输入参数分别为常数1和0,因此可以直接替换为具体结果true。如此一来,else分支将变成不可达代码,可以直接删除,其优化结果如下所示。
1 | static int bar(Foo o, int x) { |
我们再来看另一个例子。下面这段代码的bar方法中,实例字段a会被赋值为true,后面紧跟着一个以a为条件的while循环。
1 | class Foo { |
同样,即时编译器会将while循环中读取实例字段a的操作直接替换为常量true,即下面代码所示的死循环。
1 | void bar() { |
在介绍Java内存模型时,我们便知道可以通过volatile关键字标记实例字段a,以此强制对它的读取。
实际上,即时编译器将在volatile字段访问前后插入内存屏障节点。这些内存屏障节点会阻止即时编译器将屏障之前所缓存的值用于屏障之后的读取节点之上。
就我们的例子而言,尽管在X86_64平台上,volatile字段读取操作前后的内存屏障是no-op,在即时编译过程中的屏障节点,还是会阻止即时编译器的字段读取优化,强制在循环中使用内存读取指令访问实例字段Foo.a的最新值。
1 | 0x00e0: movzx r11d,BYTE PTR [rbx+0xc] // 读取a |
同理,加锁、解锁操作也同样会阻止即时编译器的字段读取优化。
字段存储优化
除了字段读取优化之外,即时编译器还将消除冗余的存储节点。如果一个字段先后被存储了两次,而且这两次存储之间没有对第一次存储内容的读取,那么即时编译器可以将第一个字段存储给消除掉。
1 | class Foo { |
举例来说,上面这段代码中的bar方法先后存储了两次Foo.a实例字段。由于第一次存储之后没有读取Foo.a的值,因此,即时编译器会将其看成冗余存储,并将之消除掉,生成如下代码:
1 | void bar() { |
实际上,即便是在这两个字段存储操作之间读取该字段,即时编译器还是有可能在字段读取优化的帮助下,将第一个存储操作当成冗余存储给消除掉。
1 | class Foo { |
当然,如果所存储的字段被标记为volatile,那么即时编译器也不能将冗余的存储操作消除掉。
这种情况看似很蠢,但实际上并不少见,比如说两个存储之间隔着许多其他代码,或者因为方法内联的缘故,将两个存储操作(如构造器中字段的初始化以及随后的更新)纳入同一个编译单元里。
死代码消除
除了字段存储优化之外,局部变量的死存储(dead store)同样也涉及了冗余存储。这是死代码消除(dead code eliminiation)的一种。不过,由于Sea-of-Nodes IR的特性,死存储的优化无须额外代价。
1 | int bar(int x, int y) { |
上面这段代码涉及两个存储局部变量操作。当即时编译器将其转换为Sea-of-Nodes IR之后,没有节点依赖于t的第一个值x*y。因此,该乘法运算将被消除,其结果如下所示:
1 | int bar(int x, int y) { |
死存储还有一种变体,即在部分程序路径上有冗余存储。
1 | int bar(boolean f, int x, int y) { |
举个例子,上面这段代码中,如果所传入的boolean类型的参数f是true,那么在程序执行路径上将先后进行两次对局部变量t的存储。
同样,经过Sea-of-Nodes IR转换之后,返回节点所依赖的值是一个phi节点,将根据程序路径选择x+y或者x*y。也就是说,当f为true的程序路径上的乘法运算会被消除,其结果如下所示:
1 | int bar(boolean f, int x, int y) { |
另一种死代码消除则是不可达分支消除。不可达分支就是任何程序路径都不可到达的分支,我们之前已经多次接触过了。
在即时编译过程中,我们经常因为方法内联、常量传播以及基于profile的优化等,生成许多不可达分支。通过消除不可达分支,即时编译器可以精简数据流,并且减少编译时间以及最终生成机器码的大小。
1 | int bar(int x) { |
举个例子,在上面的代码中,if语句将一直跳转至else分支之中。因此,另一不可达分支可以直接消除掉,形成下面的代码:
1 | int bar(int x) { |
总结与实践
今天我介绍了即时编译器关于字段访问的优化方式,以及死代码消除。
即时编译器将沿着控制流缓存字段存储、读取的值,并在接下来的字段读取操作时直接使用该缓存值。
这要求生成缓存值的访问以及使用缓存值的读取之间没有方法调用、内存屏障,或者其他可能存储该字段的节点。
即时编译器还会优化冗余的字段存储操作。如果一个字段的两次存储之间没有对该字段的读取操作、方法调用以及内存屏障,那么即时编译器可以将第一个冗余的存储操作给消除掉。
此外,我还介绍了死代码消除的两种形式。第一种是局部变量的死存储消除以及部分死存储消除。它们可以通过转换为Sea-of-Nodes IR来完成。第二种则是不可达分支。通过消除不可达分支,即时编译器可以精简数据流,并且减少编译时间以及最终生成机器码的大小。
今天的实践环节,请思考即时编译器会怎么优化下面代码中的除法操作?
1 | int bar(int x, int y) { |
[1] https://en.wikipedia.org/wiki/X86_calling_conventions#System_V_AMD64_ABI
25 | 循环优化
作者: 郑雨迪

在许多应用程序中,循环都扮演着非常重要的角色。为了提升循环的运行效率,研发编译器的工程师提出了不少面向循环的编译优化方式,如循环无关代码外提,循环展开等。
今天,我们便来了解一下,Java虚拟机中的即时编译器都应用了哪些面向循环的编译优化。
循环无关代码外提
所谓的循环无关代码(Loop-invariant Code),指的是循环中值不变的表达式。如果能够在不改变程序语义的情况下,将这些循环无关代码提出循环之外,那么程序便可以避免重复执行这些表达式,从而达到性能提升的效果。
1 | int foo(int x, int y, int[] a) { |
举个例子,在上面这段代码中,循环体中的表达式x*y,以及循环判断条件中的a.length均属于循环不变代码。前者是一个整数乘法运算,而后者则是内存访问操作,读取数组对象a的长度。(数组的长度存放于数组对象的对象头中,可通过arraylength指令来访问。)
理想情况下,上面这段代码经过循环无关代码外提之后,等同于下面这一手工优化版本。
1 | int fooManualOpt(int x, int y, int[] a) { |
我们可以看到,无论是乘法运算x*y,还是内存访问a.length,现在都在循环之前完成。原本循环中需要执行这两个表达式的地方,现在直接使用循环之前这两个表达式的执行结果。
在Sea-of-Nodes IR的帮助下,循环无关代码外提的实现并不复杂。

上图我截取了Graal为前面例子中的foo方法所生成的IR图(局部)。其中B2基本块位于循环之前,B3基本块为循环头。
x*y所对应的21号乘法节点,以及a.length所对应的47号读取节点,均不依赖于循环体中生成的数据,而且都为浮动节点。节点调度算法会将它们放置于循环之前的B2基本块中,从而实现这些循环无关代码的外提。
1 | 0x02f0: mov edi,ebx // ebx存放着x*y的结果 |
上面这段机器码是foo方法的编译结果中的循环。这里面没有整数乘法指令,也没有读取数组长度的内存访问指令。它们的值已在循环之前计算好了,并且分别保存在寄存器ebx以及r10d之中。在循环之中,代码直接使用寄存器ebx以及r10d所保存的值,而不用在循环中反复计算。
从生成的机器码中可以看出,除了x*y和a.length的外提之外,即时编译器还外提了int数组加载指令iaload所暗含的null检测(null check)以及下标范围检测(range check)。
如果将iaload指令想象成一个接收数组对象以及下标作为参数,并且返回对应数组元素的方法,那么它的伪代码如下所示:
1 | int iaload(int[] arrayRef, int index) { |
foo方法中的null检测属于循环无关代码。这是因为它始终检测作为输入参数的int数组是否为null,而这与第几次循环无关。
为了更好地阐述具体的优化,我精简了原来的例子,并将iaload展开,最终形成如下所示的代码。
1 | int foo(int[] a) { |
在这段代码中,null检测涉及了控制流依赖,因而无法通过Sea-of-Nodes IR转换以及节点调度来完成外提。
在C2中,null检测的外提是通过额外的编译优化,也就是循环预测(Loop Prediction,对应虚拟机参数-XX:+UseLoopPredicate)来实现的。该优化的实际做法是在循环之前插入同样的检测代码,并在命中的时候进行去优化。这样一来,循环中的检测代码便会被归纳并消除掉。
1 | int foo(int[] a) { |
除了null检测之外,其他循环无关检测都能够按照这种方式外提至循环之前。甚至是循环有关的下标范围检测,都能够借助循环预测来外提,只不过具体的转换要复杂一些。
之所以说下标范围检测是循环有关的,是因为在我们的例子中,该检测的主体是循环控制变量i(检测它是否在[0, a.length)之间),它的值将随着循环次数的增加而改变。
由于外提该下标范围检测之后,我们无法再引用到循环变量i,因此,即时编译器需要转换检测条件。具体的转换方式如下所示:
1 | for (int i = INIT; i < LIMIT; i += STRIDE) { |
循环展开
另外一项非常重要的循环优化是循环展开(Loop Unrolling)。它指的是在循环体中重复多次循环迭代,并减少循环次数的编译优化。
1 | int foo(int[] a) { |
举个例子,上面的代码经过一次循环展开之后将形成下面的代码:
1 | int foo(int[] a) { |
在C2中,只有计数循环(Counted Loop)才能被展开。所谓的计数循环需要满足如下四个条件。
- 维护一个循环计数器,并且基于计数器的循环出口只有一个(但可以有基于其他判断条件的出口)。
- 循环计数器的类型为int、short或者char(即不能是byte、long,更不能是float或者double)。
- 每个迭代循环计数器的增量为常数。
- 循环计数器的上限(增量为正数)或下限(增量为负数)是循环无关的数值。
1 | for (int i = START; i < LIMIT; i += STRIDE) { .. } |
在上面两种循环中,只要LIMIT是循环无关的数值,STRIDE是常数,而且循环中除了i < LIMIT之外没有其他基于循环变量i的循环出口,那么C2便会将该循环识别为计数循环。
循环展开的缺点显而易见:它可能会增加代码的冗余度,导致所生成机器码的长度大幅上涨。
不过,随着循环体的增大,优化机会也会不断增加。一旦循环展开能够触发进一步的优化,总体的代码复杂度也将降低。比如前面的例子经过循环展开之后便可以进一步优化为如下所示的代码:
1 | int foo(int[] a) { |
循环展开有一种特殊情况,那便是完全展开(Full Unroll)。当循环的数目是固定值而且非常小时,即时编译器会将循环全部展开。此时,原本循环中的循环判断语句将不复存在,取而代之的是若干个顺序执行的循环体。
1 | int foo(int[] a) { |
举个例子,上述代码将被完全展开为下述代码:
1 | int foo(int[] a) { |
即时编译器会在循环体的大小与循环展开次数之间做出权衡。例如,对于仅迭代三次(或以下)的循环,即时编译器将进行完全展开;对于循环体IR节点数目超过阈值的循环,即时编译器则不会进行任何循环展开。
其他循环优化
除了循环无关代码外提以及循环展开之外,即时编译器还有两个比较重要的循环优化技术:循环判断外提(loop unswitching)以及循环剥离(loop peeling)。
循环判断外提指的是将循环中的if语句外提至循环之前,并且在该if语句的两个分支中分别放置一份循环代码。
1 | int foo(int[] a) { |
举个例子,上面这段代码经过循环判断外提之后,将变成下面这段代码:
1 | int foo(int[] a) { |
循环判断外提与循环无关检测外提所针对的代码模式比较类似,都是循环中的if语句。不同的是,后者在检查失败时会抛出异常,中止当前的正常执行路径;而前者所针对的是更加常见的情况,即通过if语句的不同分支执行不同的代码逻辑。
循环剥离指的是将循环的前几个迭代或者后几个迭代剥离出循环的优化方式。一般来说,循环的前几个迭代或者后几个迭代都包含特殊处理。通过将这几个特殊的迭代剥离出去,可以使原本的循环体的规律性更加明显,从而触发进一步的优化。
1 | int foo(int[] a) { |
举个例子,上面这段代码剥离了第一个迭代后,将变成下面这段代码:
1 | int foo(int[] a) { |
总结与实践
今天我介绍了即时编译器所使用的循环优化。
循环无关代码外提将循环中值不变的表达式,或者循环无关检测外提至循环之前,以避免在循环中重复进行冗余计算。前者是通过Sea-of-Nodes IR以及节点调度来共同完成的,而后者则是通过一个独立优化 —— 循环预测来完成的。循环预测还可以外提循环有关的数组下标范围检测。
循环展开是一种在循环中重复多次迭代,并且相应地减少循环次数的优化方式。它是一种以空间换时间的优化方式,通过增大循环体来获取更多的优化机会。循环展开的特殊形式是完全展开,将原本的循环转换成若干个循环体的顺序执行。
此外,我还简单地介绍了另外两种循环优化方式:循环判断外提以及循环剥离。
今天的实践环节,我们来看这么一段代码:
1 | void foo(byte[] dst, byte[] src) { |
上面这段代码经过循环展开变成下面这段代码。请问你能想到进一步优化的机会吗?
(提示:数组元素在内存中的分布是连续的。假设dst[0]位于0x1000,那么dst[1]位于0x1001。)
1 | void foo(byte[] dst, byte[] src) { |
26 | 向量化
作者: 郑雨迪

在上一篇的实践环节中,我给你留了一个题目:如何进一步优化下面这段代码。
1 | void foo(byte[] dst, byte[] src) { |
由于X86_64平台不支持内存间的直接移动,上面代码中的dst[i] = src[i]通常会被编译为两条内存访问指令:第一条指令把src[i]的值读取至寄存器中,而第二条指令则把寄存器中的值写入至dst[i]中。
因此,上面这段代码中的一个循环迭代将会执行四条内存读取指令,以及四条内存写入指令。
由于数组元素在内存中是连续的,当从src[i]的内存地址处读取32位的内容时,我们将一并读取src[i]至src[i+3]的值。同样,当向dst[i]的内存地址处写入32位的内容时,我们将一并写入dst[i]至dst[i+3]的值。
通过综合这两个批量操作,我们可以使用一条内存读取指令以及一条内存写入指令,完成上面代码中循环体内的全部工作。如果我们用x[i:i+3]来指代x[i]至x[i+3]合并后的值,那么上述优化可以被表述成如下所示的代码:
1 | void foo(byte[] dst, byte[] src) { |
SIMD指令
在前面的示例中,我们使用的是byte数组,四个数组元素并起来也才4个字节。如果换成int数组,或者long数组,那么四个数组元素并起来将会是16字节或32字节。
我们知道,X86_64体系架构上通用寄存器的大小为64位(即8个字节),无法暂存这些超长的数据。因此,即时编译器将借助长度足够的XMM寄存器,来完成int数组与long数组的向量化读取和写入操作。(为了实现方便,byte数组的向量化读取、写入操作同样使用了XMM寄存器。)
所谓的XMM寄存器,是由SSE(Streaming SIMD Extensions)指令集所引入的。它们一开始仅为128位。自从X86平台上的CPU开始支持AVX(Advanced Vector Extensions)指令集后(2011年),XMM寄存器便升级为256位,并更名为YMM寄存器。原本使用XMM寄存器的指令,现将使用YMM寄存器的低128位。
前几年推出的AVX512指令集,更是将YMM寄存器升级至512位,并更名为ZMM寄存器。HotSpot虚拟机也紧跟时代,更新了不少基于AVX512指令集以及ZMM寄存器的优化。不过,支持AVX512指令集的CPU都比较贵,目前在生产环境中很少见到。

SSE指令集以及之后的AVX指令集都涉及了一个重要的概念,那便是单指令流多数据流(Single Instruction Multiple Data,SIMD),即通过单条指令操控多组数据的计算操作。这些指令我们称之为SIMD指令。
SIMD指令将XMM寄存器(或YMM寄存器、ZMM寄存器)中的值看成多个整数或者浮点数组成的向量,并且批量进行计算。

举例来说,128位XMM寄存器里的值可以看成16个byte值组成的向量,或者8个short值组成的向量,4个int值组成的向量,两个long值组成的向量;而SIMD指令PADDB、PADDW、PADDD以及PADDQ,将分别实现byte值、short值、int值或者long值的向量加法。
1 | void foo(int[] a, int[] b, int[] c) { |
上面这段代码经过向量化优化之后,将使用PADDD指令来实现c[i:i+3] = a[i:i+3] + b[i:i+3]。其执行过程中的数据流如下图所示,图片源自Vladimir Ivanov的演讲[1]。下图中内存的右边是高位,寄存器的左边是高位,因此数组元素的顺序是反过来的。

