01|中间件生态(上):有哪些类型的中间件?
作者: 丁威

你好,我是丁威。
最近十年是互联网磅礴发展的十年,IT系统从单体应用逐渐向分布式架构演变,高并发、高可用、高性能、分布式等话题变得异常火热,中间件也在这一时期如雨后春笋般涌现出来,那到底什么是中间件呢?存在哪些类型的中间件呢?同一类型的中间件,我们该怎么选择?接下来的两节课,我们就来聊聊这些问题。
中间件的种类很多,我们无法把所有类型和产品列出来逐一讲解。但是每个类别的中间件在设计原理、使用上有很多共同的考量标准,只要了解了最重要、最主流的几种中间件,我们就可以方便地进行知识迁移,举一反三了,然后学习其他中间件将变得非常简单。
所以呢,你可以把这两节课看作是提纲挈领的知识清单。下面我们讲到的中间件你不一定都能够用上,但在需要的时候,可以帮你从更加高屋建瓴的角度迅速决策。
什么是中间件?
先来说说什么是中间件,我认为中间件是游离于业务需求之外,专门为了处理项目中涉及高可用、高性能、高并发等技术需求而引入的一个个技术组件。它的一个重要作用就是能够实现业务代码与技术功能之间解耦合。
这么说是不是还有点抽象?在这里定义里,我提到了业务需求和技术需求,关于这两个词我需要再解释一下。
业务需求,笼统地说就是特定用户的特定诉求。以我们快递行业为例:人与人之间需要跨城市传递物品,逢年过节我们需要给远方的亲人寄礼物,这就是所谓的业务需求。
技术需求,就是随着业务的不断扩展,形成规模效应后带来的使用上的需求。例如上面提到的寄件服务,原先只需要服务1万个客户,用户体验非常好,但现在需要服务几个亿的用户,用户在使用的过程中就会出现卡顿、系统异常等问题,因此产生可用性、稳定性方面的技术诉求。
为了解决各式各样的业务和技术诉求,代码量会越来越多。如果我们任凭业务代码与技术类代码没有秩序地纠缠在一起,系统会变得越来越不可维护,运营成本也会成指数级增加,故障频发,最终直接导致项目建设失败。
怎么解决这个问题呢?计算机领域有一个非常经典的分层架构思想,还有这样一句话“计算机领域任何一个问题都可以通过分层来解决,如果不行,那就再增加一层。”要想让系统做得越来越好,我们通常会基于分层的架构思想引入一个中间层,专门来解决可用性、稳定性、高性能方面的技术类诉求,这个中间层就是中间件,这也正是“中间件”这个词的来源。
中间件生态漫谈
明白了中间件的内涵,我们再来看看市面上有哪些中间件。我在开篇词中已经提到过了,中间件的种类繁多,我整理了一版分布式架构体系中常见的中间件,你可以先打开图片仔细看一看。
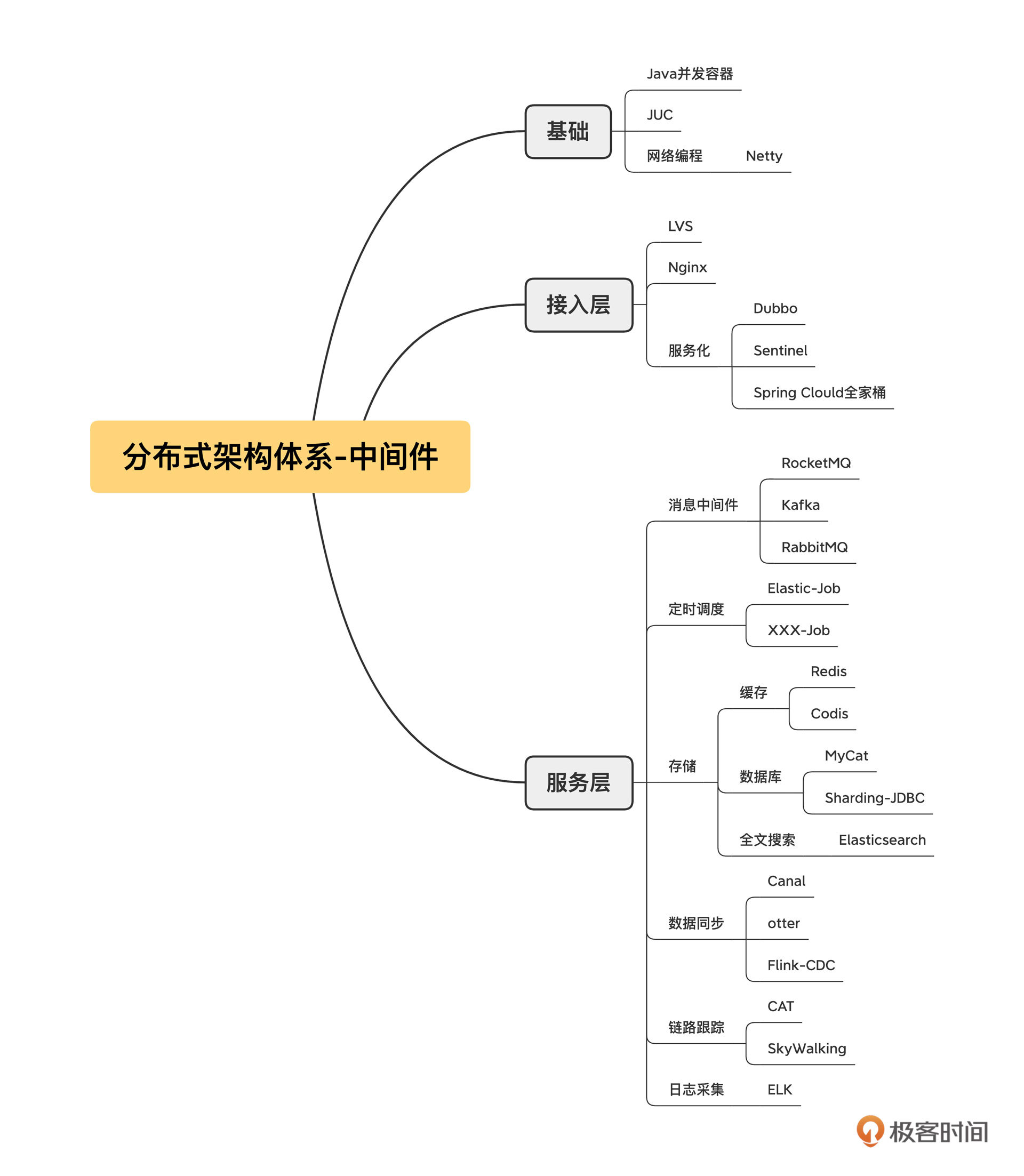
结合我10多年的从业经验,特别是对互联网主流分布式架构体系的研读,我发现微服务中间件、消息中间件、定时调度的使用频率极高,在解决分布式架构相关问题中是排头兵,具有无可比拟的普适性。这三者的设计理念和案例能对分布式、高可用和高并发等理念实现全覆盖。
所以,在专栏的第三章到第五章,我会深度剖析微服务、消息中间件和定时调度这三个方向,结合生产级经典案例深入剖析它们的架构设计理念,带你扎实地掌握分布式架构设计相关的基本技能。
- 微服务
具体而言,作为软件架构从单体应用向分布式演进出现的第一个新名词,微服务涉及分布式领域中服务注册、服务动态发现、RPC调用、负载均衡、服务聚合等核心技术,而Dubbo在微服务领域是当仁不让的王者。所以在微服务这一部分,我们会以Dubbo为例进行实战演练。
- 消息中间件
随着微服务的蓬勃发展,系统的复杂度越来越高,加上互联网秒杀、双十一、618等各种大促活动层出不穷,我们急切需要对系统解耦和应对突发流量的解决办法,这时候消息中间件应运而生了,它同样成为我们架构设计工作中最常用的工具包。常用的消息中间件包括RocketMQ、Kafka,它们在适用性上有所不同,如何保障消息中间件的稳定性是一大挑战。
- 定时调度
而定时调度呢?我们既可以认为它是个技术需求,也可以认为它是一个业务类需求,通过研读ElasticJob、XXL-Job等定时调度框架,可以很好地提升我们对业务需求的架构设计能力。
这三部分我们会在后面的模块中重点展开,所以这一模块不做深入讲解。接下来,为了让你对主流中间件有一个更全面的认知,我会分两节课对另外的几类中间件(数据库、缓存、搜索、日志等)进行简要阐述,以补全你的中间件知识图谱,帮助你更加有底气、有效率地进行决策。这节课,我们先来看看数据库中间件。
数据库中间件
数据库中间件应该是我们接触得最早也是最为常见的中间件,在引入数据库中间件之前,由于单体应用向分布式架构演进的过程中单表日数据急速增长,单个数据库的节点很容易成为系统瓶颈,无法提供稳定的服务。因此,为了解决可用性问题,在技术架构领域通常有如下两种解决方案:
- 读写分离;
- 分库分表。
我们先分别解析下这两个方案。最后再来看一看,引入数据库中间件给技术带来的简化。
读写分离
这是我在没有接触中间件之前,在一个项目中使用过的方案:
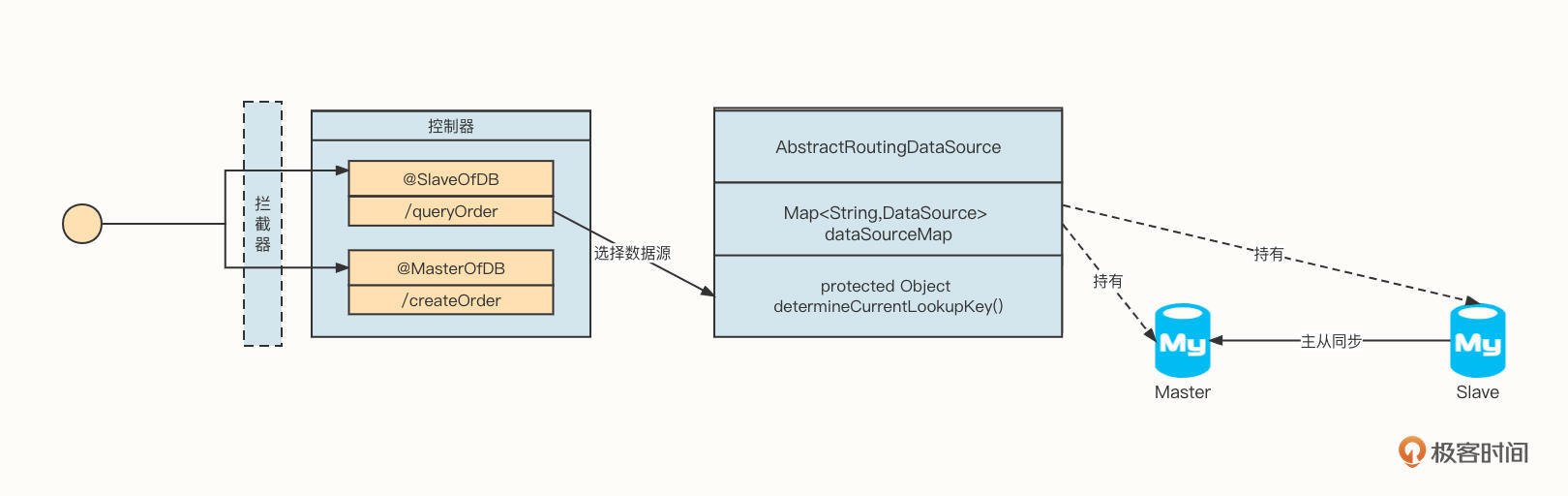
这个方案的实现要点有三个。
第一,在编写业务接口时,要通过在接口上添加注解来指示运行时应该使用的数据源。例如,@SlaveofDB表示使用Slave数据库,@MasterOfDB表示使用主库。
第二,当用户发起请求时,要先经过一个拦截器获取用户请求的具体接口,然后使用反射机制获取该方法上的注解。举个例子,如果存在@SlaveofDB,则往线程上下文环境中存储一个名为dbType的变量,赋值为slave,表示走从库;如果存在@MasterOfDB,则存储为master,表示走主库。
第三,在Dao层采用Spring提供的路由选择机制,继承自AbastractRoutingDataSource。应用程序启动时自动注入两个数据源(master-slave),采用key-value键值对的方式存储。在真正需要获取链接时,根据上下文环境中存储的数据库类型,从内部持有的dataSourceMap中获取对应的数据源,从而实现数据库层面的读写分离。
总结一下,读写分离的思路就是通过降低写入节点的负载,将耗时的查询类请求转发到从节点,从而有效提升写入的性能。
但是,当业务量不断增加,单个数据库节点已无法再满足业务需求时,我们就要对数据进行切片,分库分表的技术思想就应运而生了。
分库分表
分库分表是负载均衡在数据库领域的应用,主要的原理你可以参考下面这张图。
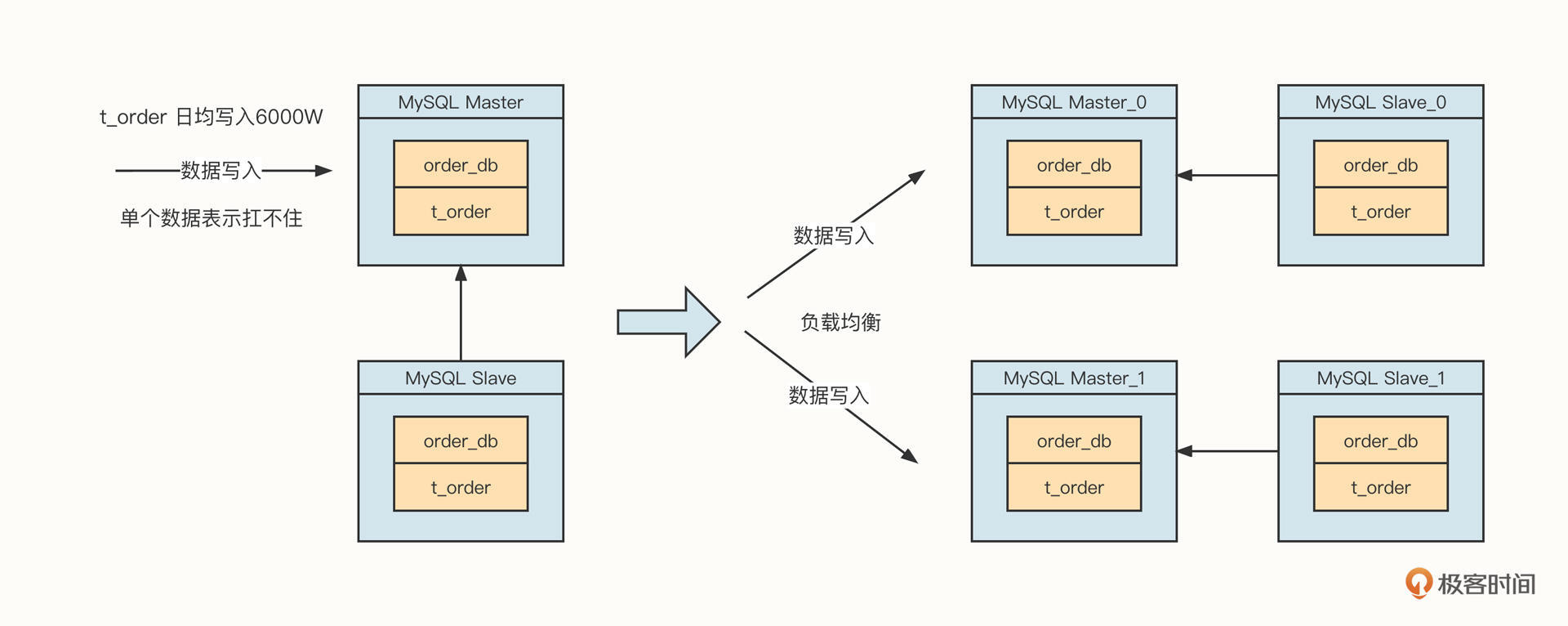
简单说明一下。分库分表主要是通过引入多个写入节点来缓解数据压力的。因此,在接受写入请求后,负载均衡算法会将数据路由到其中一个节点上,多个节点共同分担数据写入请求,降低单个节点的压力,提升扩展性,解决单节点的性能瓶颈。
不过,要实现数据库层面的分库分表还是存在一定技术难度的。因为分库分表和读写分离一样,最终要解决的都是如何选择数据源的问题。所以在分库分表方案中,首先我们要有两个算法。
- 一个分库字段和分库算法,即在进行数据查询、数据写入时,根据分库字段的值算出要路由到哪个数据库实例上;
- 一个分表字段和分表算法,即在进行数据查询、数据写入时,根据分表字段的值算出要路由到哪个表上。
不管是上面的分库、还是分表都需要解决一个非常关键的问题:SQL解析。你可以看下面这张图。
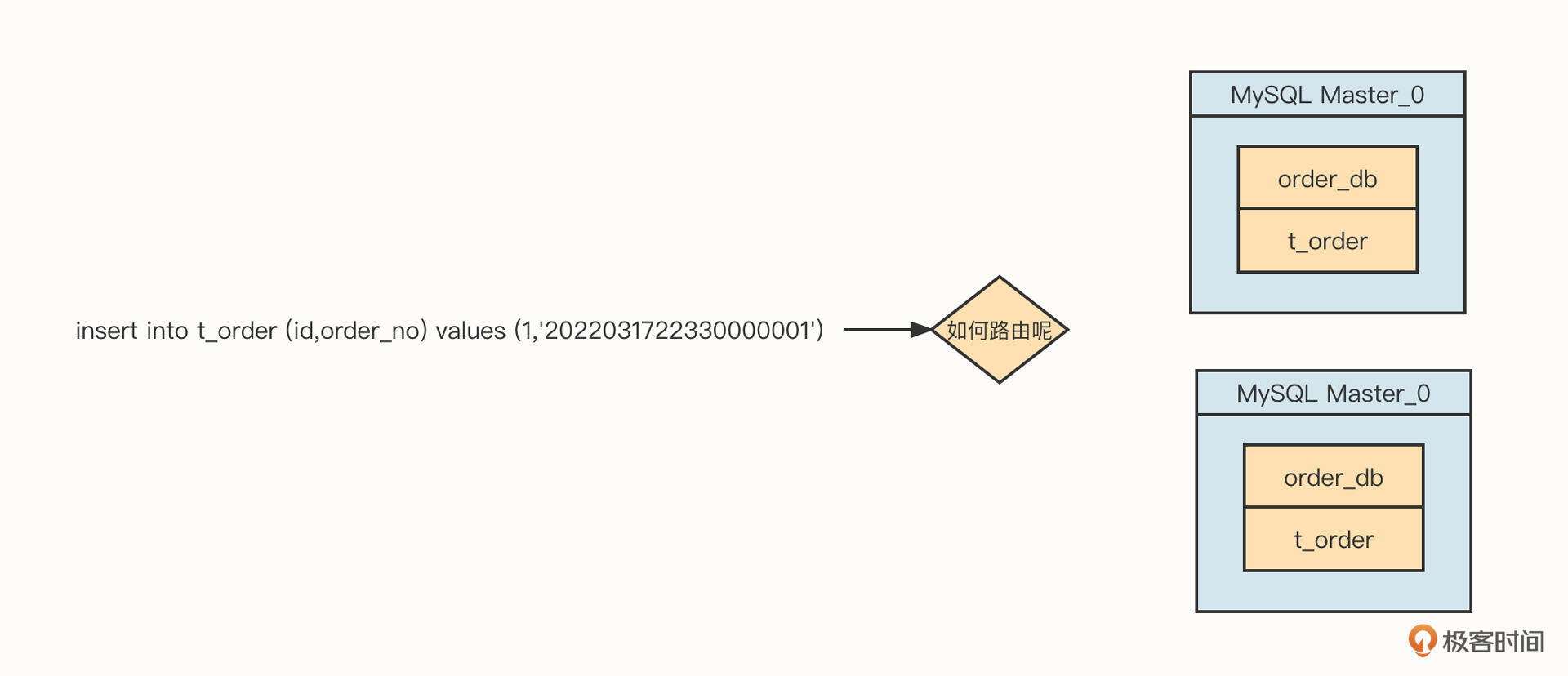
如果订单库的分库字段设置为order_no,要想正确执行这条SQL语句,我们首先要解析这条SQL语句,提取order_no的字段值,再根据分库算法(负载均衡算法)计算应该发送到哪一个具体的库上执行。
SQL语句语法非常复杂,要实现一套高性能的SQL解析引擎绝非易事,如果按照上面我提供的解决方案,将会带来几个明显的弊端。
- 技术需求会污染业务代码,维护成本高
在业务控制器中需要使用注解来声明读写分离按相关的规则进行,随着业务控制的不断增加、或者读写分离规则的变化,我们需要对系统所有注解进行修改,但业务逻辑其实并没有改变。这就造成两者之间相互影响,后期维护成本较高。
- 技术实现难度较大,极大增加开发成本
由于SQL语句的格式太复杂、太灵活,如果不是数据库专业人才,很难全面掌握SQL语法。在这样的情况下,你写出的SQL解析引擎很难覆盖所有的场景,容易出现遗漏最终导致故障的发生;这也给产品的性能带来极大挑战。
那怎么办呢?其实,我们完全可以使用业界大神的开源作品来解决问题,这就要说到数据库中间件了。
引进数据库中间件
技术类诉求往往是相通的,极具普适性,为了解决上面的通病,根据分层的架构理念,我们通常会引入一个中间层,专门解决数据库方面的技术类需求。
MyCat 和ShardingJDBC/ShardingSphere是目前市面最主流的两个数据库中间件,二者各有优势。
MyCat服务端代理模式
先来看下MyCat代理数据库。它的工作模式可以用下面这张图概括:
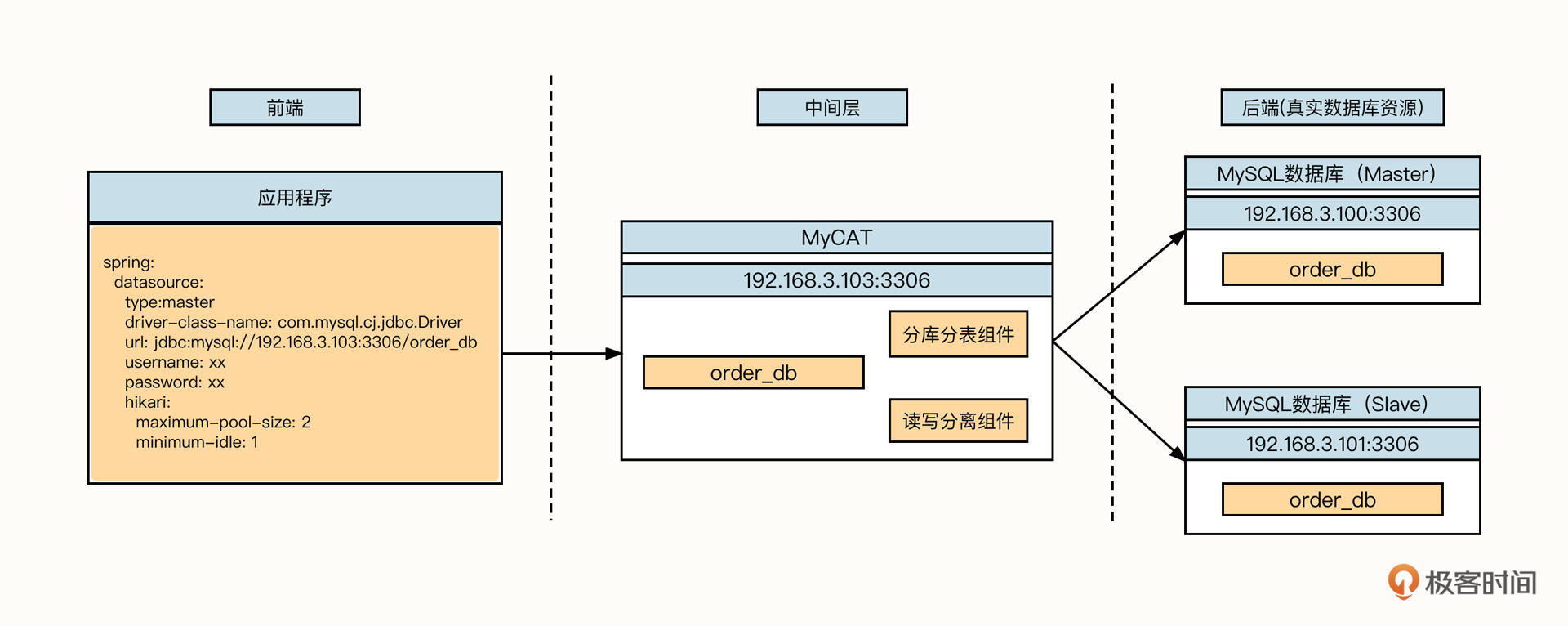
面对应用程序,MyCat会伪装成一个数据库服务器(例如MySQL服务端)。它会根据各个数据库的通信协议,从二进制请求中根据协议进行解码,然后提取SQL,并根据配置的分库分表、读写分离规则计算出需要发送到哪个物理数据库。
随后,面对真实的数据库资源,MyCat会伪装成一个数据库客户端。它会根据通信协议将SQL语句封装成二进制流,发送请求到真实的物理资源,真实的物理数据库收到请求后解析请求并进行对应的处理,再将结果层层返回到应用程序。
这种架构的优势是它对业务代码无任何侵入性,应用程序只需要修改项目中数据库的连接配置就可以了,而且使用简单,易于推广。同时它也有劣势:
- 存在性能损耗
数据库中间件需要对应用程序发送过来的请求进行解码并计算路由,随后它还要再次对请求进行编码并转发到真实的数据库,这就增加了性能开销。
- 高度中心化,数据库中间件容易成为性能瓶颈
数据库中间件需要处理所有的数据库请求,返回结果都需要在数据库中进行聚合,虽然减少了后端数据库的压力,但中间件本身很容易成为系统的瓶颈,扩展能力受到一定制约。
- 代理层实现复杂,普适性差
数据库中间件本身的实现比较复杂,需要适配市面上各主流数据库,例如MySQL、Oracle等,通用性大打折扣。
ShardingJDBC客户端代理模式
下面我们再来看下ShardingJDBC客户端代理数据库。ShardingJDBC的工作模式如下图所示:
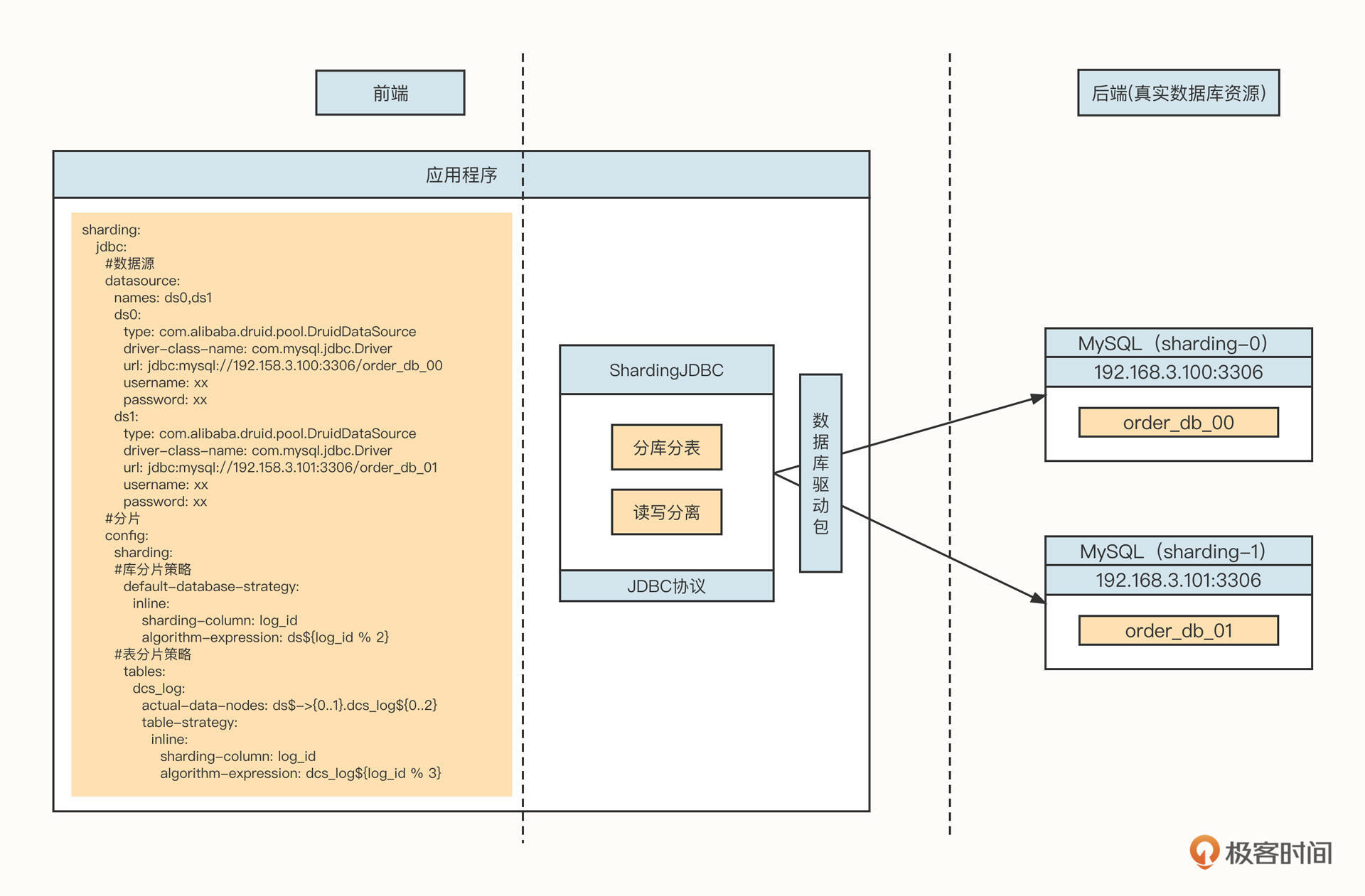
ShardingJDBC主要实现的是JDBC协议。实现JDBC协议,其实主要是面向java.sql.Datasource、Connection、ResultSet等对象编程。它通常以客户端Jar包的方式嵌入到业务系统中,ShardingjJDBC根据分库分表的配置信息,初始化一个ShardingJdbcDatasource对象,随后解析SQL语句来提取分库、分表字段值,再根据配置的路由规则选择正确的后端真实数据库,最后,ShardingJDBC用各种类型数据库的驱动包将SQL发送到真实的物理数据库上。
我们同样来分析一下这个方案的优缺点。
主要的优势有如下几点:
- 无性能损耗
ShardingJDBC使用的是基于客户端的代理模式,不需要对SQL进行编码解码等操作,只要根据SQL语句进行路由选择就可以了,没有太多性能损耗。
- 无单点故障、扩展性强
ShardingJDBC以Jar包的形式存在于项目中,其分布式特性随着应用的增加而增加,扩展性极强。
- 基于JDBC协议,可无缝支持各主流数据库
JDBC协议是应用程序与关系型数据库交互的业界通用标准,市面上所有关系型数据库都天然支持JDBC,故不存在兼容性问题。
当然缺点也很明显,对于分库分表,它没有一个统一的视图,运维类成本较高。举个例子,如果订单表被分成了1024个表,这时候如果你想根据订单编号去查询数据,必须人为计算出这条数据存在于哪个库的哪个表中,然后再去对应的库上执行SQL语句。
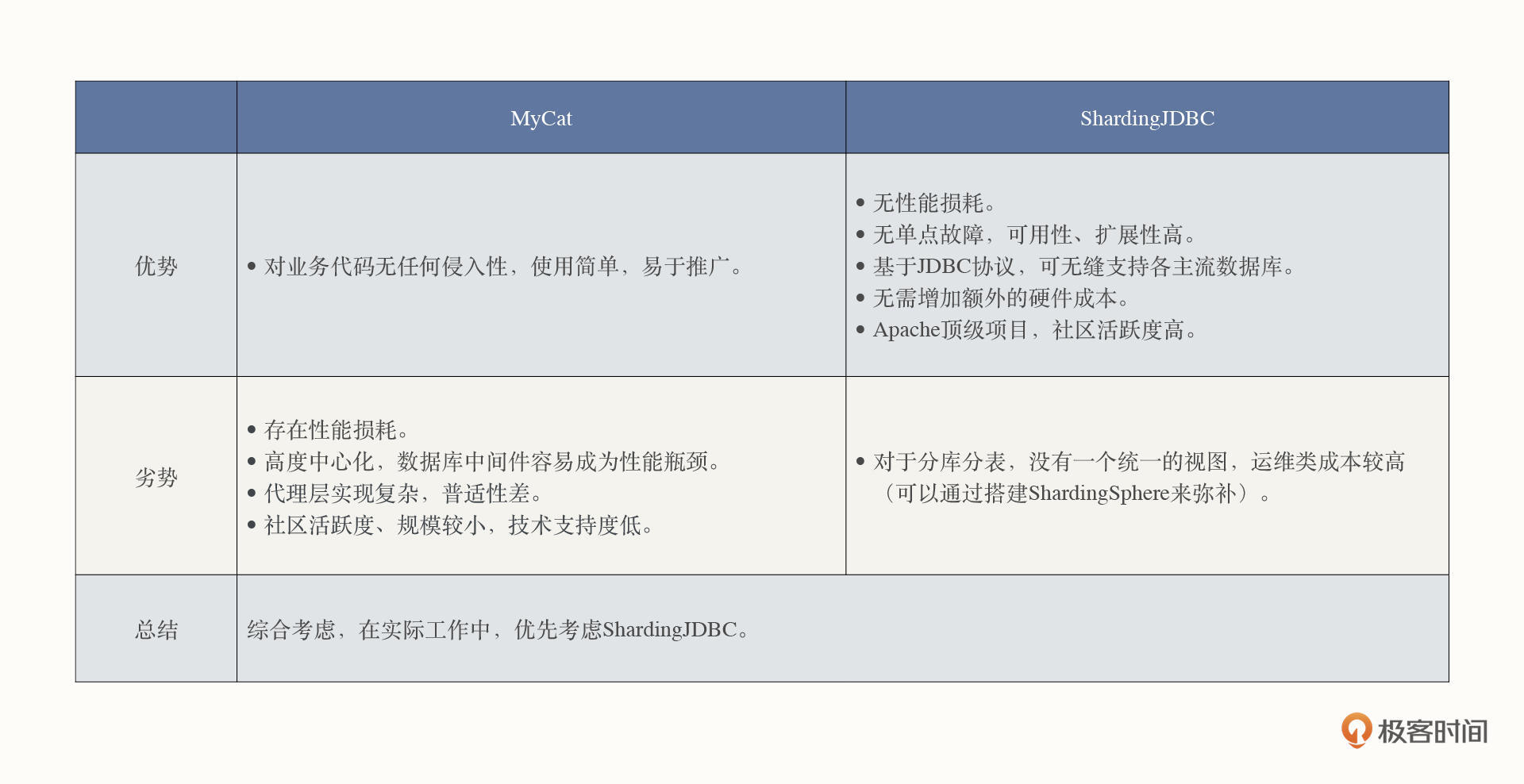
为了解决ShardingJDBC存在的问题,官方提供了ShardingSphere,其工作机制基于代理模式,与MyCat的设计理念一致,作为数据库的代理层,提供统一的数据聚合层,可以有效弥补ShardingJDBC在运维层面的缺陷,因此项目通常采用ShardingDBC的编程方式,然后再搭建一套ShardingSphere供数据查询。
在没有ShardingSphere之前,使用MyCat也有一定优势。MyCat对业务代码无侵入性,接入成本也比较低。但ShardingSphere弥补了ShardingJDBC对运维的不友好,而且它的性能损耗低、扩展性强、支持各类主流数据库,可以说相比MyCat已经占有明显的优势了。
所以如果要在实践生产中选择数据库中间件,我更加推荐ShardingJDBC。
除了上面的原因,从资源利用率和社区活跃度的角度讲,首先,MyCat的“前身”是阿里开源的Cobar,是数据库中间件的开山鼻祖,技术架构稍显古老,而ShardingJDBC在设计之初就可以规避MyCat的固有缺陷,摒弃服务端代理模式。代理模式需要额外的机器搭建MyCat进程,引入了新的进程,势必需要增加硬件资源的投入。
其次,ShardingJDBC目前已经是Apache的顶级项目,它的社区活跃度也是MyCat无法比拟的。一个开源项目社区越活跃,寻求帮助后问题得到解决的概率就会越大,越多人使用,系统中存在的Bug也更容易被发现、被修复,这就使得中间件本身的稳定性更有保障。
总结
好了,这节课就讲到这里,我们来做个小结。通过刚才的学习,我们知道了中间件的概念,它是为了解决系统中的技术需求,将技术需求与业务需求进行解耦,让我们专注于业务代码开发的一个个技术组件。中间件的存在,就是为了解决高并发、高可用性、高性能等各领域的技术难题。
在项目中,合理引用中间件能极大提升我们系统的稳定性、可用性,但同时也会提升系统维护的复杂度,对我们的技术能力提出了更高的要求,我们必须要熟练掌握项目中引用的各种中间件,深入理解其工作原理、实现细节,提高对中间件的驾驭能力,否则一旦运用不当,很可能给系统带来灾难性的故障。
为了让你对中间件有一个更加宏观的认识,我给你列举了市面最为常用的中间件。虽然现在新的中间件层出不穷,但在我看来,大都不超过我列的这几类。这节课我们重点讲了两个主流的数据库中间件,下节课,我们再来解读缓存、全文索引、分布式日志这几类中间件。
课后题
学完这节课,我也给你出两道课后题吧!
1.从数据库中间件的演变历程中,你能提炼出哪些分布式架构设计理念?
2.请你以订单业务场景,搭建一个2库2表的ShardingSphere集群,实现数据的插入、查询功能。
如果你想要分享你的修改或者想听听我的意见,可以提交一个 GitHub的push请求或issues,并把对应地址贴到留言里。我们下节课见!
02|中间件生态(下):同类型的中间件如何进行选型?
作者: 丁威

你好,我是丁威。
这节课,我们继续中间件生态的讲解。
缓存中间件
纵观整个计算机系统的发展历程,不难得出这样一个结论:缓存是性能优化的一大利器。
我们先一起来看一个用户中心查询用户信息的基本流程:
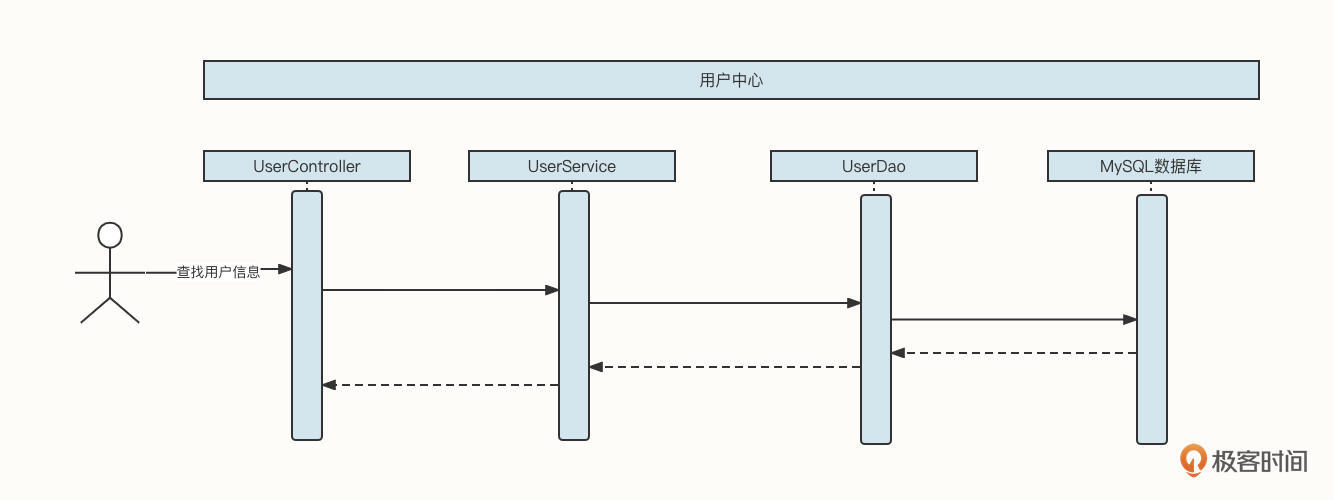
这时候,如果查找用户信息这个API的调用频率增加,并且在整个业务流程中,同一个用户的信息会多次被调用,那么我们可以引入缓存机制来提升性能:
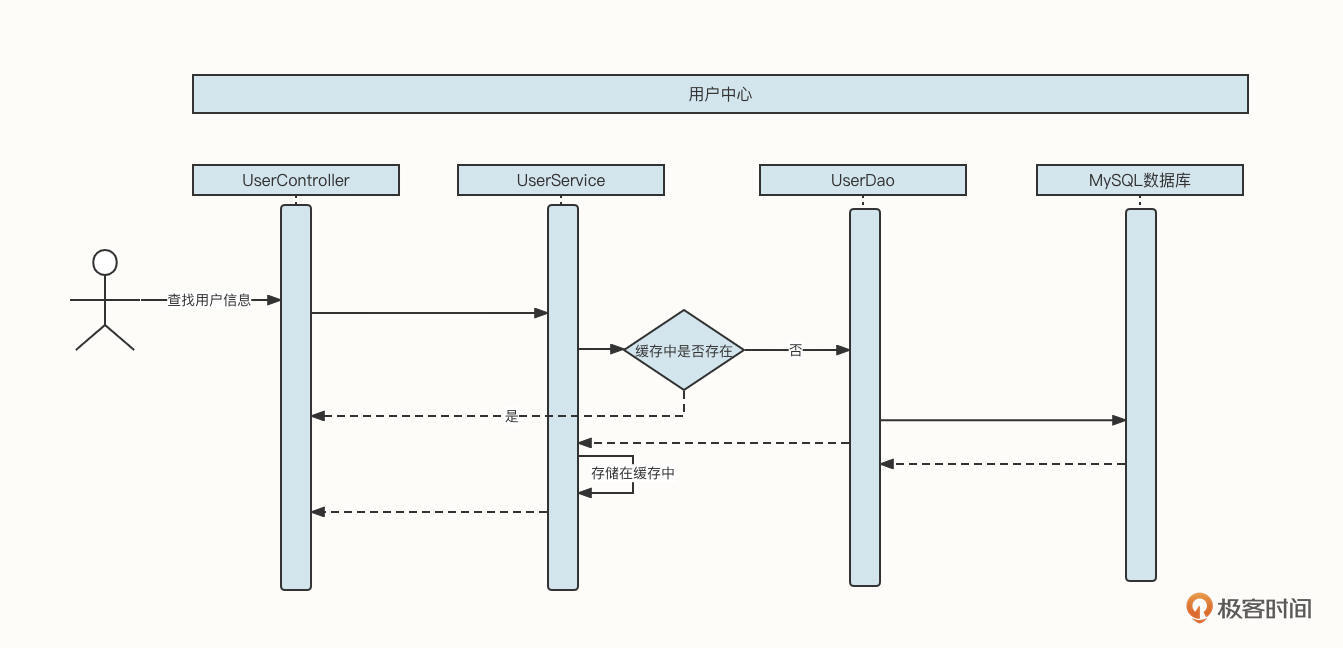
也就是说,在UserService中引入一个LinkedHashMap结构的内存容器,用它存储已经查询到的数据。如果新的查询请求能命中缓存,那么我们就不需要再查询数据库了,这就降低了数据库的压力,将网络IO、磁盘IO转变为了直接访问内存,性能自然而然也提升了。
但上面这个方案实在算不上一个优秀的方案,因为它考虑得非常不全面,存在下面这几个明显的缺陷:内存容量有限、容易引发内存溢出,缓存在节点之间不一致,数据量非常庞大。
上面每一个问题都会带来巨大的影响,如果我们每做一个业务系统,都需要花这么多精力去解决这些技术问题,那这个成本也是不可估量的。为了解决与缓存相关的技术诉求,市面上也涌现出了一些非常优秀的中间件。缓存中间件经历了从本地缓存到分布式缓存的演变历程,我们先来看本地缓存中间件。
本地缓存中间件
本地缓存与应用属于同一个进程,主要的优势是没有网络访问开销,其中Ehcache、Guava Cache与Caffeine是Java领域当下比较知名的本地缓存框架。由于Ehcache比较耗磁盘空间,并且在进程宕机后容易造成缓存数据结构破坏,只能通过重建索引的方式进行修复,所以目前我们主要使用Guava Cache和Caffeine,他们之间并没有明显的优劣势。
尽管内部实现细节不同,但本地缓存中间件基本都需要包含下面三个功能。
支持大容量。
它们基本都会采取内存+磁盘两级存储模型,其中内存存放热数据,磁盘存放全量数据。
过期/淘汰机制。
评估缓存对性能提升程度的一个重要依据就是缓存的命中率。如果用户每次访问都无法命中缓存,相当于缓存没有起到效果,存储的数据都是“无用”的数据,只会带来存储空间的浪费。所以,必须引入缓存过期机制,删除不常用的数据。
基本的数据统计功能。
监控数据的主要目的是检测当前缓存的工作状态是否健康,需要检测的内容包括缓存命中率、内存空间使用情况、磁盘空间使用情况等。
总的来说,本地缓存对单体应用非常友好,但对分布式应用就会显得有点浪费资源,为什么这么说呢?你可以先看看下面这张图。
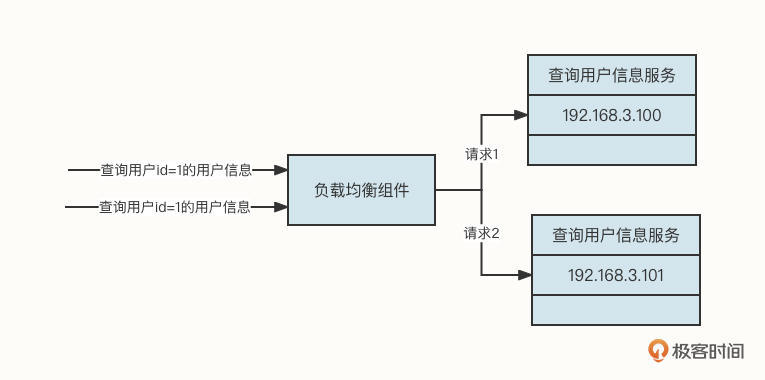
在这张图中,当连续两次查询用户ID为1的用户信息时,受到负载均衡组件的影响,其中一个请求会转发到192.168.3.100,另外一个请求会转发到192.168.3.101。这样,同一个用户的信息会在两台机器上分别缓存一份数据。
而且,如果数据发生变化,也需要通知多台机器同时刷新缓存,这就造成了资源浪费。因此,本地缓存更适合存储一些变化频率极低,数据量较小的场景,诸如基础数据、配置了类型的数据缓存等。
分布式缓存中间件
本地缓存属于单进程管理的范畴,存在单点故障与资源瓶颈,无法应对数据的持续增长。为了适应分布式架构的特点,市面上也出现了一批基于内存存储的分布式存储框架。
由于分布式缓存与应用进程分属不同的进程,存在网络访问开销,所以几乎各个缓存中间件都是基于内存存储的系统,它们的存储容量受限于机器内存容量。
为了解决存储方面的瓶颈,各个分布式缓存中间件都支持集群部署。分布式缓存中间件中比较出名的非Redis与Memcached莫属。我们以Redis为例,来看一下经典的分布式缓存部署架构:
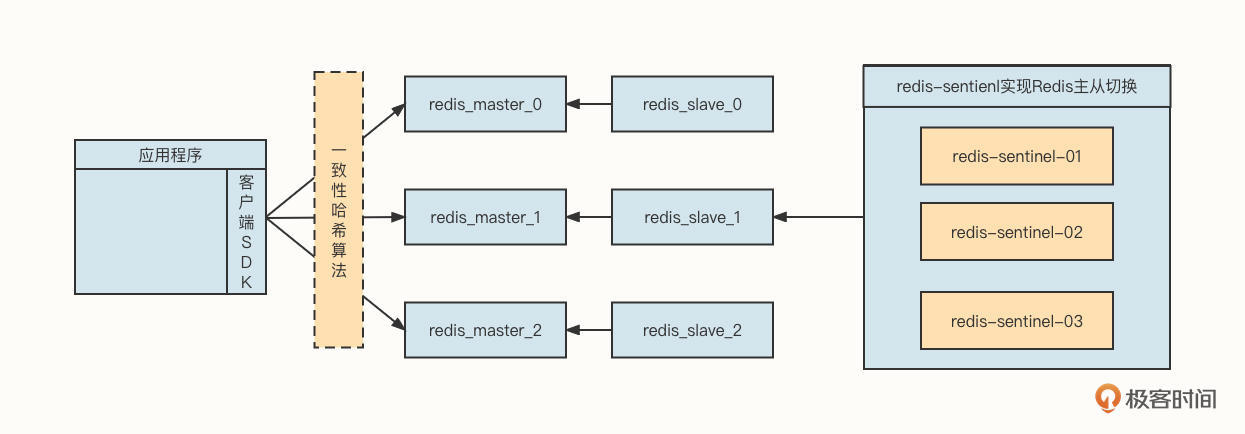
从这张图中,我们可以提取出下面几个要点。
首先,客户端通常会使用一致性哈希算法进行负载均衡,主要是为了提高节点扩容、缩容时的缓存命中率。
第二,Redis采用主从同步模式,这可以提升数据的存储可靠性。如果是像Memcache这种不能持久化的中间件,进程一旦退出,存储在内存中的数据将会丢失,就要重新从数据库加载数据,这会让大量流量在短时间内穿透到数据库,造成数据库层面不稳定。
第三,单台Redis受限于机器内存的容量限制,通常会采用集群部署,即每一个节点存储部分数据。
第四,为了提升 Redis 的 master-slave 高可用性能,降低由于master节点宕机导致的集群写入节点数量减少问题,通常会引入哨兵集群,使 master-slave 主从自动切换,进一步提升缓存中间件的高可用性。
那么,同为分布式缓存中间件,Redis和Memcached又有什么区别与联系呢?二者的共同点是,它们都是基于内存访问的高性能缓存存储系统,具有高并发、低延迟特性。
但它们的不同点也很多,我总结为了以下四点。
- 数据类型:Redis支持丰富的数据类型,不仅支持key-value的存储结构,还支持List、Set等复杂数据结构,而Memcache只支持简单的数据类型。
- 数据持久化:Redis支持基于AOF、快照两种数据持久机制,持久化带来的好处便是进程重启后数据不会丢失,能有效防止缓存被击穿的风险;Memcache不支持数据持久化。
- 分布式存储:Redis自身支持master-slave、Cluster两种分布式存储架构,而Memcache自身并不支持集群部署,需要使用一致性哈希算法来构建集群。
- 线程模型:Redis命令执行采用单线程,故Redis不适合大Value值的存储,但借助Redis单线程模型可以非常方便地实现分布式锁等功能;Memcache基于多线程运行模型,可以充分利用多核CPU的并发优势,提升资源的利用率。
讲了这么多,要一下记住可能有点难度,我给你画了两张图,总结了刚才不同中间件的差异、适用场景,你可以保存下来随时回顾:
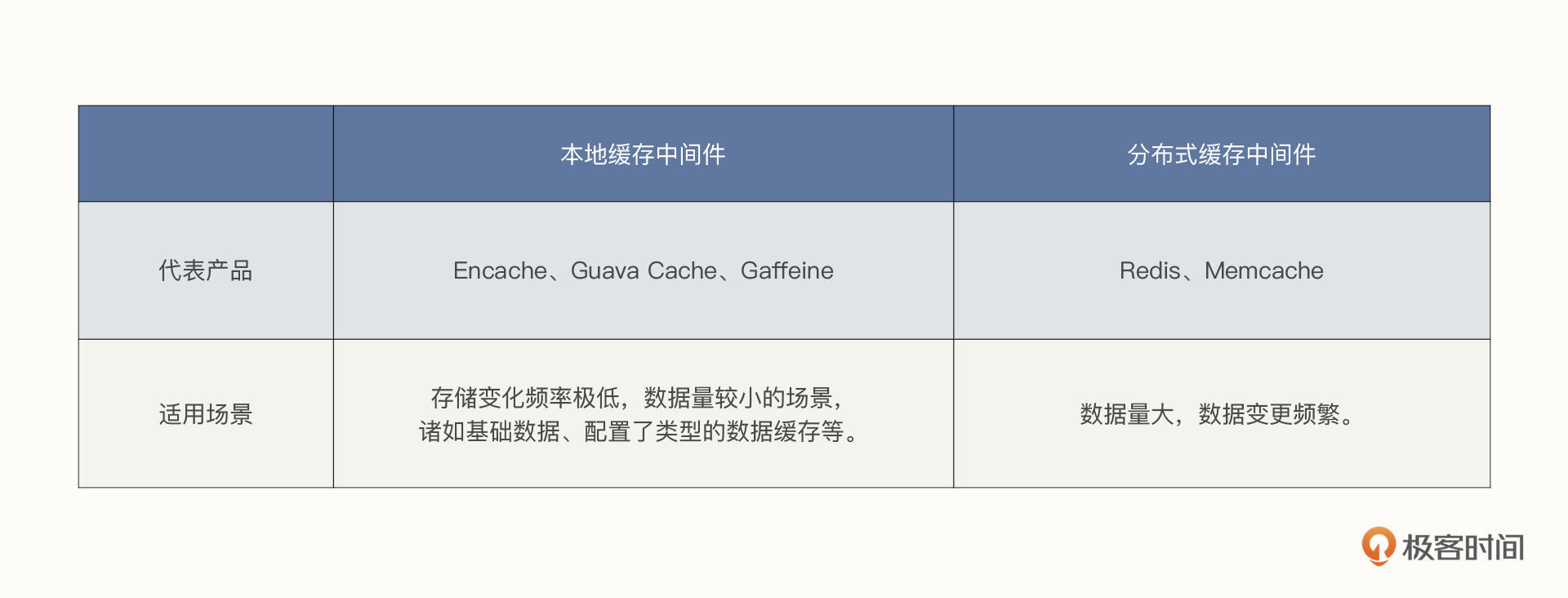
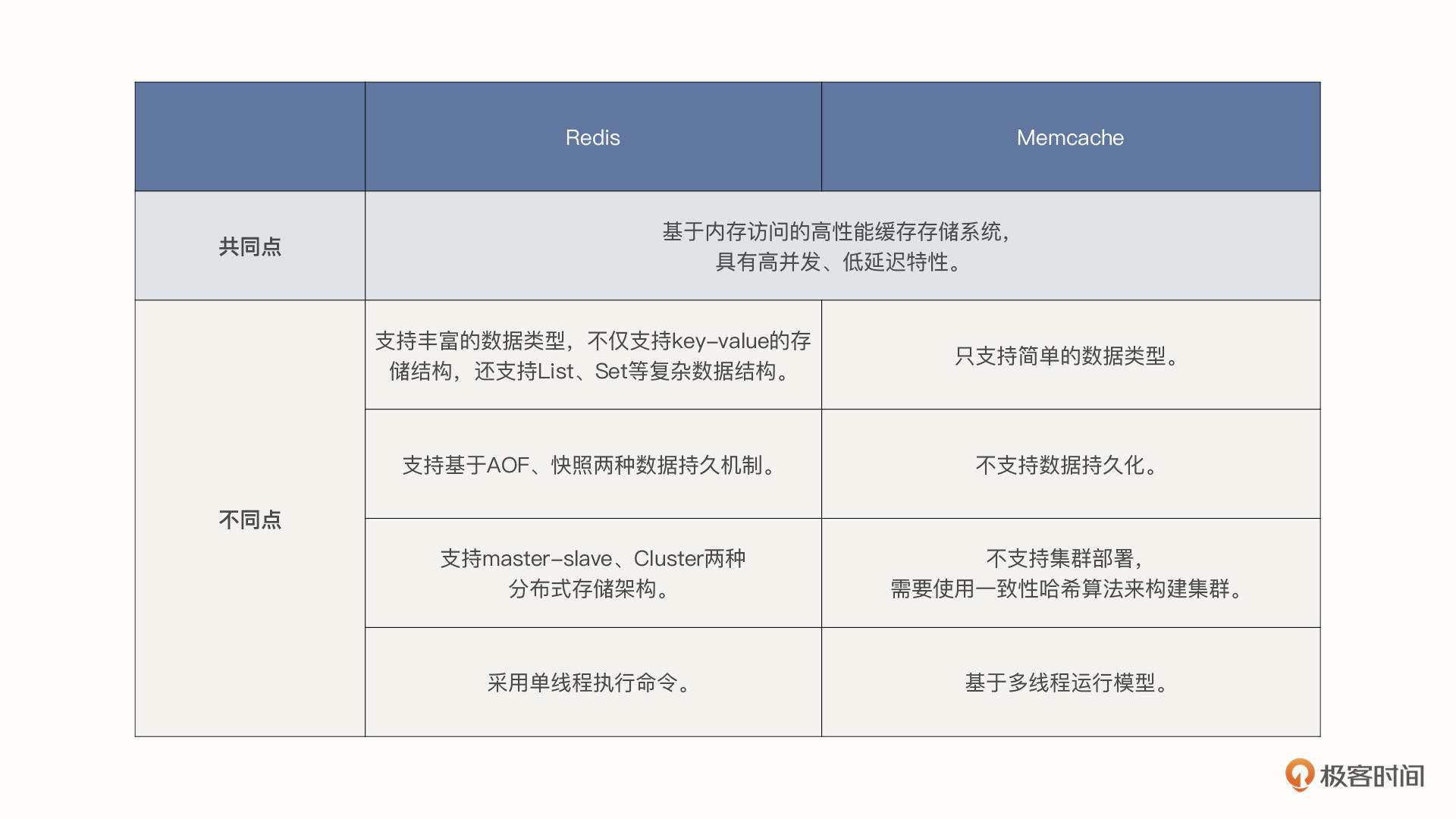
一句话总结,缓存框架是不断在演进的,在项目中引入缓存相关的中间件技术绝对是一个明智之举。在数据量较少,并且变更不频繁时,我建议你采用本地缓存,其他情况建议使用分布式缓存。
那如何在Redis与Memcache中进行选型呢?虽然技术选型我们需要结合业务场景来看,但从上述功能的对比来看,Redis基本在各个对比项中对Memcache呈“压制”态势,所以多数情况下,我建议你使用Redis。
全文索引中间件
Elasticsearch是一个基于Apache Lucene的开源且支持全文搜索的搜索引擎。
Lucene被公认为迄今为止性能最强、功能最齐全的搜索引擎库。但Lucene只是一个类库,只提供单机版本的搜索功能,无法与分布式计算、分布式存储等协调展开工作。为了适应分布式的架构体系,Elasticsearch应运而生。
Elasticsearch提供了强大的分布式文件存储能力、分布式实时分析搜索能力、实时全文搜索能力、强大的集群扩展能力,PB级别的结构化和非结构化数据处理能力。
Elasticsearch在分布式架构中有两个最常见的应用场景,一个是宽表、解决跨库Join,另一个就是全文搜索。接下来我们分别展开介绍。
在数据库领域,如果一个表的数据量庞大,我们通常会引入分库分表技术以提高可用性。但这会带来一个新的问题,就是数据关联、报表等查询会变得无比复杂,性能也无法得到保障。
我们以订单场景为例。在一个订单中通常会包含多个商品,一个非常经典的设计策略是会创建t_order与t_order_item表,其中t_order_item是torder的子表。但如果我们使用了分库分表技术,关联查询将变得非常复杂:
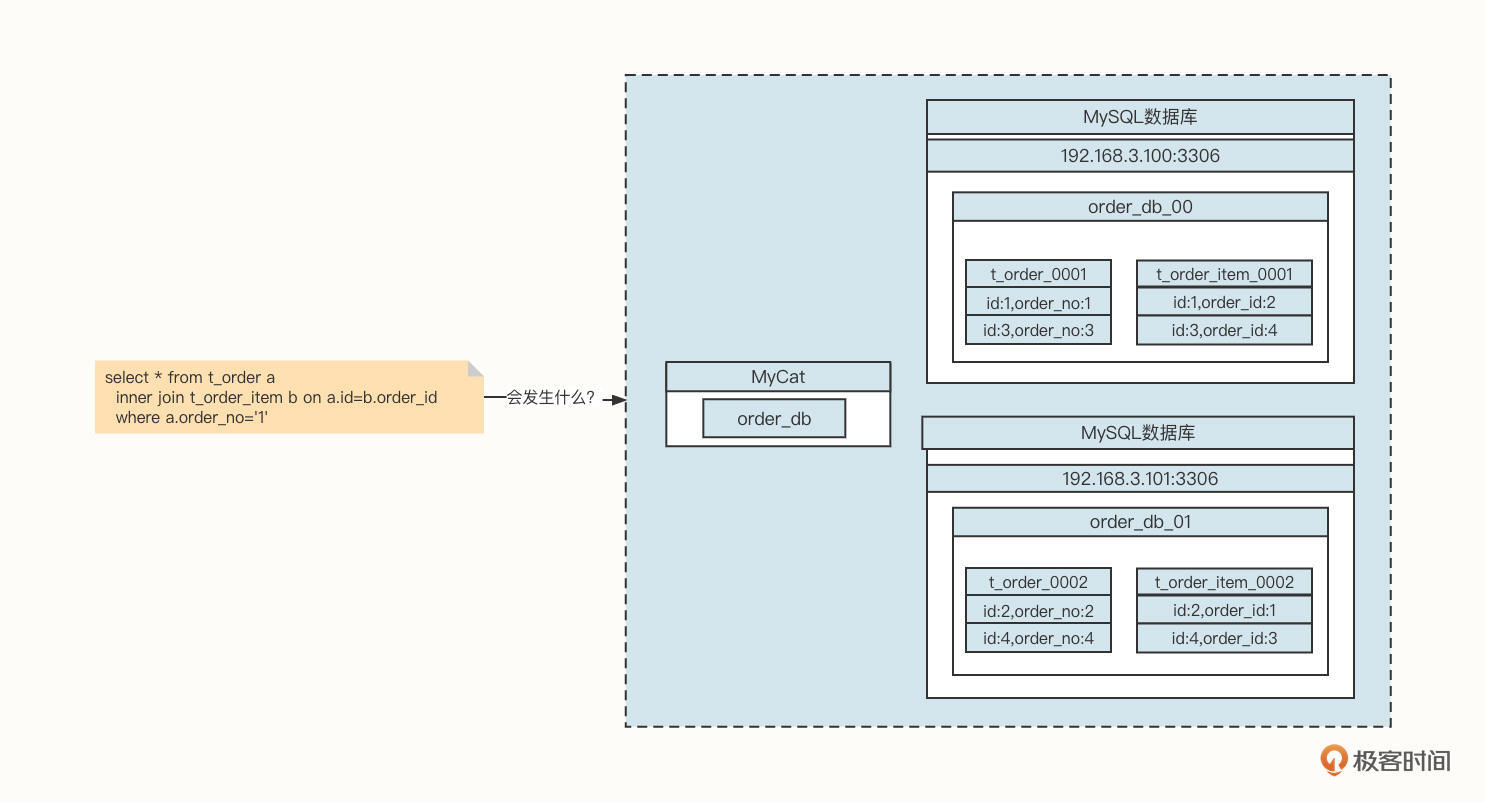
看一下上面这张图片,想象一下,如果应用程序发送一条Join语句给数据库,会发生什么事情呢?
由于订单编号为1的订单信息存储在order_db_00中,但与这条订单关联的订单字表却存储在order_db_01中,而Join操作需要的笛卡尔积操作存在于不同的数据库实例中,所以我们就要将多个数据库中的数据统一加载到内存中。这就需要创建众多对象,如果需要加载的数据庞大,无疑会导致内存竞争,垃圾回收加剧,性能将直线下降。
我相信你一定能想到这个问题的解法:用ER分库思想,让具有关联性的表使用字段相同的分片算法。例如上面的示例,我们可以将t_order、t_order_item两个表的分库字段都设置为订单ID,这样一来,同一订单id的父子数据都在同一个数据库实例中,就避免了跨库Join,可以让性能得到很大提升。
但真实的应用场景比这个要复杂很多,面对的用户不同,他们的诉求也不一样。
我们还是说回订单系统。
- 从买家的角度出发,我们希望同一个买家的订单数据(父子关联表)能够采用同样的分库策略,以此保证同一个买家的订单关联数据存储在同一个库中,这样买家在查询订单时不必跨库。
- 但是如果采用这种策略,从商家的角度出发就会发现,商家在查询商家订单信息、商家日订单报表、月订单报表时要查询多个数据库,甚至可能产生跨库Join的风险。这无疑会降低性能,严重时会使整个数据库变得不可用。
用一句话概述就是,分库分表在面对多维度查询时将变得力不从心,那该如何解决呢?
我们通常会引入数据异构+宽表的设计方案:
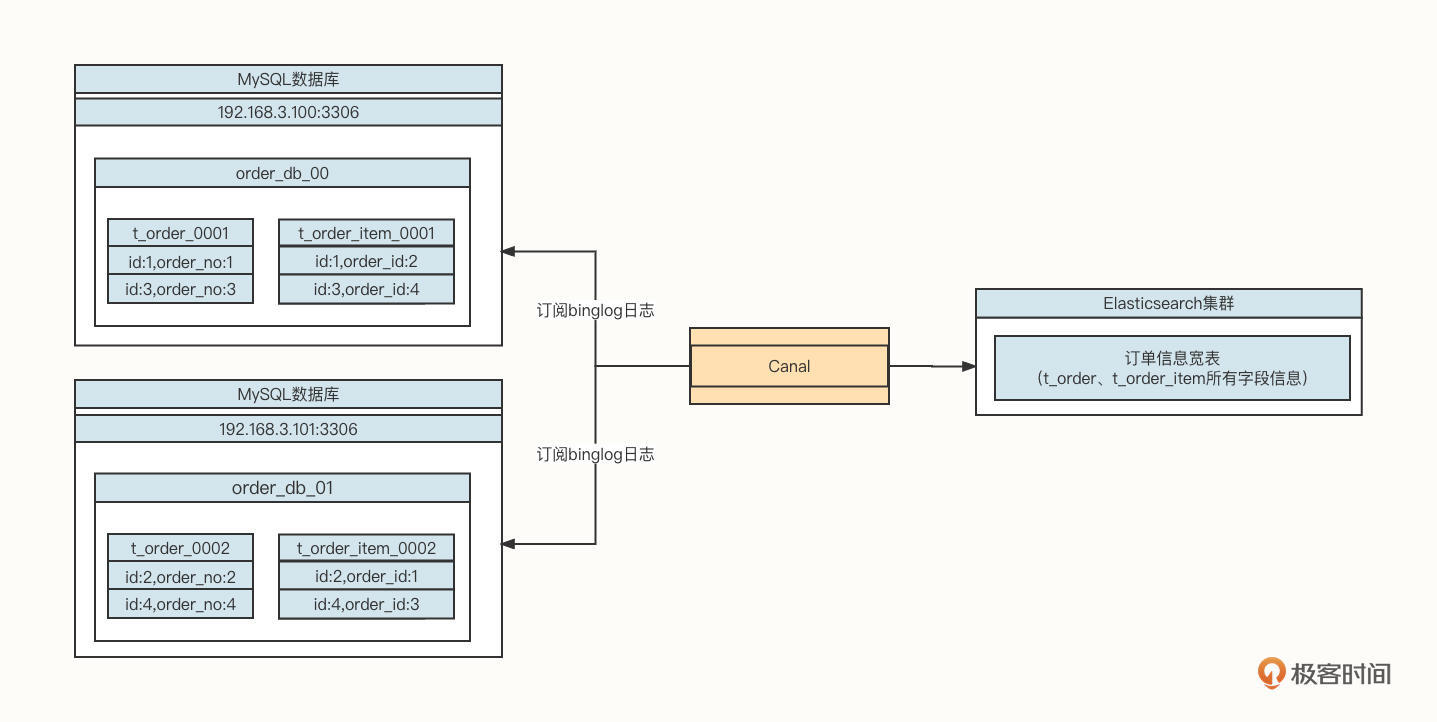
我们需要引入Canal数据同步工具,订阅MySQL的Binglog,将增量数据同步到Elasticsearch中,实现数据访问层面的读写分离。
ElasticSearch另外一个场景就是全文搜索。
我们以电商场景为例,用户在购买商品之前通常需要输入一些关键字搜索出符合自己期望的数据,例如商品表的表结构如下图所示:
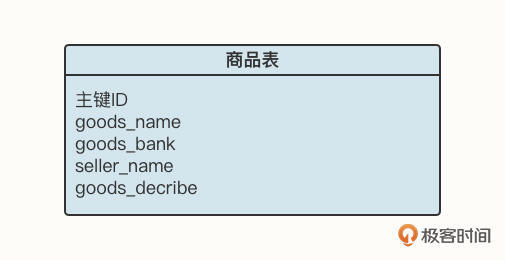
如果我们要查询关键字为“苹果电脑”,基于关系型数据库,我们通常会写出这样的SQL语句:
1 | select * from goods a where a.goods_decribe like '%苹果电脑%'; |
运行上述代码,如果商品数量少那倒没关系,但如果是淘宝、天猫、京东等一线电商平台,需要存储海量商品信息,在商品库中运行上述SQL,对数据库来说就是一个“噩梦”,因为上述语句并不会走索引,容易很快耗尽数据库链接而导致系统不可用。
这个时候,使用Elasticsearch就是一个非常明智的选择。因为Elasticsearch的底层是Lucene,可以对需要查找的字段建立索引,中间还会进行分词处理,进行更智能的匹配。由于Elasticsearch底层会为字段建立倒排索引,根据关键字查询可以轻松命中缓存,从而能极大提升访问性能,实现低延迟访问。
分布式日志中间件
随着微服务的兴起、业务量的增长,每一个服务在生产环境都会部署多台机器。例如,在我们公司,光是订单中心的“创建订单”服务就部署了四十多台机器。当遇到生产问题时,如果我们想要查看服务器日志,就会异常困难,因为我们根本不知道发生错误的请求具体在哪台机器上。
在机器数量较少(10台机器以内)的时候,通常我们可以使用Ansibe同时向所有需要采集的服务端执行日志检索命令,其工作示意图如下:
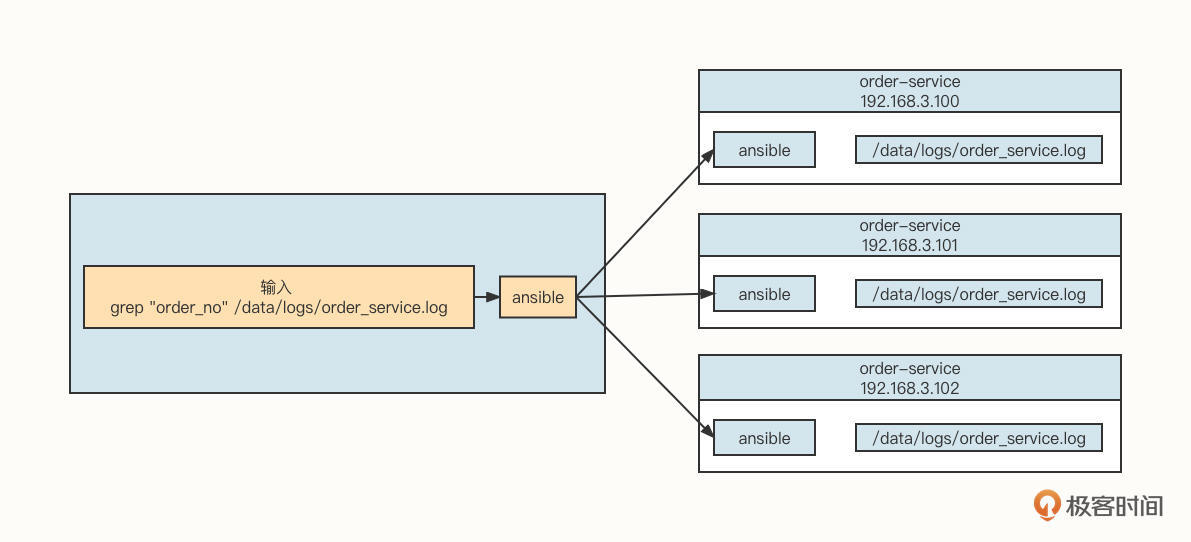
这种方式对于用户来说就像是操作单机模式一样,但是它的缺陷也是显而易见的。
- 基于Ansibe这种命令行等批量运维工具,需要保存目标机器的用户名与密码,安全性会受到影响。
- 如果要管理的目标机器有成百上千台,这种方式的系统开销会很大,搜索的响应时间很长,几乎是不太可能顺畅使用的。
为了进一步解决这个问题,我们通常需要采集每台服务器的日志,并将它存储在一个集中的地方,再提供一个可视化界面供用户查询。那么问题来了,市面上有这样的中间件吗?
我的回答是,必须得有,它就是大名鼎鼎的ELK。我们可以先看下这张ELK的工作架构图:
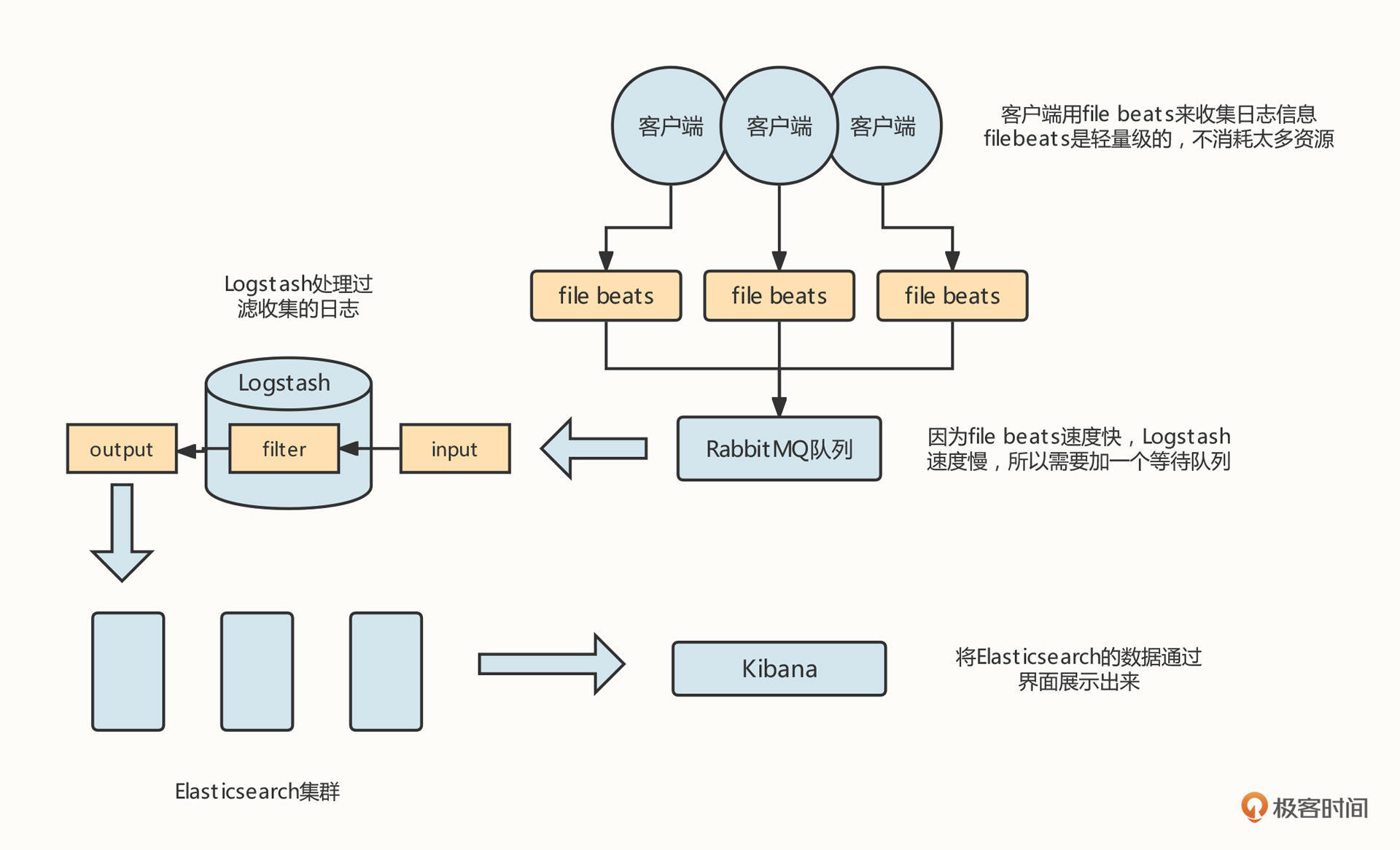
我们需要在需要进行日志采集的机器上安装一个filebeat工具,用来采集服务器的日志,并将它们存储到消息中间件中。然后,在需要采集的机器中安装Logstash进程,通过Logstash将日志数据存储到Elasticsearch服务器,用户可以通过Kibana查询存储在Elasticsearch中的日志数据,这样,我们就可以有针对性地查询所需要的日志了。
总结
好了,这节课就讲到这里。这节课,我们重点介绍了缓存、全文索引、分布式日志三类中间件。
缓存是性能优化的一柄利器,我们重点阐述了缓存技术从本地缓存到分布式缓存的演进之路,各种技术引入的背景以及解决方案,你可以根据自身情况,选择适合自己的缓存中间件。
另外,搜索相关技术也是应用系统必不可少的一环。随着微服务技术和数据库分库分表技术的兴起,数据写入效率大大提高,但与此同时,数据查询也面临更大的挑战,而基于Elasticsearch的数据异构架构方式能非常方便地解决数据查询的性能问题。
在分布式环境下,传统的应用日志查询方式也变得越来越难使用,ELK日志技术则为日志搜索带来了新气象,是分布式日志中间件的不二之选。
课后题
学完这节课,我也给你出一道课后题吧。
数据异构是一种非常经典的架构方式,请你尝试使用Canal或者Flink-CDC,将数据从MySQL同步到Elasticsearch中。
欢迎你在留言区与我交流讨论,我们下节课见。
03 | 数组与链表:存储设计的基石有哪些?
作者: 丁威