也就是说,原本需要c.length次加法操作的代码,现在最少只需要c.length/4次向量加法即可完成。因此,SIMD指令也被看成CPU指令级别的并行。
这里
c.length/4次是理论值。现实中,C2还将考虑缓存行对齐等因素,导致能够应用向量化加法的仅有数组中间的部分元素。
使用SIMD指令的HotSpot Intrinsic
SIMD指令虽然非常高效,但是使用起来却很麻烦。这主要是因为不同的CPU所支持的SIMD指令可能不同。一般来说,越新的SIMD指令,它所支持的寄存器长度越大,功能也越强。
目前几乎所有的X86_64平台上的CPU都支持SSE指令集,绝大部分支持AVX指令集,三四年前量产的CPU支持AVX2指令集,最近少数服务器端CPU支持AVX512指令集。AVX512指令集的提升巨大,因为它不仅将寄存器长度增大至512字节,而且引入了非常多的新指令。
为了能够尽量利用新的SIMD指令,我们需要提前知道程序会被运行在支持哪些指令集的CPU上,并在编译过程中选择所支持的SIMD指令中最新的那些。
或者,我们可以在编译结果中纳入同一段代码的不同版本,每个版本使用不同的SIMD指令。在运行过程中,程序将根据CPU所支持的指令集,来选择执行哪一个版本。
虽然程序中包含当前CPU可能不支持的指令,但是只要不执行到这些指令,程序便不会出问题。如果不小心执行到这些不支持的指令,CPU会触发一个中断,并向当前进程发出
sigill信号。
不过,这对于使用即时编译技术的Java虚拟机来说,并不是一个大问题。
我们知道,Java虚拟机所执行的Java字节码是平台无关的。它首先会被解释执行,而后反复执行的部分才会被Java虚拟机即时编译为机器码。换句话说,在进行即时编译的时候,Java虚拟机已经运行在目标CPU之上,可以轻易地得知其所支持的指令集。
然而,Java字节码的平台无关性却引发了另一个问题,那便是Java程序无法像C++程序那样,直接使用由Intel提供的,将被替换为具体SIMD指令的intrinsic方法[2]。
HotSpot虚拟机提供的替代方案是Java层面的intrinsic方法,这些intrinsic方法的语义要比单个SIMD指令复杂得多。在运行过程中,HotSpot虚拟机将根据当前体系架构来决定是否将对该intrinsic方法的调用替换为另一高效的实现。如果不,则使用原本的Java实现。
举个例子,Java 8中Arrays.equals(int[], int[])的实现将逐个比较int数组中的元素。
1 | public static boolean equals(int[] a, int[] a2) { |
对应的intrinsic高效实现会将数组的多个元素加载至XMM/YMM/ZMM寄存器中,然后进行按位比较。如果两个数组相同,那么其中若干个元素合并而成的值也相同,其按位比较也应成功。反过来,如果按位比较失败,则说明两个数组不同。
使用SIMD指令的HotSpot intrinsic是虚拟机开发人员根据其语义定制的,因而性能相当优越。
不过,由于开发成本及维护成本较高,这种类型的intrinsic屈指可数,如用于复制数组的System.arraycopy和Arrays.copyOf,用于比较数组的Arrays.equals,以及Java 9新加入的Arrays.compare和Arrays.mismatch,以及字符串相关的一些方法String.indexOf、StringLatin1.inflate。
Arrays.copyOf将调用System.arraycopy,实际上只有后者是intrinsic。在Java 9之后,数组比较真正的intrinsic是ArraySupports.vectorizedMismatch方法,而Arrays.equals、Arrays.compare和Arrays.mismatch将调用至该方法中。
另外,这些intrinsic方法只能做到点覆盖,在不少情况下,应用程序并不会用到这些intrinsic的语义,却又存在向量化优化的机会。这个时候,我们便需要借助即时编译器中的自动向量化(auto vectorization)。
自动向量化
即时编译器的自动向量化将针对能够展开的计数循环,进行向量化优化。如前面介绍过的这段代码,即时编译器便能够自动将其展开优化成使用PADDD指令的向量加法。
1 | void foo(int[] a, int[] b, int[] c) { |
关于计数循环的判定,我在上一篇介绍循环优化时已经讲解过了,这里我补充几点自动向量化的条件。
- 循环变量的增量应为1,即能够遍历整个数组。
- 循环变量不能为long类型,否则C2无法将循环识别为计数循环。
- 循环迭代之间最好不要有数据依赖,例如出现类似于
a[i] = a[i-1]的语句。当循环展开之后,循环体内存在数据依赖,那么C2无法进行自动向量化。 - 循环体内不要有分支跳转。
- 不要手工进行循环展开。如果C2无法自动展开,那么它也将无法进行自动向量化。
我们可以看到,自动向量化的条件较为苛刻。而且,C2支持的整数向量化操作并不多,据我所致只有向量加法,向量减法,按位与、或、异或,以及批量移位和批量乘法。C2还支持向量点积的自动向量化,即两两相乘再求和,不过这需要多条SIMD指令才能完成,因此并不是十分高效。
为了解决向量化intrinsic以及自动向量化覆盖面过窄的问题,我们在OpenJDK的Paname项目[3]中尝试引入开发人员可控的向量化抽象。
该抽象将提供一套通用的跨平台API,让Java程序能够定义诸如IntVector<S256Bits>的向量,并使用由它提供的一系列向量化intrinsic方法。即时编译器负责将这些intrinsic的调用转换为符合当前体系架构/CPU的SIMD指令。如果你感兴趣的话,可以参考Vladimir Ivanov今年在JVMLS上的演讲[4]。
总结与实践
今天我介绍了即时编译器中的向量化优化。
向量化优化借助的是CPU的SIMD指令,即通过单条指令控制多组数据的运算。它被称为CPU指令级别的并行。
HotSpot虚拟机运用向量化优化的方式有两种。第一种是使用HotSpot intrinsic,在调用特定方法的时候替换为使用了SIMD指令的高效实现。Intrinsic属于点覆盖,只有当应用程序明确需要这些intrinsic的语义,才能够获得由它带来的性能提升。
第二种是依赖即时编译器进行自动向量化,在循环展开优化之后将不同迭代的运算合并为向量运算。自动向量化的触发条件较为苛刻,因此也无法覆盖大多数用例。
今天的实践环节,我们来观察一下即时编译器的自动向量化的自适配性。
在支持256位YMM寄存器的机器上,C2会根据循环回边的执行次数以及方法的执行次数来推测每个循环的次数。如果超过一定值,C2会采用基于256位YMM寄存器的指令,相比起基于128位XMM寄存器的指令而言,单指令能处理的数据翻了一倍。
请采用Java 9以上的版本运行下述代码。(Java 8始终采用基于128位XMM寄存器指令的Bug可能仍未修复。)
1 | // Run with |
输出将包含如下机器码:
1 | 0x000000011ce7c650: vmovdqu xmm0,XMMWORD PTR [rdx+rbx*4+0x10] |
如果替换为:
1 | int[] a = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; |
输出将包含如下机器码:
1 | 0x000000010ff04d9c: vmovdqu ymm0,YMMWORD PTR [rdx+rbx*4+0x10] |
你可以将foo方法更改为下述代码:
1 | static void foo(int[] a) { |
重复上述实验,看看会发生什么。
[1] http://cr.openjdk.java.net/~vlivanov/talks/2017_Vectorization_in_HotSpot_JVM.pdf
[2] https://software.intel.com/sites/landingpage/IntrinsicsGuide/
[3] http://openjdk.java.net/projects/panama/
[4]: http://cr.openjdk.java.net/~vlivanov/talks/2018_JVMLS_VectorAPI.pdf
27 | 注解处理器
作者: 郑雨迪

注解(annotation)是Java 5引入的,用来为类、方法、字段、参数等Java结构提供额外信息的机制。我先举个例子,比如,Java核心类库中的@Override注解是被用来声明某个实例方法重写了父类的同名同参数类型的方法。
1 | package java.lang; |
@Override注解本身被另外两个元注解(即作用在注解上的注解)所标注。其中,@Target用来限定目标注解所能标注的Java结构,这里@Override便只能被用来标注方法。
@Retention则用来限定当前注解生命周期。注解共有三种不同的生命周期:SOURCE,CLASS或RUNTIME,分别表示注解只出现在源代码中,只出现在源代码和字节码中,以及出现在源代码、字节码和运行过程中。
这里@Override便只能出现在源代码中。一旦标注了@Override的方法所在的源代码被编译为字节码,该注解便会被擦除。
我们不难猜到,@Override仅对Java编译器有用。事实上,它会为Java编译器引入了一条新的编译规则,即如果所标注的方法不是Java语言中的重写方法,那么编译器会报错。而当编译完成时,它的使命也就结束了。
我们知道,Java的注解机制允许开发人员自定义注解。这些自定义注解同样可以为Java编译器添加编译规则。不过,这种功能需要由开发人员提供,并且以插件的形式接入Java编译器中,这些插件我们称之为注解处理器(annotation processor)。
除了引入新的编译规则之外,注解处理器还可以用于修改已有的Java源文件(不推荐),或者生成新的Java源文件。下面,我将用几个案例来详细阐述注解处理器的这些功能,以及它背后的原理。
注解处理器的原理
在介绍注解处理器之前,我们先来了解一下Java编译器的工作流程。

如上图所示 出处[1],Java源代码的编译过程可分为三个步骤:
- 将源文件解析为抽象语法树;
- 调用已注册的注解处理器;
- 生成字节码。
如果在第2步调用注解处理器过程中生成了新的源文件,那么编译器将重复第1、2步,解析并且处理新生成的源文件。每次重复我们称之为一轮(Round)。
也就是说,第一轮解析、处理的是输入至编译器中的已有源文件。如果注解处理器生成了新的源文件,则开始第二轮、第三轮,解析并且处理这些新生成的源文件。当注解处理器不再生成新的源文件,编译进入最后一轮,并最终进入生成字节码的第3步。
1 | package foo; |
在上面这段代码中,我定义了一个注解@CheckGetter。它既可以用来标注类,也可以用来标注字段。此外,它和@Override相同,其生命周期被限定在源代码中。
下面我们来实现一个处理@CheckGetter注解的处理器。它将遍历被标注的类中的实例字段,并检查有没有相应的getter方法。
1 | public interface Processor { |
所有的注解处理器类都需要实现接口Processor。该接口主要有四个重要方法。其中,init方法用来存放注解处理器的初始化代码。之所以不用构造器,是因为在Java编译器中,注解处理器的实例是通过反射API生成的。也正是因为使用反射API,每个注解处理器类都需要定义一个无参数构造器。
通常来说,当编写注解处理器时,我们不声明任何构造器,并依赖于Java编译器,为之插入一个无参数构造器。而具体的初始化代码,则放入init方法之中。
在剩下的三个方法中,getSupportedAnnotationTypes方法将返回注解处理器所支持的注解类型,这些注解类型只需用字符串形式表示即可。
getSupportedSourceVersion方法将返回该处理器所支持的Java版本,通常,这个版本需要与你的Java编译器版本保持一致;而process方法则是最为关键的注解处理方法。
JDK提供了一个实现Processor接口的抽象类AbstractProcessor。该抽象类实现了init、getSupportedAnnotationTypes和getSupportedSourceVersion方法。
它的子类可以通过@SupportedAnnotationTypes和@SupportedSourceVersion注解来声明所支持的注解类型以及Java版本。
下面这段代码便是@CheckGetter注解处理器的实现。由于我使用了Java 10的编译器,因此将支持版本设置为SourceVersion.RELEASE_10。
1 | package bar; |
该注解处理器仅重写了process方法。这个方法将接收两个参数,分别代表该注解处理器所能处理的注解类型,以及囊括当前轮生成的抽象语法树的RoundEnvironment。
由于该处理器针对的注解仅有@CheckGetter一个,而且我们并不会读取注解中的值,因此第一个参数并不重要。在代码中,我直接使用了
1 | `roundEnv.getElementsAnnotatedWith(CheckGetter.class)` |
来获取所有被@CheckGetter注解的类(以及字段)。
process方法涉及各种不同类型的Element,分别指代Java程序中的各个结构。如TypeElement指代类或者接口,VariableElement指代字段、局部变量、enum常量等,ExecutableElement指代方法或者构造器。
1 | package foo; // PackageElement |
这些结构之间也有从属关系,如上面这段代码所示(出处[2])。我们可以通过TypeElement.getEnclosedElements方法,获得上面这段代码中Foo类的字段、构造器以及方法。
我们也可以通过ExecutableElement.getParameters方法,获得setA方法的参数。具体这些Element类都有哪些API,你可以参考它们的Javadoc[3]。
在将该注解处理器编译成class文件后,我们便可以将其注册为Java编译器的插件,并用来处理其他源代码。注册的方法主要有两种。第一种是直接使用javac命令的-processor参数,如下所示:
1 | $ javac -cp /CLASSPATH/TO/CheckGetterProcessor -processor bar.CheckGetterProcessor Foo.java |
第二种则是将注解处理器编译生成的class文件压缩入jar包中,并在jar包的配置文件中记录该注解处理器的包名及类名,即bar.CheckGetterProcessor。
1 | (具体路径及配置文件名为`META-INF/services/javax.annotation.processing.Processor`) |
当启动Java编译器时,它会寻找classpath路径上的jar包是否包含上述配置文件,并自动注册其中记录的注解处理器。
1 | $ javac -cp /PATH/TO/CheckGetterProcessor.jar Foo.java |
此外,我们还可以在IDE中配置注解处理器。这里我就不过多演示了,感兴趣的同学可以自行搜索。
利用注解处理器生成源代码
前面提到,注解处理器可以用来修改已有源代码或者生成源代码。
确切地说,注解处理器并不能真正地修改已有源代码。这里指的是修改由Java源代码生成的抽象语法树,在其中修改已有树节点或者插入新的树节点,从而使生成的字节码发生变化。
对抽象语法树的修改涉及了Java编译器的内部API,这部分很可能随着版本变更而失效。因此,我并不推荐这种修改方式。
如果你感兴趣的话,可以参考[Project Lombok][4]。这个项目自定义了一系列注解,并根据注解的内容来修改已有的源代码。例如它提供了@Getter和@Setter注解,能够为程序自动添加getter以及setter方法。有关对使用内部API的讨论,你可以参考[这篇博客][5],以及[Lombok的回应][6]。
用注解处理器来生成源代码则比较常用。我们以前介绍过的压力测试jcstress,以及接下来即将介绍的JMH工具,都是依赖这种方式来生成测试代码的。
1 | package foo; |
在上面这段代码中,我定义了一个注解@Adapt。这个注解将接收一个Class类型的参数value(如果注解类仅包含一个名为value的参数时,那么在使用注解时,我们可以省略value=),具体用法如这段代码所示。
1 | // Bar.java |
接下来,我们来实现一个处理@Adapt注解的处理器。该处理器将生成一个新的源文件,实现参数value所指定的接口,并且调用至被该注解所标注的方法之中。具体的实现代码比较长,建议你在网页端观看。
1 | package bar; |
在这个注解处理器实现中,我们将读取注解中的值,因此我将使用process方法的第一个参数,并通过它获得被标注方法对应的@Adapt注解中的value值。
之所以采用这种麻烦的方式,是因为value值属于Class类型。在编译过程中,被编译代码中的Class常量未必被加载进Java编译器所在的虚拟机中。因此,我们需要通过process方法的第一个参数,获得value所指向的接口的抽象语法树,并据此生成源代码。
生成源代码的方式实际上非常容易理解。我们可以通过Filer.createSourceFile方法获得一个类似于文件的概念,并通过PrintWriter将具体的内容一一写入即可。
当将该注解处理器作为插件接入Java编译器时,编译前面的test/Bar.java将生成下述代码,并且触发新一轮的编译。
1 | package test; |
注意,该注解处理器没有处理所编译的代码包名为空的情况。
总结与实践
今天我介绍了Java编译器的注解处理器。
注解处理器主要有三个用途。一是定义编译规则,并检查被编译的源文件。二是修改已有源代码。三是生成新的源代码。其中,第二种涉及了Java编译器的内部API,因此并不推荐。第三种较为常见,是OpenJDK工具jcstress,以及JMH生成测试代码的方式。
Java源代码的编译过程可分为三个步骤,分别为解析源文件生成抽象语法树,调用已注册的注解处理器,和生成字节码。如果在第2步中,注解处理器生成了新的源代码,那么Java编译器将重复第1、2步,直至不再生成新的源代码。
今天的实践环节,请实现本文的案例CheckGetterProcessor中的TODO项,处理由@CheckGetter注解的字段。
[1] http://openjdk.java.net/groups/compiler/doc/compilation-overview/index.html
[2] http://hannesdorfmann.com/annotation-processing/annotationprocessing101
[3] https://docs.oracle.com/javase/10/docs/api/javax/lang/model/element/package-summary.html
[4] https://projectlombok.org/
[5] http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
[6] http://jnb.ociweb.com/jnb/jnbJan2010.html#controversy
28 | 基准测试框架JMH(上)
作者: 郑雨迪

今天我们来聊聊性能基准测试(benchmarking)。
大家或许都看到过一些不严谨的性能测试,以及基于这些测试结果得出的令人匪夷所思的结论。
1 | static int foo() { |
举个例子,上面这段代码中的foo方法,将进行10^9次加法操作及跳转操作。
不少开发人员,包括我在介绍反射调用那一篇中所做的性能测试,都使用了下面这段代码的测量方式,即通过System.nanoTime或者System.currentTimeMillis来测量每若干个操作(如连续调用1000次foo方法)所花费的时间。
1 | public class LoopPerformanceTest { |
这种测量方式实际上过于理性化,忽略了Java虚拟机、操作系统,乃至硬件系统所带来的影响。
性能测试的坑
关于Java虚拟机所带来的影响,我们在前面的篇章中已经介绍过不少,如Java虚拟机堆空间的自适配,即时编译等。
在上面这段代码中,真正进行测试的代码(即// measurement后的代码)由于循环次数不多,属于冷循环,没有能触发OSR编译。
也就是说,我们会在main方法中解释执行,然后调用foo方法即时编译生成的机器码中。这种混杂了解释执行以及即时编译生成代码的测量方式,其得到的数据含义不明。
有同学认为,我们可以假设foo方法耗时较长(毕竟10^9次加法),因此main方法的解释执行并不会对最终计算得出的性能数据造成太大影响。上面这段代码在我的机器上测出的结果是,每1000次foo方法调用在20微秒左右。
这是否意味着,我这台机器的CPU已经远超它的物理限制,其频率达到100,000,000 GHz了。(假设循环主体就两条指令,每时钟周期指令数[1]为1。)这显然是不可能的,目前CPU单核的频率大概在2-5 GHz左右,再怎么超频也不可能提升七八个数量级。
你应该能够猜到,这和即时编译器的循环优化有关。下面便是foo方法的编译结果。我们可以看到,它将直接返回10^9,而不是循环10^9次,并在循环中重复进行加法。
1 | 0x8aa0: sub rsp,0x18 // 创建方法栈桢 |
之前我忘记解释所谓的”无关指令“是什么意思。我指的是该指令和具体的代码逻辑无关。即时编译器生成的代码可能会将RBP寄存器作为通用寄存器,从而是寄存器分配算法有更多的选择。由于调用者(caller)未必保存了RBP寄存器的值,所以即时编译器会在进入被调用者(callee)时保存RBP的值,并在退出被调用者时复原RBP的值。
1 | static int foo() { |
该循环优化并非循环展开。在默认情况下,即时编译器仅能将循环展开60次(对应虚拟机参数-XX:LoopUnrollLimit)。实际上,在介绍循环优化那篇文章中,我并没有提及这个优化。因为该优化实在是太过于简单,几乎所有开发人员都能够手工对其进行优化。
在即时编译器中,它是一个基于计数循环的优化。我们也已经学过计数循环的知识。也就是说,只要将循环变量i改为long类型,便可以“避免”这个优化。
关于操作系统和硬件系统所带来的影响,一个较为常见的例子便是电源管理策略。在许多机器,特别是笔记本上,操作系统会动态配置CPU的频率。而CPU的频率又直接影响到性能测试的数据,因此短时间的性能测试得出的数据未必可靠。