你好,我是丁威。
从这节课开始,我们就要进行基础篇的学习了。想要熟练使用中间件解决各种各样的问题,首先需要掌握中间件的基础知识。
我认为,中间件主要包括如下三方面的基础:数据结构、JUC和Netty,接下来的两节课,我们先讲数据结构。
数据结构主要解决的是数据的存储方式问题,是程序设计的基座。
按照重要性和复杂程度,我选取了数组和链表、键值对(HashMap)、红黑树、LinkedHashMap和PriorityQueue几种数据结构重点解析。其中,数组与链表是最底层的两种结构,是后续所有数据结构的基础。
我会带你分析每种结构的存储结构、新增元素和搜索元素的方式、扩容机制等,让你迅速抓住数据结构底层的特性。当然,我还会结合一些工业级实践,带你深入理解这些容器背后蕴含的设计理念。
说明一下,数据结构其实并不区分语言,但为了方便阐述,这节课我主要基于Java语言进行讲解。
数组
我们先来看下数组。
数组是用于储存多个相同类型数据的集合,它具有顺序性,并且也要求内存空间必须连续。高级编程语言基本都会提供数组的实现。
为了更直观地了解数组的内存布局,我们假设从操作系统申请了128字节的内存空间,它的数据结构可以参考下面这张图:
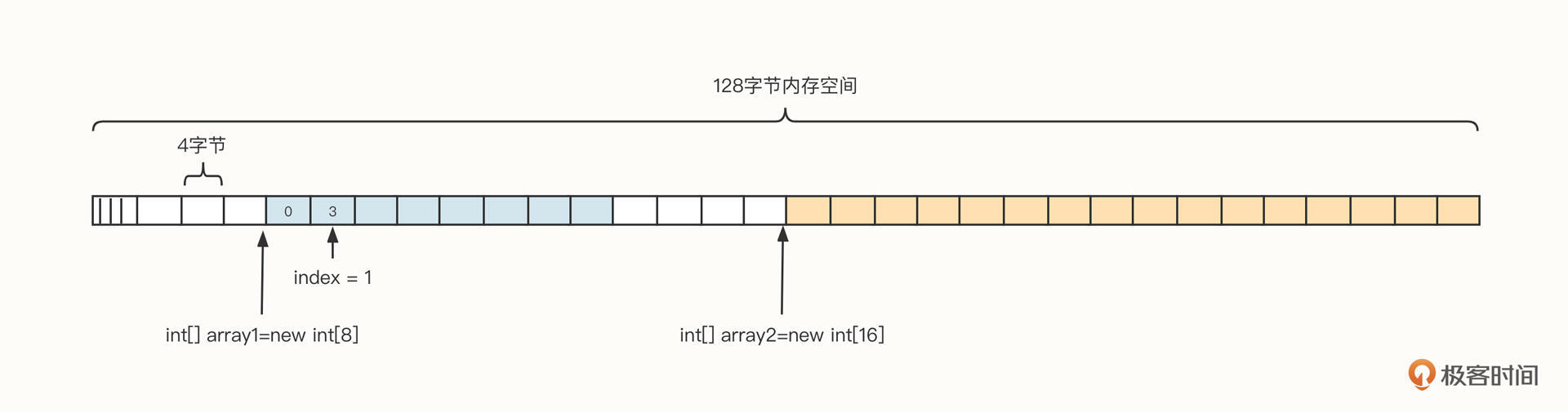
结合这张图我们可以看到,在Java中,数组通常包含下面几个部分。
- 引用:每一个变量都会在栈中存储数组的引用,我们可以通过引用对数组进行操作,对应上图的 array1、array2。
- 容量:数组在创建时需要指定容量,一旦创建,无法修改,也就是说,数组并不能自动扩容。
- 下标:数组可以通过下标对数组中的元素进行随机访问,例如array1[0]表示访问数组中的第一个元素,下标从0开始,其最大值为容量减一。
在后面的讲解中,你能看到很多数据结构都是基于数组而构建的。
那么数组有哪些特性呢?这里我想介绍两个我认为最重要的点:内存连续性和随机访问效率高。
我们先来看下内存连续性。
内存连续性的意思是,数组在向操作系统申请内存时,申请的必须是连续的内存空间。我们还是继续用上面这个例子做说明。我们已经创建了array1、array2两个数组,如果想要再申请一个拥有五个int元素的数组,能把这五个元素拆开,分别放在数组1的前面和后面吗?你可以看看下面这张示意图。
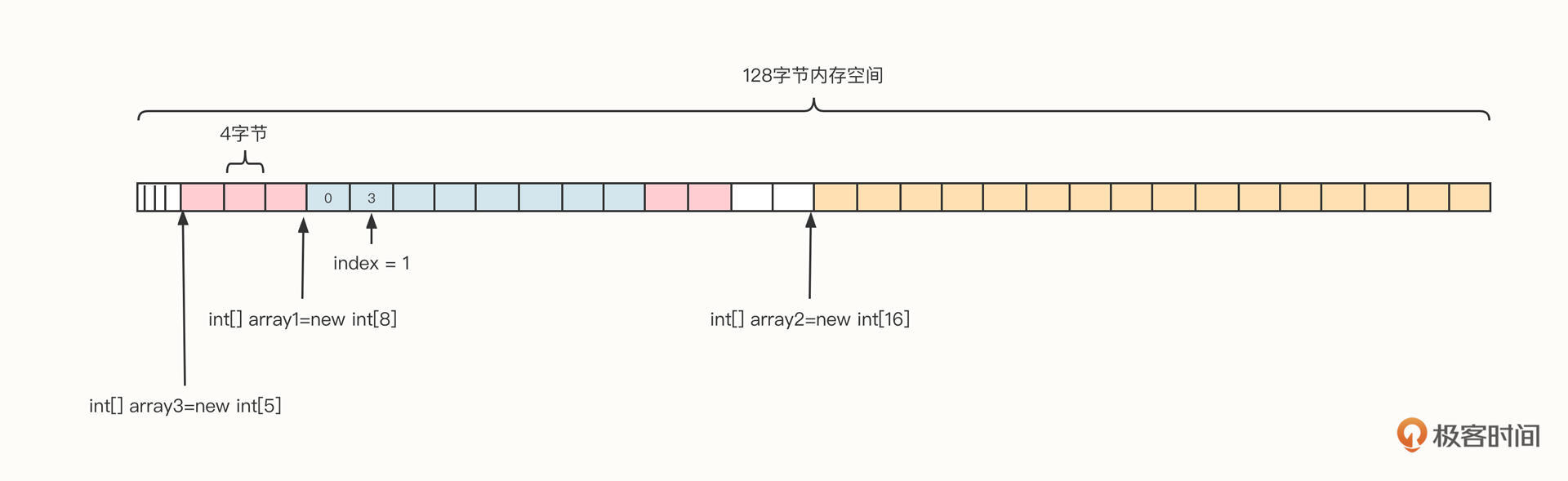
答案当然是不可以。
虽然当前内存中剩余可用空间为32个字节,乍一看上去有充足的内存。但是,因为不存在连续的20字节的空间,所以不能直接创建array3。
当我们想要创建20字节长度的array3时,在Java中会触发一次内存回收,如果垃圾回收器支持整理特性,那么垃圾回收器对内存进行回收后,我们就可以得到一个新的布局:
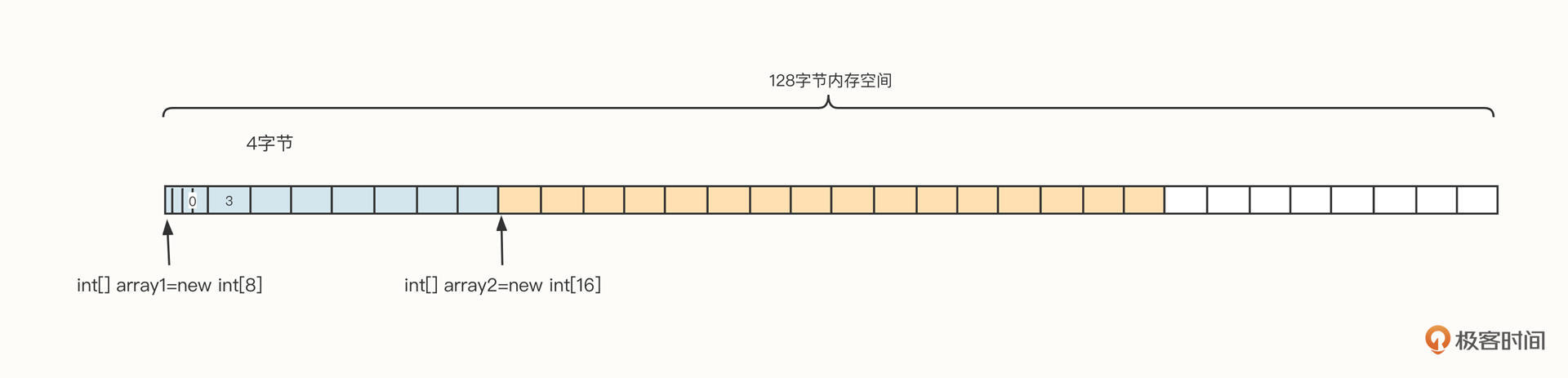
经过内存整理后就能创建数组3了。也就是说,如果内存管理不当,确实容易产生内存碎片,从而影响性能。
那我们为什么要把内存设计为连续的呢?换句话说,连续内存有什么好处呢?
这就不得不提到数组一个无可比拟的优势了:数组的随机访问性能极好。连续内存确保了地址空间的连续性,寻址非常简单高效。
举个例子,我们创建一个存放int数据类型的数组,代码如下:
1 | int[] array1 = new int[10]; |
然后我们看下JVM中的布局:
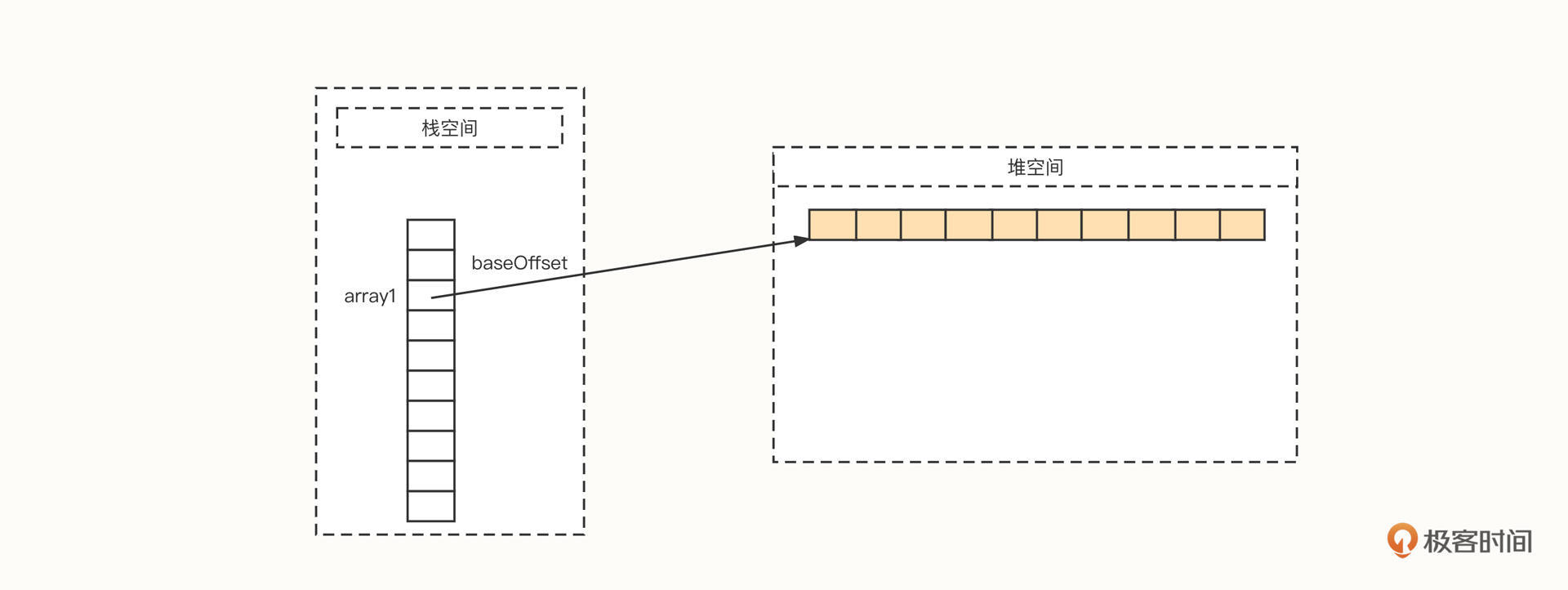
可以看到,首先内存管理器在栈空间会分配一段空间,用它存储数组在物理内存的起始地址,这个起始地址我们用baseOffset表示。如果是64位操作系统,默认一个变量使用8字节,如果采用了指针压缩技术,可以减少到4字节。
数组能够高效地随机访问数组中的元素,主要原因是它能够根据下标快速计算出真实的物理地址,寻找算法为“baseOffset + index * size”。
其中,size为数组中单个元素的长度,是一个常量。在上面这个数组中,存储的元素是int类型的数据,所以size为4。因此,我们根据数组下标就可以迅速找到对应位置存储的数据。
数组这种高效的访问机制在中间件领域有着非常广泛的应用,大名鼎鼎的消息中间件RocketMQ在它的文件设计中就灵活运用了这个特性。
RocketMQ为了追求消息写入时极致的顺序写,会把所有主题的消息全部顺序写入到commitlog文件中。也就是说,commitlog文件中混杂着各个主题的消息,但消息消费时,需要根据主题、队列、消费位置向消息服务器拉取消息。如果想从commitlog文件中读取消息,则需要遍历commitlog文件中的所有消息,检索性能非常低下。
一开始,为了提高检索效率,RocketMQ引入了ConsumeQueue文件,可以理解为commitlog文件按照主题创建索引。
为了在消费端支持消息按tag进行消息过滤,索引数据中需要包含消息的tag信息,它的数据类型是String,索引文件遵循{topic}/{queueId},也就是按照主题、队列两级目录存储。单个索引文件的存储结构设计如下图所示:
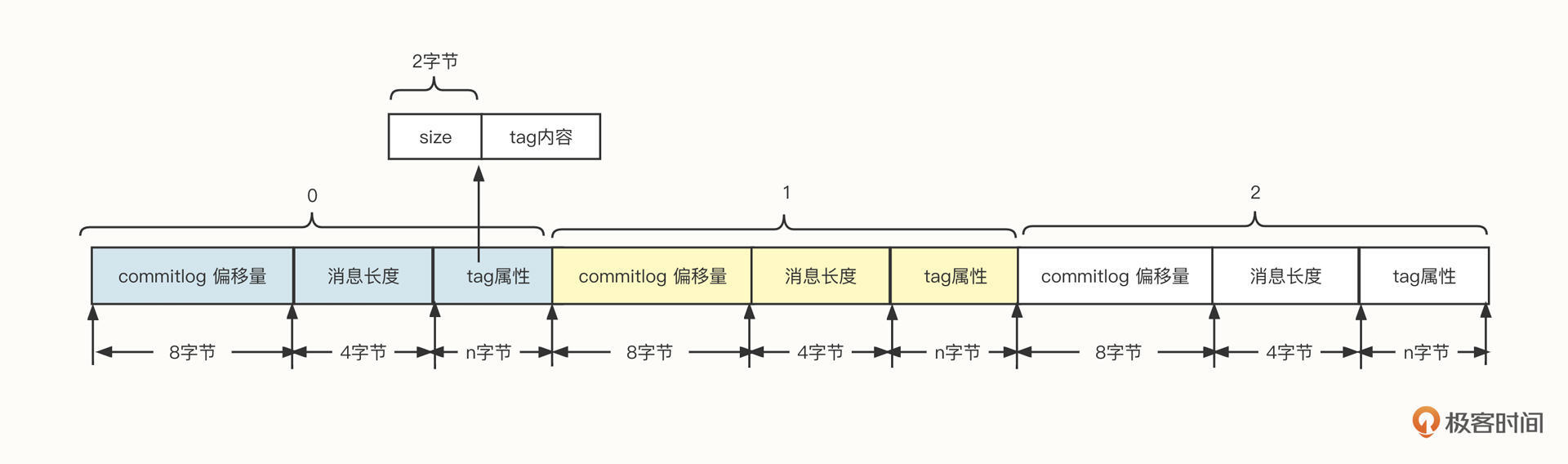
索引文件中,每一条消息都包含偏移量、消息长度和tag内容 3个字段。
commitlog偏移量
可以根据该值快速从commitlog文件中找到消息,这也是索引文件的意义。
消息长度
消息的长度,知道它可以方便我们快速提取一条完整的消息。
tag内容
由于消息的tag是由用户定义的,例如tagA、createorder等,它的长度可变。在文件存储领域,一般存储可变长的数据,通常会采用“长度字段+具体内容”的存储方式。其中用来存储内容的长度使用固定长度,它是用来记录后边内容的长度。
回到消息消费这个需求,我们根据主题、消费组,消息位置(队列中存储的第N条消息),能否快速找到消息呢?例如输入 topic:order_topic、queueId:0,offset:2,能不能马上找到第N条消息?
答案是可以找到,但不那么高效。原因是,我们根据topic、queueid,能非常高效地找到对应的索引文件。我们只需要找到对应的topic文件夹,然后在它的子目录中找到对应的队列id文件夹就可以了。但要想从索引文件中找到具体条目,我们还是必须遍历索引文件中的每一个条目,直到到达offset的条目,才能取出对应的commitlog偏移量。
那是否有更高效的索引方式呢?
当然有,我们可以将每一个条目设计成固定长度,然后按照数组下标的方式进行检索。
为了实现每一个条目定长,我们在这里不存储tag的原始字符串,而是存储原始字符串的hashCode,这样就可以确保定长了。你可以看看下面这张设计图:
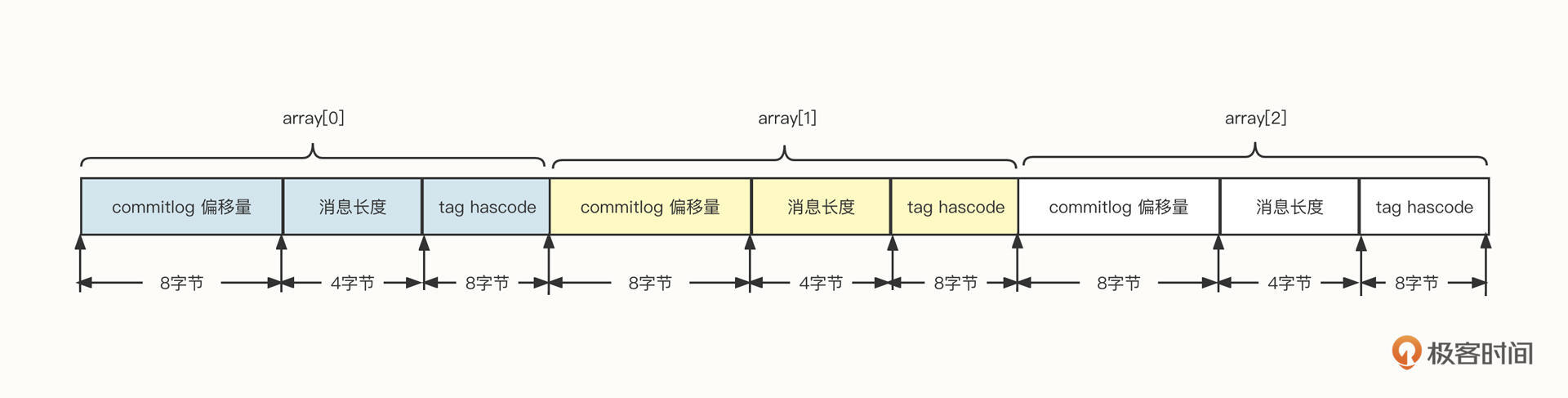
基于这种设计,如果给定一个offset,我们再想快速提取一条索引就变得非常简单了。
首先,根据 offset * 20(每一个条目的长度),定位到需要查找条目的起始位置,用startOffset表示。
然后,从startOffset位置开始读取20个字节的长度,就可以得到物理偏移量、消息长度和tag的hashCode了。
接着,我们可以通过hashCode进行第一次过滤,如果遇到hash冲突,就让客户端再根据消息的tag字符串精确过滤一遍。
这种方式,显然借鉴了数组高效访问数据的设计理念,是数组实现理念在文件存储过程中的经典运用。
总之,正是由于数组具有内存连续性,具有随机访问的特性,它在存储设计领域的应用才非常广泛,我们后面介绍的HashMap也引入了数组。
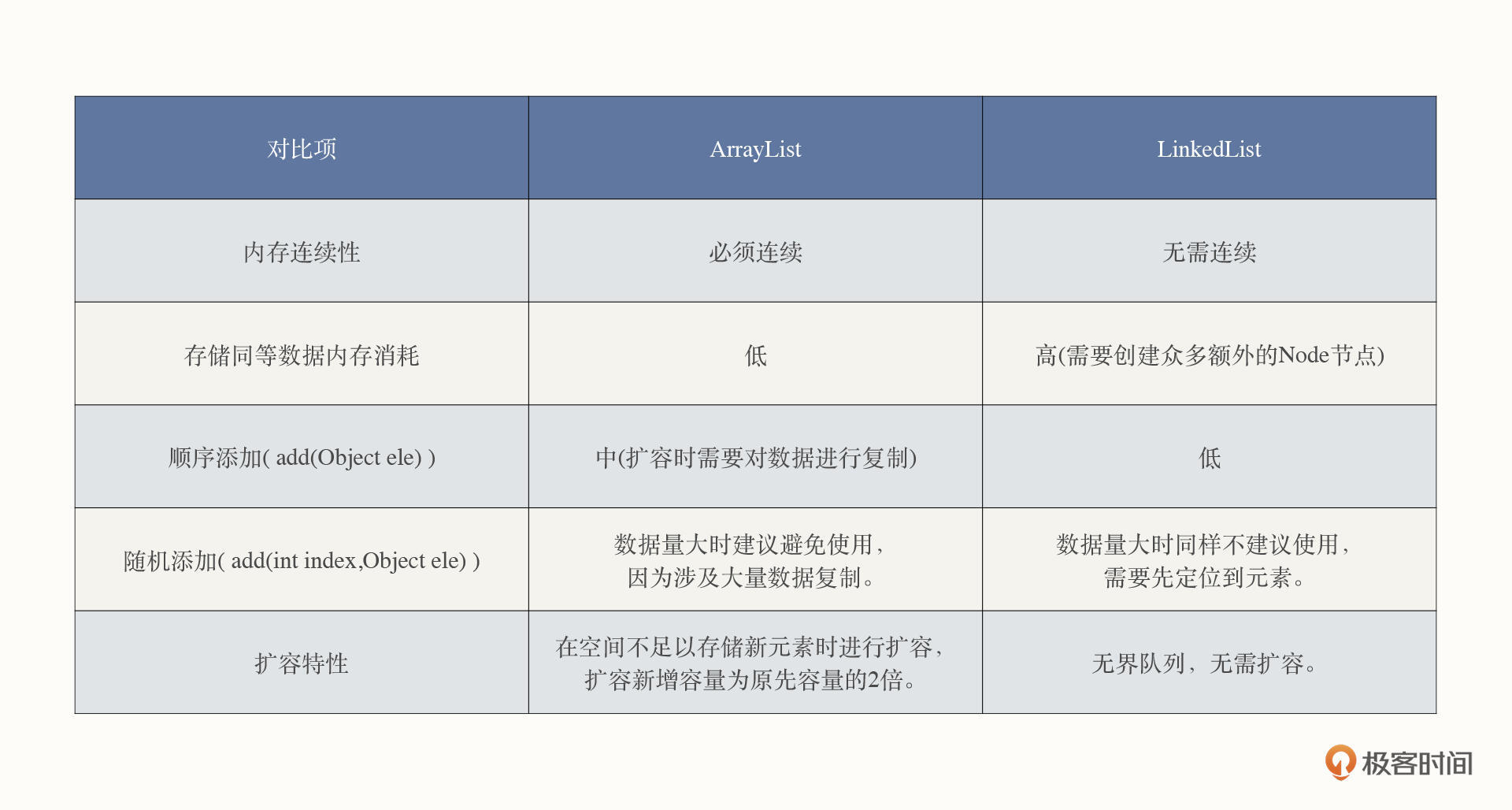
ArrayList
不过,数组从严格意义上来说是面向过程编程中的产物,而Java是一门面向对象编程的语言,所以,直接使用数组容易破坏面向对象的编程范式,故面向对象编程语言都会对数组进行更高级别的抽象,在Java中对应的就是ArrayList。
我会从数据存储结构、扩容机制、数据访问特性三个方面和你一起来探究一下ArrayList。
首先我们来看一下ArrayList的底层存储结构,你可以先看下这个示意图:

从图中可以看出,ArrayList的底层数据直接使用了数组,是对数组的抽象。
ArrayList相比数组,增加了一个特性,它支持自动扩容。其扩容机制如下图所示:
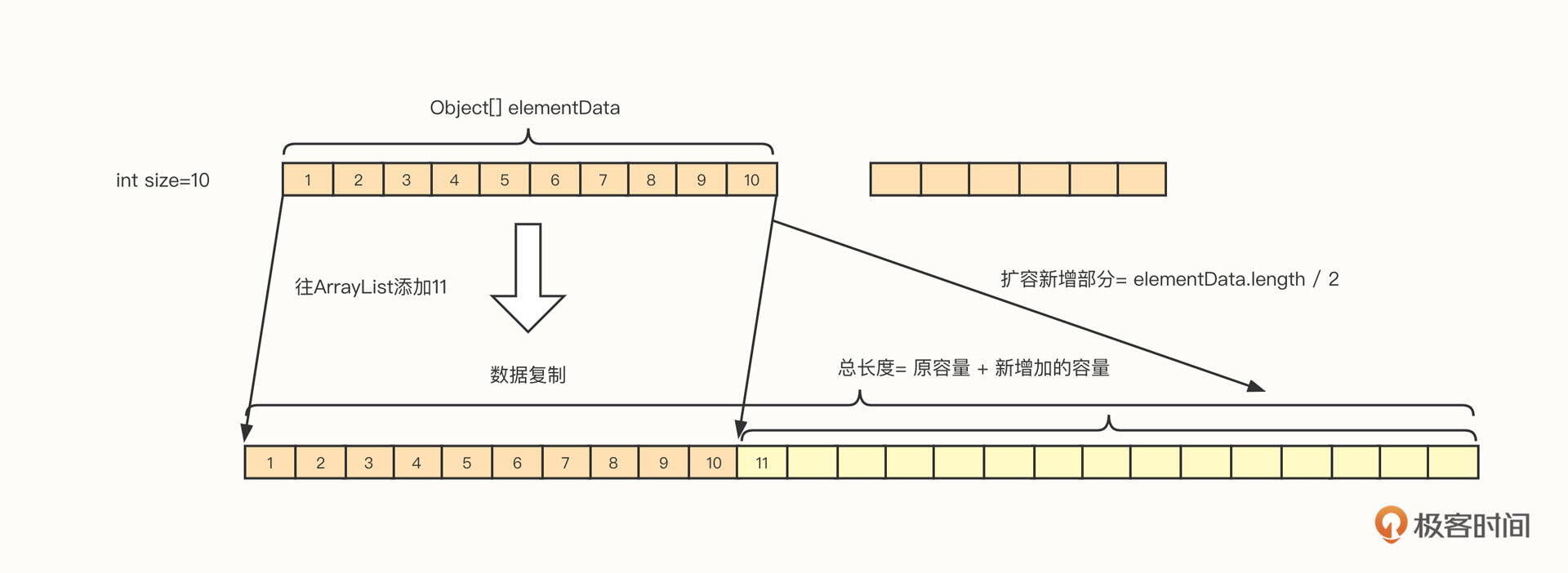
扩容的实现有三个要点。
- 扩容后的容量= 原容量 +(原容量)/ 2,以 1.5 倍进行扩容。
- 内部要创建一个新的数组,数组长度为扩容后的新长度。
- 需要将原数组中的内容拷贝到新的数组,即扩容过程中存在内存复制等较重的操作。
注意,只在当前无剩余空间时才会触发扩容。在实际的使用过程中,我们要尽量做好容量评估,减少扩容的发生。因为扩容的成本还是比较高的,存储的数据越多,扩容的成本越高。
接下来,我们来看一下ArrayList的数据访问特性。
- 顺序添加元素的效率高
ArrayList顺序添加元素,如果不需要扩容,直接将新的数据添加到elementData[size]位置,然后size加一即可(其中,size表示当前数组中存储的元素个数)。
ArrayList添加元素的时间复杂度为O(1),也就是说它不会随着存储数据的大小而改变,是非常高效的存储方式。
- 中间位置插入/删除元素的效率低
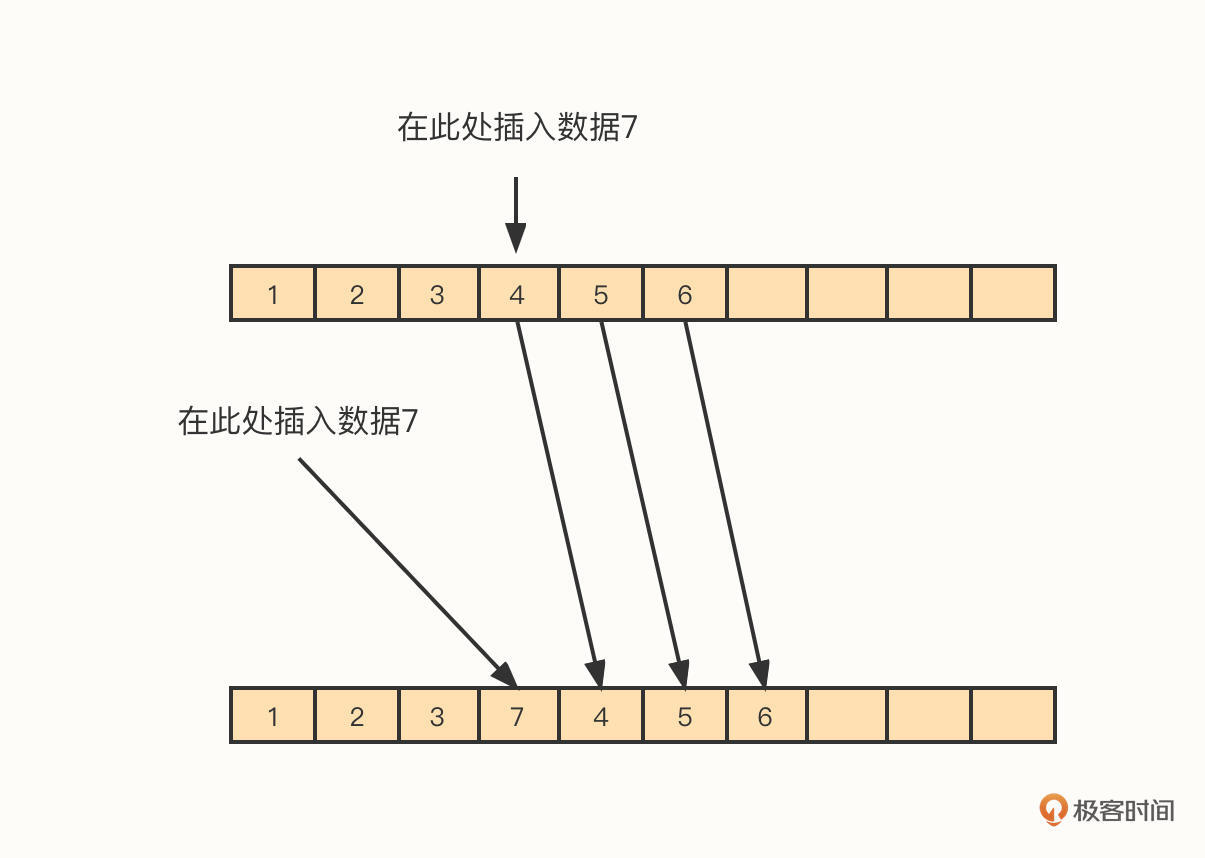
在插入元素时,我们将需要插入数据的下标用 index 表示,将 index 之后的依次向后移动(复制到 index + 1),然后将新数据存储在下标 index的位置。
删除操作与插入类似,只是一个数据是往后移,而删除动作是往前移。
ArrayList在中间位置进行删除的时间复杂度为O(n),这是一个比较低效的操作。
- 随机访问性能高
由于ArrayList的底层就是数组,因此它拥有高效的随机访问数据特性。
LinkedList
除了ArrayList,在数据结构中,还有一种也很经典的数据结构:链表。LinkedList就是链表的具体实现。
我们先来看一下LinkedList的底层存储结构,最后再对比一下它和ArrayList的差异。
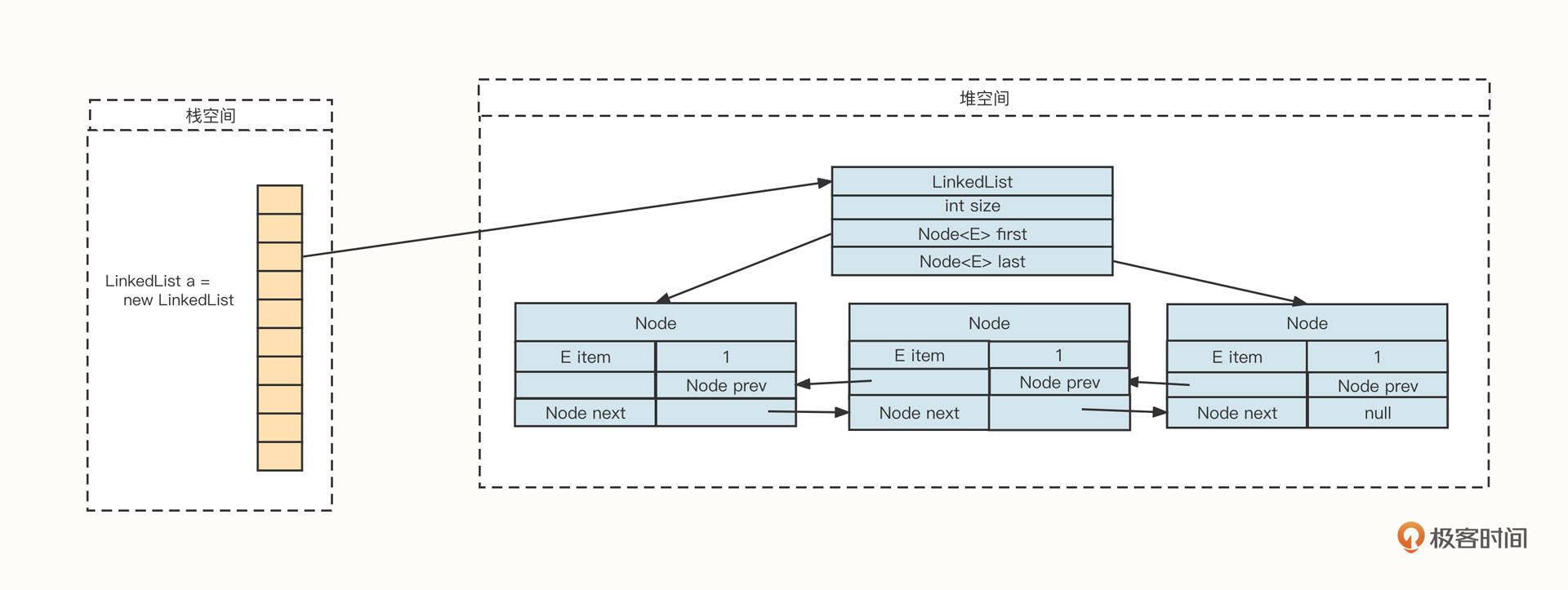
从上面这张图你可以看到,一个LinkedList对象在内存中通常由两部分组成:LinkedList对象和由Node节点组成的链条。
一个LinkedList对象在内存中主要包含3个字段。
- int size:链表中当前存在的Node节点数,主要用来判断是否为空、判断随机访问位点是否存在;
- Node first:指向链表的头节点;
- Node last:指向链表的尾节点。
再来说说由Node节点组成的链条。Node节点用于存储真实的数据,并维护两个指针。分别解释一下。
- E item:拥有存储用户数据;
- Node prev:前驱节点,指向当前节点的前一个指针;
- Node last:后继节点,指向当前节点的下一个节点。
由这两部分构成的链表具有一个非常典型的特征:内存的申请无须连续性。这就减少了内存申请的限制。
接下来我们来看看如何操作链表。对于链表的操作主要有两类,一类是在链表前后添加或删除节点,一类是在链表中间添加或删除数据。
当你想要在链表前后添加或删除节点时,因为我们在LinkedList对象中持有链表的头尾指针,可以非常快地定位到头部或尾部节点。也就是说,这时如果我们想要增删数据,都只需要更新相关的前驱或后继节点就可以了,具体操作如下图所示:
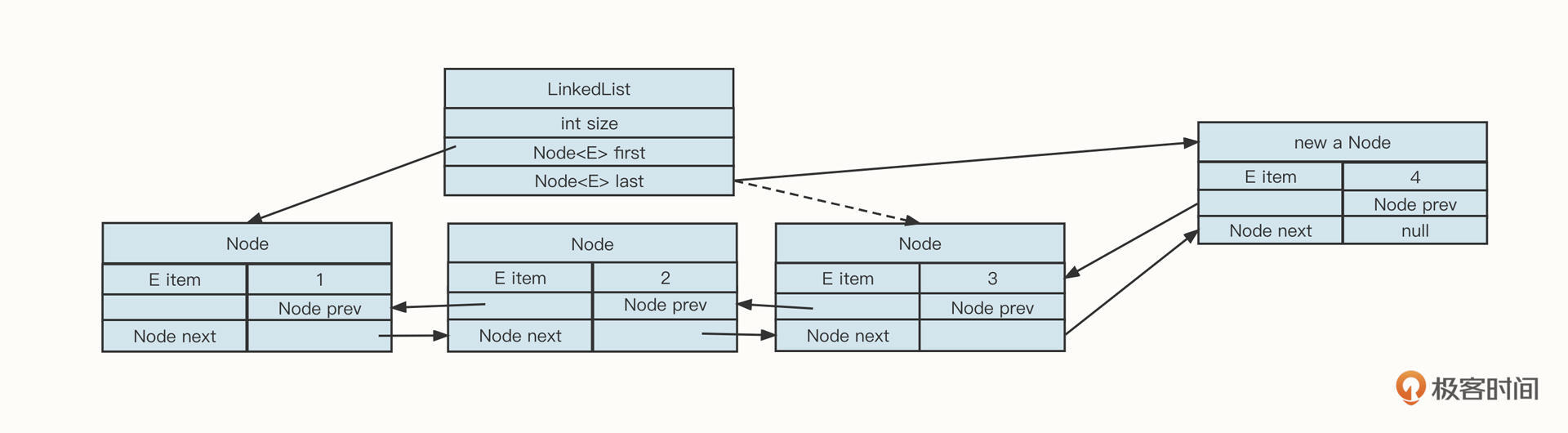
举个例子,如果我们向尾部节点添加节点,它的代码是这样的:
1 | Node oldLastNode = list.last; //添加数据之前原先的尾部节点 |
在链表的尾部、头部添加和删除数据,时间复杂度都是O(1),比ArrayList在尾部添加节点效率要高。因为当ArrayList需要扩容时,会触发数据的大量复制,而LinkedList是一个无界队列,不存在扩容问题。
如果要在链表的中间添加或删除数据,我们首先需要遍历链表,找到操作节点。因为链表是非连续内存,无法像数组那样直接根据下标快速定位到内存地址。
例如,在下标index为1的后面插入新的数据,它的操作示例图如下:
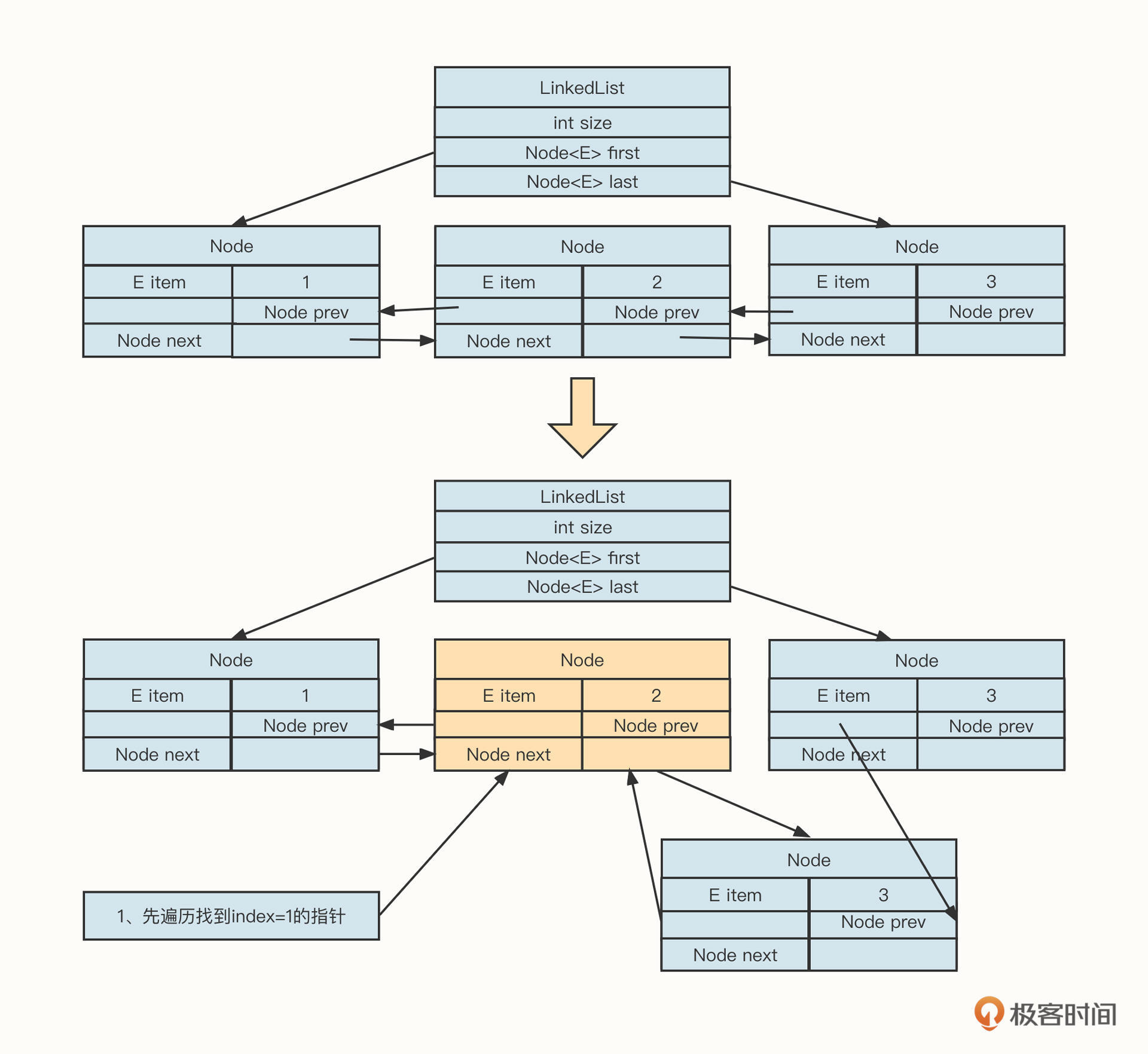
我们从上往下看。插入新节点的第一步是需要从头节点开始遍历,找到下标为i=1的节点,然后在该节点的后面插入节点,最后执行插入节点的逻辑。
插入节点的具体实现主要是为了维护链表中相关操作节点的前驱与后继节点。
遍历链表、查询操作节点的时间复杂度为O(n),然后基于操作节点进行插入与删除动作的时间复杂度为O(1)。
关于链表的知识点就讲到这里。由于链表与数组是数据结构中两种最基本的存储结构,为了让你更直观地了解二者的差异,我也给你画了一个表格,对两种数据结构做了对比:
HashMap
无论是链表还是数组都是一维的,在现实世界中有一种关系也非常普遍:关联关系。关联关系在计算机领域主要是用键值对来实现,HashMap就是基于哈希表Map接口的具体实现。
JDK1.8版本之前,HashMap的底层存储结构如下图所示:
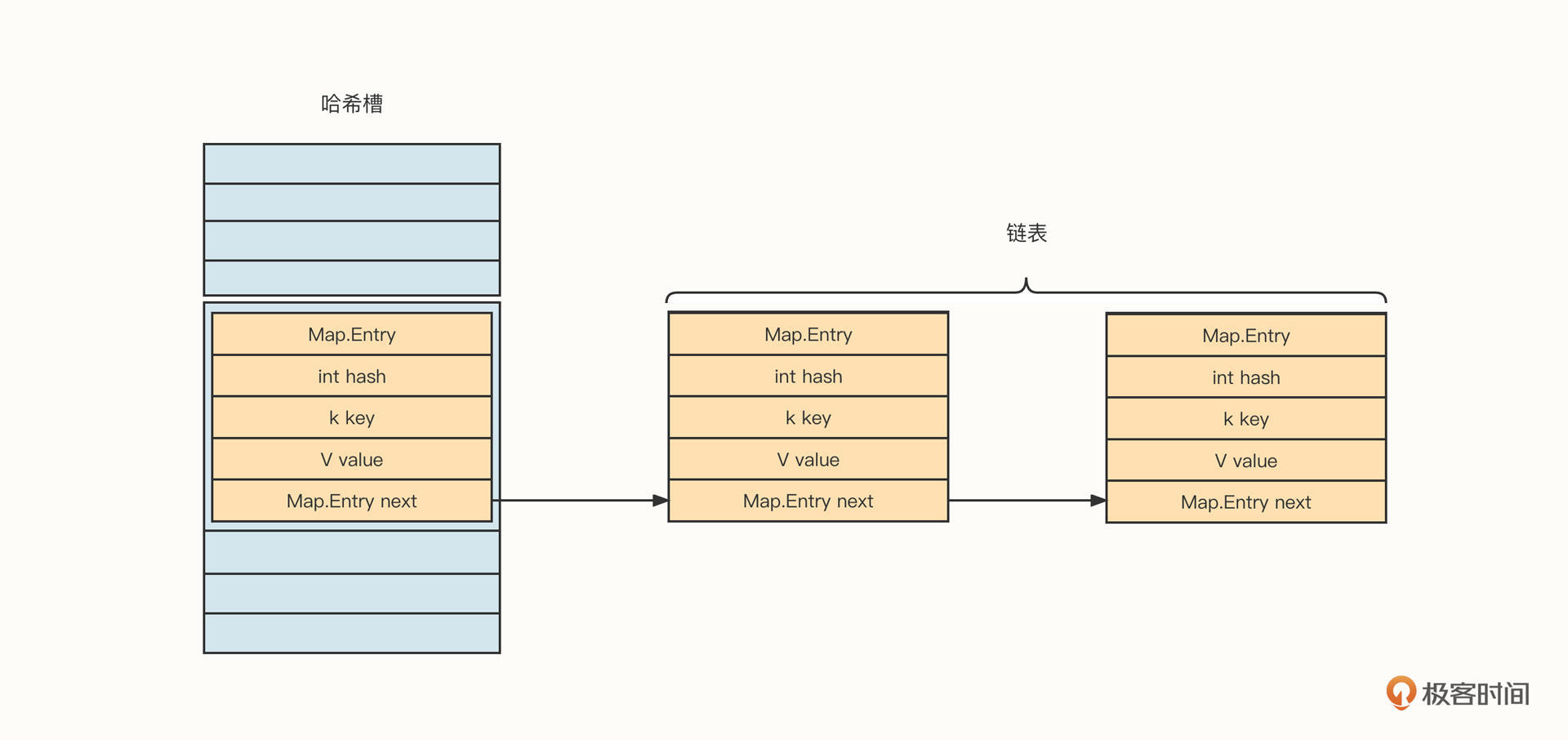
HashMap的存储结构主体是哈希槽与链表的组合,类似一个抽屉。
我们向HashMap中添加一个键值对,用这个例子对HashMap的存储结构做进一步说明。
HashMap内部持有一个Map.Entry[]的数组,俗称哈希槽。当我们往HashMap中添加一个键值对时,HashMap会根据Key的hashCode与槽的总数进行取模,得出槽的位置(也就是数组的下标),然后判断槽中是否已经存储了数据。如果未存储数据,则直接将待添加的键值对存入指定的槽;如果槽中存在数据,那就将新的数据加入槽对应的链表中,解决诸如哈希冲突的问题。
在HashMap中,单个键值对用一个Map.Entry结构表示,具体字段信息如下。
- K key:存储的Key,后续可以用该Key进行查找
- V value:存储的Value;
- int hash:Key的哈希值;
- Ma.Entry :next 链表。
到这里,你可以停下来思考一下,当哈希槽中已经存在数据时,新加入的元素是存储在链表的头部还是尾部呢?
答案是放在头部。代码如下:
1 | //假设新放入的槽位下标用 index 表示,哈希槽用 hashArray 表示 |
我们将新增加的元素放到链表的头部,也就是直接放在哈希槽中,然后用next指向原先存在于哈希槽中的元素。
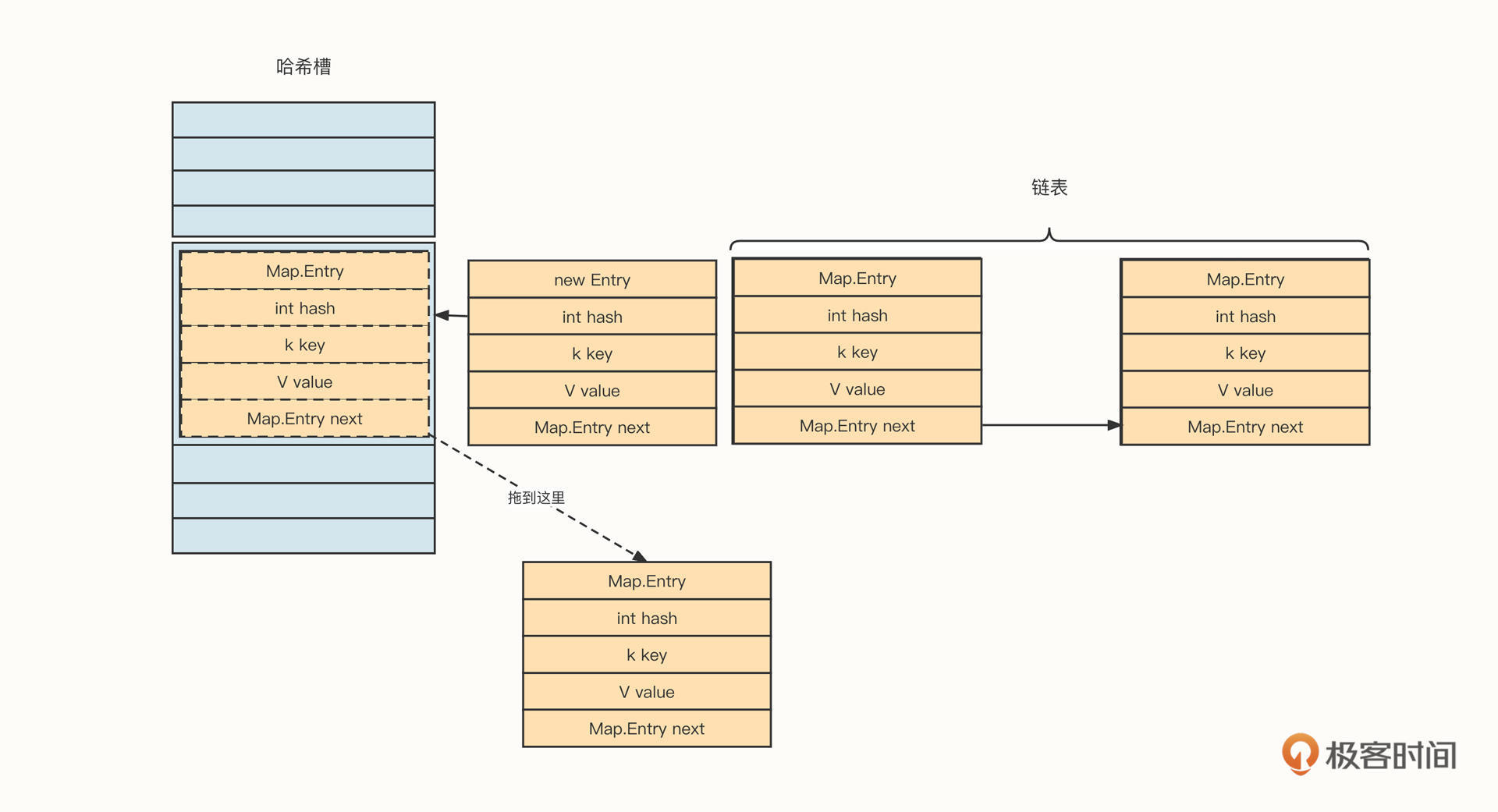
这种方式的妙处在于,只涉及两个指针的修改。如果我们把新增加的元素放入链表的头部,链表的复杂度为O(1)。相反,如果我们把新元素放到链表的尾部,那就需要遍历整条链表,写入复杂度会有所提高,随着哈希表中存储的数据越来越多,那么新增数据的性能将随着链表长度的增加而逐步降低。
介绍完添加元素,我们来看一下元素的查找流程,也就是如何根据Key查找到指定的键值对。
首先,计算Key的hashCode,然后与哈希槽总数进行取模,得到对应哈希槽下标。
然后,访问哈希槽中对应位置的数据。如果数据为空,则返回“未找到元素”。如果哈希槽对应位置的数据不为空,那我们就要判断Key值是否匹配了。如果匹配,则返回当前数据;如果不匹配,则需要遍历哈希槽,如果遍历到链表尾部还没有匹配到任何元素,则返回“未找到元素”。
说到这里,我们不难得出这样一个结论:如果没有发生哈希槽冲突,也就是说如果根据Key可以直接命中哈希槽中的元素,数据读取访问性能非常高。但如果需要从链表中查找数据,则性能下降非常明显,时间复杂度将从O(1)提升到O(n),这对查找来说就是一个“噩梦”。
一旦出现这种情况,HashMap的结构会变成下面这个样子:
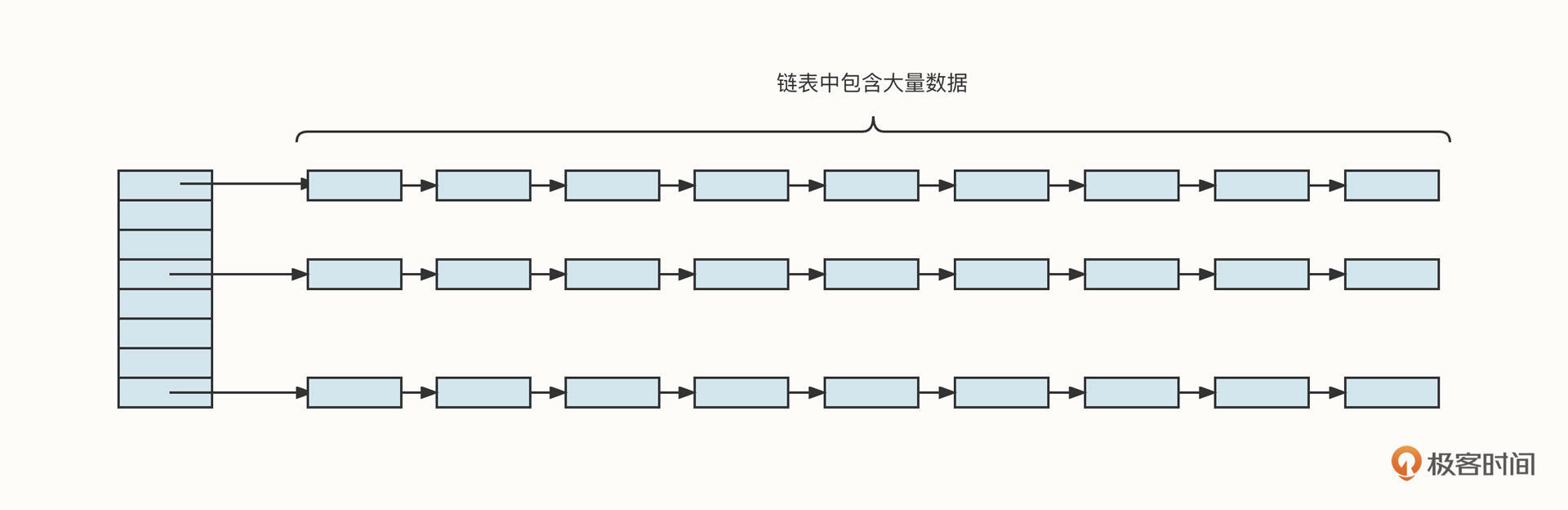
怎么解决这个问题呢?JDK的设计者们给出了两种优化策略。
第一种,对Hash槽进行扩容,让数据尽可能分布到哈希槽上,但不能解决因为哈希冲突导致的链表变长的问题。
第二种,当链表达到指定长度后,将链表结构转换为红黑树,提升检索性能(JDK8开始引入)。
我们先来通过源码深入探究一下HashMap的扩容机制。HashMap的扩容机制由resize方法实现,该方法主要分成两个部分,上半部分处理初始化或扩容容量计算,下半部分处理扩容后的数据复制(重新布局)。
上半部分的具体源码如下:
1 | /** |
为了方便你对代码进行理解,我画了一个与之对应的流程图:
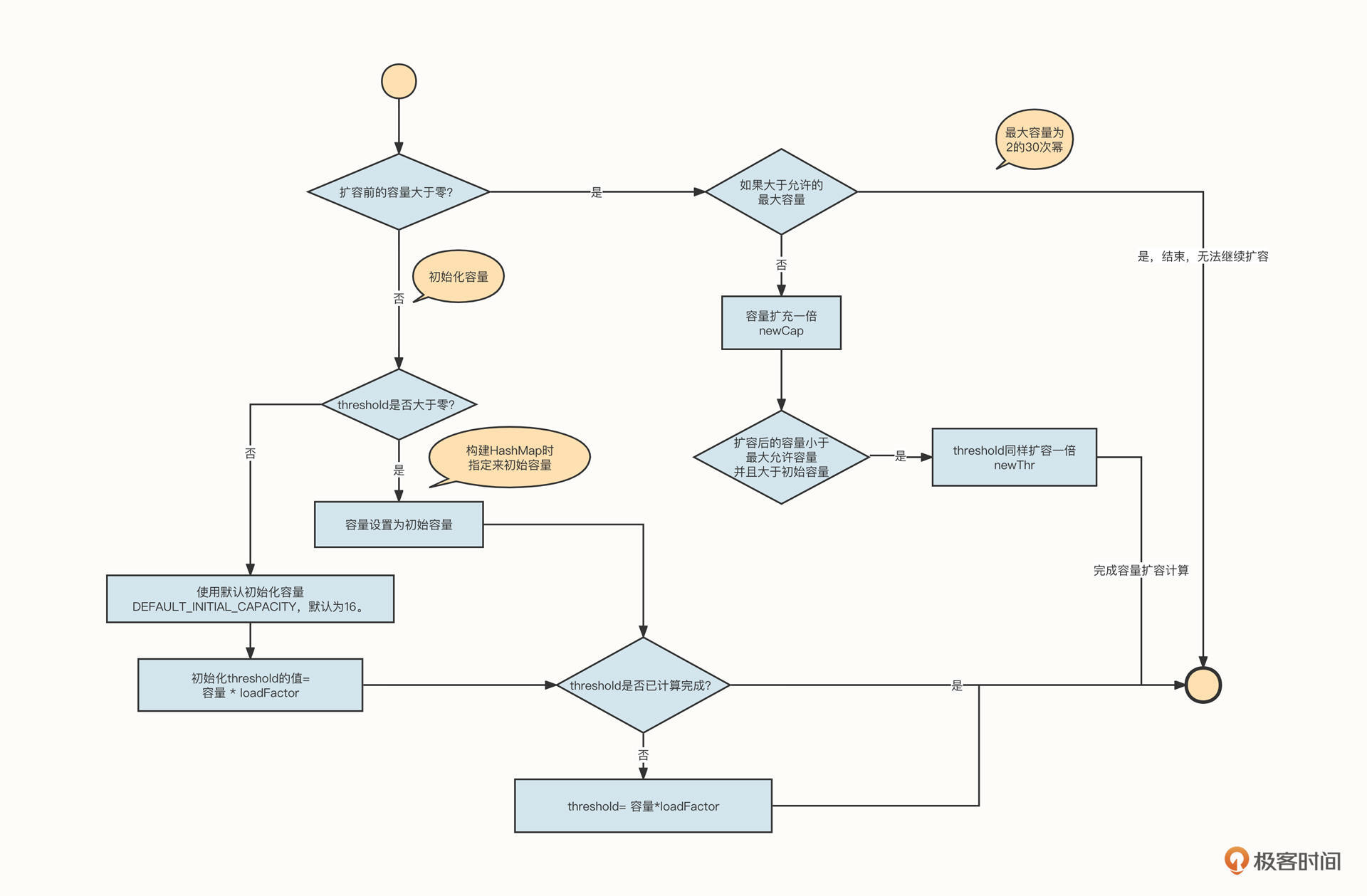
总结一下扩容的要点。
- HashMap的容量并无限制,但超过2的30次幂后不再扩容哈希槽。
- 哈希槽是按倍数扩容的。
- HashMap在不指定容量时,默认初始容量为16。
HashMap并不是在无容量可用的时候才扩容。它会先设置一个扩容临界值,当HashMap中的存储的数据量达到设置的阔值时就触发扩容,这个阔值用threshold表示。
我们还引入了一个变量loadFactor来计算阔值,阔值=容量*loadFactor。其中,loadFactor表示加载因子,默认为0.75。
加载因子的引入与HashMap哈希槽的存储结构与存储算法有关。
HashMap在出现哈希冲突时,会引入一个链表,形成“数组+链表”的存储结构。这带来的效果就是,如果HashMap有32个哈希槽,当前存储的数据也刚好有32个,这些数据却不一定全会落在哈希槽中,因为可能存在hash值一样但是不同Key的数据,这时,数据就会进入到链表中。
前面我们也提到过,数据放入链表就容易引起查找性能的下降,所以,HashMap的设计者为了将数据尽可能地存储到哈希槽中,会提前进行扩容,用更多的空间换来检索性能的提高。
我们再来看一下扩容的下半部分代码。
我们先来看下这段代码:
1 |
|
这段代码不难理解,就是按照扩容后的容量创建一个新的哈希槽数组,遍历原先的哈希槽(数组),然后将数据重新放入到新的哈希槽中,为了保证链表中数据的顺序性,在扩容时采用尾插法。
除了扩容,JDK8之后的版本还有另外一种提升检索能力的措施,那就是在链表长度超过8时,将链表演变为红黑树。这时的时间复杂度为O(2lgN),可以有效提升效率。
关于红黑树,我会在下节课详细介绍。
总结
这节课,我们介绍了数组、ArrayList、LinkedList、HashMap这几种数据结构。
数组,由于其内存的连续性,可以通过下标的方式高效随机地访问数组中的元素。
数组与链表可以说是数据结构中两种最基本的数据结构,这节课,我们详细对比了两种数据结构的存储特性。
哈希表是我们使用得最多的数据结构,它的底层的设计也很具技巧性。哈希表充分考虑到数组与链表的优劣,扬长避短,HashMap就是这两者的组合体。为了解决链表检索性能低下的问题,HashMap内部又引入了扩容与链表树化两种方式进行性能提升,提高了使用的便利性,降低了使用门槛。
课后题
最后,我也给你留两道思考题吧!
1、业界在解决哈希冲突时除了使用链表外,还有其他什么方案?请你对这两者的差异进行简单的对比。
2、HashMap中哈希槽的容量为什么必须为2的倍数?如果不是很理解,推荐你先学习一下位运算,然后在留言区告诉我你的答案。
我们下节课再见!
04 | 红黑树:图解红黑树的构造过程与应用场景
作者: 丁威

你好,我是丁威。
这节课,我们继续Java中常用数据结构的讲解。我会重点介绍TreeMap、LinkedHashMap和 PriorityQueue这三种数据结构。
TreeMap
先来看TreeMap。TreeMap的底层数据结构是一棵红黑树,这是一种比较复杂但也非常重要的数据结构。它是由树这种基础的数据结构演化而来的。
我们知道,在计算机领域,树指的就是具有树状结构的数据的集合。把它叫做“树”,是因为它看起来像一棵自上而下倒挂的树。一棵树通常有下面几个特点:
- 每个节点都只有有限个子节点或无子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
- 树里面没有环路(cycle)。
如果一棵树的每个节点最多有两个子树,那它就是一棵二叉树。二叉树是“树”的一个重要分支,我们可以通过文稿中这张图来直观感受一下:
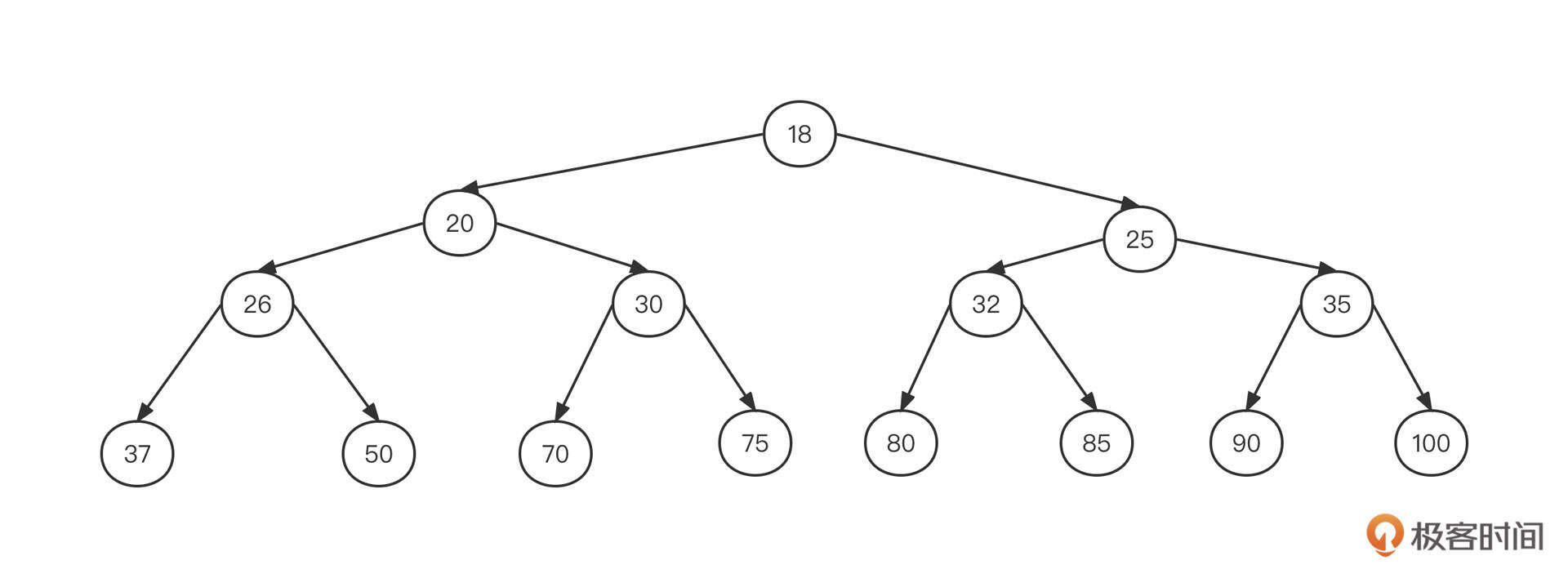
但是如果数据按照这样的结构存储,想要新增或者查找数据就需要沿着根节点去遍历所有的节点,这时的效率为O(n),可以看出性能非常低下。作为数据结构的设计者,肯定不能让这样的事情发生。
这时候,我们就需要对数据进行排序了,也就是使用所谓的二叉排序树(二叉查找树)。它有下面几个特点:
- 若任意节点的左子树不为空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不为空,则右子树上所有节点的值均大于它的根节点的值;
- 没有键值相等的节点。
如果上图这棵二叉树变成一棵二叉排序树,可能长成下面这个样子:
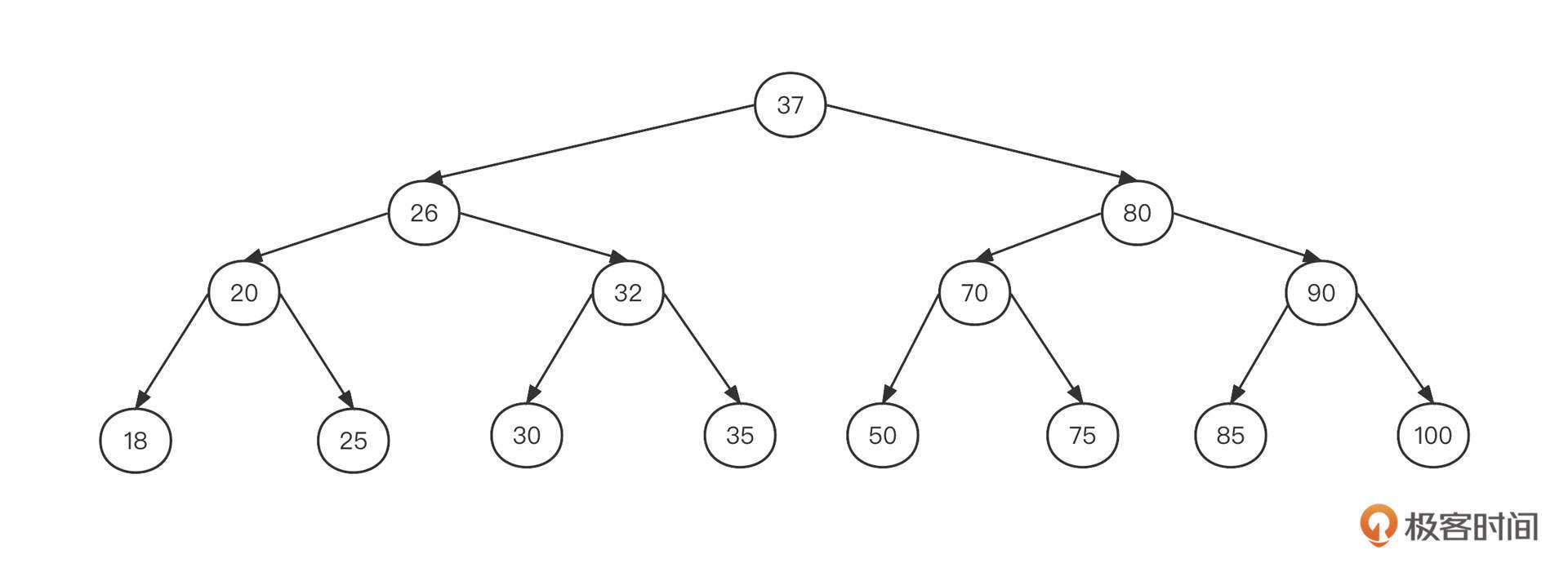
基于排序后的数据存储结构,我们来尝试一下查找数字30:
- 从根节点37开始查找,判断出37比30大,然后尝试从37的左子树继续查找;
- 37的左子节点为26,判断出26比30小,所以需要从26的右子树继续查找;
- 26的右子节点为32,由于32比30大,所以从32的左子树继续查找;
- 32的左子节点为30,命中,结束。
你应该已经发现了,每次查找,都可以排除掉一半的数据。我们可以将它类比作二分查找算法,其时间复杂度为O(logN),也就是对数级。所以说,二叉排序树是一种比较高效的查找算法。
不过,二叉排序树也有缺陷。一个最主要的问题就是,在查找之前我们需要按照二叉排序树的存储特点来构建它。我们还是用上面这个例子,将节点按照从小到大的顺序构建二叉排序树,构建过程如下图所示:
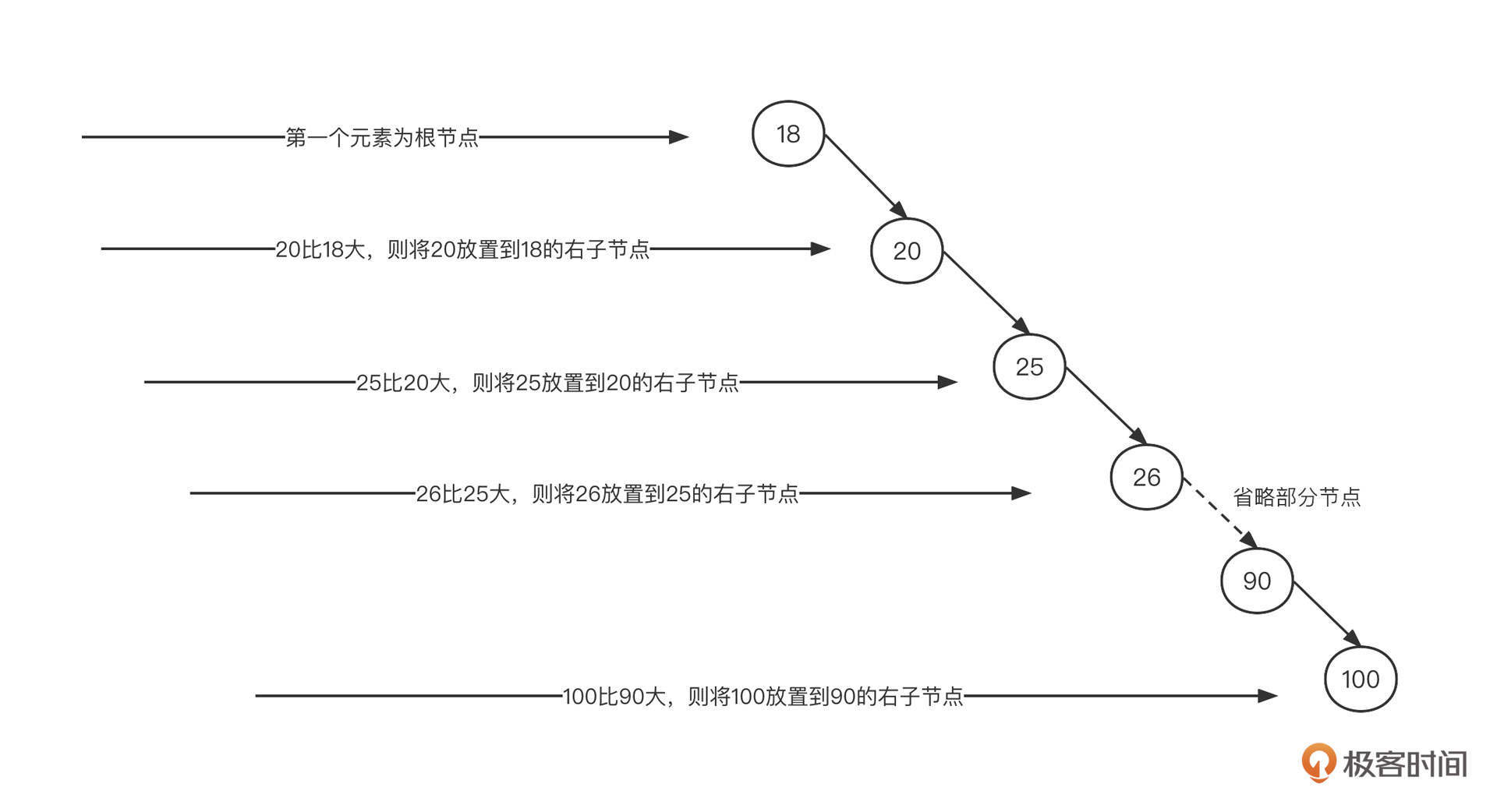
根据排序二叉树的构建规则,如果数据本身是顺序的,那么二叉排序树会退化成单链表,时间复杂度飙升到O(n),我们显然不能接受这种情况。
对比这两棵二叉排序树,第一棵左右子树比较对称,两边基本能保持平衡,但第二棵严重地向右边倾斜,这会导致每遍历新的一层,都无法有效过滤一半的数据,也就意味着性能的下降。
那有没有一种办法能够自动调整二叉排序树的平衡呢?这就是红黑树要解决的问题了。
红黑树是一种每个节点都带有颜色属性(红色或黑色)的二叉查找树,它可以实现树的自平衡,查找、插入和删除节点的时间复杂度都为O(logn)。
除了要具备二叉排序树的特征外,红黑树还必须具备下面五个特性。
性质1:节点是红色或黑色。
性质2:根是黑色。
性质3:所有叶子都是黑色(叶子是NIL节点)。
性质4:每个红色节点必须有两个黑色的子节点。也就是说,从每个叶子到根的所有路径上不能有两个连续的红色节点。
性质5:从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
由于插入、删除节点都有可能破坏红黑树的这些特性,所以我们需要进行一些操作,也就是通过树的旋转让它重新满足这些特点。
树的旋转又分为右旋和左旋两种:右旋指的是旋转后需要改变支点节点的右子树,左旋指的是旋转后需要改变支点节点的左节点。 这个通过旋转重新满足特性的过程就是自平衡。树越平衡,数据的查找效率越高。
为了让你直观地看到“红黑树的魅力”,我们还是沿用上面的例子,将节点按照从小到大的顺序依次插入到一棵红黑树中,最终产生的红黑树为如下图所示:
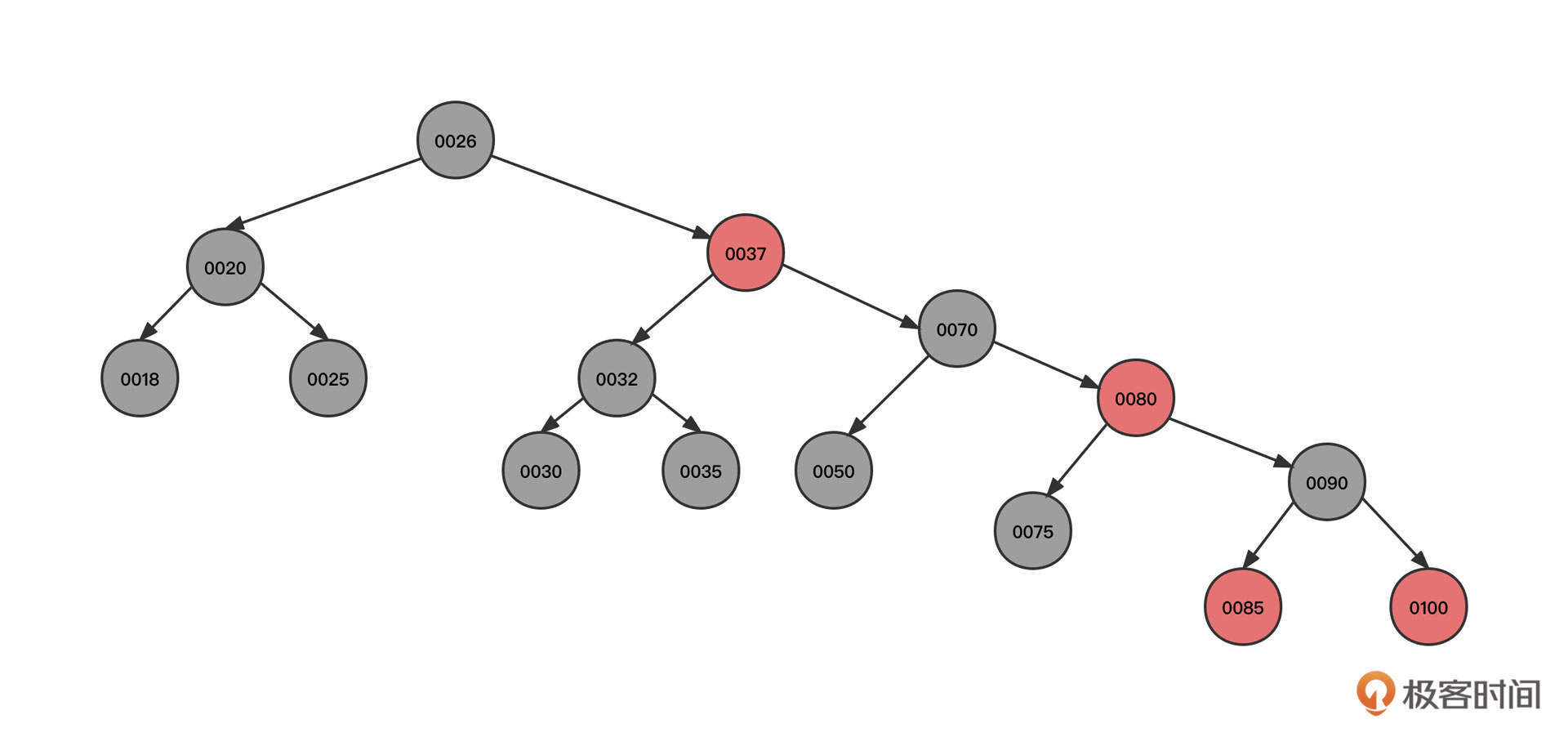
这是一棵地地道道的二叉排序树。
但是我们刚才说,在查找元素时,时间复杂度从O(n)飙升到了O(logN),这棵树是如何做到节点顺序插入时没有退化成链表的呢?我们一起来看下红黑树的构建过程。
提前说明一下,由于从小到大排序是一种特殊情况,不能覆盖建构红黑树的多种情况,所以为了更好地说明红黑树的工作机制,我们把节点的插入顺序变更为50、37、70、35、25、30、26、80、90、100、20、18、32、75、85。
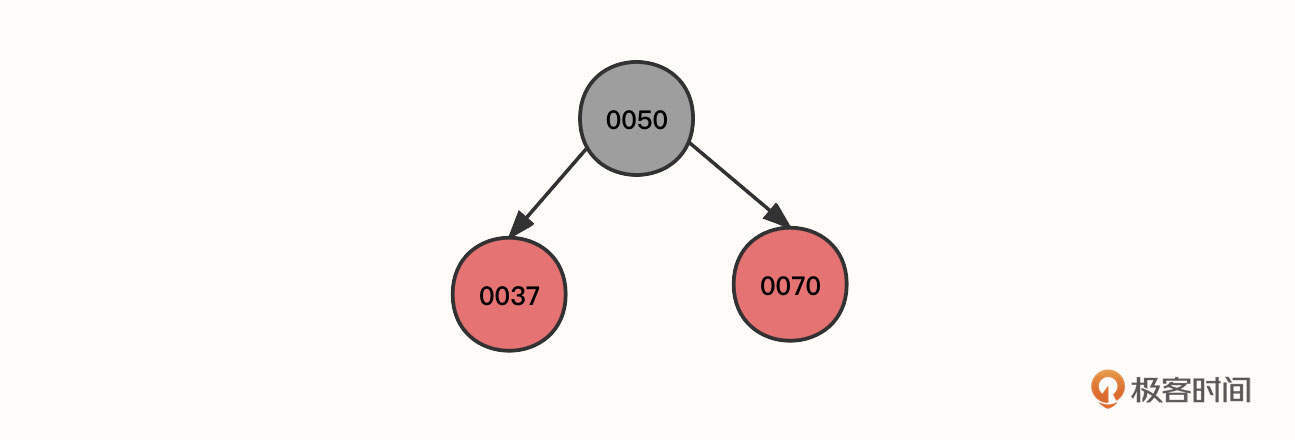
1. 按照这个顺序,首先我们连续插入节点50、节点37、节点70,其初始状态如下图所示:
2. 然后,继续插入节点35:
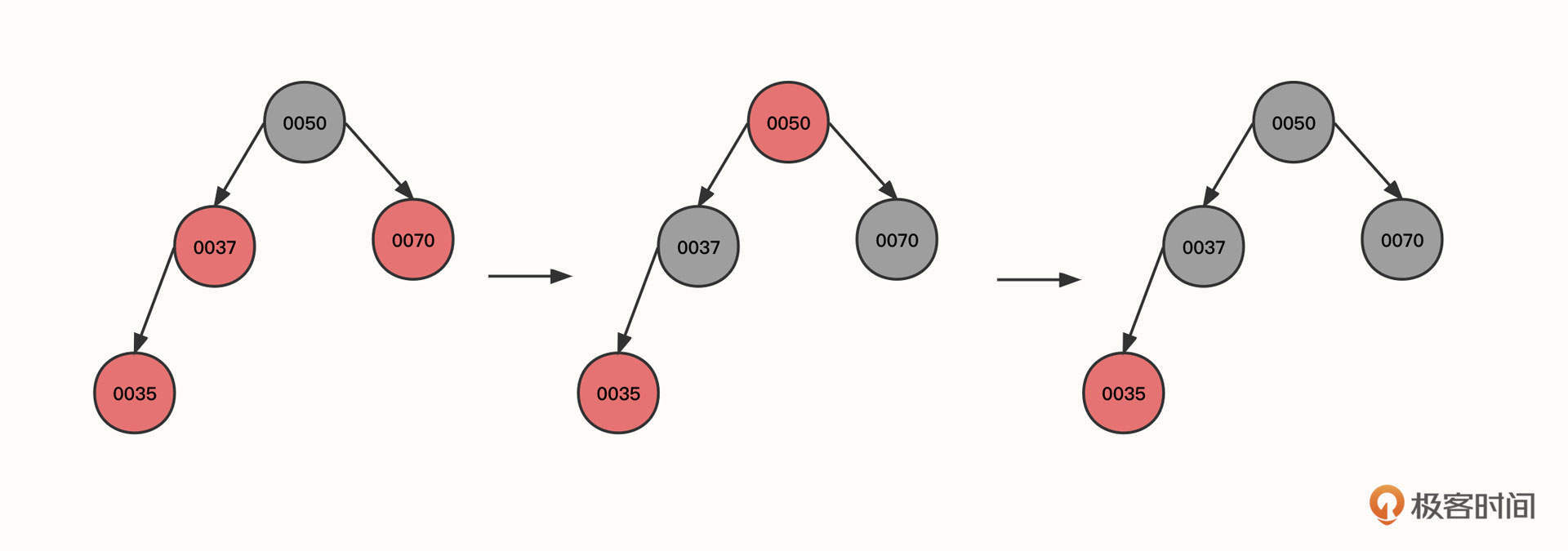
这个时候,新插入的节点0035的父节点(00037)和叔叔节点(0070)都是红色,所以我们需要将0035的祖父节点的颜色传递到它的两个子节点,这样也就到了图里的第二个状态。由于根节点的颜色为红色,不符合红黑树的特点,我们再将根节点的颜色变更为黑色。
3. 继续插入节点25****:
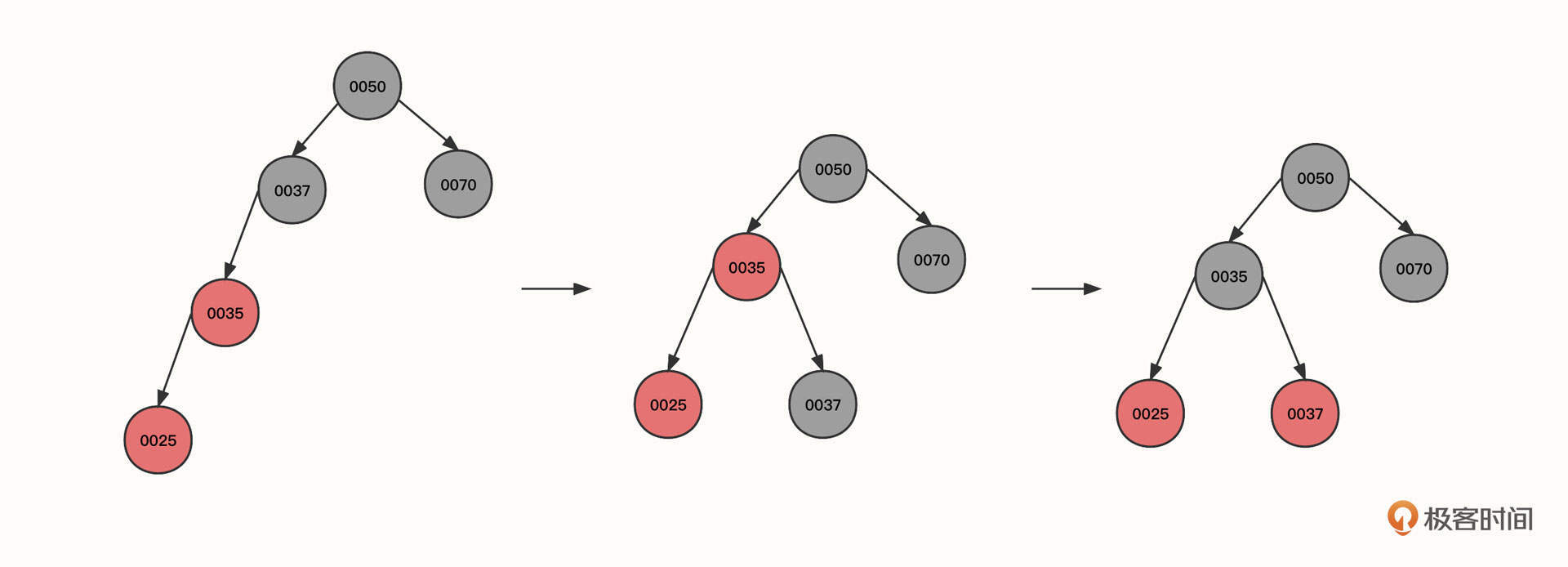
可以看到,初始状态的当前节点、父节点和祖先节点的形状为一条斜线。这时红色节点0025与0035都是红色,违背了红黑树的性质4,这种情况可以使用右旋来解决,具体操作是:
- 让当前节点(0025)的祖先节点(0037)下沉,作为当前节点的父节点(0035)的右子节点。同时,当前父节点(0025)的祖先节点(0050)的左节点指向当前节点的父节点,这样,0050的左节点就直接指向了0035。本轮操作后变成图里的第二个状态。
- 旋转之后0035节点的右子树路径多了一个黑色的节点0037,为了符合红黑树的特性,我们需要将0037父节点的颜色进行翻转,变成图里的第三个状态。
总结一下,右旋的第一个触发条件:当前节点与父亲节点为红色,并且都是左节点。
4. 继续插入节点30:
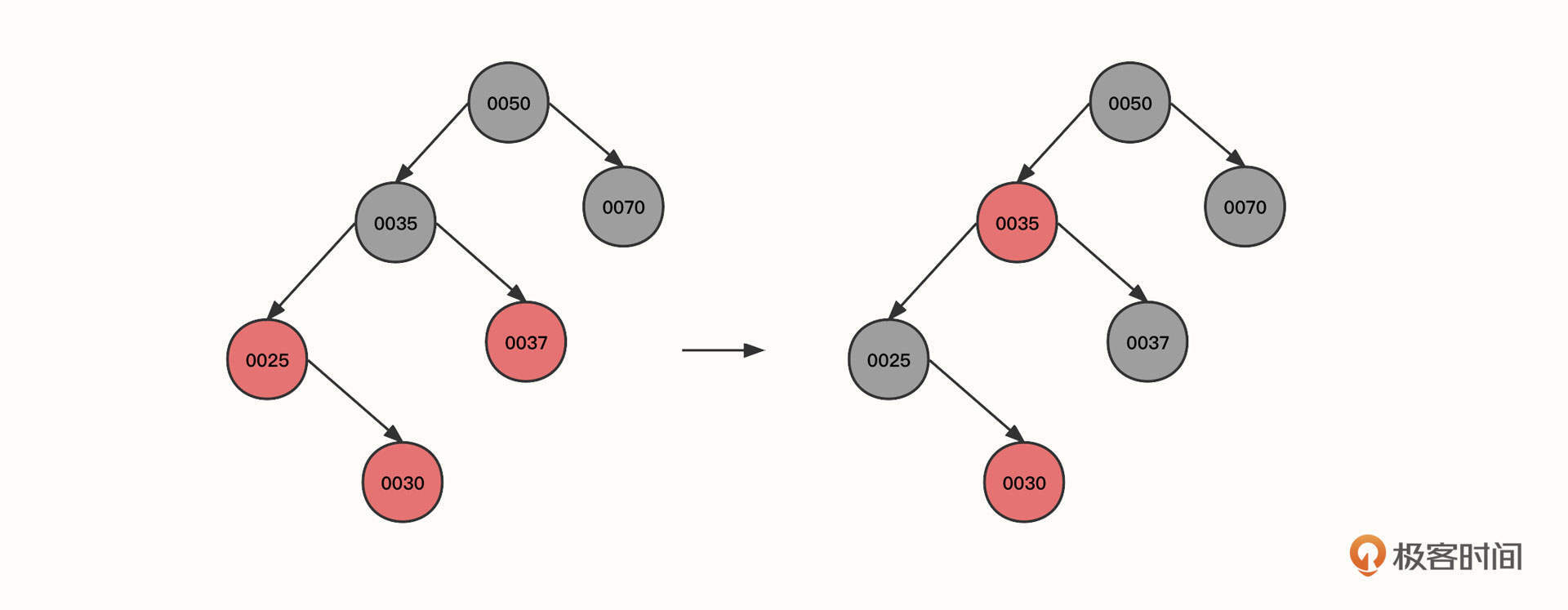
当前节点(0030)、父节点(0025)和叔叔节点(0037)都为红色,所以可以将当前节点的祖先(0035)的状态传递给子节点,变成上图第二个状态。
5. 继续插入节点26:
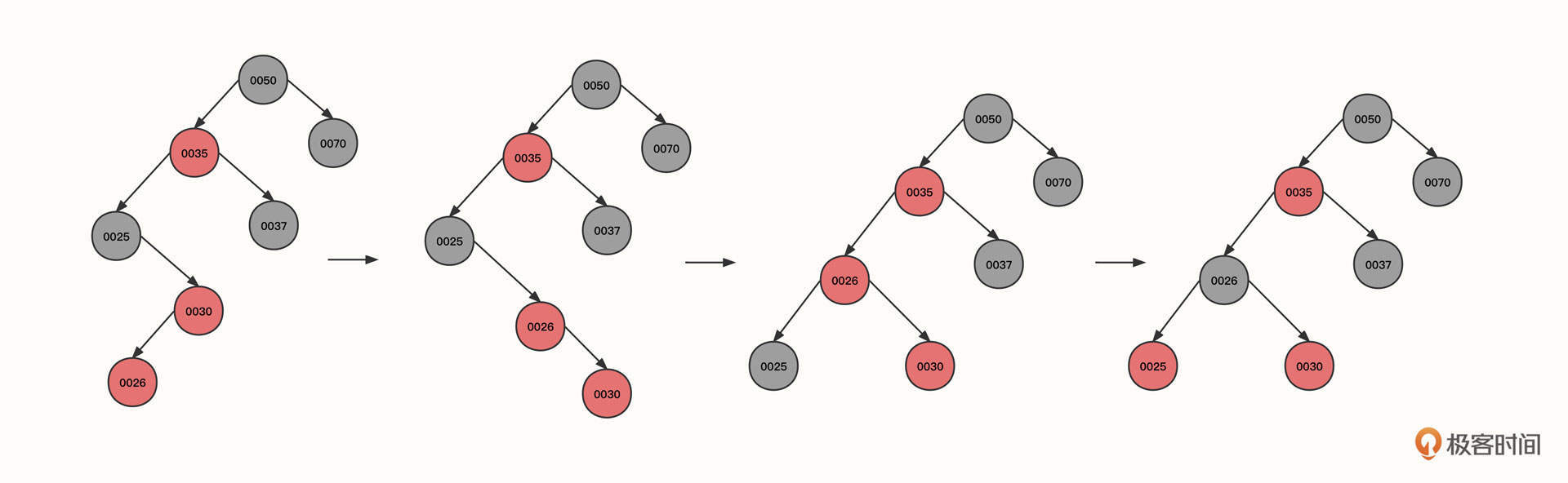
可以看到,现在的状态是,当前节点(0026)和父节点(0030)为红色,当前节点为左子树,父节点为右子树,并且叔叔节点并不为红色(组成一个大于号)。
这时候我们也需要右旋,以当前节点为支点,将其父节点作为当前节点的右节点,当前节点重新充当其祖父节点的右节点,状态从图一转为图二。
这是右旋的第二个触发条件:当前节点、父节点、祖父节点的形状为大于号,而且当前节点的父节点为支点。
状态变为图二之后,当前节点(0030)与父节点(0026)都是红色,并且都是右节点,所以应该执行一次左旋。以父节点0026为支点,将当前节点(0030)的祖父节点(0025)变为父节点(0026)的左子节点,经过这个动作后,状态从图二转为图三。
左旋之后,黑色节点0025变成了节点0026的左子树,左子树的黑色节点数量变多,所以我们需要将黑色传递到父节点,也就是要把节点0025变为红色,0026变为黑色,变成图中的第四个状态。
6. 我们接着插入节点80,此时不会改变红黑色特性,再插入节点90:
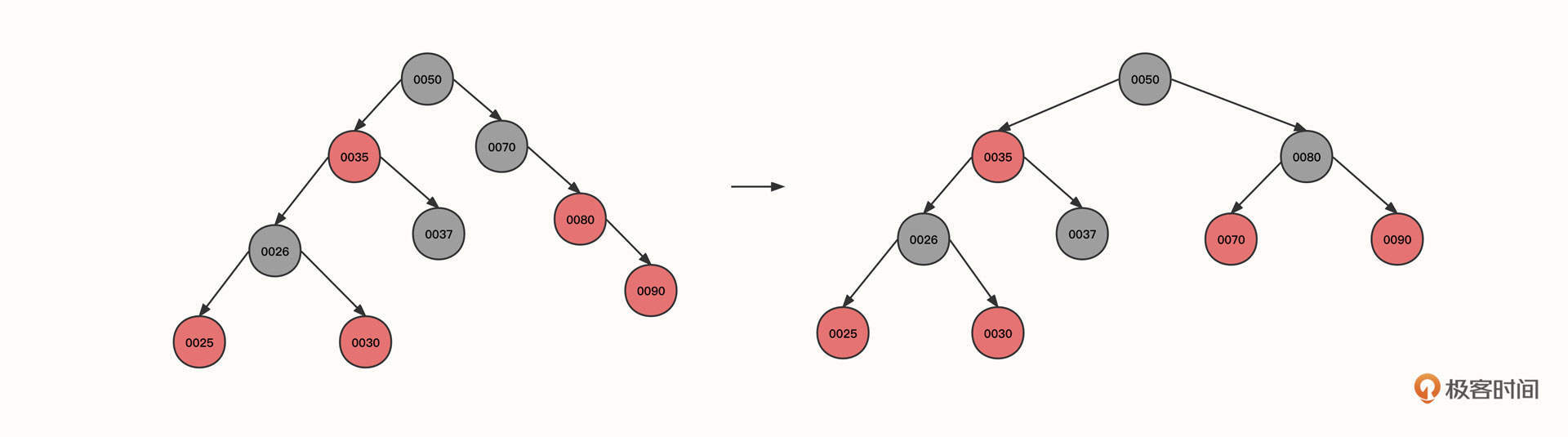
由于当前节点与父节点都是红色,并且都是右节点,需要执行左旋。
其实,到底什么时候需要左旋,什么时候需要右旋你没有必要死记硬背。因为左旋、右旋的最终目的是要满足树的平衡,也就是降低树的层级。只要确保旋转后的最终效果满足二叉排序树的定义(根节点比左子树大,比右子数小)就可以了。
7. 继续插入节点100、20:
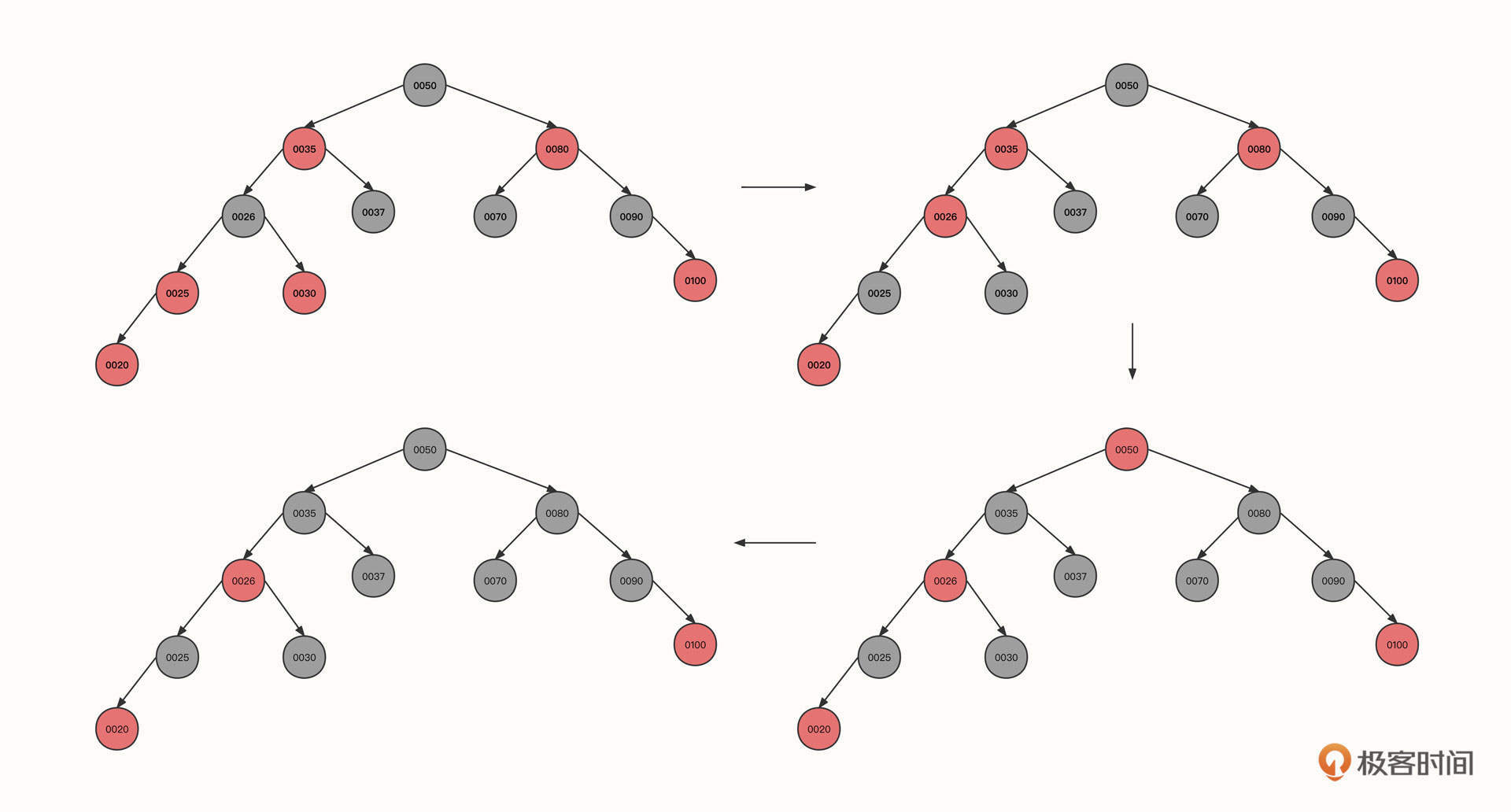
到这里我们就需要说明一下了。
这一步和步骤2一样,当前节点、父节点和叔叔节点都是红色,只需要将当前节点的祖父节点的颜色传递到祖父节点的两个子节点就可以了,这就到了图中的第二个状态。
但这个时候,0026和它的父节点0035同为红色,并且叔叔节点也是红色,我们需要再像上面一样传递颜色,调整后变成图里的第三个状态。
最后,由于根节点是红色,我们需要将根节点转为黑色。
这里重点强调的是,无论是左旋、右旋还是变色,都需要再次向上递归进行验证。
8. 继续插入18、32、75、85等节点:
到这一步基本没有什么新的知识点了,按照我们前面所讲过的方法进行调整,就可以得到上面这棵红黑树了。
红黑树的构建过程就介绍到这里。红黑树的主要过程就是通过为节点引入颜色、左旋、右旋、变色等手段实现树的平衡,保证查询功能高效有序进行。
聊完数据结构,我们再来看看它的应用。其实,TreeMap在中间件开发领域的运用非常广泛,其中最出名的估计要属使用TreeMap实现一致性哈希算法了。
下面是一致性哈希算法的示意图:
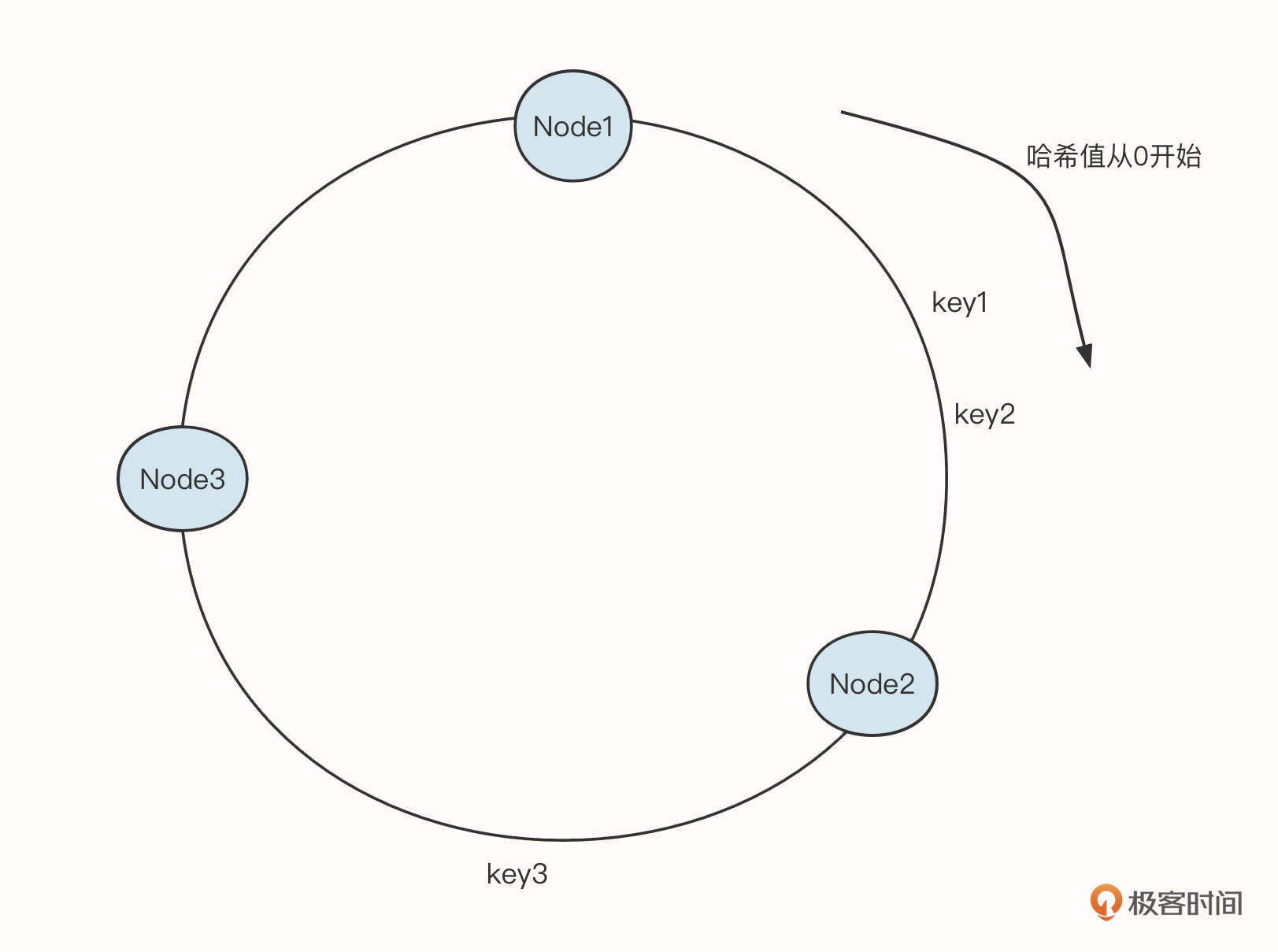
其中,Node1、Node2、Node3是真实存储的有效数据,每一个节点需要存储一些关联信息,很适合key-value的存储形式。一致性哈希算法的查询规则是:查询第一个大于目标哈希值的节点。
例如,如果输入key1,key2,需要命中Node2,如果输入key3,则需要命中Node3。
这种情况其实就是需要将数据按照key进行排序,而TreeMap中的数据本身就是顺序的,所以非常适合这个场景。
在RocketMQ中,就使用了一致性哈希算法来实现消费组队列的负载均衡。

TreeMap的TailMap是返回大于等于key的子树,然后调用子树的firstKey获取TreeMap中最小的元素,符合一致性哈希算法的命中规则。又因为TreeMap是一棵排序树,所以得到最小、最大值会非常容易。
在TreeMap中实现firstkey方法时,内部会先获取TreeMap中的键值对,也就是Entry对象:

然后从根节点开始遍历,查找到节点的左子树,再一直遍历到树的最后一个左节点,时间复杂度为O(logN)。
LinkedHashMap
红黑树就介绍到这里了,接下来我们再来看一个与LRU相关的数据结构LinkedHashMap。
LinkedHashMap是LinkedList和HashMap的结合体,它内部的存储结构可以简单表示为下面这样:
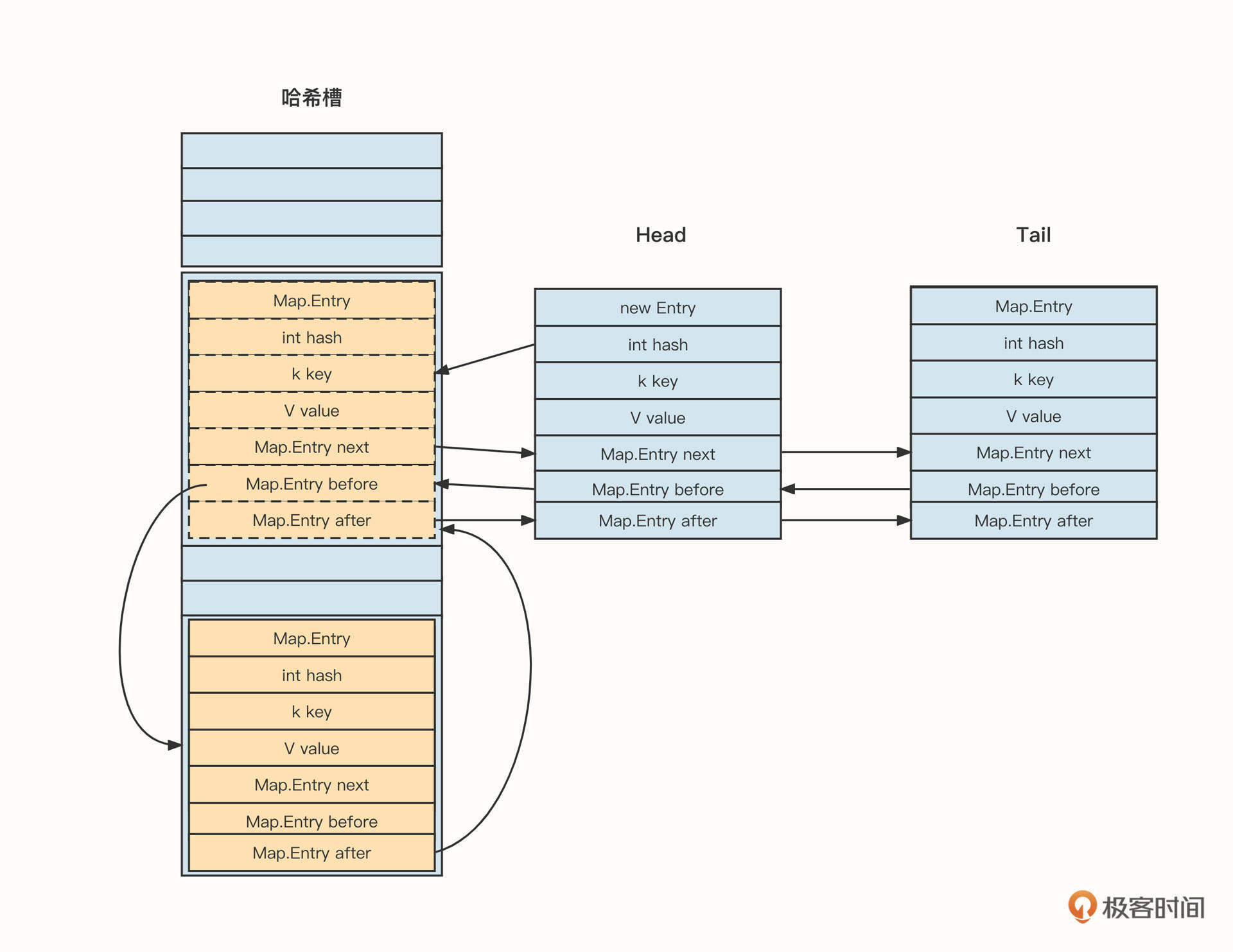
LinkedHashMap内部存储的Entry在HashMap的基础上增加了两个指针:before和after。这两个节点可以对插入的节点进行链接,以此来维护顺序性。同时,链表结构为了方便插入,也会持有“头尾节点”这两个指针。
那引入链表有什么好处呢?
我认为大概有下面两个优点。
一个是降低了遍历实现的复杂度。我们对比一下,HashMap的遍历是首先遍历哈希槽,然后遍历链表;但LinkedHashMap则可以基于头节点遍历,复杂度明显降低。引入链表的第二个优点则是提供了顺序性。接下来,我们就来看看LinkedHashMap的顺序性和使用场景。
LinkedHashMap提供了两种顺序性机制:
- 按节点插入顺序,是LinkedHashMap的默认行为;
- 按节点的访问性顺序,最新访问的节点将被放到链表的末尾。
它的使用场景也很常见,有一种知名的淘汰算法叫LRU。顾名思义,LRU就是要淘汰最近没有使用的数据。在Java领域,实现LRU的首选就是LinkedHashMap,因为LinkedHashMap能够按访问性排序。
在LinkedHashMap中,如果顺行性机制选择“按访问顺序”,那么当元素被访问时,元素会默认被放到链表的尾部,并且在向LinkedHashMap添加元素时会调用afterNodeInsertion方法。这个方法的具体实现代码如下:
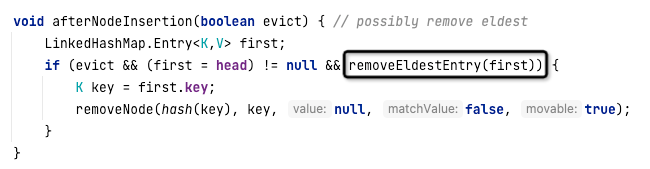
从代码中可以看出,如果removeEldestEntry函数返回true,则会删除LinkedHashMap中的第一个元素,这样就淘汰了旧的数据,实现了LRU的效果。removeEledestEntry方法的代码如下:

可以看到,默认返回的是false,表示LinkedHashMap并不会启用节点的淘汰机制。为了实现LRU算法,我们需要继承LinkedHashMap并重写该方法,具体实现代码如下:
1 | package net.codingw.datastruct; |
LinkedHashMap就介绍到这里了,我们再来看一种特殊的队列——优先级队列,它是实现定时调度的核心数据结构。
PriorityQueue
我们知道,普通队列都是先进先出的,但优先级队列不同,它可以为元素设置优先级,优先级高的元素完全可以后进先出。
我们先来看一下PriorityQueue的类图:

优先级队列的底层结构是数组,可是怎么在数组的基础上排列优先级呢?原来,PriorityQueue的底层是基于最小堆实现的堆排序。
所谓最小堆指的是一棵经过排序的完全二叉树,根结点的键值是所有堆结点键值中最小者。无论是最大堆还是最小堆,都只固定根节点与子节点的关系,两个子节点之间的关系并不做强制要求。
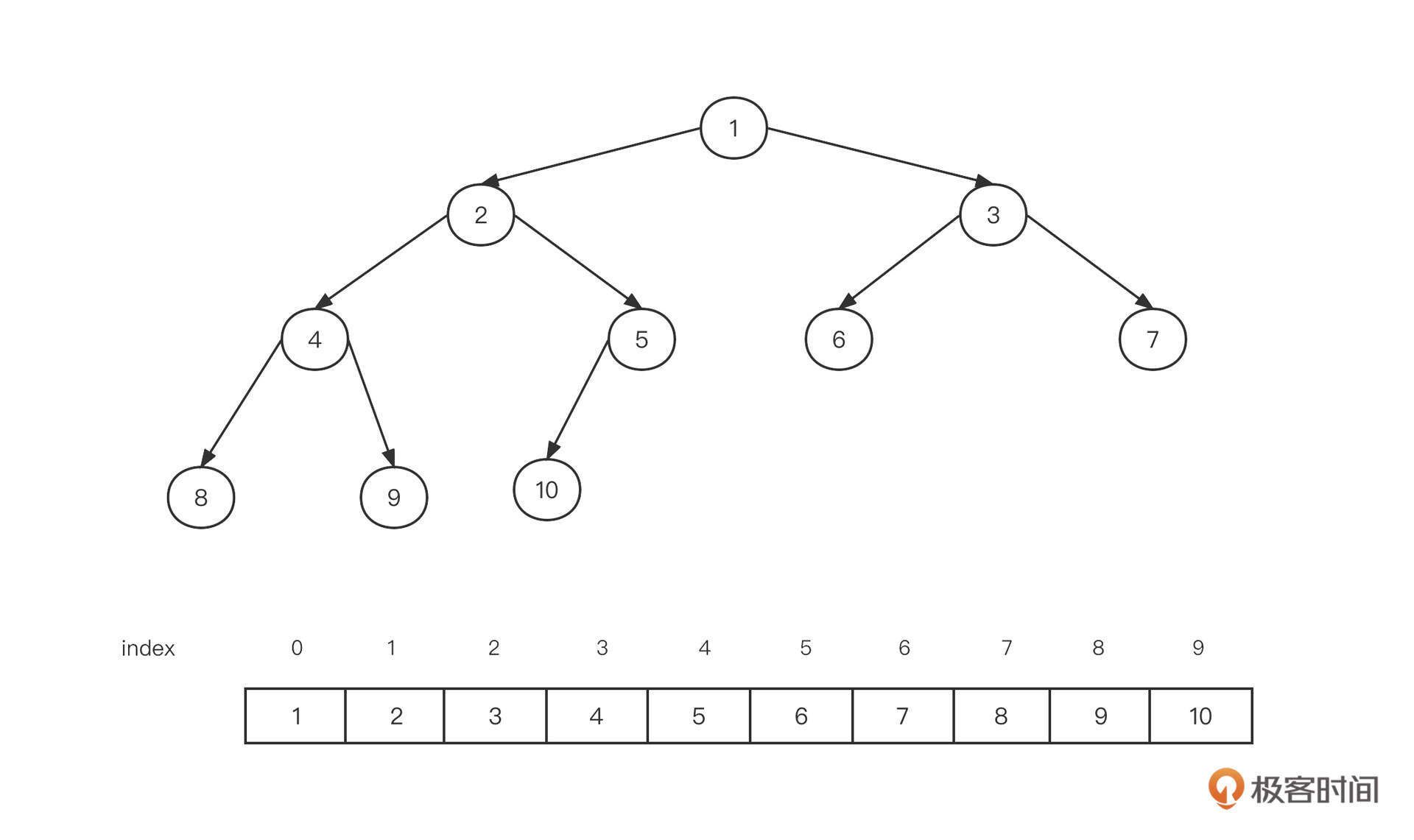
我们采用数组作为最小堆的底层数据结构,将最小堆用一棵二叉树来表示,这时的数据是按照从上到下、从左到右的方式依次存储在数组中的:
这种存储方式有两个特点:
- 假设一个节点在数组中的下标为n,则它的左子节点的下标为2n+1,它的右子节点的下标为2n+2;
- 假设一个节点在数组中的下标为n,那么它的父节点下标为 (n -1) >>> 1。
有些最小堆的存储方式是将数组的第一个元素空出来,把根节点存储在下标为1的位置。如果基于这种方式,存储有下面两个特点:
- 假设一个节点在数组中的下标为n,则它的左子节点的下标为2n,它的右子节点的下标为2n+1;
- 假设一个节点在数组中的下标为n,则它的父节点下标为 (n) >>> 1。
但在实践场景中,数据不可能按顺序插入,既然如此,要实现优先级队列,该怎么对这棵树进行排序呢?
PriorityQueue队列的实现中采用了堆排序。我们还是用图解的方式来看一下构建规则。
首先我们连续插入节点 500,600,700,800,其内部结构如下图所示:
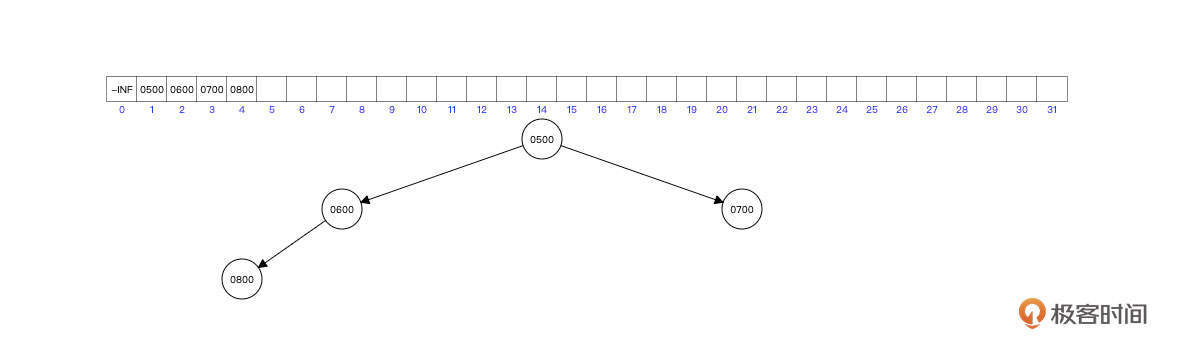
由于首先插入了根节点为500,后续600,700比根节点都小,所以600和700可以直接成为根节点的左右子树。
继续插入800,由于比根节点大,同时比600大,则直接放入到600的子节点即可。
继续插入490,插入过程如下图所示:
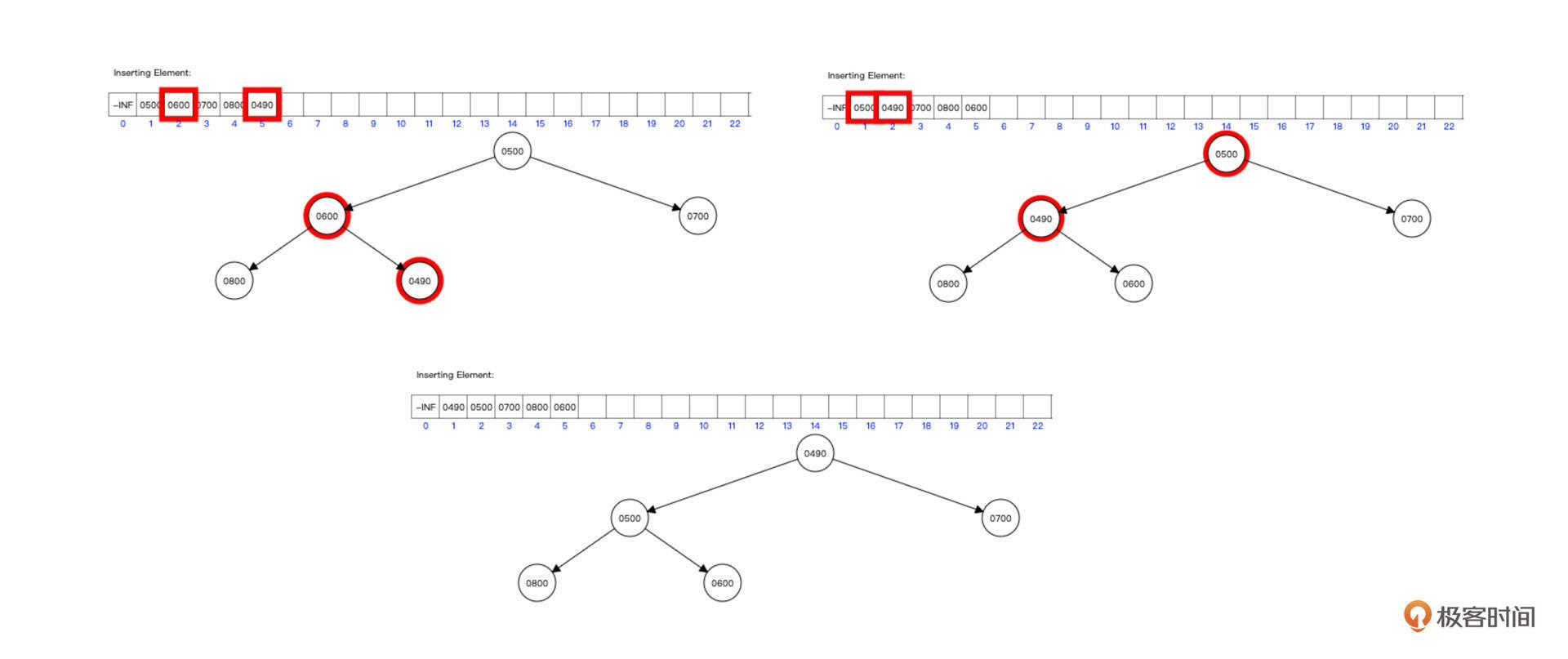
解释一下。我们首先将新元素插入到数组的最后,下标为n=5,队列是图中的第一个状态。
根据公式 n >>> 1 ,可以算出它的父节点的下标为2,比较两者的大小,如果新插入的节点比父节点少,那么交换两者的值,变化到图中的第二个状态。
这时候,我们再通过公式n>>>1算出父节点的下标为1,比较两者的值,发现子节点的值比父节点的值低,则继续交换两者的值,成为图中的第三个状态。
要实现上面的步骤,我们相应的代码是:
1 | private void siftUp(int k, E x) { |
在这段代码里,我们首先使用while(k>0)实现递归,因为最小堆是将新插入的节点放在叶子结点,然后不断与其父节点进行比较,直到到达根节点。
然后,我们要根据当前节点的序号,计算其父节点的序号(这里的算法与图解方式不一样,是因为PriorityQueue是将根节点的下标定为0),然后比较大小:
- 如果当前节点比父节点的值大,则跳出循环,符合最小堆的要求;
- 如果当前节点比父节点的值小,则交换两者的值,将k的值赋值为父节点(k = parent),然后继续向上递归做判断。
构建好堆之后,我们再来看看怎么从堆中获取数据。要注意的是,访问数据只能从堆的根节点开发方法,具体做法就是删除根节点,并将根节点的值返回。我们先尝试删除根节点490:
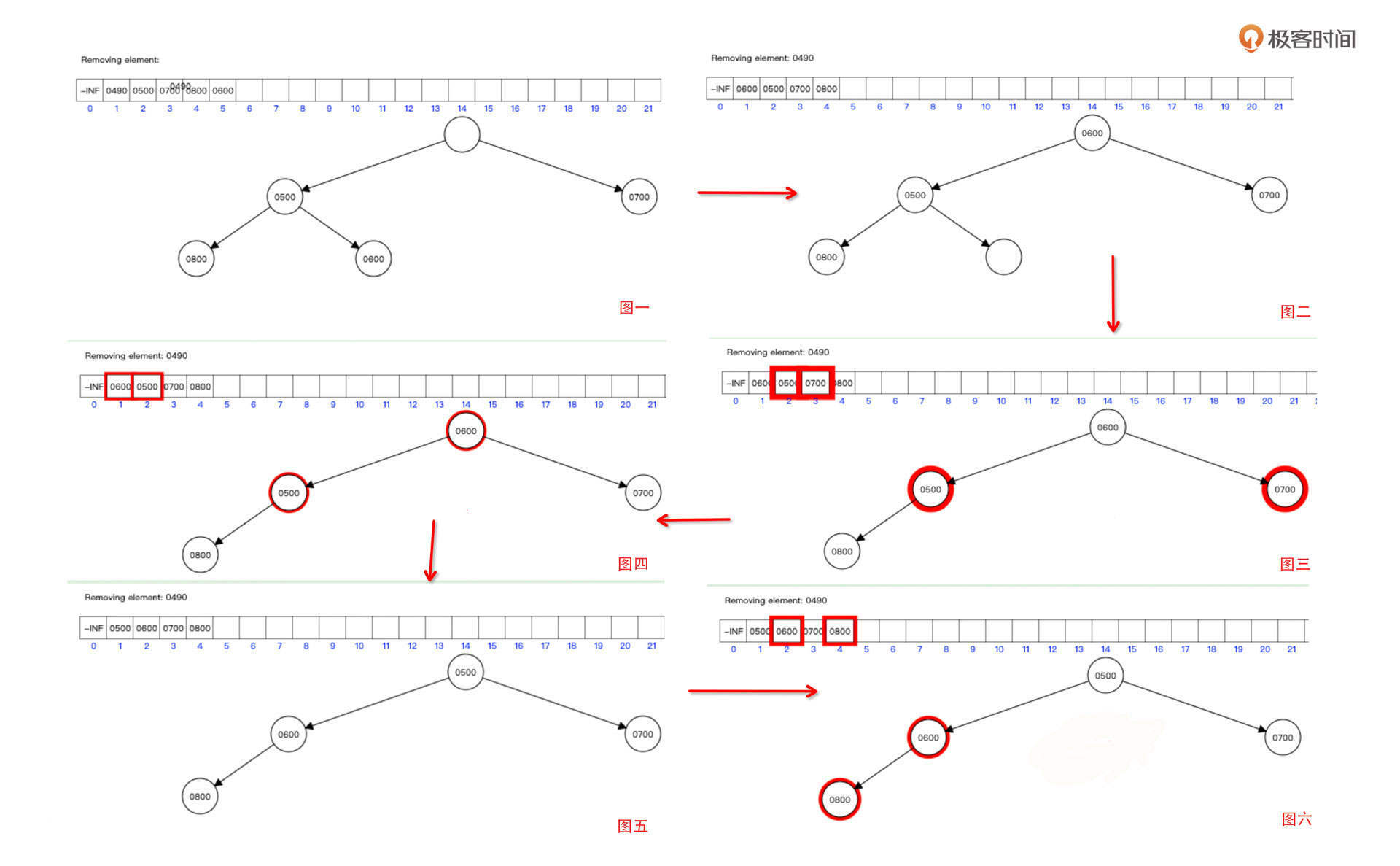
删除根节点和删除其他任何节点的算法是一样的:
- 首先,我们将待删除的位置的值清除,状态为图一。
- 然后,将数组最后的元素移动到待删除位置,我们用下标n表示。删除根节点,n为0,状态转为图二。
- 接下来,根据下标算法分别算出其子节点的下标为2n、2n+1,从左右节点中挑选最小值,如图三。
- 用父节点的值与左右子节点中最小的值进行对比,如图四。如果父节点比最小子节点大,则交换两者的值,如图五。
- 我们要一直往下递归,直到节点没有子节点,或者没有父节点比子节点小为止。
结合这张图,我们同样来看一下PriorityQueue中删除元素的代码:
1 | private void siftDown(int k, E x) { |
可以看到,在这段代码中,我们设定half为size的一半,如果下标大于half,则下标对应的位置不会再有子节点,可以跳出循环。
代码的第12行是计算左右节点下标的公式,我们可以按照公式算出左右节点的下标,并比较两者的大小,挑选更小的值与父节点进行对比。
最后,我们再来看一下优先级队列的应用场景。其实,JUC中的定时调度线程池ScheduledExecutorService的底层就使用了优先级队列。
定时任务调度线程池的基本实现原理是:
在将调度任务提交到线程池之前,首先计算出下一次需要执行的时间戳,通过时间戳来计算优先级,将其存入最小堆中,这样就确保了最先需要执行的调度任务位于最小堆的顶部(也就是根节点)。
然后开一个定时任务,拿队列中第一个元素和当前时间进行比较: - 如果下一次执行时间大于等于当前时间,则将队列中第一个元素(调度任务)从队列中移除,投入线程池中执行。
- 如果下一次执行时间小于当前时间,则不处理,因为队列中最小的待执行任务都还没有到执行时间,其他任务一定也是这样。
可以看到,定时调度场景的关键是找到第一个需要触发的任务,类似SQL中的min语义,重在优先二字,而优先级队列的实现原理同样注重优先。理念上的契合让定时任务调度和优先级队列经常绑定在一起出现。
总结
好了,这节课就讲到这里。内容比较多,但是把脉络拎出来,其实我们主要讲了三种数据结构。
其中,树是数据结构中比较难但同时也非常常见的一种数据结构。我们从二叉排序树的优劣势出发,引出了红黑树,并用图解的方式详细介绍了红黑树的构建过程,介绍了红黑树的左旋、右旋、变色方法,还列举了红黑树的经典应用场景。
紧接着我们介绍了LinkedHashMap,它是链表与HashMap的结合体。LinkedHashMap既拥有HashMap快速的检索能力,还引入了节点顺序性,可以基于它实现LRU缓存淘汰算法。
最后,我们还通过图解认识了优先级队列,看到了用数组存储树的高阶用法,以及堆排序的工作机制和应用场景。
希望你能够借这个机会再巩固一下自己的基础知识,有所收获。同时,我也建议你在学完这些数据结构基本原理之后,有针对性地阅读一下源码,提炼出自己的学习方法。
课后题
最后我还是照例给你留两道课后题吧!
1、请你根据红黑树的特性,实现一棵红黑树(插入、删除、查找)。
2、红黑树和最小堆之间有什么区别,各自适用于什么场景?
欢迎你在留言区与我交流讨论,我们下节课见!
05 | 多线程:多线程编程有哪些常见的设计模式?
作者: 丁威

你好,我是丁威。
从这节课开始,我们开始学习Java多线程编程。
多线程是很多人在提升技术能力的过程中遇到的第一个坎,关于这部分的资料在网络上已经很多了,但是这些资料往往只重知识点的输出,很少和实际的生产实践相挂钩。但是我不想给你机械地重复“八股文”,接下来的两节课,我会结合这些年来在多线程编程领域的经验,从实际案例出发,带你掌握多线程编程的要领,深入多线程的底层运作场景,实现理解能力的跃升。
如何复用线程?
线程是受操作系统管理的最核心的资源,反复创建和销毁线程会给系统层面带来比较大的开销。所以,为了节约资源,我们需要复用线程,这也是我们在多线程编程中遇到的第一个问题。那怎么复用线程呢?
我们先来看一小段代码:
1 | Thread t = new Thread(new UserTask()); |
请你思考一下,这段代码会创建一个操作系统线程吗?
答案是不会。这段代码只是创建了一个普通的Java对象,要想成为一个真实的线程,必须调用线程的start方法,让线程真正受操作系统调度。而线程的结束和run方法的执行情况有关,一旦线程的run方法结束运行,线程就会进入消亡阶段,相关资源也会被操作系统回收。
所以要想复用线程,一个非常可行的思路就是,不让run方法结束。
通常我们会想到下面这种办法:
1 | class Task implements Runnable { |
通过一个while(true)死循环确保run方法不会结束,然后不断地判断当前是否可以执行业务逻辑;如果不符合执行条件,就让线程休眠一段时间,然后再次进行判断。
这个方法确实可以复用线程,但存在明显的缺陷。因为一旦不满足运行条件,就会进行反复无意义的判断,造成CPU资源的浪费。另外,在线程处于休眠状态时,就算满足执行条件,也需要等休眠结束后才能触发检测,时效性会大打折扣。
那我们能不能一有任务就立马执行,没有任务就阻塞线程呢?毕竟,如果线程处于阻塞状态,就不会参与CPU调度,自然也就不会占用CPU时间了。
答案当然是可以的,业界有一种非常经典的线程复用模型:while循环+阻塞队列,下面是一段示范代码:
1 | class Task implements Runnable { |
我们来解读一下。这里,我们用AtomicBoolean变量来标识线程是否在运行中,用while(running.get())替换while(true),方便优雅地退出线程。
线程会从阻塞队列中获取待执行任务,如果当前没有可执行的任务,那么线程处于阻塞状态,不消耗CPU资源;一旦有任务进入到阻塞队列,线程会被唤醒执行任务,这就很好地保证了时效性。
那怎么停止一个线程呢?调用线程的shutdown方法一定能停止线程吗?
答案是不一定。 如果任务队列中没有任务,那么线程会一直处于阻塞状态,不能被停止。而且,Java中Thread对象的stop方法被声明为已过期,直接调用并不能停止线程。那怎么优雅地停止一个线程呢?
原来,Java中提供了中断机制,在Thread类中与中断相关的方法有三个。
- public void interrupt():Thread实例方法,用于设置中断标记,但是不能立即中断线程。
- public boolean isInterrupted():Thread实例方法,用于获取当前线程的中断标记。
- public static boolean interrupted():Thread静态方法,用于获取当前线程的中断标记,并且会清除中断标记。
如果调用线程对象的interrupt()方法,会首先设置线程的中断位,这时又会出现两种情况:
- 如果线程阻塞在支持中断的方法上,会立即结束阻塞,并向外抛出InterruptedException(中断异常);
- 如果线程没有阻塞在支持中断的方法上,则该方法不能立即停止线程。
不过要说明的是,JUC类库中的所有阻塞队列、锁、Object的wait等方法都支持中断。
通常,我们需要在代码中添加显示的中断检测代码,我还是用前面的例子给出示例代码,你可以看一下:
1 | static class Task implements Runnable { |
我们继续说回线程的复用。JUC框架提供了线程池供我们使用。关于线程池相关的基础知识,你可以参考我之前的文章《如何评估一个线程池需要设置多少个线程》,这里我就不过多展开了。接下来,我就结合自己的工作经验分享一下怎么在实战中使用线程池。
我非常不建议你直接使用Executors相关的API来创建线程池,因为通过这种方式创建的线程池内部会默认创建一个无界的阻塞队列,一旦使用不当就会造成内存泄露。
我更推荐你使用new的方式创建线程,然后给线程指定一个可阅读的名称:
1 | ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 5, 0, TimeUnit.MILLISECONDS, |
这样,当系统发生故障时,如果我们想要分析线程栈信息,就能很快定位各个线程的职责。例如,RocketMQ的消费线程我就会以“ConsumeMessageThread_”开头。
使用线程池另一个值得关注的问题是怎么选择阻塞队列,是使用无界队列还是有界队列。
通常,我们可以遵循这样的原则:对于Request-Response等需要用户交互的场景,建议使用有界队列,避免内存溢出;对于框架内部线程之间的交互,可以根据实际情况加以选择。
我们通过几个例子来看一下具体的场景。
项目开发中通常会遇到文件下载、DevOps的系统发布等比较耗时的请求,这类场景就非常适合使用线程池。基本的工作方式如图:
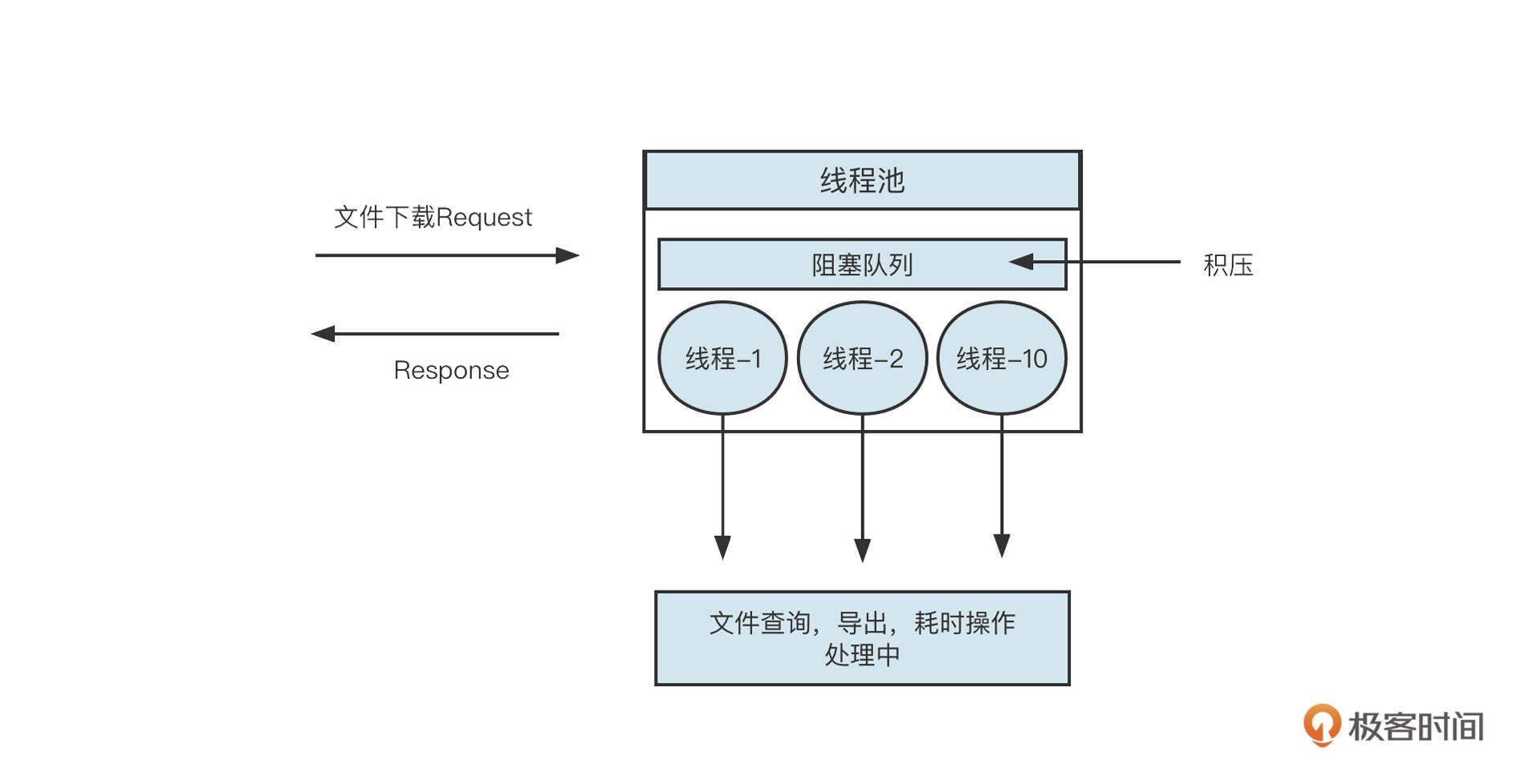
在与用户交互的场景中,如果几十万个文件下载请求同时提交到线程池,当线程池中的所有线程都在处理任务时,无法及时处理的请求就会存储到线程池中的阻塞队列中。这就很容易使内存耗尽,从而触发Full-GC,导致系统无法正常运作。
因此,这类场景我建议使用有界队列,直接拒绝暂时处理不了的请求,并给用户返回一条消息“请求排队中,请稍后再试”,这就保证了系统的可用性。
在一个线程或多个线程向一个阻塞队列中添加数据时,通常也会使用有界队列。记得我在开发数据同步产品时,为了实现源端与目标端线程,就采用了阻塞队列,下面是一张示意图:
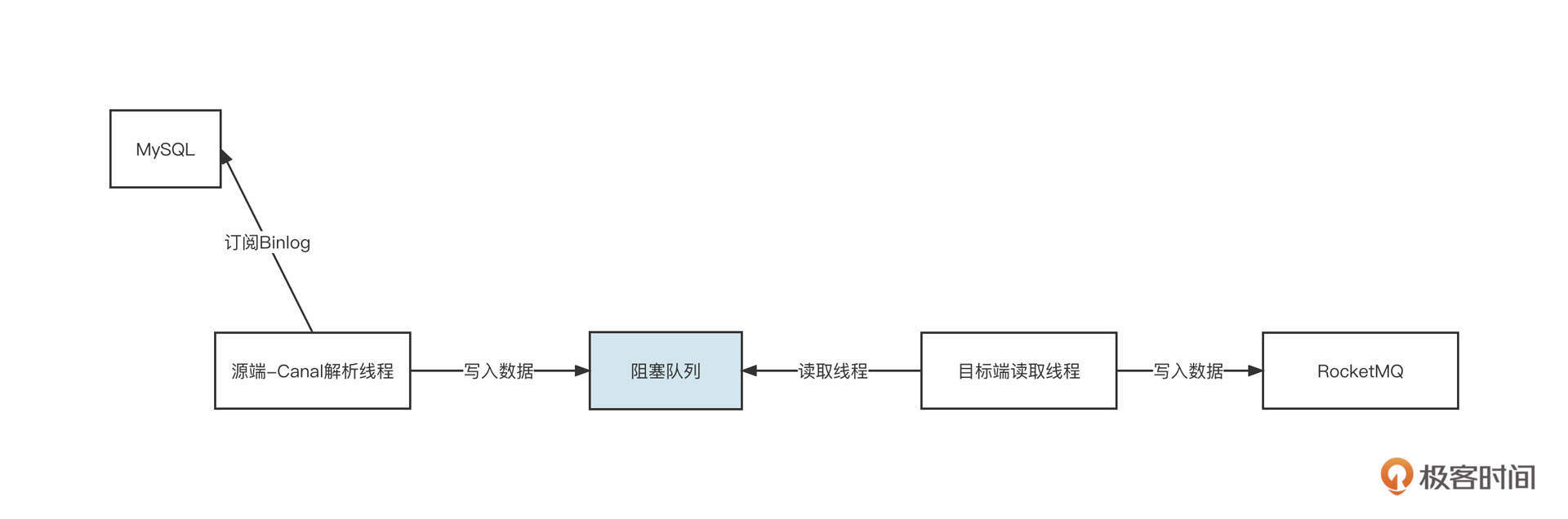
为了实现MySQL增量同步,Canal线程源源不断地将MySQL数据写入到阻塞队列,然后目标端线程从队列中读取数据并写入到MQ。如果写入端的写入速度变慢,阻塞队列中的数据就变得越来越多,一旦不加以控制就可能导致内存溢出。所以,为了避免由于写入端性能瓶颈造成的整个系统的不可用,这时候需要引入有界阻塞队列。这样,队列满了之后,我们就能让源端线程处于阻塞状态,从而对源端进行限流。
但在选择阻塞队列时还可能有另外一种情况,那就是一个线程对应多个阻塞队列,这时我们一般会采用无界阻塞队列+size的机制,实现细粒度限流。当时,我设计的RocketMQ消费模型是下面这样:
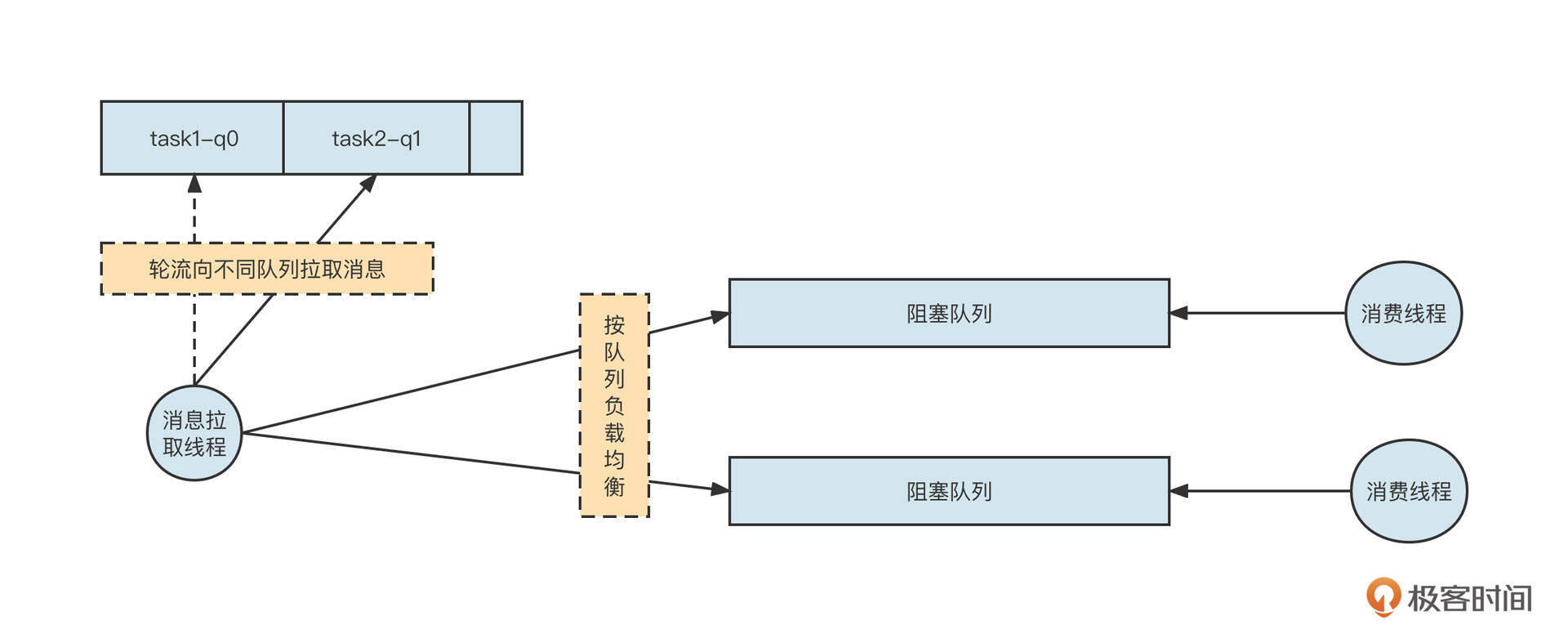
一个拉取线程轮流从Broker端队列(q0、q1)中拉取消息,然后根据队列分别放到不同的阻塞队列中,每一个阻塞队列会单独分配单个或多个线程去处理。
这个时候,采用有界队列可能出现问题。如果我们采用有界队列,一旦其中一个阻塞队列对应的下游消费者处理性能降低,阻塞队列中没有剩余空间存储消息,就会阻塞消息发送线程,最终造成另外一个任务也无法拉取新的消息。显然,这会让整体并发度降低,影响性能。
那如果采用无界队列呢?单纯使用无界队列容易导致内存泄露,触发更严重的后果,好像也不是一个好的选择。
其实我们可以在无界队列的基础上额外引入一个参数,用它来控制阻塞队列中允许存放的消息条数。当阻塞队列中的数据大于允许存放的阔值时,新的消息还可以继续写入队列,不会阻塞消息发送线程。但我们需要给消息拉取线程一个反馈,暂时停止从对应队列中拉取消息,从而实现限流。
阻塞队列是多线程协作的核心纽带,除了清楚它的使用方法,我们还应该理解它的使用原理,也就是 “锁 + 条件等待与唤醒”。我们来看一下LinkedBlockingQueue 的put的实现代码:
1 | public void put(E e) throws InterruptedException { |
这里,我重点解读一下关键代码。
第8行:我们要申请锁,获取队列内部数据存储结构(LinkedBlockingQueue底层结构为链表)的修改控制权,也就是让一个阻塞队列同一时刻只能操作一个线程。
第10行:判断队列中元素的数量是否等于其最大容量,如果是,则线程进入到条件等待队列(第13行),调用put的线程会释放锁进入到阻塞队列。当队列中存在空闲空间时,该线程会得到通知,从而结束阻塞状态进入到可调度状态。
队列中有可用空间之后,线程被唤醒,但是不能立即执行代码(第15行),它需要重新和其他线程竞争锁,获得锁后将数据存储到底层数据结构中。关于锁的底层原理,我们会在下节课详细介绍。
这里也请你思考一下:为什么上面的代码我们要采用while(count.get() == capacity)而不使用if(count.get() == capacity)呢?
多线程编程常用的设计模式
如果你刚开始学习多线程编程,可能会觉得这个问题很难。不过不用担心,业界大佬早就总结出了很多和多线程编程相关的设计模式。接下来,我就带你一起看看其中应用最广的几个。
Future模式
多线程领域一个非常经典的设计模式是Future模式。它指的是主线程向另外一个线程提交任务时,无须等待任务执行完毕,而是立即返回一个凭证,也就是Future。这时主线程还可以做其他的事情,不会阻塞。等到需要异步执行结果时,主线程调用Future的get方法,如果异步任务已经执行完毕,则立即获取结果;如果任务还没执行完,则主线程阻塞,等待执行结果。
Future模式的核心要领是将多个请求进行异步化处理,并且可以得到返回结果。我们来看一个示例:
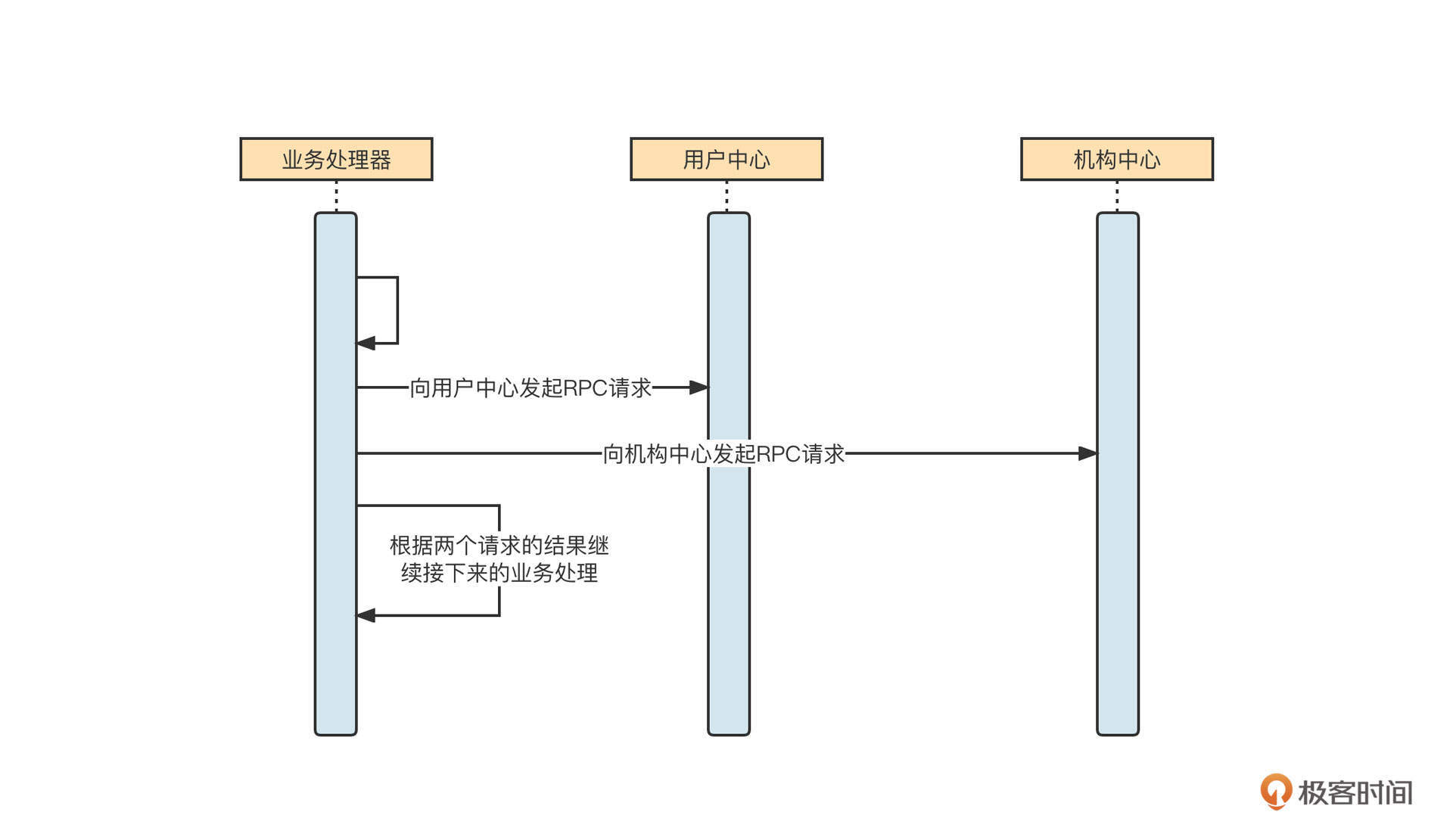
当一个请求在处理时,需要发起多个远程调用,并且返回多个请求,再根据结果进行下一步处理。它的伪代码如下:
1 | Object result1 = sendRpcToUserCenter(); // @1 |
说明一下,在不使用Future模式的情况下,两个远程RPC调用是串行执行的。例如,第一个请求需要1s才能返回,第二个请求需要1.5s才能返回,这两个过程就需要2.5s。为了提高性能,我们可以将这两个请求进行异步处理,然后分别得到处理结果。这就到了Future模式发挥作用的时候了。
业务开发领域通常会采用线程池的方式来实现Future模式,你可以看下具体的实现代码:
1 | package net.codingw.jk02; |
我们还是解读一下这段代码的要点。
- 首先,我们需要创建一个线程池。
- 接着,要将需要执行的具体任务进行封装,并实现java.util.concurrent.Callable接口(如上述代码中的Rpc2UserCenterTask),并重写其Call方法。
- 然后将一个具体的任务提交到线程池中去执行,返回一个Future对象。
- 在想要获取异步执行结果时,可以调用Future的get方法。如果任务已经执行成功,则直接返回;否则就会进入阻塞状态,直到任务执行完成后被唤醒。
因为线程池是一个较重的资源,而中间件领域的开发追求极致的性能,所以在中间件开发领域通常不会直接使用线程池来实现Future模式。
RocketMQ会使用CountDownLatch来实现Future模式,它的设计非常精妙,我们先一起来看一下它的序列图:
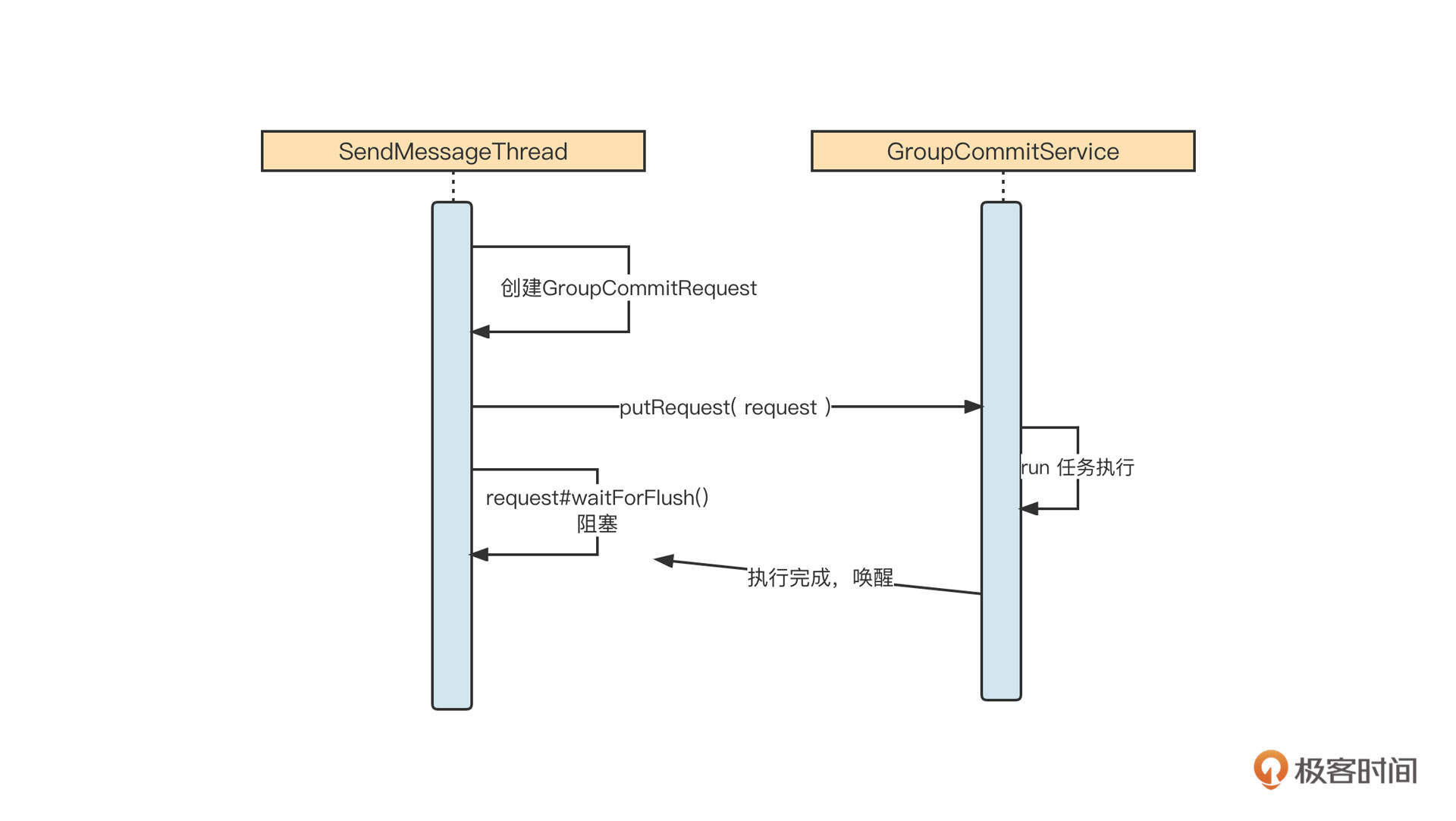
可以看到,SendMessageThread会首先创建一个GroupCommitRequest请求对象,并提交到刷盘线程,然后发送线程阻塞,等待刷盘动作完成。刷盘线程在执行具体刷盘逻辑后,会调用request的通知方法,唤醒发送线程。
乍一看,主线程提交刷盘任务之后并没有返回一个Future,那为什么说这是Future模式呢?这就是RocketMQ的巧妙之处了。它其实是把请求对象当作Future来使用了。我们来看一下GroupCommitRequest的实现代码:
1 | public static class GroupCommitRequest { |
在这里,GroupCommitRequest 中的 waitForFlush 方法相当于 Future 的 get 方法。具体实现是,调用CountDownLatch的await方法使自己处于阻塞状态,然后当具体的刷盘线程完成刷盘之后,通过调用wakeupCustomer方法,实际上调用了CountDownLatch的countDown方法,实现唤醒主线程的目的。
基于CountDownLatch实现的Future模式非常巧妙,更加得轻量级,性能也会更好。不过要说明的是,在业务开发领域,直接使用线程池将获得更高的开发效率和更低的使用成本。
生产者-消费者模式
Future模式就说到这里,我们再来看看多线程编程领域中最常见的设计模式:生产者-消费者模式。
程序设计中一个非常重要的思想是解耦合,在Java设计领域也有一条重要的设计原则就是要职责单一。基于这些原则,通常一个功能需要多个角色相互协作才能正常完成。
生产者-消费者模式正是这种思想的体现,它的理论也很简单,我们这里不会深入介绍。但我想用RocketMQ举一个实操的例子。
在RocketMQ消费线程模型中,应用程序在启动消费者时,首先需要根据负载算法进行队列负载,然后消息拉取线程会根据负载线程计算的结果有针对性地拉取消息。交互流程如下图所示:
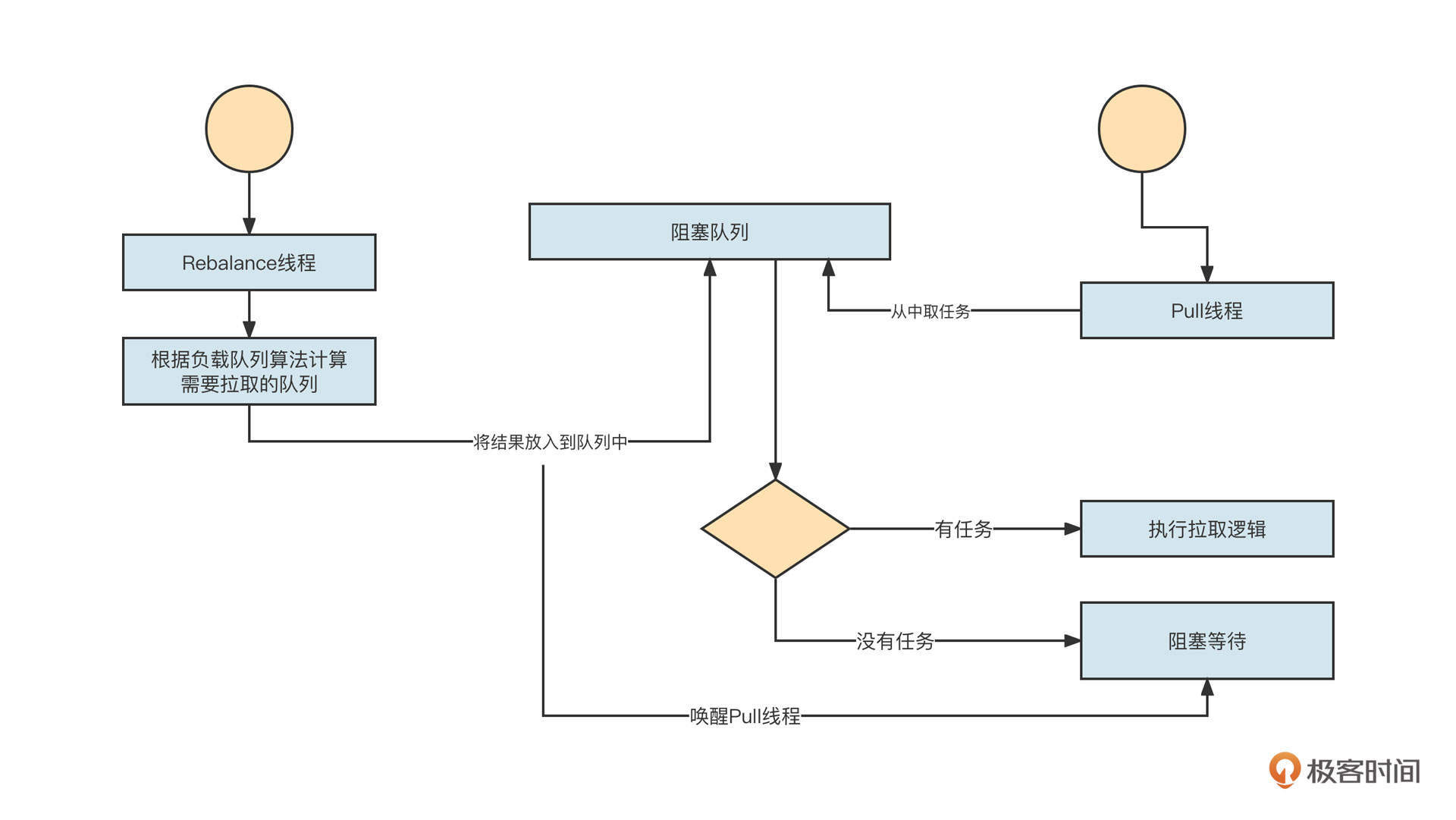
Rebalace线程作为生产者,会根据业务逻辑生成消息拉取任务,然后Pull线程作为消费者会从队列中获取任务,执行对应的逻辑;如果当前没有可执行的逻辑,Pull线程则会阻塞等待,当生产者将新的任务存入到阻塞队列中后,Pull线程会再次被唤醒。
系统的运行过程中会存在很多意料之外的突发事件,在高并发领域更是这样。所以在进行系统架构设计时,我们必须具备底线思维,对系统进行必要的兜底,防止最坏的情况发生,这里最常见的做法就是采用限流机制。
所以在这节课的最后,我们一起来看看并发编程领域如何实现限流。
线程池自带一定的限流效果,因为工作线程数量是一定的,线程池允许的最大并发也是确定的。一旦达到最大并发,新的请求就会进入到阻塞队列,或者干脆被拒绝。不过这节课我想给你介绍另一种限流的方法:使用信号量。
我们先来看一个具体的示例:
1 | public static void main(String[] args) { |
这段代码非常简单,其实就是通过信号量来控制doSomething方法的并发度,使用了信号量的两个主要的方法。
- tryAcquire:这种方法是尝试获取一个信号,如果当前没有剩余的许可,过了指定等待时间之后会返回false,表示未获取许可;
- release:归还许可,该方法必须在tryAcquire方法返回true时调用,不然会发生“许可超发”。
但是如果场景再复杂一点,比如doSomething是一个异步方法,前面这段代码的效果就会大打折扣了。如果doSomething的分支非常多,或者遇到异步调用等复杂情况下,归还许可将变得非常复杂。
因为在使用信号量时,如果多次调用release,应用程序实际的并发数量会超过设置的许可值。所以避免重复调用release方法显得非常关键。RocketMQ给出的解决方案如下:
1 | public class SemaphoreReleaseOnlyOnce { |
这套方案的核心思想是对Semaphore进行一次包装,然后将包装对象(SemaphoreReleaseOnlyOnce)传到业务方法中。就像上面这段代码,其中的doSomething方法无论调用release多少次都可以保证底层的Semaphore只会被释放一次。
SemaphoreReleaseOnlyOnce的release方法引入了CAS机制,如果release方法被调用,就使用CAS将released设置为true。下次其他线程再试图归还许可时,由于状态为true,所以不会再次调用Semaphore的release方法,这样就可以有效控制并发数量了。
总结
好了,这节课就讲到这里。
这节课一开始,我们就讲了一个大家在多线程编程中常会遇到的问题:如何复用线程?我们重点介绍了线程池这种复用方法。它的内部的原理是采用 while + 阻塞队列的机制,确保线程的run方法不会结束。在有任务执行时运行任务,无任务运行时则通过阻塞队列阻塞线程。我们还顺便讲了讲怎么通过中断技术优雅地停止线程。
使用线程池时,还有一个常见的问题就是怎么选择阻塞队列,我总结了下面三个小窍门:
- Request-Response等需要用户交互的场景,建议使用有界队列,避免内存溢出;
- 如果一个线程向多个队列写入消息,建议使用“无界队列+size”机制,不阻塞队列;
- 如果一个线程向一个队列写入消息,建议使用有界队列,避免内存溢出。
这节课的后半部分,我们详细介绍了多线程领域Future模式、生产者-消费者模式的工作原理和使用场景。我还提到了高并发架构设计中的底线思维:限流机制。基于信号量来实现限流,在多线程环境中避免信号量的超发可以防止你踩到很多坑。
课后题
在课程的最后,我还是照例给你留两道思考题。
- 你是怎么理解Future模式的?又会怎么实现它呢?
- 场景题:有一家主要生产面包的工厂,但是工厂的仓库容量非常有限。一旦仓库存满面包,就没法生产新的面包了。顾客来购买面包后,仓库容量会得到释放。请你用Java多线程相关的技术实现这个场景。
完成这个场景可以让我们迅速理解多线程编程的要领,所以请你一定要重视第二题。如果你想要分享你的修改或者想听听我的意见,可以提交一个 GitHub的push请求或issues,并把对应地址贴到留言里。我们下节课见!
06 | 锁:如何理解锁的同步阻塞队列与条件队列?
作者: 丁威

你好,我是丁威。
这节课,我们重点介绍并发编程中的基石:锁。
锁的基本存储结构
我们先通过一个简单的场景来感受一下锁的使用场景。一家三口在一起生活,家里只有一个卫生间,大家早上起床之后都要去厕所。这时候,一个人在卫生间,其他人就必须排队等待。

这个场景用IT术语可以表述为下面两点。
- 洗手间作为一个资源在同一时间只能被一个人使用,它具备排他性。
- 一个人用完洗手间(资源)之后会归还锁,然后排队者重新开始竞争洗手间的使用权。
我们可以对这个场景进行建模。
- 资源:更准确地说是公共资源或共享资源需要被不同的操作者使用,但它不能同时被使用。
- 资源使用者:共享资源的使用者。
- 锁:用来保护资源的访问权。锁对象的归属权为共享资源,但当资源使用者向资源申请操作时,可以将锁授予资源使用者。这时候,资源使用者叫做锁的占有者,在此期间它有权操作资源。操作者不再需要操作资源之后,主动将锁归还。
- 排队队列:我们可以更专业地称之为阻塞队列,它可以存储需要访问资源但还没获取锁的资源使用者,其归属权通常为锁对象。
这里我之所以强调归属权,主要是因为它可以帮助我们理解锁的基本结构和资源的关系。
那锁的结构是什么呢?我们通过上节课的课后题来理解这个问题。
上节课的第二道课后题是问你怎么用多线程实现面包厂的生产和销售。我在这里也给你写了一段示例代码:

面包仓库的职能是为面包厂存储面包,它需要提供两个基本的方法:存储面包和获取面包。面包仓库内部使用ArrayList来存储面包,但是因为ArrayList是一个线程不安全的存储容器,它不允许多个使用者同时存储数据,所以我们需要对资源进行保护。体现在代码上,我们可以通过 synchronized(资源对象)来创建一把锁,保护多线程对资源对象的串行访问。
我们结合put方法的流程来看一下锁的基本存储结构。
假设 t1、t2两个生产者(线程)同时调用Bakery的put方法。那么synchronized(breads)在编译的时候,就会在资源breads对象上创建锁相关的结构,即锁对象。
t1,t2在执行synchronized(breads)时,只有一个线程可以获取锁,另外一个线程需要等待,所以这里需要引入一个存储结构(通常为队列)来存储这些排队的线程,我们通常会使用阻塞队列。
首先获取到锁的线程t1在向仓库中存放面包之前需要先进行判断,如果存储空间足够,执行上图中的代码step2。但是如果仓库没有足够的空间存储面包,就要执行代码step3,调用锁对象的wait方法,让获得锁的线程t1阻塞,并且释放锁。
但是,被阻塞的t1和t2还是有所不同。因为t1被阻塞的原因是条件不满足,当面包仓库有额外的存储空间时,t1就会被唤醒。所以我们还要引入一个条件队列,用来存放因条件不满足而被阻塞的线程。
t1线程如果因为条件不满足而存储在条件等待队列,当存在剩余空间后,就能被其他线程唤醒继续执行后续的代码了。在这里是将面包存储到ArrayList,那此时面包工厂中存储了面包,需要通知那些因为仓库中没有面包而阻塞的线程,调用锁的notifyAll方法唤醒在等待的线程。
线程t1因为存储空间不足在step3被阻塞,进入到条件等待队列。等到面包被卖出,仓库有足够的容量之后,t1线程将被唤醒。
这里我想给你提个问题,t1线程可以立马继续执行step3之后的代码step4吗?
答案是不能,它需要先去尝试竞争锁,成功获得锁之后才能开始执行step4,否则就会进入到阻塞队列。
从上面这个过程中,我们可以归纳出锁的基本存储结构,它包括锁的持有者线程、锁的重入次数、阻塞队列和条件等待队列四个部分。
锁的底层实现机制-AQS实现原理剖析
在Java中使用锁通常有两种编程方式。一种是使用JVM虚拟机(Java规范)层面提供的synchronized关键字;另一种是使用JUC类库,也就是大名鼎鼎的AbstractQueuedSynchronizer,简称 AQS。
其中,synchronized是在JVM虚拟机层面实现的,涉及很多底层知识,直接研读源码难度太大。相比较而言,JUC并发编程遵从JSR-166规范,提供了锁的另外一种实现方式,也就是大家所熟知的AQS类库,更加常用和易学。
接下来,我会基于JUC框架,带你从代码层面近距离观摩锁的实现原理,掌握锁的本质。
在JUC框架中,ReentrantLock对标synchronized,它实现了可重入互斥锁的全部语义。语义主要包括两个方面:一个是lock(申请锁)和unlock(释放锁);另一个是条件等待,对标Object的wait/notify。
我们先来看下ReentrantLock和AQS的类图:
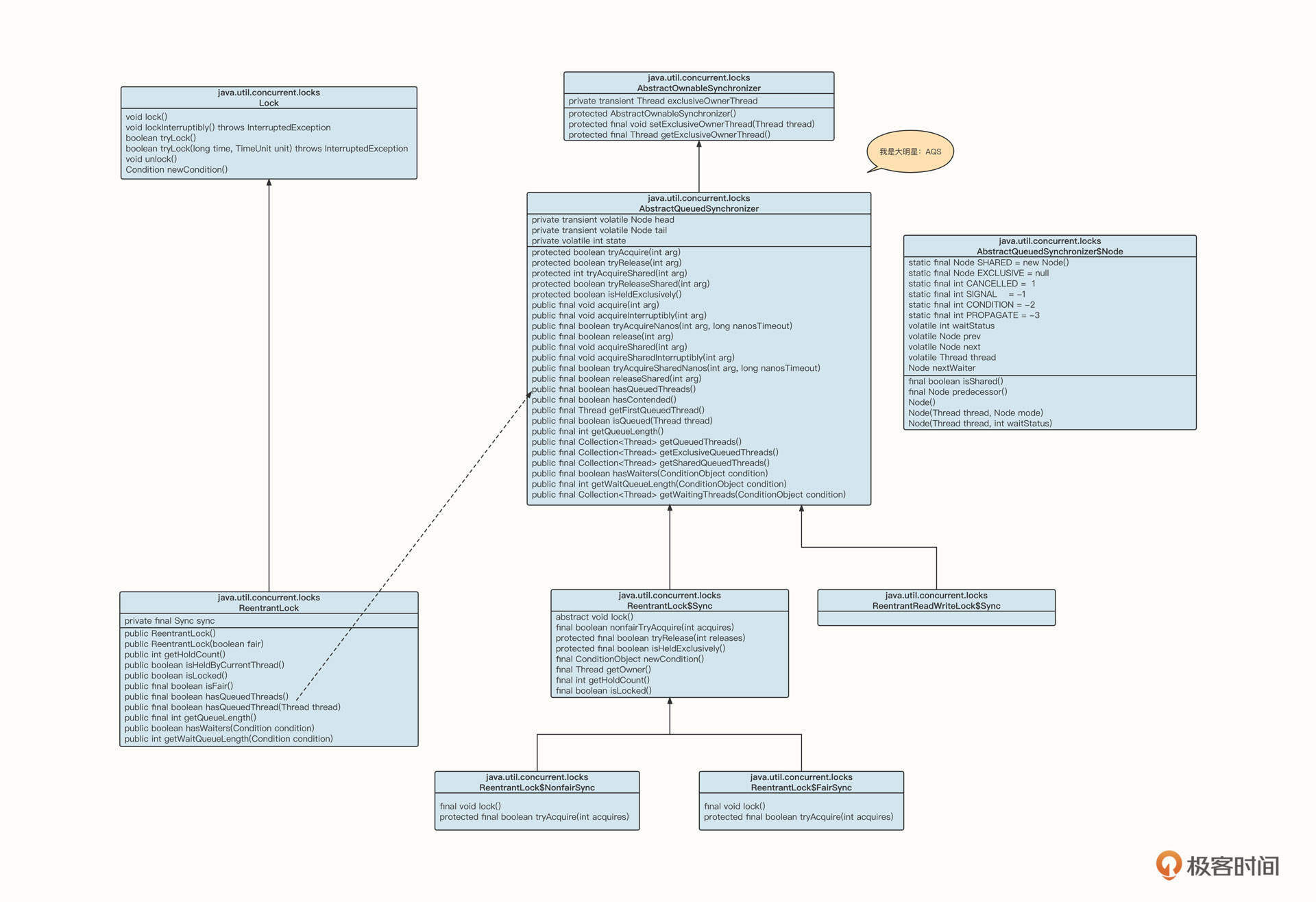
简单介绍一下类图中各个类的含义。
- AbstractQueuedSynchronizer
它是AQS体系的核心基类,使用的是类模版设计模式。这个类实现了锁的基本存储结构,定义了锁的基本行为。AQS的内部数据结构为链表,持有链表的头尾节点,每一个节点用Node表示,可以实现阻塞队列和条件等待队列。其中,Node prev、next用于构建阻塞队列,而Node nextWatier用于构建条件等待队列。
AQS方法的修饰符也很有规律,其中,使用protected修饰的方法为抽象方法,通常需要子类去实现,从而实现不同特性的锁(例如互斥、共享锁、读写锁等);而用public修饰的方法基本可以认为是模板方法,不建议子类直接覆盖。
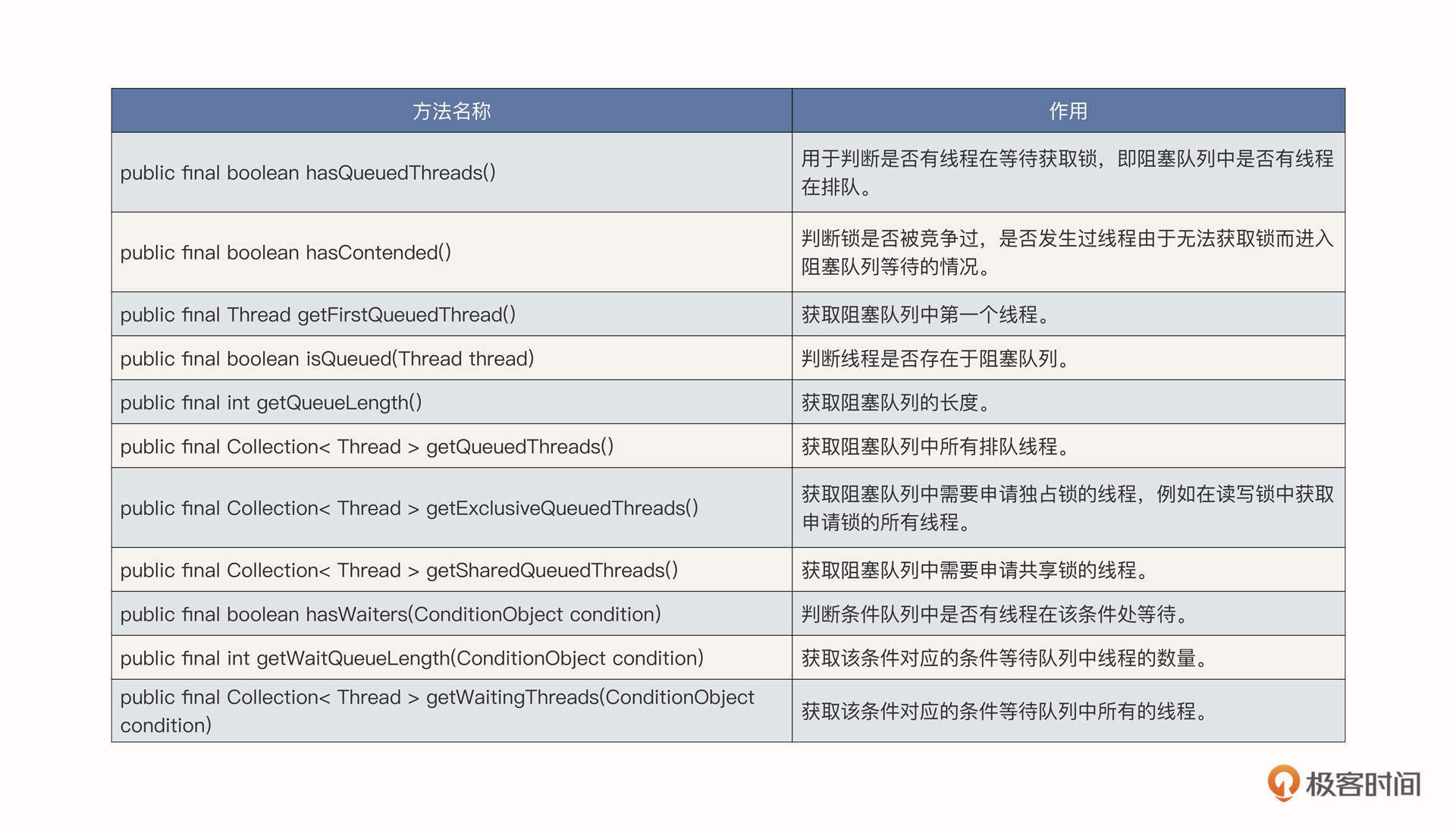
AQS还额外提供了很多有用的方法,我给你列了个表格,方便你在有需要的时候随时查看。
- AbstractOwnableSynchronizer
它是AQS核心基类的父类,用于记录锁当前的持有者线程。
- ReentrantLock
可重入互斥锁的具体实现。由于Java不支持多继承,所以由ReentrantLock继承抽象类Lock,用内部类的方式继承AQS。所以说,ReentrantLock在具体实现锁时基本都是委托内部类Sync,而Sync又继承自AQS。Sync内部有两个子类,分别是FairSync(公平锁)与NonfairSync(非公平锁)。
锁的申请
接下来我们结合ReentrantLock的部分关键源码来看看怎么实现锁的申请与释放。先看锁的申请。
ReentrantLock支持带超时时间的锁申请,具体实现方法是tryLock,时序图如下:
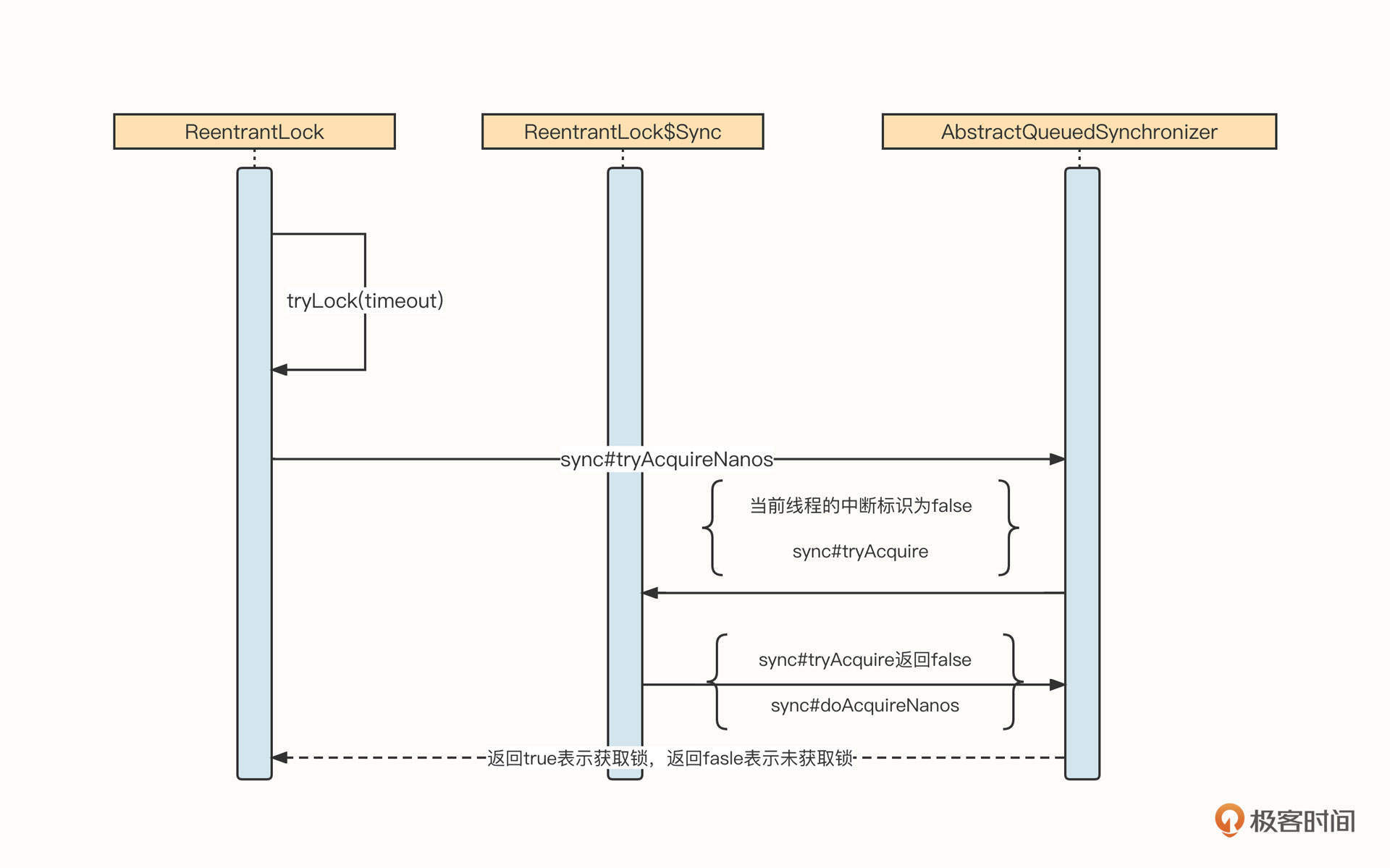
AQS的tryAcquireNanos代码如下图所示,该方法是在AQS中定义的。
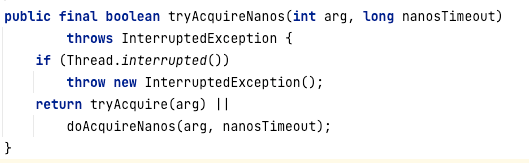
解读一下核心要点。
如果线程的中断位标记为true,表示应用方主动放弃锁的申请,可以直接抛出中断异常,结束锁的申请。
否则,调用Sync的tryAcquire尝试获取锁。如果返回true,表示成功获取锁,可以直接返回;不然就调用doAcquireNanos,进入锁等待队列。
Sync的tryAcquire方法,代码如下:

尝试实现锁有几个要点。
首先我们要确保获取当前申请锁的线程。
我们还要获取锁的当前状态,也就是state值(state字段的含义是当前锁的重入次数,如果state为0,表示当前锁并没有被占用)。这又包括两种情况。
情况一:如果state的值为0,表示当前锁并没有被占用。根据申请锁的公平与否,会有不同的处理逻辑。
- 如果是公平锁,那么我们需要判断阻塞队列中有没有其他线程在排队。如果有,公平锁此时无法竞争锁,返回false,尝试获取锁失败。这个线程最终会调用doAcquireNanos,进入到同步阻塞队列。
- 但是如果是非公平锁,则会首先和阻塞队列中的线程竞争,如果竞争成功,可以直接获取锁,如果竞争失败,则同样进入到阻塞队列。
竞争锁的代码使用的是CAS机制,尝试更新state的值为acquires,如果更新成功,则占有锁。成功占有锁之后,需要设置锁的拥有者为当前线程。
情况二:如果state的值不为0,表示锁已经被占用。我们需要判断当前线程是不是锁的持有者。如果是,则只需要更新state的值(ReentrantLock支持可重入);否则就进入阻塞队列,排队获取锁。
为什么在竞争锁时需要使用CAS呢?什么是CAS呢?
我们知道,申请锁时要先查询state的值,然后更新state的值。但这两步在多线程环境中并不是一个安全的操作。如下图所示:
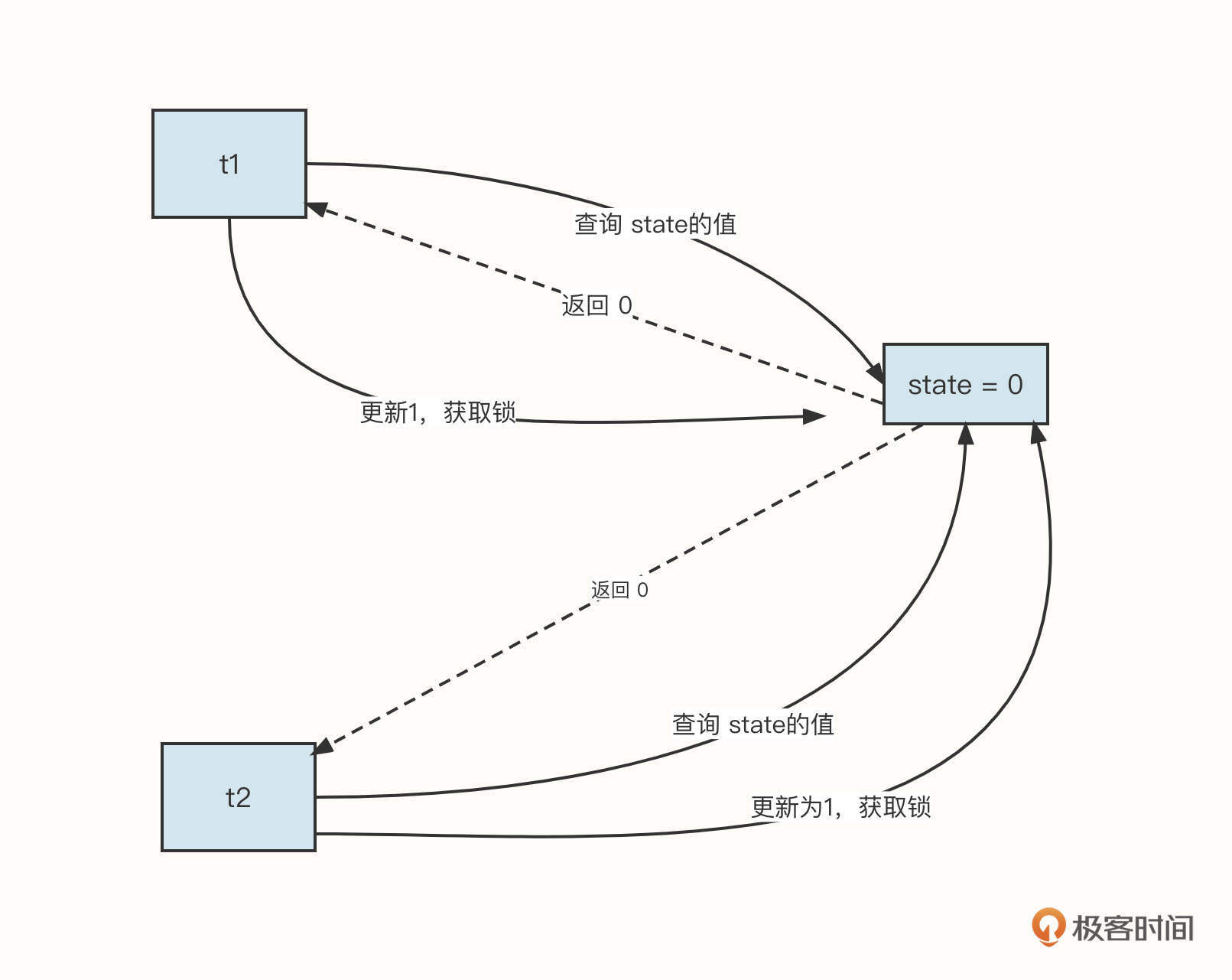
这很容易导致t1,t2都获取到了锁。根本原因是这个步骤包括两个CPU指令,无法做到原子更新。
为了解决这个问题,操作系统提供了一个新的CPU指令(CAS),用它来实现“比较-和-更新”。具体的原理是在更新一个值之前,首先比较这个值是否发生了变化,如果确实发生了变化,那么就会更新失败,否则更新成功。
如果没有成功获取锁,当前申请锁的线程还会继续调用AQS的doAcquireNanos:
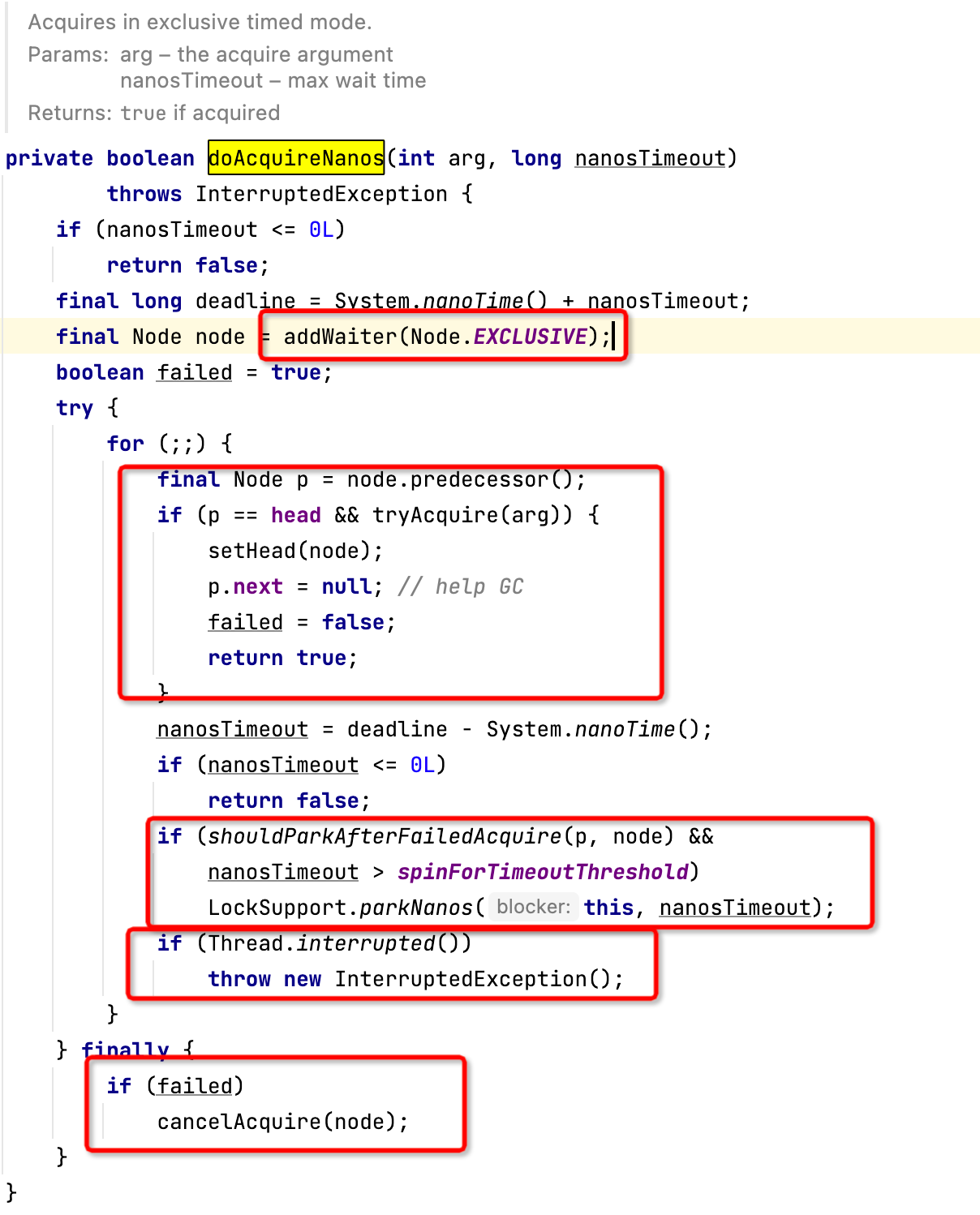
这是AQS机制中非常重要的一个方法,它的实现比较复杂。我们先来看一张流程图:
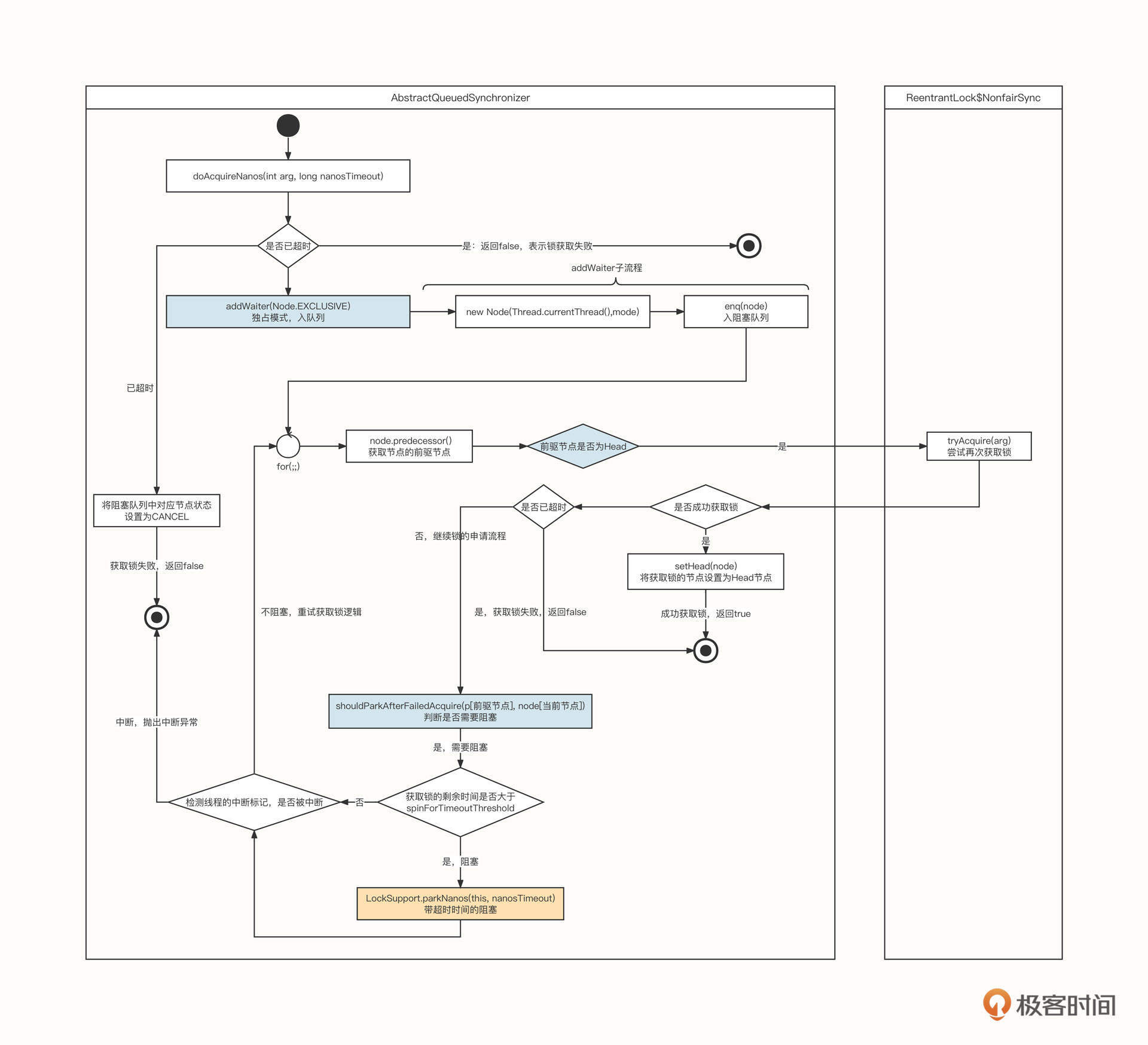
我们可以把这个流程归结为五步。
第一步:判断获取锁是不是已经超时,如果是,返回false(ReentrantLock支持锁获取超时)。
第二步:调用addWaiter方法把当前节点加入到阻塞队列中。
第三步:获取节点的前驱节点。
第四步:如果节点的前驱节点为头节点,再次调用tryAcquire方法尝试获取锁。如果成功获取锁,则将当前节点设置为Head,表示当前它是锁的持有者。
第五步:如果当前节点不是头节点,或者没有成功获取锁,调用shouldParkAfterFailedAcquire判断当前线程是否需要阻塞,如果需要阻塞,则调用LockSupport.parkNanos阻塞线程。
接下来,我们对上面流程中的关键代码进行详细的解读。
先看第二步里addWaiter的具体实现:
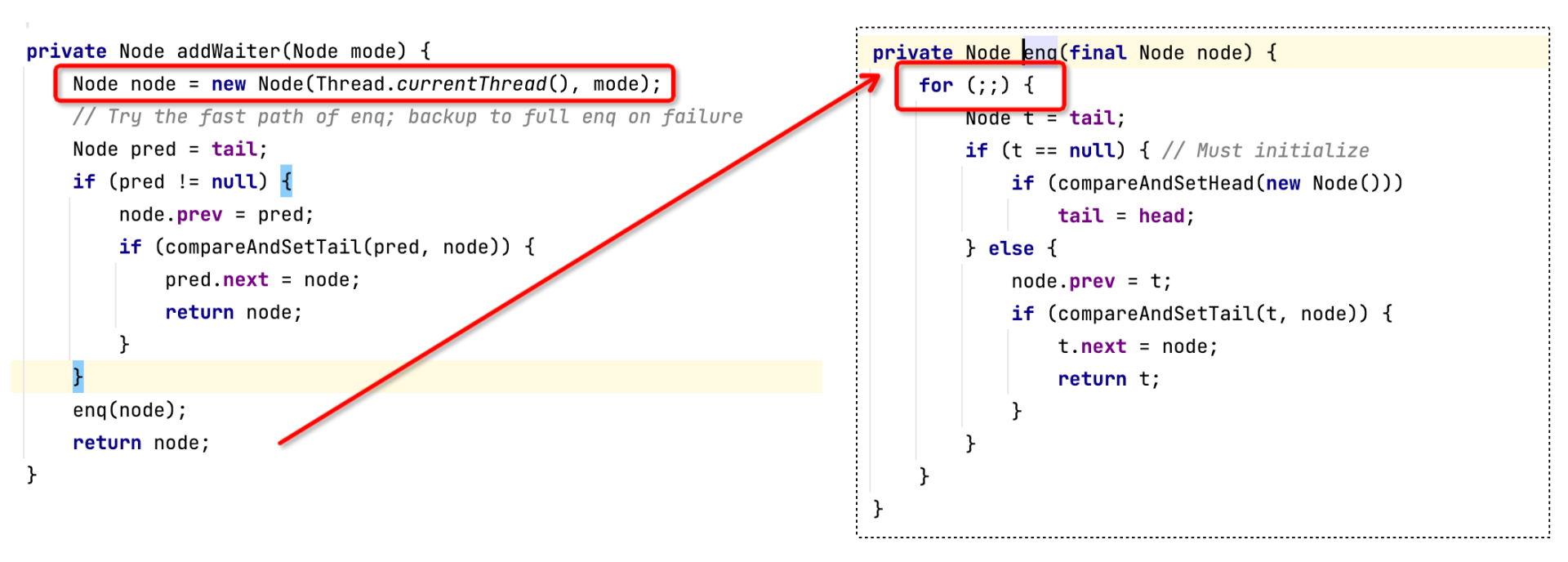
因为AQS内部不管是阻塞队列还是条件等待队列都是基于链表实现的,所以入队列的实现比较容易理解,这里主要关注三点。
- 需要创建一个Node节点,将线程对象存储在Node节点中,方便后续对线程进行阻塞或唤醒。
- 链表在多线程环境中操作并不安全,所以在更新链表相关指针时要引入CAS机制。首先将 if和CAS组合进行一次测试,如果更新成功,直接结束操作;不然就要使用 for和CAS的组合进行多次重试,一直到更新成功为止。这背后的原理是,多线程在更新Head或者Tail时,只有一个能更新成功,如果更新失败,则重新获取Head或者Tail再进行更新,直到节点安全地加入链表为止。
- 在入队的过程中,如果队列为空时,会创建一个空的Node节点,但是不持有任何线程信息。
等到节点成功加入到阻塞队列后,需要判断节点的前驱节点是否为头节点,如果是,表示成功获取锁。成功获得锁的线程对应的节点将成为头节点,设置头节点的代码如下:

头节点持有的线程对象为什么为空呢?
这是因为锁的持有者被记录在了AbstractOwnableSynchronizer的Thread exclusiveOwnerThread属性中。这样做的好处是,我们可以认为头节点是锁的持有者,但头节点却并不维护线程对象。在实现非公平锁时,如果锁被新线程抢占,不需要更新头节点。
相反,如果节点的前驱节点不是头节点,则需要判断申请锁的线程是否需要阻塞。我们可以通过shouldParkAfterFailedAcquire方法来实现它:
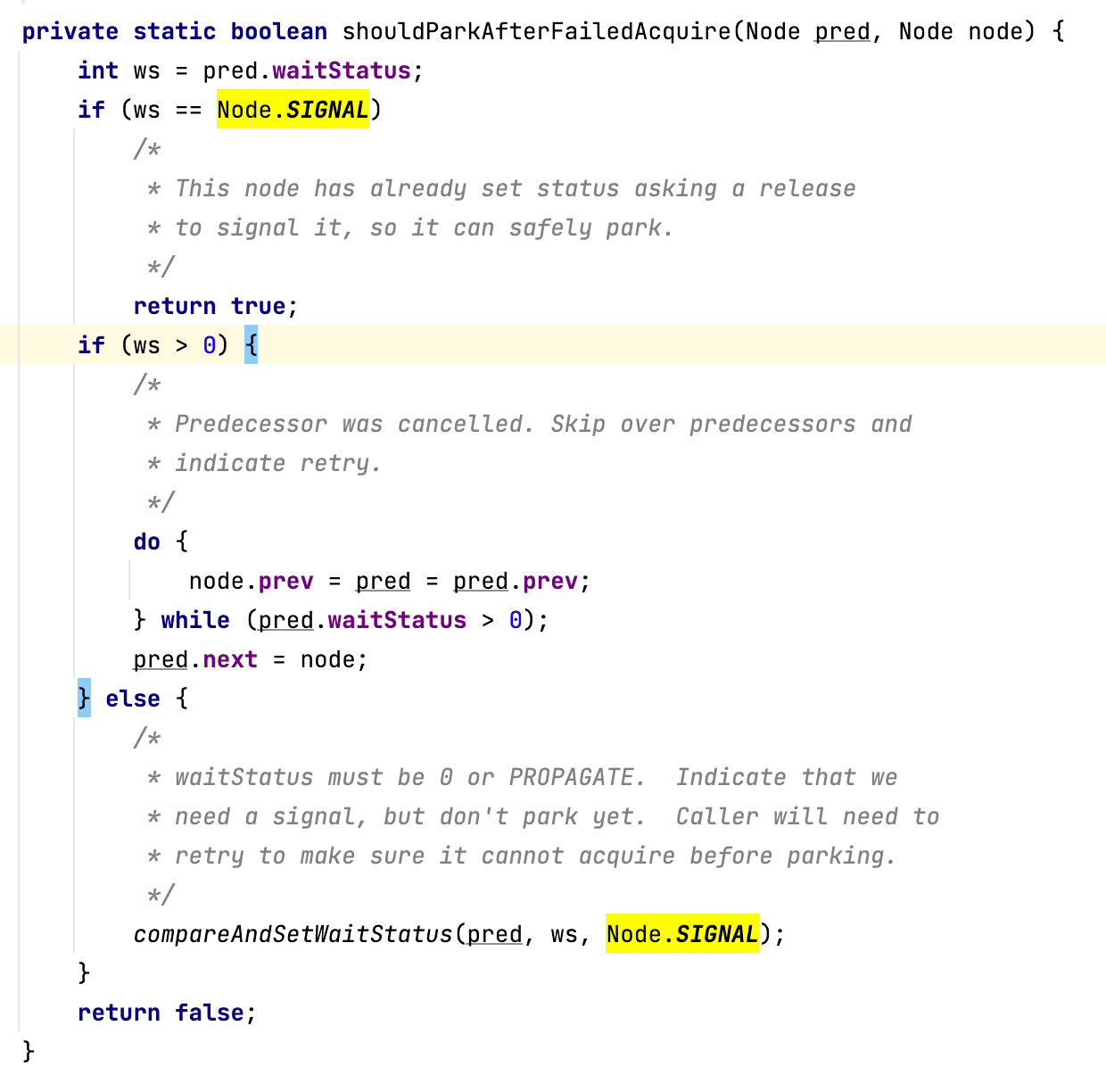
解读一下,如果前驱节点的状态是Node.SIGNAL,则当前线程直接进入到阻塞队列,排队获取锁。
这里再对Node.SIGNAL补充说明一下:Node.SIGNAL的含义是节点需要一个信号来唤醒自己,如果前驱节点的状态为Node.SIGNAL,说明前驱节点在等待被唤醒,那作为前驱节点的后继节点,自然而然也需要等待被唤醒。
如果前驱节点的状态大于0,需要删除当前节点之前连续的节点。因为当前节点的状态只有Node.CANCELLED大于0,所以如果前驱节点的状态大于0说明是已取消的节点,需要被删除。示例图如下:
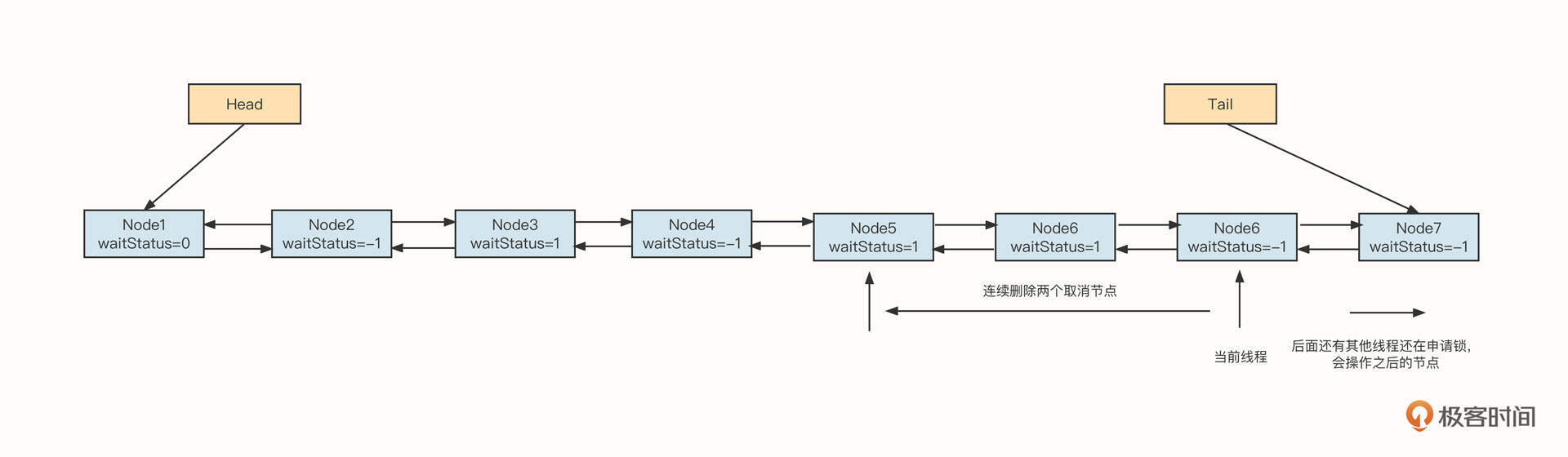
这里以当前节点为基准(状态为-1)向前删除。注意,只删除连续的1,也就是说遇到非取消节点立即停止删除。基于分段思想,我们不会删除前面所有的已取消节点,因为删除节点的方向是从后向前的,而且shouldParkAfterFailedAcquire这个方法会在多个线程获取锁之后被多个线程调用,但后续的节点在执行删除时,遇到当前线程,会被切割成段,段与段之间并不会有多线程执行,从而可以安全地操作各自的段。
如果前驱节点的状态为0或Propagate,需要尝试把前驱节点的状态变更为Node.SIGNAL。也就是说,不阻塞线程,而是再次试图获取锁相关的逻辑。
如果需要阻塞线程,先判断本次获取锁的剩余时间是否大于等于spinForTimeoutThreshold,如果是,则通过自旋方式进行循环,否则将使线程阻塞。其中spinForTimeoutThreshold默认为1s,这样做的目的主要是如果本次锁申请距超时还剩不到1s,就没有必要再阻塞线程了,避免线程切换带来的额外开销。
如果需要阻塞线程,我们可以调用LockSupport.parkNanos方法使线程阻塞,这个方法同样支持设置超时时间。
锁的释放
申请完锁之后,我们还会面临锁的释放。我们可以通过ReentrantLock的unlock方法释放锁,并最终调用AQS的模版方法:release方法,代码如图所示:
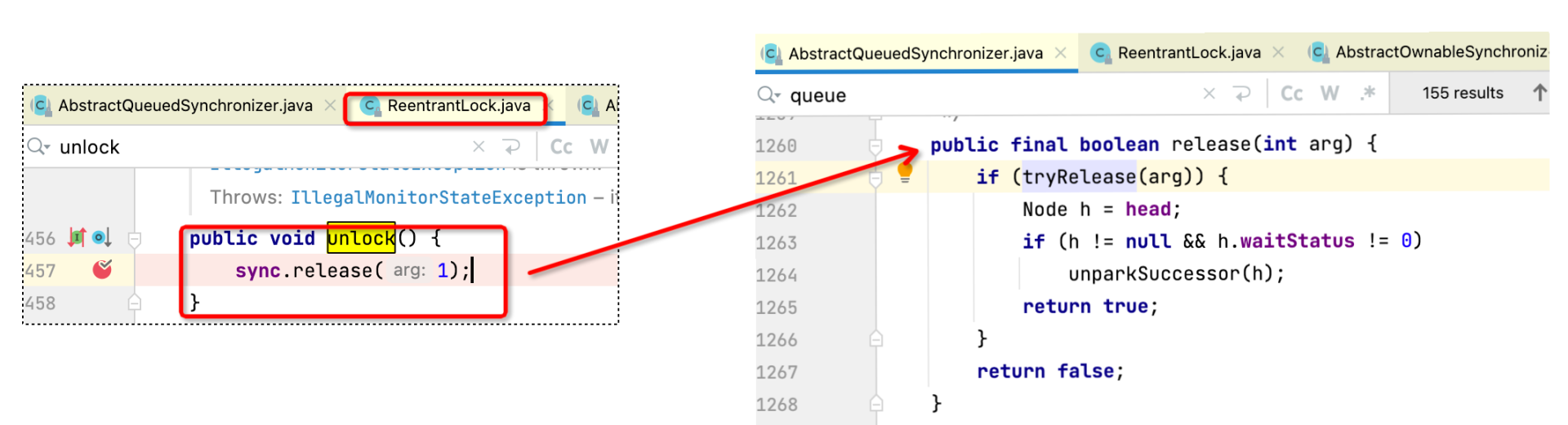
在详细地介绍具体的方法之前,我们先来看一张整体的时序图,理解一下释放锁的实现机制。
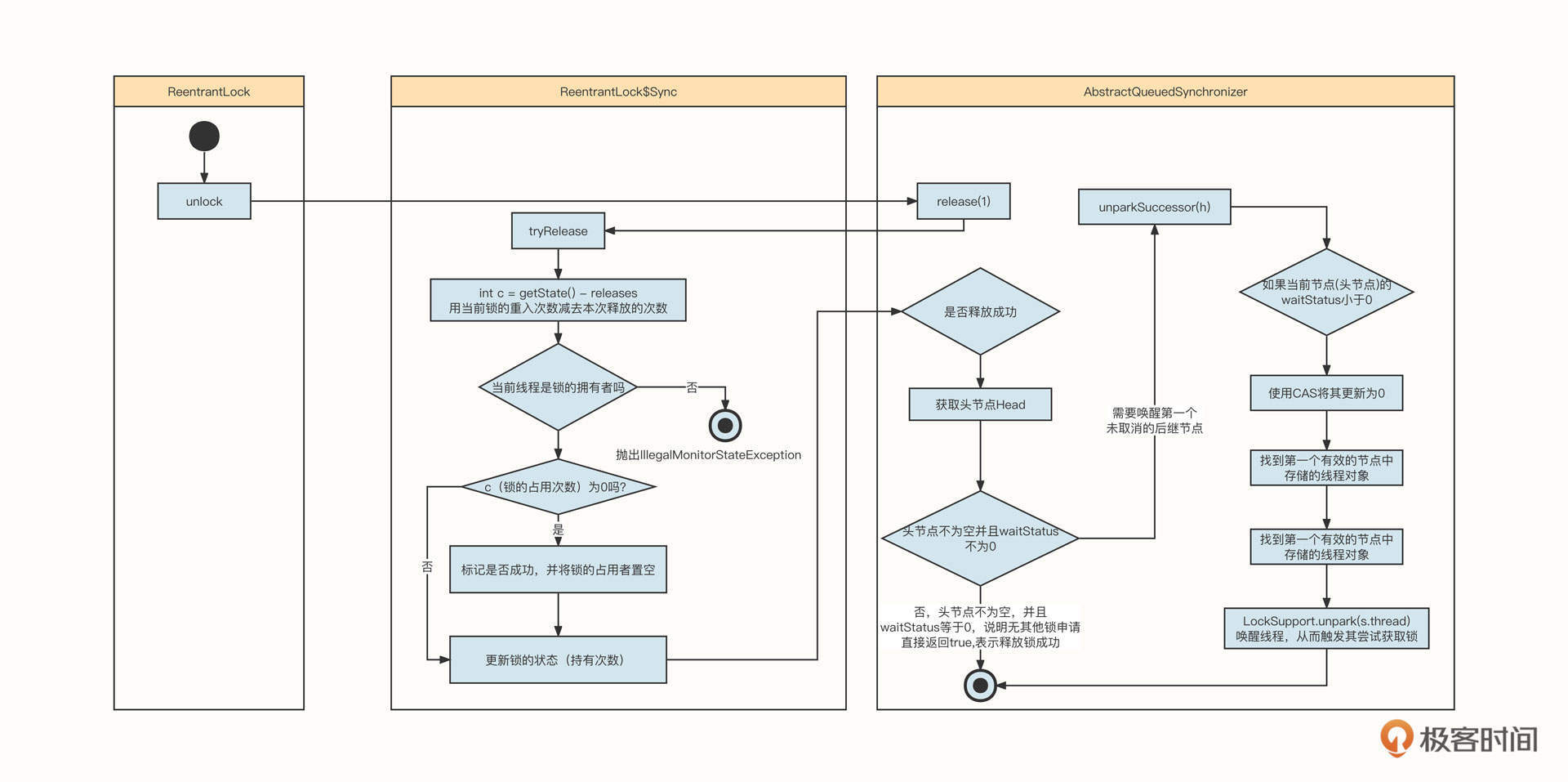
锁的释放主要包含如下几个步骤:
第一步:释放锁,必须先判断当前线程是否是锁的持有者,如果不是,抛出IllegalMonitorStateException异常。
第二步:判断锁的剩余占有次数,如果为0,表示锁已释放,需要唤醒阻塞队列中的其他排队线程。
我们看一下释放锁的关键代码。具体定义在ReentrantLock$Sync的tryRelease中:
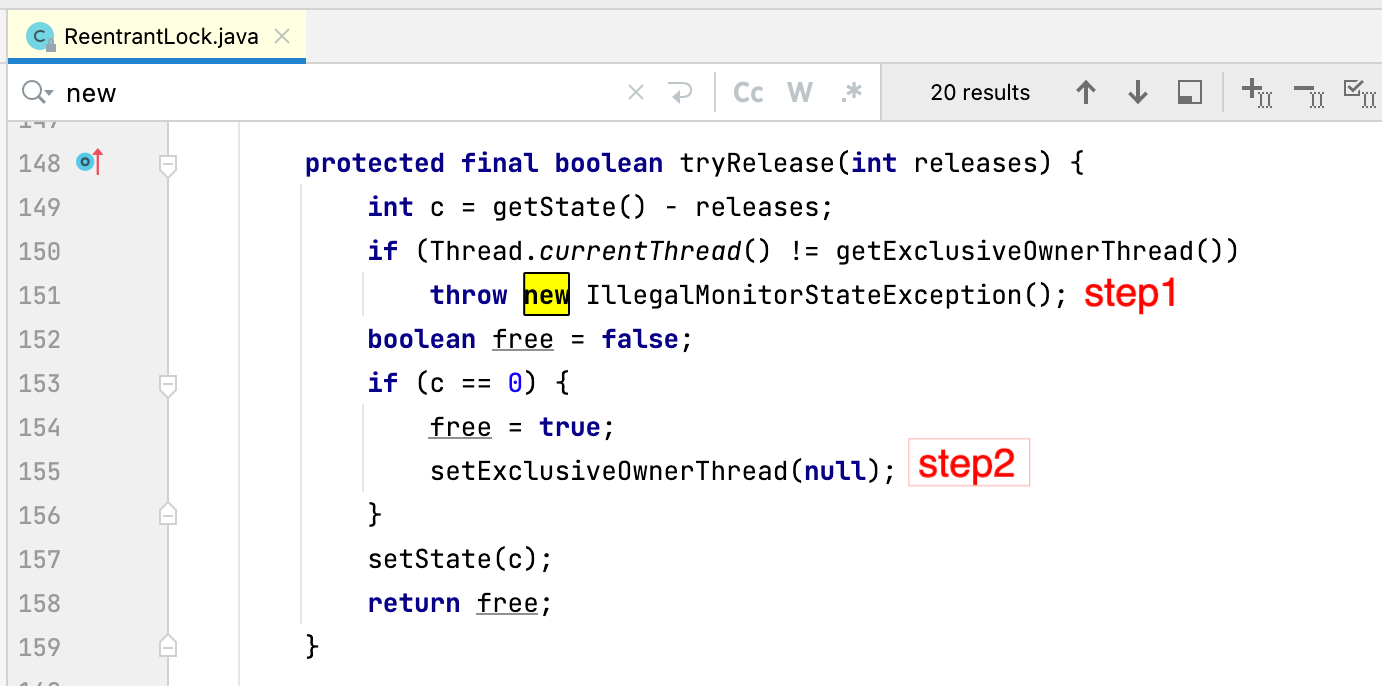
这段代码有两个要点。
- 如果当前锁的占有者不是申请释放锁的线程,那就不能释放锁,只有持有者线程才能释放锁。这个时候需要抛出监视器错误。
- 如果一个锁被同一个线程重入n次,那对应也要释放n次。当持有次数为0时,表示可以释放锁。
尝试释放锁后,返回“成功”,接下来要做的是唤醒阻塞队列中的下一个线程。当然,如果你使用的是非公平锁,新来的线程在这个时候是可以直接获取锁的,这样唤醒的线程如果没能获取锁,就又会进入到阻塞队列中。
从阻塞队列中查找下一个待唤醒的线程需要使用AQS的unparkSuccessor方法,代码如下图所示:

这个过程主要包括四个要点,分别对应上图的step1、step2、step3和step4。
step1:因为这个方法的参数是头节点,头节点是当前锁的持有者,所以在释放锁时,我们要找头节点的下一个未取消的节点。
step2:确认头节点的状态。如果头节点的状态不为0,则更新为0。
step3:从链表的尾部开始寻找,找到头节点后面的第一个非取消节点。这里说明一下,因为我们在维护节点的前驱节点时使用了CAS,通过前驱节点遍历是可靠的,不会遗漏节点。
step4:找到对应的节点,调用LockSupport.unpark方法唤醒线程。线程被唤醒后会继续去竞争锁。这里唤醒的是申请锁时用LockSupport.park阻塞的线程,因为这样可以让锁的申请和释放形成闭环通道。
锁的条件等待队列
理解了锁的申请和释放,接下来我们再来看看ReentrantLock是怎么实现Object.wait和Object.notify语义的,这是线程之间协作的基石。
线程调用锁对象的wait方法时会进入到条件等待队列,而线程调用锁对象的notify方法,会唤醒条件队列中的一个线程,具有下面三个特征。
- Object 的 wait与notify必须在临界区中调用。
- Object 的wait和notify的使用场景为条件等待。例如,一个线程获取锁后,需要等待某一个条件满足后才能继续执行。这时,为了节省CPU资源,线程可以调用锁的wait方法使自己阻塞,等待条件满足后被别的线程唤醒。
- Object的wait方法会释放当前锁。
在AQS中,实现Object的notify和wait功能的主要类为Condition,类图如下:
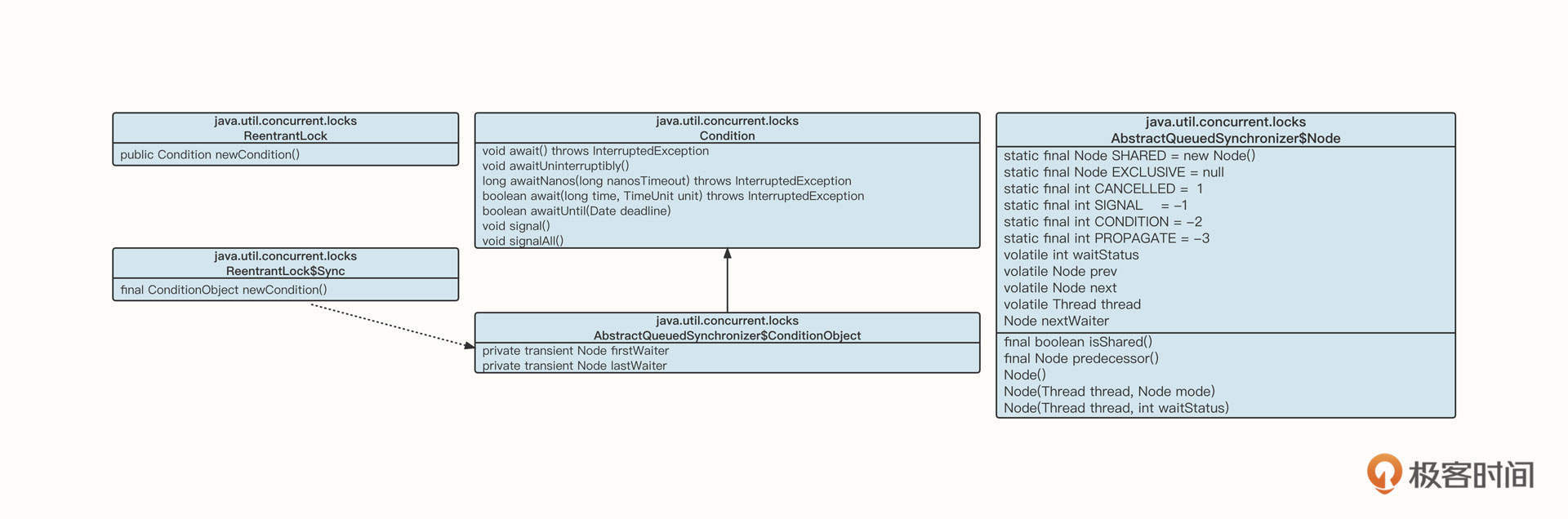
Condition的接口对标Object的wait与notify方法,底层的存储结构为一个链表(条件阻塞队列)。链表中的节点为Node,条件阻塞队列为单链表,链表通过Node nextWaiter指针维护链表。
因为前面在介绍lock语义的时候我们用的是带超时时间的方法,所以为了覆盖更多的AQS方法,这里我们就变一变,用不带超时时间的方法来解读await语言。不过这两者在本质上并没有差别。
为了帮助你更快掌控await的整体实现思路,可以先看一下时序图:
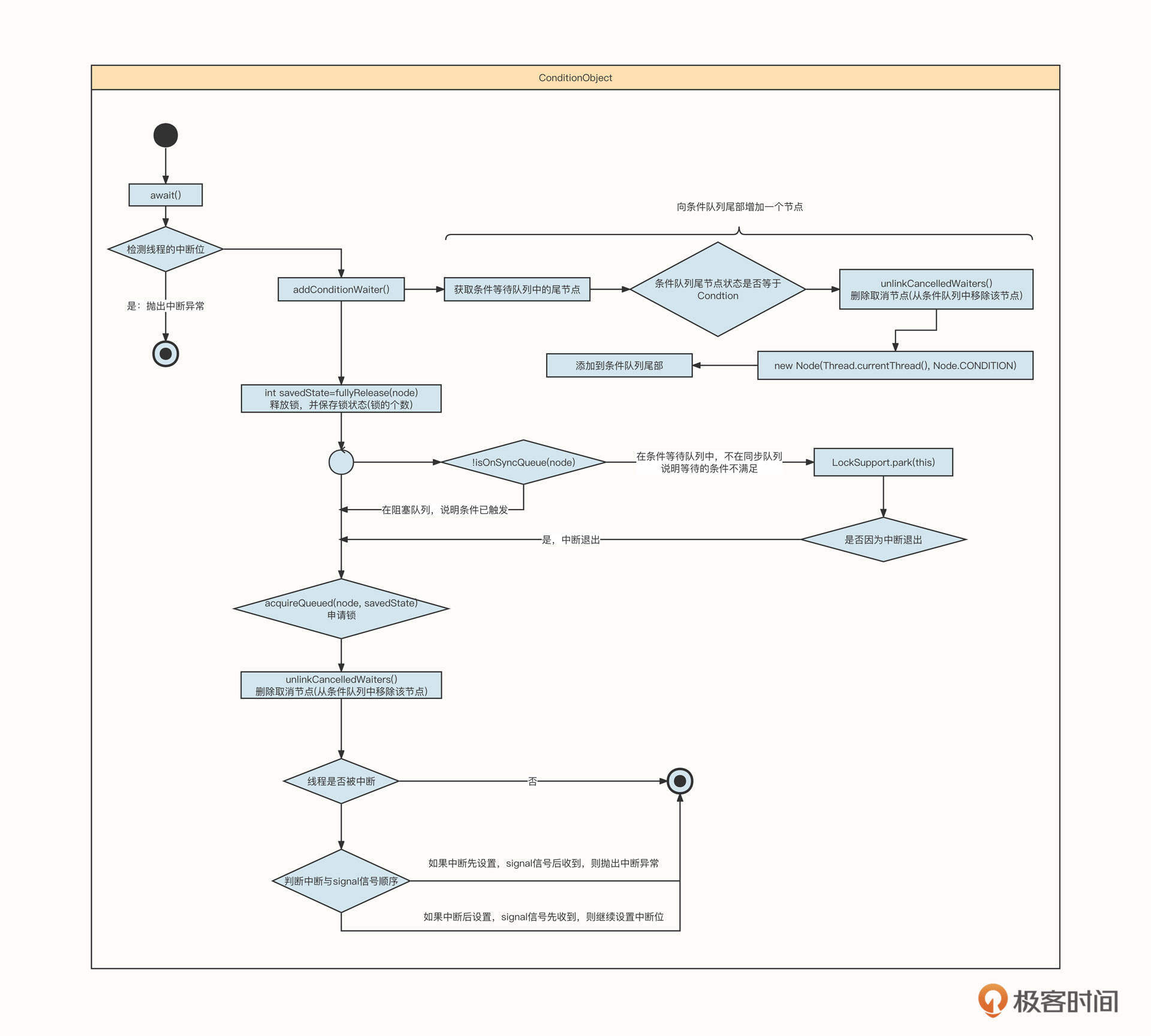
Condition的wait()方法对标Object.wait(),我们来看一下它的具体实现逻辑:

我们结合Object.wait的语义来体会一下await方法中最关键的六个步骤。
step1:如果当前线程被中断,要直接抛出中断异常。
step2:将节点加入条件等待队列中。
step3:释放锁,并保存释放之前锁的状态,等到条件满足线程被唤醒后,需要重新申请指定数量的锁。
step4:如果节点存在于条件队列而不在阻塞队列中,说明未收到signal信号,线程会被阻塞;如果线程被中断,就结束条件队列的等待。
step5:再次尝试申请锁,并检查唤醒的原因,看看是因为收到signal信号而被唤醒,还是因为收到了中断信号。
step6:如果先收到signal信号,再收到中断信号,那就要重新设置线程中断位,等待下一次中断检查点;如果是先收到中断信号,后收到signal信号,就直接抛出中断异常;如果正常收到signal信号,await方法结束阻塞,则继续执行后续逻辑。
其中,第二步中的加入条件队列,具体的代码实现是将节点接入到链表的尾部,如果有取消的节点就把它删除。这里线程是安全的,因为执行await方法的前提条件是要获取锁。
第四步是用await方法阻塞和唤醒线程的关键。核心代码如下图所示:
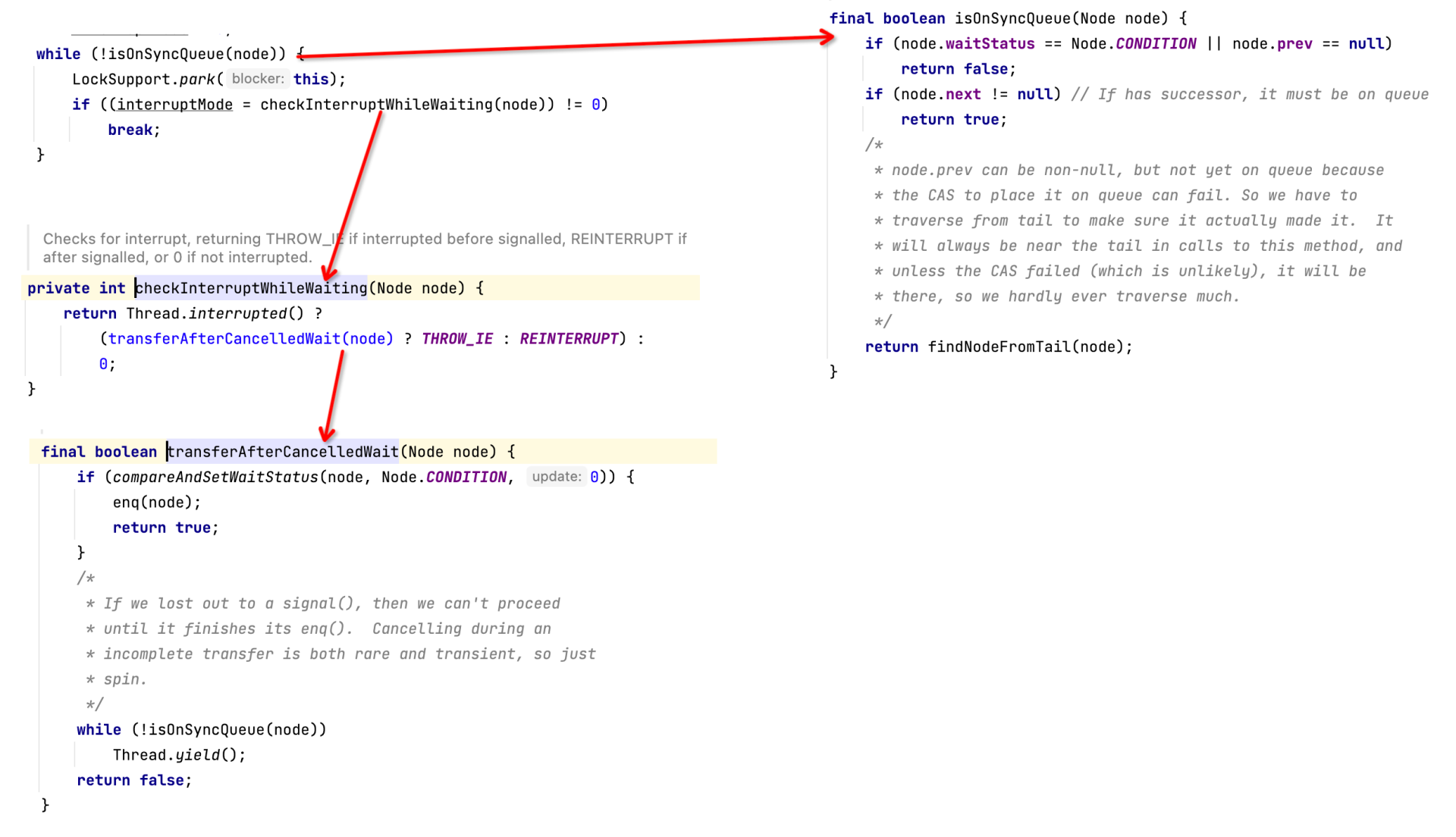
我们来看一下怎么判断线程是否在同步队列中(用isOnSyncQueue方法实现)。
- 如果节点的状态为Node.CONDITION,或者node.prev为空,表示线程在等待条件被触发。为什么节点的前驱节点不为空就可以认为线程在同步阻塞队列中呢?这是因为进入同步队列时是用CAS机制来更新前驱节点的。
- 如果Node的next指针不为空,表示线程在同步阻塞队列中,返回true。
- 如果不满足上述条件,则从尾部节点再查找一遍,如果能找到,返回true,否则返回false。
因为节点如果在条件等待队列中,说明条件不满足,线程需要阻塞并等待条件触发。线程可以通过下面几种方式被唤醒:
- 由于正常收到signal信号被唤醒;
- 先收到signal信号,然后收到中断信号;
- 先收到中断信号,再收到signal信号。
那怎么判断唤醒方式呢?
我们可以通过checkInterruptWhileWaiting来实现它。也就是检测线程的中断标志位,如果线程并没有设置中断位,则返回0。如果检测到了中断位,则用transferAfterCancelledWait方法来判断中断信号和signal的先后顺序。
transferAfterCancelledWait的核心实现逻辑是,如果成功将节点的状态从Node.CONDITION更新为0,就表示先收到了中断标记,否则就是先收到了signal信号。因为如果是先收到signal信号,节点的状态应该是NODE.SIGNAL,而且节点会进入同步阻塞队列。这样做可以有效避免signal信号丢失。
线程被唤醒后需要重新申请锁,调用acquireQueued方法来实现,这一步和前面我们提到的申请流程类似,这里就不再重复了。
当条件满足后,线程被唤醒,这时候我们就要用到Condition的signal()方法了。signal方法的时序图如下:
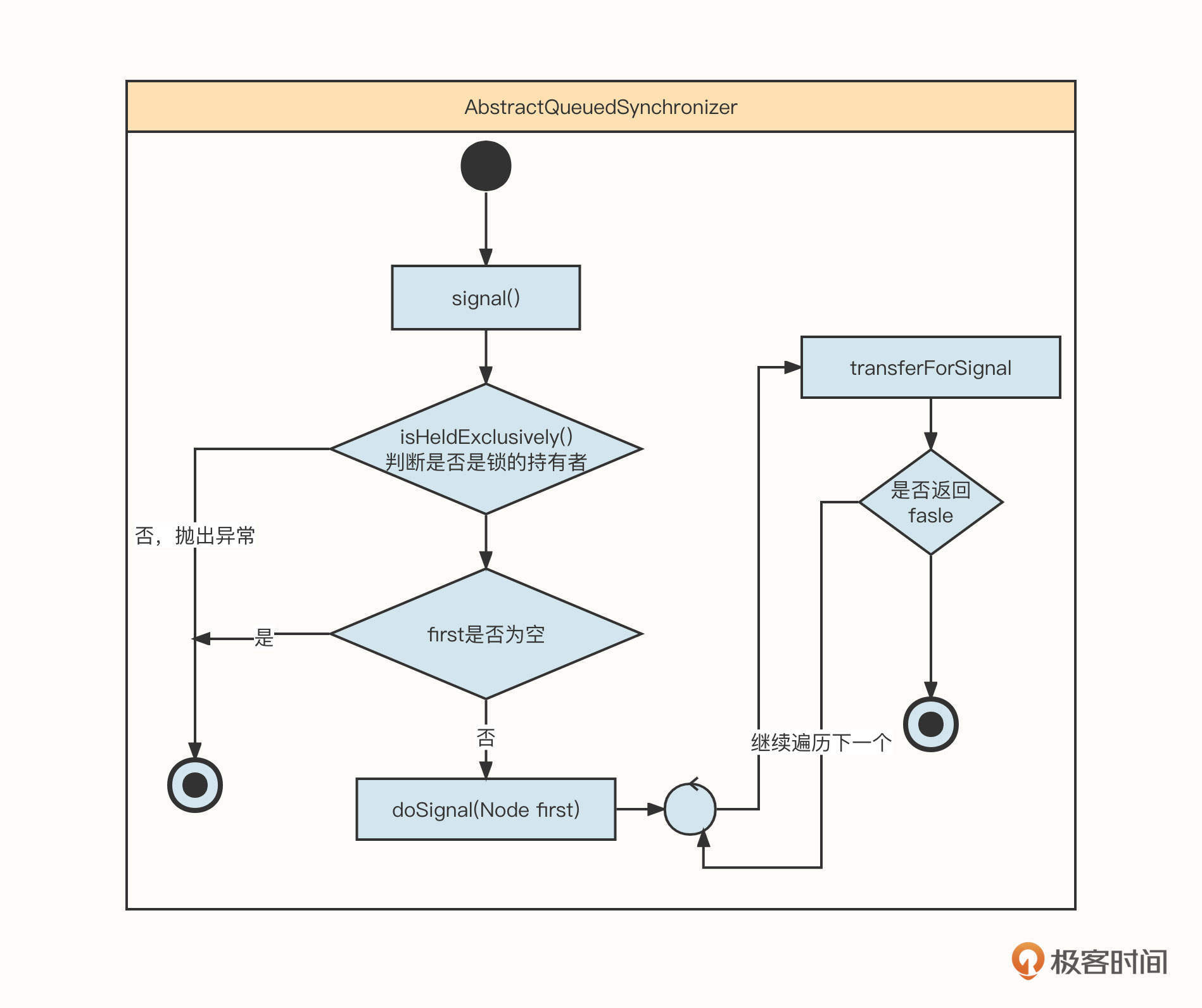
这部分就是从条件队列中找到第一个没有取消的节点,然后唤醒它。实现transferForSignal方法的具体代码如下:
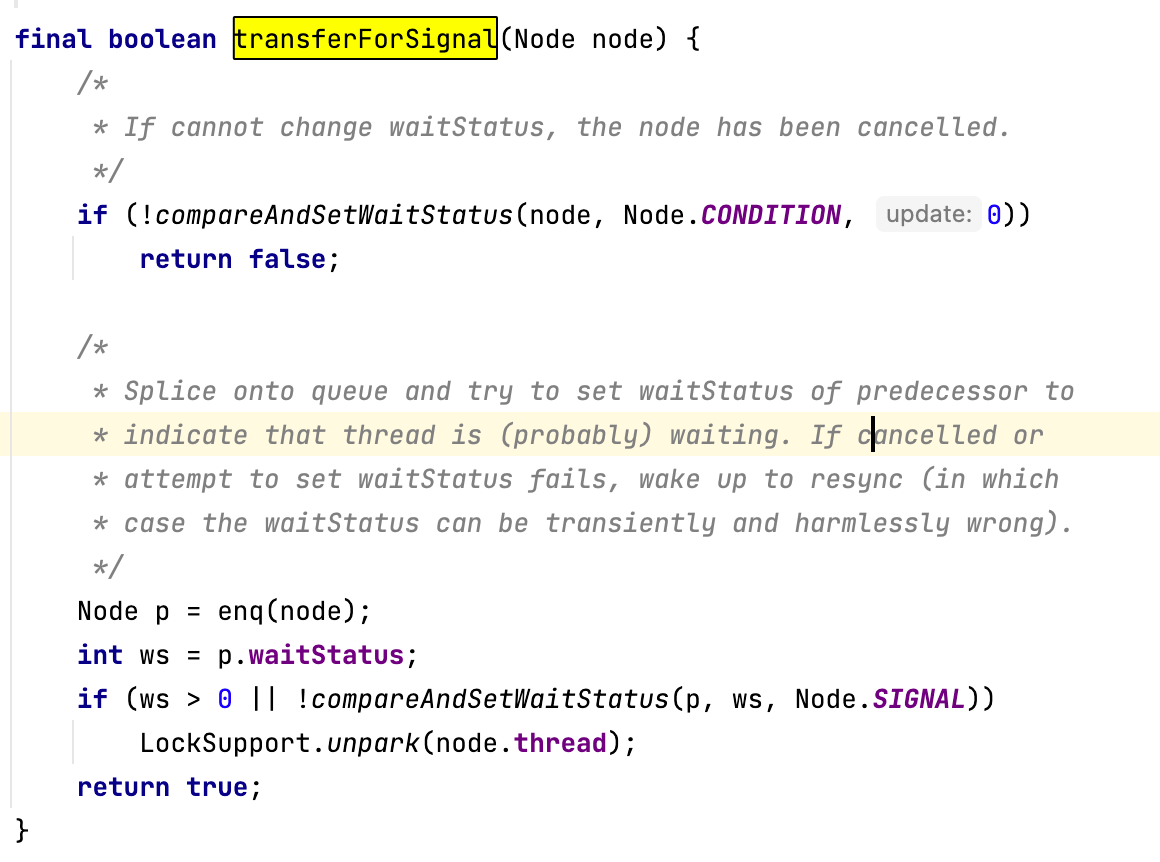
这个方法有三个要点。
第一,要使用CAS尝试将节点状态从CONDITION转化为0。如果更新失败,说明节点已取消,需要返回false,继续通知下一个等待线程。
第二,将线程从条件阻塞队列放入到同步阻塞队列,这一步非常关键,可以防止signal信号丢失。
第三,如果线程加入同步队列后,其前置节点的状态为已取消,或者将其设置为signal失败,则直接唤醒线程。
signal方法内部的实现机制就是确保线程要么在同步队列中,要么在条件等待队列中。这样可以有效防止通知信号丢失,避免线程一直被阻塞。
到这里,Condition的await和signal方法就都介绍完了。
总结
这节课,我们首先通过一个简单的生活场景,并结合生产者-消费者模型引出了锁的基本结构,它包括:锁要保护的资源、锁的拥有者、同步阻塞队列和条件等待队列。
紧接着,我们以源码分析为主要手段,辅助流程图、时序图,一步一步地实现了锁的申请和释放。
同步阻塞队列存放的都是竞争锁失败的线程,主要表征的是线程之间的竞争、互斥,而条件等待队列中存储的是因为某一个条件不满足而需要阻塞的线程,通常需要被其他线程主动唤醒,主要表征的是线程协作。
我们可以使用LockSupport.parkNanos来阻塞线程,并通过LockSupport.unpark方法来唤醒线程。
如果你对中间件感兴趣,对锁的语义的理解必不可少。它虽然有一定难度,但是只要攻下了源码,读懂AQS,对锁的理解与认知能力会有一个质的提升,对多线程协作开发大有裨益。
JUC的体系非常庞大,这节课不能全面覆盖,但是只要掌握了AQS,后面再去学习CountDownLatch、信号量、CAS等知识会变得非常容易。如果你有兴趣,也可以读一读我写过的和锁相关的文章:《锁的优化思路》和《disruptor无锁化设计实践》,应该可以给你更多的启发。
课后题
最后,还是给你留一道课后题。
请你尝试写一篇文章,分析JUC读写锁的源码,重点剖析读锁的申请与释放还有写锁的申请与释放。我也给你提供一篇文章供你参考:《Java并发锁ReentrantReadWriteLock读写锁源码分析》。
关于这节课,如果你还有不理解的问题,也欢迎你在留言区留言。我们下节课再见!
07 | NIO:手撸一个简易的主从多Reactor线程模型
作者: 丁威