例如我的笔记本,在刚开始进行性能评测时,单核频率可以达到 4.0 GHz。而后由于CPU温度升高,频率便被限制在3.0 GHz了。
除了电源管理之外,CPU缓存、分支预测器[2],以及超线程技术[3],都会对测试结果造成影响。
就CPU缓存而言,如果程序的数据本地性较好,那么它的性能指标便会非常好;如果程序存在false sharing的问题,即几个线程写入内存中属于同一缓存行的不同部分,那么它的性能指标便会非常糟糕。
超线程技术是另一个可能误导性能测试工具的因素。我们知道,超线程技术将为每个物理核心虚拟出两个虚拟核心,从而尽可能地提高物理核心的利用率。如果性能测试的两个线程被安排在同一物理核心上,那么得到的测试数据显然要比被安排在不同物理核心上的数据糟糕得多。
总而言之,性能基准测试存在着许多深坑(pitfall)。然而,除了性能测试专家外,大多数开发人员都没有足够全面的知识,能够绕开这些坑,因而得出的性能测试数据很有可能是有偏差的(biased)。
下面我将介绍OpenJDK中的开源项目 JMH[4](Java Microbenchmark Harness)。JMH是一个面向Java语言或者其他Java虚拟机语言的性能基准测试框架。它针对的是纳秒级别(出自官网介绍,个人觉得精确度没那么高)、微秒级别、毫秒级别,以及秒级别的性能测试。
由于许多即时编译器的开发人员参与了该项目,因此JMH内置了许多功能来控制即时编译器的优化。对于其他影响性能评测的因素,JMH也提供了不少策略来降低影响,甚至是彻底解决。
因此,使用这个性能基准测试框架的开发人员,可以将精力完全集中在所要测试的业务逻辑,并以最小的代价控制除了业务逻辑之外的可能影响性能的因素。
1 | REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial experiments, perform baseline and negative tests that provide experimental control, make sure the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts. Do not assume the numbers tell you what you want them to tell. |
不过,JMH也不能完美解决性能测试数据的偏差问题。它甚至会在每次运行的输出结果中打印上述语句,所以,JMH的开发人员也给出了一个小忠告:我们开发人员不要轻信JMH的性能测试数据,不要基于这些数据乱下结论。
通常来说,性能基准测试的结果反映的是所测试的业务逻辑在所运行的Java虚拟机,操作系统,硬件系统这一组合上的性能指标,而根据这些性能指标得出的通用结论则需要经过严格论证。
在理解(或忽略)了JMH的忠告后,我们下面便来看看如何使用JMH。
生成JMH项目
JMH的使用方式并不复杂。我们可以借助JMH部署在maven上的archetype,生成预设好依赖关系的maven项目模板。具体的命令如下所示:
1 | $ mvn archetype:generate \ |
该命令将在当前目录下生成一个test文件夹(对应参数-DartifactId=test,可更改),其中便包含了定义该maven项目依赖的pom.xml文件,以及自动生成的测试文件src/main/org/sample/MyBenchmark.java(这里org/sample对应参数-DgroupId=org.sample,可更改)。后者的内容如下所示:
1 | /* |
这里面,类名MyBenchmark以及方法名testMethod并不重要,你可以随意更改。真正重要的是@Benchmark注解。被它标注的方法,便是JMH基准测试的测试方法。该测试方法默认是空的。我们可以填入需要进行性能测试的业务逻辑。
举个例子,我们可以测量新建异常对象的性能,如下述代码所示:
1 | @Benchmark |
通常来说,我们不应该使用这种貌似会被即时编译器优化掉的代码(在下篇中我会介绍JMH的Blackhole功能)。
不过,我们已经学习过逃逸分析了,知道native方法调用的调用者或者参数会被识别为逃逸。而Exception的构造器将间接调用至native方法fillInStackTrace中,并且该方法调用的调用者便是新建的Exception对象。因此,逃逸分析将判定该新建对象逃逸,而即时编译器也无法优化掉原本的新建对象操作。
当Exception的构造器返回时,Java虚拟机将不再拥有指向这一新建对象的引用。因此,该新建对象可以被垃圾回收。
编译和运行JMH项目
在上一篇介绍注解处理器时,我曾提到过,JMH正是利用注解处理器[5]来自动生成性能测试的代码。实际上,除了@Benchmark之外,JMH的注解处理器还将处理所有位于org.openjdk.jmh.annotations包[6]下的注解。(其他注解我们会在下一篇中详细介绍。)
我们可以运行mvn compile命令来编译这个maven项目。该命令将生成target文件夹,其中的generated-sources目录便存放着由JMH的注解处理器所生成的Java源代码:
1 | $ mvn compile |
在这些源代码里,所有以MyBenchmark_jmhType为前缀的Java类都继承自MyBenchmark。这是注解处理器的常见用法,即通过生成子类来将注解所带来的额外语义扩张成方法。
具体来说,它们之间的继承关系是MyBenchmark_jmhType -> B3 -> B2 -> B1 -> MyBenchmark(这里A -> B代表A继承B)。其中,B2存放着JMH用来控制基准测试的各项字段。
为了避免这些控制字段对MyBenchmark类中的字段造成false sharing的影响,JMH生成了B1和B3,分别存放了256个boolean字段,从而避免B2中的字段与MyBenchmark类、MyBenchmark_jmhType类中的字段(或内存里下一个对象中的字段)会出现在同一缓存行中。
之所以不能在同一类中安排这些字段,是因为Java虚拟机的字段重排列。而类之间的继承关系,便可以避免不同类所包含的字段之间的重排列。
除了这些jmhType源代码外,generated-sources目录还存放着真正的性能测试代码MyBenchmark_testMethod_jmhTest.java。当进行性能测试时,Java虚拟机所运行的代码很有可能便是这一个源文件中的热循环经过OSR编译过后的代码。
在通过CompileCommand分析即时编译后的机器码时,我们需要关注的其实是
MyBenchmark_testMethod_jmhTest中的方法。
由于这里面的内容过于复杂,我将在下一篇中介绍影响该生成代码的众多功能性注解,这里就不再详细进行介绍了。
接下来,我们可以运行mvn package命令,将编译好的class文件打包成jar包。生成的jar包同样位于target目录下,其名字为benchmarks.jar。jar包里附带了一系列配置文件,如下所示:
1 | $ mvn package |
这里我展示了其中三个比较重要的配置文件。
MANIFEST.MF中指定了该jar包的默认入口,即org.openjdk.jmh.Main[7]。BenchmarkList中存放了测试配置。该配置是根据MyBenchmark.java里的注解自动生成的,具体我会在下一篇中详细介绍源代码中如何配置。CompilerHints中存放了传递给Java虚拟机的-XX:CompileCommandFile参数的内容。它规定了无法内联以及必须内联的几个方法,其中便有存放业务逻辑的测试方法testMethod。
在编译MyBenchmark_testMethod_jmhTest类中的测试方法时,JMH会让即时编译器强制内联对MyBenchmark.testMethod的方法调用,以避免调用开销。
打包生成的jar包可以直接运行。具体指令如下所示:
1 | $ java -jar target/benchmarks.jar |
这里JMH会有非常多的输出,具体内容我会在下一篇中进行讲解。
输出的最后便是本次基准测试的结果。其中比较重要的两项指标是Score和Error,分别代表本次基准测试的平均吞吐量(每秒运行testMethod方法的次数)以及误差范围。例如,这里的结果说明本次基准测试平均每秒生成10^6个异常实例,误差范围大致在4000个异常实例。
总结与实践
今天我介绍了OpenJDK的性能基准测试项目JMH。
Java程序的性能测试存在着许多深坑,有来自Java虚拟机的,有来自操作系统的,甚至有来自硬件系统的。如果没有足够的知识,那么性能测试的结果很有可能是有偏差的。
性能基准测试框架JMH是OpenJDK中的其中一个开源项目。它内置了许多功能,来规避由Java虚拟机中的即时编译器或者其他优化对性能测试造成的影响。此外,它还提供了不少策略来降低来自操作系统以及硬件系统的影响。
开发人员仅需将所要测试的业务逻辑通过@Benchmark注解,便可以让JMH的注解处理器自动生成真正的性能测试代码,以及相应的性能测试配置文件。
今天的实践环节,请生成一个JMH项目,并且在MyBenchmark.testMethod方法中填入自己的业务逻辑。(除非你已经提前了解@State等JMH功能,否则请不要在MyBenchmark中定义实例变量。)
[1] https://en.wikipedia.org/wiki/Instructions_per_cycle
[2] https://en.wikipedia.org/wiki/Branch_predictor
[3] https://en.wikipedia.org/wiki/Hyper-threading
[4] http://openjdk.java.net/projects/code-tools/jmh/
29 | 基准测试框架JMH(下)
作者: 郑雨迪

今天我们来继续学习基准测试框架JMH。
@Fork和@BenchmarkMode
在上一篇的末尾,我们已经运行过由JMH项目编译生成的jar包了。下面是它的输出结果:
1 | $ java -jar target/benchmarks.jar |
在上面这段输出中,我们暂且忽略最开始的Warning以及打印出来的配置信息,直接看接下来貌似重复的五段输出。
1 | # Run progress: 0,00% complete, ETA 00:08:20 |
你应该已经留意到Fork: 1 of 5的字样。这里指的是JMH会Fork出一个新的Java虚拟机,来运行性能基准测试。
之所以另外启动一个Java虚拟机进行性能基准测试,是为了获得一个相对干净的虚拟机环境。
在介绍反射的那篇文章中,我就已经演示过因为类型profile被污染,而导致无法内联的情况。使用新的虚拟机,将极大地降低被上述情况干扰的可能性,从而保证更加精确的性能数据。
在介绍虚方法内联的那篇文章中,我讲解过基于类层次分析的完全内联。新启动的Java虚拟机,其加载的与测试无关的抽象类子类或接口实现相对较少。因此,具体是否进行完全内联将交由开发人员来决定。
关于这种情况,JMH提供了一个性能测试案例[1]。如果你感兴趣的话,可以下载下来自己跑一遍。
除了对即时编译器的影响之外,Fork出新的Java虚拟机还会提升性能数据的准确度。
这主要是因为不少Java虚拟机的优化会带来不确定性,例如TLAB内存分配(TLAB的大小会变化),偏向锁、轻量锁算法,并发数据结构等。这些不确定性都可能导致不同Java虚拟机中运行的性能测试的结果不同,例如JMH这一性能的测试案例[2]。
在这种情况下,通过运行更多的Fork,并将每个Java虚拟机的性能测试结果平均起来,可以增强最终数据的可信度,使其误差更小。在JMH中,你可以通过@Fork注解来配置,具体如下述代码所示:
1 | @Fork(10) |
让我们回到刚刚的输出结果。每个Fork包含了5个预热迭代(warmup iteration,如# Warmup Iteration 1: 1023500,647 ops/s)以及5个测试迭代(measurement iteration,如Iteration 1: 1010251,342 ops/s)。
每个迭代后都跟着一个数据,代表本次迭代的吞吐量,也就是每秒运行了多少次操作(operations/s,或ops/s)。默认情况下,一次操作指的是调用一次测试方法testMethod。
除了吞吐量之外,我们还可以输出其他格式的性能数据,例如运行一次操作的平均时间。具体的配置方法以及对应参数如下述代码以及下表所示:
1 | @BenchmarkMode(Mode.AverageTime) |
一般来说,默认使用的吞吐量已足够满足大多数测试需求了。
@Warmup和@Measurement
之所以区分预热迭代和测试迭代,是为了在记录性能数据之前,将Java虚拟机带至一个稳定状态。
这里的稳定状态,不仅包括测试方法被即时编译成机器码,还包括Java虚拟机中各种自适配优化算法能够稳定下来,如前面提到的TLAB大小,亦或者是使用传统垃圾回收器时的Eden区、Survivor区和老年代的大小。
一般来说,预热迭代的数目以及每次预热迭代的时间,需要由你根据所要测试的业务逻辑代码来调配。通常的做法便是在首次运行时配置较多次迭代,并监控性能数据达到稳定状态时的迭代数目。
不少性能评测框架都会自动检测稳定状态。它们所采用的算法是计算迭代之间的差值,如果连续几个迭代与前一迭代的差值均小于某个值,便将这几个迭代以及之后的迭代当成稳定状态。
这种做法有一个缺陷,那便是在达到最终稳定状态前,程序可能拥有多个中间稳定状态。例如通过Java上的JavaScript引擎Nashorn运行JavaScript代码,便可能出现多个中间稳定状态的情况。(具体可参考Aleksey Shipilev的devoxx 2013演讲[3]的第21页。)
总而言之,开发人员需要自行决定预热迭代的次数以及每次迭代的持续时间。
通常来说,我会在保持5-10个预热迭代的前提下(这样可以看出是否达到稳定状况),将总的预热时间优化至最少,以便节省性能测试的机器时间。(这在持续集成/回归测试的硬件资源跟不上代码提交速度的团队中非常重要。)
当确定了预热迭代的次数以及每次迭代的持续时间之后,我们便可以通过@Warmup注解来进行配置,如下述代码所示:
1 | @Warmup(iterations=10, time=100, timeUnit=TimeUnit.MILLISECONDS, batchSize=10) |
@Warmup注解有四个参数,分别为预热迭代的次数iterations,每次迭代持续的时间time和timeUnit(前者是数值,后者是单位。例如上面代码代表的是每次迭代持续100毫秒),以及每次操作包含多少次对测试方法的调用batchSize。
测试迭代可通过@Measurement注解来进行配置。它的可配置选项和@Warmup的一致,这里就不再重复了。与预热迭代不同的是,每个Fork中测试迭代的数目越多,我们得到的性能数据也就越精确。
@State、@Setup和@TearDown
通常来说,我们所要测试的业务逻辑只是整个应用程序中的一小部分,例如某个具体的web app请求。这要求在每次调用测试方法前,程序处于准备接收请求的状态。
我们可以把上述场景抽象一下,变成程序从某种状态到另一种状态的转换,而性能测试,便是在收集该转换的性能数据。
JMH提供了@State注解,被它标注的类便是程序的状态。由于JMH将负责生成这些状态类的实例,因此,它要求状态类必须拥有无参数构造器,以及当状态类为内部类时,该状态类必须是静态的。
JMH还将程序状态细分为整个虚拟机的程序状态,线程私有的程序状态,以及线程组私有的程序状态,分别对应@State注解的参数Scope.Benchmark,Scope.Thread和Scope.Group。
需要注意的是,这里的线程组并非JDK中的那个概念,而是JMH自己定义的概念。具体可以参考@GroupThreads注解[4],以及这个案例[5]。
@State的配置方法以及状态类的用法如下所示:
1 | public class MyBenchmark { |
我们可以看到,状态类是通过方法参数的方式传入测试方法之中的。JMH将负责把所构造的状态类实例传入该方法之中。
不过,如果MyBenchmark被标注为@State,那么我们可以不用在测试方法中定义额外的参数,而是直接访问MyBenchmark类中的实例变量。
和JUnit测试一样,我们可以在测试前初始化程序状态,在测试后校验程序状态。这两种操作分别对应@Setup和@TearDown注解,被它们标注的方法必须是状态类中的方法。
而且,JMH并不限定状态类中@Setup方法以及@TearDown方法的数目。当存在多个@Setup方法或者@TearDown方法时,JMH将按照定义的先后顺序执行。
JMH对@Setup方法以及@TearDown方法的调用时机是可配置的。可供选择的粒度有在整个性能测试前后调用,在每个迭代前后调用,以及在每次调用测试方法前后调用。其中,最后一个粒度将影响测试数据的精度。
这三种粒度分别对应@Setup和@TearDown注解的参数Level.Trial,Level.Iteration,以及Level.Invocation。具体的用法如下所示:
1 | public class MyBenchmark { |
即时编译相关功能
JMH还提供了不少控制即时编译的功能,例如可以控制每个方法内联与否的@CompilerControl注解[6]。
另外一个更小粒度的功能则是Blackhole类。它里边的consume方法可以防止即时编译器将所传入的值给优化掉。
具体的使用方法便是为被@Benchmark注解标注了的测试方法增添一个类型为Blackhole的参数,并且在测试方法的代码中调用其实例方法Blackhole.consume,如下述代码所示:
1 | @Benchmark |
需要注意的是,它并不会阻止对传入值的计算的优化。举个例子,在下面这段代码中,我将3+4的值传入Blackhole.consume方法中。即时编译器仍旧会进行常量折叠,而Blackhole将阻止即时编译器把所得到的常量值7给优化消除掉。
1 | @Benchmark |
除了防止死代码消除的consume之外,Blackhole类还提供了一个静态方法consumeCPU,来消耗CPU时间。该方法将接收一个long类型的参数,这个参数与所消耗的CPU时间呈线性相关。
总结与实践
今天我介绍了基准测试框架JMH的进阶功能。我们来回顾一下。
@Fork允许开发人员指定所要Fork出的Java虚拟机的数目。@BenchmarkMode允许指定性能数据的格式。@Warmup和@Measurement允许配置预热迭代或者测试迭代的数目,每个迭代的时间以及每个操作包含多少次对测试方法的调用。@State允许配置测试程序的状态。测试前对程序状态的初始化以及测试后对程序状态的恢复或者校验可分别通过@Setup和@TearDown来实现。
今天的实践环节,请逐个运行JMH的官方案例[7],具体每个案例的意义都在代码注释之中。
最后给大家推荐一下Aleksey Shipilev的devoxx 2013演讲(Slides[8];视频[9],请自备梯子)。如果你已经完成本专栏前面两部分,特别是第二部分的学习,那么这个演讲里的绝大部分内容你应该都能理解。
[3] https://shipilev.net/talks/devoxx-Nov2013-benchmarking.pdf
[8] https://shipilev.net/talks/devoxx-Nov2013-benchmarking.pdf
[9] https://www.youtube.com/watch?v=VaWgOCDBxYw
30 | Java虚拟机的监控及诊断工具(命令行篇)
作者: 郑雨迪

今天,我们来一起了解一下JDK中用于监控及诊断工具。本篇中我将使用刚刚发布的Java 11版本的工具进行示范。
jps
你可能用过ps命令,打印所有正在运行的进程的相关信息。JDK中的jps命令(帮助文档)沿用了同样的概念:它将打印所有正在运行的Java进程的相关信息。
在默认情况下,jps的输出信息包括Java进程的进程ID以及主类名。我们还可以通过追加参数,来打印额外的信息。例如,-l将打印模块名以及包名;-v将打印传递给Java虚拟机的参数(如-XX:+UnlockExperimentalVMOptions -XX:+UseZGC);-m将打印传递给主类的参数。
具体的示例如下所示:
1 | $ jps -mlv |
需要注意的是,如果某Java进程关闭了默认开启的UsePerfData参数(即使用参数-XX:-UsePerfData),那么jps命令(以及下面介绍的jstat)将无法探知该Java进程。
当获得Java进程的进程ID之后,我们便可以调用接下来介绍的各项监控及诊断工具了。
jstat
jstat命令(帮助文档)可用来打印目标Java进程的性能数据。它包括多条子命令,如下所示:
1 | $ jstat -options |
在这些子命令中,-class将打印类加载相关的数据,-compiler和-printcompilation将打印即时编译相关的数据。剩下的都是以-gc为前缀的子命令,它们将打印垃圾回收相关的数据。
默认情况下,jstat只会打印一次性能数据。我们可以将它配置为每隔一段时间打印一次,直至目标Java进程终止,或者达到我们所配置的最大打印次数。具体示例如下所示:
1 | # Usage: jstat -outputOptions [-t] [-hlines] VMID [interval [count]] |
当监控本地环境的Java进程时,VMID可以简单理解为PID。如果需要监控远程环境的Java进程,你可以参考jstat的帮助文档。
在上面这个示例中,22126进程是一个使用了CMS垃圾回收器的Java进程。我们利用jstat的-gc子命令,来打印该进程垃圾回收相关的数据。命令最后的1s 4表示每隔1秒打印一次,共打印4次。
在-gc子命令的输出中,前四列分别为两个Survivor区的容量(Capacity)和已使用量(Utility)。我们可以看到,这两个Survivor区的容量相等,而且始终有一个Survivor区的内存使用量为0。
当使用默认的G1 GC时,输出结果则有另一些特征:
1 | $ jstat -gc 22208 1s |
在上面这个示例中,jstat每隔1s便会打印垃圾回收的信息,并且不断重复下去。
你可能已经留意到,S0C和S0U始终为0,而且另一个Survivor区的容量(S1C)可能会下降至0。
这是因为,当使用G1 GC时,Java虚拟机不再设置Eden区、Survivor区,老年代区的内存边界,而是将堆划分为若干个等长内存区域。
每个内存区域都可以作为Eden区、Survivor区以及老年代区中的任一种,并且可以在不同区域类型之间来回切换。(参考链接)
换句话说,逻辑上我们只有一个Survivor区。当需要迁移Survivor区中的数据时(即Copying GC),我们只需另外申请一个或多个内存区域,作为新的Survivor区。
因此,Java虚拟机决定在使用G1 GC时,将所有Survivor内存区域的总容量以及已使用量存放至S1C和S1U中,而S0C和S0U则被设置为0。
当发生垃圾回收时,Java虚拟机可能出现Survivor内存区域内的对象全被回收或晋升的现象。
在这种情况下,Java虚拟机会将这块内存区域回收,并标记为可分配的状态。这样子做的结果是,堆中可能完全没有Survivor内存区域,因而相应的S1C和S1U将会是0。
jstat还有一个非常有用的参数-t,它将在每行数据之前打印目标Java进程的启动时间。例如,在下面这个示例中,第一列代表该Java进程已经启动了10.7秒。
1 | $ jstat -gc -t 22407 |
我们可以比较Java进程的启动时间以及总GC时间(GCT列),或者两次测量的间隔时间以及总GC时间的增量,来得出GC时间占运行时间的比例。
如果该比例超过20%,则说明目前堆的压力较大;如果该比例超过90%,则说明堆里几乎没有可用空间,随时都可能抛出OOM异常。
jstat还可以用来判断是否出现内存泄漏。在长时间运行的Java程序中,我们可以运行jstat命令连续获取多行性能数据,并取这几行数据中OU列(即已占用的老年代内存)的最小值。
然后,我们每隔一段较长的时间重复一次上述操作,来获得多组OU最小值。如果这些值呈上涨趋势,则说明该Java程序的老年代内存已使用量在不断上涨,这意味着无法回收的对象在不断增加,因此很有可能存在内存泄漏。
上面没有涉及的列(或者其他子命令的输出),你可以查阅帮助文档了解具体含义。至于文档中漏掉的CGC和CGCT,它们分别代表并发GC Stop-The-World的次数和时间。
jmap
在这种情况下,我们便可以请jmap命令(帮助文档)出马,分析Java虚拟机堆中的对象。
jmap同样包括多条子命令。
-clstats,该子命令将打印被加载类的信息。-finalizerinfo,该子命令将打印所有待finalize的对象。-histo,该子命令将统计各个类的实例数目以及占用内存,并按照内存使用量从多至少的顺序排列。此外,-histo:live只统计堆中的存活对象。-dump,该子命令将导出Java虚拟机堆的快照。同样,-dump:live只保存堆中的存活对象。
我们通常会利用jmap -dump:live,format=b,file=filename.bin命令,将堆中所有存活对象导出至一个文件之中。
这里format=b将使jmap导出与hprof(在Java 9中已被移除)、-XX:+HeapDumpAfterFullGC、-XX:+HeapDumpOnOutOfMemoryError格式一致的文件。这种格式的文件可以被其他GUI工具查看,具体我会在下一篇中进行演示。
下面我贴了一段-histo子命令的输出:
1 | $ jmap -histo 22574 |
由于jmap将访问堆中的所有对象,为了保证在此过程中不被应用线程干扰,jmap需要借助安全点机制,让所有线程停留在不改变堆中数据的状态。
也就是说,由jmap导出的堆快照必定是安全点位置的。这可能导致基于该堆快照的分析结果存在偏差。举个例子,假设在编译生成的机器码中,某些对象的生命周期在两个安全点之间,那么:live选项将无法探知到这些对象。
另外,如果某个线程长时间无法跑到安全点,jmap将一直等下去。上一小节的jstat则不同。这是因为垃圾回收器会主动将jstat所需要的摘要数据保存至固定位置之中,而jstat只需直接读取即可。
关于这种长时间等待的情况,你可以通过下面这段程序来复现:
1 | // 暂停时间较长,约为二三十秒,可酌情调整。 |
jmap(以及接下来的jinfo、jstack和jcmd)依赖于Java虚拟机的Attach API,因此只能监控本地Java进程。
一旦开启Java虚拟机参数DisableAttachMechanism(即使用参数-XX:+DisableAttachMechanism),基于Attach API的命令将无法执行。反过来说,如果你不想被其他进程监控,那么你需要开启该参数。
jinfo
jinfo命令(帮助文档)可用来查看目标Java进程的参数,如传递给Java虚拟机的-X(即输出中的jvm_args)、-XX参数(即输出中的VM Flags),以及可在Java层面通过System.getProperty获取的-D参数(即输出中的System Properties)。
具体的示例如下所示:
1 | $ jinfo 31185 |
jinfo还可以用来修改目标Java进程的“manageable”虚拟机参数。
举个例子,我们可以使用jinfo -flag +HeapDumpAfterFullGC <PID>命令,开启<PID>所指定的Java进程的HeapDumpAfterFullGC参数。
你可以通过下述命令查看其他”manageable”虚拟机参数:
1 | $ java -XX:+PrintFlagsFinal -version | grep manageable |
jstack
jstack命令(帮助文档)可以用来打印目标Java进程中各个线程的栈轨迹,以及这些线程所持有的锁。
jstack的其中一个应用场景便是死锁检测。这里我用jstack获取一个已经死锁了的Java程序的栈信息。具体输出如下所示:
1 | $ jstack 31634 |
我们可以看到,jstack不仅会打印线程的栈轨迹、线程状态(BLOCKED)、持有的锁(locked …)以及正在请求的锁(waiting to lock …),而且还会分析出具体的死锁。
jcmd
你还可以直接使用jcmd命令(帮助文档),来替代前面除了jstat之外的所有命令。具体的替换规则你可以参考下表。
至于jstat的功能,虽然jcmd复制了jstat的部分代码,并支持通过PerfCounter.print子命令来打印所有的Performance Counter,但是它没有保留jstat的输出格式,也没有重复打印的功能。因此,感兴趣的同学可以自行整理。
另外,我们将在下一篇中介绍jcmd中Java Flight Recorder相关的子命令。
总结与实践
今天我介绍了JDK中用于监控及诊断的命令行工具。我们再来回顾一下。
jps将打印所有正在运行的Java进程。jstat允许用户查看目标Java进程的类加载、即时编译以及垃圾回收相关的信息。它常用于检测垃圾回收问题以及内存泄漏问题。jmap允许用户统计目标Java进程的堆中存放的Java对象,并将它们导出成二进制文件。jinfo将打印目标Java进程的配置参数,并能够改动其中manageabe的参数。jstack将打印目标Java进程中各个线程的栈轨迹、线程状态、锁状况等信息。它还将自动检测死锁。jcmd则是一把瑞士军刀,可以用来实现前面除了jstat之外所有命令的功能。
今天的实践环节,你可以探索jcmd中的下述功能,看看有没有适合你项目的监控项:
1 | Compiler.CodeHeap_Analytics |
31 | Java虚拟机的监控及诊断工具(GUI篇)
作者: 郑雨迪

今天我们来继续了解Java虚拟机的监控及诊断工具。
eclipse MAT
在上一篇中,我介绍了jmap工具,它支持导出Java虚拟机堆的二进制快照。eclipse的MAT工具便是其中一个能够解析这类二进制快照的工具。
MAT本身也能够获取堆的二进制快照。该功能将借助jps列出当前正在运行的Java进程,以供选择并获取快照。由于jps会将自己列入其中,因此你会在列表中发现一个已经结束运行的jps进程。
MAT获取二进制快照的方式有三种,一是使用Attach API,二是新建一个Java虚拟机来运行Attach API,三是使用jmap工具。
这三种本质上都是在使用Attach API。不过,在目标进程启用了DisableAttachMechanism参数时,前两者将不在选取列表中显示,后者将在运行时报错。
当加载完堆快照之后,MAT的主界面将展示一张饼状图,其中列举占据的Retained heap最多的几个对象。
这里讲一下MAT计算对象占据内存的两种方式。第一种是Shallow heap,指的是对象自身所占据的内存。第二种是Retained heap,指的是当对象不再被引用时,垃圾回收器所能回收的总内存,包括对象自身所占据的内存,以及仅能够通过该对象引用到的其他对象所占据的内存。上面的饼状图便是基于Retained heap的。
MAT包括了两个比较重要的视图,分别是直方图(histogram)和支配树(dominator tree)。

MAT的直方图和jmap的-histo子命令一样,都能够展示各个类的实例数目以及这些实例的Shallow heap总和。但是,MAT的直方图还能够计算Retained heap,并支持基于实例数目或Retained heap的排序方式(默认为Shallow heap)。此外,MAT还可以将直方图中的类按照超类、类加载器或者包名分组。
当选中某个类时,MAT界面左上角的Inspector窗口将展示该类的Class实例的相关信息,如类加载器等。(下图中的ClassLoader @ 0x0指的便是启动类加载器。)

支配树的概念源自图论。在一则流图(flow diagram)中,如果从入口节点到b节点的所有路径都要经过a节点,那么a支配(dominate)b。
在a支配b,且a不同于b的情况下(即a严格支配b),如果从a节点到b节点的所有路径中不存在支配b的其他节点,那么a直接支配(immediate dominate)b。这里的支配树指的便是由节点的直接支配节点所组成的树状结构。
我们可以将堆中所有的对象看成一张对象图,每个对象是一个图节点,而GC Roots则是对象图的入口,对象之间的引用关系则构成了对象图中的有向边。这样一来,我们便能够构造出该对象图所对应的支配树。
MAT将按照每个对象Retained heap的大小排列该支配树。如下图所示:

根据Retained heap的定义,只要能够回收上图右侧的表中的第一个对象,那么垃圾回收器便能够释放出13.6MB内存。
需要注意的是,对象的引用型字段未必对应支配树中的父子节点关系。假设对象a拥有两个引用型字段,分别指向b和c。而b和c各自拥有一个引用型字段,但都指向d。如果没有其他引用指向b、c或d,那么a直接支配b、c和d,而b(或c)和d之间不存在支配关系。
当在支配树视图中选中某一对象时,我们还可以通过Path To GC Roots功能,反向列出该对象到GC Roots的引用路径。如下图所示:

MAT还将自动匹配内存泄漏中的常见模式,并汇报潜在的内存泄漏问题。具体可参考该帮助文档以及这篇博客。
Java Mission Control
注意:自Java 11开始,本节介绍的JFR已经开源。但在之前的Java版本,JFR属于Commercial Feature,需要通过Java虚拟机参数
-XX:+UnlockCommercialFeatures开启。我个人不清楚也不能回答关于Java 11之前的版本是否仍需要商务许可(Commercial License)的问题。请另行咨询后再使用,或者直接使用Java 11。
Java Mission Control(JMC)是Java虚拟机平台上的性能监控工具。它包含一个GUI客户端,以及众多用来收集Java虚拟机性能数据的插件,如JMX Console(能够访问用来存放虚拟机各个子系统运行数据的MXBeans),以及虚拟机内置的高效profiling工具Java Flight Recorder(JFR)。
JFR的性能开销很小,在默认配置下平均低于1%。与其他工具相比,JFR能够直接访问虚拟机内的数据,并且不会影响虚拟机的优化。因此,它非常适用于生产环境下满负荷运行的Java程序。
当启用时,JFR将记录运行过程中发生的一系列事件。其中包括Java层面的事件,如线程事件、锁事件,以及Java虚拟机内部的事件,如新建对象、垃圾回收和即时编译事件。
按照发生时机以及持续时间来划分,JFR的事件共有四种类型,它们分别为以下四种。
- 瞬时事件(Instant Event),用户关心的是它们发生与否,例如异常、线程启动事件。
- 持续事件(Duration Event),用户关心的是它们的持续时间,例如垃圾回收事件。
- 计时事件(Timed Event),是时长超出指定阈值的持续事件。
- 取样事件(Sample Event),是周期性取样的事件。
取样事件的其中一个常见例子便是方法抽样(Method Sampling),即每隔一段时间统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法。
JFR的取样事件要比其他工具更加精确。以方法抽样为例,其他工具通常基于JVMTI(Java Virtual Machine Tool Interface)的GetAllStackTraces API。该API依赖于安全点机制,其获得的栈轨迹总是在安全点上,由此得出的结论未必精确。JFR则不然,它不依赖于安全点机制,因此其结果相对来说更加精确。
JFR的启用方式主要有三种。
第一种是在运行目标Java程序时添加-XX:StartFlightRecording=参数。关于该参数的配置详情,你可以参考该帮助文档(请在页面中搜索StartFlightRecording)。
下面我列举三种常见的配置方式。
- 在下面这条命令中,JFR将会在Java虚拟机启动5s后(对应
delay=5s)收集数据,持续20s(对应duration=20s)。当收集完毕后,JFR会将收集得到的数据保存至指定的文件中(对应filename=myrecording.jfr)。
1 | # Time fixed |
settings=profile指定了JFR所收集的事件类型。默认情况下,JFR将加载配置文件$JDK/lib/jfr/default.jfc,并识别其中所包含的事件类型。当使用了settings=profile配置时,JFR将加载配置文件$JDK/lib/jfr/profile.jfc。该配置文件所包含的事件类型要多于默认的default.jfc,因此性能开销也要大一些(约为2%)。
default.jfc以及profile.jfc均为XML文件。后面我会介绍如何利用JMC来进行修改。
- 在下面这条命令中,JFR将在Java虚拟机启动之后持续收集数据,直至进程退出。在进程退出时(对应
dumponexit=true),JFR会将收集得到的数据保存至指定的文件中。
1 | # Continuous, dump on exit |
- 在下面这条命令中,JFR将在Java虚拟机启动之后持续收集数据,直至进程退出。该命令不会主动保存JFR收集得到的数据。
1 | # Continuous, dump on demand |
由于JFR将持续收集数据,如果不加以限制,那么JFR可能会填满硬盘的所有空间。因此,我们有必要对这种模式下所收集的数据进行限制。
在这条命令中,maxage=10m指的是仅保留10分钟以内的事件,maxsize=100m指的是仅保留100MB以内的事件。一旦所收集的事件达到其中任意一个限制,JFR便会开始清除不合规格的事件。
然而,为了保持较小的性能开销,JFR并不会频繁地校验这两个限制。因此,在实践过程中你往往会发现指定文件的大小超出限制,或者文件中所存储事件的时间超出限制。具体解释请参考这篇帖子。
前面提到,该命令不会主动保存JFR收集得到的数据。用户需要运行jcmd <PID> JFR.dump命令方能保存。
这便是JFR的第二种启用方式,即通过jcmd来让JFR开始收集数据、停止收集数据,或者保存所收集的数据,对应的子命令分别为JFR.start,JFR.stop,以及JFR.dump。
JFR.start子命令所接收的配置及格式和-XX:StartFlightRecording=参数的类似。这些配置包括delay、duration、settings、maxage、maxsize以及name。前几个参数我们都已经介绍过了,最后一个参数name就是一个标签,当同一进程中存在多个JFR数据收集操作时,我们可以通过该标签来辨别。
在启动目标进程时,我们不再添加-XX:StartFlightRecording=参数。在目标进程运行过程中,我们可以运行JFR.start子命令远程启用目标进程的JFR功能。具体用法如下所示:
1 | $ jcmd <PID> JFR.start settings=profile maxage=10m maxsize=150m name=SomeLabel |
上述命令运行过后,目标进程中的JFR已经开始收集数据。此时,我们可以通过下述命令来导出已经收集到的数据:
1 | $ jcmd <PID> JFR.dump name=SomeLabel filename=myrecording.jfr |
最后,我们可以通过下述命令关闭目标进程中的JFR:
1 | $ jcmd <PID> JFR.stop name=SomeLabel |
关于JFR.start、JFR.dump和JFR.stop的其他用法,你可以参考该帮助文档。
第三种启用JFR的方式则是JMC中的JFR插件。