你好,我是丁威。
中间件是互联网发展的产物,而互联网有一个非常显著的特点:集群部署、分布式部署。当越来越多的服务节点分布在不同的机器上,高效地进行网络传输就变得更加迫切了。在这之后,一大批网络编程类库如雨后春笋般出现,经过不断的实践表明,Netty框架几乎成为了网络编程领域的不二之选。
接下来的两节课,我们会通过对NIO与Netty的详细解读,让你对网络编程有一个更直观的认识。
NIO和BIO模型的工作机制
NIO是什么呢?简单来说,NIO就是一种新型IO编程模式,它的特点是同步、非阻塞。
很多资料将NIO中的“N”翻译为New,即新型IO模型,既然有新型的IO模式,那当然也存在中老型的IO模型,这就是BIO,同步阻塞IO模型。
定义往往是枯燥的,我们结合实际场景看一下BIO和NIO两种IO通讯模式的工作机制,更直观地感受一下它们的差异。
MySQL的客户端(mysql-connector-java)采用的就是BIO模式,它的工作机制如下图所示:
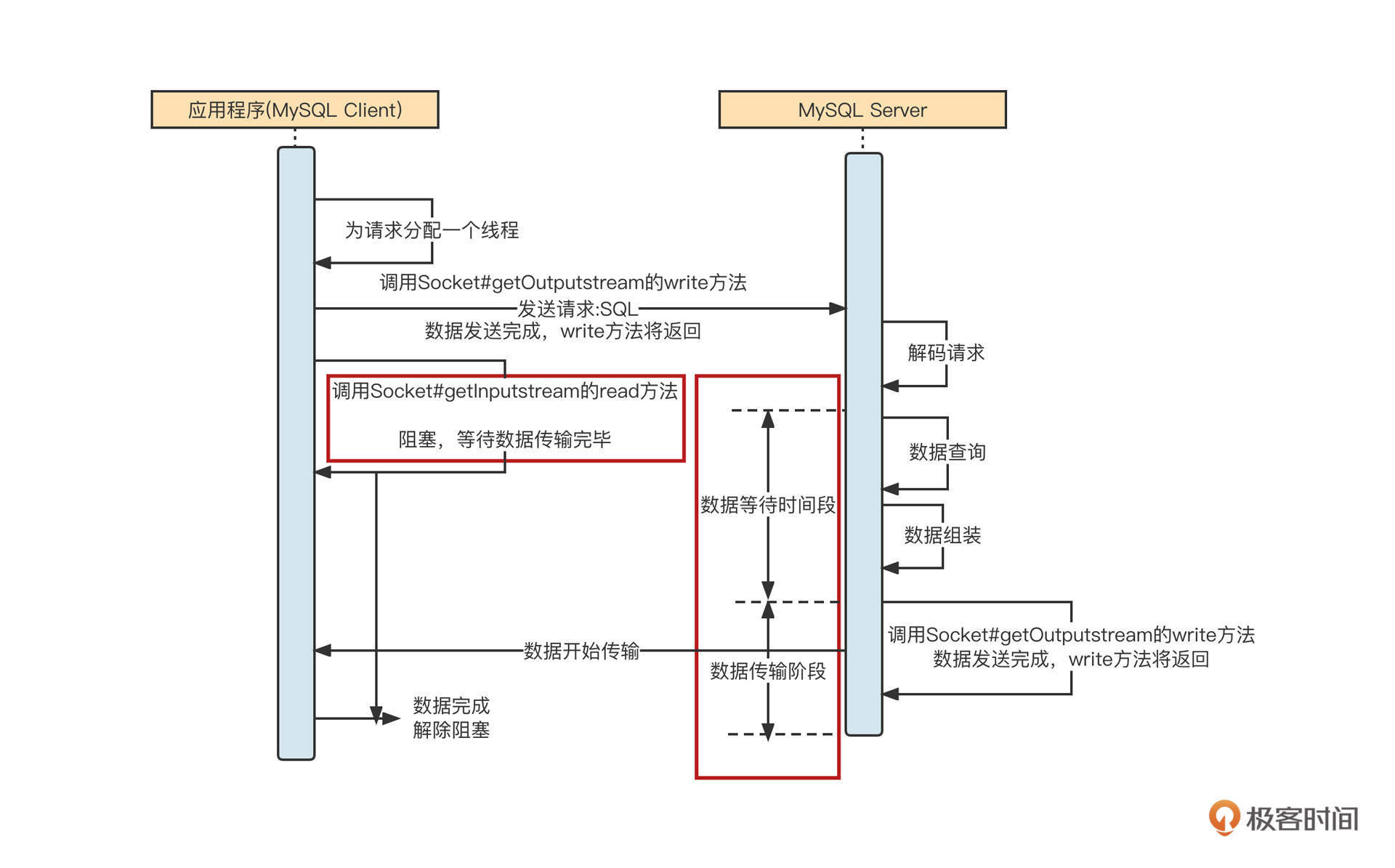
我们模拟场景,向MySQL服务端查询表中的数据,这时会经过四个步骤。
第一步,应用程序拼接SQL,然后mysql-connector-java会将SQL语句按照MySQL通讯协议编码成二进制,通过网络API将数据写入到网络中进行传输。底层最终是使用Socket的OutputStream的write与flush这两个方法实现的。
第二步,调用完write方法后,再调用Socket的InputStream的read方法,读取服务端返回数据,此时会阻塞等待。
第三步,服务端在收到请求后会解析请求,从请求中提取出对应的SQL语句,然后按照SQL抽取数据。服务端在处理这些业务逻辑时,客户端阻塞,不能做其他事情,我把这个阶段称之为等待数据阶段。
第四步,服务端执行完指定逻辑,抽取到合适的数据后,会调用Socket的OutputStream的write将响应结果通过网络传递到客户端。此时,客户端用read方法从网卡中把数据读取到应用程序的内存中,此阶段我称之为数据传输阶段。
BIO的IO模型在等待数据阶段、数据传输阶段都会阻塞。其实,“IO模型”的名称基本就是这两个阶段的特质决定的。
在等待数据阶段,如果发起网络调用后,在服务端数据没有准备好的情况下客户端会阻塞,我们称为阻塞IO;如果数据没有准备好,但网络调用会立即返回,我们称之为非阻塞IO。
在数据传输阶段,如果发起网络调用的线程还可以做其他事情,我们称之为异步,否则称之为同步。
这样看来,BIO的完整名称叫做“同步阻塞IO”也就不足为奇了。
从JDK1.4开始,Java又引入了另外一种IO模型:NIO。
虽然MySQL客户端主要使用的是BIO模型,但是我们可以演示一下MySQL Client采用NIO与MySQL服务端通信的样子:
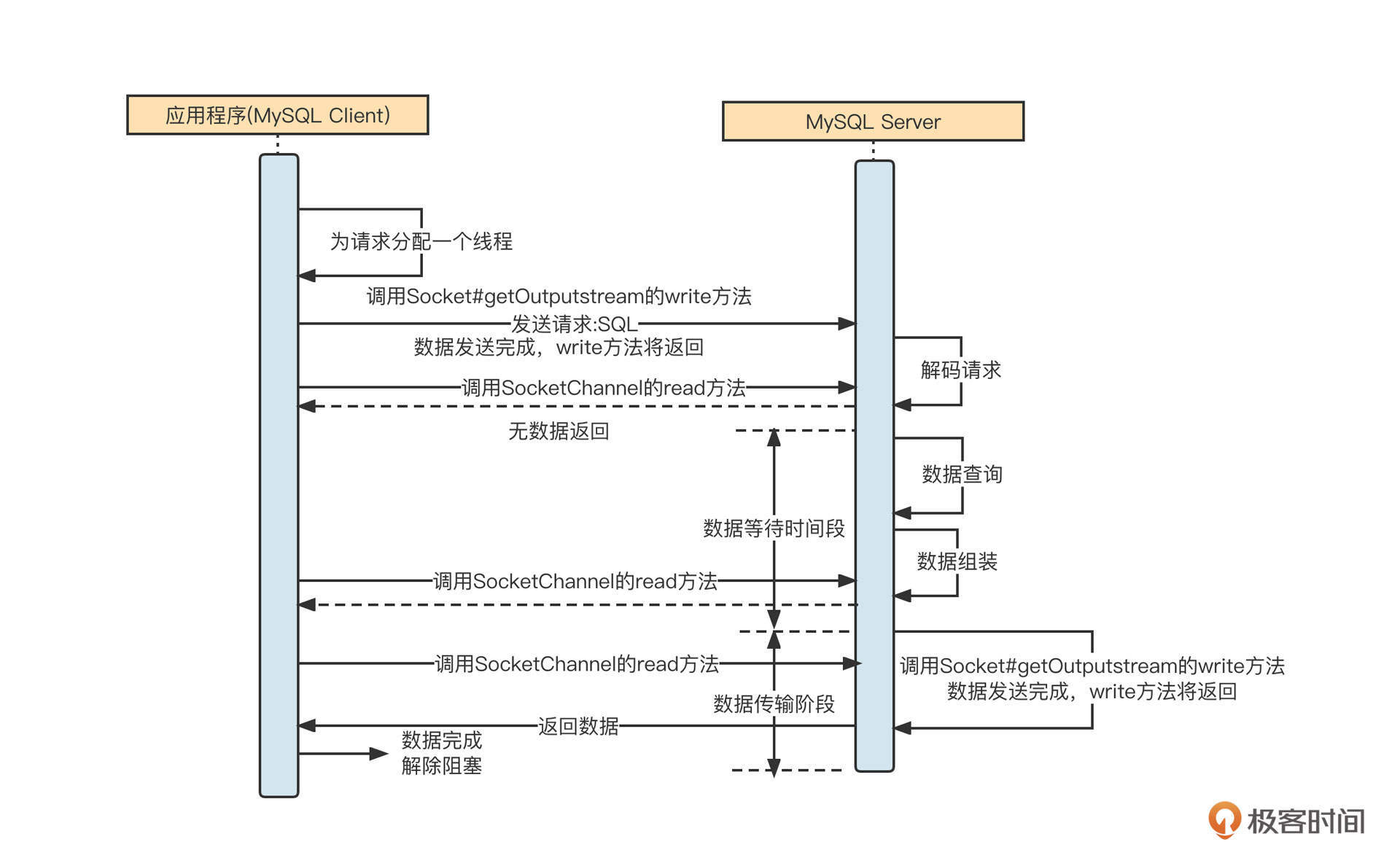
NIO与BIO的不同点在于,在调用read方法时,如果服务端没有返回数据,该方法不会阻塞当前调用线程,read方法的返回值会为本次网络调用实际读取到的字节数量。也就是说,客户端调用一次read方法,如果本次没有读取到数据,线程可以继续处理其他事情,然后在需要数据的时候再次调用,但是在数据返回的过程中同样会阻塞线程。这也是NIO全名的由来:同步非阻塞IO。
NIO提供了在数据等待阶段的灵活性,但如果需要客户端反复调用读相关的API进行测试,编程体验也极不友好,为了改进NIO网络模型的缺陷,又引入了“事件就绪选择机制”。
事件就绪选择机制指的是,应用程序只需要在通道(网络连接)上注册感兴趣的事件(如网络读事件),客户端向服务端发送请求后,无须立即调用read方法去尝试读取响应结果,而是等服务端将准备好的数据通过网络传输到客户端的网卡。这时,操作系统会通知客户端“数据已到达”,此时客户端再调用读取API,从中读取响应结果。其实我们现在说NIO,说的就是“NIO + 事件就绪选择”的合体。
NIO和BIO模型的使用场景
那BIO与NIO相比,有什么优劣势呢?它们对应的使用场景是什么?为了直观地展示两种编程模型的优缺点,我们用网络游戏这个场景来举例。
一个简易的网络游戏分为服务端与客户端(玩家)两个端口,我们一起来思考一下,如果游戏服务端分别使用BIO技术和NIO技术进行架构设计,结果会是怎样的。
BIO领域一种经典的设计范式是每个请求对应一个线程。我们就用这种思想设计一下游戏的服务端,设计图如下:
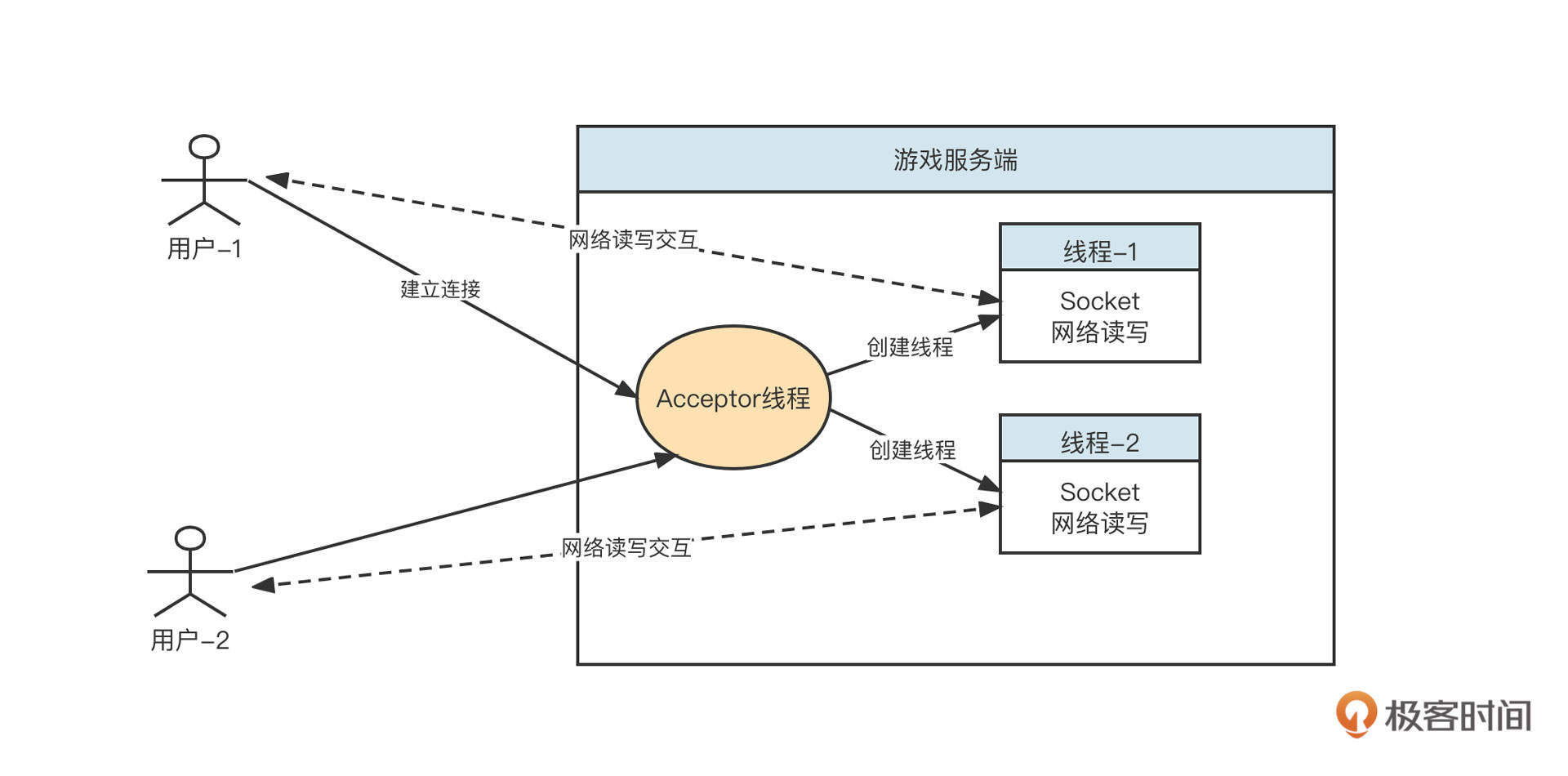
游戏服务端后端的设计思想是:采用长连接模式。每当一个客户端上线,服务端就会为请求创建一个线程,在独立的线程中和客户端进行网络读写,一旦客户端下线,就会关闭对应的线程。
但是一台服务器能创建的线程个数是有限的,所以基于BIO模式构建的优秀服务端一个非常明显的弊端:在线用户数越多,需要创建的线程数就越多,支撑的并发在线用户数量受到明显制约。更加严重的问题是,服务端与其中某些客户端并不是一直在通信,大量线程的网络连接处于阻塞状态,线程资源无法得到有效利用。
为了防止因为线程急剧膨胀、线程资源耗尽影响到服务端的设计,这时候我们通常会引入线程池。因为引入线程池就相当于是在限流,超过线程池规定的线程数量,服务器就会拒绝连接。
对于需要支持大量在线并发用户(连接)的服务器来说,BIO的网络IO模型绝对不是一个好的选择。
我们再来看下NIO模式。基于NIO模式设计的游戏服务端模型如下图所示:
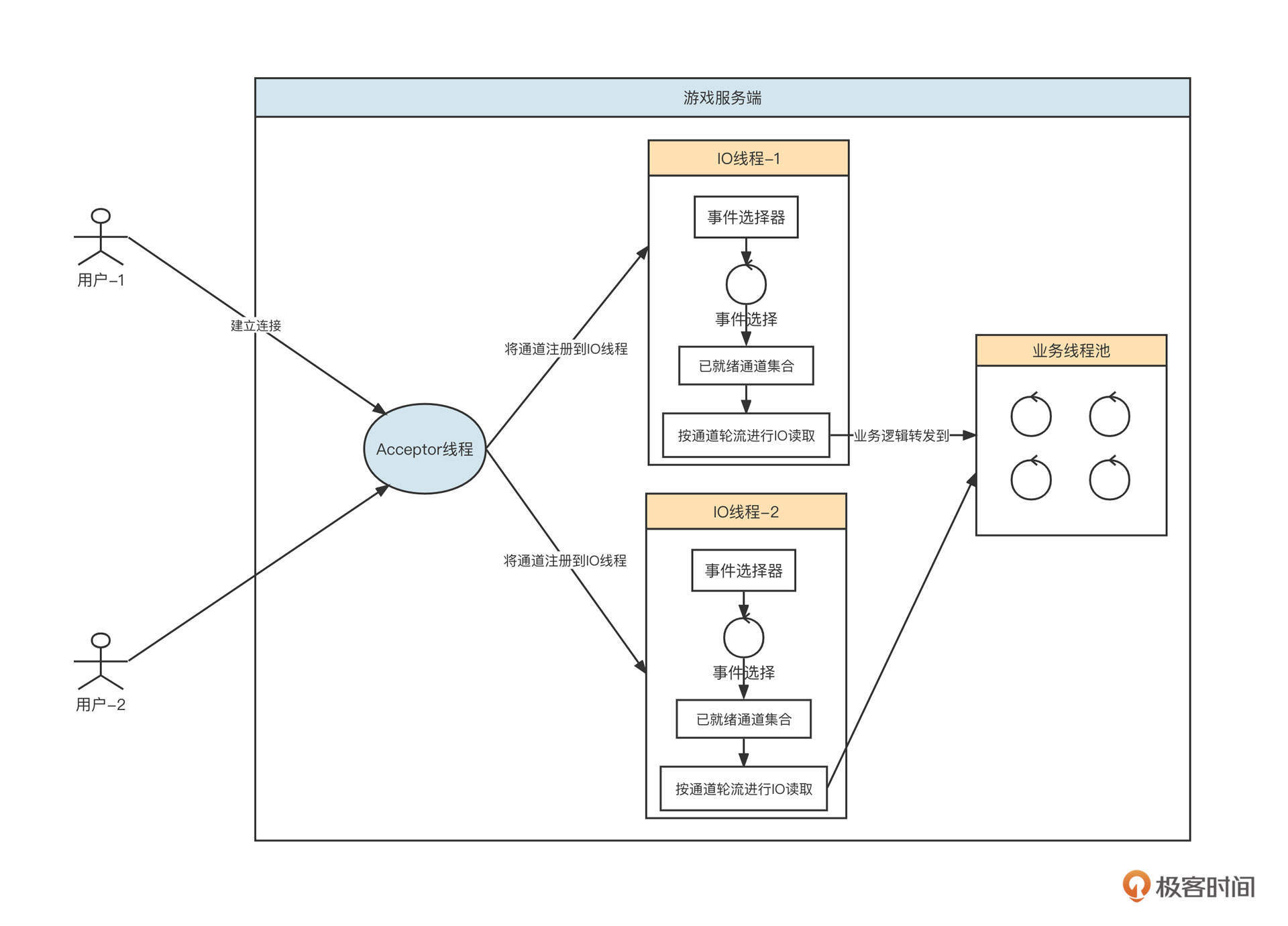
基于NIO,在业界有一种标准的线程模型Reactor,在这节课的后半部分我们还会详细介绍,这里我们先说明一下NIO的优势。
首先,服务端会创建一个线程池专门处理网络读写,我们称之为IO线程池。IO线程池内会内置NIO的事件选择器。当游戏服务端监听到一个客户端时,会从IO线程池中根据负载均衡算法选择一个IO线程,将其注册到事件选择器中。
事件选择器会定时进行事件轮询,挑选=出数据进行传输(读取或写入),执行事件选择,然后在IO线程中按连接分别读取数据。在将请求解码后,丢到业务线程中执行对应的业务逻辑,它的主要功能是分担IO线程的压力,做到尽量不阻塞IO线程。
使用NIO可以做到用少量线程来服务大量连接,哪怕客户端连接数增长,也不会造成服务端线程膨胀。这个优势的关键点在于,基于事件选择机制,IO线程都在进行有效的读写,而不像BIO那样,在没有数据传输时还得占用线程资源。
也正是因此,NIO非常适合需要同时支持大量客户端在线的场景。在NIO模型下,单个请求的数据包建议不要太大。
值得注意的是,一个IO线程在一次事件就绪选择可能会有多个网络连接具备了读或写的准备,但此时对这些网络通道是串行执行的,所以如果每一个网络通道需要读或写的数据比较大,这就必然导致其他连接的延时。
既然NIO这么优秀,那为什么MySQL数据访问客户端还是采用BIO模式呢?为啥不改造成NIO呢?
其实在进行技术选型时,并不是越新的技术就越好,我们还是要结合具体问题具体分析。
我们再回过头来看MySQL客户端的场景。目前在应用层面,我们会为每一个应用配置一个数据库连接池。当业务线程需要进行数据库操作时,它会尝试从数据库连接池获取一个数据库连接(底层是一条TCP连接,负责与服务端进行网络的读与写),然后使用这条连接发送SQL语句并获取SQL结果。任务结束之后,业务线程会把数据库连接归还给连接池,从而实现数据库连接的复用。
与此同时,我们为了保证数据库服务端的可用性,通常需要强制限制客户端能使用的连接数量。这就注定了数据库客户端没有需要支持大量连接的诉求,在这个场景下,客户端使用阻塞型IO对保护数据库服务端更有优势。
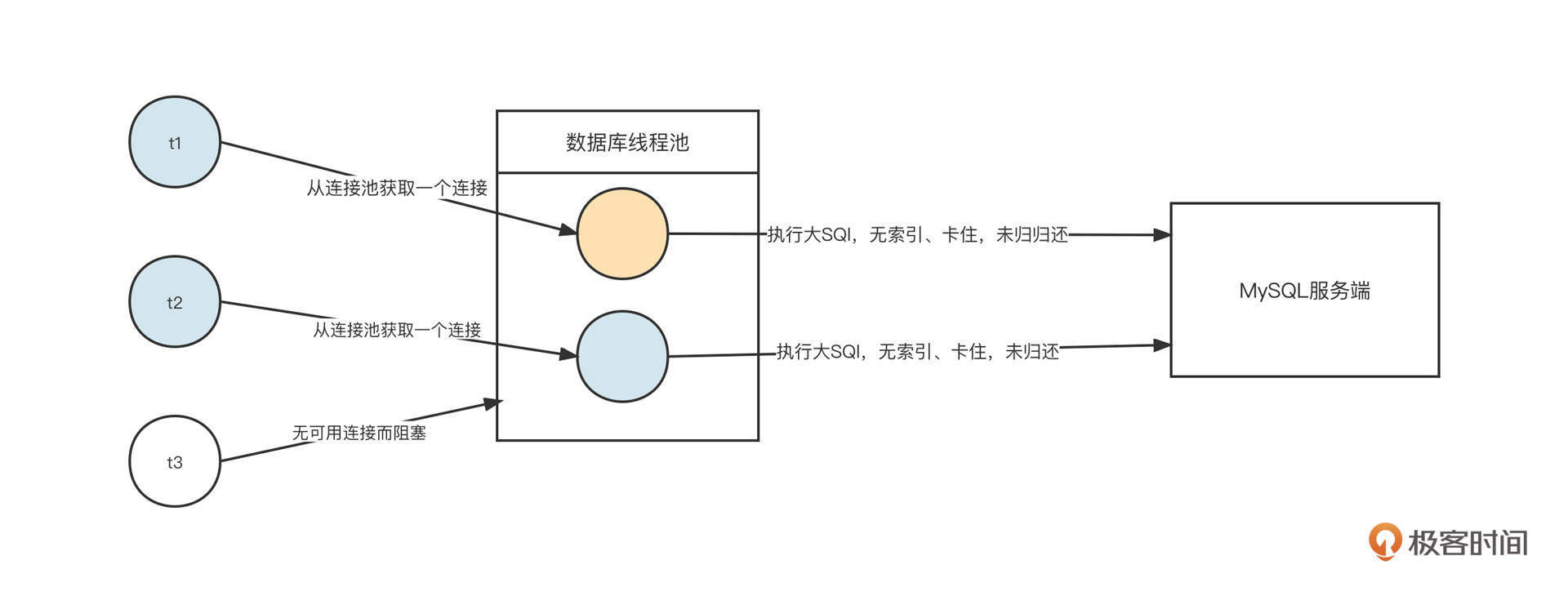
简单说明一下。假设业务代码存在缺陷,导致需要执行一条SQL语句来获取大量数据。这时,我们要尝试从数据库连接池中获取连接,并通过这个连接向MySQL服务端发送SQL语句。由于这条SQL语句的执行性能很差,这条连接在客户端一直被阻塞,无法继续发送更多的SQL。另外如果数据库连接池中没有空闲连接,再尝试获取连接时还需要等待连接被释放,服务器缓慢的执行速度确保了客户端不能持续发送新的请求,对保护数据库服务器大有裨益。
这种情况下如果使用NIO模型,客户端会无节制地用一条连接发送大量请求,导致服务端出现完全不可用的情况。
总结一下就是,NIO模型更适合需要大量在线活跃连接的场景,常见于服务端;BIO模型则适合只需要支持少量连接的场景,常常用于客户端,这也是MySQL数据访问客户端会在网络IO模型方面使用BIO的原因。
Reactor线程模型
学习NIO的理论知识非常枯燥,而且很难做到透彻地理解,我们需要一个实例来深入进去。结合我的学习经验,我觉得学习Reactor经典线程模型,尝试编写一个Reactor线程模型对提升NIO的理解非常有帮助。
为什么这么说呢?因为在编写网络通信相关的功能模块时,建立一套线程模型是非常重要的一环,经过各位前辈不断的实践,Reactor线程模型已成为NIO领域的事实标准,无论是网络编程类库NIO,还是Kafka、Dubbo等主流中间件的底层网络模型都是直接或间接受到了Reactor模型的影响。
那什么是Reactor线程模型?怎么使用NIO来实现Reactor模型?这两个问题,就是我们这节课后半部分的重点。
什么是Reactor线程模型?
Reactor主从多Reactor模型的架构设计如下图所示:
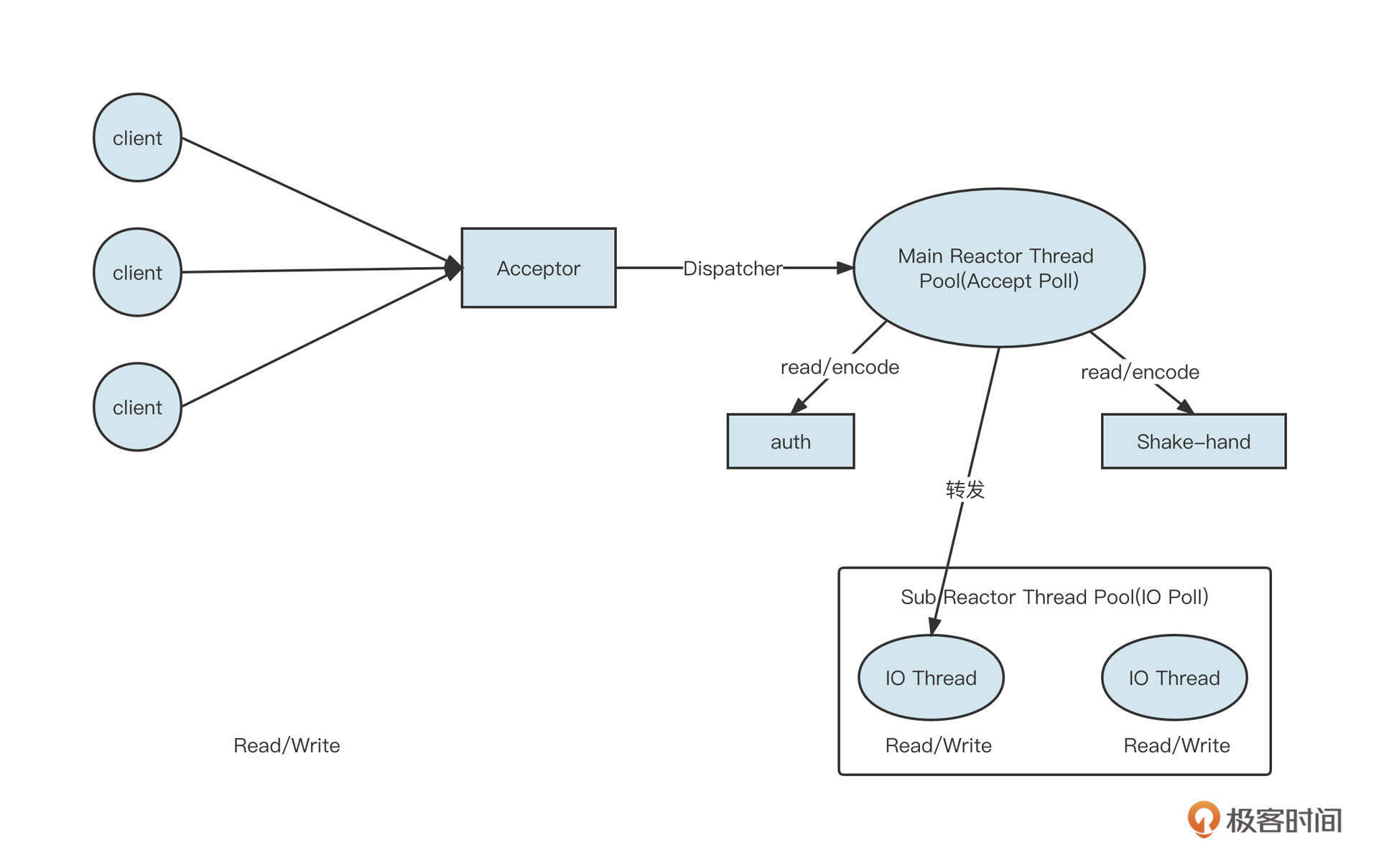
说明一下各个角色的职责。
Acceptor:请求接收者,作用是在特定端口建立监听。Main Reactor Thread Pool:主Reactor模型,主要负责处理OP_ACCEPT事件(创建连接),通常一个监听端口使用一个线程。在具体实践时,如果创建连接需要进行授权校验(Auth)等处理逻辑,也可以直接让Main Reactor中的线程负责。NIO Thread Group( IO 线程组):在Reactor模型中也叫做从Reactor,主要负责网络的读与写。当Main Reactor Thread 线程收到一个新的客户端连接时,它会使用负载均衡算法从NIO Thread Group中选择一个线程,将OP_READ、OP_WRITE事件注册在NIO Thread的事件选择器中。接下来这个连接所有的网络读与写都会在被选择的这条线程中执行。NIO Thread:IO线程。负责处理网络读写与解码。IO线程会从网络中读取到二进制流,并从二进制流中解码出一个个完整的请求。业务线程池:通常IO线程解码出的请求将转发到业务线程池中运行,业务线程计算出对应结果后,再通过IO线程发送到客户端。
我们再通过一个网络通信图进一步理解Reactor线程模型。
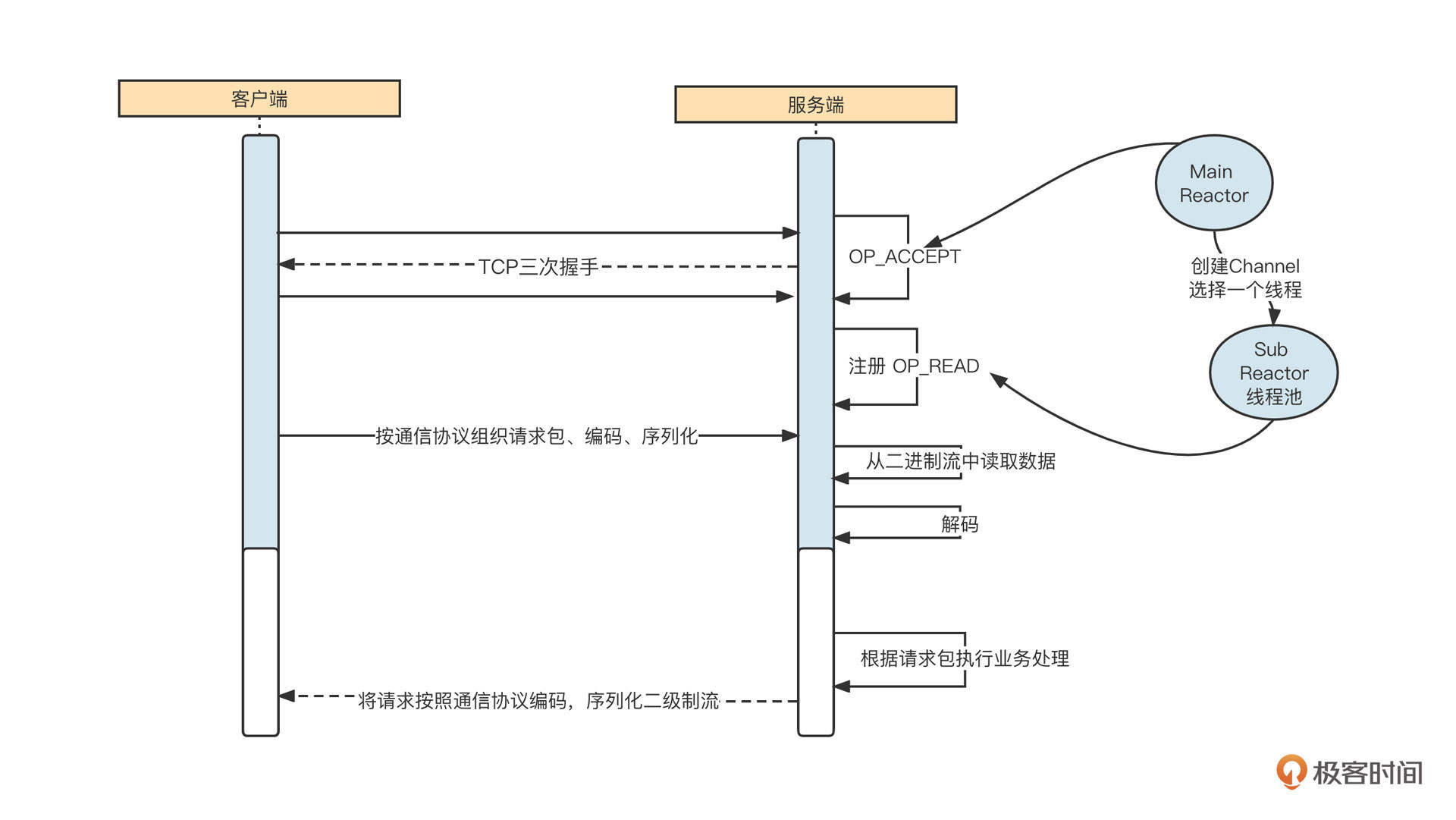
网络通信的交互过程通常包括下面六个步骤。
- 启动服务端,并在特定端口上监听,例如,web 应用默认在80端口监听。
- 客户端发起TCP的三次握手,与服务端建立连接。这里以 NIO 为例,成功建立连接后会创建NioSocketChannel对象。
- 服务端通过 NioSocketChannel 从网卡中读取数据。
- 服务端根据通信协议从二进制流中解码出一个个请求。
- 根据请求执行对应的业务操作,例如,Dubbo 服务端接受了请求,并根据请求查询用户ID为1的用户信息。
- 将业务执行结果返回到客户端(通常涉及到协议编码、压缩等)。
线程模型需要解决的问题包括:连接监听、网络读写、编码、解码、业务执行等,那如何运用多线程编程优化上面的步骤从而提升性能呢?
主从多Reactor模型是业内非常经典的,专门解决网络编程中各个环节问题的线程模型。各个线程通常的职责分工如下。
- Main Reactor 线程池,主要负责连接建立(OP_ACCEPT),即创建NioSocketChannel后,将其转发给SubReactor。
- SubReactor 线程池,主要负责网络的读写(从网络中读字节流、将字节流发送到网络中),即监听OP_READ、OP_WRITE,并且同一个通道会绑定一个SubReactor线程。
编码、解码和业务执行则具体情况具体分析。通常,编码、解码会放在IO线程中执行,而业务逻辑的执行会采用额外的线程池。但这不是绝对的,一个好的框架通常会使用参数来进行定制化选择,例如 ping、pong 这种心跳包,直接在 IO 线程中执行,无须再转发到业务线程池,避免线程切换开销。
怎么用NIO实现Reactor模型?
理解了Reactor线程模型的内涵,接下来就到了实现这一步了。
我建议你在学习这部分内容时,同步阅读一下《Java NIO》这本电子书的前四章。这本书详细讲解了NIO的基础知识,是我学习Netty的老师,相信也会给你一些帮助。
我们先来看一下Reactor模型的时序图,从全局把握整体脉络:
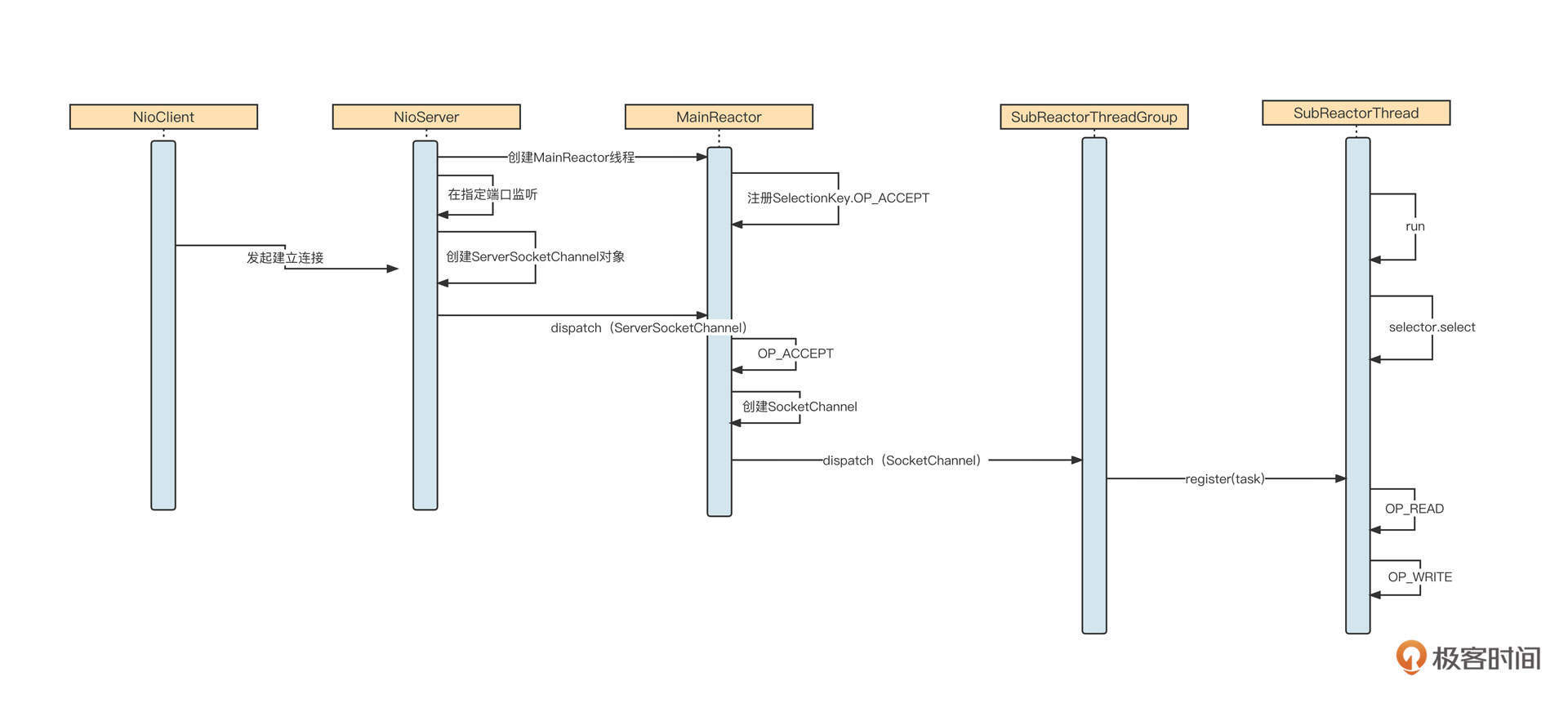
这里核心的流程有三个。
- 服务端启动,会创建MainReactor线程池,在MainReactor中创建NIO事件选择器,并注册OP_ACCEPT事件,然后在指定端口监听客户端的连接请求。
- 客户端向服务端建立连接,服务端OP_ACCEPT对应的事件处理器被执行,创建NioSocketChannel对象,并按照负载均衡机制将其转发到SubReactor线程池中的某一个线程上,注册OP_READ事件。
- 客户端向服务端发送具体请求,服务端OP_READ对应的事件处理器被执行,它会从网络中读取数据,然后解码、转发到业务线程池执行具体的业务逻辑,最后将返回结果返回到客户端。
我们解读下核心类的核心代码。
NioServer的代码如下:
1 | private static class Acceptor implements Runnable { |
启动服务端会创建一个Acceptor线程,它的职责就是绑定端口,创建ServerSocketChannel,然后交给MainReactor去处理接收连接的逻辑。
MainReactor的具体实现如下:
1 | public class MainReactor implements Runnable{ |
SubReactorThreadGroup内部包含一个SubReactorThread数组,并提供负载均衡机制,供MainReactor线程选择具体的SubReactorThread线程,具体代码如下:
1 | public class SubReactorThreadGroup { |
SubReactorThread IO线程的具体实现如下:
1 | public class SubReactorThread extends Thread{ |
IO线程负责从网络中读取二进制并将其解码成具体请求,然后转发到业务线程池执行。
接下来,业务线程池会执行业务代码并将响应结果通过IO线程写入到网络中,我们对业务进行简单的模拟:
1 | public class Handler implements Runnable{ |
我们再来看一下客户端创建连接的代码:
1 | public class NioClient { |
这样,一个Reactor模型就搭建好了。如果你想完整地学习这个Reactor模型的详细代码,可以到我的GitHub上查看。
总结
好了,这节课就讲到这里。
这节课,我们先结合场景介绍了BIO与NIO两种网络编程模型和它们的优缺点。
根据等待数据阶段和数据传输阶段这两个阶段的特质,我们可以得到BIO的全称同步阻塞IO,还有NIO的全称同步非阻塞IO。NIO模型更适合需要大量在线活跃连接的场景,常见于服务端;BIO模型则适合只需要支持少量连接的场景。
我们还了解了一个业内非常经典的线程模型:主从多Reactor模型。它的核心设计理念是让线程分工明确,相互协作。Main Reactor 线程池主要负责连接建立,SubReactor 线程池主要负责网络的读写,而编码、解码和业务执行则需要具体情况具体分析。
最后,我还带你使用NIO技术实现了主从多Reactor模型,给你推荐了一本学习NIO必备的电子书《Java NIO》,这本书非常详细介绍了NIO的三大金刚:缓存、通道和选择器的各类基础知识。我建议你在阅读完本电子书后,再来反复看看这个Reactor示例,相信可以在你进修NIO的基础上助你一臂之力。
课后题
学完这节课,我也给你出两道课后题。
- 为什么NIO不适合请求体很大的场景?
- 请你详细阅读《Java NIO》这本书中Reactor模型的示例子代码,尝试实现一个简易的RPC Request-Response模型。
例如,模拟Dubbo服务调用需要传入基本的参数:包名、方法名,参数。客户端发送这些数据后,服务端根据接收的数据,在服务端要正确打印包名、方法名、参数,并向客户端返回 “hello,收到请求” + 包名 + 方法名。
欢迎你在留言区留下你的思考结果,我们下节课见!
08 | Netty:如何优雅地处理网络读写,制定网络通信协议?
作者: 丁威

你好,我是丁威。
上一节课,我们介绍了中间件领域最经典的网络编程模型NIO,我也在文稿的最后给你提供了用NIO模拟Reactor线程模型的示例代码。如果你真正上手了,你会明显感知到,如果代码处理得过于粗糙,只关注正常逻辑却对一些异常逻辑考虑不足,就不能成为一个生产级的产品。
这是因为要直接基于NIO编写网络通讯层代码,需要开发者拥有很强的代码功底和丰富的网络通信理论知识。所以,为了降低网络编程的门槛,Netty框架就出现了,它能够对NIO进行更高层级的封装。
从这之后,开发人员只需要关注业务逻辑的开发就好了,网络通信的底层可以放心交给Netty,大大降低了网络编程的开发难度。
这节课,我们就来好好谈谈Netty。
我会先从网络编程中通信协议、线程模型这些网络编程框架的共性问题入手,然后重点分析Netty NIO的读写流程,最后通过一个Netty编程实战,教会你怎么使用Netty解决具体问题,让你彻底掌握Netty。
通信协议
如果你不从事中间件开发工作,那估计网络编程对你来说会非常陌生,为了让你对它有一个直观的认知,我给你举一个例子。
假如我们在使用Dubbo构建微服务应用,Dubbo客户端在向服务提供者发起远程调用的过程中,需要告诉服务提供者服务名、方法名和参数。但这些参数是怎么在网络中传递的呢?服务提供者又怎么识别出客户端的意图呢?
你可以先看看我画的这张图:
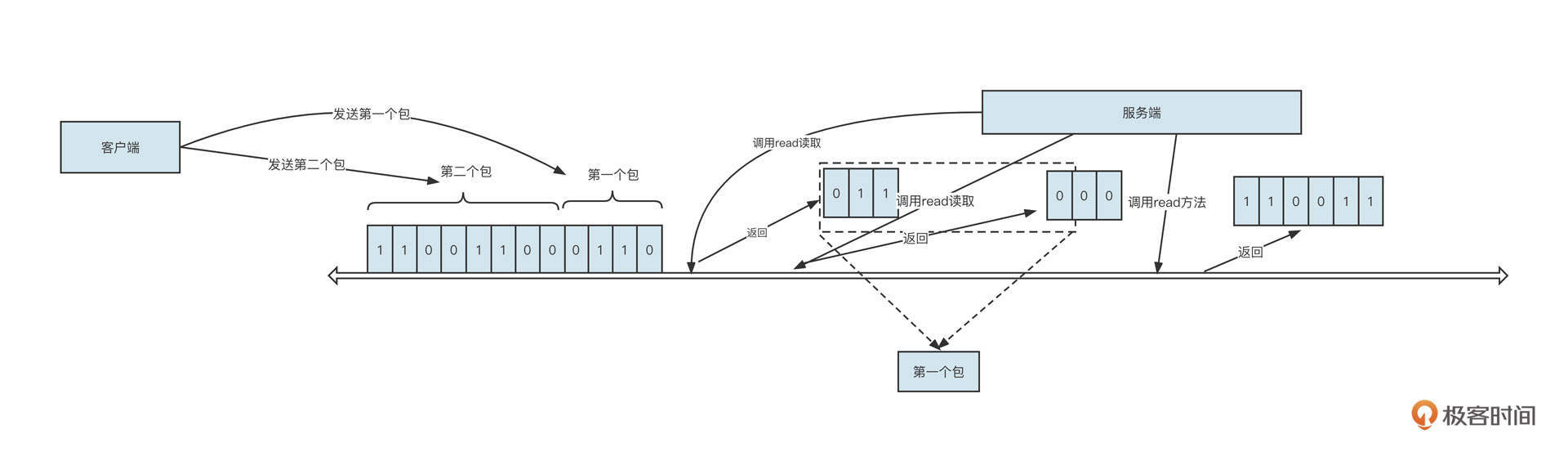
客户端在发送内容之前需要先将待发送的内容序列化为二进制流。例如,上图发送了两个包,第一个包的二进制流是0110,第二个包的二进制流是00110011。这时,服务端读取数据的情形可能有两种。
- 经过多次读取:在上面这张图中,服务端调用了3次read方法才把数据全部读取出来,分别读取到的包是011、000、110011。
- 调用一次read就读取到所有数据:例如011000110011。
这里我插播一个小知识,一次read方法能读取到的数据量,要取决于网卡中可读数据和接收缓冲区的大小。
那服务端是如何正确识别出0110就是第一个请求包,00110011是第二个请求包的呢?它为什么不会将011当成第一个请求包,000当成第二个请求包,110011当成第三个包,或者直接将011000110011当成一个请求包呢?其实这种现象叫做粘包。
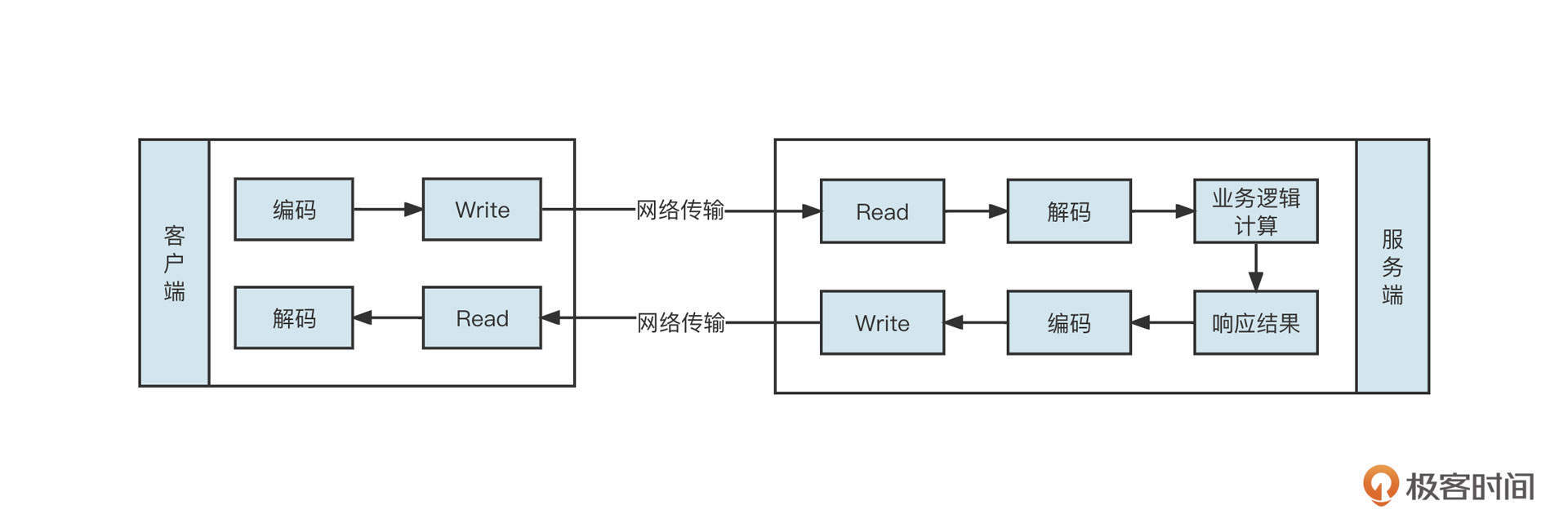
常用的解决方案是客户端与服务端共同制定一个通信规范(也称通信协议),用它来定义请求包/响应包的具体格式。这样,客户端发送请求之前,需要先将内容按照通信规范序列化成二进制流,这个过程称之为编码;同样,服务端会按照通信规范将收到的二进制流进行反序列化,这个过程称之为解码。
从这里你也可以看出,网络编程中通常涉及编码、往网络中写数据(Write)、从网络中读取数据(Read)、解码、业务逻辑处理、发送响应结果和接受响应结果等步骤,你可以看下下面这张图,加深理解:
那如何制订通信协议呢?
通信协议的制订方法有很多,有的是采用特殊符号来标记一个请求的结束,但如果请求体中也包含这个分隔符就会使协议破坏,还有一种方法是使用固定长度来表述一个请求包,定义一个请求包固定包含多少字节,如果请求体内存不足,就使用填充符合进行填充,但这种方式会造成空间的浪费。
业界最为经典的协议设计方法是协议头+Body的设计理念,如图所示:
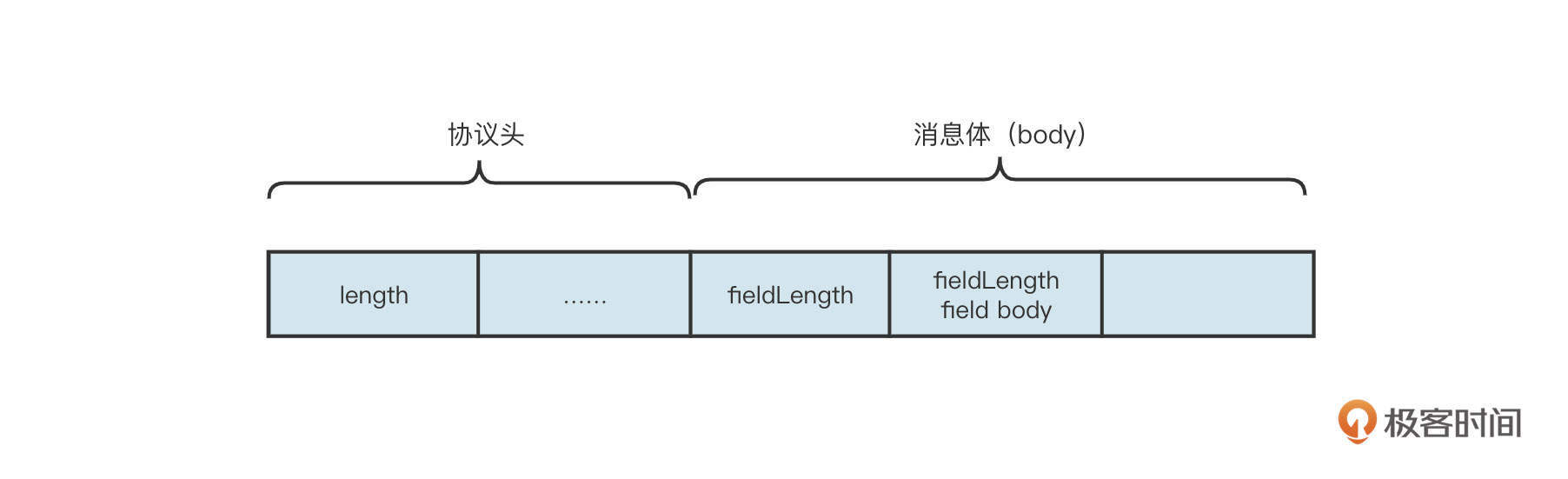
这里有几个关键点,你需要注意一下:
- 协议头的长度是固定的,通常为识别出一个业务的最小长度;
- 协议头中会包含一个长度字段,用来标识一个完整包的长度,用来表示长度字段的字节位数直接决定了一个包的最大长度;
- 消息体中存储业务数据。
为了更直观地给你展示,我直接以一个简单的 RPC 通信场景为例,实现类似Dubbo服务远程服务调用,通信协议设计如下图所示:
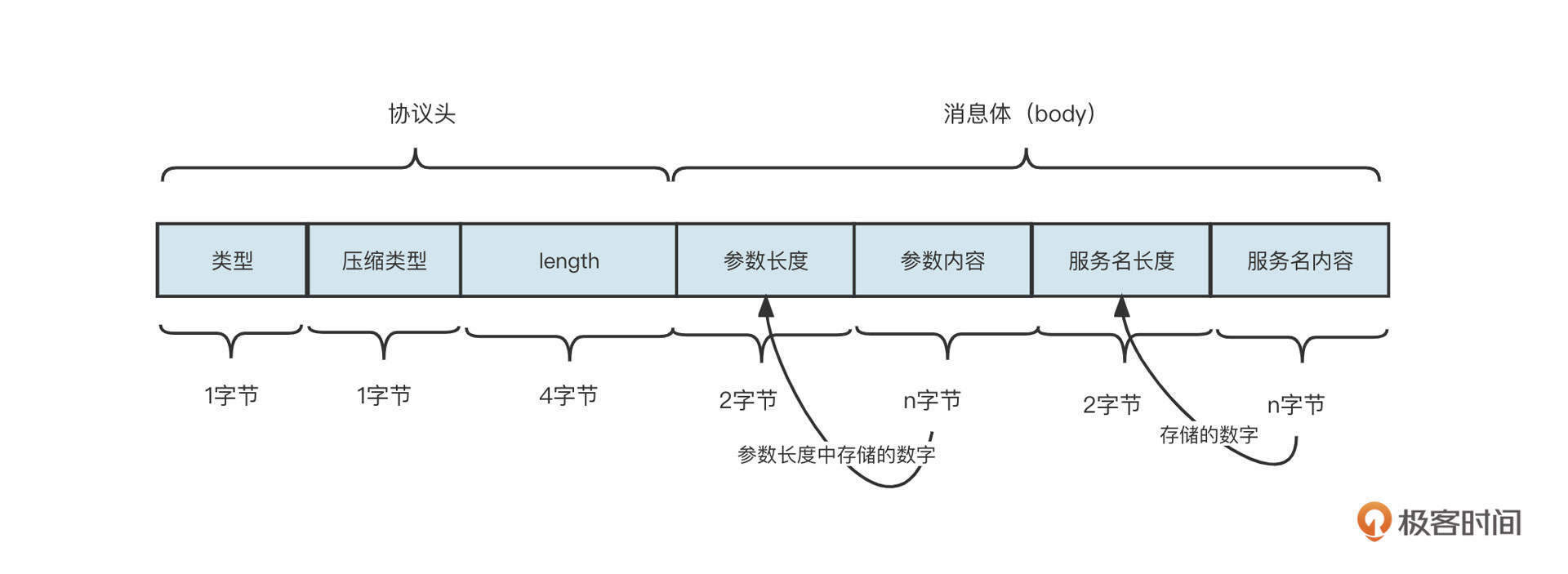
这里我们演示的是基于Header+Body的设计模式,接受端从网络中读取到字节后解码的流程。接受端将读取到的数据存储在一个接收缓冲区,在Netty中称为累积缓冲区。
首先我们要判断累积缓存区中是否包含一个完整的Head,例如上述示例中,一个包的Header 的长度为 6 个字节,那首先判断累积缓存中可读字节数是否大于等于 6,如果不足 6 个字节,跳过本次处理,等待更多数据到达累积缓存区。
如果累积缓存区中包含一个完整的Header,就解析头部,并且提取长度字段中存储的数值,即包长度,然后判断累积缓存区中可读字节数是否大于或等于整个包的长度。如果累积缓存区不包含一个完整的数据包,则跳过本次处理,等待更多数据到达累积缓存区。如果累积缓存区包含一个完整的包,则按照通信协议的格式按顺序读取相关的内容。
通过上面这种方式,我们就可以完美解决粘包问题了。
我们前面也说了,网络编程中包含编码、解码、网络读取、业务逻辑等多个步骤,所以如何使用多线程提升并发度,合理处理多线程之间的高效协作就显得尤为重要,接下来我们来看一下Netty的线程模型是怎么做的。
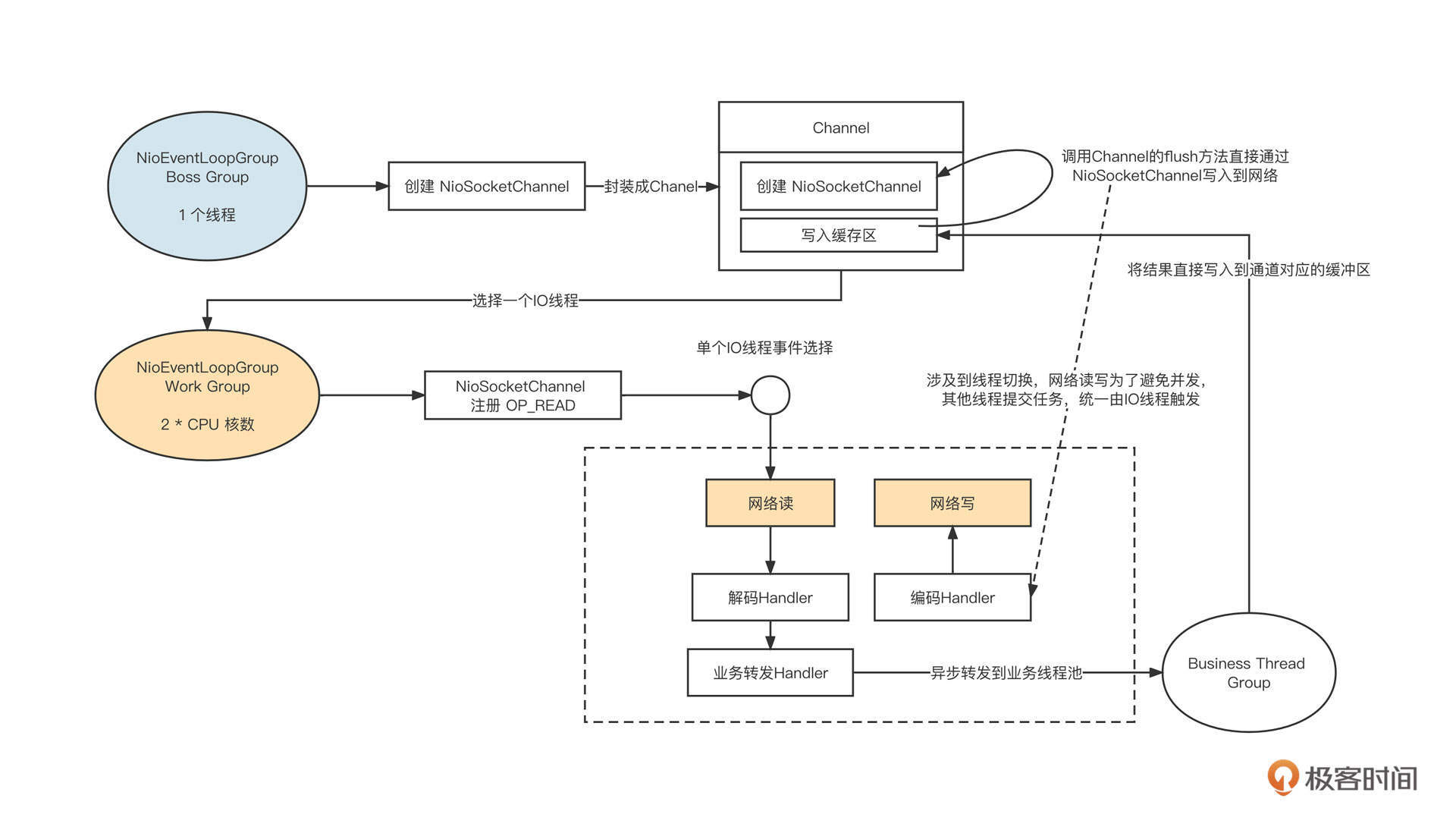
Netty的线程模型采取的是业界的主流线程模型,也就是主从多Reactor模型:
它的设计重点主要包括下面这几个方面。
- Netty Boss Group线程组
主要处理OP_ACCEPT事件,用于处理客户端链接,默认为1个线程。当Netty Boss Group线程组接收到一个客户端链接时,会创建NioSocketChannel对象,并封装成Channel对象,在Channel对象内部会创建一个缓冲区。这个缓冲区可以接收需要通过这个通道写入到对端的数据,然后从Netty Work Group线程组中选择一个线程并注册读事件。
- Nettty Work Group线程组
主要处理OP_READ、OP_WRITE事件,处理网络的读与写,所以也称为IO线程组,线程组中线程个数默认为CPU的核数。由于注册了读事件,所以当客户端发送请求时,读事件就会触发,从网络中读取请求,进入请求处理流程。
- 扩展机制采用责任链设计模式
编码、解码等功能对应一个独立的Handler,这些Handler默认在IO线程中执行,但Netty支持将Handler的执行放在额外的线程中执行,实现与IO线程的解耦合,避免IO线程阻塞。
- Business Thread Group
经过解码后得到一个完整的请求包,根据请求包执行业务逻辑,通常会额外引入一个独立线程池,执行业务逻辑后会将结果再通过IO线程写入到网络中。
业务线程在处理完业务逻辑后,通过调用通道将数据发送到目标端。但它并不能当下直接发送,而是要将数据放入到Channel中的写缓存区,并向IO线程提交一个写入任务。这里涉及到线程切换,因为所有的读写操作都需要在IO线程中执行(即一个通道的IO操作都是同一个线程触发的),避免了多线程编程的复杂性。
说到这里,我建议你停下来,尝试用NIO实现Netty的线程模型,检验一下自己对NIO的掌握程度。
理解了Netty的线程模型,接下来我们继续学习Netty是怎样处理读写流程的。在进入下面的学习之前,我有几个问题希望你先思考一下:
- 如何处理连接半关闭?
- 什么时候应该注册读事件?
- 写数据之前一定要先注册写事件吗?
Netty如何处理网络读写事件?
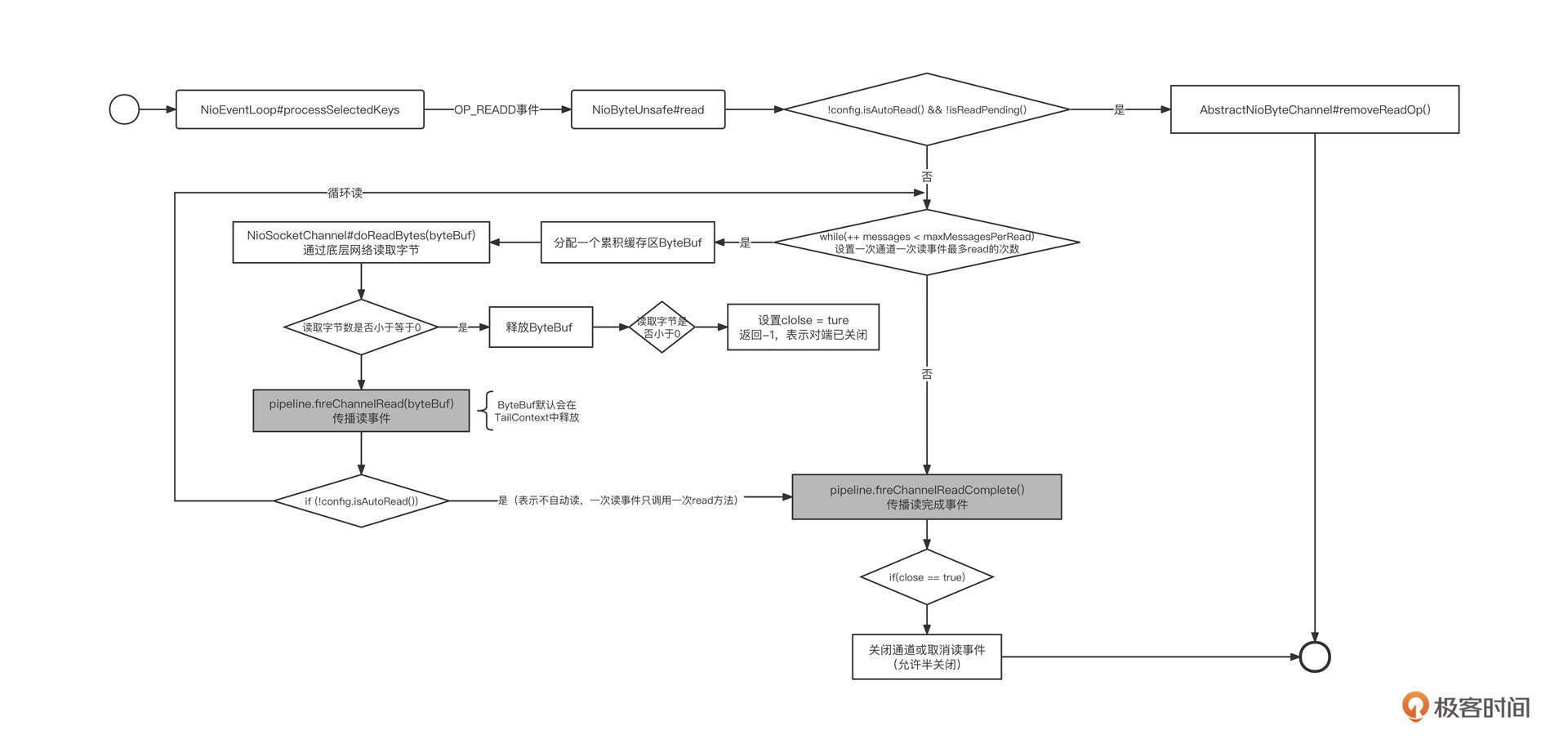
Netty IO 读事件由 AbstractNioByteChannel 内部类 AbstractNioUnsafe 的 read 方法实现,接下来我们就来重点剖析一下这个方法,从中窥探 Netty 是如何实现 IO 读事件的。
由于AbstractNioUnsafe的read方法代码很长,我们分步进行解读。
第一步,如果没有开启自动注册读事件,在每一次读时间处理过后会取消读事件,代码片段如下:
1 | final ChannelConfig config = config(); |
这段代码背后蕴含的知识点是,事件注册是一次性的。例如,为通道注册了读事件,然后经事件选择器选择触发后,选择器不再监听读事件,再出来完成一次读事件后需要再次注册读事件。Netty中默认每次读取处理后会自动注册读事件,如果通道没有注册读事件,则无法从网络中读取数据。
第二步,为本次读取创建接收缓冲区,临时存储从网络中读取到的字节,代码片段如下:
1 | final ByteBufAllocator allocator = config.getAllocator(); |
创建接收缓存区需要考虑的问题是,该创建多大的缓存区呢?如果缓存区创建大了,就容易造成内存浪费;如果分配少了,在使用过程中就可能需要进行扩容,性能就会受到影响。
Netty在这里提供了扩展机制,允许用户自定义创建策略,只需实现RecvByteBufAllocator接口就可以了。它又包括两种实现方式:
- 分配固定大小,待内存不够时扩容;
- 动态变化,根据历史的分配大小,动态调整接收缓冲区的大小。
第三步,循环从网络中读取数据,代码片段如下:
1 | do { |
为什么要循环读取呢?为什么不一次性把通道中需要读取到的数据全部读完再继续下一个通道呢?
其实,这主要是为了避免单个通道占用太多时间,导致其他链接没有机会去读取数据。所以Netty会限制在一次读事件处理过程中调用底层读取API的次数,这个次数默认为16次。
接下来我们进行第四步。这里要提醒一下,第四步和第五步都是位于第三步的循环之中的。
第四步,调用底层SokcetChannel的read方法从网络中读取数据,代码片段如下:
1 | byteBuf = allocHandle.allocate(allocator); |
解释一下,首先用writable存储接收缓存区可写字节数,然后通过调用底层NioSocketChannel从网络中读取数据,并返回本次读取的字节数。
那在什么情况下读取的字节数小于0呢?原来,TCP是全双工通信模型,任意一端都可以关闭接收或者写入,如果对端连接调用了关闭(半关闭),那么我们尝试从网络中读取字节时就会返回-1,跳出循环。
然后,我们要将读取到的内容传播到事件链中,事件链中各个事件处理器会依次对这些数据进行处理。
如果你也在使用Netty进行应用代码开发,请特别注意byteBuf的释放问题。自定义的事件处理器中要尽量继续调用fireChannelRead方法,Netty内置了一个HeadContext,它在实现时会主动释放ByteBuf。但如果自定义的事件处理器阻断了事件传播,请记得一定要释放ByteBuf,否则会造成内存泄露。
第五步,判断是否要跳出读取:
1 | if (totalReadAmount >= Integer.MAX_VALUE - localReadAmount) { |
这里需要关注的一个点是,本次读取到的字节数如果小于接收缓冲区的可写大小,说明通道中已经没有数据可读了,结束本次读取事件的处理。
第六步,完成网络IO读取后,进行善后操作。具体代码片段如下:
1 | pipeline.fireChannelReadComplete(); |
操作结束后,会触发一次读完成事件,并向整个事件链传播。这时候如果对端已经关闭了,则主动关闭链接。
就像我们在上节课提到的,事件机制触发后将失效,需要再次注册,所以Netty支持自动注册读事件。在每一次读事件完成后会主动调用下面这段代码实现读事件的自动注册,具体实现在HeadContext的fireChannelReadComplete方法中,代码片段如下:
1 | public void channelReadComplete(ChannelHandlerContext ctx) throws Exception { |
这里还涉及另一问题,那就是Netty的channelRead、channelReadComplete等事件是怎么传播的呢?我建议你查看我的另一篇文章《Netty4 事件处理传播机制》。
Netty网络读流程就讲到这里了,我们用一张流程图结束网络读取部分的讲解:
接下来,我们一起看看Netty的网络写入流程。
基于Netty网络模型,通常会使用一个业务线程池来执行业务操作,业务执行完成后,需要通过网络将响应结果提交给对应的IO线程,再通过IO线程将数据返回给客户端,其过程大致如下:
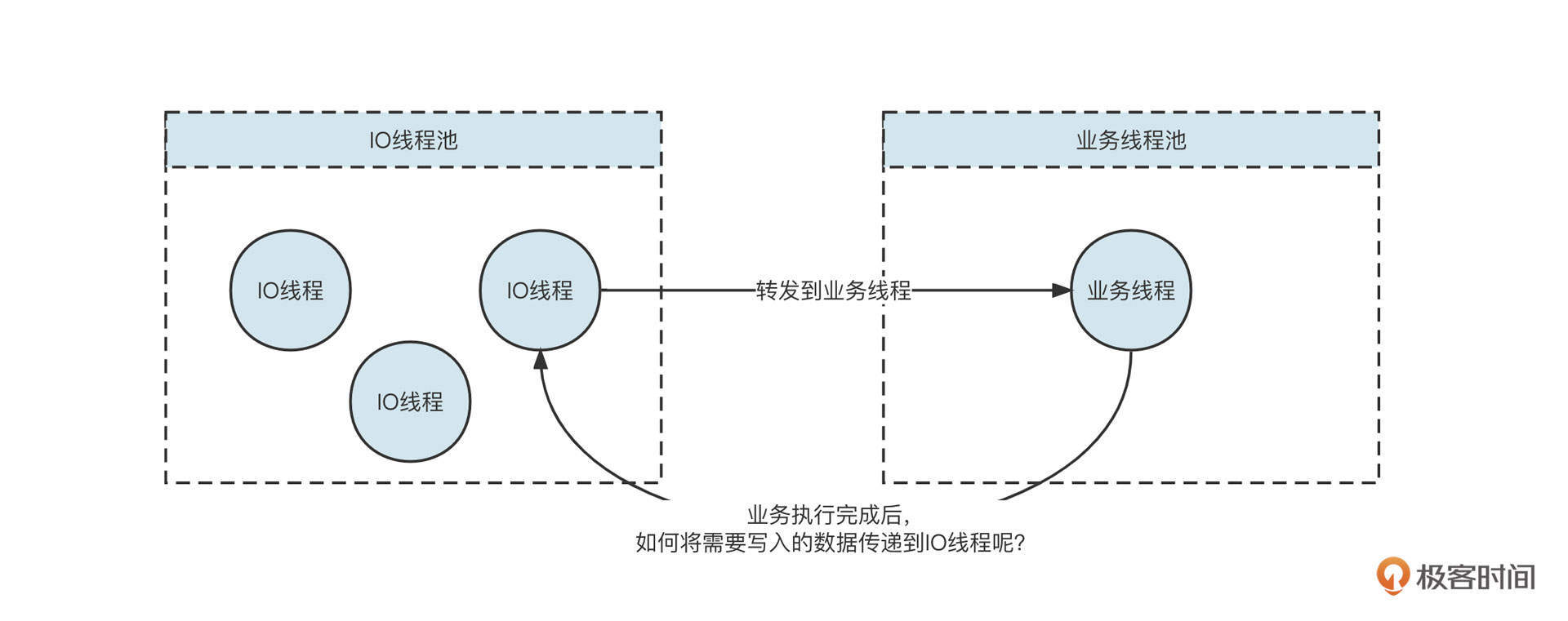
那在代码实现层面,业务线程与IO线程是怎么协作的呢?我们带着这个问题,继续深入研究Netty的网络写入流程。
在Netty中,一眼就能看到写事件的处理入口,也就是NioEventLoop(IO线程)的processSelectedKey方法,代码片段如下所示:
1 | // Process OP_WRITE first as we may be able to write some queued buffers and so free memory. |
查看processSelectedKey方法的调用链,我们看到这个方法最终会调用AbstractUnsafe的flush0方法,代码片段如下所示:
1 | protected void flush0() { |
flush0方法的核心要点主要包括下面三点。
- 获取写缓存队列。如果写缓存队列为空,则跳过本次写事件。每一个通道Channel内部维护一个写缓存区,其他线程调用Channel向网络中写数据时,首先会写入到写缓存区,等到写事件被触发时,再将写缓存区中的数据写入到网络中。
- 如果通道处于未激活状态,需要清理写缓存区,避免数据污染。
- 通过调用 doWrite 方法将写缓存中的数据写入网络通道中。
这里的doWrite方法比较重要,我们重点介绍一下。
doWrite方法主要使用NIO完成数据的写入,具体由NioSocketChannel的doWrite实现,由于这一方法代码较长,我们还是分段来进行讲解。
第一步,如果通道的写缓存区中没有可写数据,需要取消写事件,也就是说,这时候不必关注写事件。具体代码如下:
1 | int size = in.size(); |
这背后的逻辑是,如果注册写事件,每次进行事件就绪选择时,只要底层TCP连接的写缓存区不为空,写就会就绪,它会继续通知上层应用程序可以往通道中就绪了。但这种情况下,如果上层应用无数据可写,写事件就绪就变得没有意义了。所以,为了避免出现这种情况,如果没有数据可写,建议直接取消写事件。
第二步,尝试将缓存区数据写入到网络中:
1 | switch (nioBufferCnt) { |
也就是说,这一步要根据缓存区中的数据进行区分写入,各个分支的情况有所不同:
- 如果缓存区nioBufferCnt的个数为0,说明待写入数据为FileRegion(Netty零拷贝实现关键点),需要调用父类NIO相关方法完成数据写入。
- 如果数据是Buffer类型,且只有1个,则直接调用父类的doWrite方法,它的底层逻辑是基于NIO通道写入数据。
- 如果数据是Buffer类型而且有多个,那就要使用NIO Gather机制了,这可以避免数据复制。
写入端的处理逻辑也是差不多的。我们可以通过底层NIO SocketChannel的write方法将数据写入到Socket缓存区,有三种情况需要分别考虑。
- 如果返回值为0,表示Socket底层的缓存区已满,需要暂停写入。具体做法是,注册写事件,等Socket底层写缓存区空闲后再继续写入。
- 如果写缓存区的数据写入到了网络,那就需要取消注册写事件,避免毫无意义的写事件就绪。
- 如果写缓存区中的数据很大,为了避免单个通道对其他通道的影响,默认设置单次写事件最多调用底层 NIO SocketChannel的write方法的次数为16。
第三步,如果底层缓存区已写满,重新注册写事件;如果需要写入的数据太多,则需要创建一个Task放入到IO线程中,待就绪事件处理完毕后继续处理。代码片段如下:
1 | if (!done) { |
注意,这里是处理写入的第二个触发点。将写入请求添加到IO线程的任务列表中,就可以继续执行数据写入。也就是说,并不一定要注册写事件才能进行写入。
Task的触发点在NioEventLoop的run方法,代码片段如下:
1 | if (ioRatio == 100) { |
其中,processSelectedKeys就是NIO事件的就绪执行入口。IO线程在执行完事件就绪选择后,会继续执行任务列表中的任务。
在实际开发中,通常是在完成业务逻辑后,往网络中写入数据,调用Channel的writeAndFlush方法。在Channel内部会分别调用write和flush方法。write方法是将数据写入到通道(Channel)对象的写缓存区,而调用flush方法是将通道缓存中的数据写入到网络(Socket 的写缓存区),继而通过网络传输到接收端。
Netty为了避免IO线程与多个业务线程之间的并发问题,业务线程不能直接调用IO线程的数据写入方法,只能是向IO线程提交写入任务,具体代码定义在AbstractChannelHandlerContext的write方法中。
1 | private void write(Object msg, boolean flush, ChannelPromise promise) { |
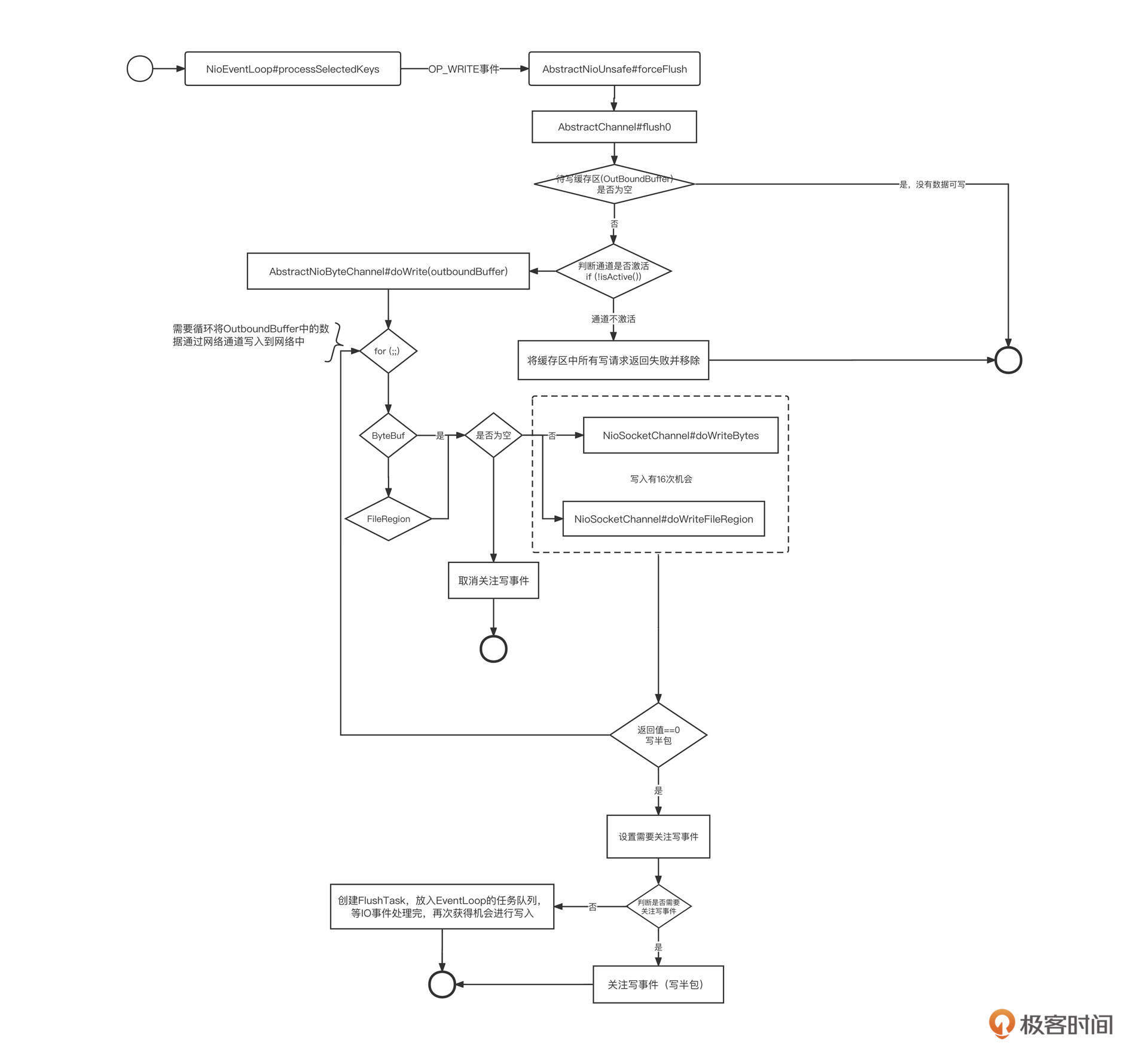
为了方便你深入阅读Netty相关源码,我还给你整理了Netty写入的流程图:
Netty编程实战
好了,关于Netty网络读写的理解就介绍到这里了,但是只有理论是不行的,在这节课的最后,我们来看一个Netty的实战案例。
Netty通常会用在中间件开发、即时通信(IM)、游戏服务器、高性能网关服务器等领域,阿里巴巴的高性能消息中间件RocketMQ就是用Netty进行网络层开发的。
为了方便你学习,我将RocketMQ网络层代码单独抽取成了一个网络编程框架,并上传到了GitHub,你可以拷贝下来跟我一起操作。
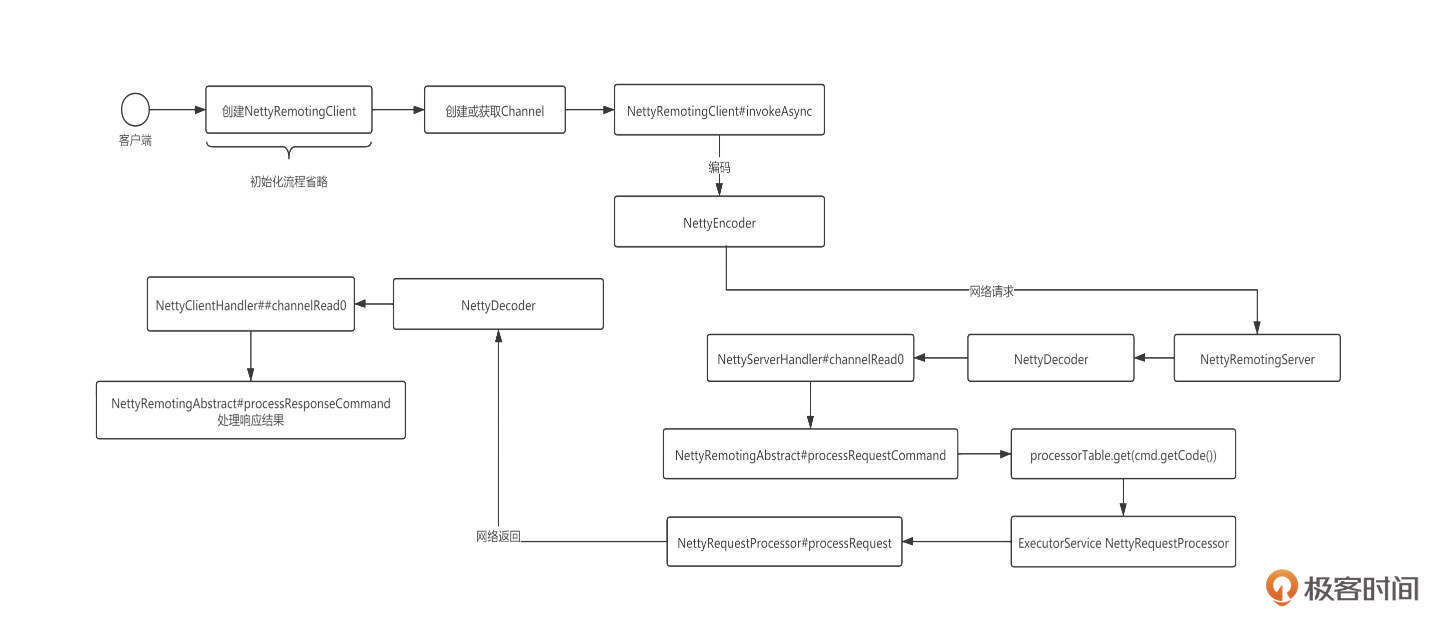
在深入RocketMQ网络层具体实践之前,我们先来看一下RocketMQ的网络交互流程:
基于Netty进行网络编程,我们通常需要编写客户端代码、服务端代码和通信协议。
我们先来看Netty客户端编程的通用示例:
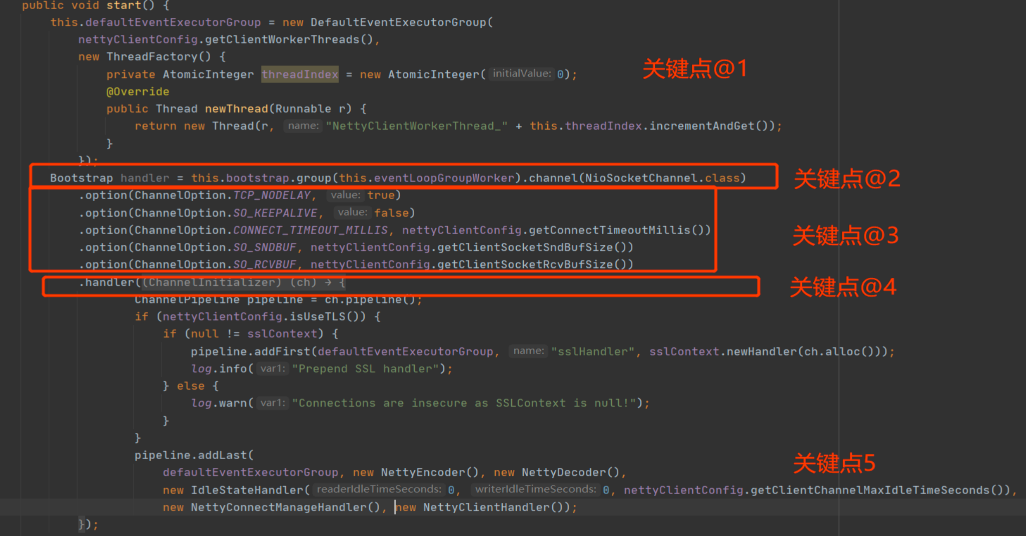
这里我们需要注意五个关键点。
- 需要创建Handler执行线程池,让IO线程只负责网络读写,而且创建线程池一定要使用线程工厂,同时要记得为线程命名。
- 使用Bootstrap的Group方法指定Work线程组。
- 通过Option方法设置网络参数。
- 通过Handler方法创建事件调用链。
- 将编码、解码、业务逻辑处理相关的事件处理器加入到事件执行链条。
再来看一下客户端如何创建连接,其代码片段如下:
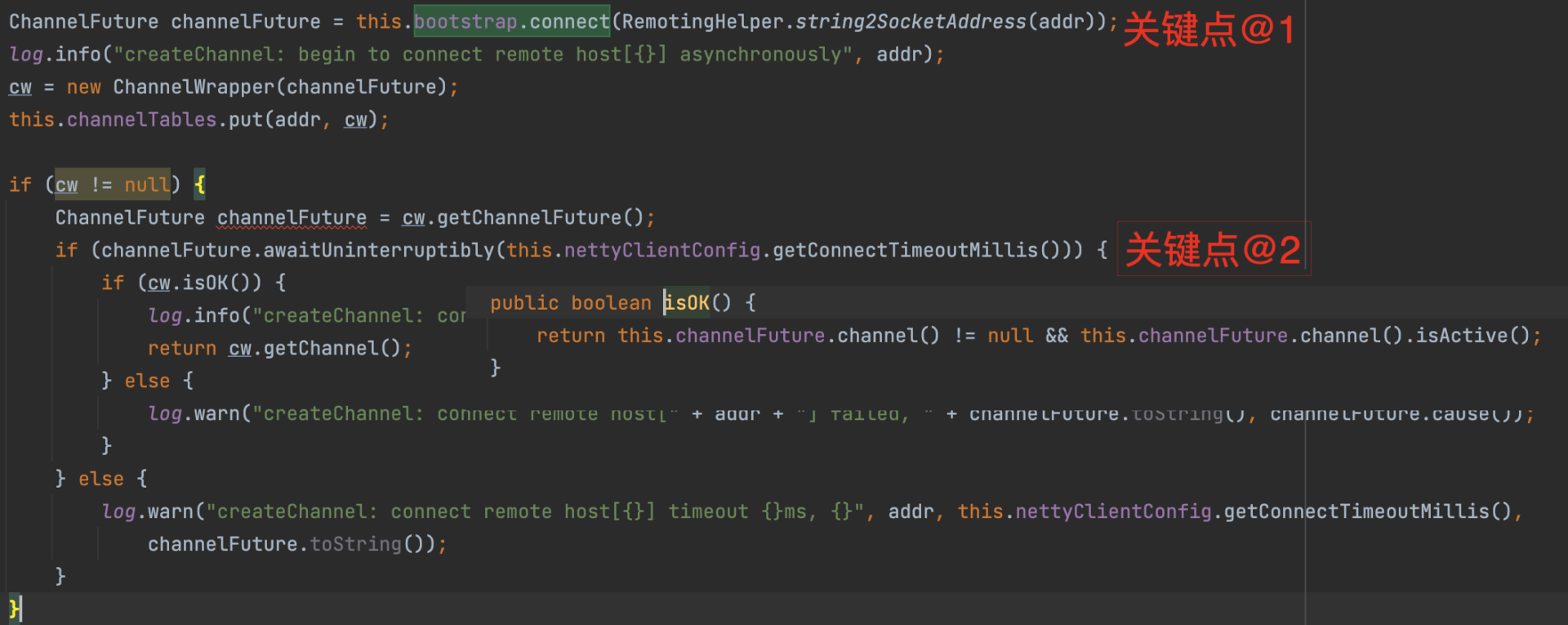
客户端通过调用Bootstrap的connect方法尝试与服务端建立连接,该方法会立即返回一个Future而无须等待连接建立,所以该方法调用结束后并不一定成功创建了连接。但是连接只有在创建成功之后才能被用来发送和读取数据,所以这里我们需要再调用Future对象的awaitUninterruptibly方法等待连接成功建立。
客户端与服务端建立连接后,就可以通过连接向服务端发送请求了:
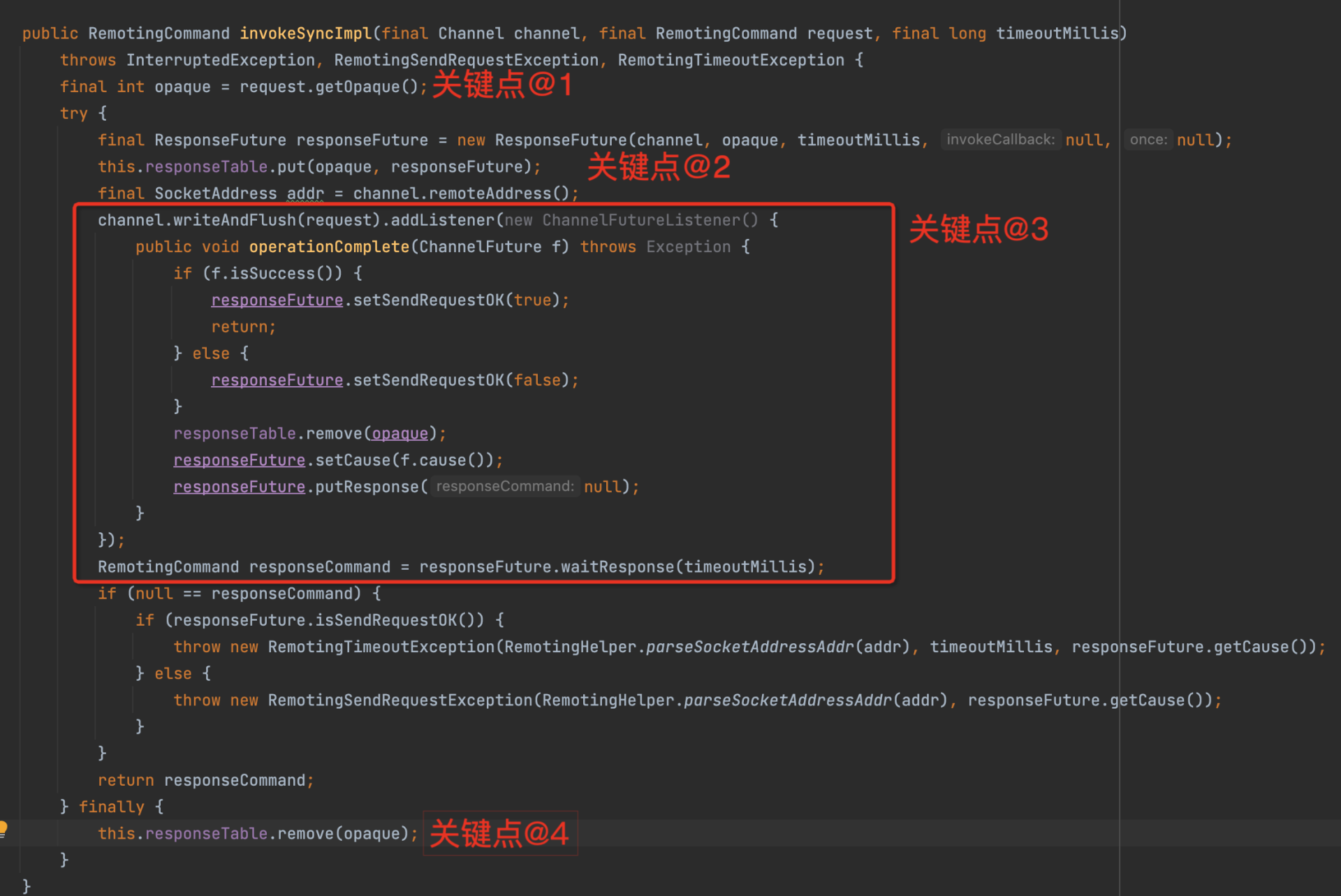
这里主要有四个实现要点。
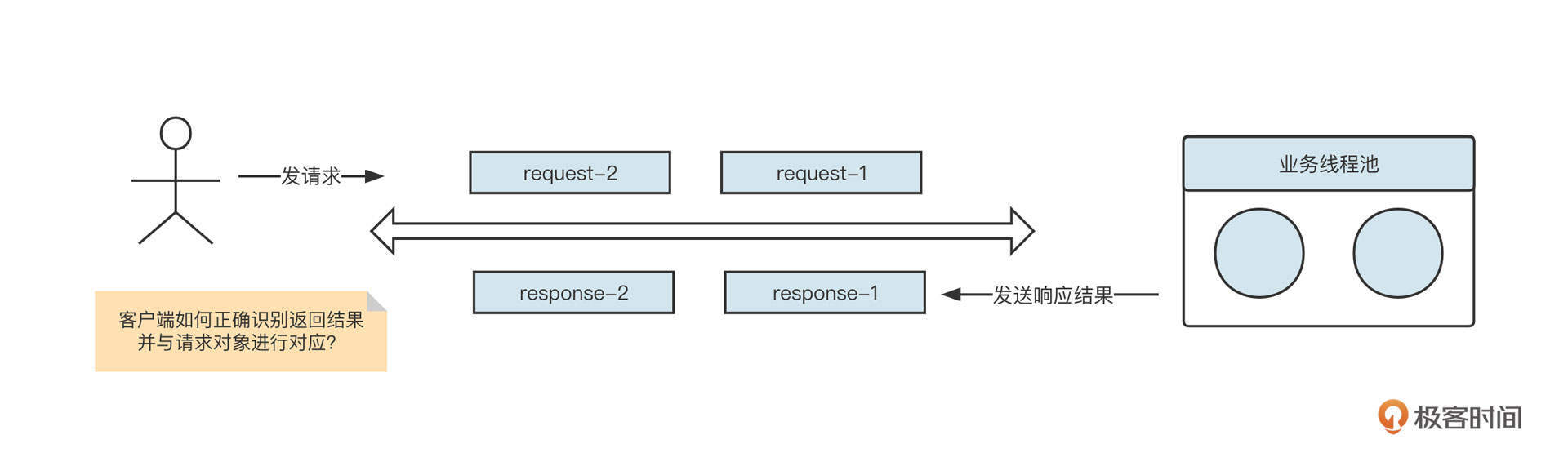
- 为每一个请求创建一个唯一的请求序号。也就是为每一个请求创建一个响应结果Future,并建立RequestId到响应结果的映射Map,这样在收到服务端响应结果时,就可以准确地知道具体是哪一个请求的结果了。这是多线程共同使用单一连接发送请求的核心要点。为了更进一步理解,你可以再看一下这张示意图:
- 通过调用Channel的writeAndFlush方法,将数据写入到网络中。也就是说,不需要在发送数据之前先注册写事件。然后基于Future模式添加事件监听器,在收到返回结构后,ResponseFuture中的状态会被更新。
- 同步发送的实现模板,通过调用ResponseFuture获取等待结果,如果使用异步发送模式,就在第三步执行用户定义的回调函数。
- 处理完一个请求后,删除requestId-ResponseFuture的映射关系。
介绍完客户端编程范例后,接下来我们看一下如何使用Netty编写服务端程序。
首先,创建相关线程组,代码片段如下:
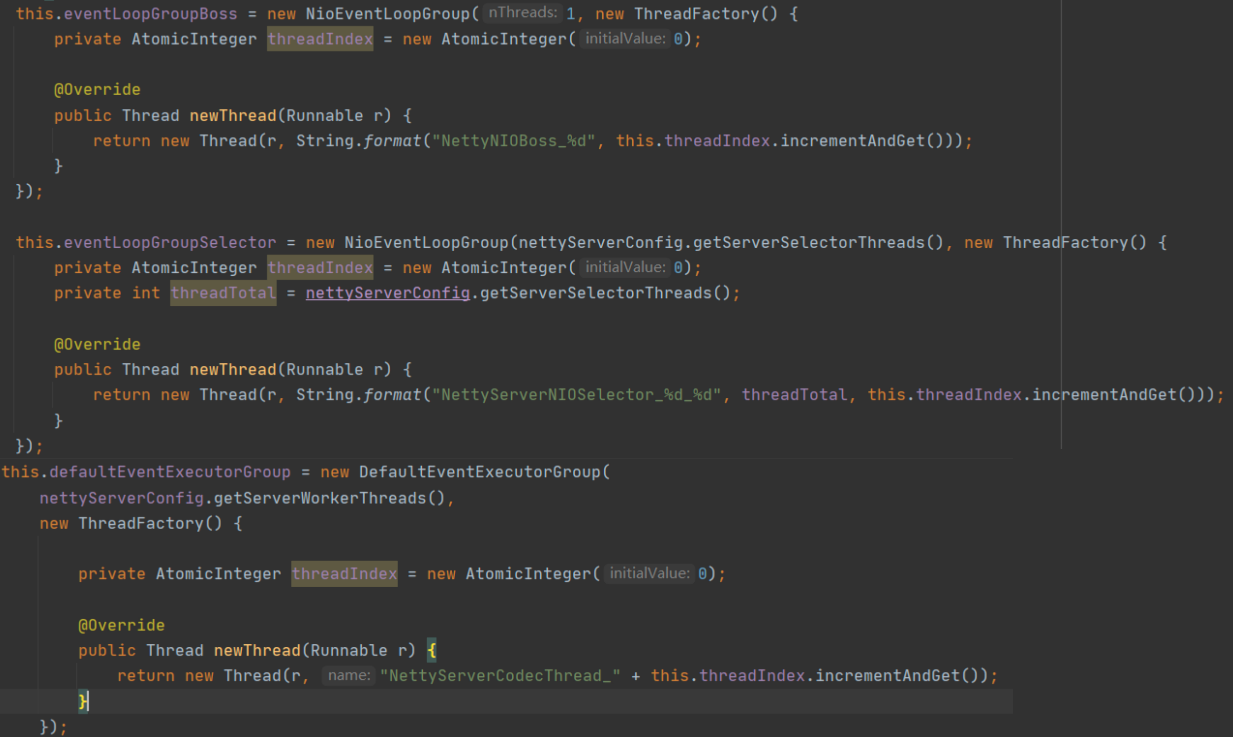
这里分别创建了3个线程组。
- eventLoopGroupBoss线程组,默认使用1个线程,对应Netty线程模型中的主Reactor。
- eventLoopGroupSelector线程组,对应Netty线程模型中的从Reactor组,俗称IO线程池。
- defaultEventExecutorGroup线程组,在Netty中,可以为编解码等事件处理器单独指定一个线程池,从而使IO线程只负责数据的读取与写入。
下一步,使用Netty提供的ServerBootstrap对象创建Netty服务端,示例代码如下所示:
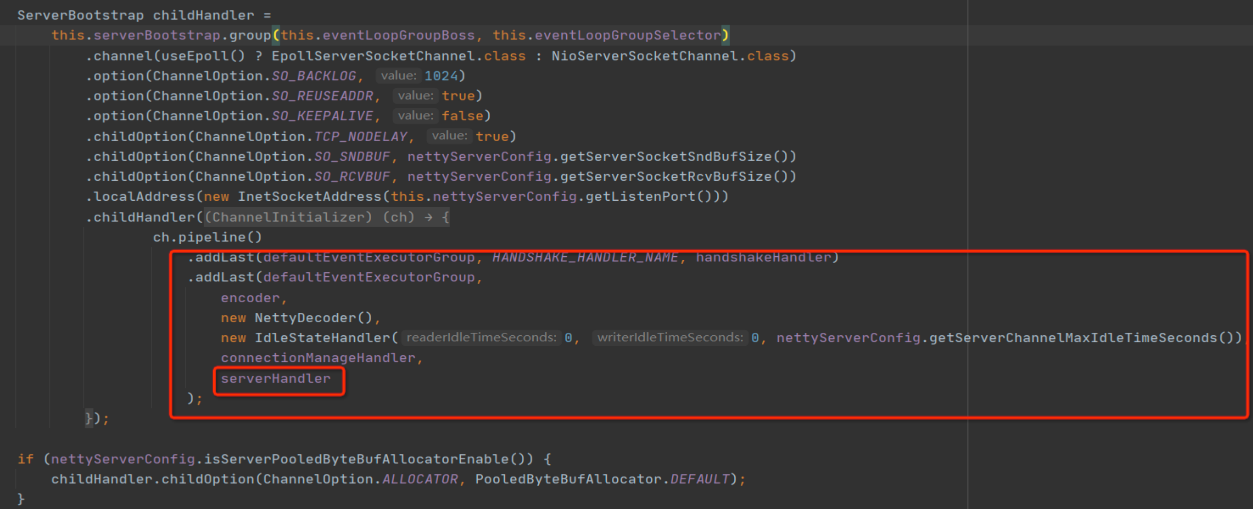
上面的代码基本都是模版代码,少数不同点就是需要自己实现编码器、解码器和业务处理Handler。其中,编码器、解码器其实就是实现通信协议,而ServerHandler就是服务端业务处理器。
再下一步,服务端在指定接口建立监听,等待客户端连接:
ServerBootstrap的bind方法是一个非阻塞方法,调用sync()方法会变成阻塞方法,它需要等待服务端启动完成。
最后一步就是编写服务端业务处理Handler了:
服务端处理器需要接收客户端请求,所以通常需要实现channelRead事件。通常业务Handler是在解码器之后执行,所以业务Handler中channelRead方法接收到的参数已经是通信协议中定义的具体模型,也就是请求对象了。后面就是根据该请求对象中的内容,执行对应的业务逻辑了。业务Handler会在defaultEventExecutorGroup线程组中执行,为了提高解码的性能,避免业务逻辑与IO操作相互影响,通常会将业务执行派发到业务线程池。
总结
好了,这节课就讲到这里。
这节课,我们从一个简单的RPC请求-响应模式说起,串起了网络编程中编码、网络写、网络传输、网络读取、解码、业务逻辑执行等步骤,并引出了网络粘包问题,最终通过制定通信协议解决了粘包问题。
通信协议看似是一个非常高大上的名词,它其实是一种发送端和接收端共同制定的通信格式。我在这里介绍了一种通用的设计方法:Header(请求头) + Body(消息体)的经典设计方法。
接下来,我们还讲解了Netty的线程模型,也是主从多Reactor模型。但我们要知道业务Handler默认是在IO线程池中执行的,我们改变这种行为,让Handler在一个独立的线程池中执行,主要是为了提升IO线程的执行效率。
在讲解Netty读写流程之前,我给你提了下面几个问题。只有真正理解了这些问题,才能算是真正理解了NIO编程。在这里,我也给出我的答案,你可以对照思考一下。
- 如何处理连接半关闭?
在调用SocketChannel方法的read方法时,如果其返回值为-1,则表示对端已经关闭了连接,接受端也需要同样关闭连接,释放相关资源。
- 什么时候应该注册读事件?
接受端通常在创建好NioSocketChannel后就应该注册读事件。这样才能接受发送端的数据,如果服务端感觉到有压力时,可以暂时取消关注读事件,达到限流的效果。
- 写数据之前一定要先注册写事件吗?
写数据之前不需要注册写事件,写事件一般是底层NioSocketChannel的底层缓存区满了,无法再往网络中写入数据时,再注册通道的写事件,等待缓冲区空闲时通知应用程序继续将剩余数据写入到网络中。
在课程的最后,我们以消息中间件RocketMQ是如何使用Netty开发网络通信模块,进行Netty网络编程实战,做到理论与实践相结合。
Netty是一个庞大的体系,如果你想进一步提升高并发编程能力,我建议你体系化地学习一下它,我也非常推荐这本《Netty 源码分析与实战-网络通道篇》,希望可以让你在学习Netty的过程中少走一些弯路。
课后题
学完这节课,你应该已经掌握了NIO的读写处理过程,那我也给你留一道课后题。
请你尝试重构上节课的代码:实现一个简易的RPC Request-Response模型,确保这个模型支持同步请求、异步请求两种请求发送模式。
如果你想要分享你的代码想听听我的意见,可以提交一个 GitHub的push请求或issues,并把对应地址贴到留言里。我们下节课见!
09|技术选型:如何选择微服务框架和注册中心?
作者: 丁威