在JMC GUI客户端左侧的JVM浏览器中,我们可以看到所有正在运行的Java程序。当点击右键弹出菜单中的Start Flight Recording...时,JMC便会弹出另一个窗口,用来配置JFR的启动参数,如下图所示:

这里的配置参数与前两种启动JFR的方式并无二致,同样也包括标签名、收集数据的持续时间、缓存事件的时间及空间限制,以及配置所要监控事件的Event settings。
(这里对应前两种启动方式的settings=default|profile)
JMC提供了两个选择:Continuous和Profiling,分别对应
$JDK/lib/jfr/里的default.jfc和profile.jfc。
我们可以通过JMC的Flight Recording Template Manager导入这些jfc文件,并在GUI界面上进行更改。更改完毕后,我们可以导出为新的jfc文件,以便在服务器端使用。
当收集完成时,JMC会自动打开所生成的jfr文件,并在主界面中列举目标进程在收集数据的这段时间内的潜在问题。例如,Parallel Threads一节,便汇报了没有完整利用CPU资源的问题。

客户端的左边则罗列了Java虚拟机的各个子系统。JMC将根据JFR所收集到的每个子系统的事件来进行可视化,转换成图或者表。

这里我简单地介绍其中两个。
垃圾回收子系统所对应的选项卡展示了JFR所收集到的GC事件,以及基于这些GC事件的数据生成的堆已用空间的分布图,Metaspace大小的分布图,最长暂停以及总暂停的直方分布图。

即时编译子系统所对应的选项卡则展示了方法编译时间的直方图,以及按编译时间排序的编译任务表。
后者可能出现同方法名同方法描述符的编译任务。其原因主要有两个,一是不同编译层次的即时编译,如3层的C1编译以及4层的C2编译。二是去优化后的重新编译。

JMC的图表总体而言都不难理解。你可以逐个探索,我在这里便不详细展开了。
总结与实践
今天我介绍了两个GUI工具:eclipse MAT以及JMC。
eclipse MAT可用于分析由jmap命令导出的Java堆快照。它包括两个相对比较重要的视图,分别为直方图和支配树。直方图展示了各个类的实例数目以及这些实例的Shallow heap或Retained heap的总和。支配树则展示了快照中每个对象所直接支配的对象。
Java Mission Control是Java虚拟机平台上的性能监控工具。Java Flight Recorder是JMC的其中一个组件,能够以极低的性能开销收集Java虚拟机的性能数据。
JFR的启用方式有三种,分别为在命令行中使用-XX:StartFlightRecording=参数,使用jcmd的JFR.*子命令,以及JMC的JFR插件。JMC能够加载JFR的输出结果,并且生成各种信息丰富的图表。
今天的实践环节,请你试用JMC中的MBean Server功能,并通过JMC的帮助文档(Help->Java Mission Control Help),以及该教程来了解该功能的具体含义。

由于篇幅的限制,我就不再介绍VisualVM 以及JITWatch 了。感兴趣的同学可自行下载研究。
32 | JNI的运行机制
作者: 郑雨迪

我们经常会遇见Java语言较难表达,甚至是无法表达的应用场景。比如我们希望使用汇编语言(如X86_64的SIMD指令)来提升关键代码的性能;再比如,我们希望调用Java核心类库无法提供的,某个体系架构或者操作系统特有的功能。
在这种情况下,我们往往会牺牲可移植性,在Java代码中调用C/C++代码(下面简述为C代码),并在其中实现所需功能。这种跨语言的调用,便需要借助Java虚拟机的Java Native Interface(JNI)机制。
关于JNI的例子,你应该特别熟悉Java中标记为native的、没有方法体的方法(下面统称为native方法)。当在Java代码中调用这些native方法时,Java虚拟机将通过JNI,调用至对应的C函数(下面将native方法对应的C实现统称为C函数)中。
1 | public class Object { |
举个例子,Object.hashCode方法便是一个native方法。它对应的C函数将计算对象的哈希值,并缓存在对象头、栈上锁记录(轻型锁)或对象监视锁(重型锁所使用的monitor)中,以确保该值在对象的生命周期之内不会变更。
native方法的链接
在调用native方法前,Java虚拟机需要将该native方法链接至对应的C函数上。
链接方式主要有两种。第一种是让Java虚拟机自动查找符合默认命名规范的C函数,并且链接起来。
事实上,我们并不需要记住所谓的命名规范,而是采用javac -h命令,便可以根据Java程序中的native方法声明,自动生成包含符合命名规范的C函数的头文件。
举个例子,在下面这段代码中,Foo类有三个native方法,分别为静态方法foo以及两个重载的实例方法bar。
1 | package org.example; |
通过执行javac -h . org/example/Foo.java命令,我们将在当前文件夹(对应-h后面跟着的.)生成名为org_example_Foo.h的头文件。其内容如下所示:
1 | /* DO NOT EDIT THIS FILE - it is machine generated */ |
这里我简单讲解一下该命名规范。
首先,native方法对应的C函数都需要以Java_为前缀,之后跟着完整的包名和方法名。由于C函数名不支持/字符,因此我们需要将/转换为_,而原本方法名中的_符号,则需要转换为_1。
举个例子,org.example包下Foo类的foo方法,Java虚拟机会将其自动链接至名为Java_org_example_Foo_foo的C函数中。
当某个类出现重载的native方法时,Java虚拟机还会将参数类型纳入自动链接对象的考虑范围之中。具体的做法便是在前面C函数名的基础上,追加__以及方法描述符作为后缀。
方法描述符的特殊符号同样会被替换掉,如引用类型所使用的;会被替换为_2,数组类型所使用的[会被替换为_3。
基于此命名规范,你可以手动拼凑上述代码中,Foo类的两个bar方法所能自动链接的C函数名,并用javac -h命令所生成的结果来验证一下。
第二种链接方式则是在C代码中主动链接。
这种链接方式对C函数名没有要求。通常我们会使用一个名为registerNatives的native方法,并按照第一种链接方式定义所能自动链接的C函数。在该C函数中,我们将手动链接该类的其他native方法。
举个例子,Object类便拥有一个registerNatives方法,所对应的C代码如下所示:
1 | // 注:Object类的registerNatives方法的实现位于java.base模块里的C代码中 |
我们可以看到,上面这段代码中的C函数将调用RegisterNatives API,注册Object类中其他native方法所要链接的C函数。并且,这些C函数的名字并不符合默认命名规则。
当使用第二种方式进行链接时,我们需要在其他native方法被调用之前完成链接工作。因此,我们往往会在类的初始化方法里调用该registerNatives方法。具体示例如下所示:
1 | public class Object { |
下面我们采用第一种链接方式,并且实现其中的bar(String, Object)方法。如下所示:
1 | // foo.c |
然后,我们可以通过gcc命令将其编译成为动态链接库:
1 | # 该命令仅适用于macOS |
这里需要注意的是,动态链接库的名字须以lib为前缀,以.dylib(或Linux上的.so)为扩展名。在Java程序中,我们可以通过System.loadLibrary("foo")方法来加载libfoo.dylib,如下述代码所示:
1 | package org.example; |
如果libfoo.dylib不在当前路径下,我们可以在启动Java虚拟机时配置java.library.path参数,使其指向包含libfoo.dylib的文件夹。具体命令如下所示:
1 | $ java -Djava.library.path=/PATH/TO/DIR/CONTAINING/libfoo.dylib org.example.Foo |
JNI的API
在C代码中,我们也可以使用Java的语言特性,如instanceof测试等。这些功能都是通过特殊的JNI函数(JNI Functions)来实现的。
Java虚拟机会将所有JNI函数的函数指针聚合到一个名为JNIEnv的数据结构之中。
这是一个线程私有的数据结构。Java虚拟机会为每个线程创建一个JNIEnv,并规定C代码不能将当前线程的JNIEnv共享给其他线程,否则JNI函数的正确性将无法保证。
这么设计的原因主要有两个。一是给JNI函数提供一个单独命名空间。二是允许Java虚拟机通过更改函数指针替换JNI函数的具体实现,例如从附带参数类型检测的慢速版本,切换至不做参数类型检测的快速版本。
在HotSpot虚拟机中,JNIEnv被内嵌至Java线程的数据结构之中。部分虚拟机代码甚至会从JNIEnv的地址倒推出Java线程的地址。因此,如果在其他线程中使用当前线程的JNIEnv,会使这部分代码错误识别当前线程。
JNI会将Java层面的基本类型以及引用类型映射为另一套可供C代码使用的数据结构。其中,基本类型的对应关系如下表所示:

引用类型对应的数据结构之间也存在着继承关系,具体如下所示:
1 | jobject |
我们回头看看Foo类3个native方法对应的C函数的参数。
1 | JNIEXPORT void JNICALL Java_org_example_Foo_foo |
静态native方法foo将接收两个参数,分别为存放JNI函数的JNIEnv指针,以及一个jclass参数,用来指代定义该native方法的类,即Foo类。
两个实例native方法bar的第二个参数则是jobject类型的,用来指代该native方法的调用者,也就是Foo类的实例。
如果native方法声明了参数,那么对应的C函数将接收这些参数。在我们的例子中,第一个bar方法声明了int型和long型的参数,对应的C函数则接收jint和jlong类型的参数;第二个bar方法声明了String类型和Object类型的参数,对应的C函数则接收jstring和jobject类型的参数。
下面,我们继续修改上一小节中的foo.c,并在C代码中获取Foo类实例的i字段。
1 | // foo.c |
我们可以看到,在JNI中访问字段类似于反射API:我们首先需要通过类实例获得FieldID,然后再通过FieldID获得某个实例中该字段的值。不过,与Java代码相比,上述代码貌似不用处理异常。事实果真如此吗?
下面我就尝试获取了不存在的字段j,运行结果如下所示:
1 | $ java org.example.Foo |
我们可以看到,printf语句照常执行并打印出Hello, World 0x5,但这个数值明显是错误的。当从C函数返回至main方法时,Java虚拟机又会抛出NoSuchFieldError异常。
实际上,当调用JNI函数时,Java虚拟机便已生成异常实例,并缓存在内存中的某个位置。与Java编程不一样的是,它并不会显式地跳转至异常处理器或者调用者中,而是继续执行接下来的C代码。
因此,当从可能触发异常的JNI函数返回时,我们需要通过JNI函数ExceptionOccurred检查是否发生了异常,并且作出相应的处理。如果无须抛出该异常,那么我们需要通过JNI函数ExceptionClear显式地清空已缓存的异常。
具体示例如下所示(为了控制代码篇幅,我仅在第一个GetFieldID后检查异常以及清空异常):
1 | // foo.c |
局部引用与全局引用
在C代码中,我们可以访问所传入的引用类型参数,也可以通过JNI函数创建新的Java对象。
这些Java对象显然也会受到垃圾回收器的影响。因此,Java虚拟机需要一种机制,来告知垃圾回收算法,不要回收这些C代码中可能引用到的Java对象。
这种机制便是JNI的局部引用(Local Reference)和全局引用(Global Reference)。垃圾回收算法会将被这两种引用指向的对象标记为不可回收。
事实上,无论是传入的引用类型参数,还是通过JNI函数(除NewGlobalRef及NewWeakGlobalRef之外)返回的引用类型对象,都属于局部引用。
不过,一旦从C函数中返回至Java方法之中,那么局部引用将失效。也就是说,垃圾回收器在标记垃圾时不再考虑这些局部引用。
这就意味着,我们不能缓存局部引用,以供另一C线程或下一次native方法调用时使用。
对于这种应用场景,我们需要借助JNI函数NewGlobalRef,将该局部引用转换为全局引用,以确保其指向的Java对象不会被垃圾回收。
相应的,我们还可以通过JNI函数DeleteGlobalRef来消除全局引用,以便回收被全局引用指向的Java对象。
此外,当C函数运行时间极其长时,我们也应该考虑通过JNI函数DeleteLocalRef,消除不再使用的局部引用,以便回收被引用的Java对象。
另一方面,由于垃圾回收器可能会移动对象在内存中的位置,因此Java虚拟机需要另一种机制,来保证局部引用或者全局引用将正确地指向移动过后的对象。
HotSpot虚拟机是通过句柄(handle)来完成上述需求的。这里句柄指的是内存中Java对象的指针的指针。当发生垃圾回收时,如果Java对象被移动了,那么句柄指向的指针值也将发生变动,但句柄本身保持不变。
实际上,无论是局部引用还是全局引用,都是句柄。其中,局部引用所对应的句柄有两种存储方式,一是在本地方法栈帧中,主要用于存放C函数所接收的来自Java层面的引用类型参数;另一种则是线程私有的句柄块,主要用于存放C函数运行过程中创建的局部引用。
当从C函数返回至Java方法时,本地方法栈帧中的句柄将会被自动清除。而线程私有句柄块则需要由Java虚拟机显式清理。
进入C函数时对引用类型参数的句柄化,和调整参数位置(C调用和Java调用传参的方式不一样),以及从C函数返回时清理线程私有句柄块,共同造就了JNI调用的额外性能开销(具体可参考该stackoverflow上的回答)。
总结与实践
今天我介绍了JNI的运行机制。
Java中的native方法的链接方式主要有两种。一是按照JNI的默认规范命名所要链接的C函数,并依赖于Java虚拟机自动链接。另一种则是在C代码中主动链接。
JNI提供了一系列API来允许C代码使用Java语言特性。这些API不仅使用了特殊的数据结构来表示Java类,还拥有特殊的异常处理模式。
JNI中的引用可分为局部引用和全局引用。这两者都可以阻止垃圾回收器回收被引用的Java对象。不同的是,局部引用在native方法调用返回之后便会失效。传入参数以及大部分JNI API函数的返回值都属于局部引用。
今天的实践环节,请阅读该文档中的Performance pitfalls以及Correctness pitfalls两节。
33 | Java Agent与字节码注入
作者: 郑雨迪