你好,我是丁威。
从这节课开始,我们正式进入微服务领域中间件的学习。我们会从微服务框架的诞生背景、服务注册中心的演变历程还有Dubbo微服务框架的实现原理出发,夯实基础。然后,我会结合自己在微服务领域的实践经验,详细介绍Dubbo网关的设计与落地方案,以及蓝绿发布的落地过程。
这节课,我们先从基础学起。
微服务框架的诞生背景
分布式架构体系是伴随着互联网的发展而发展的,它经历了单体应用和分布式应用两个阶段。记得我在2010年入职了一家经营传统行业的公司,公司主要负责政府采购和招投标系统的开发与维护工作,那是我第一次真正见识了庞大的单体应用架构的样子。
当时公司的架构体系是下面这个样子:
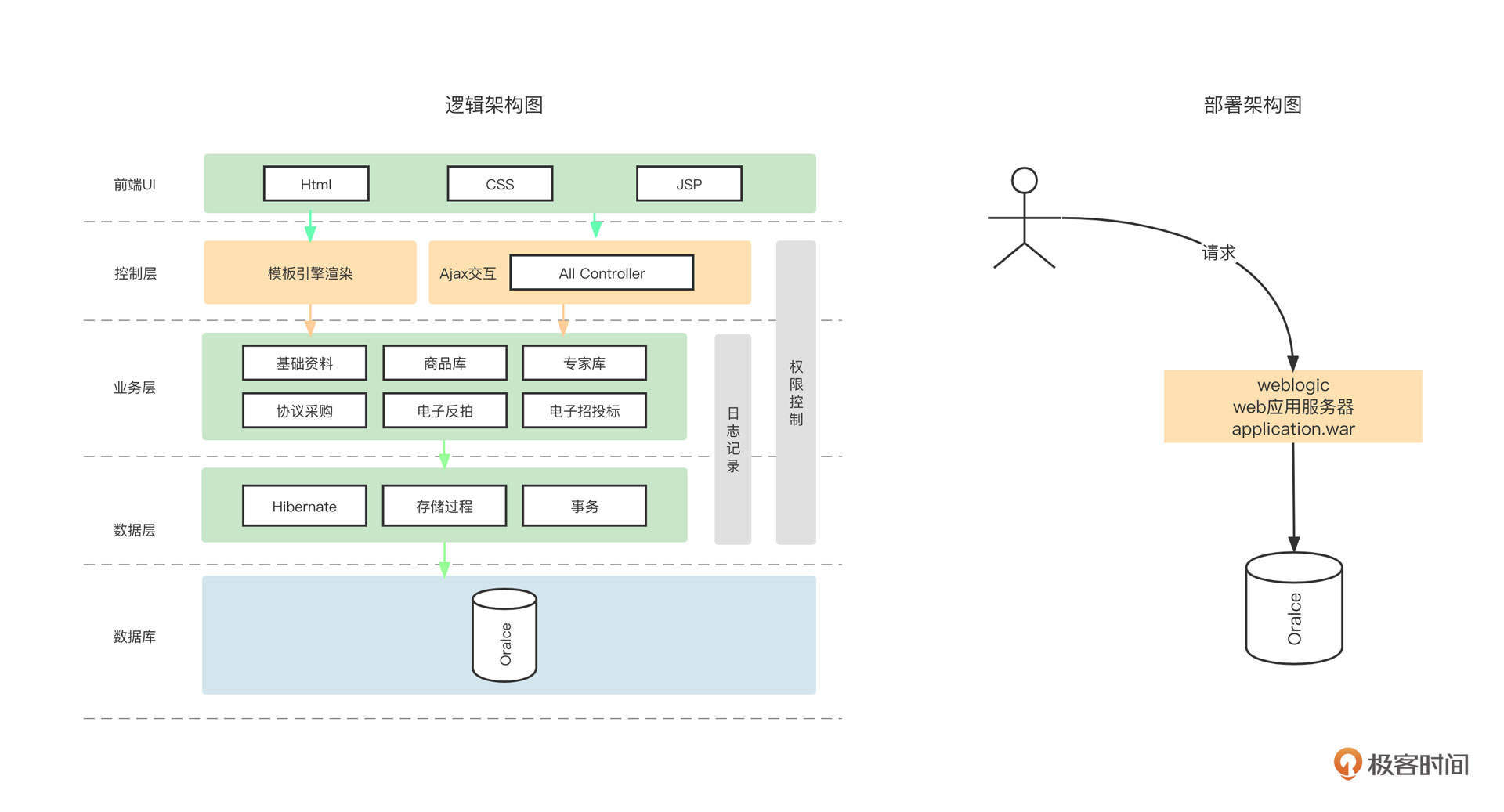
所有的业务组件、业务模块都耦合在一个工程里,最终部署的时候会打成一个统一的War包然后部署在一台Web容器中,所有的业务模块都访问同一个数据库。
在传统行业,这种架构的优势也很明显。因为部署结构单一,所以管理非常方便,而且一般情况下,政府采购等行为的流量变化不大,不会像互联网那样,随着平台的搭建造成业务体量的指数型增长。
我们设想一下,如果某一天国家发布政策,想要做一个全国的统一的政府采购平台,假设这家公司中标了,他们会怎么改造系统呢?通常的做法就是对系统进行拆分,单独部署和扩展各个子系统,拆分后的系统架构如下图所示:
由于单个子系统只部署一个节点已经无法满足要求了,所以他们需要部署多个进程,并且需要根据业务的体量进行动态的增加与减少,这样维护调用关系就会变得非常复杂而且容易出错。
在上面这张架构图中,基础资料子系统被其他所有模块调用,如果我们想要增加新的部署节点,或者由于一些机器老化需要更换设备,导致服务对应的IP地址发生变化,这时候应该怎么维护信息呢?
你可能会说这不就是负载均衡吗。我们可以通过Nginx来实现负载均衡,而调用方不需要维护调用者列表。它的架构是下面这样:
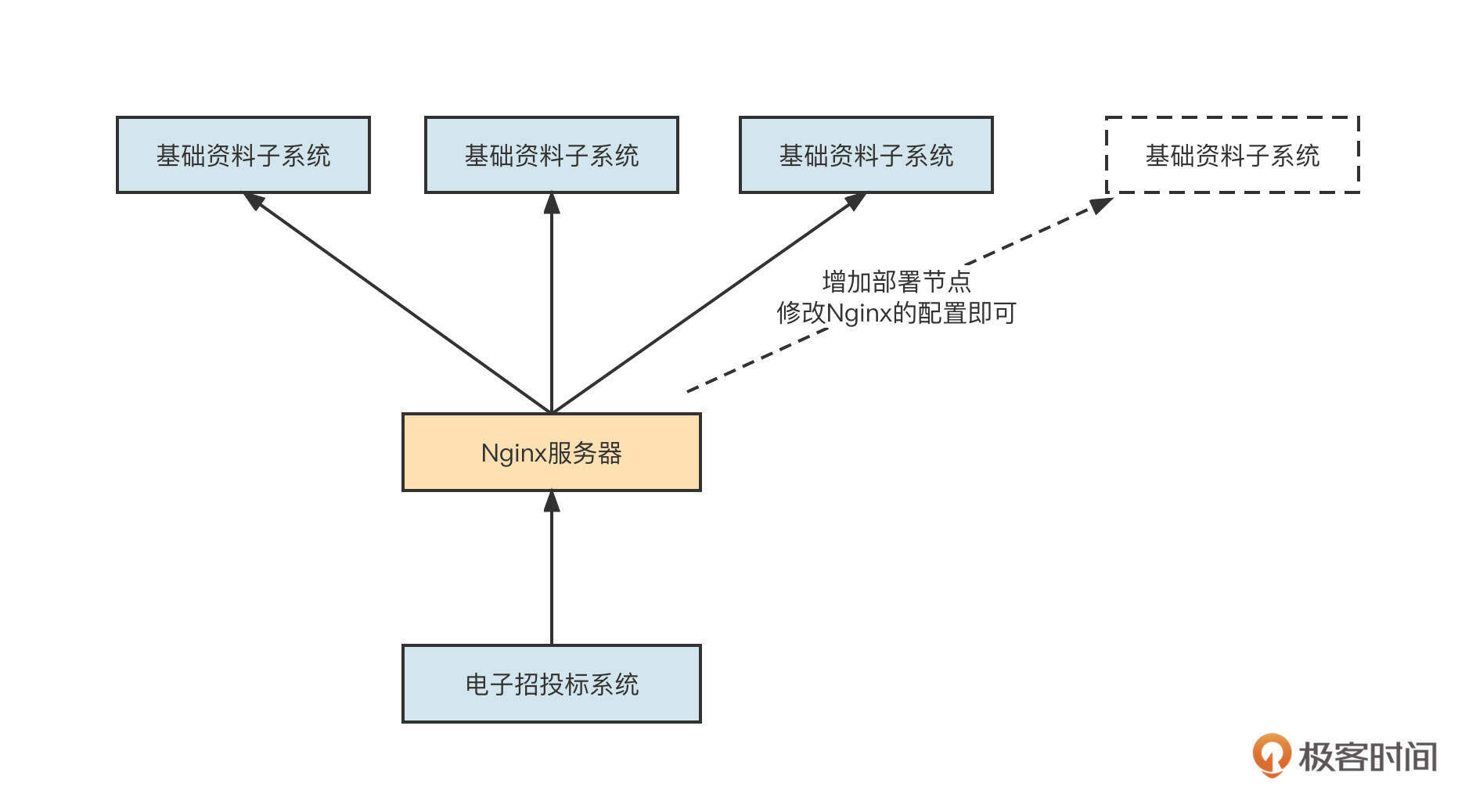
没错,通过引入Nginx可以实现负载均衡,并且在节点发生变化时,只需要修改Nginx的配置,不需要去修改调用方的代码。但是一旦部署了新的节点,我们还是需要手动在Nginx中添加路由信息,也就是说,这个操作只能是人工完成的。随着系统的膨胀,路由配置会变得越来越不可维护,容易出错甚至引发严重的故障。
这个问题代表着一系列与微服务相关的共性需求,如服务注册与自动发现机制、高性能RPC调用、服务治理等。
为了解决这些共性需求,很多微服务中间件如雨后春笋般涌现出来,其中要数Dubbo和Spring Cloud最为突出。
如何选择微服务框架?
Dubbo和Spring Cloud是什么?怎么在Dubbo和SpringCloud之间进行选择呢?
Dubbo是阿里巴巴开源的优秀的微服务框架,它开源之后迅速成为了互联网程序员们的首选微服务框架,我认为Dubbo有下面几个核心优势。
- 易用性
微服务框架通常包含服务注册与自动发现、高性能的RPC远程调用、服务治理等众多复杂的功能需求,框架内部非常复杂。但用户操作这种框架却非常简单,不需要太多专业知识,仅仅是通过Dubbo提供的dubbo:service、dubbo:reference、dubbo:registry等几个配置命令就可以轻松构建自己的微服务体系。
而且,这些配置命令拥有众多配置参数(涵盖服务发现、服务治理、性能调优等维度),而且都根据经验提供了默认值,用户几乎不需要对任何参数进行调优,就能保证项目的稳定运行。
- 可扩展机制
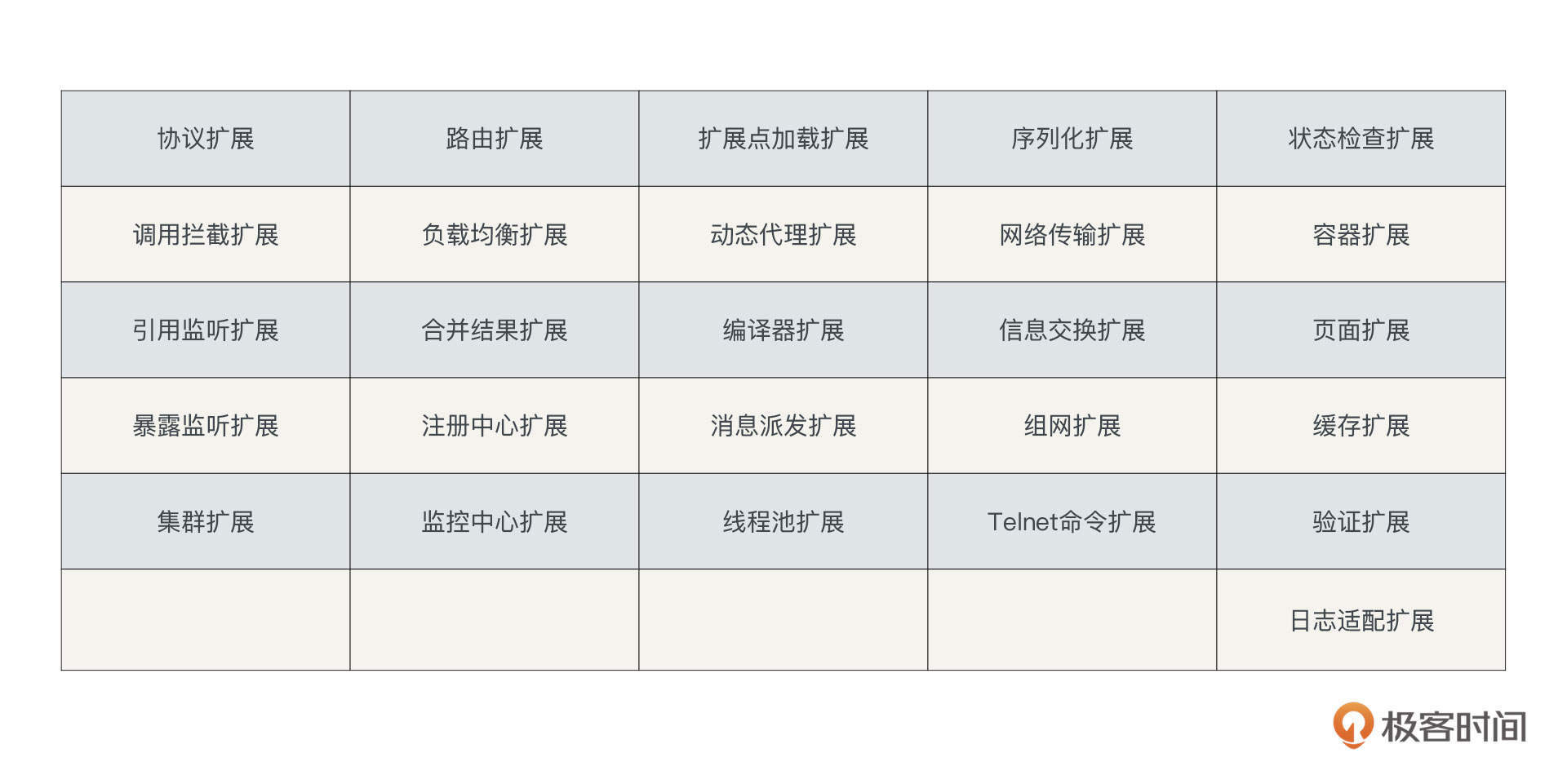
Dubbo通过SPI提供了高度灵活的扩展机制,Dubbo内部几乎所有的核心特性都提供了扩展点,Dubbo官方文档中给出的SPI扩展点有下面这些:
- 高性能
Dubbo RPC协议运行在传输层,并基于TCP协议实现了私有协议栈,支持多种序列化协议,包含protocuf、kryo等高性能序列化协议。
Dubbo的易用性、可扩展机制和高性能让它在一段时间内备受拥护,但也许是Dubbo发展得已经非常成熟了,又或者是阿里巴巴在部署其他的战略,Dubbo竟然“断更了”。我们知道持续迭代、持续创新是开源项目的生命源泉,停止更新的Dubbo也就无法继续高歌猛进了。这也给了其他微服务框架更多的生存空间,SpringCloud技术栈就在这个时候崛起了。
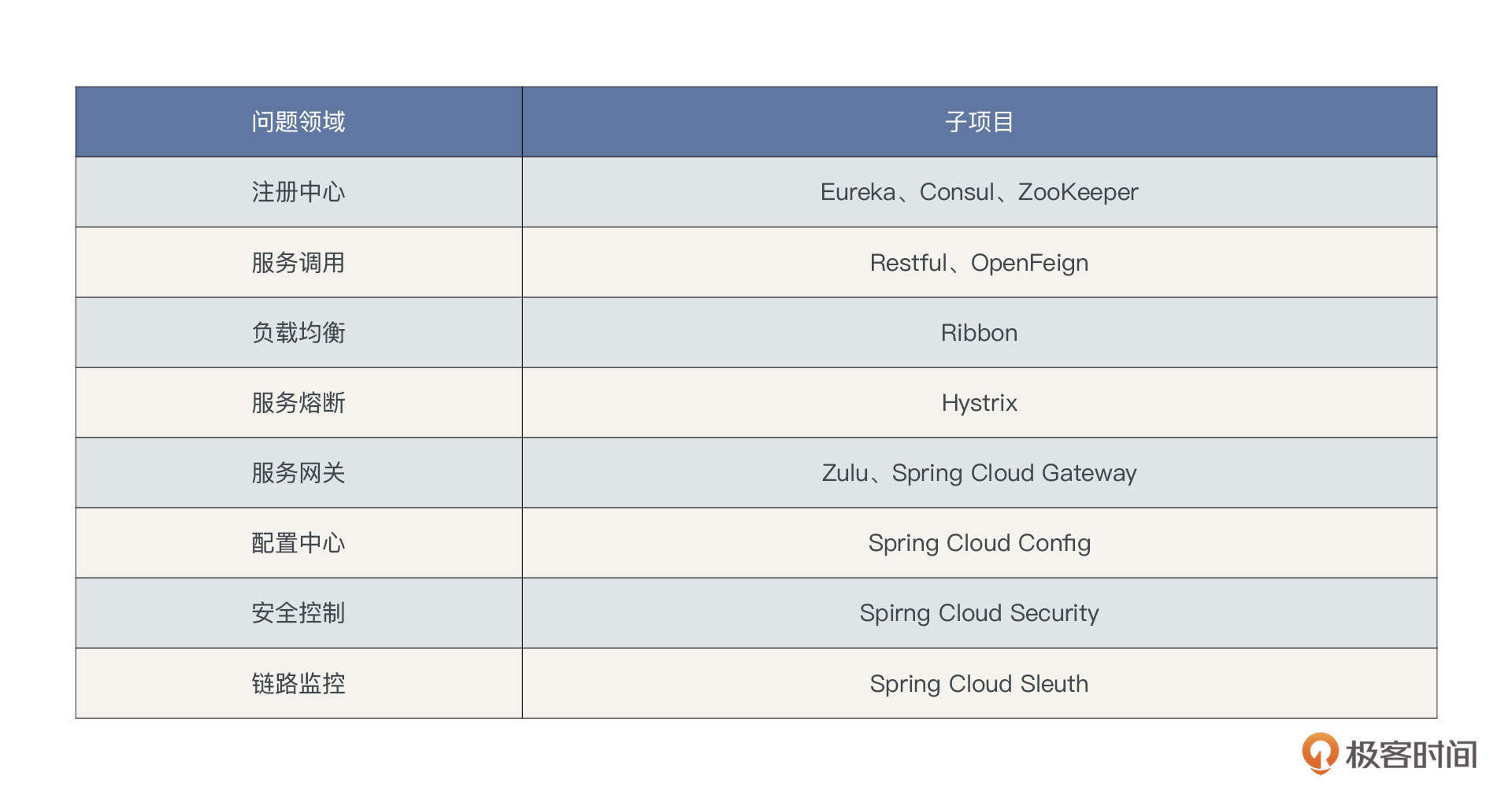
Spring Cloud技术栈由各个不同的子项目构成,每一个项目解决微服务架构领域的一个问题,我把SpringCloud和微服务架构相关的技术组件列了个表格:
SpringCloud技术栈和Dubbo都是非常优秀的微服务框架,并且随着互联网分布式架构正式拥抱云原生,Dubbo也顺应云原生发展浪潮,重新开始维护。那这两个框架我们该如何选择呢?
技术选项要考虑框架本身的特性,同时也需要结合公司的技术栈、使用的开发语言等因素综合考虑,这节课我们重点从框架本身这个维度来考量,也会顺便提一提如何结合公司自身的情况去进行选型。
从功能的丰富程度上讲,SpringCloud体系更占优势,但并不是说使用Dubbo来构建微服务体系就无法实现链路监控、服务网关这些功能。Dubbo的设计理念是职责分明,链路跟踪功能完全可以选择业界主流的链路跟踪开源项目,所以从功能维度我也给你列了一张表格,分别对比了用Spring Cloud和Dubbo搭建的微服务架构体系采用的技术栈:
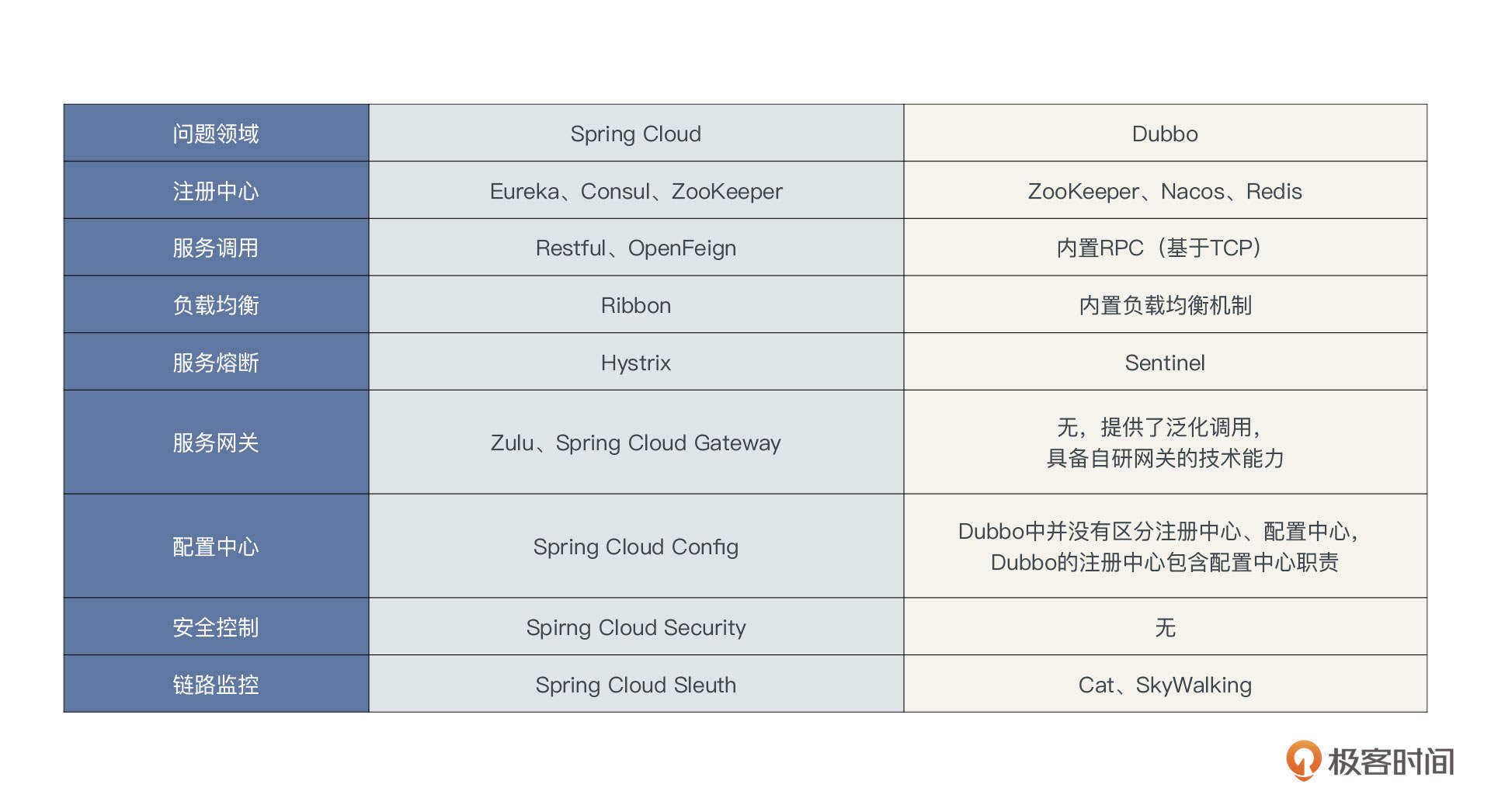
从表格中我们也能看出,在微服务架构必备的注册中心、服务调用、负载均衡、熔断等基础功能上,Dubbo都是内置的,不需要用户关注太多技术细节,而Spring Cloud需要单独进行学习,入门成本偏高。
Dubbo的设计理念是提供对应的扩展点,供用户根据需要自行扩展。而Spring Cloud中各个技术组件都是单独发展的,最终SpringBoot体系将第三方的开源项目进行了整合,省去了用户的整合成本。
从性能的角度,Dubbo要明显优于SpringCloud。
Spring Cloud的RPC调用是基于HTTP协议开发的,它处于网络模型的应用层,而Dubbo的RPC调用的底层是TCP协议,它处于网络模型的传输层。所以说,在底层网络通讯方面,Dubbo就天然地占据了优势。
由于Dubbo是基于TCP编程的,这就比直接使用HTTP进行数据传输具有更大的灵活度。直接基于TCP网络进行编程,对网络通讯中各个环节可以灵活进行定制化开发,例如Dubbo在序列化、反序列化、IO线程、业务线程等方面的设置具有高度配置化,性能的提升非常明显,而Spring Cloud在这方面显得就有些吃力了。阿里、腾讯、美团、拼多多等一线互联网企业的微服务框架都是基于TCP来构建的。
Dubbo、SpringCloud都是主流的微服务,你可以根据实际情况加以选择。不过,结合目前我所处的行业和公司的技术栈,我倾向于采用Dubbo来构建微服务架构体系。
如何选择微服务注册中心?
在这节课的最后,我想结合生产中遇到的一个故障,和你聊聊注册中心的选型问题。
在微服务架构体系相当长的一段发展时间里,ZooKeeper都占领着微服务注册中心的头把交椅,几乎成为注册中心唯一的选择。这是为什么呢?接下来我们就重点解读一下ZooKeeper的CP设计理念。下节课,我们还会对微服务注册中心的设计理念做详细介绍。
ZooKeeper是一个分布式协调组件,符合CAP分布式理论中的CP。
CAP理论指的是,在一个分布式集群中存储同一份数据,无法同时实现C(一致性)、A(可用性)和P(持久性),只能同时满足其中两个。由于P在数据存储领域是必须要满足的,所以通常需要在C与A之间做权衡。ZooKeeper是保住了一致性和持久性,选择性地牺牲了可用性。
ZooKeeper的数据写入流程如下:
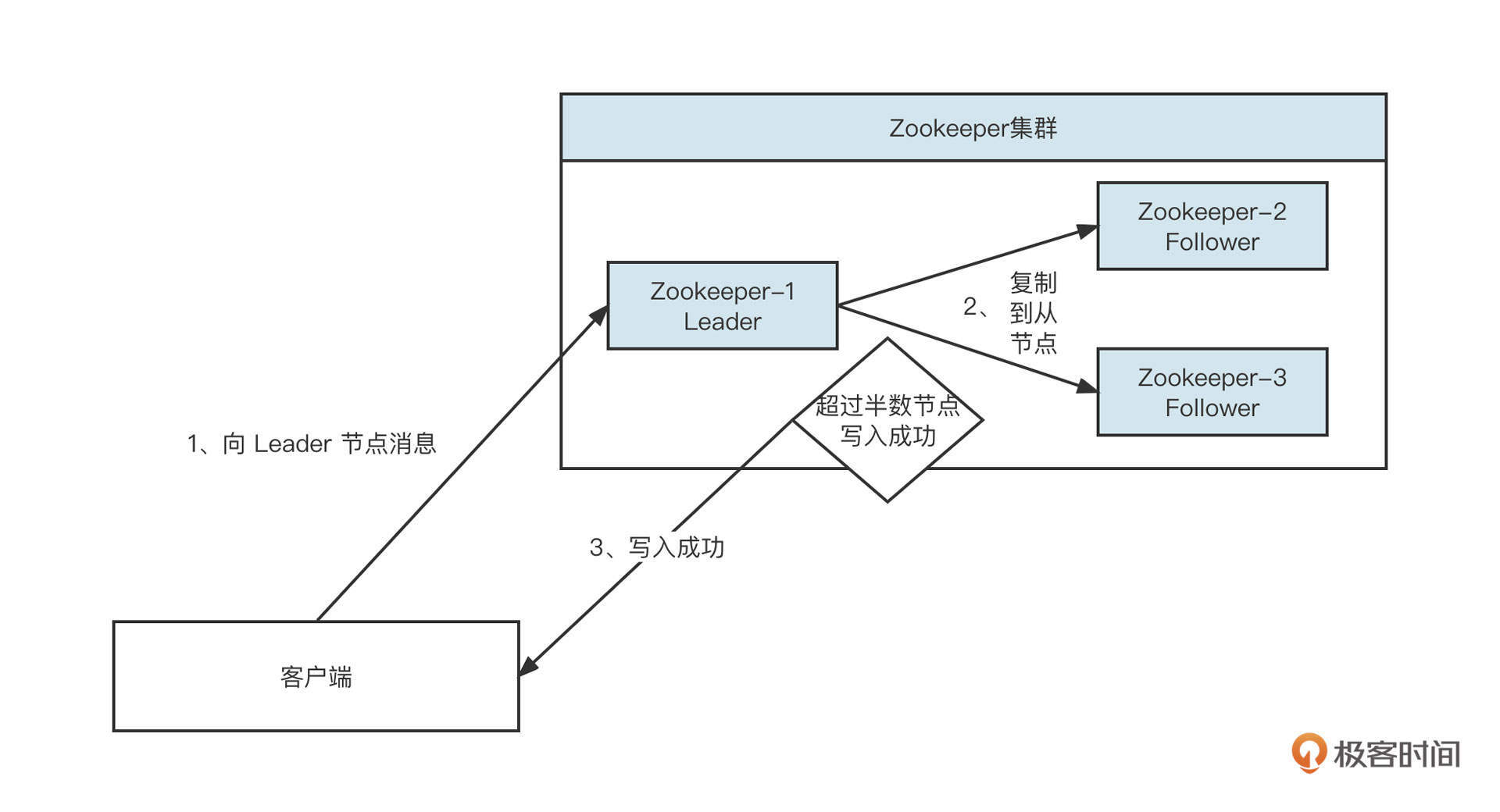
在ZooKeeper集群中,首先会进行Leader选举,根据ZAB协议选举出一个Leader节点用来处理写请求,然后将数据复制给从节点:
- 当集群内超过半数节点写入成功,则返回“数据写入成功”;
- 如果集群内还没有成功选举出Leader,则ZooKeeper集群无法向外提供数据写入与读取服务。
在Leader选举期间,集群是不可用的(牺牲了可用性)。但在正常生产实践过程中,ZooKeeper集群内部选举Leader节点的耗时在毫秒级别,并不会影响使用。然而,一旦遇到异常情况就很难说了。
我在生产过程中就出现了由于ZooKeeper集群内存溢出导致频繁Full GC的情况。当时的情况是,公司内部的Dubbo专用ZooKeeper地址被业务方用做分布式锁,但他们在使用过程中频繁创建节点,加上遇到Bug,节点数据没有及时删除,这就导致占用的内存越来越大,最终频繁Full GC,使得ZooKeeper会话超时,所有注册在ZooKeeper注册中心的服务全部被删除,所有客户端服务调用都出现“No Provider”警告,酿成一场严重的生产级故障。
经过这次故障,我也开始重新审视ZooKeeper和CP模式的合理性。注册中心是微服务体系的大脑,一旦出现问题会带来不可估量的损失,其可用性尤为重要。
也正是因为CP模型存在严重的可用性问题,以AP为设计思想的注册中心开始逐渐涌现出来。AP的核心指导思想是容忍分布式集群中多个节点之间的数据短暂不一致,但最终能达到一致性。EureKa就是典型的基于AP的注册中心。
由于基于AP的注册中心不需要保证强一致性,所以集群内节点的地位通常都是平等的。客户端在同一时间与集群中一个节点保持长连接,当出现错误后,客户端再从注册中心集群中选择另外一个节点,并且客户端可以向集群中任何一个节点写入数据后立即返回“写入成功”,然后让数据异步在集群内部复制,最终实现数据的一致性。EureKa集群的写入流程如下:
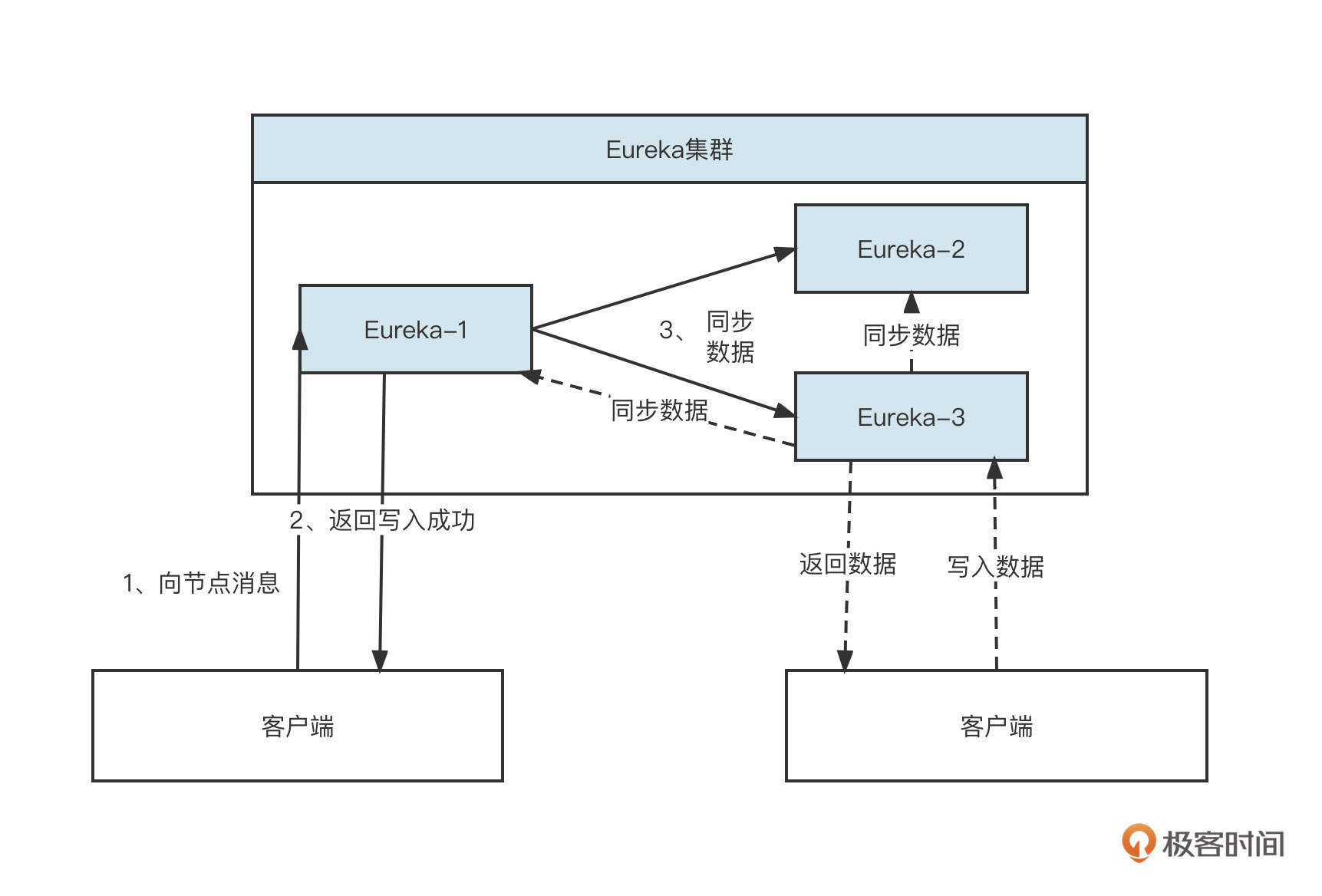
由于集群内部节点的地位是平等的,客户端在其中一个节点不可用时,可以快速切换到另外的节点,这样可用性就得到了保障。那么问题来了,节点之间路由信息不一致会带来什么问题呢?这些问题我们可不可以接受?
在回答这个问题之前我们不妨来看看一个注册中心各个节点数据不一致的例子,如下所示:
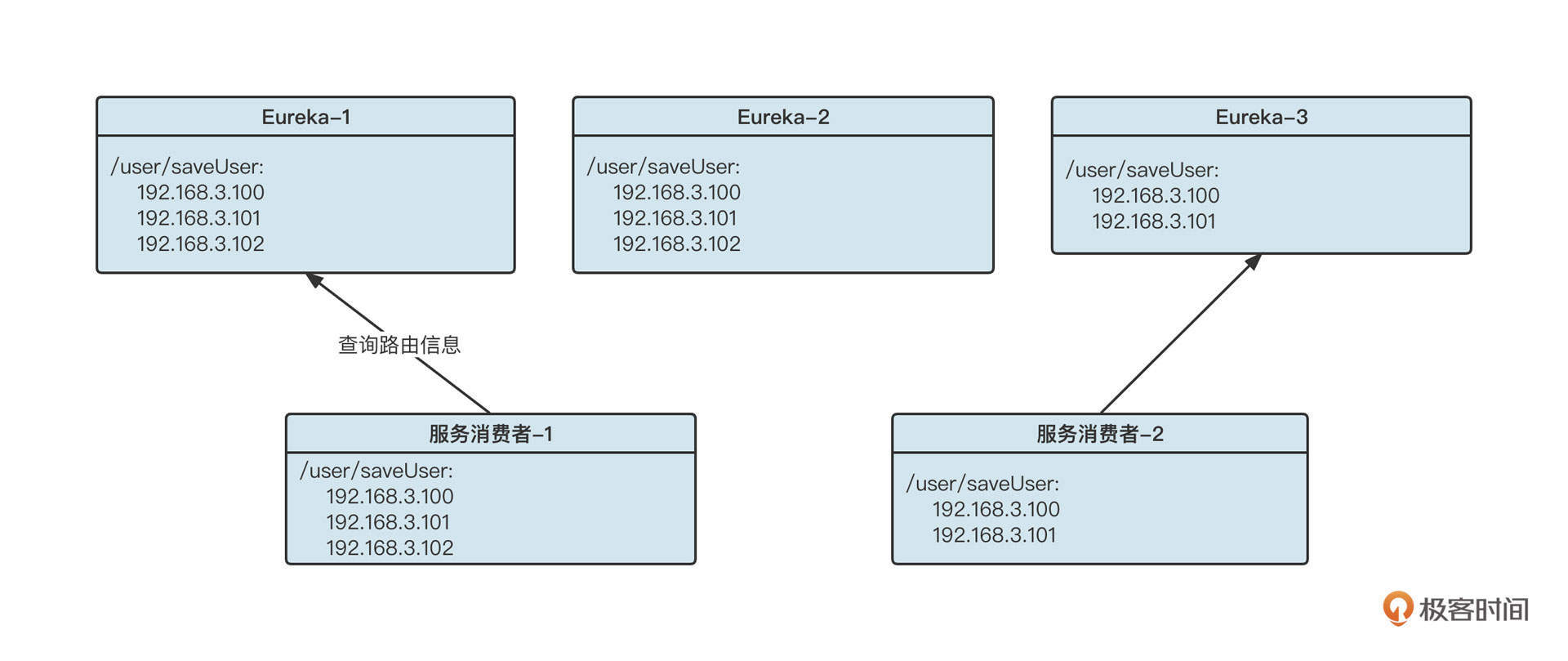
在这里,由于某种异常,Eureka集群中各个节点存储的数据并不一致,在节点1和2中关于/user/saveUser接口有三个服务提供者,但在节点3中只有两个服务提供者。但无论是三个服务提供者也好,还是两个服务提供者也好,都会造成负载不均衡,如果节点出现类似Full GC的问题,节点无法对外提供服务,这时候客户端会从集群中选择其他节点重试,并不会对系统带来致命影响。
综合来看,服务注册中心这种场景,AP模式显然比CP模式更佳。这也是为什么现在很多原先使用CP模式的注册中心都开始尝试向AP转化,而像Eureka、Nacos这种注册中心基本都同时提供了AP和CP两种工作模式,用户可以按照场景进行选择。
总结
好了,这节课就讲到这里。这节课我们主要从微服务框架诞生背景、微服务框架选型和注册中心框架的演变三个方面介绍了微服务。
微服务框架的基本诉求主要包括:服务注册与自动发现机制、高性能RPC调用和服务治理,它致力于让分布式架构中的服务治理变得简单高效。
我们还分析了市面上两种最主流的微服务研发框架:Dubbo和Spring Cloud,Dubbo具有易用性、灵活的扩展机制和更好的性能,Spring Cloud则具有更加丰富的功能。你可以根据实际情况加以选择,结合目前我所处的行业,公司的技术栈,我倾向于采用Dubbo来构建微服务架构体系。
最后,我还结合自己在实践过程中发生的一起故障,介绍了注册中心从CP向AP架构演进的原因。总的来说,以Eureka和Nacos为代表的注册中心,正在逐渐取代采用CP模式的ZooKeeper,成为注册中心的优先选项。
思考题
最后,我也给你留一道思考题。
我们刚才讲了一个我在生产实践中经历的一次事故。基于Zookeeper搭建的Dubbo服务注册中心,由于ZooKeeper节点的内存使用不当导致频繁触发Full GC,最终导致ZooKeeper会话超时,在注册中心的服务提供者会全部被删除,所有的消费者调用都感知不到服务提供者,进而导致服务调用雪崩。这时候我们应该怎么做呢?难道要重启所有服务提供者,让他们重新注册吗?你有什么快速恢复的方法?
欢迎你在评论区留下自己的看法,我们下节课见!
10|设计原理:Dubbo核心设计原理剖析
作者: 丁威

你好,我是丁威。
这节课,我们来剖析一下Dubbo中一些重要的设计理念。这些设计理念非常重要,在接下来的11和12讲Dubbo案例中也都会用到,所以希望你能跟上我的节奏,好好吸收这些知识。
微服务架构体系包含的技术要点很多,我们这节课没法覆盖Dubbo的所有设计理念,但我会带着你梳理Dubbo设计理念的整体脉络,把生产实践过程中会频繁用到的底层原理讲透,让你轻松驾驭Dubbo微服务。
我们这节课的主要内容包括服务注册与动态发现、服务调用、网络通信模型、高度灵活的扩展机制和泛化调用五个部分。
服务注册与动态发现
我们首先来看一下Dubbo的服务注册与动态发现机制。
Dubbo的服务注册与发现机制如下图所示:
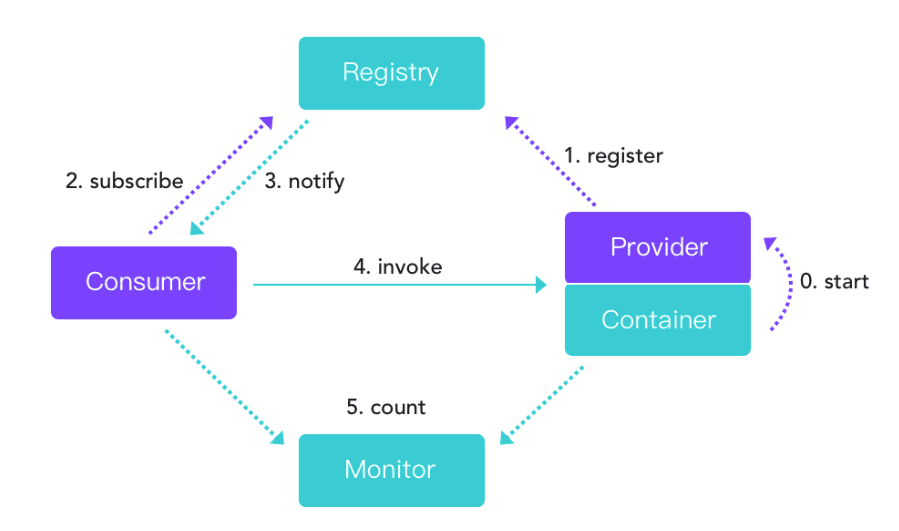
Dubbo中主要包括四类角色,它们分别是注册中心(Registry)、服务调用者&消费端(Consumer)、服务提供者(Provider)和监控中心(Monitor)。
在实现服务注册与发现时,有三个要点。
- 服务提供者(Provider)在启动的时候在注册中心(Register)注册服务,注册中心(Registry)会存储服务提供者的相关信息。
- 服务调用者(Consumer)在启动的时候向注册中心订阅指定服务,注册中心将以某种机制(推或拉)告知消费端服务提供者列表。
- 当服务提供者数量变化(服务提供者扩容、缩容、宕机等因素)时,注册中心需要以某种方式(推或拉)告知消费端,以便消费端进行正常的负载均衡。
Dubbo官方提供了多种注册中心,我们选择使用最为普遍的ZooKeeper进一步理解注册中心的原理。
我们先来看一下Zookeeper注册中心中的数据存储目录结构。

可以看到,它的目录组织结构为 /dubbo/{ServiceName},其中,ServiceName表示一个具体的服务,通常用包名+类名表示,在每一个服务名下又会创建四个目录,它们分别是:
- providers,服务提供者列表;
- consumers,消费者列表;
- routers,路由规则列表(一个服务可以设置多个路由规则);
- configurators,动态配置条目。
要说明的是,在Dubbo中,我们可以在不重启消费者、服务提供者的前提下动态修改服务提供者、服务消费者的配置,配置信息发生变化后会存储在configurators子节点中。此时,服务提供者、消费者会动态监听配置信息的变化,变化一旦发生就使用最新的配置重构服务提供者和服务消费者。
基于Zookeeper注册中心的服务注册与发现有下面三个实现细节。
- 服务提供者启动时会向注册中心进行注册,具体是在对应服务的providers目录下增加一条记录(临时节点),记录服务提供者的IP、端口等信息。同时服务提供者会监听configurators节点的变化。
- 服务消费者在启动时会向注册中心订阅服务,具体是在对应服务的consumers目录下增加一条记录(临时节点),记录消费者的IP、端口等信息,同时监听 configurators、routers 目录的变化,所谓的监听就是利用ZooKeeper提供的watch机制。
- 当有新的服务提供者上线后, providers 目录会增加一条记录,注册中心会将最新的服务提供者列表推送给服务调用方(消费端),这样消费者可以立刻收到通知,知道服务提供者的列表产生了变化。如果一个服务提供者宕机,因为它是临时节点,所以ZooKeeper会把这个节点移除,同样会触发事件,消费端一样能得知最新的服务提供者列表,从而实现路由的动态注册与发现。
服务调用
接下来我们再来看看服务调用。Dubbo的服务调用设计十分优雅,其实现原理图如下:
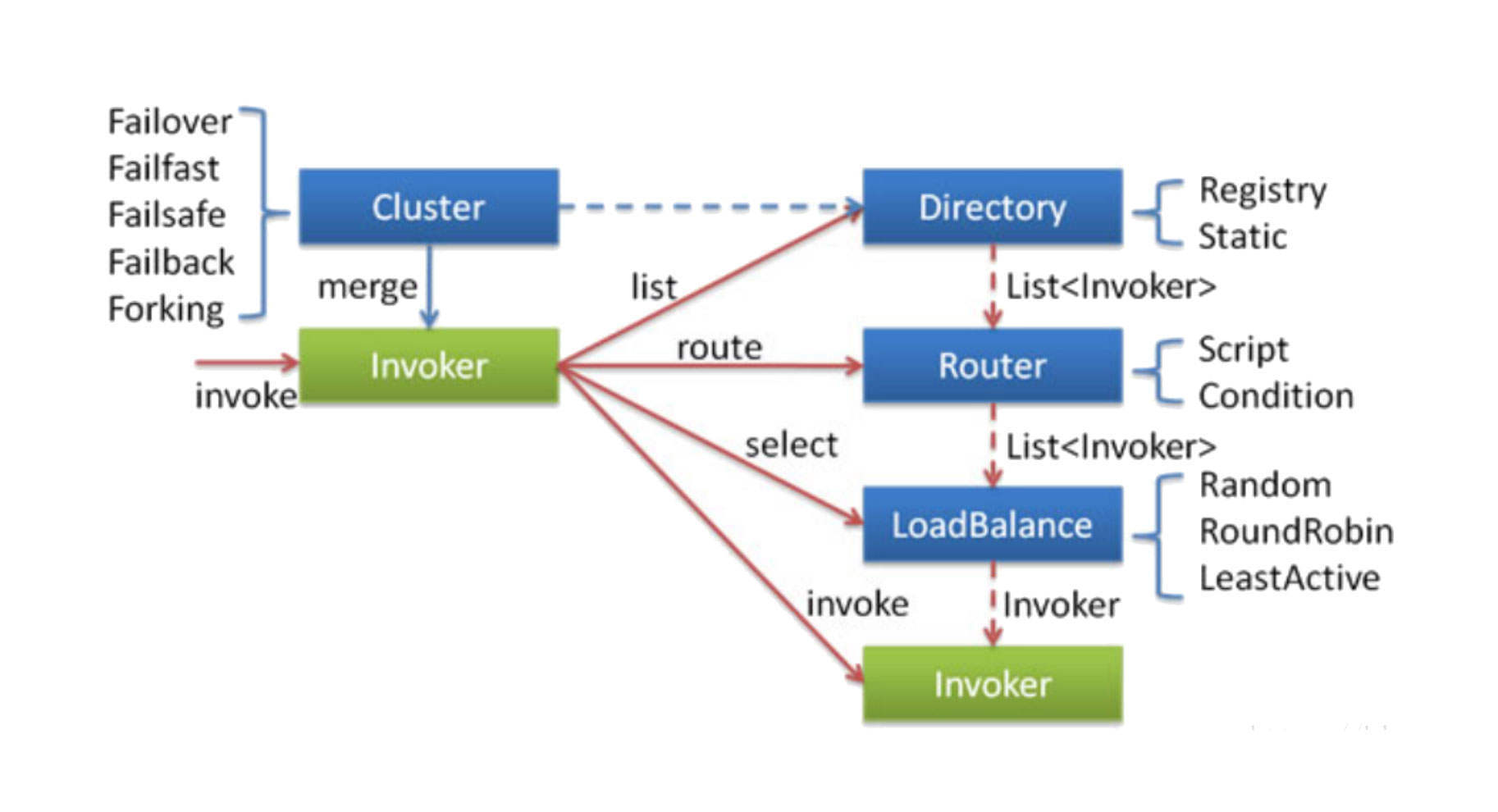
服务调用重点阐述的是客户端发起一个RPC服务调用时的所有实现细节,它包括服务发现、故障转移、路由转发、负载均衡等方面,是Dubbo实现灰度发布、多环境隔离的理论指导。
刚才,我们已经就服务发现做了详细介绍,接下来我们重点关注负载均衡、路由、故障转移这几个方面。
客户端通过服务发现机制,能动态发现当前存活的服务提供者列表,接下来要考虑的就是如何从服务提供者列表中选择一个服务提供者发起调用,这就是所谓的负载均衡(LoadBalance)。
Dubbo默认提供了随机、加权随机、最少活跃连接、一致性Hash等负载均衡算法。
值得注意的是,Dubbo不仅提供了负载均衡机制,还提供了智能路由机制,这是实现Dubbo灰度发布的重要理论基础。
所谓路由机制,是指设置一定的规则对服务提供者列表进行过滤。负载均衡时,只在经过了路由机制的服务提供者列表中进行选择。为了更好地理解路由机制的工作原理,你可以看看下面这张示意图:
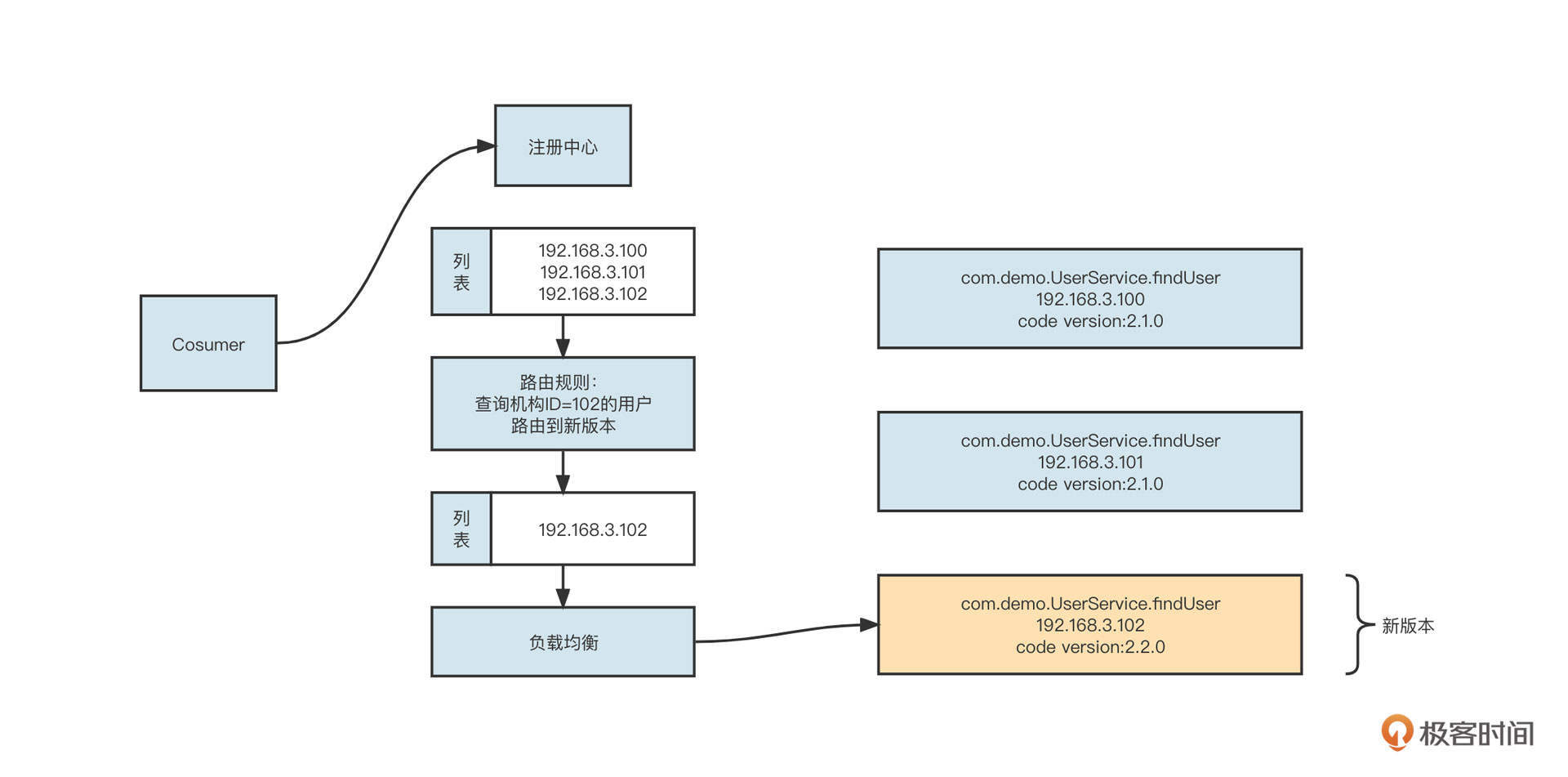
我们为查找用户信息服务设置了一条路由规则,即“查询机构ID为102的查询用户请求信息将被发送到新版本(192.168.3.102)上。具体的做法是,在进行负载均衡之前先执行路由选择,按照路由规则对原始的服务提供者列表进行过滤,从中挑选出符合要求的提供者列表,然后再进行负载均衡。
接下来,客户端就要向服务提供者发起RPC请求调用了。远程服务调用通常涉及到网络等因素,因此并不能保证100%成功,当调用失败时应该采用什么策略呢?
Dubbo提供了下面五种策略:
- failover,失败后选择另外一台服务提供者进行重试,重试次数可配置,通常适合实现幂等服务的场景;
- failfast,快速失败,失败后立即返回错误;
- failsafe,调用失败后打印错误日志,返回成功,通常用于记录审计日志等场景;
- failback,调用失败后,返回成功,但会在后台定时无限次重试,重启后不再重试;
- forking,并发调用,收到第一个响应结果后返回给客户端。通常适合实时性要求比较高的场景。但这一策略浪费服务器资源,通常可以通过forks参数设置并发调用度。
如果将服务调用落到底层,就不得不说说网络通信模型了,这部分包含了很多性能调优手段。
网络通信模型
我们先看看Dubbo的网络通信模型,如下图所示:
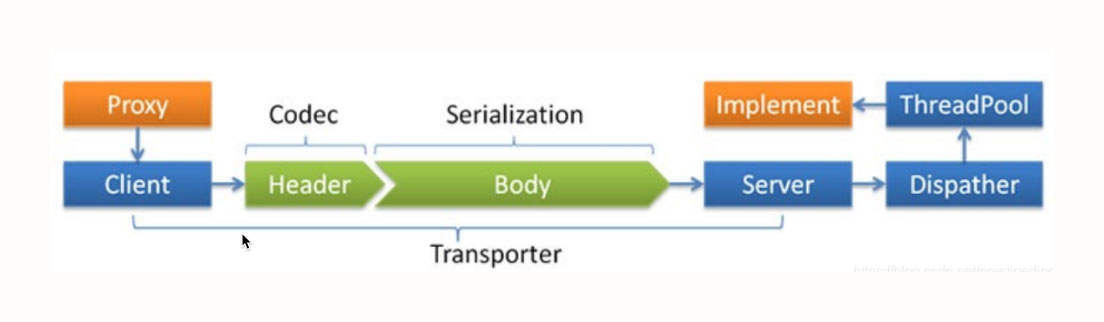
Dubbo的网络通信模型主要包括网络通信协议和线程派发机制(Dispatcher)两部分。
网络传输通常需要自定义通信协议,我们常用的协议设计方式是 Header + Body,其中Header 长度固定,包含一个长度字段,用于记录整个协议包的大小。
同时,为了提高传输效率,我们一般会对传输数据也就是Body的内容进行序列化与压缩处理。
Dubbo支持目前支持 java、compactedjava、nativejava、fastjson、fst、hessian2、kryo等序列化协议,生产环境默认为hessian2。
网络通信模型的另一部分是线程派发机制。Dubbo中会默认创建200个线程处理业务,这时候就需要线程派发机制来指导IO线程与业务线程如何分工。
Dubbo提供了下面几种线程派发机制:
- all,所有的请求转发到业务线程池中执行(IO读写、心跳包除外,因为在Dubbo中这两种请求都必须在IO线程中执行,不能通过配置修改);
- message,只有请求事件在线程池中执行,其他请求在IO线程上执行;
- connection ,求事件在线程池中执行,连接和断开连接的事件排队执行(含一个线程的线程池);
- direct,所有请求直接在IO线程中执行。
为什么线程派发机制有这么多种策略呢?其实这主要是考虑到线程切换带来的开销问题。也就是说,我们希望通过多种策略让线程切换带来的开销小于多线程处理带来的提升。
我举个例子,Dubbo中的心跳包都必须在IO线程中执行。在处理心跳包时,我们只需直接返回PONG包(OK)就可以了,逻辑非常简单,处理速度也很快。如果将心跳包转换到业务线程池,性能不升反降,因为切换线程会带来额外的性能损耗,得不偿失。
网络编程中需要遵循一条最佳实践:IO线程中不能有阻塞操作,通常将阻塞操作转发到业务线程池异步执行。
与网络通信协议相关的参数定义在dubbo:protocol,关键的设置属性如下。
- threads,业务线程池线程个数,默认为200。
- queues,业务线程池队列长度,默认为0,表示不支持排队,如果线程池满,则直接拒绝。该参数与threads配合使用,主要是对服务端进行限流,一旦超过其处理能力,就拒绝请求,快速失败,引导客户端重试。
- iothreads:默认为CPU核数再加一,用于处理网络读写。在生产实践中,通常的瓶颈在于业务线程池,如果业务线程无明显瓶颈(jstack日志查询到业务线程基本没怎么干活),但吞吐量已经无法继续提升了,可以考虑调整iothreads,增加IO线程数量,提高IO读写并发度。该值建议保持在“2*CPU核数”以下。
- serialization:序列化协议,新版本支持protobuf等高性能序列化机制。
- dispatcher:线程派发机制,默认为all。
高度灵活的扩展机制
Dubbo出现之后迅速成为微服务领域最受欢迎的框架,除操作简单这个原因外,还有扩展机制的功劳。Dubbo高度灵活的扩展机制堪称“王者级别的设计”。
Dubbo的扩展设计主要是基于SPI设计理念,我们来看下具体的实现方案。
Dubbo所有的底层能力都通过接口来定义。用户在扩展时只需要实现对应的接口,定义一个统一的扩展目录(META-INF.dubbo.internal)存放所有的扩展定义即可。要注意的是,目录下的文件名是需要扩展的接口的全名,像下图这样:
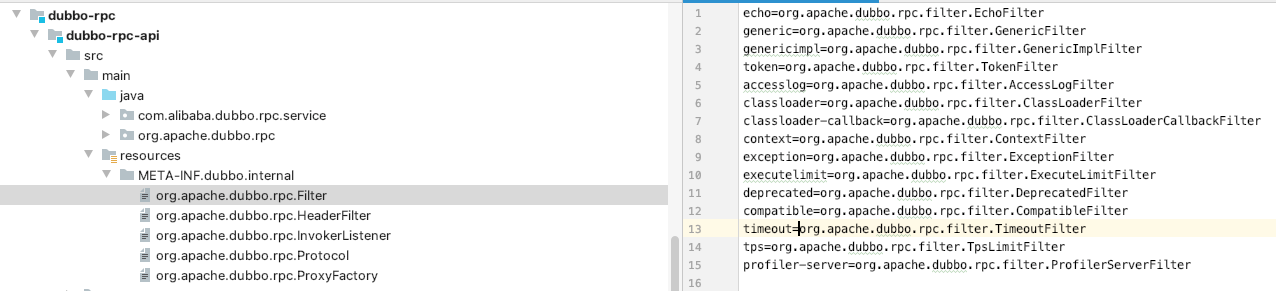
在初次使用对应接口实例时,可以扫描扩展目录中的文件,并根据文件中存储的key-value初始化具体的实例。
我们以RPC模块为例看一下Dubbo强悍的扩展能力。众所周知,目前gRPC协议以优异的性能表现正在逐步成为RPC领域的王者,很多人误以为gRPC是来革Dubbo的“命”的。其实不然,我们可以认为Dubbo是微服务体系的完整解决方案,而RPC只是微服务体系中的重要一环,Dubbo完全可以吸收gRPC,让gRPC成为Dubbo的远程调用方式。
具体的做法只需要在dubbo-rpc模块中添加一个dubbo-rpc-grpc模块,然后使用gRPC实现org.apache.dubbo.rpc.protocol接口,并将其配置在扩展目录中:
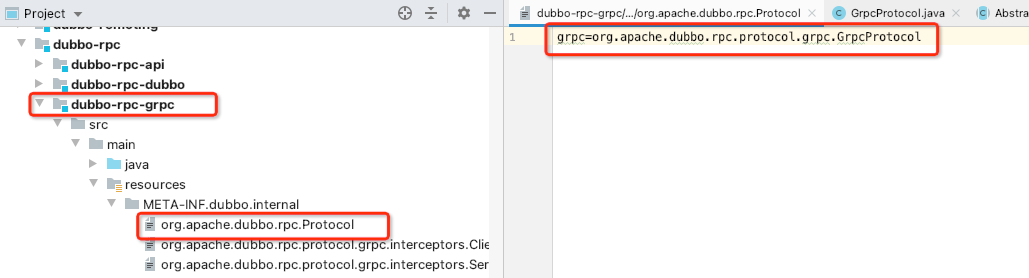
面对gRPC这么强大的功能扩展机制,绝大部分人应该和我一样,都是作为中间件的应用人员,不需要使用模块级别的扩展机制。我们通常只是结合应用场景来进行功能扩展。
Dubbo在业务功能级别的扩展可以通过Filter机制来实现。Filter的工作机制如下:
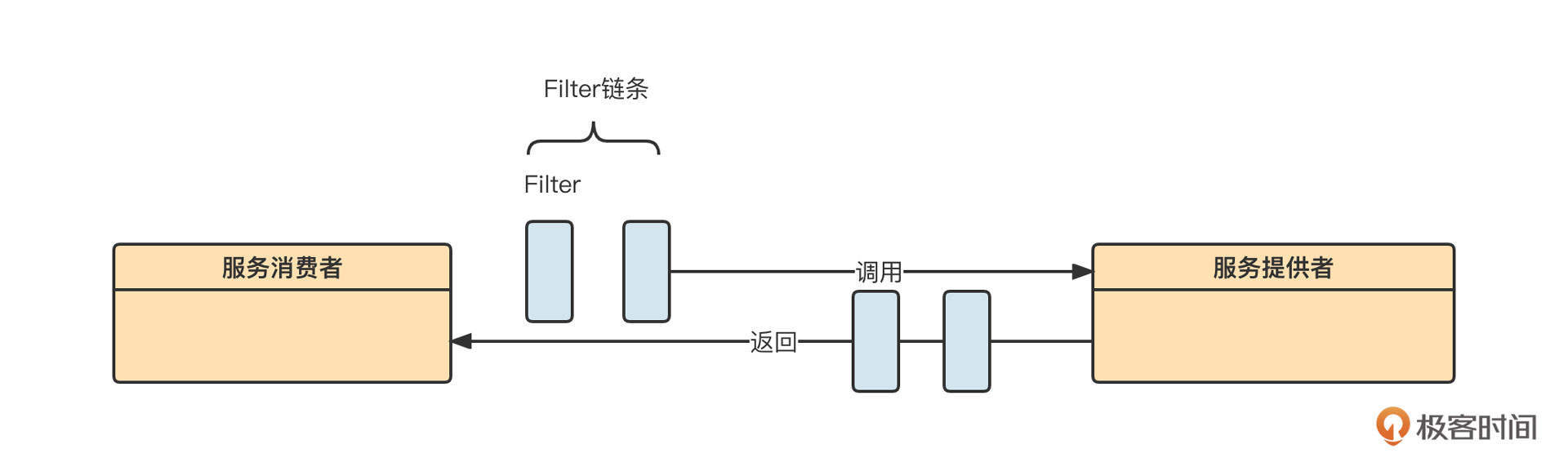
这里,过滤器链的执行时机是在服务消费者发起远程RPC请求之前。最先执行的是消费端的过滤器链,每一个过滤器可以设置执行顺序。服务端在解码之后、执行业务逻辑之前,也会首先调用过滤器链。
在专栏的最后一讲,我还会通过一个全链路压测方案讲解如何利用Filter机制来解决实际问题。
泛化调用
在这节课的最后,我们再来介绍一下Dubbo的泛化调用机制,它也是实现Dubbo网关的理论基础。
我们在开发Dubbo应用时通常会包含API、Consumer、Provider三个子模块。
其中API模块通常定义统一的服务接口,而Consumer、Provider模块都需要显示依赖API模块。这种设计理念虽然将Provider与Consumer进行了解耦合,但对API模块形成了强依赖,如果API模块发生改变,Provider和Consumer必须同时改变。也就是说,一旦API模块发生变化,服务调用方、服务消费方都需要重新部署,这对应用发布来说非常不友好。特别是在网关领域,几乎是不可接受的,如下图所示:
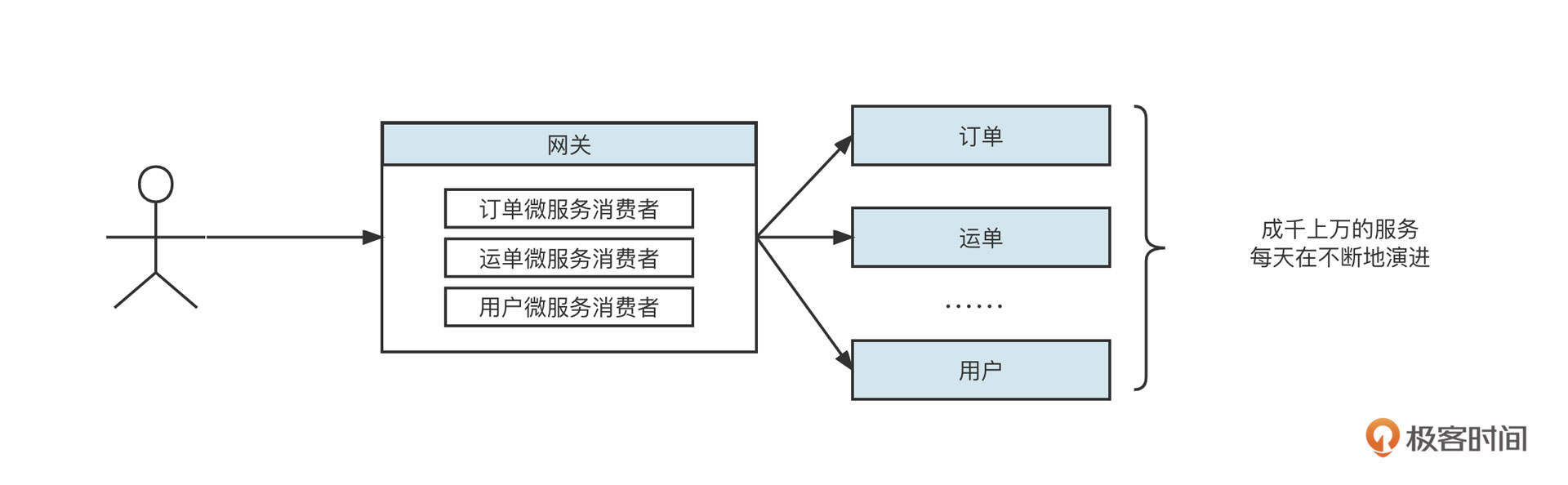
公司的微服务在不停地演进,如果网关需要跟着API模块不停地发布新版本,网关的可用性和稳定性都将受到极大挑战。怎么解决这个问题呢?
这就要说到Dubbo的机制了。泛化调用具体实现原理如下:

当服务消费端发生调用时,我们使用Map来存储一个具体的请求参数对象,然后传输到服务提供方。由于服务提供方引入了模型相关的Jar,服务提供方在执行业务方法之前,需要将Map转化成具体的模型对象,然后再执行业务逻辑。
Dubbo的泛化调用在服务提供方的转化是通过Filter机制统一处理的,服务端并不需要关注消费方采取何种方式进行调用。
通过泛化调用机制,客户端不再需要依赖服务端的Jar包,服务端可以不断地演变,而不会影响客户端已有服务的运行。
总结
好了,这节课就讲到这里。我们这节课主要介绍了Dubbo的服务注册与发现、服务调用、网络通信模型、扩展机制还有泛化调用等核心工作机制,了解这些内容可以指导我们更好实践微服务。
另外,Dubbo框架算是阿里巴巴开源的所有框架中文档最为齐全的框架了,非常值得我们深入学习与研究。如果你想要进一步掌握Dubbo,建议你看看Dubbo官方文档。
课后题
- 我们将在下节课和你一起聊聊Dubbo的网关设计方案,其中泛化调用是其理论设计基础,所以我们的第一道课后题就是,请你试着先编写一个Dubbo泛化调用的示例。
提示一下,Dubbo提供了dubbo-demo模块,你可以在官方提供的示例中进行泛化调用编写,节省搭建基础项目的时间。
- 请你尝试通过dubbo-admin运维管理工具动态修改参数,看看它是否可以动态生效。你知道它背后是如何实现的么?
欢迎你在留言区与我交流讨论,我们下节课再见!
11|案例:如何基于Dubbo进行网关设计?
作者: 丁威

你好,我是丁威。
这节课我们通过一个真实的业务场景来看看Dubbo网关(开放平台)的设计要领。
设计背景
要设计一个网关,我们首先要知道它的设计背景。
2017年,我从传统行业脱身,正式进入物流行业。说来也非常巧,我当时加入的是公司的网关项目组,主要解决泛化调用与协议转换代码的开发问题。刚进公司不久,网关项目组就遇到了技术难题。快递物流行业的业务量可以比肩互联网,从那时候开始,我的传统技术思维开始向互联网技术思维转变。
当时网关项目组的核心任务就是确保能够快速接入各个电商平台。我来简单说明一下具体的场景。
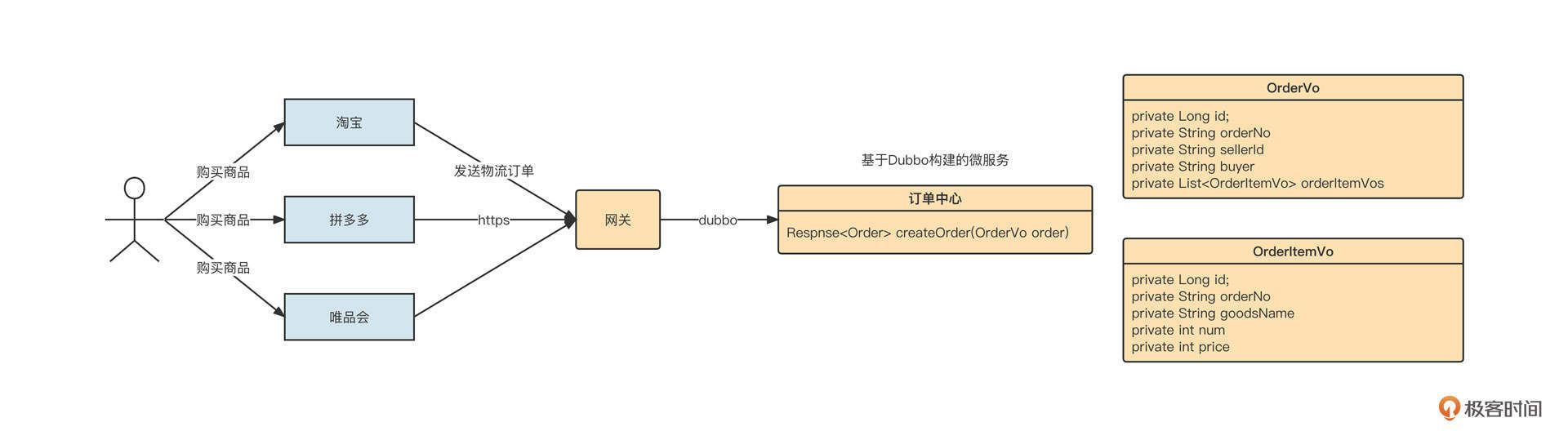
解释一下上面这个图。
物流公司内部已经基于Dubbo构建了订单中心微服务域,其中创建订单接口的定义如下:
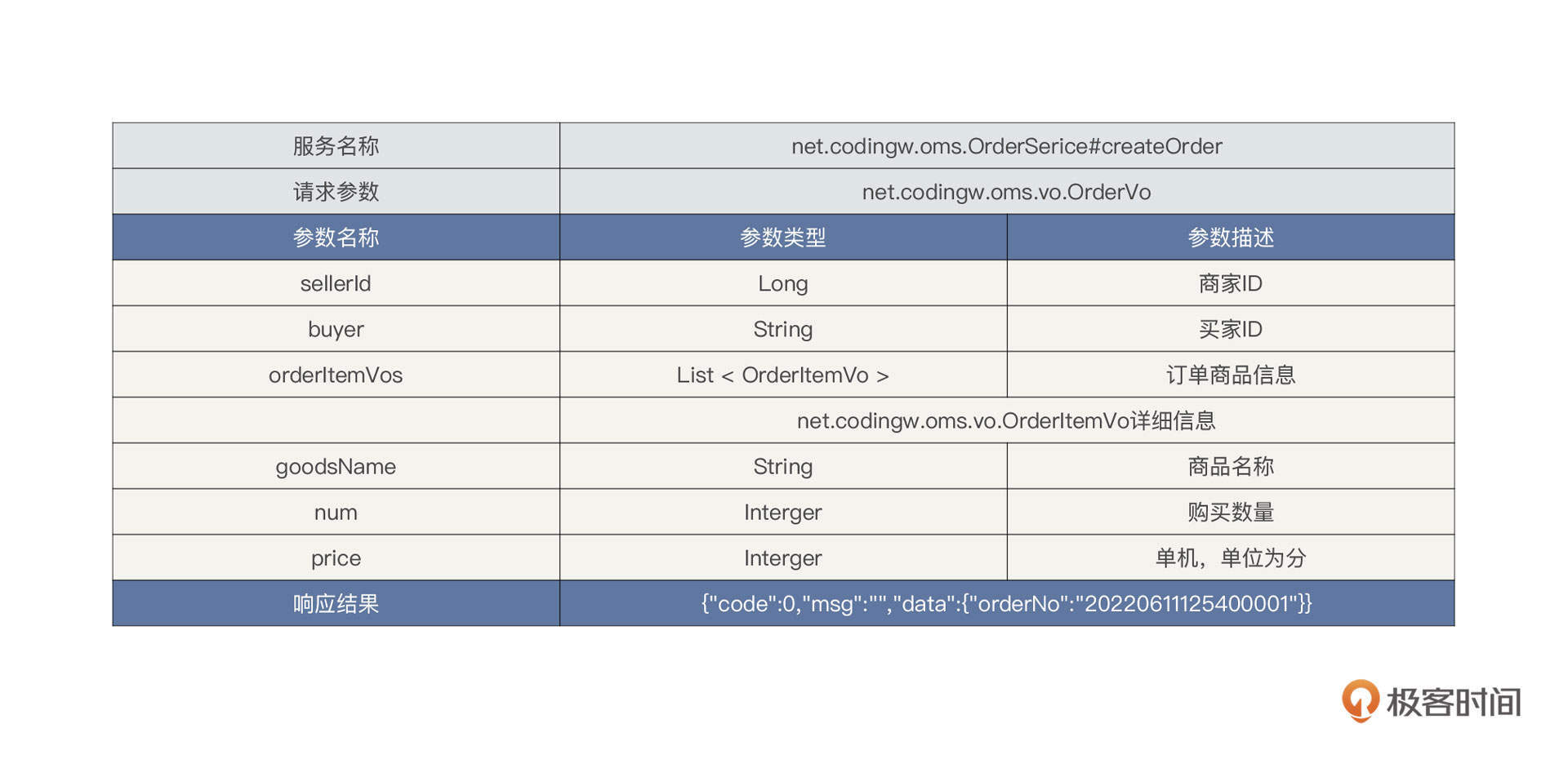
外部电商平台众多,每一家电商平台内部都有自己的标准,并不会遵循统一的标准。例如在淘宝中,当用户购买商品后,淘宝内部会定义一个统一的订单外派接口。它的请求包可能是这样的:
1 | { |
但拼多多内部定义的订单外派接口,它的请求包可能是下面这样的:
1 | <order> |
当电商的快递件占据快递公司总业务量的大半时,电商平台的话语权是高于快递公司的。也就是说,电商平台不管下游对接哪家物流公司,都会下发自己公司内部定义的订单派发接口,适配工作需要由物流公司自己来承担。
那站在物流公司的角度,应该怎么做呢?总不能每接入一个电商平台就为它们开发一套下单服务吧?那样的话,随着越来越多的电商平台接入,系统的复杂度会越来越高,可维护性将越来越差。
设计方案
正是在这样的背景下,网关平台被立项开发出来了。这个网关平台是怎么设计的呢?在设计的过程中需要解决哪些常见的问题?
我认为,网关的设计至少需要包括三个方面,分别是签名验证、服务配置和限流。
先说签名验证。保证请求的安全是系统设计需要优先考虑的。业界有一种非常经典的通信安全校验机制:验证签名。
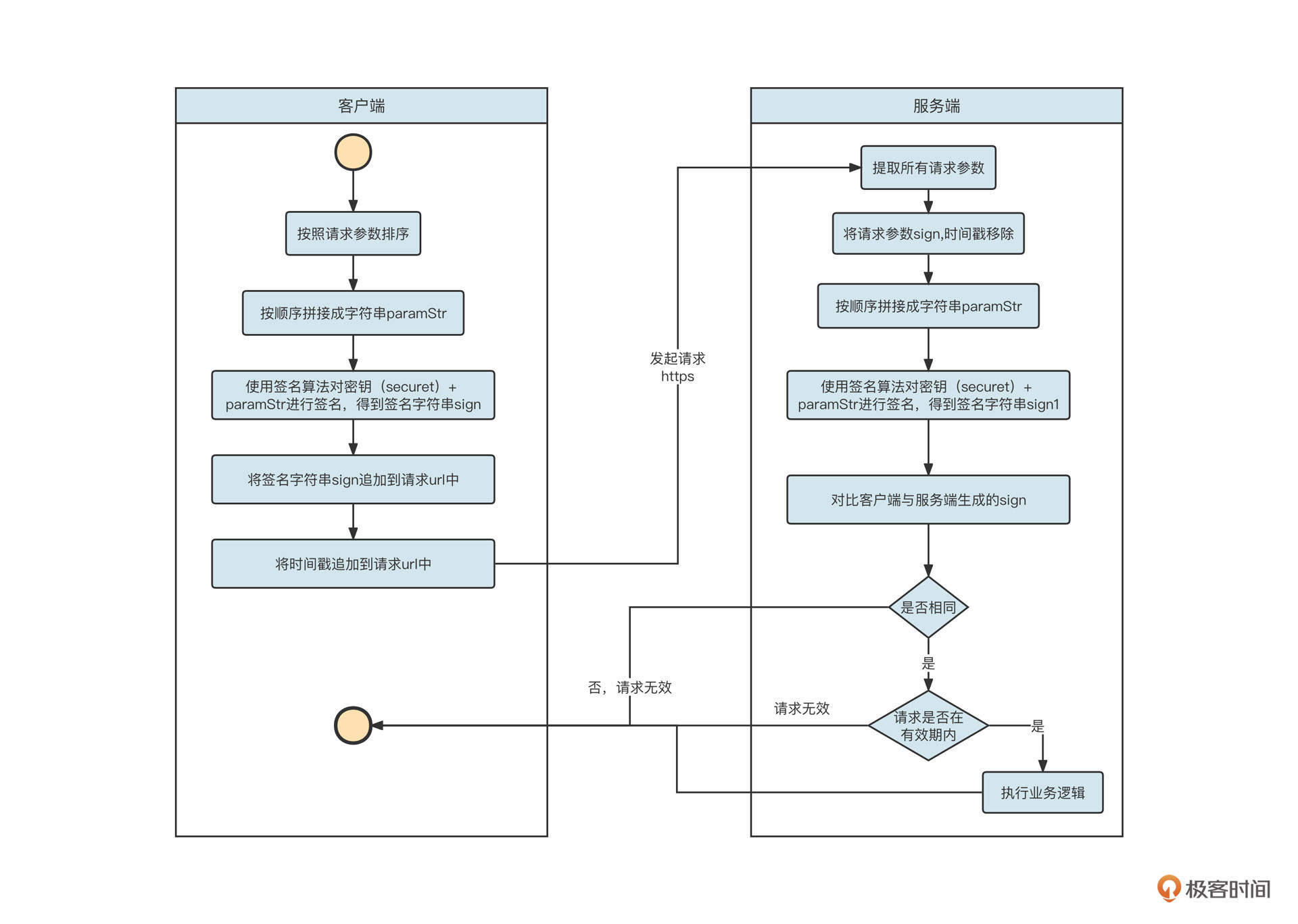
这种机制的做法是,客户端与服务端会首先采用HTTPS进行通信,确保传输过程的私密性。
客户端在发送请求时,先将请求参数按参数名称进行排序,然后按顺序拼接成字符串,格式为key1=a & key2=b。接下来,客户端使用一个约定的密钥对拼接出来的参数字符串进行签名,生成签名字符串(我们用sign表示签名字符串)并追加到URL。通常,还会在URL中追加一个发送时间戳(时间戳不参与签名验证)。
服务端在接收到客户端的请求后,先从请求中解析出所有的参数,同样按照参数名对参数进行排序,然后使用同样的密钥对参数进行签名。得到的签名字符串需要与客户端计算的签名字符串进行对比,如果两者不同,则请求无效。与此同时,通常我们还需要将服务端当前的时间戳与客户端时间戳进行对比,如果相差超过一定的时间,同样认为请求无效,这个操作主要是为了避免使用同一个连接对网络进行连续攻击。
这整个过程里有一个非常重要的点,就是密钥自始至终并没有在网络上进行过传播,它的安全性可以得到十足的保证。签名验证的流程大概可以用下面这张图表示:
如果要对验证签名进行产品化设计,我们通常需要:
- 为不同的接入端(电商平台)创建不同的密钥,并通过安全的方式告知他们;
- 为不同的接入端(电商平台)配置签名算法。
在确保能够安全通信后,接下来就是网关设计最核心的部分了:服务接口配置化。它主要包括两个要点:微服务调用协议(Dubbo服务描述)和接口定义与参数映射。
我们先来看一下微服务调用协议的配置,设计的原型界面如下图所示:
将所有的微服务(细化到方法级名称)维护到网关系统中,网关应用就可以使用Dubbo提供的编程API,根据这些元信息动态构建一个个消费者(服务调用者),进而通过创建的服务调用客户端发起RPC远程调用,最终实现网关应用的Dubbo服务调用。
基于这些元信息构建消费者对象的关键代码如下:
1 | public static GenericService getInvoker(String serviceInterface, String version, List<String> methods, int retry, String registryAddr ) { |
通过getInvoker方法发起调用远程RPC服务,这样,网关应用就成为了对应服务的消费者。
因为网关应用引入服务规约(API包)不太现实,所以这里使用的是泛化调用,这样方便网关应用不受约束地构建消费者对象。
值得注意的是,ReferenceConfig实例很重,它封装了与注册中心的连接以及所有服务提供者的连接,需要被缓存起来。因此,在真实的生产实践中,我们需要将ReferenceConfig对象存储到缓存中。否则,重复生成的ReferenceConfig可能造成性能问题并伴随着内存和连接泄漏。
除了ReferenceConfig,其实getInvoker生成对象也可以进行缓存,缓存的key通常为接口名称、版本和注册中心。
那如果配置信息动态发生了变化,例如需要添加新的服务,这时候网关应用如何做到动态感知呢?我们通常可以用基于MQ的方式来解决这个问题。具体的解决方案如下:
也就是说,用户如果在网关运营平台上修改原有服务协议(Dubbo服务)或者添加新的服务协议,变动后的协议会首先存储到数据库中,然后运营平台发送一条消息到MQ,紧接着Gateway的后台进程以广播模式进行订阅。这样,所有后台网关进程都可以感知。
如果是对已有服务协议进行修改,在具体实践时有一个小细节请你一定注意。我们先看看这段代码:
1 | Map<String /* 缓存key */,GenericService> invokerCache; |
如果已经存在对应的Invoker对象,为了不影响现有调用,应该先用新的Invoker对象去更新缓存,然后再销毁旧的Invoker对象。
上面的方法解决了网关调用公司内部的Dubbo微服务问题,但还有另外一个非常重要的问题,怎么配置服务接口相关参数呢?
联系这节课前面的场景,我们需要在页面上配置公司内部Dubbo服务与外部电商的接口映射。