关于Java agent,大家可能都听过大名鼎鼎的premain方法。顾名思义,这个方法指的就是在main方法之前执行的方法。
1 | package org.example; |
我在上面这段代码中定义了一个premain方法。这里需要注意的是,Java虚拟机所能识别的premain方法接收的是字符串类型的参数,而并非类似于main方法的字符串数组。
为了能够以Java agent的方式运行该premain方法,我们需要将其打包成jar包,并在其中的MANIFEST.MF配置文件中,指定所谓的Premain-class。具体的命令如下所示:
1 | # 注意第一条命令会向manifest.txt文件写入两行数据,其中包括一行空行 |
除了在命令行中指定Java agent之外,我们还可以通过Attach API远程加载。具体用法如下面的代码所示:
1 | import java.io.IOException; |
使用Attach API远程加载的Java agent不会再先于main方法执行,这取决于另一虚拟机调用Attach API的时机。并且,它运行的也不再是premain方法,而是名为agentmain的方法。
1 | public class MyAgent { |
相应的,我们需要更新jar包中的manifest文件,使其包含Agent-Class的配置,例如Agent-Class: org.example.MyAgent。
1 | $ echo 'Agent-Class: org.example.MyAgent |
Java虚拟机并不限制Java agent的数量。你可以在java命令后附上多个-javaagent参数,或者远程attach多个Java agent,Java虚拟机会按照定义顺序,或者attach的顺序逐个执行这些Java agent。
在premain方法或者agentmain方法中打印一些字符串并不出奇,我们完全可以将其中的逻辑并入main方法,或者其他监听端口的线程中。除此之外,Java agent还提供了一套instrumentation机制,允许应用程序拦截类加载事件,并且更改该类的字节码。
接下来,我们来了解一下基于这一机制的字节码注入。
字节码注入
1 | package org.example; |
我们先来看一个例子。在上面这段代码中,premain方法多出了一个Instrumentation类型的参数,我们可以通过它来注册类加载事件的拦截器。该拦截器需要实现ClassFileTransformer接口,并重写其中的transform方法。
transform方法将接收一个byte数组类型的参数,它代表的是正在被加载的类的字节码。在上面这段代码中,我将打印该数组的前四个字节,也就是Java class文件的魔数(magic number)0xCAFEBABE。
transform方法将返回一个byte数组,代表更新过后的类的字节码。当方法返回之后,Java虚拟机会使用所返回的byte数组,来完成接下来的类加载工作。不过,如果transform方法返回null或者抛出异常,那么Java虚拟机将使用原来的byte数组完成类加载工作。
基于这一类加载事件的拦截功能,我们可以实现字节码注入(bytecode instrumentation),往正在被加载的类中插入额外的字节码。
在工具篇中我曾经介绍过字节码工程框架ASM的用法。下面我将演示它的tree包(依赖于基础包),用面向对象的方式注入字节码。
1 | package org.example; |
上面这段代码不难理解。我们将使用ClassReader读取所传入的byte数组,并将其转换成ClassNode。然后我们将遍历ClassNode中的MethodNode节点,也就是该类中的构造器和方法。
当遇到名字为"main"的方法时,我们会在方法的入口处注入System.out.println("Hello, Instrumentation!");。运行结果如下所示:
1 | $ java -javaagent:myagent.jar -cp .:/PATH/TO/asm-7.0-beta.jar:/PATH/TO/asm-tree-7.0-beta.jar HelloWorld |
Java agent还提供了另外两个功能redefine和retransform。这两个功能针对的是已加载的类,并要求用户传入所要redefine或者retransform的类实例。
其中,redefine指的是舍弃原本的字节码,并替换成由用户提供的byte数组。该功能比较危险,一般用于修复出错了的字节码。
retransform则将针对所传入的类,重新调用所有已注册的ClassFileTransformer的transform方法。它的应用场景主要有如下两个。
第一,在执行premain或者agentmain方法前,Java虚拟机早已加载了不少类,而这些类的加载事件并没有被拦截,因此也没有被注入。使用retransform功能可以注入这些已加载但未注入的类。
第二,在定义了多个Java agent,多个注入的情况下,我们可能需要移除其中的部分注入。当调用Instrumentation.removeTransformer去除某个注入类后,我们可以调用retransform功能,重新从原始byte数组开始进行注入。
Java agent的这些功能都是通过JVMTI agent,也就是C agent来实现的。JVMTI是一个事件驱动的工具实现接口,通常,我们会在C agent加载后的入口方法Agent_OnLoad处注册各个事件的钩子(hook)方法。当Java虚拟机触发了这些事件时,便会调用对应的钩子方法。
1 | JNIEXPORT jint JNICALL |
举个例子,我们可以为JVMTI中的ClassFileLoadHook事件设置钩子,从而在C层面拦截所有的类加载事件。关于JVMTI的其他事件,你可以参考该链接。
基于字节码注入的profiler
我们可以利用字节码注入来实现代码覆盖工具(例如JaCoCo),或者各式各样的profiler。
通常,我们会定义一个运行时类,并在某一程序行为的周围,注入对该运行时类中方法的调用,以表示该程序行为正要发生或者已经发生。
1 | package org.example; |
举个例子,上面这段代码便是一个运行时类。该类维护了一个HashMap,用来统计每个类所新建实例的数目。当程序退出时,我们将逐个打印出每个类的名字,以及其新建实例的数目。
在Java agent中,我们会截获正在加载的类,并且在每条new字节码之后插入对fireAllocationEvent方法的调用,以表示当前正在新建某个类的实例。具体的注入代码如下所示:
1 | package org.example; |
你或许已经留意到,我们不得不排除对JDK类以及该运行时类的注入。这是因为,对这些类的注入很可能造成死循环调用,并最终抛出StackOverflowException异常。
举个例子,假设我们在PrintStream.println方法入口处注入System.out.println("blahblah"),由于out是PrintStream的实例,因此当执行注入代码时,我们又会调用PrintStream.println方法,从而造成死循环。
解决这一问题的关键在于设置一个线程私有的标识位,用以区分应用代码的上下文以及注入代码的上下文。当即将执行注入代码时,我们将根据标识位判断是否已经位于注入代码的上下文之中。如果不是,则设置标识位并正常执行注入代码;如果是,则直接返回,不再执行注入代码。
字节码注入的另一个技术难点则是命名空间。举个例子,不少应用程序都依赖于字节码工程库ASM。当我们的注入逻辑依赖于ASM时,便有可能出现注入使用最新版本的ASM,而应用程序使用较低版本的ASM的问题。
JDK本身也使用了ASM库,如用来生成Lambda表达式的适配器类。JDK的做法是重命名整个ASM库,为所有类的包名添加jdk.internal前缀。我们显然不好直接更改ASM的包名,因此需要借助自定义类加载器来隔离命名空间。
除了上述技术难点之外,基于字节码注入的工具还有另一个问题,那便是观察者效应(observer effect)对所收集的数据造成的影响。
举个利用字节码注入收集每个方法的运行时间的例子。假设某个方法调用了另一个方法,而这两个方法都被注入了,那么统计被调用者运行时间的注入代码所耗费的时间,将不可避免地被计入至调用者方法的运行时间之中。
再举一个统计新建对象数目的例子。我们知道,即时编译器中的逃逸分析可能会优化掉新建对象操作,但它不会消除相应的统计操作,比如上述例子中对fireAllocationEvent方法的调用。在这种情况下,我们将统计没有实际发生的新建对象操作。
另一种情况则是,我们所注入的对fireAllocationEvent方法的调用,将影响到方法内联的决策。如果该新建对象的构造器调用恰好因此没有被内联,从而造成对象逃逸。在这种情况下,原本能够被逃逸分析优化掉的新建对象操作将无法优化,我们也将统计到原本不会发生的新建对象操作。
总而言之,当使用字节码注入开发profiler时,需要辩证地看待所收集的数据。它仅能表示在被注入的情况下程序的执行状态,而非没有注入情况下的程序执行状态。
面向方面编程
说到字节码注入,就不得不提面向方面编程(Aspect-Oriented Programming,AOP)。面向方面编程的核心理念是定义切入点(pointcut)以及通知(advice)。程序控制流中所有匹配该切入点的连接点(joinpoint)都将执行这段通知代码。
举个例子,我们定义一个指代所有方法入口的切入点,并指定在该切入点执行的“打印该方法的名字”这一通知。那么每个具体的方法入口便是一个连接点。
面向方面编程的其中一种实现方式便是字节码注入,比如AspectJ。
在前面的例子中,我们也相当于使用了面向方面编程,在所有的new字节码之后执行了下面这样一段通知代码。
1 | `MyProfiler.fireAllocationEvent(<Target>.class)` |
我曾经参与开发过一个应用了面向方面编程思想的字节码注入框架DiSL。它支持用注解来定义切入点,用普通Java方法来定义通知。例如,在方法入口处打印所在的方法名,可以简单表示为如下代码:
1 | @Before(marker = BodyMarker.class) |
如果有同学对这个工具感兴趣,或者有什么需求或者建议,欢迎你在留言中提出。
总结与实践
今天我介绍了Java agent以及字节码注入。
我们可以通过Java agent的类加载拦截功能,修改某个类所对应的byte数组,并利用这个修改过后的byte数组完成接下来的类加载。
基于字节码注入的profiler,可以统计程序运行过程中某些行为的出现次数。如果需要收集Java核心类库的数据,那么我们需要小心避免无限递归调用。另外,我们还需通过自定义类加载器来解决命名空间的问题。
由于字节码注入会产生观察者效应,因此基于该技术的profiler所收集到的数据并不能反映程序的真实运行状态。它所反映的是程序在被注入的情况下的执行状态。
今天的实践环节,请你思考如何注入方法出口。除了正常执行路径之外,你还需考虑异常执行路径。
34 | Graal:用Java编译Java
作者: 郑雨迪

最后这三篇文章,我将介绍Oracle Labs的GraalVM项目。
GraalVM是一个高性能的、支持多种编程语言的执行环境。它既可以在传统的OpenJDK上运行,也可以通过AOT(Ahead-Of-Time)编译成可执行文件单独运行,甚至可以集成至数据库中运行。
除此之外,它还移除了编程语言之间的边界,并且支持通过即时编译技术,将混杂了不同的编程语言的代码编译到同一段二进制码之中,从而实现不同语言之间的无缝切换。
今天这一篇,我们就来讲讲GraalVM的基石Graal编译器。
在之前的篇章中,特别是介绍即时编译技术的第二部分,我们反反复复提到了Graal编译器。这是一个用Java写就的即时编译器,它从Java 9u开始便被集成自JDK中,作为实验性质的即时编译器。
Graal编译器可以通过Java虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler启用。当启用时,它将替换掉HotSpot中的C2编译器,并响应原本由C2负责的编译请求。
在今天的文章中,我将详细跟你介绍一下Graal与Java虚拟机的交互、Graal和C2的区别以及Graal的实现细节。
Graal和Java虚拟机的交互
我们知道,即时编译器是Java虚拟机中相对独立的模块,它主要负责接收Java字节码,并生成可以直接运行的二进制码。
具体来说,即时编译器与Java虚拟机的交互可以分为如下三个方面。
- 响应编译请求;
- 获取编译所需的元数据(如类、方法、字段)和反映程序执行状态的profile;
- 将生成的二进制码部署至代码缓存(code cache)里。
即时编译器通过这三个功能组成了一个响应编译请求、获取编译所需的数据,完成编译并部署的完整编译周期。
传统情况下,即时编译器是与Java虚拟机紧耦合的。也就是说,对即时编译器的更改需要重新编译整个Java虚拟机。这对于开发相对活跃的Graal来说显然是不可接受的。
为了让Java虚拟机与Graal解耦合,我们引入了Java虚拟机编译器接口(JVM Compiler Interface,JVMCI),将上述三个功能抽象成一个Java层面的接口。这样一来,在Graal所依赖的JVMCI版本不变的情况下,我们仅需要替换Graal编译器相关的jar包(Java 9以后的jmod文件),便可完成对Graal的升级。
JVMCI的作用并不局限于完成由Java虚拟机发出的编译请求。实际上,Java程序可以直接调用Graal,编译并部署指定方法。
Graal的单元测试便是基于这项技术。为了测试某项优化是否起作用,原本我们需要反复运行某一测试方法,直至Graal收到由Java虚拟机发出针对该方法的编译请求,而现在我们可以直接指定编译该方法,并进行测试。我们下一篇将介绍的Truffle语言实现框架,同样也是基于这项技术的。
Graal和C2的区别
Graal和C2最为明显的一个区别是:Graal是用Java写的,而C2是用C++写的。相对来说,Graal更加模块化,也更容易开发与维护,毕竟,连C2的作者Cliff Click大神都不想重蹈用C++开发Java虚拟机的覆辙。
许多开发者会觉得用C++写的C2肯定要比Graal快。实际上,在充分预热的情况下,Java程序中的热点代码早已经通过即时编译转换为二进制码,在执行速度上并不亚于静态编译的C++程序。
再者,即便是解释执行Graal,也仅是会减慢编译效率,而并不影响编译结果的性能。
换句话说,如果C2和Graal采用相同的优化手段,那么它们的编译结果是一样的。所以,程序达到稳定状态(即不再触发新的即时编译)的性能,也就是峰值性能,将也是一样的。
由于Java语言容易开发维护的优势,我们可以很方便地将C2的新优化移植到Graal中。反之则不然,比如,在Graal中被证实有效的部分逃逸分析(partial escape analysis)至今未被移植到C2中。
Graal和C2另一个优化上的分歧则是方法内联算法。相对来说,Graal的内联算法对新语法、新语言更加友好,例如Java 8的lambda表达式以及Scala语言。
我们曾统计过数十个Java或Scala程序的峰值性能。总体而言,Graal编译结果的性能要优于C2。对于Java程序来说,Graal的优势并不明显;对于Scala程序来说,Graal的性能优势达到了10%。
大规模使用Scala的Twitter便在他们的生产环境中部署了Graal编译器,并取得了11%的性能提升。(Slides, Video,该数据基于GraalVM社区版。)
Graal的实现
Graal编译器将编译过程分为前端和后端两大部分。前端用于实现平台无关的优化(如方法内联),以及小部分平台相关的优化;而后端则负责大部分的平台相关优化(如寄存器分配),以及机器码的生成。
在介绍即时编译技术时,我曾提到过,Graal和C2都采用了Sea-of-Nodes IR。严格来说,这里指的是Graal的前端,而后端采用的是另一种非Sea-of-Nodes的IR。通常,我们将前端的IR称之为High-level IR,或者HIR;后端的IR则称之为Low-level IR,或者LIR。
Graal的前端是由一个个单独的优化阶段(optimization phase)构成的。我们可以将每个优化阶段想象成一个图算法:它会接收一个规则的图,遍历图上的节点并做出优化,并且返回另一个规则的图。前端中的编译阶段除了少数几个关键的之外,其余均可以通过配置选项来开启或关闭。

Graal编译器前端的优化阶段(局部)
感兴趣的同学可以阅读Graal repo里配置这些编译优化阶段的源文件
我们知道,Graal和C2都采用了激进的投机性优化手段(speculative optimization)。
通常,这些优化都基于某种假设(assumption)。当假设出错的情况下,Java虚拟机会借助去优化(deoptimization)这项机制,从执行即时编译器生成的机器码切换回解释执行,在必要情况下,它甚至会废弃这份机器码,并在重新收集程序profile之后,再进行编译。
举个以前讲过的例子,类层次分析。在进行虚方法内联时(或者其他与类层次相关的优化),我们可能会发现某个接口仅有一个实现。
在即时编译过程中,我们可以假设在之后的执行过程中仍旧只有这一个实现,并根据这个假设进行编译优化。当之后加载了接口的另一实现时,我们便会废弃这份机器码。
Graal与C2相比会更加激进。它从设计上便十分青睐这种基于假设的优化手段。在编译过程中,Graal支持自定义假设,并且直接与去优化节点相关联。
当对应的去优化被触发时,Java虚拟机将负责记录对应的自定义假设。而Graal在第二次编译同一方法时,便会知道该自定义假设有误,从而不再对该方法使用相同的激进优化。
Java虚拟机的另一个能够大幅度提升性能的特性是intrinsic方法,我在之前的篇章中已经详细介绍过了。在Graal中,实现高性能的intrinsic方法也相对比较简单。Graal提供了一种替换方法调用的机制,在解析Java字节码时会将匹配到的方法调用,替换成对另一个内部方法的调用,或者直接替换为特殊节点。
举例来说,我们可以把比较两个byte数组的方法java.util.Arrays.equals(byte[],byte[])替换成一个特殊节点,用来代表整个数组比较的逻辑。这样一来,当前编译方法所对应的图将被简化,因而其适用于其他优化的可能性也将提升。
总结与实践
Graal是一个用Java写就的、并能够将Java字节码转换成二进制码的即时编译器。它通过JVMCI与Java虚拟机交互,响应由后者发出的编译请求、完成编译并部署编译结果。
对Java程序而言,Graal编译结果的性能略优于OpenJDK中的C2;对Scala程序而言,它的性能优势可达到10%(企业版甚至可以达到20%!)。这背后离不开Graal所采用的激进优化方式。
今天的实践环节,你可以尝试使用附带Graal编译器的JDK。在Java 10,11中,你可以通过添加虚拟机参数-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler来启用,或者下载我们部署在Oracle OTN上的基于Java 8的版本。
在刚开始运行的过程中,Graal编译器本身需要被即时编译,会抢占原本可用于编译应用代码的计算资源。因此,目前Graal编译器的启动性能会较差。最后一篇我会介绍解决方案。
35 | Truffle:语言实现框架
作者: 郑雨迪

今天我们来聊聊GraalVM中的语言实现框架Truffle。
我们知道,实现一门新编程语言的传统做法是实现一个编译器,也就是把用该语言编写的程序转换成可直接在硬件上运行的机器码。
通常来说,编译器分为前端和后端:前端负责词法分析、语法分析、类型检查和中间代码生成,后端负责编译优化和目标代码生成。
不过,许多编译器教程只涉及了前端中的词法分析和语法分析,并没有真正生成可以运行的目标代码,更谈不上编译优化,因此在生产环境中并不实用。
另一种比较取巧的做法则是将新语言编译成某种已知语言,或者已知的中间形式,例如将Scala、Kotlin编译成Java字节码。
这样做的好处是可以直接享用Java虚拟机自带的各项优化,包括即时编译、自动内存管理等等。因此,这种做法对所生成的Java字节码的优化程度要求不高。
不过,不管是附带编译优化的编译器,还是生成中间形式并依赖于其他运行时的即时编译优化的编译器,它们所针对的都是编译型语言,在运行之前都需要这一额外的编译步骤。
与编译型语言相对应的则是解释型语言,例如JavaScript、Ruby、Python等。对于这些语言来说,它们无须额外的编译步骤,而是依赖于解释执行器进行解析并执行。
为了让该解释执行器能够高效地运行大型程序,语言实现开发人员通常会将其包装在虚拟机里,并实现诸如即时编译、垃圾回收等其他组件。这些组件对语言设计 本身并无太大贡献,仅仅是为了实用性而不得不进行的工程实现。
在理想情况下,我们希望在不同的语言实现中复用这些组件。也就是说,每当开发一门新语言时,我们只需要实现它的解释执行器,便能够直接复用即时编译、垃圾回收等组件,从而达到高性能的效果。这也是Truffle项目的目标。接下来,我们就来讲讲这个项目。
Truffle项目简介
Truffle是一个用Java写就的语言实现框架。基于Truffle的语言实现仅需用Java实现词法分析、语法分析以及针对语法分析所生成的抽象语法树(Abstract Syntax Tree,AST)的解释执行器,便可以享用由Truffle提供的各项运行时优化。
就一个完整的Truffle语言实现而言,由于实现本身以及其所依赖的Truffle框架部分都是用Java实现的,因此它可以运行在任何Java虚拟机之上。
当然,如果Truffle运行在附带了Graal编译器的Java虚拟机之上,那么它将调用Graal编译器所提供的API,主动触发对Truffle语言的即时编译,将对AST的解释执行转换为执行即时编译后的机器码。
在这种情况下,Graal编译器相当于一个提供了即时编译功能的库,宿主虚拟机本身仍可使用C2作为其唯一的即时编译器,或者分层编译模式下的4层编译器。

我们团队实现并且开源了多个Truffle语言,例如JavaScript,Ruby,R,Python,以及可用来解释执行LLVM bitcode的Sulong。关于Sulong项目,任何能够编译为LLVM bitcode的编程语言,例如C/C++,都能够在这上面运行。
下图展示了运行在GraalVM EE上的Java虚拟机语言,以及除Python外Truffle语言的峰值性能指标(2017年数据)。

这里我采用的基线是每个语言较有竞争力的语言实现。
- 对于Java虚拟机语言(Java、Scala),我比较的是使用C2的HotSpot虚拟机和使用Graal的HotSpot虚拟机。
- 对于Ruby,我比较的是运行在HotSpot虚拟机之上的JRuby和Truffle Ruby。
- 对于R,我比较的是GNU R和基于Truffle的FastR。
- 对于C/C++,我比较的是利用LLVM编译器生成的二进制文件和基于Truffle的Sulong。
- 对于JavaScript,我比较的是Google的V8和Graal.js。
针对每种语言,我们运行了上百个基准测试,求出各个基准测试峰值性能的加速比,并且汇总成图中所示的几何平均值(Geo. mean)。
简单地说明一下,当GraalVM的加速比为1时,代表使用其他语言实现和使用GraalVM的性能相当。当GraalVM加速比超过1时,则代表GraalVM的性能较好;反之,则说明GraalVM的性能较差。
我们可以看到,Java跑在Graal上和跑在C2上的执行效率类似,而Scala跑在Graal上的执行效率则是跑在C2上的1.2倍。
对于Ruby或者R这类解释型语言,经由Graal编译器加速的Truffle语言解释器的性能十分优越,分别达到对应基线的4.1x和4.5x。这里便可以看出使用专业即时编译器的Truffle框架的优势所在。
不过,对于同样拥有专业即时编译器的V8来说,基于Truffle的Graal.js仍处于追赶者的位置。考虑到我们团队中负责Graal.js的工程师仅有个位数,能够达到如此性能已属不易。现在Graal.js已经开源出来,我相信借助社区的贡献,它的性能能够得到进一步的提升。
Sulong与传统的C/C++相比,由于两者最终都将编译为机器码,因此原则上后者定义了前者的性能上限。
不过,Sulong将C/C++代码放在托管环境中运行,所有代码中的内存访问都会在托管环境的监控之下。无论是会触发Segfault的异常访问,还是读取敏感数据的恶意访问,都能够被Sulong拦截下来并作出相应处理。
Partial Evaluation
如果要理解Truffle的原理,我们需要先了解Partial Evaluation这一个概念。
假设有一段程序P,它将一系列输入I转换成输出O(即P: I -> O)。而这些输入又可以进一步划分为编译时已知的常量IS,和编译时未知的ID。
那么,我们可以将程序P: I -> O转换为等价的另一段程序P': ID -> O。这个新程序P'便是P的特化(Specialization),而从P转换到P'的这个过程便是所谓的Partial Evaluation。
回到Truffle这边,我们可以将Truffle语言的解释执行器当成P,将某段用Truffle语言写就的程序当作IS,并通过Partial Evaluation特化为P'。由于Truffle语言的解释执行器是用Java写的,因此我们可以利用Graal编译器将P'编译为二进制码。
下面我将用一个具体例子来讲解。
假设有一门语言X,只支持读取整数参数和整数加法。这两种操作分别对应下面这段代码中的AST节点Arg和Add。
1 | abstract class Node { |
所谓AST节点的解释执行,便是调用这些AST节点的execute方法;而一段程序的解释执行,则是调用这段程序的AST根节点的execute方法。
我们可以看到,Arg节点和Add节点均实现了execute方法,接收一个用来指代程序输入的int数组参数,并返回计算结果。其中,Arg节点将返回int数组的第i个参数(i是硬编码在程序之中的常量);而Add节点将分别调用左右两个节点的execute方法, 并将所返回的值相加后再返回。
下面我们将利用语言X实现一段程序,计算三个输入参数之和arg0 + arg1 + arg2。这段程序解析生成的AST如下述代码所示:
1 | // Sample program: arg0 + arg1 + arg2 |
这段程序对应的解释执行则是interpret(sample, args),其中args为代表传入参数的int数组。由于sample是编译时常量,因此我们可以将其通过Partial Evaluation,特化为下面这段代码所示的interpret0方法:
1 | static final Node sample = new Add(new Add(new Arg(0), new Arg(1)), new Arg(2)); |
Truffle的Partial Evaluator会不断进行方法内联(直至遇到被``@TruffleBoundary注解的方法)。因此,上面这段代码的interpret0方法,在内联了对Add.execute`方法的调用之后,会转换成下述代码:
1 | static final Node sample = new Add(new Add(new Arg(0), new Arg(1)), new Arg(2)); |
同样,我们可以进一步内联对Add.execute方法的调用以及对Arg.execute方法的调用,最终将interpret0转换成下述代码:
1 | static int interpret0(int[] args) { |
至此,我们已成功地将一段Truffle语言代码的解释执行转换为上述Java代码。接下来,我们便可以让Graal编译器将这段Java代码编译为机器码,从而实现Truffle语言的即时编译。
节点重写
Truffle的另一项关键优化是节点重写(node rewriting)。
在动态语言中,许多变量的类型是在运行过程中方能确定的。以加法符号+为例,它既可以表示整数加法,还可以表示浮点数加法,甚至可以表示字符串加法。
如果是静态语言,我们可以通过推断加法的两个操作数的具体类型,来确定该加法的类型。但对于动态语言来说,我们需要在运行时动态确定操作数的具体类型,并据此选择对应的加法操作。这种在运行时选择语义的节点,会十分不利于即时编译,从而严重影响到程序的性能。
Truffle语言解释器会收集每个AST节点所代表的操作的类型,并且在即时编译时,作出针对所收集得到的类型profile的特化(specialization)。
还是以加法操作为例,如果所收集的类型profile显示这是一个整数加法操作,那么在即时编译时我们会将对应的AST节点当成整数加法;如果是一个字符串加法操作,那么我们会将对应的AST节点当成字符串加法。
当然,如果该加法操作既有可能是整数加法也可能是字符串加法,那么我们只好在运行过程中判断具体的操作类型,并选择相应的加法操作。

这种基于类型profile的优化,与我们以前介绍过的Java虚拟机中解释执行器以及三层C1编译代码十分类似,它们背后的核心都是基于假设的投机性优化,以及在假设失败时的去优化。
在即时编译过后,如果运行过程中发现AST节点的实际类型和所假设的类型不同,Truffle会主动调用Graal编译器提供的去优化API,返回至解释执行AST节点的状态,并且重新收集AST节点的类型信息。之后,Truffle会再次利用Graal编译器进行新一轮的即时编译。
当然,如果能够在第一次编译时便已达到稳定状态,不再触发去优化以及重新编译,那么,这会极大地减短程序到达峰值性能的时间。为此,我们统计了各个Truffle语言的方法在进行过多少次方法调用后,其AST节点的类型会固定下来。
据统计,在JavaScript方法和Ruby方法中,80%会在5次方法调用后稳定下来,90%会在7次调用后稳定下来,99%会在19次方法调用之后稳定下来。
R语言的方法则比较特殊,即便是不进行任何调用,有50%的方法已经稳定下来了。这背后的原因也不难推测,这是因为R语言主要用于数值统计,几乎所有的操作都是浮点数类型的。
Polyglot
在开发过程中,我们通常会为工程项目选定一门语言,但问题也会接踵而至:一是这门语言没有实现我们可能需要用到的库,二是这门语言并不适用于某类问题。
Truffle语言实现框架则支持Polyglot,允许在同一段代码中混用不同的编程语言,从而使得开发人员能够自由地选择合适的语言来实现子组件。
与其他Polyglot框架不同的是,Truffle语言之间能够共用对象。也就是说,在不对某个语言中的对象进行复制或者序列化反序列化的情况下,Truffle可以无缝地将该对象传递给另一门语言。因此,Truffle的Polyglot在切换语言时,性能开销非常小,甚至经常能够达到零开销。
Truffle的Polyglot特性是通过Polyglot API来实现的。每个实现了Polyglot API的Truffle语言,其对象都能够被其他Truffle语言通过Polyglot API解析。实际上,当通过Polyglot API解析外来对象时,我们并不需要了解对方语言,便能够识别其数据结构,访问其中的数据,并进行进一步的计算。
总结与实践
今天我介绍了GraalVM中的Truffle项目。
Truffle是一个语言实现框架,允许语言开发者在仅实现词法解析、语法解析以及AST解释器的情况下,达到极佳的性能。目前Oracle Labs已经实现并维护了JavaScript、Ruby、R、Python以及可用于解析LLVM bitcode的Sulong。后者将支持在GraalVM上运行C/C++代码。
Truffle背后所依赖的技术是Partial Evaluation以及节点重写。Partial Evaluation指的是将所要编译的目标程序解析生成的抽象语法树当做编译时常量,特化该Truffle语言的解释器,从而得到指代这段程序解释执行过程的Java代码。然后,我们可以借助Graal编译器将这段Java代码即时编译为机器码。
节点重写则是收集AST节点的类型,根据所收集的类型profile进行的特化,并在节点类型不匹配时进行去优化并重新收集、编译的一项技术。
Truffle的Polyglot特性支持在一段代码中混用多种不同的语言。与其他Polyglot框架相比,它支持在不同的Truffle语言中复用内存中存储的同一个对象。
今天的实践环节,请你试用GraalVM中附带的各项语言实现。你可以运行我们官网上的各个示例程序。
36 | SubstrateVM:AOT编译框架
作者: 郑雨迪

今天我们来聊聊GraalVM中的Ahead-Of-Time(AOT)编译框架SubstrateVM。
先来介绍一下AOT编译,所谓AOT编译,是与即时编译相对立的一个概念。我们知道,即时编译指的是在程序的运行过程中,将字节码转换为可在硬件上直接运行的机器码,并部署至托管环境中的过程。
而AOT编译指的则是,在程序运行之前,便将字节码转换为机器码的过程。它的成果可以是需要链接至托管环境中的动态共享库,也可以是独立运行的可执行文件。
狭义的AOT编译针对的目标代码需要与即时编译的一致,也就是针对那些原本可以被即时编译的代码。不过,我们也可以简单地将AOT编译理解为类似于GCC的静态编译器。
AOT编译的优点显而易见:我们无须在运行过程中耗费CPU资源来进行即时编译,而程序也能够在启动伊始就达到理想的性能。
然而,与即时编译相比,AOT编译无法得知程序运行时的信息,因此也无法进行基于类层次分析的完全虚方法内联,或者基于程序profile的投机性优化(并非硬性限制,我们可以通过限制运行范围,或者利用上一次运行的程序profile来绕开这两个限制)。这两者都会影响程序的峰值性能。
Java 9引入了实验性AOT编译工具jaotc。它借助了Graal编译器,将所输入的Java类文件转换为机器码,并存放至生成的动态共享库之中。
在启动过程中,Java虚拟机将加载参数-XX:AOTLibrary所指定的动态共享库,并部署其中的机器码。这些机器码的作用机理和即时编译生成的机器码作用机理一样,都是在方法调用时切入,并能够去优化至解释执行。
由于Java虚拟机可能通过Java agent或者C agent改动所加载的字节码,或者这份AOT编译生成的机器码针对的是旧版本的Java类,因此它需要额外的验证机制,来保证即将链接的机器码的语义与对应的Java类的语义是一致的。
jaotc使用的机制便是类指纹(class fingerprinting)。它会在动态共享库中保存被AOT编译的Java类的摘要信息。在运行过程中,Java虚拟机负责将该摘要信息与已加载的Java类相比较,一旦不匹配,则直接舍弃这份AOT编译的机器码。
jaotc的一大应用便是编译java.base module,也就是Java核心类库中最为基础的类。这些类很有可能会被应用程序所调用,但调用频率未必高到能够触发即时编译。
因此,如果Java虚拟机能够使用AOT编译技术,将它们提前编译为机器码,那么将避免在执行即时编译生成的机器码时,因为“不小心”调用到这些基础类,而需要切换至解释执行的性能惩罚。
不过,今天要介绍的主角并非jaotc,而是同样使用了Graal编译器的AOT编译框架SubstrateVM。
SubstrateVM的设计与实现
SubstrateVM的设计初衷是提供一个高启动性能、低内存开销,并且能够无缝衔接C代码的Java运行时。它与jaotc的区别主要有两处。
第一,SubstrateVM脱离了HotSpot虚拟机,并拥有独立的运行时,包含异常处理,同步,线程管理,内存管理(垃圾回收)和JNI等组件。
第二,SubstrateVM要求目标程序是封闭的,即不能动态加载其他类库等。基于这个假设,SubstrateVM将探索整个编译空间,并通过静态分析推算出所有虚方法调用的目标方法。最终,SubstrateVM会将所有可能执行到的方法都纳入编译范围之中,从而免于实现额外的解释执行器。
有关SubstrateVM的其他限制,你可以参考这篇文档。
从执行时间上来划分,SubstrateVM可分为两部分:native image generator以及SubstrateVM运行时。后者SubstrateVM运行时便是前面提到的精简运行时,经过AOT编译的目标程序将跑在该运行时之上。
native image generator则包含了真正的AOT编译逻辑。它本身是一个Java程序,将使用Graal编译器将Java类文件编译为可执行文件或者动态链接库。
在进行编译之前,native image generator将采用指针分析(points-to analysis),从用户提供的程序入口出发,探索所有可达的代码。在探索的同时,它还将执行初始化代码,并在最终生成可执行文件时,将已初始化的堆保存至一个堆快照之中。这样一来,SubstrateVM将直接从目标程序开始运行,而无须重复进行Java虚拟机的初始化。
SubstrateVM主要用于Java虚拟机语言的AOT编译,例如Java、Scala以及Kotlin。Truffle语言实现本质上就是Java程序,而且它所有用到的类都是编译时已知的,因此也适合在SubstrateVM上运行。不过,它并不会AOT编译用Truffle语言写就的程序。
SubstrateVM的启动时间与内存开销
SubstrateVM的启动时间和内存开销非常少。我们曾比较过用C和用Java两种语言写就的Hello World程序。C程序的执行时间在10ms以下,内存开销在500KB以下。在HotSpot虚拟机上运行的Java程序则需要40ms,内存开销为24MB。
使用SubstrateVM的Java程序的执行时间则与C程序持平,内存开销在850KB左右。这得益于SubstrateVM所保存的堆快照,以及无须额外初始化,直接执行目标代码的特性。
同样,我们还比较了用JavaScript编写的Hello World程序。这里的测试对象是Google的V8以及基于Truffle的Graal.js。这两个执行引擎都涉及了大量的解析代码以及执行代码,因此可以当作大型应用程序来看待。
V8的执行效率非常高,能够与C程序的Hello World相媲美,但是它使用了约18MB的内存。运行在HotSpot虚拟机上的Graal.js则需要650ms方能执行完这段JavaScript的Hello World程序,而且内存开销在120MB左右。
运行在SubstrateVM上的Graal.js无论是执行时间还是内存开销都十分优越,分别为10ms以下以及4.2MB。我们可以看到,它在运行时间与V8持平的情况下,内存开销远小于V8。
由于SubstrateVM的轻量特性,它十分适合于嵌入至其他系统之中。Oracle Labs的另一个团队便是将Truffle语言实现嵌入至Oracle数据库之中,这样就可以在数据库中运行任意语言的预储程序(stored procedure)。如果你感兴趣的话,可以搜索Oracle Database Multilingual Engine(MLE),或者参阅这个网址。我们团队也在与MySQL合作,开发MySQL MLE,详情可留意我们在今年Oracle Code One的讲座。
Metropolis项目
去年OpenJDK推出了Metropolis项目,他们希望可以实现“Java-on-Java”的远大目标。
我们知道,目前HotSpot虚拟机的绝大部分代码都是用C++写的。这也造就了一个非常有趣的现象,那便是对Java语言本身的贡献需要精通C++。此外,随着HotSpot项目日渐庞大,维护难度也逐渐上升。
由于上述种种原因,使用Java来开发Java虚拟机的呼声越来越高。Oracle的架构师John Rose便提出了使用Java开发Java虚拟机的四大好处:
- 能够完全控制编译Java虚拟机时所使用的优化技术;
- 能够与C++语言的更新解耦合;
- 能够减轻开发人员以及维护人员的负担;
- 能够以更为敏捷的方式实现Java的新功能。
当然,Metropolis项目并非第一个提出Java-on-Java概念的项目。实际上,JikesRVM项目和Maxine VM项目都已用Java完整地实现了一套Java虚拟机(后者的即时编译器C1X便是Graal编译器的前身)。
然而,Java-on-Java技术通常会干扰应用程序的垃圾回收、即时编译优化,从而严重影响Java虚拟机的启动性能。
举例来说,目前使用了Graal编译器的HotSpot虚拟机会在即时编译过程中生成大量的Java对象,这些Java对象同样会占据应用程序的堆空间,从而使得垃圾回收更加频繁。
另外,Graal编译器本身也会触发即时编译,并与应用程序的即时编译竞争编译线程的CPU资源。这将造成应用程序从解释执行切换至即时编译生成的机器码的时间大大地增长,从而降低应用程序的启动性能。
Metropolis项目的第一个子项目便是探索部署已AOT编译的Graal编译器的可能性。这个子项目将借助SubstrateVM技术,把整个Graal编译器AOT编译为机器码。
这样一来,在运行过程中,Graal编译器不再需要被即时编译,因此也不会再占据可用于即时编译应用程序的CPU资源,使用Graal编译器的HotSpot虚拟机的启动性能将得到大幅度地提升。
此外,由于SubstrateVM编译得到的Graal编译器将使用独立的堆空间,因此Graal编译器在即时编译过程中生成的Java对象将不再干扰应用程序所使用的堆空间。
目前Metropolis项目仍处于前期验证阶段,如果你感兴趣的话,可以关注之后的发展情况。
总结与实践
今天我介绍了GraalVM中的AOT编译框架SubstrateVM。
SubstrateVM的设计初衷是提供一个高启动性能、低内存开销,和能够无缝衔接C代码的Java运行时。它是一个独立的运行时,拥有自己的内存管理等组件。
SubstrateVM要求所要AOT编译的目标程序是封闭的,即不能动态加载其他类库等。在进行AOT编译时,它会探索所有可能运行到的方法,并全部纳入编译范围之内。
SubstrateVM的启动时间和内存开销都非常少,这主要得益于在AOT编译时便已保存了已初始化好的堆快照,并支持从程序入口直接开始运行。作为对比,HotSpot虚拟机在执行main方法前需要执行一系列的初始化操作,因此启动时间和内存开销都要远大于运行在SubstrateVM上的程序。
Metropolis项目将运用SubstrateVM项目,逐步地将HotSpot虚拟机中的C++代码替换成Java代码,从而提升HotSpot虚拟机的可维护性,也加快新Java功能的开发效率。
今天的实践环节,请你参考我们官网的SubstrateVM教程,AOT编译一段Java-Kotlin代码。
【工具篇】 常用工具介绍
作者: 郑雨迪