为此,我们专门建立了一条参数映射协议:
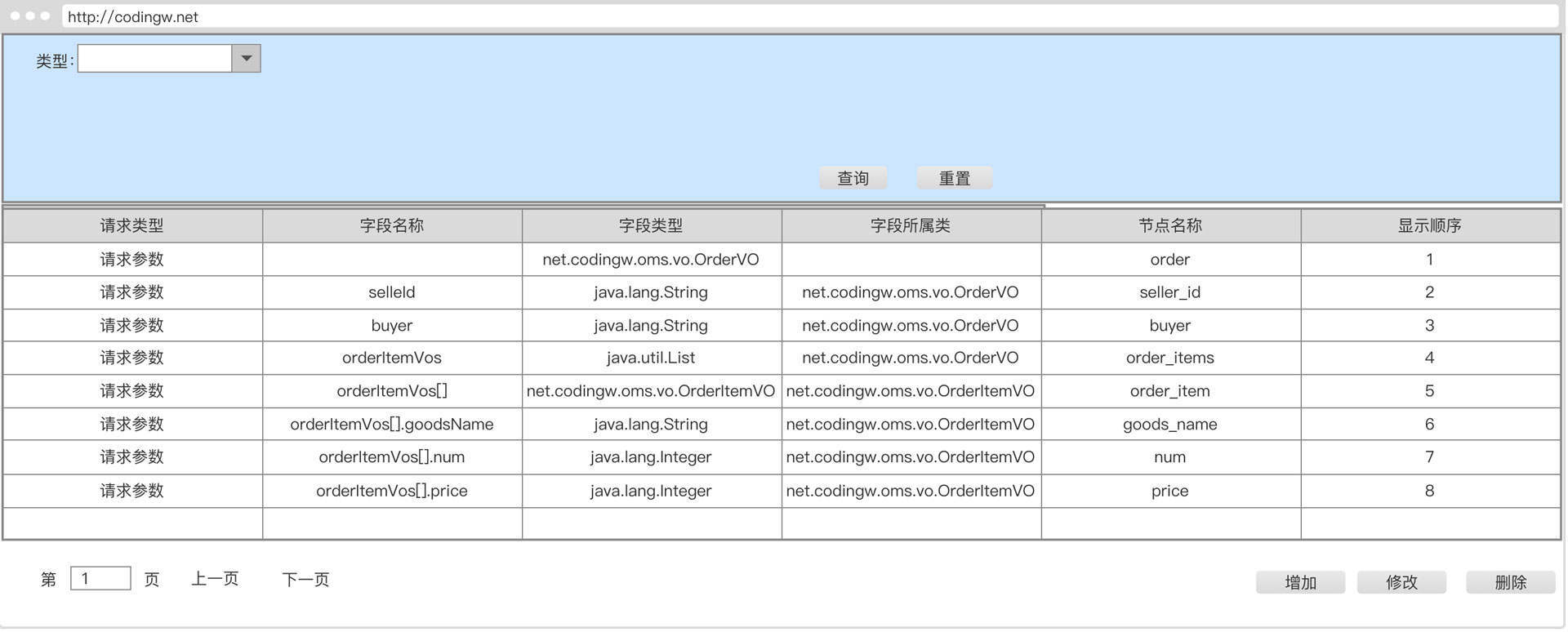
参数映射设计的说明如下。
- 请求类型:主要分为请求参数与响应参数;
- 字段名称:Dubbo服务对应的字段名称;
- 字段类型:Dubbo服务对应字段的属性;
- 字段所属类:Dubbo服务对应字段所属类型;
- 节点名称:外部请求接口对应的字段名称;
- 显示顺序:排序字段。
由于网关采取了泛化调用,在编写转换代码时,主要是遍历传入的参数,根据每一个字段查询对应的转换规则,然后转换为Map,返回值则刚好相反,是将Map转换为XML或者JSON。
在真正请求调用时,根据映射规则构建出请求参数Map后,通过Dubbo的泛化调用执行真正的调用:
1 | GenericService genericService = (GenericService) invokeBean; |
这样,网关就具备了高扩展性和稳定性,可以非常灵活地支撑业务的扩展,为不同的电商平台配置不同的参数转换,从而在内部只需要开发一套接口就可以非常灵活地支撑业务的扩展,基本做到网关代码零修改。
总结
这节课,我通过一个真实的场景,详细介绍了网关设计的需求背景,然后针对网关设计的痛点给出了设计方案。通过对这个方案中关键代码的解读,你应该能够更加深刻地理解Dubbo泛化调用背后的逻辑,真正做到理论与实际相结合。
值得注意的是,我们这节课提到的转换协议也是一绝,它使用中括号来定义多层嵌套结构,使得该协议具有普适性。
课后题
检测对知识的掌握程度最好的方式是自己写出来。所以,我建议你将我们这节课所讲的方案落到实处,尝试自己实现一个demo级的网关设计。
如果你想听听我的意见,可以提交一个 GitHub的push请求或issues,并把对应地址贴到留言里。我们下节课见!
12|案例:如何实现蓝绿发布?
作者: 丁威

你好,我是丁威。
前面,我们讲了服务的注册与发现机制,它是微服务体系的基石,这节课,我想聊聊微服务的另外一个重要课题:服务治理。
随着微服务应用的不断增加,各个微服务之间的依赖关系也变得比较复杂,各个微服务的更新、升级部署给整个服务域的稳定性带来很大挑战。怎么以不停机的方式部署升级微服务呢?
这就是我们这节课的任务,我们来看看如何在生产环境用蓝绿发布来满足不停机升级的要求。
设计背景
在进行技术方案的设计之前,我们先来了解一下生产环境的基本部署情况,如下图所示:
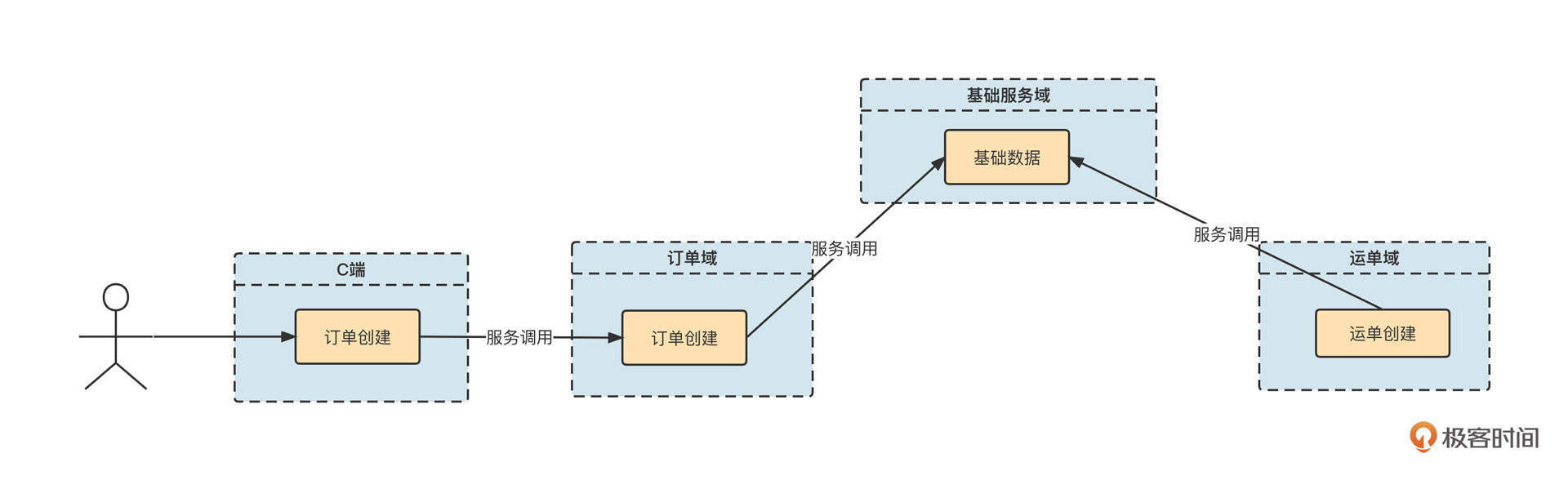
用户在面向用户端(下文通称C端)下单后,C端订单系统需要远程调用订单域中的“创建订单“接口。同时,订单域、运单域相关服务都需要调用基础服务域,进行基础数据的查询服务。
从这里也可以看出,基础服务的稳定运行对整个微服务体系至关重要。那如何确保基础服务域不受版本的影响,始终能够提供稳定可控的服务呢?
设计方案
我们公司为了解决这个问题实现了蓝绿发布。那什么是蓝绿发布呢?
蓝绿发布指的是在蓝、绿两套环境中分别运行项目的两个版本的代码。但是在进行版本发布时只更新其中一个环境,这样方便另一个环境快速回滚。
接下来我们看一下蓝绿发布的基本流程。
如果系统采取蓝绿发布,在下一个版本(base-service v1.2.0)发布之前,会这样部署架构:
当前订单域调用流量进入基础服务域 GREEN环境。团队计划在12:00发布新版本(base-service v1.2.0),这时我们通常会执行下面几个操作。
- 将新版本1.2.0全部发布在BLUE环境上。因为此时BLUE环境没有任何流量,对运行中的系统无任何影响。
- 在请求入口对流量进行切分。通常可以按照百分比分配流量,待系统运行良好后,再逐步将流量全部切换到新版本。
- 如果发现新版本存在严重问题,可以将流量全部切换到原来的环境,实现版本快速回滚。
这个过程可以用下面这张图表示:
这个思路听起来很简单,但是怎么实现呢?
这就不得不提到上节课专门提到的路由选择(Router)了,它是Dubbo服务调用中非常重要的一步。路由选择的核心思想是在客户端进行负载均衡之前,通过一定的过滤规则,只在服务提供者列表中选择符合条件的提供者。
我们再看上面的实例图,从订单域消费者的视角,服务提供者列表大概是下面这个样子:
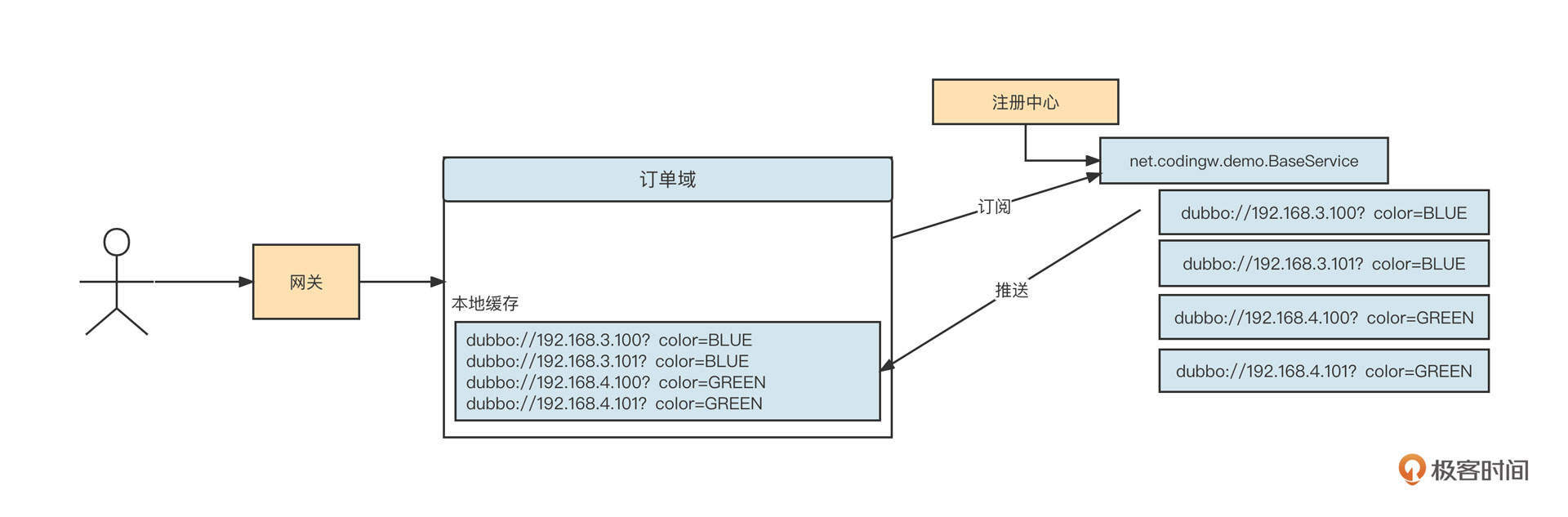
然后呢,我们按照比例对入口流量进行分流。例如,80%的请求颜色为BLUE,20%的请求颜色为GREEN。那些颜色为BLUE的请求,在真正执行RPC服务调用时,只从服务提供者列表中选择“color=BLUE”的服务提供者。同样,颜色为GREEN的请求只选择“color=GREEN”的服务提供者,这就实现了流量切分。
具体的操作是,在Dubbo中为这个场景引入Tag路由机制。
首先,服务提供者在启动时需要通过“-Dubbo.provider.tag”系统参数来设置服务提供者所属的标签。
例如,在192.168.3.100和192.168.3.101这两台机器上启动base-service程序时,需要添加“-Dubbo.provider.tag=BLUE”系统参数;而在192.168.4.100和192.168.4.101这两台机器上启动base-service程序时,则要添加“-Dubbo.provider.tag=GREEN”系统参数,通过这个操作完成对服务提供者的打标。服务提供者启动后,生成的服务提供者URL连接如下所示:
1 | dubbo://192.168.3.100:20880/net.codingw.demo.BaseUser?dubbo.tag=BLUE |
下一步,在服务入口对流量进行染色,从而实现流量切分。
蓝绿发布的流量通常是在流量入口处进行染色的。例如,我们可以使用随机加权来实现流量切分算法,用它对流量进行染色,具体示范代码如下:
1 | public static String selectColor(String[] colorArr, int[] weightArr) { |
根据流量切分算法计算得到流量标识后,怎么在消费端跟进流量标识从而进行路由选择呢?我们通常会将染色标记放在ThreadLocal中,然后再编写Filter,获取或者传递路由标签。
但这个只是一个流量的切分算法,那如何动态设置蓝绿的比例或者说权重呢?其实,我们可以为发布系统提供一个设置权重的页面,用户设置完权重后写入到配置中心(ZooKeeper、Apollo),然后应用程序动态感知到变化,利用最新的权重进行流量切分。
通过流量切分算法计算出一个请求的流量标识后,通常会存储在ThreadLocal中,实现代码如下:
1 | public class ThreadLocalContext { |
将请求的流量标识存储到线程本地变量之后,还需要将流量标识附加到RPC请求调用中,这样才能触发正确的路由选择,具体代码示例如下:
1 | import org.apache.commons.lang3.StringUtils; |
这样在RPC调用的过程中,服务调用者就能根据本地线程变量中存储的流量标记,选择不同机房的服务提供者,从而实现蓝绿发布了。
同时,在实际生产环境中,一个调用链条中往往会存在多个RPC调用,那第一个RPC中的路由标签能自动传递到第二个RPC调用吗?
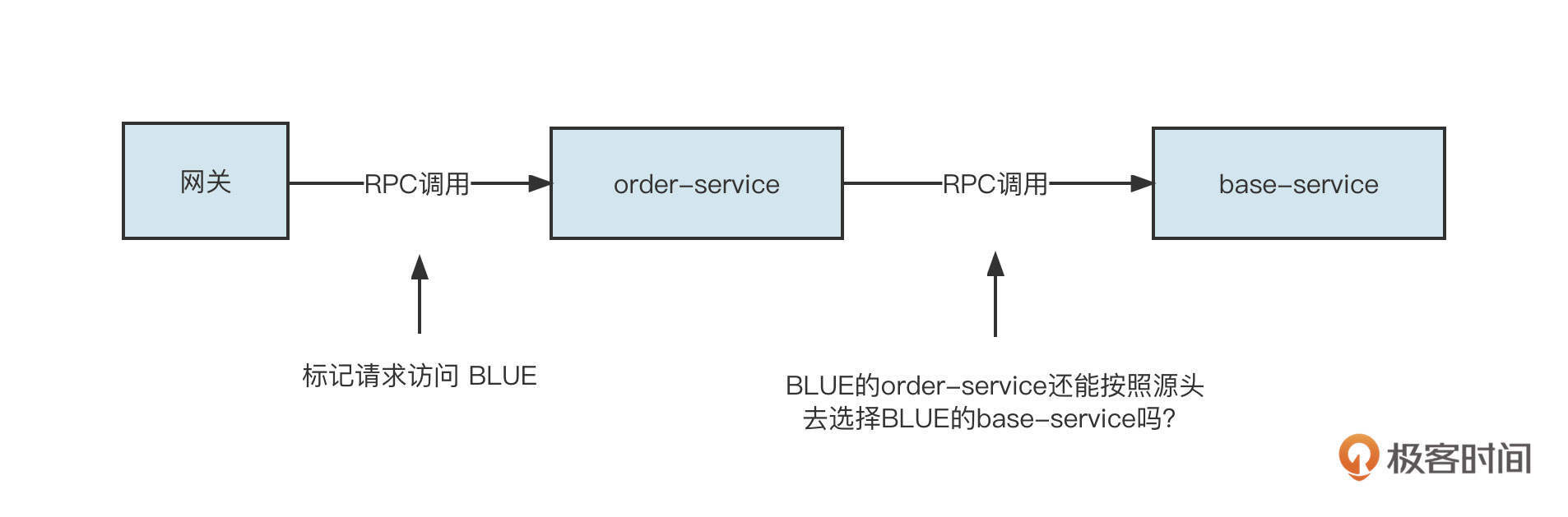
答案是不可以,我们需要再写一个服务端生效的Filter,示例代码如下:
1 | import org.apache.commons.lang3.StringUtils; |
也就是将调用链中的tag存储到服务端的线程本地上下文环境中,当服务端调用其他服务时,可以继续将tag传递到下一个RPC调用链中。
这样,我们的蓝绿发布就基本完成了。但这里还有一个问题。规模较大的公司的生产环境往往会运行很多微服务,我们无法将蓝绿机制一下引入到所有微服务当中,必然会存在一部分应用使用蓝绿发布,但其他应用没有使用蓝绿的情况。怎么做到兼容呢?
比方说,我们公司目前核心业务域的蓝绿部署情况如下:
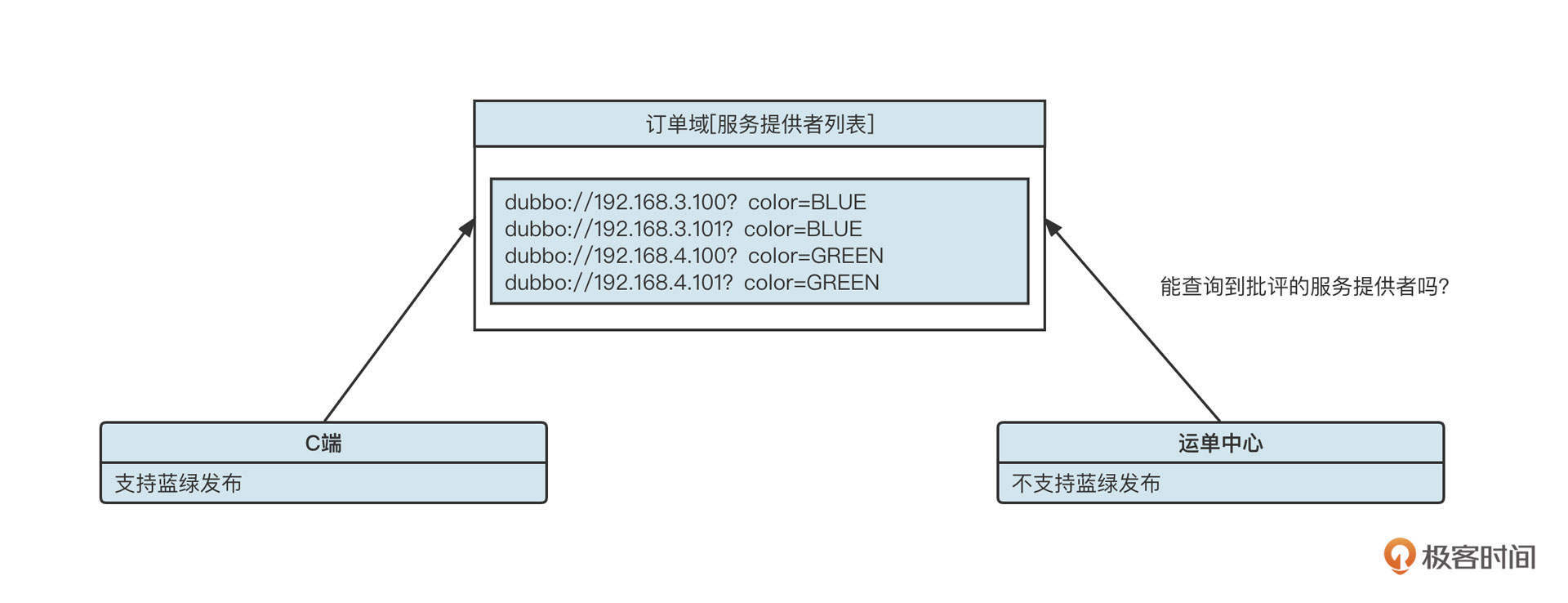
这里,订单域接入了蓝绿发布;C端应用需要调用订单域相关接口,因此也接入了蓝绿发布;但运单中心并未接入蓝绿发布。这时候,运单中心能调用订单域的服务吗?
要回答这个问题,我们要先看看Dubbo官方的降级策略。
- 如果消费者侧设置了标签,那么如果集群中没有对应标签的服务提供者,默认可以选择不带任何标签的服务提供者进行服务调用。该行为可以通过设置request.tag.force=true来禁止,这就是说如果request.tag.force为true,一旦没有对应标签的服务提供者,就会跑出“No Provider”异常。
- 如果消费者侧没有设置标签,那就只能向集群中没有设置标签的服务提供者发起请求,如果不存在没有标签的服务提供者,则报“No Provider”异常。
回到上面的问题,运单中心由于未接入蓝绿发布,所以不带任何标签,它无法调用订单域的服务。为了解决这个问题,订单域还需要部署一些不带标签的服务。订单域最终的部署大概如下图所示:
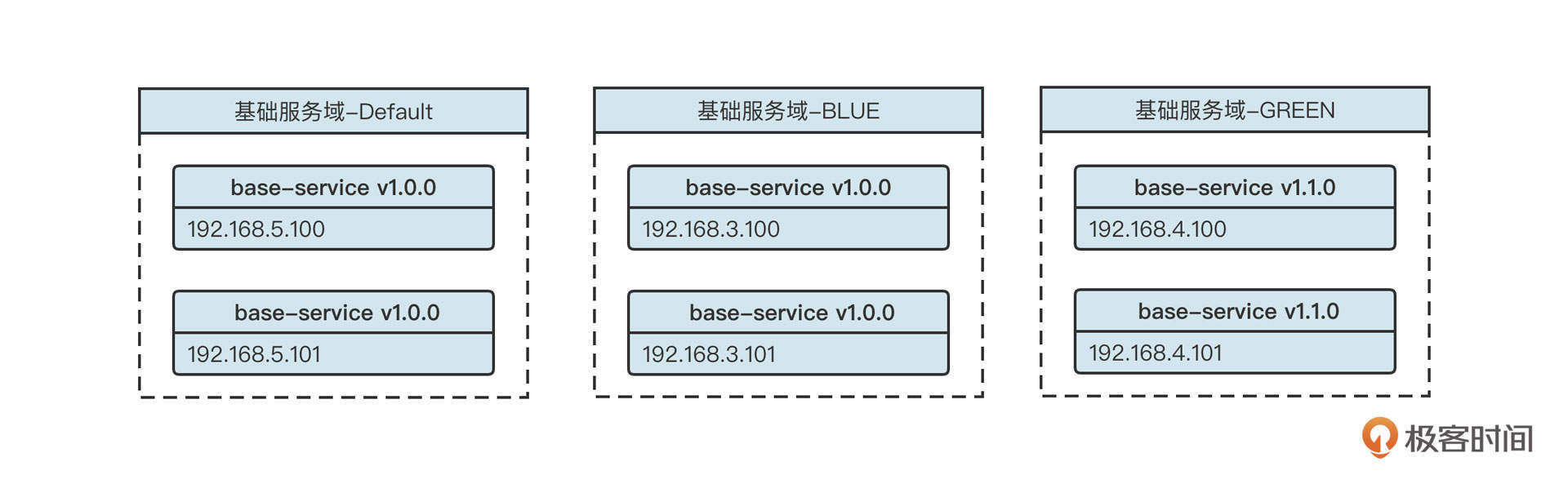
也就是说,订单域为了兼容那些还没接入蓝绿发布的应用需要部署3套环境,一套为不设置标签的服务提供者,一套为蓝颜色的服务提供者,另一套为绿颜色的服务提供者。
蓝绿发布实践就介绍到这里了,在这节课的最后,我们再来学习一下蓝绿发布底层依托的原理。
实现原理
先来看一下Dubbo服务调用的基本时序图:
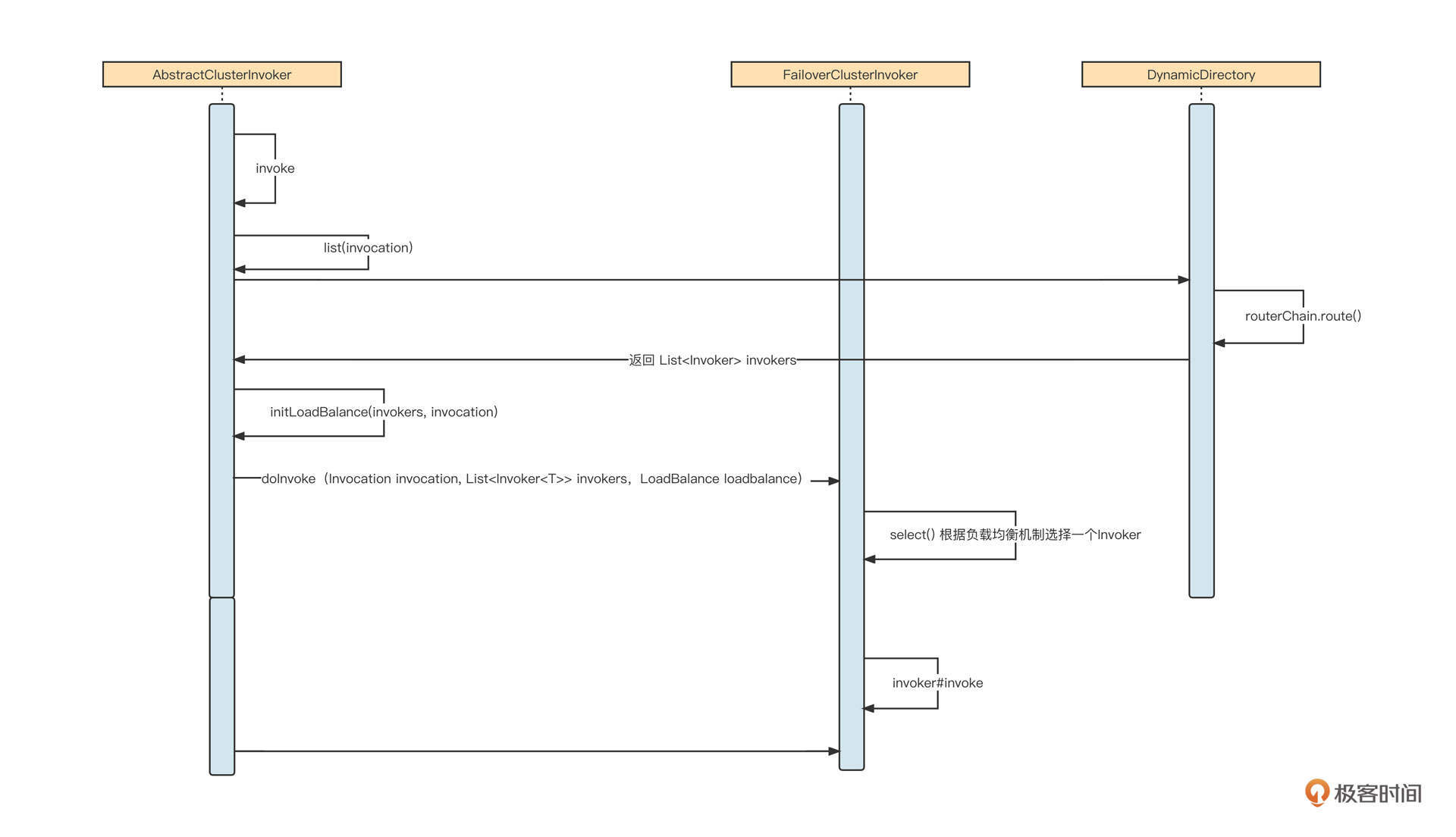
我建议你按照这张时序图跟踪一下源码,更加详细地了解Dubbo服务调用的核心流程与实现关键点,我在这里总结了几个要点:
- Dubbo的服务调用支持容错,对应的抽象类为AbstractClusterInvoker,它封装了服务调用的基本流程。Dubbo内置了failover、failfast、failsafe、failback、forking等失败容错策略,每一个策略对应AbstractClusterInvoker的一个实现;
- 在调用AbstractClusterInvoker服务的时候,首先需要获取所有的服务提供者列表,这个过程我们称之为服务动态发现(具体实现类为DynamicDirectory)。在获取路由信息之前,需要调用RouterChain的route方法,执行路由选择策略,筛选出服务动态发现的服务提供者列表。我们这一课的重点,标签路由的具体实现类TagRouter就是在这里发挥作用的。
我们也详细拆解一下TagRouter的route方法。因为这个方法的实现代码比较多,我们还是分步讲解。
第一步,执行静态路由过滤机制,代码如下:
1 | final TagRouterRule tagRouterRuleCopy = tagRouterRule; |
如果路由规则为空,则根据tag进行过滤。我们顺便也看一下基于tag的静态过滤机制是如何实现的:
1 | private <T> List<Invoker<T>> filterUsingStaticTag(List<Invoker<T>> invokers, URL url, Invocation invocation) { |
尝试从Invocation(服务调用上下文)中或者从URL中获取tag的值,根据tag是否为空,执行两种不同的策略:
- 如果tag不为空,首先按照tag找到服务提供者列表中打了同样标签的服务提供者列表,如果dubbo.force.tag的设置为false,则查找服务提供者列表,筛查出没有打标签的服务提供者列表。
- 如果tag为空,则直接查找没有打标签的服务提供者列表。
我们继续回到TagRouter的route方法。第二步操作是,按照路由规则进行筛选,具体代码如下:
1 | // if we are requesting for a Provider with a specific tag |
上面这段代码比较简单,它的过滤思路和静态tag过滤是相似的。不同点是,这里可以通过YAML格式配置单个服务的路由规则。具体的配置格式如下:
1 | force: true |
这些数据都会记录在注册中心,并在发生变化后实时通知TagRouter,从而实现路由规则的动态配置。
总结
好了,这节课就讲到这里。刚才,我们从微服务不停机发布这个需求谈起,引出了蓝绿发布机制。
蓝绿发布的实现要点是对应用分别部署蓝、绿两套环境,在版本稳定后由一套环境对外提供服务,当需要发布新版本时,将新版本一次性部署到没有流量的环境,待部署成功后再逐步将流量切换到新版本。如果新版本在验证阶段遇到严重的问题,可以直接将流量切回老版本,实现应用发布的快速回滚。
然后,我们借助蓝绿发布的指导思想,一步一步实现了基于Dubbo的蓝绿发布。
蓝绿发布的底层原理是借助Dubbo内置的标签路由功能,其核心思路是,当服务发起调用时,经过服务发现得到一个服务提供者列表,但是并不直接使用这些服务提供者进行负载均衡,而是在进行负载均衡之前,先按照路由规则对这些提供者进行过滤,挑选符合路由规则的服务提供者列表进行服务调用,从而实现服务的动态分组。
课后题
最后,我还是照例给你留一道思考题。
你认为蓝绿发布和灰度发布的共同点是什么,这两者又有什么区别?
欢迎你在留言区与我交流讨论,我们下节课再见!
13 | 技术选型:如何根据应用场景选择合适的消息中间件?
作者: 丁威

你好,我是丁威。
随着微服务技术的兴起,消息中间件也成为了分布式架构体系的必备组件,所以从这节课开始,我们一起来学习消息中间件。
我们的课程还是会将理论和实践相结合,将重点落在实战。
我会分别介绍消息中间件的应用场景与技术选型、两种消息中间件(Kafka和RocketMQ)分别是如何实现高性能的。紧接着,我会结合自己的工作经验,带你看看消息中间件如何实现蓝绿发布、如何提升RocketMQ顺序消费能力;最后,我们会一起认识消息中间件优雅的生产环境运维能力,搞清如何排查消息发送、消息消费相关的故障。
我们这节课主要来看消息中间件应用场景与技术选型。
消息中间件的应用场景
消息中间件的应用场景主要有两个:异步解耦与削峰填谷。
我们首先通过电商平台用户注册送积分、送优惠券这个场景来理解异步解耦合。如果不使用消息中间件,电商平台送积分的实现也许是下图这个样子:
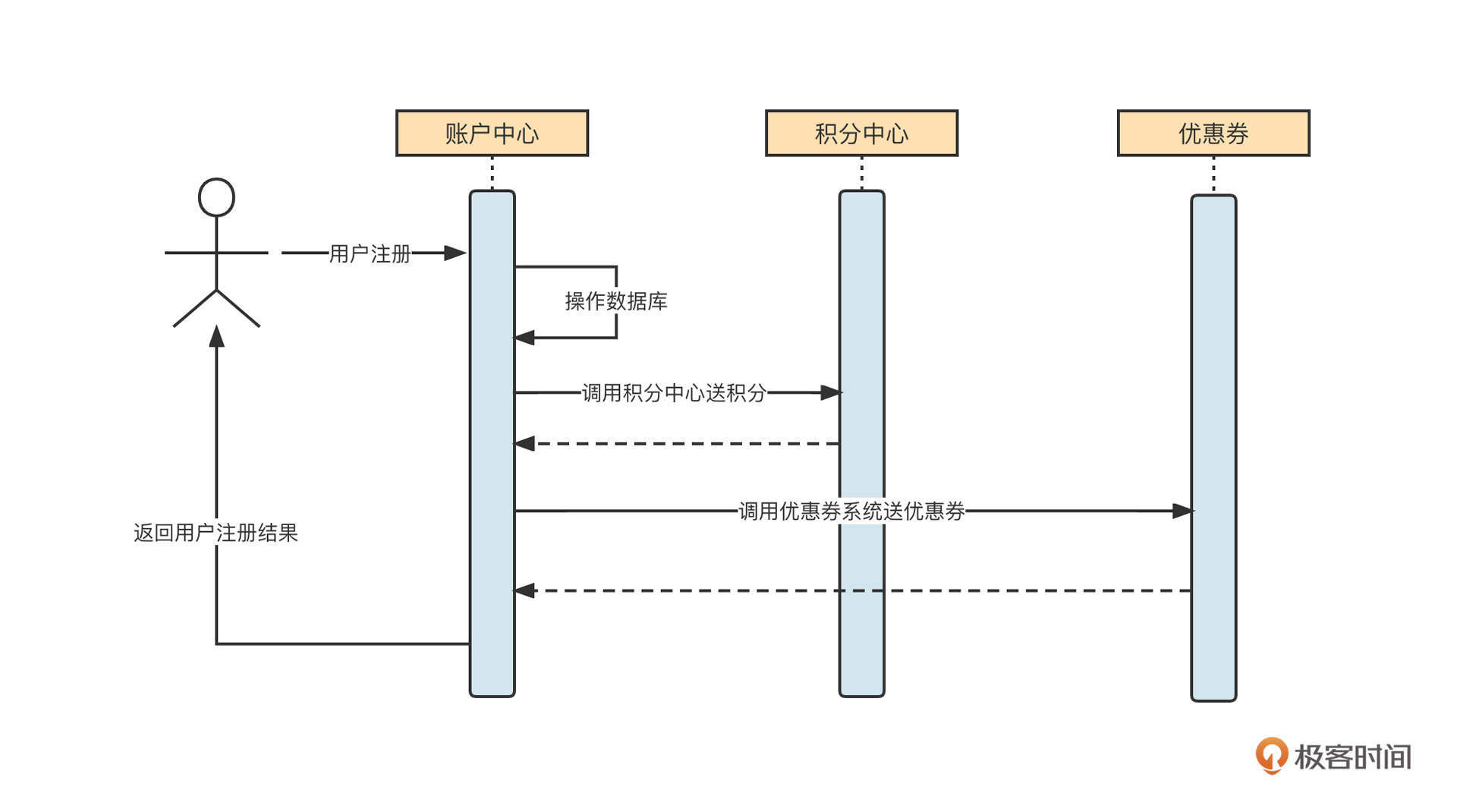
我们简单看一下这个流程。
- 用户在网站前端注册页面填写相关信息,然后调用账号中心服务,注册账号。
- 账户中心首先执行用户注册逻辑处理(例如判断用户是否已注册、是否符合注册条件等),然后写入到数据库。
- 注册成功后,需要调用积分中心(赠送积分接口)给用户送积分。
- 送完积分后,再调用优惠券相关接口,为用户赠送优惠券。
- 成功送完积分、优惠券后,向用户返回“注册成功”。
从架构角度看,上面这个实现方法有一个非常严重的问题,那就是可扩展性低。
例如,如果要在春节期间调整活动策略,在发送积分的同时,还需要额外发送新春大礼包,开发人员为了实现这一功能,就不得不修改用户注册流程,并重新部署用户注册模块。
从功能维度来看,这次需求的变更集中在活动相关的内容。用户注册本身的逻辑并未发生变化,但由于用户注册逻辑与活动模块存在耦合,两个模块必须一起调整和发布,这就对系统稳定性造成了影响。
另外,调用积分、优惠券两个远程RPC请求让用户注册主流程变长,在高并发场景下,用户注册这一环容易成为系统瓶颈。
要解决上面这两个明显的设计缺陷,常用的方案是引入消息中间件,让用户注册主流程和商家活动异步解耦合。改造后的时序图如下:
账户中心完成用户注册相关逻辑后,会向MQ发送一条消息到MQ服务器,然后就直接给用户返回“注册成功”。赠送优惠券、积分等与活动相关的需求我们可以异步执行,这样,无论后续互动逻辑发生什么变化,账户中心都不需要发布新版本。
引入送积分服务(MQ消费者应用)和送优惠券服务(MQ消费者应用)会订阅消息,并根据消息调用积分中心、优惠券中心的服务。如果后续活动发生变化,例如取消送积分活动但开始赠送新春大礼包,那我们只需停止送积分服务应用,增加送新春大礼包的消费者应用,就可以真正做到对新增开放,对修改关闭。
消息中间件的另外一个常用场景是削峰填谷。我们来看一个外卖骑手送餐的场景。它的设计架构图如下:
我们分别说明一下“创建订单流程”和“查询订单信息”两个流程,探究一下这个方案的精髓。
先来看创建订单流程。
- 用户在App中下单,App会调用网关相关接口创建订单,网关接收到请求后,并不是直接调用内部商户订单中心来创建订单接口,而是先发送一条消息到MQ。
- 商户接单模块(Consumer)订阅MQ中的消息,处理消息的时候调用内部商户订单中心创建订单接口,创建一条真正的订单数据到数据库。
- 创建订单后,商户订单中心将再发送一条消息到MQ服务器。然后骑手分配模块(Consumer)订阅消息,调用派单服务相关接口,引导骑手进行外卖配送。
- 同时,数据同步组件(Canal)将数据库中的数据准实时同步到Es服务器。
为什么网关不直接调用外部的创建订单接口,而是将数据先写入到MQ中呢?
我们不妨设想一下,商户订单中心支持的最大并发为1w/tps。如果某一个业务高峰期,从网关进入的流量突然飙升到1.5w/tps,而且持续了10分钟,商户订单系统会直接崩溃,造成服务不可用等严重故障!
那该如何解决呢?
有人可能会说,我们可以使用限流机制保护商户订单系统。例如,我们只允许9000TPS的流量从网关进入到商户订单中心,直接拒绝多余的流量,让客户端重试。这确实可以解决问题,但会带来经济损失和糟糕的用户体验。
这个时候我们有一个更加友好的解决方案:引入消息中间件。
引入消息中间件的目的是让它来扛住海量流量,流量先进入到消息队列中,然后消费端下游系统可以慢慢消费消息中间件中的数据,这样能有效保护下游系统不被瞬时的流量击破。这种方案可能带来的最坏结果就是,消费这些消息会存在延迟。但这些订单都可以成功创建,真正的交易行为已经产生了。接下来要做的就是根据实际情况扩容或者缩容,尽快将积压的数据处理掉。
不过我们这个时候引入消息中间件,其实潜台词是它们的性能必须满足下面几个基本要求:高吞吐量、低延迟,还要具体消息堆积能力。
我们再看一下订单查询流程:
- 用户在App端发起订单查询,App会调用网关的订单查询接口,网关再将请求转发到内部的订单查询服务;
- 订单查询服务不是在MySQL数据库,而是直接查询Es中的数据。
这里一个设计的亮点是,引入了数据同步组件Canal,将MySQL数据库中的数据实时同步到了Es。这样查询订单时只查Es就可以了,实现了订单写入与订单查询在异构数据源的读写分离。
消息中间件的技术选型
在这节课的最后,我们来看看如何选择消息中间件。
目前消息中间件领域主要的中间件包括RocketMQ、Kafka和RabbitMQ,我们先来看一下这张功能对比图:
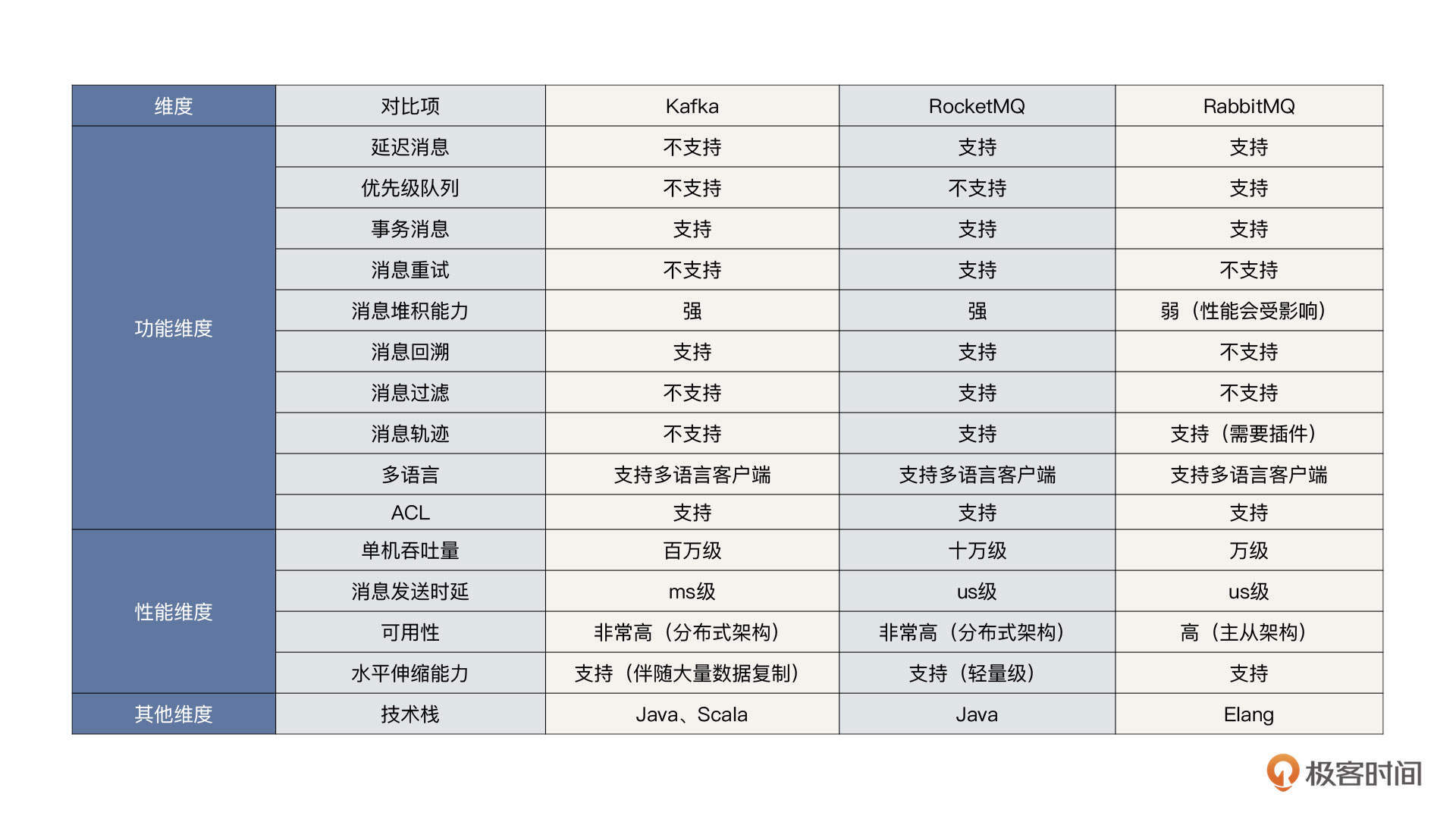
结合上面这张图,我们再对比分析一下。
首先,我认为功能级别不具备一票否决权。
例如,RabbitMQ支持优先级队列,而RocketMQ、Kafka不支持,那么如果我们的项目中有优先级队列的使用诉求,我们就必须将Kafka、RocketMQ排除掉,选择使用RabbitMQ吗?我是不建议这样做的,任何涉及到功能的短板,都可以通过其他方式实现。
但我也并不是说功能特性就一点都不重要。这一点我在后面讨论RocketMQ与Kafka的选型时会再次谈到。
其次,我认为在选型时要特别注意中间件的性能和扩展性。
因为随着业务不断地发展,性能问题会越来越突出,而且性能问题都具有隐蔽性,一旦发生,破坏性大,影响程度深,让人防不胜防。
例如,RabbitMQ的消息堆积能力不强,一旦消费端无法及时将消息处理掉,会极大影响消息服务器发送消息的性能。这一点是非常致命的,因为引入消息中间件的目的就是抵挡住洪峰流量,如果消息中间件因为积压问题影响了消息的发送,那是万万不可取的。
因此,从性能的角度来看,RocketMQ和Kafka比RabbitMQ的表现更好。
另外一个重要的因素也不得不加以考虑,那就是中间件使用的编程语言。
在使用中间件时一般都会遇到很多问题,一个非常行之有效的方法就是深入研究源码。这时候,如果中间件的编写语言和团队技术栈不匹配,将会极大地增加深入研究这款中间件的难度。如果团队对中间件的掌控能力很弱,自然很难保持中间件的稳定运行。
在进行具体的选型时,我们可以结合自己团队的实际情况。
- 如果公司或团队的技术栈以Golang为主,建议选择RabbitMQ,RabbitMQ在性能上的缺陷可以通过搭建多套集群加以规避。
- 如果公司或团队的技术栈以Java为主,我建议使用Kafka或RocketMQ。RocketMQ和Kafka都是性能优秀的中间件,在这两者之间进行选择时可以更多地关注功能特性。RocketMQ提供了消息重试、消息过滤、消息轨迹、消息检索等功能特性,特别是RocketMQ的消息检索功能,因此RocketMQ很适合核心业务场景。而kafka更加擅长于日志、大数据计算、流式计算等场景。
总结
好了,这节课就讲到这里。
刚才,我们结合案例学习了消息中间件的两大经典使用场景:异步解耦与削峰填谷。最后重点阐述了消息中间件的选型问题。
在选择消息中间件时,需要格外注意以下三点:
- 功能级别不具备一票否决权;
- 选型时要特别注意中间件的性能与扩展性;
- 需要注重团队技术栈与中间件编程语言的匹配度。
在这三点之上,我们就可以根据实际情况选择一款适合自己团队的消息中间件了。
课后题
最后,我还是照例给你留一道思考题。
刚才我们说异步解耦是消息中间件的常见使用场景。在电商注册送积分这个场景中,引入消息中间件能在活动需求不断变化的同时,保证用户注册主流程的稳定性。但你知道这会带来哪些问题吗?我们又该如何解决它们呢?
欢迎你在留言区与我交流讨论,我们下节课见!
14 |性能之道:RocketMQ与Kafka高性能设计对比
作者: 丁威

你好,我是丁威。
RocketMQ和Kafka是当下最主流的两款消息中间件,我们这节课就从文件布局、数据写入方式、消息发送客户端这三个维度对比一下实现kafka和RocketMQ的差异,通过这种方式学习高性能编程设计的相关知识。
文件布局
我们首先来看一下Kafka与RocketMQ的文件布局。
Kafka 的文件存储设计在宏观上的布局如下图所示:
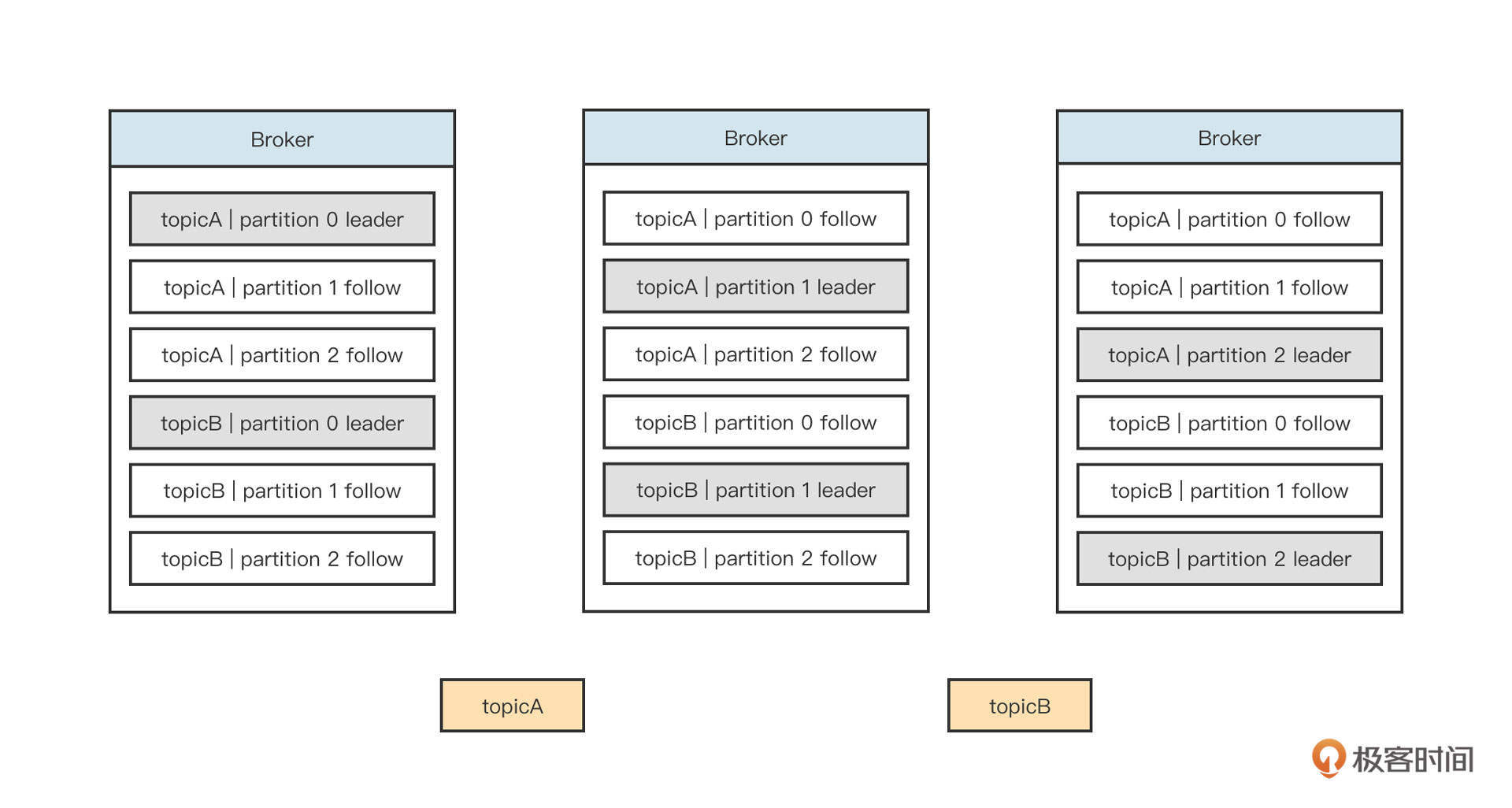
我们解析一下它的主要特征。
- 文件的组织方式是“ topic + 分区”,每一个 topic 可以创建多个分区,每一个分区包含单独的文件夹。
- 分区支持副本机制,即一个分区可以在多台机器上复制数据。topic 中每一个分区会有 Leader 与 Follow。Kafka的内部机制可以保证 topic 某一个分区的 Leader 与Follow 不在同一台机器上,并且每一台Broker 会尽量均衡地承担各个分区的 Leade。当然,在运行过程中如果Leader不均衡,也可以执行命令进行手动平衡。
- Leader 节点承担一个分区的读写,Follow 节点只负责数据备份。
Kafka 的负载均衡主要取决于分区 Leader 节点的分布情况。分区的 Leader 节点负责读写,而从节点负责数据同步,如果Leader分区所在的Broker节点宕机,会触发主从节点的切换,在剩下的 Follow 节点中选举一个新的 Leader 节点。这时数据的流入流程如下图所示:
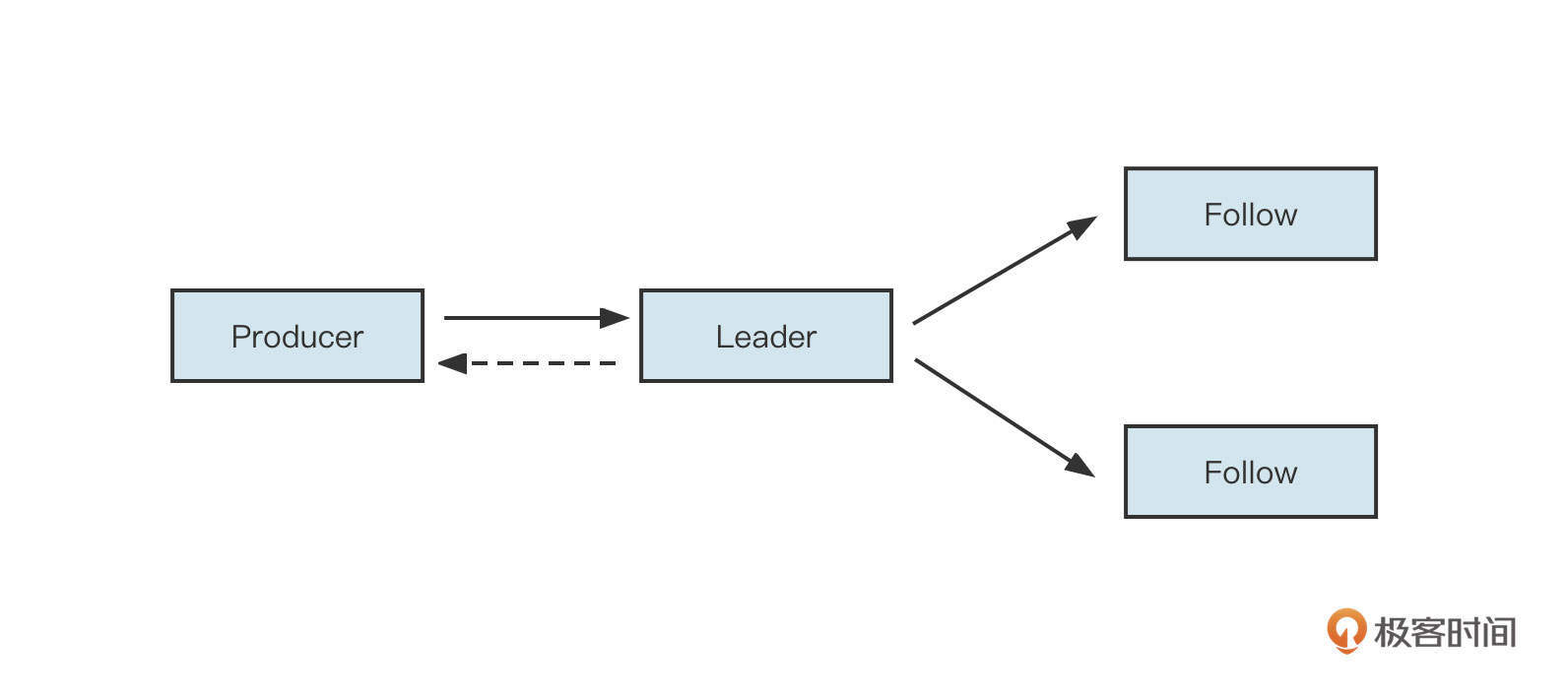
分区 Leader 收到客户端的消息发送请求后,可以有两种数据返回策略。一种是将数据写入到 Leader 节点后就返回,还有一种是等到它的从节点全部写入完成后再返回。这个策略选择非常关键,会直接影响消息发送端的时延,所以 Kafka 提供了 ack 这个参数来进行策略选择:
- 当ack = 0时,不等Broker端确认就直接返回,即客户端将消息发送到网络中就返回“发送成功”;
- 当ack = 1时,Leader 节点接受并存储消息后立即向客户端返回“成功”;
- 当ack = -1时,Leader节点和所有的Follow节点接受并成功存储消息,再向客户端返回“成功”。
我们再来看一下RocketMQ 的文件布局:
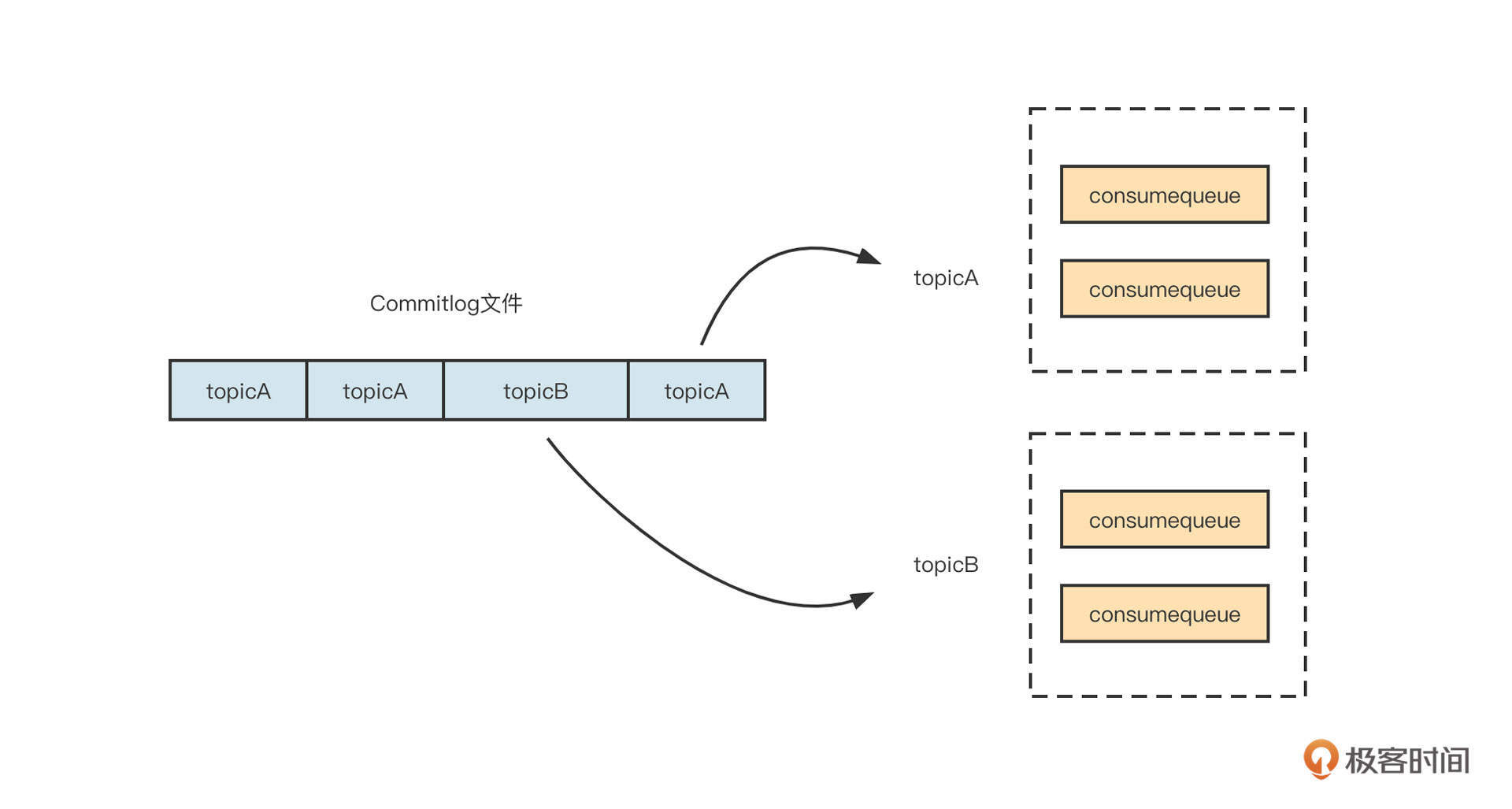
RocketMQ 所有主题的消息都会写入到 commitlog 文件中,然后基于 commitlog 文件构建消息消费队列文件(Consumequeue),消息消费队列的组织结构按照 /topic/{queue} 来组织。从集群的视角来看如下图所示:
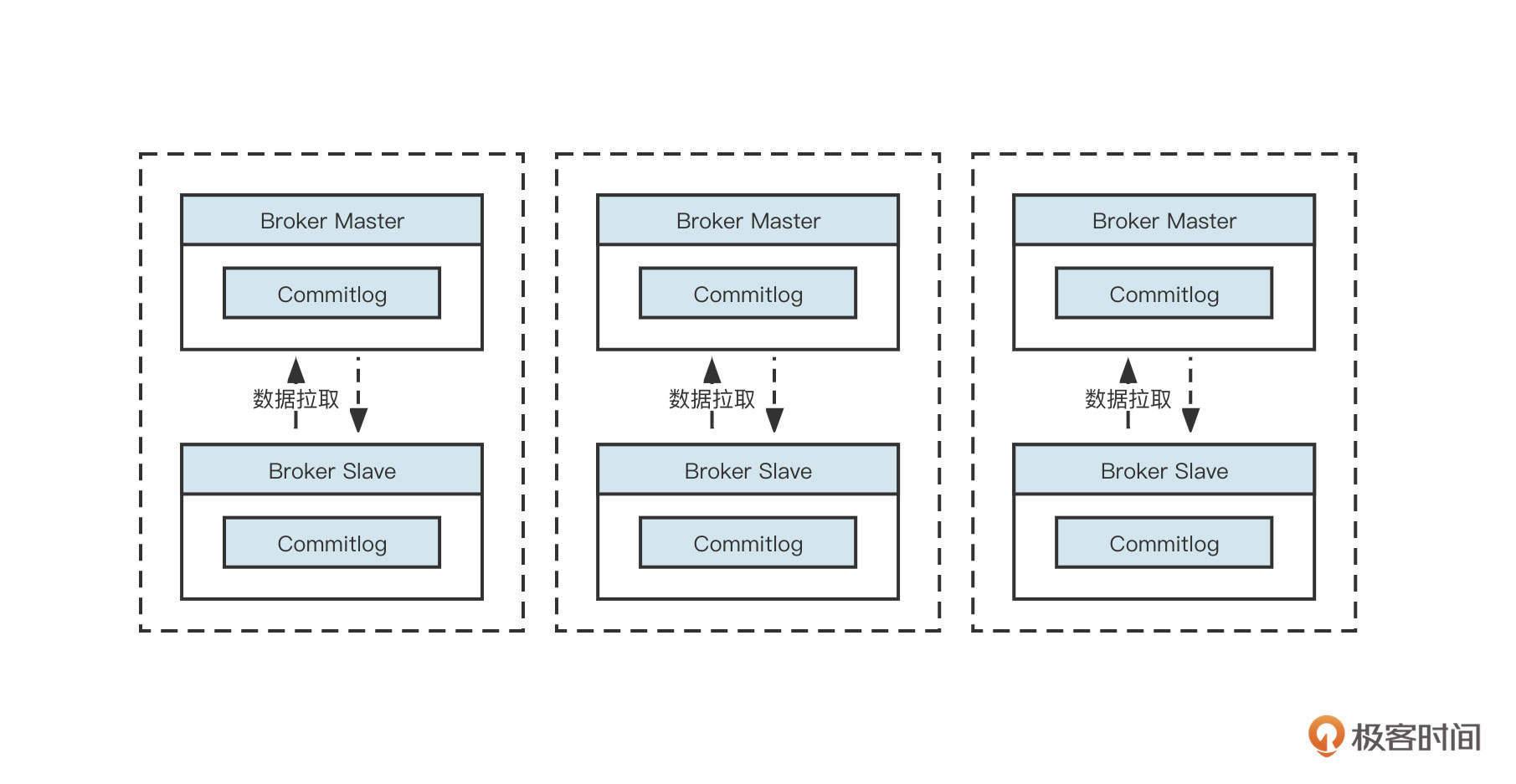
RocketMQ 默认采取的是主从同步架构,即Master-Slave方式,其中Master节点负责读写,Slave节点负责数据同步与消费。
值得注意的是,RocketMQ4.5引入了多副本机制,RocketMQ的副本机制与kafka的多副本两者之间的不同点是RocketMQ的副本维度是Commitlog文件,而kafka是主题分区级别。
我们来看看Kafka和RocketMQ在文件布局上的异同。
Kafka中文件的布局是以 Topic/partition为主 ,每一个分区拥有一个物理文件夹,Kafka在分区级别实现文件顺序写。如果一个Kafka集群中有成百上千个主题,每一个主题又有上百个分区,消息在高并发写入时,IO操作就会显得很零散,效果相当于随机IO。也就是说,Kafka 在消息写入时的IO性能,会随着 topic 、分区数量的增长先上升,后下降。
而 RocketMQ 在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入 commitlog 文件, topic 和 分区数量的增加不会影响写入顺序。
根据我的实践经验,当磁盘是SSD时,采用同样的配置,Kafka的吞吐量要超过RocketMQ,我认为这里的主要原因是单文件顺序写入很难充分发挥磁盘IO的性能。
除了在磁盘顺序写方面的差别,Kafka和RocketMQ的运维成本也不同。由于粒度的原因,Kafka 的topic扩容分区会涉及分区在各个Broker的移动,它的扩容操作比较重。而RocketMQ 的数据存储主要基于commitlog文件,扩容时不会产生数据移动,只会对新的数据产生影响。因此,RocketMQ的运维成本相对Kafka更低。
不过,Kafka和RocketMQ也有一些共同点。Kafka的ack参数可以类比RocketMQ的同步复制、异步复制。
- Kafka的“ack参数=1”时,对标RocketMQ的异步复制,有数据丢失的风险;
- kafka的“ack参数=-1”时,对标RocketMQ的同步复制;
- Kafka的“ack参数=0”时,对标RocketMQ消息发送方式的 oneway 模式,适合日志采集场景。
在业务领域通常是不容许数据丢失的。但如果这些数据容易重推,就可以使用ack=1,而不使用ack=-1,因为ack=-1时的性能较低。
例如,我们在公司开发数据同步中间件时,都是基于数据库Binlog日志同步到Es、MySQL、Oracle等目标端,由于同步任务支持回溯,故通常将ack设置为1。
数据写入方式
聊完数据文件布局,我们再来看一下Kafka、和RocketMQ的服务端是如何处理数据写入的。
我们还是先来看Kafka。
Kafka服务端处理消息写入的代码定义在MemoryRecords的writeTo方法中,具体代码截图如下(具体是调用入口LogSegment的append方法):
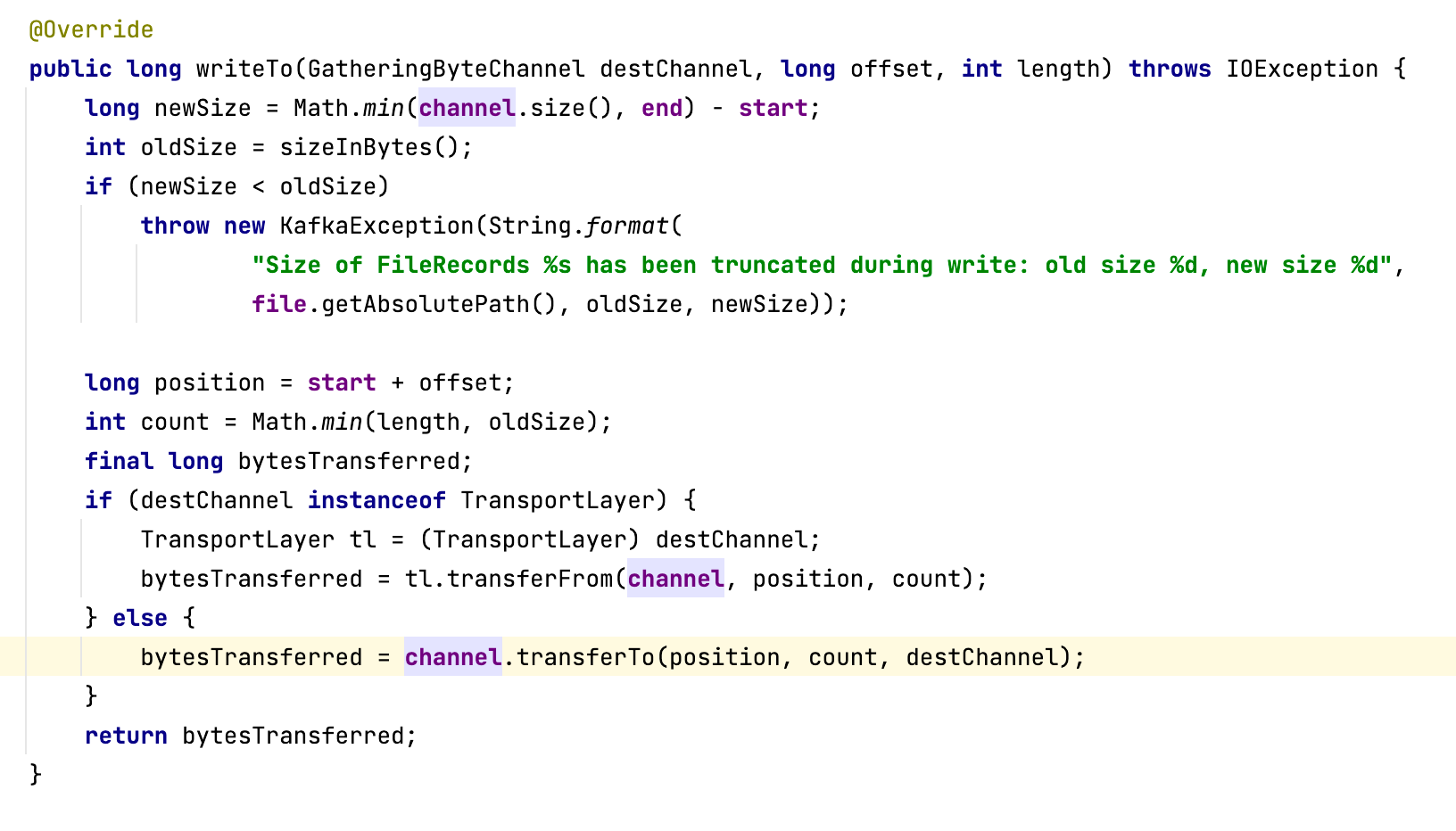
Kafka服务端写入消息时,主要是调用FileChannel的transferTo方法,该方法底层使用了操作系统的sendfile系统调用。
而RocketMQ的消息写入支持内存映射与FileChannel两种写入方式,如下图所示:
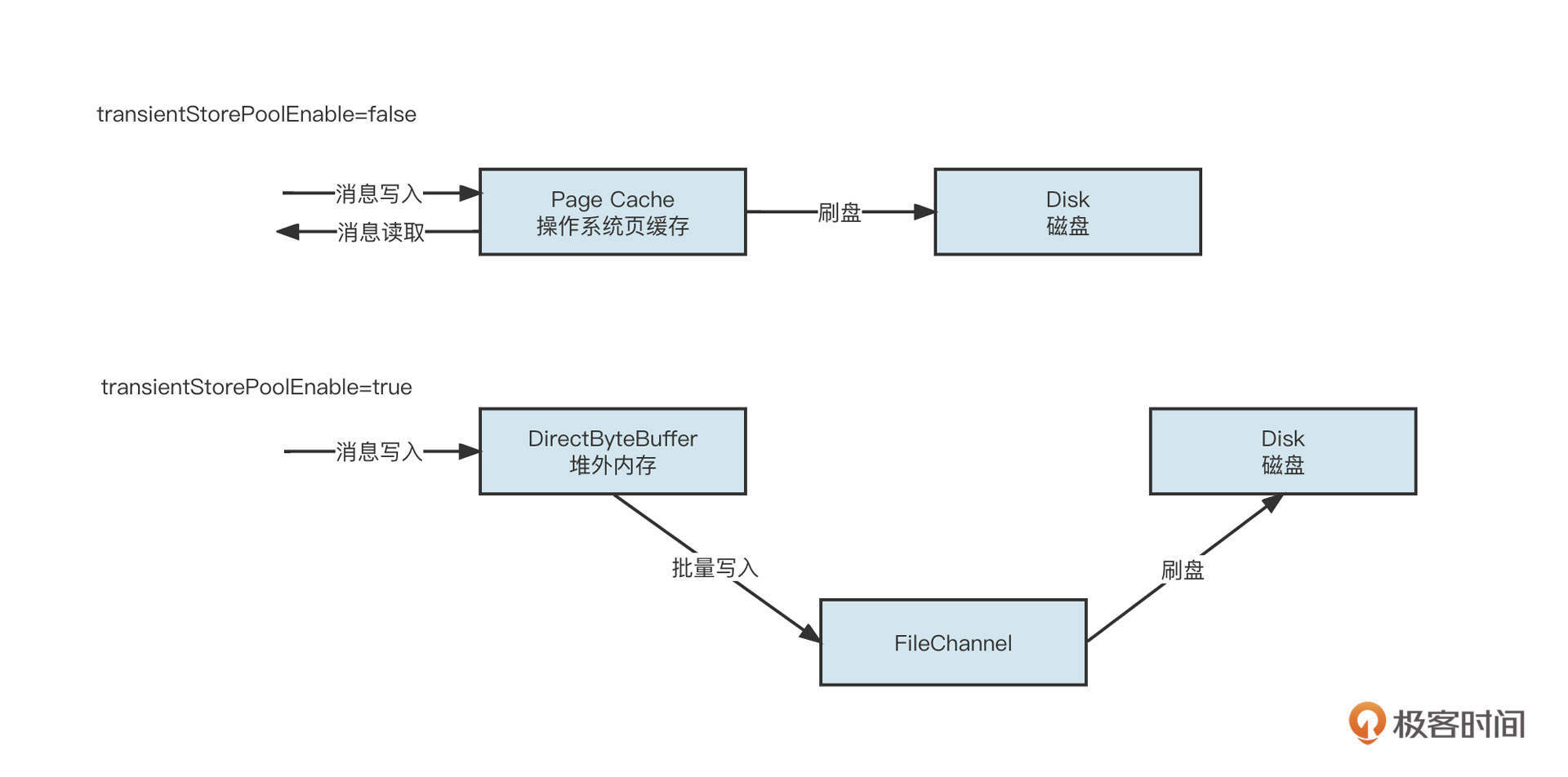
也就是说,如果将参数tranisentStorePoolEnable设置为false,那就先将消息写入到页缓存,然后根据刷盘机制持久化到磁盘中。如果将参数设置为true,数据会先写入到堆外内存,然后批量提交到FileChannel,并最终根据刷盘策略将数据持久化到磁盘中。
值得注意的是,RocketMQ与Kafka都支持通过FileChannel方式写入,但RocketMQ基于FileChannel写入时,调用的API并不是transferTo,而是先调用writer,然后定时flush 刷写到磁盘,具体调用入口为MappedFile。代码截图如下:
直接调用FileChannel的transferTo方法比write方法性能更优,因为transferTo底层使用了操作系统的sendfile系统调用,能充分发挥块设备的优势。
根据我的实践经验,sendfile 系统调用相比内存映射多了一个从用户缓存区拷贝到内核缓存区的步骤,但当内存写入超过64K时, sendfile 的性能往往更高,故Kafka在服务端的写入比RocketMQ会有更好的表现。
消息发送
最后我们再从客户端消息发送这个角度看一下两款中间件的差异。
Kafka消息发送客户端采用的是双端队列,还引入了批处理思想,它的消息发送机制如下图所示:
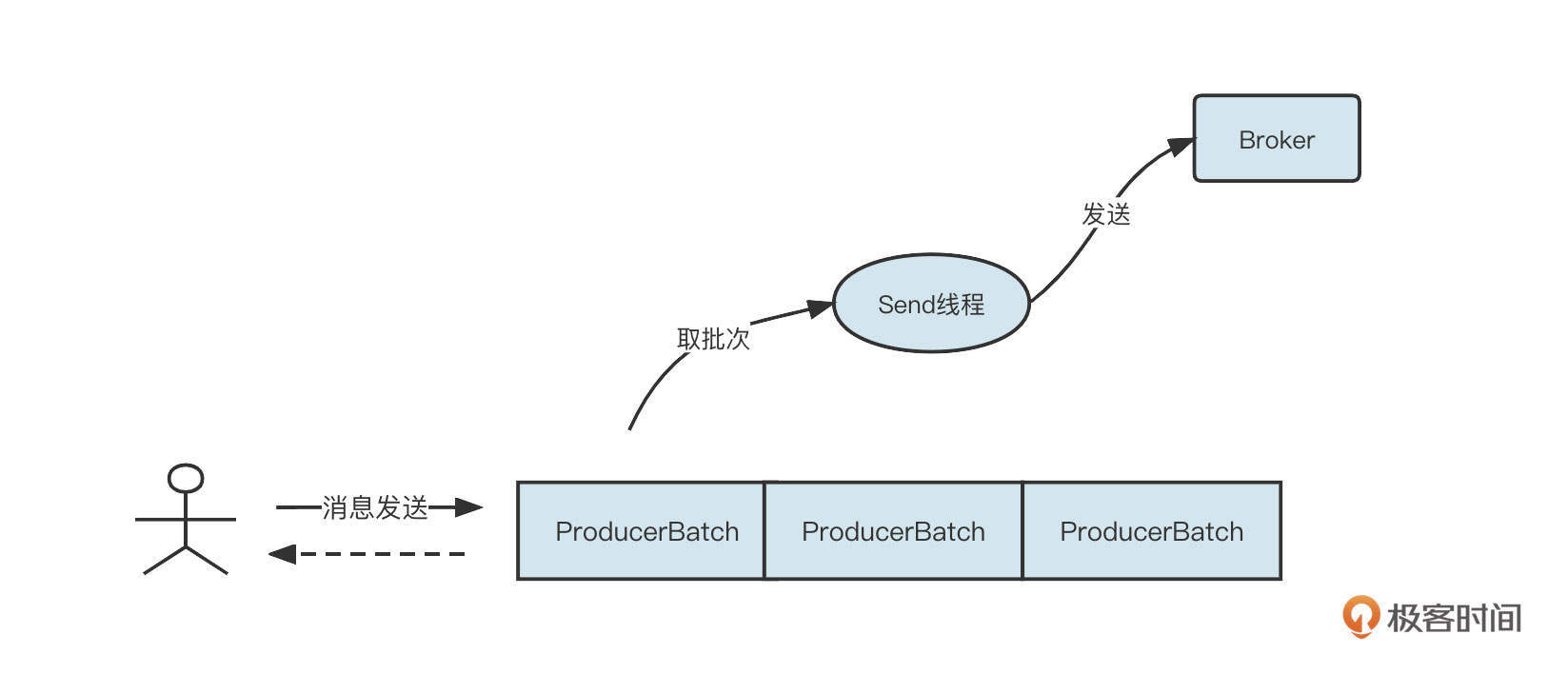
当客户端想要调用Kafka的消息发送者发送消息时,消息会首先存入到一个双端队列中,双端队列中单个元素为 ProducerBatch,表示一个发送批次,其最大值受参数 batch.size 控制,默认为 16K。
然后,Kafka客户端会单独开一个 Send 线程,从双端队列中获取发送批次,将消息按批发送到Kafka集群中。Kafka还引入了linger.ms参数来控制Send线程的发送行为,代表批次要在双端队列中等待的最小时长。
如果将linger.ms设置为0,表示立即发送消息;如果将参数设置为大于0,那么发送线程在发送消息时只会从双端队列中获取等待时长大于该值的批次。 注意,linger.ms 参数会延长响应时间,但有利于增加吞吐量。有点类似于 TCP 领域的 Nagle 算法。
Kafka的消息发送,在写入ProducerBatch时会按照消息存储协议组织数据,在服务端可以直接写入到文件中。
RocketMQ的消息发送在客户端主要是根据路由选择算法选择一个队列,然后将消息发送到服务端。消息会在服务端按照消息的存储格式进行组织,然后进行持久化等操作。
Kafka相比RocketMQ有一个非常大的优势,那就是它的消息格式是在客户端组装的,这就节约了 Broker端的CPU压力,这两款中间件在架构方式上的差异有点类似ShardingJDBC与MyCat的区别。
Kafka在消息发送端的另外一个特点就是,引入了双端缓存队列。可以看出,Kafka的设计始终在追求批处理,这能够提高消息发送的吞吐量,但与之相对的问题是,消息的响应时间延长了,消息丢失的可能性也加大(因为Kafka追加到消息缓存后会返回“成功”,但是如果消息发送方异常退出,会导致消息丢失)。
我们可以将Kafka中linger.ms=0的情况类比RocketMQ消息发送的效果。但Kafka通过调整batch.size与linger.ms两个参数来适应不同场景,这种方式比RocketMQ更为灵活。例如,日志集群通常会调大batch.size与linger.ms参数,充分发挥消息批量发送带来的优势,提高吞吐量;但如果有些场景对响应时间比较敏感,就可以适当调低linger.ms的值。
总结
好了,这节课就讲到这里。刚才,我们从文件布局、服务端数据写入方式、客户端消息发送方式三个维度,对比了Kafka和RocketMQ各自在追求高性能时所采用的技术。综合对比来看,在同等硬件配置一下,Kafka的综合性能要比RocketMQ更为强劲。
RocketMQ和Kafka都使用了顺序写机制,但相比Kafka,RocketMQ在消息写入时追求极致的顺序写,会在同一时刻将消息全部写入一个文件,这显然无法压榨磁盘的性能。而Kafka是分区级别顺序写,在分区数量不多的情况下,从所有分区的视角来看是随机写,但这能重复发挥CPU的多核优势。因此,在磁盘没有遇到瓶颈时,Kafka的性能要优于RocketMQ。
同时,Kafka在服务端写入时使用了FileChannel的transferTo方法,底层使用sendfile系统调用,比普通的FileChannel的write方法更有优势。结合压测效果来看,如果待写入的消息体大小超过64K,使用sendfile的块写入方式甚至比内存映射拥有更好的性能。
在消息发送方面,Kafka的客户端则充分利用了批处理思想,比RocketMQ拥有更高的吞吐率。
课后题
最后,我还是给你留一道思考题。
通过了解RocketMQ和Kafka的实现机制,我们知道RocketMQ还有很大的进步空间。你认为应该如何优化RocketMQ?
欢迎你在留言区与我交流讨论,我们下节课见!
15|案例:消息中间件如何实现蓝绿?
作者: 丁威