在前面的文章中,我曾使用了不少工具来辅助讲解,也收到了不少同学留言,说不了解这些工具,不知道都有什么用,应该怎么用。那么今天我便统一做一次具体的介绍。本篇代码较多,你可以点击文稿查看。
javap:查阅Java字节码
javap是一个能够将class文件反汇编成人类可读格式的工具。在本专栏中,我们经常借助这个工具来查阅Java字节码。
举个例子,在讲解异常处理那一篇中,我曾经展示过这么一段代码。
1 | public class Foo { |
编译过后,我们便可以使用javap来查阅Foo.test方法的字节码。
1 | $ javac Foo.java |
这里面我用到了两个选项。第一个选项是-p。默认情况下javap会打印所有非私有的字段和方法,当加了-p选项后,它还将打印私有的字段和方法。第二个选项是-v。它尽可能地打印所有信息。如果你只需要查阅方法对应的字节码,那么可以用-c选项来替换-v。
javap的-v选项的输出分为几大块。
1.基本信息,涵盖了原class文件的相关信息。
class文件的版本号(minor version: 0,major version: 54),该类的访问权限(flags: (0x0021) ACC_PUBLIC, ACC_SUPER),该类(this_class: #7)以及父类(super_class: #8)的名字,所实现接口(interfaces: 0)、字段(fields: 4)、方法(methods: 2)以及属性(attributes: 1)的数目。
这里属性指的是class文件所携带的辅助信息,比如该class文件的源文件的名称。这类信息通常被用于Java虚拟机的验证和运行,以及Java程序的调试,一般无须深入了解。
1 | Classfile ../Foo.class |
class文件的版本号指的是编译生成该class文件时所用的JRE版本。由较新的JRE版本中的javac编译而成的class文件,不能在旧版本的JRE上跑,否则,会出现如下异常信息。(Java 8对应的版本号为52,Java 10对应的版本号为54。)
1 | Exception in thread "main" java.lang.UnsupportedClassVersionError: Foo has been compiled by a more recent version of the Java Runtime (class file version 54.0), this version of the Java Runtime only recognizes class file versions up to 52.0 |
类的访问权限通常为ACC_开头的常量。具体每个常量的意义可以查阅Java虚拟机规范4.1小节[1]。
2.常量池,用来存放各种常量以及符号引用。
常量池中的每一项都有一个对应的索引(如#1),并且可能引用其他的常量池项(#1 = Methodref #8.#23)。
1 | Constant pool: |
举例来说,上图中的1号常量池项是一个指向Object类构造器的符号引用。它是由另外两个常量池项所构成。如果将它看成一个树结构的话,那么它的叶节点会是字符串常量,如下图所示。

3.字段区域,用来列举该类中的各个字段。
这里最主要的信息便是该字段的类型(descriptor: I)以及访问权限(flags: (0x0002) ACC_PRIVATE)。对于声明为final的静态字段而言,如果它是基本类型或者字符串类型,那么字段区域还将包括它的常量值。
1 | private int tryBlock; |
另外,Java虚拟机同样使用了“描述符”(descriptor)来描述字段的类型。具体的对照如下表所示。其中比较特殊的,我已经高亮显示。
4.方法区域,用来列举该类中的各个方法。
除了方法描述符以及访问权限之外,每个方法还包括最为重要的代码区域(Code:)。
1 | public void test(); |
代码区域一开始会声明该方法中的操作数栈(stack=2)和局部变量数目(locals=3)的最大值,以及该方法接收参数的个数(args_size=1)。注意这里局部变量指的是字节码中的局部变量,而非Java程序中的局部变量。
接下来则是该方法的字节码。每条字节码均标注了对应的偏移量(bytecode index,BCI),这是用来定位字节码的。比如说偏移量为10的跳转字节码10: goto 35,将跳转至偏移量为35的字节码35: aload_0。
紧跟着的异常表(Exception table:)也会使用偏移量来定位每个异常处理器所监控的范围(由from到to的代码区域),以及异常处理器的起始位置(target)。除此之外,它还会声明所捕获的异常类型(type)。其中,any指代任意异常类型。
再接下来的行数表(LineNumberTable:)则是Java源程序到字节码偏移量的映射。如果你在编译时使用了-g参数(javac -g Foo.java),那么这里还将出现局部变量表(LocalVariableTable:),展示Java程序中每个局部变量的名字、类型以及作用域。
行数表和局部变量表均属于调试信息。Java虚拟机并不要求class文件必备这些信息。
1 | LocalVariableTable: |
最后则是字节码操作数栈的映射表(StackMapTable: number_of_entries = 3)。该表描述的是字节码跳转后操作数栈的分布情况,一般被Java虚拟机用于验证所加载的类,以及即时编译相关的一些操作,正常情况下,你无须深入了解。
2.OpenJDK项目Code Tools:实用小工具集
OpenJDK的Code Tools项目[2]包含了好几个实用的小工具。
在第一篇的实践环节中,我们使用了其中的字节码汇编器反汇编器ASMTools[3],当前6.0版本的下载地址位于[4]。ASMTools的反汇编以及汇编操作所对应的命令分别为:
1 | $ java -cp /path/to/asmtools.jar org.openjdk.asmtools.jdis.Main Foo.class > Foo.jasm |
和
1 | $ java -cp /path/to/asmtools.jar org.openjdk.asmtools.jasm.Main Foo.jasm |
该反汇编器的输出格式和javap的不尽相同。一般我只使用它来进行一些简单的字节码修改,以此生成无法直接由Java编译器生成的类,它在HotSpot虚拟机自身的测试中比较常见。
在第一篇的实践环节中,我们需要将整数2赋值到一个声明为boolean类型的局部变量中。我采取的做法是将编译生成的class文件反汇编至一个文本文件中,然后找到boolean flag = true对应的字节码序列,也就是下面的两个。
1 | iconst_1; |
将这里的iconst_1改为iconst_2[5],保存后再汇编至class文件即可完成第一篇实践环节的需求。
除此之外,你还可以利用这一套工具来验证我之前文章中的一些结论。比如我说过class文件允许出现参数类型相同、而返回类型不同的方法,并且,在作为库文件时Java编译器将使用先定义的那一个,来决定具体的返回类型。
具体的验证方法便是在反汇编之后,利用文本编辑工具复制某一方法,并且更改该方法的描述符,保存后再汇编至class文件。
Code Tools项目还包含另一个实用的小工具JOL[6],当前0.9版本的下载地址位于[7]。JOL可用于查阅Java虚拟机中对象的内存分布,具体可通过如下两条指令来实现。
1 | $ java -jar /path/to/jol-cli-0.9-full.jar internals java.util.HashMap |
3.ASM:Java字节码框架
ASM[8]是一个字节码分析及修改框架。它被广泛应用于许多项目之中,例如Groovy、Kotlin的编译器,代码覆盖测试工具Cobertura、JaCoCo,以及各式各样通过字节码注入实现的程序行为监控工具。甚至是Java 8中Lambda表达式的适配器类,也是借助ASM来动态生成的。
ASM既可以生成新的class文件,也可以修改已有的class文件。前者相对比较简单一些。ASM甚至还提供了一个辅助类ASMifier,它将接收一个class文件并且输出一段生成该class文件原始字节数组的代码。如果你想快速上手ASM的话,那么你可以借助ASMifier生成的代码来探索各个API的用法。
下面我将借助ASMifier,来生成第一篇实践环节所用到的类。(你可以通过该地址[9]下载6.0-beta版。)
1 | $ echo ' |
可以看到,ASMifier生成的代码中包含一个名为FooDump的类,其中定义了一个名为dump的方法。该方法将返回一个byte数组,其值为生成类的原始字节。
在dump方法中,我们新建了功能类ClassWriter的一个实例,并通过它来访问不同的成员,例如方法、字段等等。
每当访问一种成员,我们便会得到另一个访问者。在上面这段代码中,当我们访问方法时(即visitMethod),便会得到一个MethodVisitor。在接下来的代码中,我们会用这个MethodVisitor来访问(这里等同于生成)具体的指令。
这便是ASM所使用的访问者模式。当然,这段代码仅包含ClassWriter这一个访问者,因此看不出具体有什么好处。
我们暂且不管这个访问者模式,先来看看如何实现第一篇课后实践的要求。首先,main方法中的boolean flag = true;语句对应的代码是:
1 | mv.visitInsn(ICONST_1); |
也就是说,我们只需将这里的ICONST_1更改为ICONST_2,便可以满足要求。下面我用另一个类Wrapper,来调用修改过后的FooDump.dump方法。
1 | $ echo 'import java.nio.file.*; |
这里的输出结果应和通过ASMTools修改的结果一致。
通过ASM来修改已有class文件则相对复杂一些。不过我们可以从下面这段简单的代码来开始学起:
1 | public static void main(String[] args) throws Exception { |
这段代码的功能便是读取一个class文件,将之转换为ASM的数据结构,然后再转换为原始字节数组。其中,我使用了两个功能类。除了已经介绍过的ClassWriter外,还有一个ClassReader。
ClassReader将读取“Foo”类的原始字节,并且翻译成对应的访问请求。也就是说,在上面ASMifier生成的代码中的各个访问操作,现在都交给ClassReader.accept这一方法来发出了。
那么,如何修改这个class文件的字节码呢?原理很简单,就是将ClassReader的访问请求发给另外一个访问者,再由这个访问者委派给ClassWriter。
这样一来,新增操作可以通过在某一需要转发的请求后面附带新的请求来实现;删除操作可以通过不转发请求来实现;修改操作可以通过忽略原请求,新建并发出另外的请求来实现。

1 | import java.nio.file.*; |
这里我贴了一段代码,在ClassReader和ClassWriter中间插入了一个自定义的访问者MyClassVisitor。它将截获由ClassReader发出的对名字为“main”的方法的访问请求,并且替换为另一个自定义的MethodVisitor。
这个MethodVisitor会忽略由ClassReader发出的任何请求,仅在遇到visitCode请求时,生成一句“System.out.println(“Hello World!”);”。
由于篇幅的限制,我就不继续深入介绍下去了。如果你对ASM有浓厚的兴趣,可以参考这篇教程[10]。
你对这些常用工具还有哪些问题呢?可以给我留言,我们一起讨论。感谢你的收听,我们下期再见。
[1]
https://docs.oracle.com/javase/specs/jvms/se10/html/jvms-4.html#jvms-4.1
[2]
http://openjdk.java.net/projects/code-tools/
[3]
https://wiki.openjdk.java.net/display/CodeTools/asmtools
[4]
[5]
https://cs.au.dk/~mis/dOvs/jvmspec/ref–21.html
[6]
http://openjdk.java.net/projects/code-tools/jol/
[7]
http://central.maven.org/maven2/org/openjdk/jol/jol-cli/0.9/jol-cli-0.9-full.jar
[8]
[9]
[10]
http://web.cs.ucla.edu/~msb/cs239-tutorial/
尾声 | 道阻且长,努力加餐
作者: 郑雨迪

说句实话,我也不知道是怎么写完这36篇技术文章的。
一周三篇的文章接近近万字,说多不多,对我而言还是挺困难的一件事。基本上,我连续好几个月的业余时间都贡献给写作,甚至一度重温了博士阶段被论文支配的恐怖。我想,这大概也算是在工作相对清闲的国外环境下,体验了一把997的生活。
这一路下来,我感觉写专栏的最大问题,其实并不在于写作本身,而在于它对你精力的消耗,这种消耗甚至会让你无法专注于本职工作。因此,我也愈发地佩服能够持续分享技术的同行们。还好我的工作挺有趣的,每天开开心心地上班写代码,只是一到下班时间就蔫了,不得不应付编辑的催稿回家码字。
我在写作的中途,多次感受到存稿不足的压力,以致于需要请年假来填补写作的空缺。不过,最后做到了风雨无阻、节假无休地一周三更,也算是幸不辱命吧。
说回专栏吧。在思考专栏大纲时,我想着,最好能够和杨晓峰老师的Java核心技术专栏形成互补,呈现给大家的内容相对更偏向于技术实现。
因此,有读者曾反馈讲解的知识点是否太偏,不实用。当时我的回答是,我并不希望将专栏单纯写成一本工具书,这样的知识你可以从市面上任意买到一本书获得。
我更希望的是,能够通过介绍Java虚拟机各个组件的设计和实现,让你之后遇到虚拟机相关的问题时,能够联想到具体的模块,甚至是对于其他语言的运行时,也可以举一反三相互对照。
不过,当我看到Aleksey Shipilev介绍JMH的讲座时,发现大部分的内容专栏里都有涉及。于是心想,我还能够在上述答复中加一句:看老外的技术讲座再也不费劲了。
还有一个想说的是关于专栏知识点的正确性。我认为虚拟机的设计可以写一些自己的理解,但是具体到目前HotSpot的工程实现则是确定的。
为此,几乎每篇专栏我都会大量阅读HotSpot的源代码,和同事讨论实现背后的设计理念,在这个过程中,我也发现了一些HotSpot中的Bug,或者年久失修的代码,又或者是设计不合理的地方。这大概也能够算作写专栏和我本职工作重叠的地方吧。
我会仔细斟酌文章中每一句是否可以做到达意。即便是这样,文章肯定还有很多不足,比如叙述不够清楚,内容存在误导等问题。许多读者都热心地指了出来,在此感谢各位的宝贵意见。接下来一段时间,我会根据大家的建议,对前面的文章进行修订。
专栏虽然到此已经结束了,但是并不代表你对Java虚拟机学习的停止, 我想,专栏的内容仅仅是为你打开了JVM学习的大门,里面的风景,还是需要你自己来探索。在文章的后面,我列出了一系列的Java虚拟机技术的相关博客和阅读资料,你仍然可以继续加餐。
你可以关注国内几位Java虚拟机大咖的微信公众号:R大,个人认为是中文圈子里最了解Java虚拟机设计实现的人,你可以关注他的知乎账号;你假笨,原阿里Java虚拟机团队成员,现PerfMa CEO;江南白衣,唯品会资深架构师;占小狼,美团基础架构部技术专家;杨晓峰,前甲骨文首席工程师。
如果英文阅读没问题的话,你可以关注Cliff Click、Aleksey Shipilëv(他的JVM Anatomy Park十分有趣)和Nitsan Wakart的博客。你也可以关注Java Virtual Machine Language Submit和Oracle Code One(前身是JavaOne大会)中关于Java虚拟机的演讲,以便掌握Java的最新发展动向。
当然,如果对GraalVM感兴趣的话,你可以订阅我们团队的博客。我会在之后考虑将文章逐一进行翻译。
如果这个专栏激发了你对Java虚拟机的学习热情,那么我建议你着手去阅读HotSpot源代码,并且回馈给OpenJDK开源社区。这种回馈并不一定是提交patch,也可以是Bug report或者改进建议等等。
我也会不定期地在本专栏中发布新的Java虚拟机相关内容,你如果有想要了解的内容,也可以给我留言反馈。
最后,感谢一路以来的陪伴与支持,谢谢你,我们后会有期!