你好,我是丁威。
我们这节课结合一个真实的生产环境案例,来看看消息中间件如何实现蓝绿发布。我们会提到消息中间件的设计背景和隔离机制,在此基础上探究基于消息属性和消息主题分别如何实现蓝绿发布。
设计背景
消息中间件在分布式架构体系中的应用非常广泛,要想实现蓝绿发布,只在微服务调用层面实现还远远不够。
在进行具体的方案设计之前,我们还是先来看一下我们这个项目中消息中间件的部署情况:
这里有四个应用,简单解释一下。
- 应用1支持蓝绿发布,并且处理完业务后,需要向消息中间件中的topic_A主题发送消息。
- 应用2不支持蓝绿发布,但同样需要在处理完业务后,向消息中间件中的topic_A发送消息。
- 应用3不支持蓝绿发布,需要处理完业务逻辑后,向消息中间件中的主题topic-B发送消息。
- 应用4中创建了两个消费组,其中consumer_group_a订阅topicA,支持接入蓝绿;而consumer_group_b没有接入蓝绿。
这就是在设计蓝绿发布方案之前,我们这个项目的现状。
消息中间件隔离机制
那么怎么基于这一条件来设计和实施蓝绿方案呢?这又涉及到一个隔离机制的问题。因为无论是蓝绿发布还是全链路压测,需要着重解决的一个问题就是消息的隔离性。蓝绿发布的本质就是对消息进行分类,蓝颜色的消息只能被蓝颜色的消费者消费,绿颜色的消息只能被绿颜色的消费者消费。
消息中间件领域通常有“基于消息主题”和“基于消息属性”两种隔离机制。我们先来看第一种隔离机制,基于消息主题的物理隔离机制:
基于主题的隔离机制在消息服务端是分开存储的,属于物理层面的隔离。在消息消费端,由于应用使用不同的消费组进行消费,每一个消费组在物理层面也是互不影响的,每一个消费组有独立的线程池、消费进度等。
消息中间件中的另外一种隔离机制是基于消息属性的。例如,蓝绿两种颜色的消息使用的是同一个主题,但我们可以在消息中添加一个属性,标识这条消息的颜色。其存储示意图如下:
这样,不同属性的消息就可以共用一个主题了。消息发送端在发送消息时,会为消息设置相应的属性,将它存储到消息的属性中。然后单个消费端应用会创建蓝绿两个消费组,都订阅同一个主题。消费组拉取到消息后,需要先解码找到对应的消息属性,蓝颜色消费者只真正处理属性为BLUE的消息,那些属性为GREEN的消息会默认向服务端返回“消费成功”。这样就在客户端实现了消息过滤机制。
目前主流消息中间件的隔离机制都是基于消息属性的。在消息发送端为消息指定属性的示例代码如下:
1 | //RocketMQ示例 |
接下来我会基于这两种隔离机制分别给出蓝绿发布的设计方案。
基于消息属性的蓝绿设计方案
我们这个方案是基于RocketMQ展开的,Kafka的设计方案类似。所以如果你使用的是Kafka,完全可以进行知识迁移。
基于消息属性的隔离机制的一个显著的特点是,蓝绿消息使用的是同一个主题。因此我们需要在不同环境的生产者发送消息时,为消息设置不同的颜色。
和在微服务领域实现蓝绿发布一样,我们通过系统参数为应用设置所属环境:
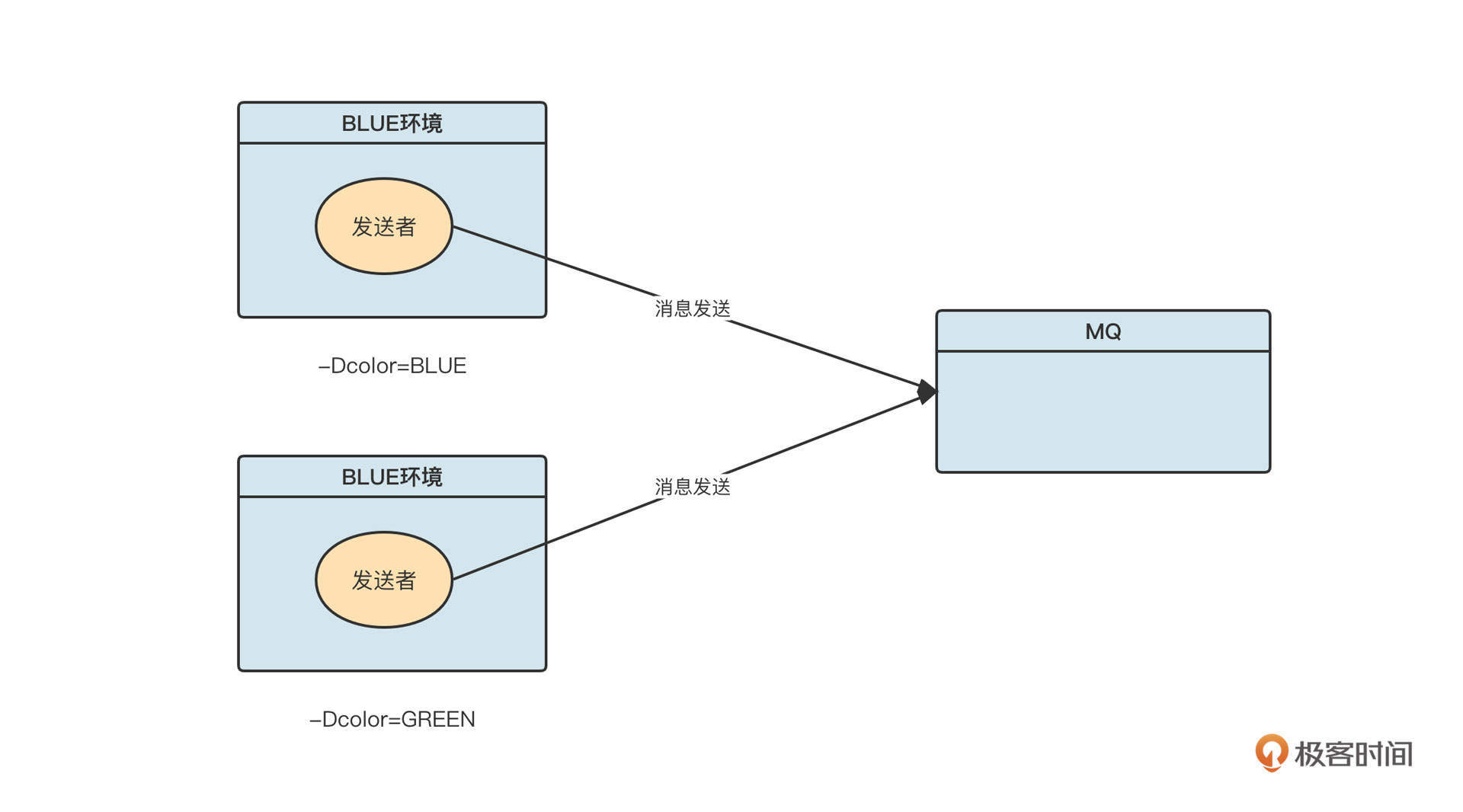
通常每一家公司都会有一个统一的开发框架,会基于目前主流的RocketMQ、Kafka客户端进行封装,或者使用类似rocketmq-spring这样的开源类库。为了防止对业务代码进行侵入,通常会采用拦截器机制,拦截消息发送API,然后在拦截器中根据系统参数,为消息设置对应的属性。从系统参数中获取颜色值的示例代码如下:
1 | private static final String COLOR_SYS_PROP = "color"; |
当不同环境的消息发送者将消息发送到消息服务器后,消费端就要按颜色将消费分开了。
虽然消费端的隔离机制是通过不同的消费组来实现的,每一个消费组拥有自己独立的消费者线程池、消费进度,组与组之间互不影响。但是消费端不能简单粗暴地用系统参数来区分消费组的颜色,因为一个应用中可能存在多个消费组,这些消费组并不都开启了蓝绿机制。
所以基于消费组的蓝绿定义,首先需要在消费者的元信息中定义。例如,我们公司在申请消费组时,可以根据环境为消费组设置是否启用蓝绿机制。如下图所示:
蓝绿发布状态可选择:蓝、绿、所有。这里的“所有”表示消费组未开启蓝绿,选择“蓝”或“绿”都表示消费组开启蓝绿。
消费组是如何进行消息过滤的呢?我们来看下部署示意图:
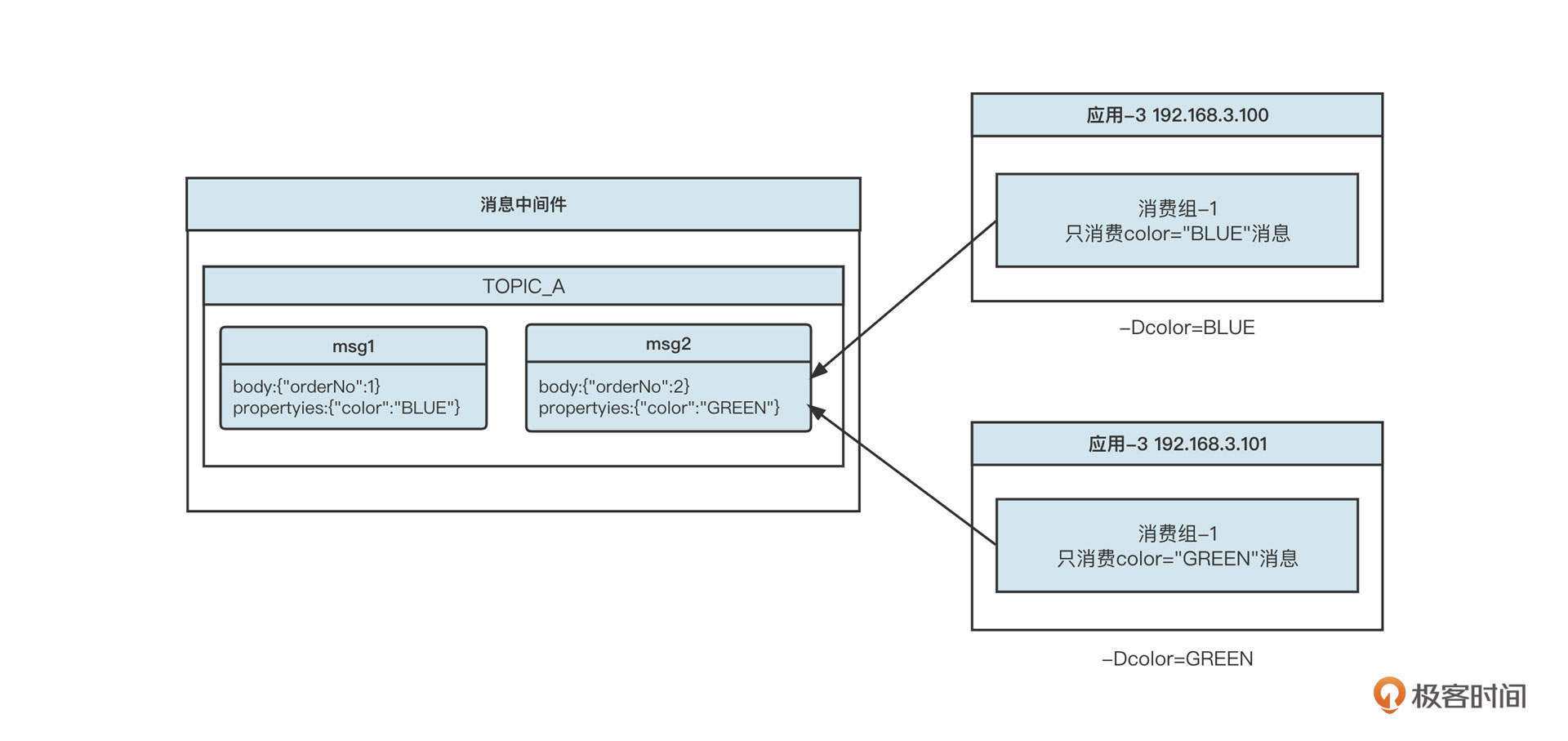
我们看应用3会部署在蓝、绿两个环境,但是在原始的镜头项目代码中我们只会定义一个基本的消费组,例如dw_test_consumer_group,蓝绿发布要求我们这套代码用不同的系统属性定义后,就能分别实现消息的过滤。
例如,我们在代码中定义一个消费组,示例代码如下(这段代码来源于中通快递开源的消息中间件运维平台,封装了Kafka/RocketMQ的消息发送与消息消费、可视化监控与告警):
1 | public void testSubscribe() { |
那我们如何动态开启蓝绿发布机制呢?我总结了下面两个实现要点。
- 应用启动时,首先获取系统参数color的值(如果有设置),并根据设置的值改写原消费组的名称。如果color的值为BLUE,那我们在调用RocketMQ底层DefaultMqPushConsumer时,传入的消费组名称为 _BLUE_dw_test_consumer_group;如果color的值为GREEN,那最终会创建的消费组名称就是 _GREEN_dw_test_consumer_group。
- 消费者启动后开始处理消费,在真正调用用户定义的消息业务处理器(MessageListener)之前,需要将消息进行解码,然后提取消息属性中color的值,用mqProColor表示,如果mqProColor的值与系统参数color中的值相等,就调用用户定义的消息业务处理器。否则就认为消费成功,直接给MQ服务器返回“成功”,相当于跳过这条消息的处理。
这么乍一看,蓝颜色的消费者消费color=BLUE的消息,绿颜色的消费者消费color=GREEN的消息,这不是很“完美”地解决了蓝绿发布的问题了吗?
事实不是这样的。因为topic中发送的消息有可能不带颜色,例如应用-1需要发送消息到TOPIC_A中, 这个应用接入了蓝绿,会发送蓝色或者绿颜色的消息。但应用-2没有接入蓝绿,所以应用-2发送的消息是不包含颜色的。按照上面的方案,这部分消息将无法被消费,最终结果就是:消息丢失。
那怎么解决消息消费丢失的问题呢?我们可以在消费组元信息中定义不带颜色的消息由哪个环境来消费。
我在公司实践时,消费者的蓝绿发布状态有下面三个值。
- 所有: 表示该消费组未接入蓝绿。
- 蓝:表示该消费组接入蓝绿,并且消息属性中未带颜色的消息由蓝环境的消费者进行消费。
- 绿:表示该消费组接入蓝绿,并且消息属性中未带颜色的消息由绿环境的消费者进行消费。
这样定义了之后,应用启动时,如果消费者的蓝绿状态为蓝,我们会同时启动两个消费组,一个消费组为_BLUE_dw_test_consumer_group,用来专门消费蓝颜色的消费者;另外一个消费组为dw_test_consumer_group,用来消费不带颜色的消息。蓝环境的应用在启动时只会创建一个消费组,那就是 _GREEN_dw_test_consumer_group。
同时,我们还支持在蓝绿之间进行切换。如果将消费组的蓝绿状态由BLUE变为GREEN,我们会将原本在蓝环境的dw_test_consumer_group关闭,然后在绿环境中新增一个dw_test_consumer_group消费组。这样,我们就在消息中间件层面实现了蓝绿发布。
基于消息主题的蓝绿设计方案
不过,基于消息属性的蓝绿发布机制存在一个比较严重的问题,那就是一旦开启了蓝绿发布,一份消息就会被多次拉取,这无形中增加了消息服务器的读取请求。示意图如下:
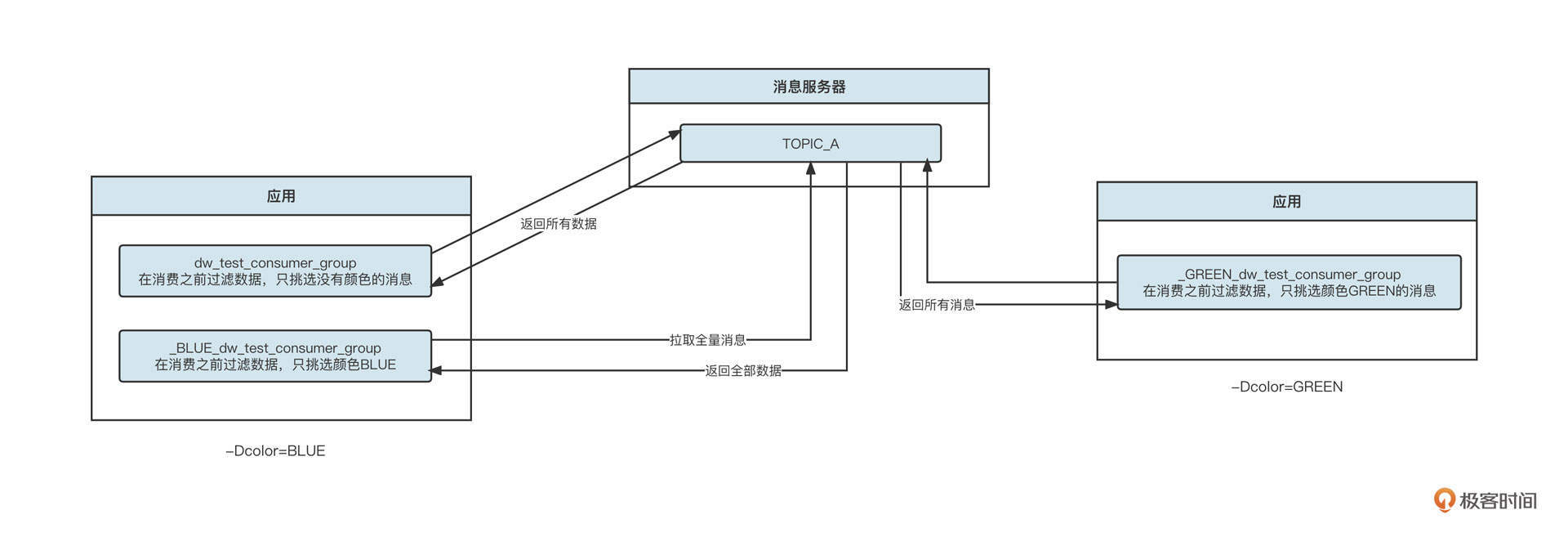
原本代码中只声明了一个消费组dw_test_consumer_group,但我们引入蓝绿发布机制之后,会创建三个消费组,读取流量是原来的三倍,这会给服务端带来较大压力。
造成读流量放大的主要原因是,蓝绿消息在物理存储上并未实现真正隔离,仍然需要在消费端进行过滤。既然如此,如果我们在发送消息的时候就对消息进行隔离,是不是可以避免这种情况?
这就要说到另外一种蓝绿设计方案了,它使用的是基于主题的消息隔离机制。
这种机制在发送消息时,就根据发送者所在的环境将消息发送到不同的主题中。示意图如下:
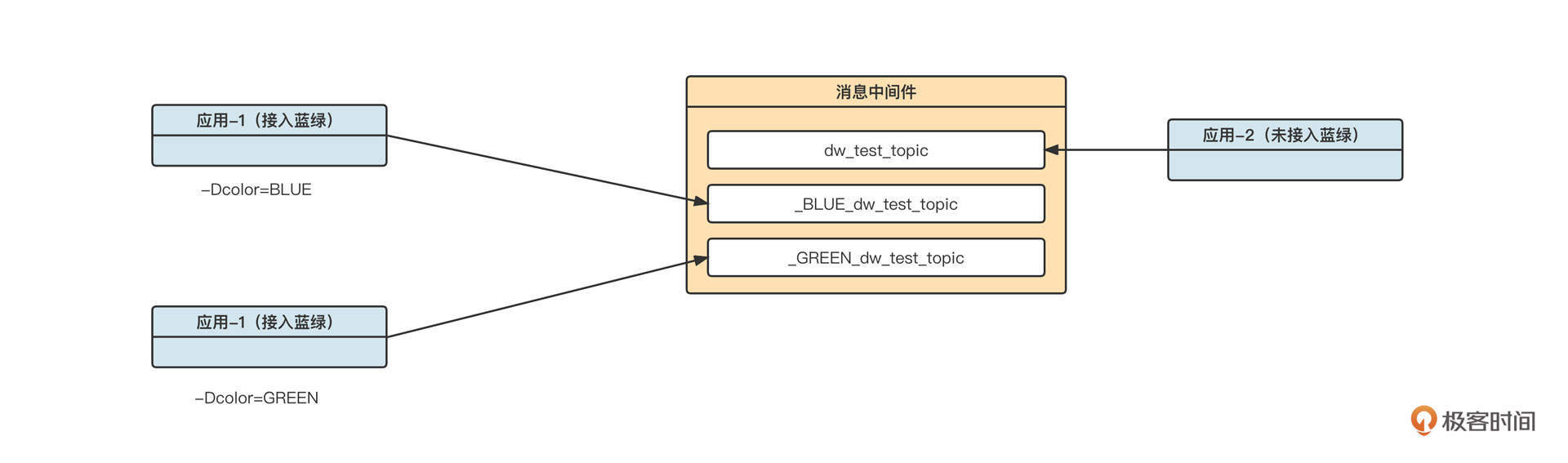
在代码层面,要在发送端改变消息发送的主题名称非常简单。只需要拦截消息发送方法,根据系统变量color的值改写主题的名称就可以了。但是在实践过程中,我们还要避免发送方法的嵌套调用,避免主题名称在一次发送过程中多次被改写,所以在改写主题名称之前,我们还要对代码进行判断:
1 | public static String renameTopicName(String topicName) { |
之后,消费端的隔离机制仍然是为不同的环境创建不同的消费组:
这样,每一个消费组就只会拉取符合条件的消息。因为所有的消息拉取都是有效拉取,所以基于消息隔离而产生的弊端就解决了。
总结
我们这节课首先结合消息中间件在生产环境的部署情况,引出了蓝绿设计需要解决的具体问题,然后介绍了实现蓝绿的两种方案。
我认为,实现蓝绿的关键其实最终都落在了“如何有效隔离消息”这个问题上。
基于消息属性的隔离,是在发送端使用一个主题,在每一条消息中添加一个属性color来存储消息的颜色,而消费端采取不同的消费组来消费消息。其中,蓝颜色的消息由蓝消费组消费,绿颜色的消息由绿消费组消费,没有颜色的消息由默认消费组来消费。这本质上是在消费端将数据从服务端全量拉取下来,然后在消费端进行了一层过滤,各个消费组都会读取到很多无效数据,无形中放大了拉取消息的调用次数。
而基于主题的隔离机制,是在消息发送时就将消息分别发送到不同的主题中,在消费端对各个消费组进行分工。蓝颜色的消费组只订阅蓝颜色主题,绿颜色的消费者只订阅绿颜色的主题,这就实现了有针对性的消费,效率更高。
课后题
学完今天的内容,请你思考下面两个问题。
- 基于消息属性的蓝绿发布机制,支持从“蓝”或“绿”切换到“所有”吗?也就是说,如果原本消费组开启了蓝绿发布,现在又想抛弃蓝绿发布,能不能行呢?这样做存在什么问题?
- 基于主题的过滤机制可以避免读流量的放大,但这个方案也不是完美的,你认为基于主题来实现蓝绿发布存在什么问题?哪些场景适合使用基于主题的蓝绿发布?
欢迎你在留言区与我交流讨论,我们下节课见!
16|案例:如何提升RocketMQ顺序消费性能?
作者: 丁威

你好,我是丁威。
在课程正式开始之前,我想先分享一段我的经历。我记得2020年双十一的时候,公司订单中心有一个业务出现了很大程度的延迟。我们的系统为了根据订单状态的变更进行对应的业务处理,使用了RocketMQ的顺序消费。但是经过排查,我们发现每一个队列都积压了上千万条消息。
当时为了解决这个问题,我们首先决定快速扩容消费者。因为当时主题的总队列为64个,所以我们一口气将消费者扩容到了64台。但上千万条消息毕竟还是太多了。还有其他办法能够加快消息的消费速度吗?比较尴尬的是,没有,我们当时能做的只有等待。
作为公司消息中间件的负责人,在故障发生时没有其他其他补救手段确实比较无奈。事后,我对顺序消费模型进行了反思与改善。接下来,我想和你介绍我是如何优化RocketMQ的顺序消费性能的。
RocketMQ顺序消费实现原理
我们先来了解一下 RocketMQ 顺序消费的实现原理。RocketMQ支持局部顺序消息消费,可以保证同一个消费队列上的消息顺序消费。例如,消息发送者向主题为ORDER_TOPIC的4个队列共发送12条消息, RocketMQ 可以保证1、4、8这三条按顺序消费,但无法保证消息4和消息2的先后顺序。
那RocketMQ是怎么做到分区顺序消费的呢?我们可以看一下它的工作机制:
顺序消费实现的核心要点可以细分为三个阶段。
第一阶段:消费队列负载。
RebalanceService线程启动后,会以20s的频率计算每一个消费组的队列负载、当前消费者的消费队列集合(用newAssignQueueSet表),然后与上一次分配结果(用oldAssignQueueSet表示)进行对比。这时候会出现两种情况。
如果一个队列在newAssignQueueSet中,但并不在oldAssignQueueSet中,表示这是新分配的队列。这时候我们可以尝试向Broker申请锁: - 如果成功获取锁,则为该队列创建拉取任务并放入到PullMessageService的pullRequestQueue中,以此唤醒Pull线程,触发消息拉取流程;
- 如果未获取锁,说明该队列当前被其他消费者锁定,放弃本次拉取,等下次重平衡时再尝试申请锁。
这种情况下,消费者能够拉取消息的前提条件是,在Broker上加锁成功。
如果一个队列在newAssignQueueSet中不存在,但存在于oldAssignQueueSet中,表示该队列应该分配给其他消费者,需要将该队列丢弃。但在丢弃之前,要尝试申请ProceeQueue的锁: - 如果成功锁定ProceeQueue,说明ProceeQueue中的消息已消费,可以将该ProceeQueue丢弃,并释放锁;
- 如果未能成功锁定ProceeQueue,说明该队列中的消息还在消费,暂时不丢弃ProceeQueue,这时消费者并不会释放Broker中申请的锁,其他消费者也就暂时无法消费该队列中的消息。
这样,消费者在经历队列重平衡之后,就会创建拉取任务,并驱动Pull线程进入到消息拉取流程。
第二阶段:消息拉取。
PullMessageService线程启动,从pullRequestQueue中获取拉取任务。如果该队列中没有待拉取任务,则Pull线程会阻塞,等待RebalanceImpl线程创建拉取任务,并向Broker发起消息拉取请求:
- 如果未拉取到消息。可能是Tag过滤的原因,被过滤的消息其实也可以算成被成功消费了。所以如果此时处理队列中没有待消费的消息,就提交位点(当前已拉取到最大位点+1),同时再将拉取请求放到待拉取任务的末尾,反复拉取,实现Push模式。
- 如果拉取到一批消息。首先要将拉取到的消息放入ProceeQueue(TreeMap),同时将消息提交到消费线程池,进入消息消费流程。再将拉取请求放到待拉取任务的末尾,反复拉取,实现Push模式。
第三阶段:顺序消费。
RocketMQ一次只会拉取一个队列中的消息,然后将其提交到线程池。为了保证顺序消费,RocketMQ在消费过程中有下面几个关键点:
- 申请MessageQueue锁,确保在同一时间,一个队列中只有一个线程能处理队列中的消息,未获取锁的线程阻塞等待。
- 获取MessageQueue锁后,从处理队列中依次拉取一批消息(消息偏移量从小到大),保证消费时严格遵循消息存储顺序。
- 申请MessageQueue对应的ProcessQueue,申请成功后调用业务监听器,执行相应的业务逻辑。
经过上面三个关键步骤,RocketMQ就可以实现队列(Kafka中称为分区)级别的顺序消费了。
RocketMQ顺序消费设计缺陷
回顾上面RocketMQ实现顺序消费的核心关键词,我们发现其实就是加锁、加锁、加锁。没错,为了实现顺序消费,RocketMQ需要进行三次加锁:
- 进行队列负载平衡后,对新分配的队列,并不能立即进行消息拉取,必须先在Broker端获取队列的锁;
- 消费端在正式消费数据之前,需要锁定MessageQueue和ProceeQueue。
上述三把锁的控制,让并发度受到了队列数量的限制。在互联网、高并发编程领域,通常是“谈锁色变”,锁几乎成为了性能低下的代名词。试图减少锁的使用、缩小锁的范围几乎是性能优化的主要手段。
RocketMQ顺序消费优化方案
而RocketMQ为了实现顺序消费引入了三把锁,极大地降低了并发性能。那如何对其进行优化呢?
破局思路:关联顺序性
我们不妨来看一个金融行业的真实业务场景:银行账户余额变更短信通知。
当用户的账户余额发生变更时,金融机构需要发送一条短信,告知用户余额变更情况。为了实现余额变更和发送短信的解耦,架构设计时通常会引入消息中间件,它的基本实现思路你可以参考这张图:
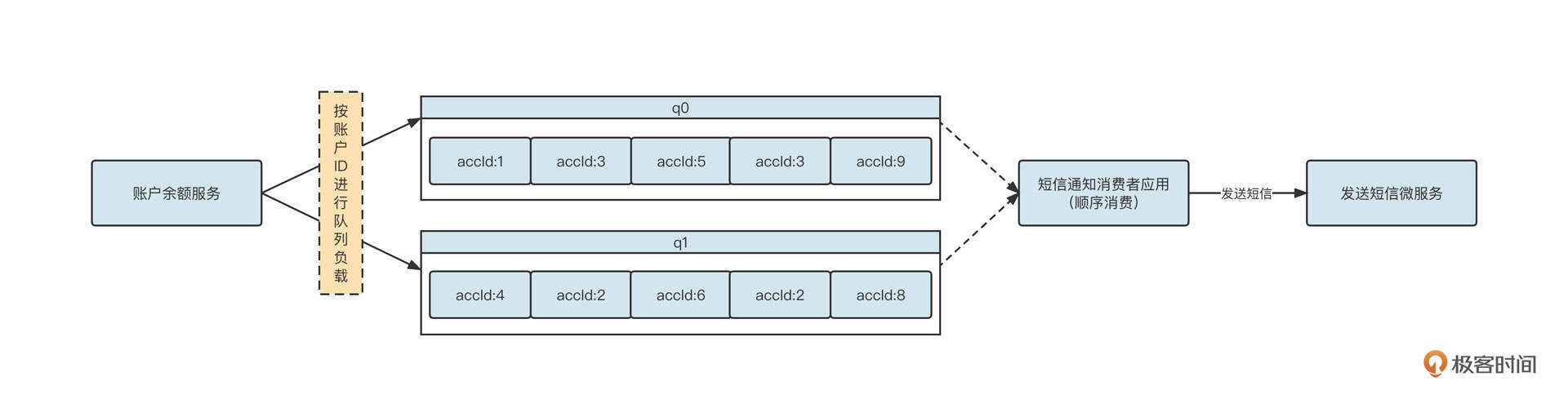
基于RocketMQ的顺序消费机制,我们可以实现基于队列的顺序消费,在消息发送时只需要确保同一个账号的多条消息(多次余额变更通知)发送到同一个队列,消费端使用顺序消费,就可以保证同一个账号的多次余额变更短信不会顺序错乱。
q0队列中依次发送了账号ID为1、3、5、3、9的5条消息,这些消息将严格按照顺序执行。但是,我们为账号1和账号3发送余额变更短信,时间顺序必须和实际的时间顺序保持一致吗?
答案是显而易见的,没有这个必要。
例如,用户1在10:00:01发生了一笔电商订单扣款,而用户2在10:00:02同样发生了一笔电商订单扣款,那银行先发短信告知用户2余额发生变更,然后再通知用户1,并没有破坏业务规则。
不过要注意的是,同一个用户的两次余额变更,必须按照发生顺序来通知,这就是所谓的关联顺序性。
显然,RocketMQ顺序消费模型并没有做到关联顺序性。针对这个问题,我们可以看到一条清晰的优化路线:并发执行同一个队列中不同账号的消息,串行执行同一个队列中相同账号的消息。
RocketMQ顺序模型优化
基于关联顺序性的整体指导思路,我设计出了一种顺序消费改进模型:
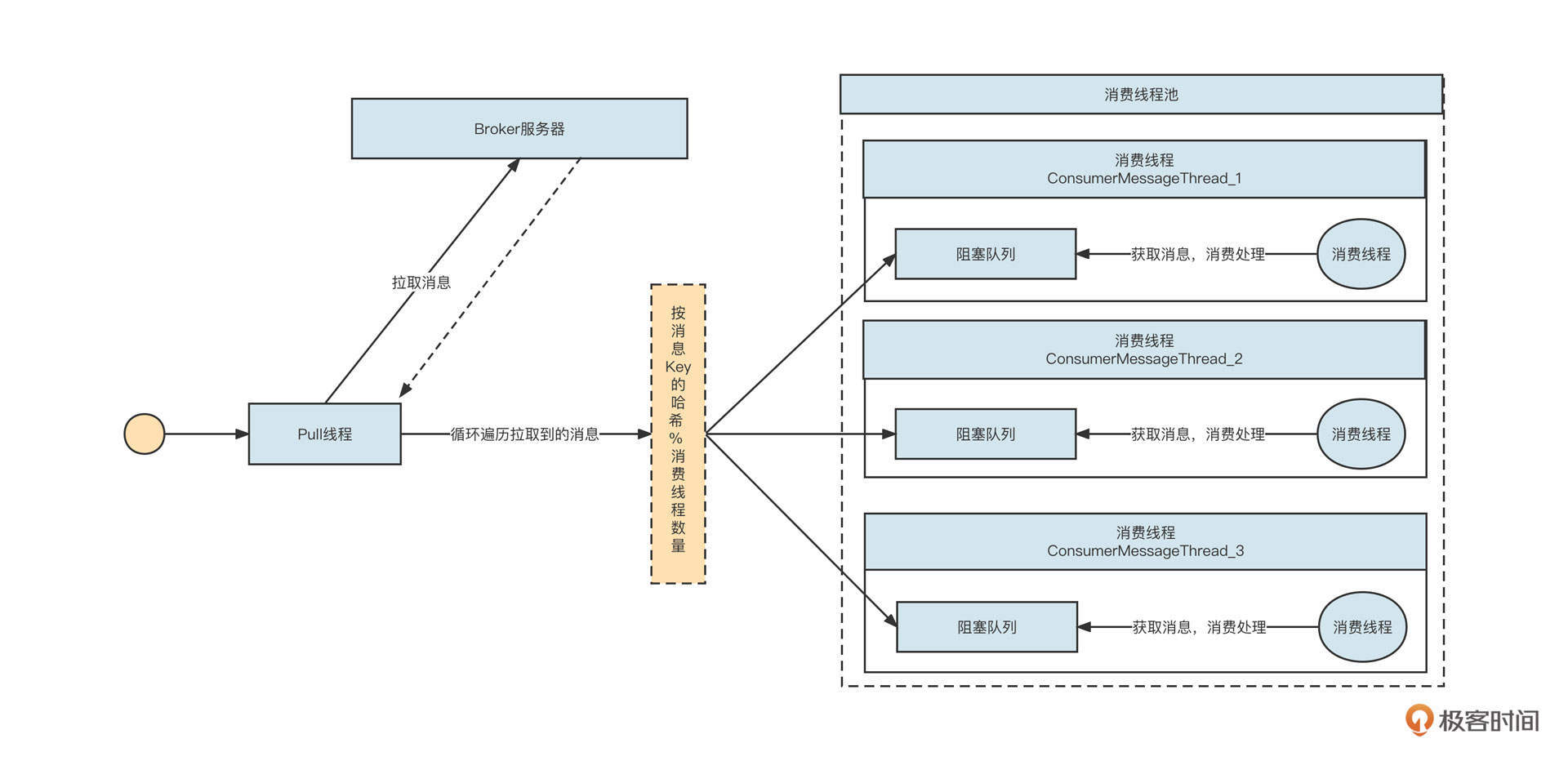
详细说明一下。
- 消息拉取线程(PullMeessageService)从Broker端拉取一批消息。
- 遍历消息,获取消息的Key(消息发送者在发送消息时根据Key选择队列,同一个Key的消息进入同一个队列)的HashCode和线程数量,将消息投递到对应的线程。
- 消息进入到某一个消费线程中,排队单线程执行消费,遵循严格的消费顺序。
为了让你更加直观地体会两种设计的优劣,我们来看一下两种模式针对一批消息的消费行为对比:
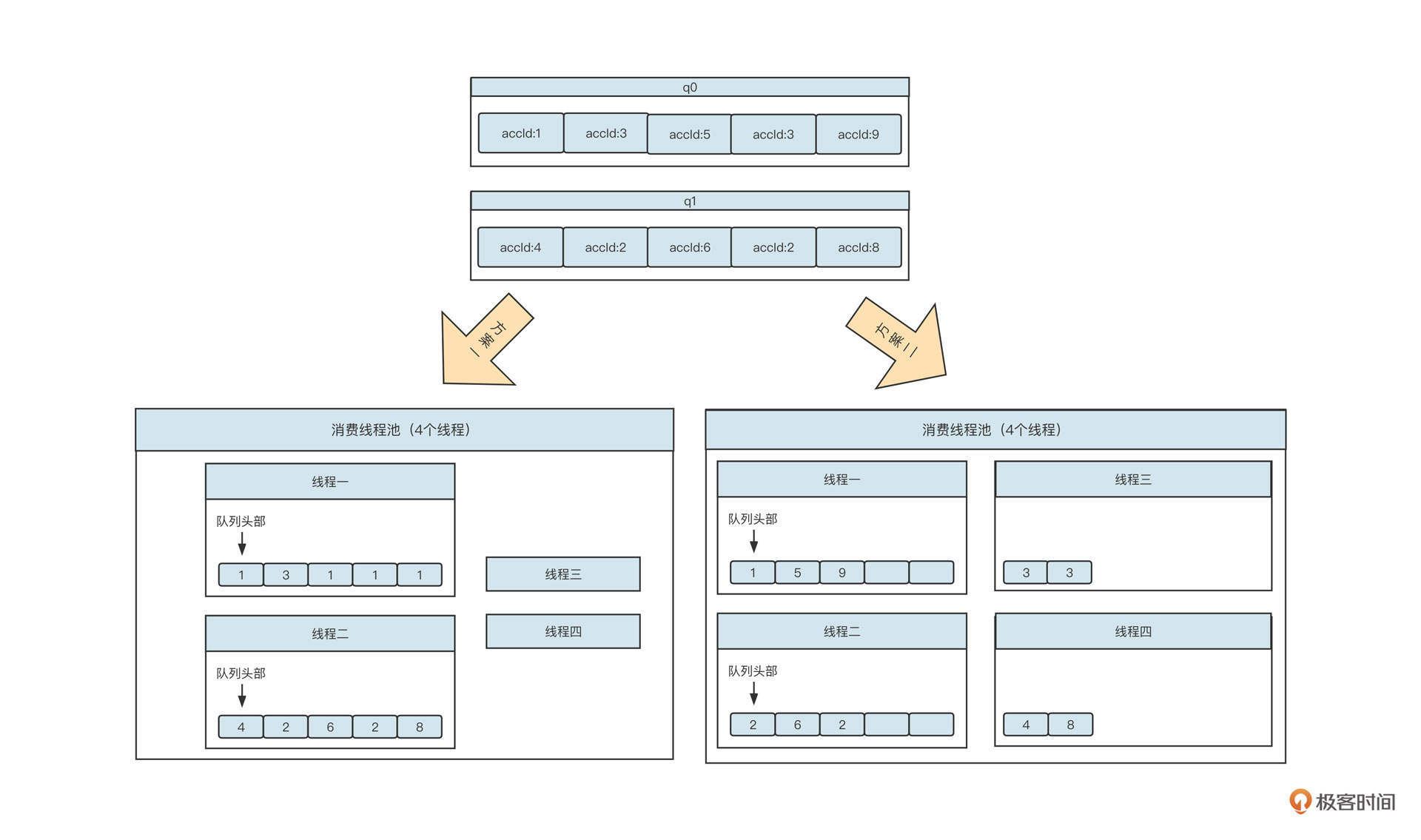
在这里,方案一是RocketMQ内置的顺序消费模型。实际执行过程中,线程三、线程四也会处理消息,但内部线程在处理消息之前必须获取队列锁,所以说同一时刻一个队列只会有一个线程真正存在消费动作。
方案二是优化后的顺序消费模型,它和方案一相比最大的优势是并发度更高。
方案一的并发度取决于消费者分配的队列数,单个消费者的消费并发度并不会随着线程数的增加而升高,而方案二的并发度与消息队列数无关,消费者线程池的线程数量越高,并发度也就越高。
代码实现
在实际生产过程中,再好看的架构方案如果不能以较为简单的方式落地,那就等于零,相当于什么都没干。
所以我们就尝试落地这个方案。接下来我们基于RocketMQ4.6版本的DefaultLitePullConsumer类,引入新的线程模型,实现新的Push模式。
为了方便你阅读代码,我们先详细看看各个类的职责(类图)与运转主流程(时序图)。
类图设计
DefaultMQLitePushConsumer
基于DefaultMQLitePullCOnsumer实现的Push模式,它的内部对线程模型进行了优化,对标DefaultMQPushConsumer。
ConsumeMessageQueueService
消息消费队列消费服务类接口,只定义了void execute(List< MessageExt > msg) 方法,是基于MessageQueue消费的抽象。
AbstractConsumeMessageService
消息消费队列服务抽象类,定义一个抽象方法selectTaskQueue来进行消息的路由策略,同时实现最小位点机制,拥有两个实现类:
- 顺序消费模型(ConsumeMessageQueueOrderlyService),消息路由时按照Key的哈希与线程数取模;
- 并发消费模型(ConsumerMessageQueueConcurrentlyService),消息路由时使用默认的轮循机制选择线程。
- AbstractConsumerTask
定义消息消费的流程,同样有两个实现类,分别是并发消费模型(ConcurrentlyConsumerTask)和顺序消费模型(OrderlyConsumerTask)。
时序图
类图只能简单介绍各个类的职责,接下来,我们用时序图勾画出核心的设计要点:
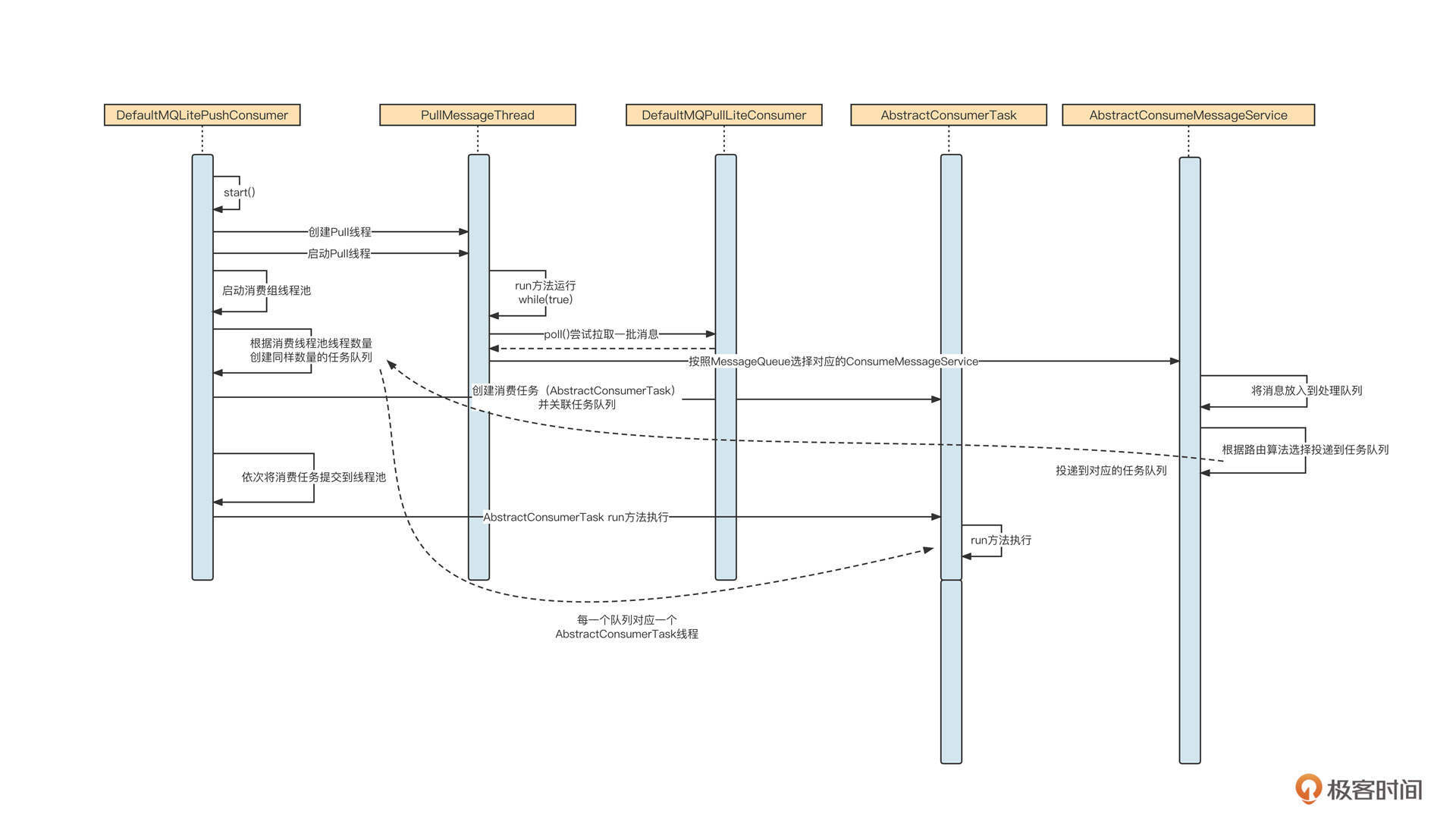
这里,我主要解读一下与顺序消费优化模型相关的核心流程:
- 调用DefaultMQLitePushConsumer的start方法后,会依次启动Pull线程(消息拉取线程)、消费组线程池、消息处理队列与消费处理任务。这里的重点是,一个AbstractConsumerTask代表一个消费线程,一个AbstractConsumerTask关联一个任务队列,消息在按照Key路由后会放入指定的任务队列,从而被指定线程处理。
- Pull线程每拉取一批消息,就按照MessageQueue提交到对应的AbstractConsumeMessageService。
- AbstractConsumeMessageService会根据顺序消费、并发消费模式选择不同的路由算法。其中,顺序消费模型会将消息Key的哈希值与任务队列的总个数取模,将消息放入到对应的任务队列中。
- 每一个任务队列对应一个消费线程,执行AbstractConsumerTask的run方法,将从对应的任务队列中按消息的到达顺序执行业务消费逻辑。
- AbstractConsumerTask每消费一条或一批消息,都会提交消费位点,提交处理队列中最小的位点。
关键代码解读
类图与时序图已经强调了顺序消费模型的几个关键点,接下来我们结合代码看看具体的实现技巧。
创建消费线程池
创建消费线程池部分是我们这个方案的点睛之笔,它对应的是第三小节顺序消费改进模型图中用虚线勾画出的线程池。为了方便你回顾,我把这个图粘贴在下面。
代码实现如下所示:
1 | // 启动消费组线程池 |
这段代码有三个实现要点。
- 第7行:创建一个指定线程数量的线程池,消费线程数可以由consumerThreadCont指定。
- 第12行:创建一个ArrayList < LinkedBlockingQueue > taskQueues的任务队列集合,其中taskQueues中包含consumerThreadCont个队列。
- 第13行:创建consumerThreadCont个AbstractConsumerTask任务,每一个task关联一个LinkedBlockingQueue任务队列,然后将AbstractConsumerTask提交到线程池中执行。
以5个消费线程池为例,从运行视角来看,它对应的效果如下:
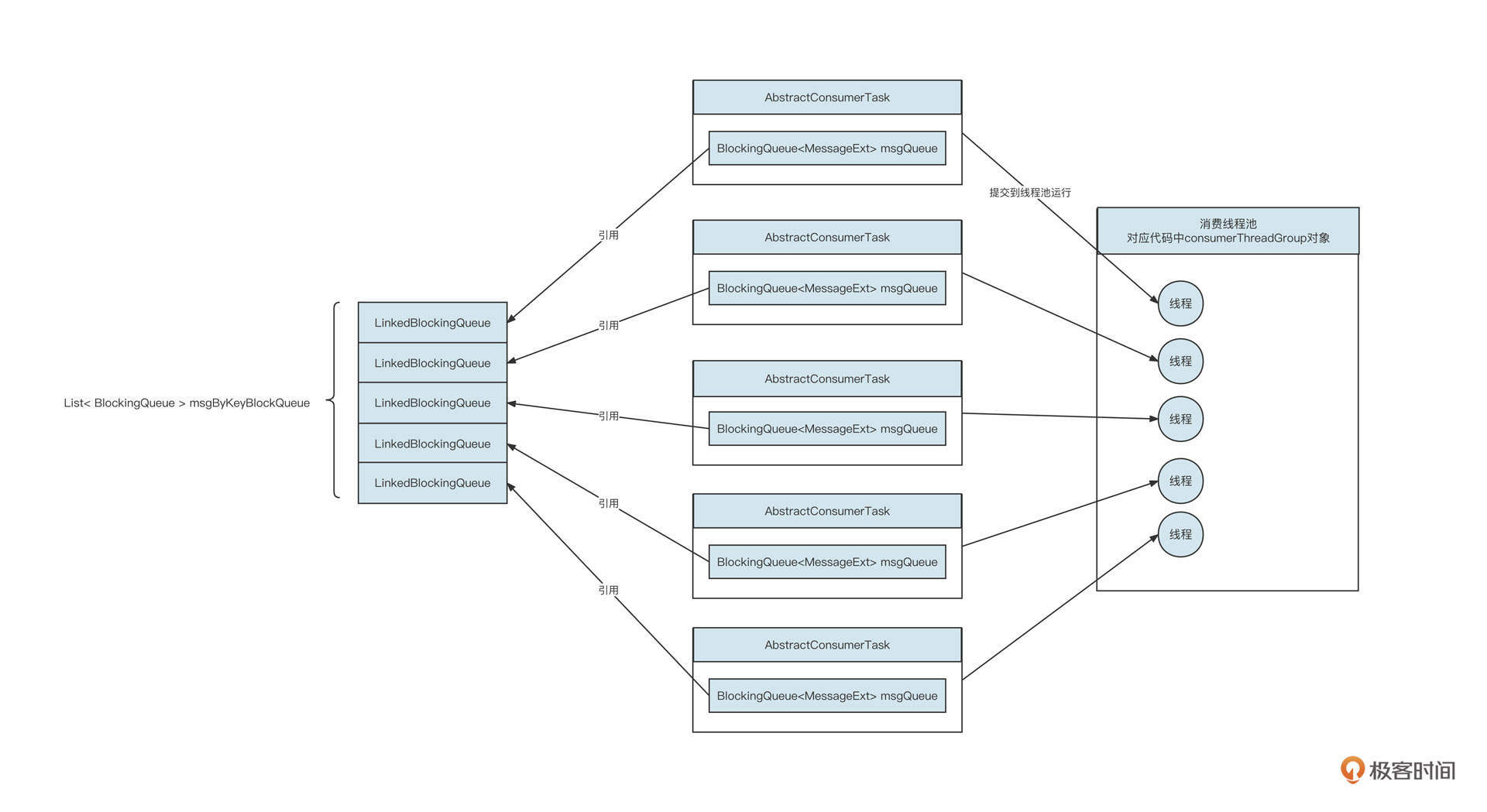
消费线程内部执行流程
将任务提交到提交到线程池后,异步运行任务,具体代码由AbstractConsumerTask的run方法来实现,其run方法定义如下:
1 | public void run() { |
在这段代码中,消费线程从阻塞队列中抽取数据进行消费。顺序消费、并发消费模型具体的重试策略不一样,根据对应的子类实现即可。
Pull线程
这段代码对标的是改进方案中的Pull线程,它负责拉取消息,并提交到消费线程。Pull线程的核心代码如下:
1 | private void startPullThread() { |
Pull线程做的事情比较简单,就是反复拉取消息,然后按照MessageQueue提交到对应的ConsumeMessageQueueService去处理,进入到消息转发流程中。
消息路由机制
此外,优化后的线程模型还有一个重点,那就是消息的派发,它的实现过程如下:
1 | public void execute(List<MessageExt> consumerRecords) { |
这里,顺序消费模型按照消息的Key选择不同的队列,而每一个队列对应一个线程,即实现了按照Key来选择线程,消费并发度与队列个数无关。
完整代码
这节课我们重点展示了顺序消费线程模型的改进方案。但实现一个消费者至少需要涉及队列自动负载、消息拉取、消息消费、位点提交、消费重试等几个部分。因为这一讲我们聚焦在顺序消费模型的处理上,其他内部机制都蕴含在DefaultMQLitePushConsumer类库的底层代码中,所以我们这里只是使用,就不再发散了。不过我把全部代码都放到了GitHub,你可以自行查看。
总结
好了,总结一下。
这节课,我们首先通过一个我经历过的真实案例,看到了RocketMQ顺序消费模型的缺陷。RocketMQ只是实现了分区级别的顺序消费,它的并发度受限于主题中队列的个数,不仅性能低下,在遇到积压问题时,除了横向扩容也几乎没有其他有效的应对手段。
在高并发编程领域,降低锁的粒度是提升并发性能屡试不爽的绝招。本案例中通过对业务规则的理解,找到了降低锁粒度的办法,那就是处于同一个消息队列中的消息,只有具有关系的不同消息才必须确保顺序性。
基于这一思路,并发度从队列级别降低到了消息级别,性能得到显著提升。
课后题
学完今天的内容,请你思考一个问题。
RocketMQ在消息拉取中使用了长轮询机制,你知道这样设计目的是什么吗?
欢迎你在留言区与我交流讨论,我们下节课见!
17|运维:如何运维日均亿级的消息集群?
作者: 丁威

你好,我是丁威。
得益于我所处的平台,依托快递行业巨大的业务流量,我所在的公司的日均消息流转量(消息发送、消息消费)已经达到万亿级别,消息中间件在公司的使用也非常广泛。这节课,我会结合自己的实践经验和你一起来看看如何在生产环境中运维消息集群。
集群部署
尽管消息集群都可以灵活地扩缩容,但我们在运维集群时还是不应该搭建太大的集群。因为一旦集群受影响,影响范围会很大。合理规划消息集群尤为重要,结合我的集群规划实践,我提炼出了下面几条经验供你参考。
- 业务场景
核心业务要按业务域进行规划,并且通常采用RocketMQ。例如我们可以划分出订单、运单、财金等业务域。业务域内尽量独占。
日志采集类通常采用Kafka,并且也要搭建几套日志集群,做好拆分,控制好影响的范围。
- 应用特点
消息集群的客户端通常使用长连接。但大数据领域很多数据抽取都是批处理任务,而批处理任务使用的是短连接,所以大数据领域这种我们会规划到单独的集群;另外在定时消息、大消息等场景下,也要规划专属集群。
规划了这么多的集群,集群的管理就成了难点。我们专门开发一个消息运维平台ZMS,它支持在线安装RocketMQ、Kafka、ZooKeeper等中间件,安装原理如下:
我们对集群部署设计原理中的关键角色一一做个说明。
service instance
服务实例,它是服务中的一个节点。在同一时刻,一个服务实例只能有一个正在主机中运行的进程。一个服务可能包含多个服务实例。
zms-agent
zms-agent(ZMS代理)是zms-portal与主机中的服务实例进行交互的桥梁。它可以实现服务实例的启动、停止和重启操作,还能够监控服务实例进程状态。
supervisor
zms-agent通过supervisor对主机上的进程进行管理,可实现进程状态监控、异常退出、重启等功能。
顺便说一句,ZMS是通过在主机上安装代理,来实现对主机上服务的控制的,这种控制包括服务启动、停止、重启等操作。同时,我们还可以通过agent把服务进程和主机状态上报到zms-portal,实现对主机和服务进程的监控。
ZMS目前已开源,可以点击“开源地址”下载。
集群扩容
从运维角度解决了集群的安装部署问题,接下来我们来看看在生产环境中,一般是怎么运维消息中间件的。
中间件的运维必须遵循一个最基本的原则:中间件所做的变更要对业务无感知。即,中间件做的任何变更不需要业务方配合,也不会影响正在运行的业务,当然为了安全起见,还是需要将变更操作通知业务方,做一些必要的检查工作。
我们先来看如何优雅地对集群进行扩容。
“双十一”、618等大促活动时,各快递公司的业务量往往是平时的几倍。所以,在大促来临之前,我们都会对现有系统进行压测,评估容量,压测后通常会采取扩容等手段以扛住大促前后的巨大流量。那怎么对消息集群进行扩容呢?
我们分别讨论RocketMQ、Kafka这两种中间件。
先说RocketMQ。例如现在已经有一个两主的集群了,部署如下图所示:
现在需要扩容到3个主节点,我们首先要在新添加的机器192.168.3.106上也安装一个Broker,命名为broker-c。扩容后的部署图为:
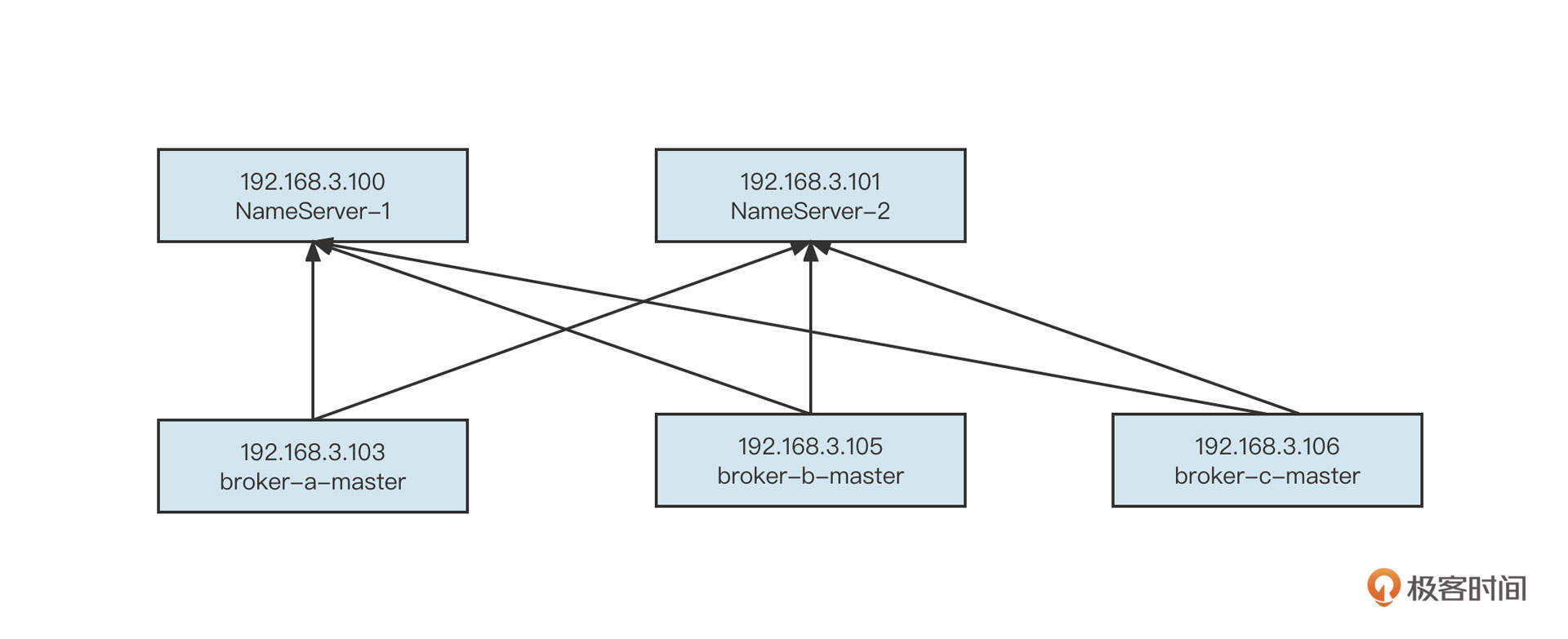
这样就把broker-c扩容到集群了。但这个时候你会发现,新增加的Broker并没有任何流量,这是因为broker-c上目前没有创建任何主题,自然就没有消息写入。
为了快速让broker-c上拥有集群内其他节点中的主题定义,我们通常可以拷贝集群内其他节点的主题定义文件,具体要复制的文件路径为:{ROCKETMQ_HOME}/store/config/topics.json文件。其中,ROCKETMQ_HOME 表示集群的主目录,具体的文件存储如下图所示:
如果Broker关闭了自动创建消费组(autoCreateSubscriptionGroup=false),还需要拷贝subscriptionGroup.json文件。
这样,再次重启新加入的机器,就可以承担读写流量,实现负载均衡了。
我们再来说一下Kafka中集群节点的扩容。
第一步和RocketMQ一样,也就是在新节点上安装一个Kafka,并与原先节点使用相同的ZooKeeper集群。这时,节点会扩容到集群中,但是与RocketMQ相同,这个节点暂时也不会有任何流量进来。那要如何使新节点承担数据的读写呢?
我们需要进行分区重分配,手动将部分主题的分区分配到新的节点。
在介绍具体的分配方式之前,我们先来看一下dw_test_topic_0709003的分区分布情况:
你可以重点关注一下Leader这一项,它表示分区所在的Broker节点。
好了,下面我们具体来看一下怎么对分区进行重分配。这里总共有三个步骤。
第一步:挑选出一部分重要主题,或者是当前TPS排名靠前的主题,整理成JSON文件。
1 | {"topics": |
第二步:使用Kafka提供的kafka-reassign-partitions.sh命令生成执行计划。具体命令如下:
1 | ./kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --topics-to-move-json-file ./tmp/dw_test_topic_0709003-topics-to-move.json --broker-list "0,1,2,4" --generate --zookeeper 127.0.0.1:2181 |
该命令运行后的截图如下:
执行命令后会输出下面两部分内容。
- Current partition replica assignment:表示主题分区迁移之前的结果,通常把这部分内容保存在一个文件中,用于回滚操作。
- Proposed partition reassignment configuration:分区重新分配后的执行计划。
第三步:把上一步生成的执行计划存储到一个JSON文件中,然后执行如下命令:
1 | ./kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./tmp/dw_test_topic_0709003-reassignment-json-file.json --execute --zookeeper 127.0.0.1:2181/kafka_cluster_01 |
该命令的执行结果如下图所示:
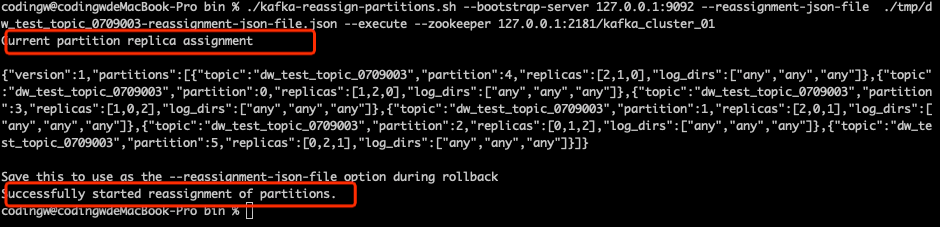
响应结果还会返回迁移之前的分区情况,可用作回滚操作。值得注意的是,这个操作只会触发分区重分配,不会影响客户端的写入和读取。但如果分区的数据比较多的话,由于分区数据需要在节点之间进行迁移,所以需要一个过程。
如果在紧急情况下, 通常在修改操作之前会首先修改主题的存储时间,适当降低存储数据量,这样可以加快数据的迁移。
分区重分配成功后,结果如下:
可以看到,新扩容的节点4上已经有主分区了,这样它就可以接受数据的读写请求了。
集群缩容
大促结束后,为了节省资源,通常需要对集群进行缩容处理。将节点从集群中移除的基本原则是,存储在这些节点上的消息必须完成消费,否则会造成消息消费丢失。
首先我们来看一下RocketMQ节点的缩容。
双十一过后,我们需要将192.168.3.106的节点下线,但是,直接把节点从集群中摘除是不可行的。我们通常要先关闭写权限,避免新的数据再写入该节点,然后等消息过期再下线。具体有两个步骤。
第一步:关闭节点的写权限。具体命令如下:
1 | sh ./mqadmin updateBrokerConfig -b 127.0.0.1:10911 -n 127.0.0.1:9876 -k brokerPermission -v 4 |
第二步:为了保守起见,通常要等待消息过期后,再关闭Broker。如果消息的存储时间为72小时,那要在关闭写权限3天之后才可以下线该节点。在此期间,该节点还是可以提供读取服务,也就是说,存在这个节点的消息仍然可以被消费端消费。
Kafka的缩容需要分情况处理。
如果Kafka集群中所有主题都是多副本的话,这样每一个分区都会有多个副本,并且这些副本会分布在不同的节点上,缩容的时候直接停止一个机器即可。
但如果Kafka中有些主题是采取的单副本,要想缩容,就需要将这些单副本的主题再次进行分区重分配,把这些单副本主题的分片转移到其他节点。然后就可以直接停掉机器了。
分区扩容
除了在集群维度扩容和缩容外,无论是RocketMQ还是Kafka都支持分区级别的扩容。
在RocketMQ中为主题进行队列扩容比较简单,只需要执行一条命令:
1 | sh ./mqadmin updateTopic -n 127.0.0.1:9876 -c DefaultCluster -t dw_test_01 -r 8 -w 8 |
-w 、-r 分别指定扩容后的队列数。其中-w表示写队列个数,-r表示读队列个数,在进行主题扩容时,它们必须一致。
在Kafka中扩容分区同样只需要执行一条命令:
1 | ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic dw_test_topic_0709003 --partitions 8 --alter |
其中,“–partitions”表示要扩容后的分片数量。
分区缩容
再来看分区缩容。
Kafka目前不支持分区缩容,也就是说,一个主题的分区数量只能增加不能减少。而RocketMQ可以无缝实现缩容。
在RocketMQ要减少主题的分区数量,通常需要经过两步。
第一步:将主题的写队列更改为缩容后的队列,例如dw_test_01这个主题原本有8个队列,现在要缩容为4,就将主题的写队列改为4。具体的命令如下:
1 | sh ./mqadmin updateTopic -n 127.0.0.1:9876 -c DefaultCluster -t dw_test_01 -r 8 -w 4 |
第二步:等消息达到过期时间后,再将读队列数量变更为缩容后的队列。命令如下:
1 | sh ./mqadmin updateTopic -n 127.0.0.1:9876 -c DefaultCluster -t dw_test_01 -r 4 -w 4 |
位点重置
在生产实践中,还有一个非常高频的动作是位点重置(回溯)。
RocketMQ不需要停止消费组就可以进行位点回溯,只需要运维人员执行如下命令:
1 | sh ./mqadmin resetOffsetByTime -g dw_test_mq_consuemr_test_01 -n 127.0.0.1:9876 -t dw_zms_test_topic -s '2022-07-10#10:00:00:000' |
这里重点说一下-s参数,它表示回溯时间。其中:
- now 或者 currentTimeMillis表示当前时间;
- yyyy-MM-dd#HH:mm:ss:SSS 表示具体的时间戳。在执行命令时,需要严格按照格式,否则会抛出空指针异常,这个错误会让人看得莫名其妙。
运行的结果如下:

我们再来看一下Kafka的位点回溯。
kafka中在进行位点重置之前,首先需要停止该消费组内所有的消费者,然后执行如下命令:
1 | ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group dw_test_consumer_20220710001 --reset-offsets --to-datetime '2022-07-10T00:00:00.000' --topic dw_test_topic_0709003 --execute |
命令的运行结果如下:
其中,NEW-OFFSET表示当时的位点,消费组启动时会从该位点开始消费。
RocketMQ NameServer的扩容与下线
在生产环境中,RocketMQ还有一个重要组件是NameServer。它的扩容与缩容也需要特别注意,避免操作过程造成人为的数据不一致。
举个例子,如果现在我们需要将2个节点的NameServer扩容为3个节点,需求如下图所示:
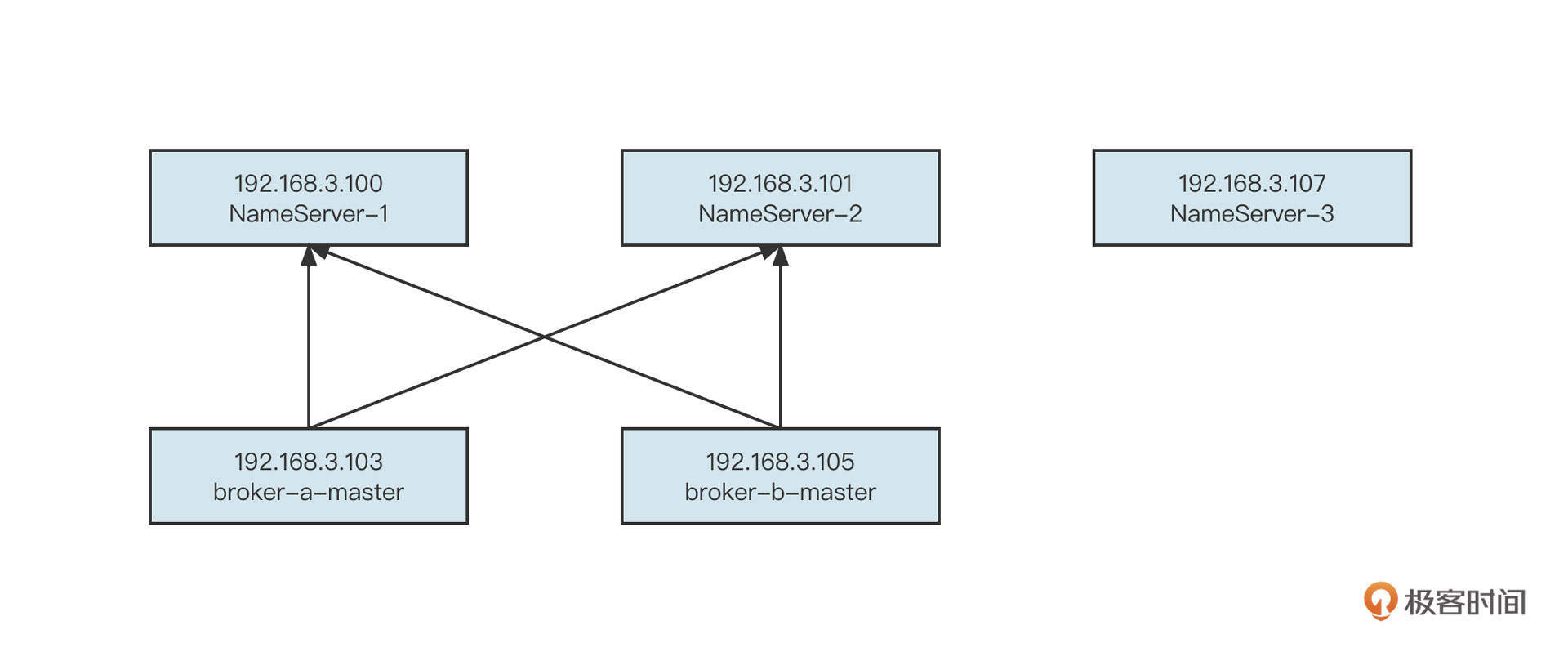
首先要在新的机器上安装好NameServer。
然后更新两台Broker的配置文件,让Broker能够感知NameServer的存在,具体的配置项:
1 | namesrvAddr=192.168.3.100:9876;192.168.3.101:9876;192.168.3.107:9876 |
紧接着,依次重启Broker。
这样,NameServer就扩容完成了。
乍一看这个过程很简单,但你一定要注意的是,集群内的Broker没有全部重启时,新加入集群的NameServer地址是不能让消息发送/消息消费客户端使用的。因为这时候新的NameServer上的路由信息会和集群内其他NamServer存储的信息不一致。
NameServer的下线就比较简单了。直接先kill掉NameServer进程,这时,无论是Broker、还是消息发送、消息消费客户端都会抛出错误,但这个错误不影响使用。
然后依次更新Broker配置文件中的namesrvAddr,移除已下线的NameServer地址并依次重启。
在生产实践中,NameServer的扩容还是比较少见的,更多的是更换机器。举个例子,192.168.3.100这台机器由于内存、磁盘等故障,需要被下线。但为了保证NameServer节点数量不受影响,我们通常还会在一台新机器上部署一台新的NameServer。同时,为了避免客户端或Broker需要更新NameServer列表,更换机器时还要IP保持不变。
运维技巧
最后,我们再来看看运维命令。
无论是RocketMQ还是Kafka都提供了丰富的运维命令,这可以让运维人员更好地管理集群。但是,运维命令这么多,而且每一个命令的参数也很多,我们应该怎么学习这些命令呢?
其实不需要死记硬背,这些运维命令自带帮助手册,运维命令的安装目录就是中间件的bin目录。
通过下面的命令,我们可以快速查看RocketMQ拥有哪些运维命令:
1 | sh ./mqadmin |
查看每一个命令的具体使用方法,可以使用如下命令:
1 | sh ./mqadmin updateTopic -h |
同样Kafka的运维命令也在bin目录下:
总结
好了,这节课就讲到这里。
中间件的稳定性大于一切,一旦发生故障,影响范围也比较大。所以我们不能把所有的鸡蛋放到一个“篮子”中,而是应该按照使用场景、应用特性等维度对集群进行合理规划,规划出一个一个的小集群。
中间件的运维必须遵循一个最基本的原则,那就是中间件做的变更要对业务无感知,对现有业务的运行无任何影响。
刚才,我结合我的运维实践经验,对集群扩容、缩容、分区扩容、缩容、位点重置、NameServer下线等常见场景做了演练,你可以对比自己的实际经验进行总结与归纳。
课后题
学完今天的内容,请你思考下面这个问题。
在进行消费位点回溯时,我们说Kafka必须先停掉消费者,但RocketMQ却不需要,你知道RocketMQ是怎么做到的吗?
欢迎你在留言区与我交流讨论,我们下节课见!
18|案例:如何排查RocketMQ消息发送超时故障?
作者: 丁威

你好,我是丁威。
不知道你在使用RocketMQ的时候有没有遇到过让人有些头疼的问题。我在用RocketMQ时遇到的最常见,也最让我头疼的问题就是消息发送超时。而且这种超时不是大面积的,而是偶尔会发生,占比在万分之一到万分之五之间。
现象与关键日志
消息发送超时的情况下,客户端的日志通常是下面这样:

我们这节课就从这些日志入手,看看怎样排查RocketMQ的消息发送超时故障。
首先,我们要查看RocketMQ相关的日志,在应用服务器上,RocketMQ的日志默认路径为${USER_HOME}/logs/rocketmqlogs/ rocketmq_client.log。
在上面这张图中,有两条非常关键的日志。
invokeSync:wait response timeout exception.
它表示等待响应结果超时。
recive response, but not matched any request.
这条日志非常关键,它表示,尽管客户端在获取服务端返回结果时超时了,但客户端最终还是能收到服务端的响应结果,只是此时客户端已经在等待足够时间之后放弃处理了。
单一长连接如何实现多请求并发发送?
为什么第二条日志超时后还能收到服务端的响应结果,又为什么匹配不到对应的请求了呢?
我们可以详细探究一下这背后的原理。原来,这是使用单一长连接进行网络请求的编程范式。举个例子,一条长连接向服务端先后发送了两个请求,客户端在收到服务端响应结果时,需要判断这个响应结果对应的是哪个请求。
正如上图所示,客户端多个线程通过一条连接依次发送了req1,req2两个请求,服务端解码请求后,会将请求转发到线程池中异步执行。如果请求2处理得比较快,比请求1更早将结果返回给客户端,那客户端怎么识别服务端返回的数据对应的是哪个请求呢?
解决办法是,客户端在发送请求之前,会为这个请求生成一个本机器唯一的请求ID(requestId),它还会采用Future模式,将requestId和Future对象放到一个Map中,然后将reqestId放入请求体。服务端在返回响应结果时,会将请求ID原封不动地放入响应结果中。客户端收到响应时,会先解码出requestId,然后从缓存中找到对应的Future对象,唤醒业务线程,将返回结果通知给调用方,完成整个通信。
结合日志我发现,如果客户端在指定时间内没有收到服务端的请求,最终会抛出超时异常。但是,网络层面上客户端还是能收到服务端的响应结果。这就把矛头直接指向了Broker端,是不是Broker有瓶颈,处理慢导致的呢?
如何诊断Broker端内存写入性能?
我们知道消息发送时,一个非常重要的过程就是服务端写入。如果服务端出现写入瓶颈,通常会返回各种各样的Broker Busy。我们可以简单来看一下消息发送的写入流程:
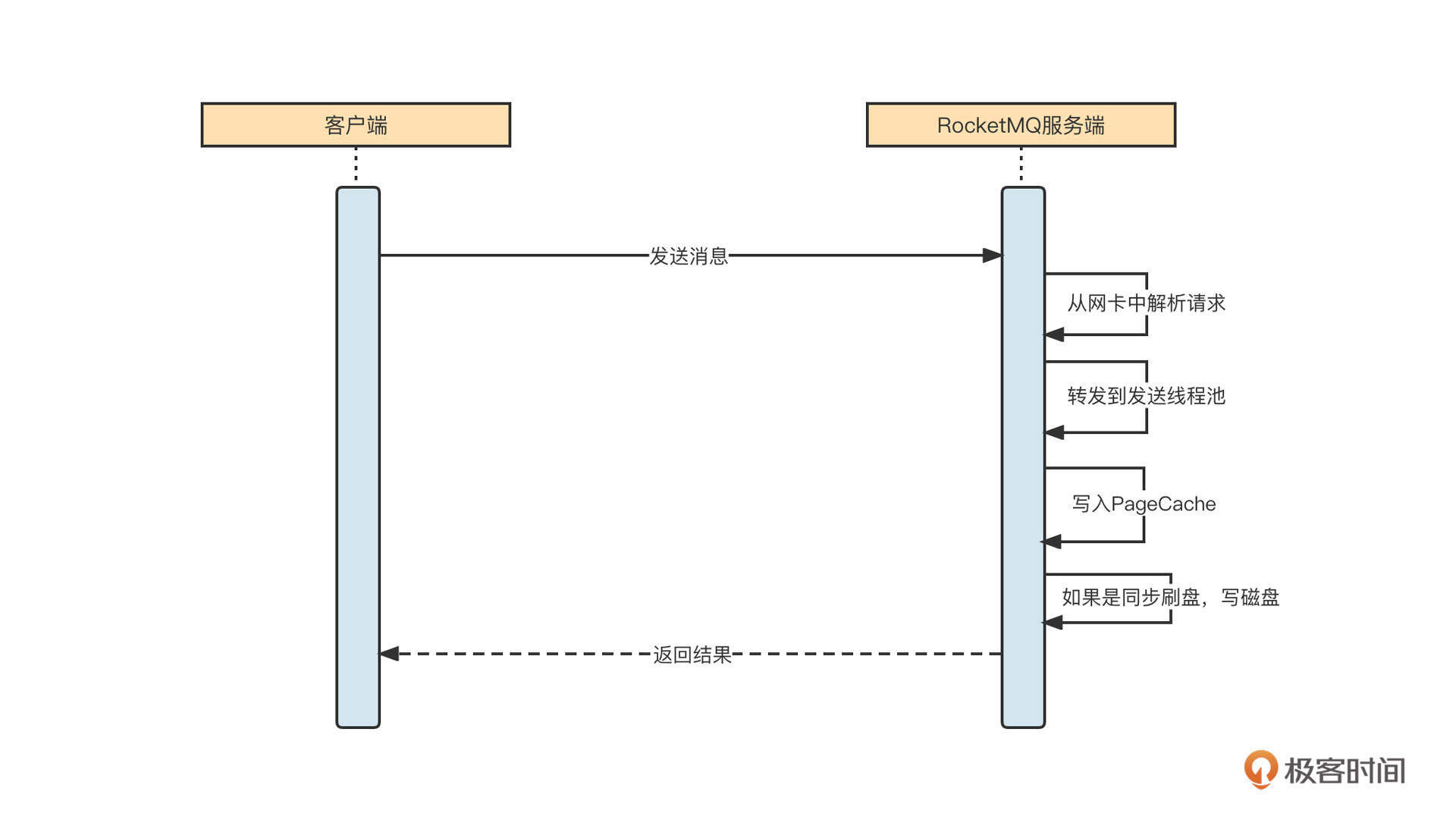
我们首先要判断的是,是不是消息写入PageCache或者磁盘写入慢导致的问题。我们这个集群采用的是异步刷盘机制,所以写磁盘这一环可以忽略。
然后,我们可以通过跟踪Broker端写入PageCache的数据指标来判断Broker有没有遇到瓶颈。具体做法是查看RocketMQ中的store.log文件,具体使用命令如下:
1 | cd /home/codingw/logs/rocketmqlogs/store.log //其中codingw为当前rocketmq broker进程的归属用户 |
执行命令后,可以得到这样的结果:
这段日志记录了消息写入到PageCache的耗时分布。通过分析我们可以知道,写入PageCache的耗时都小于100ms,所以PageCache的写入并没有产生瓶颈。不过,客户端可是真真切切地在3秒后才收到响应结果,难道是网络问题?
网络层排查通用方法
接下来我们就分析一下网络。
通常,我们可以用netstat命令来分析网络通信,需要重点关注网络通信中的Recv-Q与Send-Q这两个指标。
netstat命令的执行效果如下图所示:
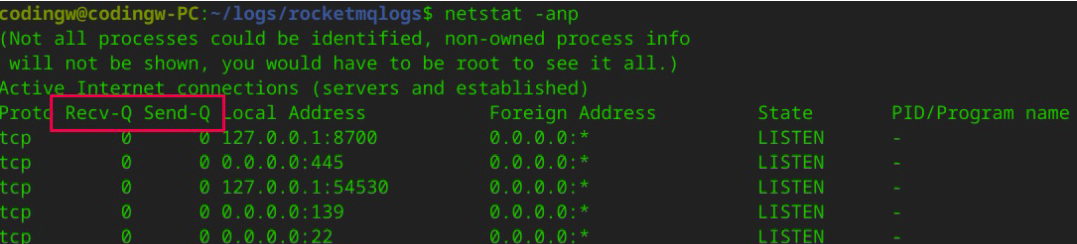
解释一下,这里的Recv-Q是TCP通道的接受缓存区;Send-Q是TCP通道的发送缓存区。
在TCP中,Recv-Q和Send-Q的工作机制如下图所示:
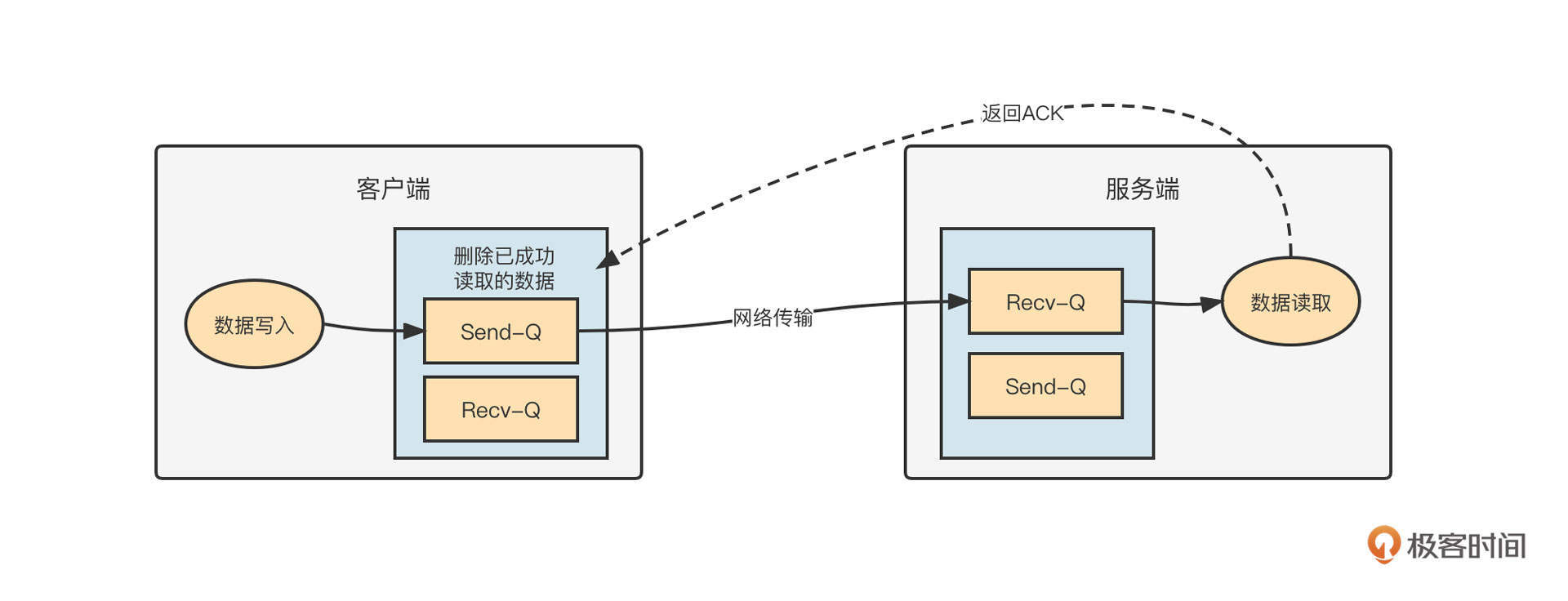
正如上图描述的那样,网络通信有下面几个关键步骤。
- 客户端调用网络通道时(例如NIO的Channel写入数据),数据首先是写入到TCP的发送缓存区,如果发送缓存区已满,客户端无法继续向该通道发送请求,从NIO层面调用Channel底层的write方法的时候会返回0。这个时候在应用层面需要注册写事件,待发送缓存区有空闲时,再通知上层应用程序继续写入上次未写入的数据。
- 数据进入到发送缓存区后,会随着网络到达目标端。数据首先进入的是目标端的接收缓存区,如果服务端采用事件选择机制的话,通道的读事件会就绪。应用从接收缓存区成功读取到字节后,会发送ACK给发送方。
- 发送方在收到ACK后,会删除发送缓冲区的数据。如果接收方一直不读取数据,那发送方也无法发送数据。
运维同事分别在客户端和MQ服务器上,在服务器上写一个脚本,每500ms采集一次netstat 。最终汇总到的采集结果如下:
从客户端来看,客户端的Recv-Q中出现大量积压,它对应的是MQ的Send-Q中的大量积压。
结合Recv-Q、Send-Q的工作机制,再次怀疑可能是客户端从网络中读取字节太慢导致的。为了验证这个观点,我修改了和RocketMQ Client相关的包,加入了Netty性能采集方面的代码:
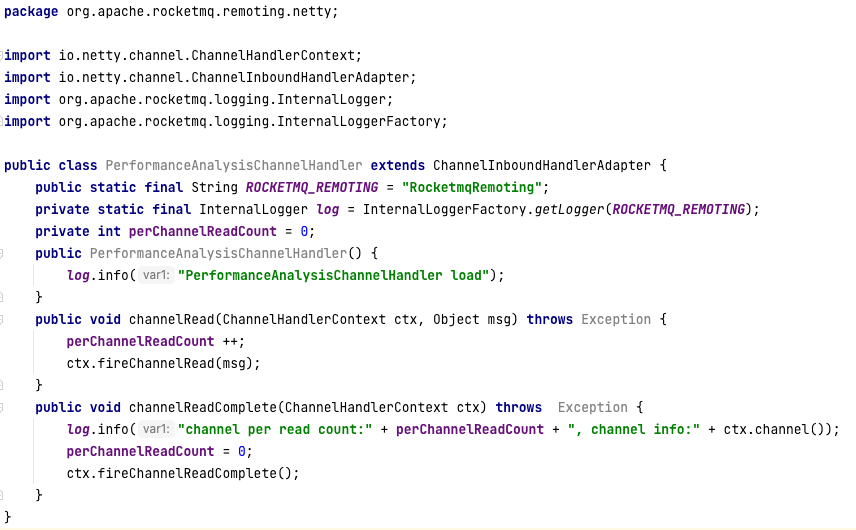
我的核心思路是,针对每一次被触发的读事件,判断客户端会对一个通道进行多少次读取操作。如果一次读事件需要触发很多次的读取,说明这个通道确实积压了很多数据,网络读存在瓶颈。
部分采集数据如下:

我们可以通过awk命令对这个数据进行分析。从结果可以看出,一次读事件触发,大部分通道只要读两次就可以成功抽取读缓存区中的数据。读数据方面并不存在瓶颈。
统计分析结果如下图所示:
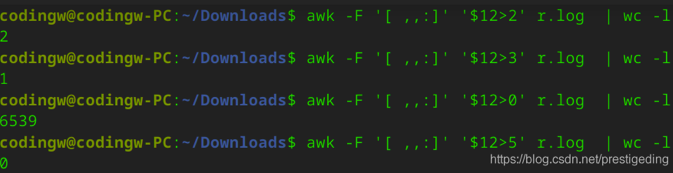
如此看来,瓶颈应该不在客户端,还是需要将目光转移到服务端。
从刚才的分析中我们已经看到,Broker服务端写入PageCache很快。但是刚刚我们唯独没有监控“响应结果写入网络”这个环节。那是不是写入响应结果不及时,导致消息大量积压在Netty的写缓存区,不能及时写入到TCP的发送缓冲区,最终造成消息发送超时呢?
解决方案
为了验证这个设想,我最初的打算是改造代码,从Netty层面监控服务端的写性能。但这样做的风险比较大,所以我暂时搁置了这个计划,又认真读了一遍RocketMQ封装Netty的代码。在这之前,我一直以为 RocketMQ的 网络层基本不需要参数优化,因为公司的服务器都是64核心的,而Netty的IO线程默认都是CPU的核数。
但这次阅读源码后我发现,RocketMQ中和IO相关的线程参数有两个,分别是serverSelectorThreads(默认值为3)和serverWorkerThreads(默认值为8)。
在Netty中,serverSelectorThreads就是WorkGroup,即所谓的IO线程池。每一个线程池会持有一个NIO中的Selector对象用来进行事件选择,所有的通道会轮流注册在这3个线程中,绑定在一个线程中的所有Channel会串行进行网络读写操作。
我们的MQ服务器的配置,CPU的核数都在48C及以上,用3个线程来做这件事显然太“小家子气”,这个参数可以调优。
RocketMQ的网络通信层使用的是Netty框架,默认情况下事件的传播(编码、解码)都在IO线程中,也就是上面提到的Selector对象所在的线程。
在RocketMQ中IO线程就只负责网络读、写,然后将读取到的二进制数据转发到一个线程池处理。这个线程池会负责数据的编码、解码等操作,线程池线程数量由serverWorkerThreads指定。
看到这里,我开始心潮澎湃了,我感觉自己离真相越来越近了。参考Netty将IO线程设置为CPU核数的两倍,我的第一波优化是让serverSelectorThreads=16,serverWorkerThreads=32,然后在生产环境中进行一波验证。
经过一个多月的验证,在集群数量逐步减少,业务量逐步上升的背景下,我们生产环境的消息发送超时比例达到了十万分之一,基本可以忽略不计。
网络超时问题的排查到这里就彻底完成了。但生产环境复杂无比,我们基本无法做到100%不出现超时。
比方说,虽然调整了Broker服务端网络的相关参数,超时问题得到了极大的缓解,但有时候还是会因为一些未知的问题导致网络超时。如果在一定时间内出现大量网络超时,会导致线程资源耗尽,继而影响其他业务的正常执行。
所以在这节课的最后我们再从代码层面介绍如何应对消息发送超时。
发送超时兜底策略
我们在应用中使用消息中间件就是看中了消息中间件的低延迟。但是如果消息发送超时,这就和我们的初衷相违背了。为了尽可能避免这样的问题出现,消息中间件领域解决超时的另一个思路是:增加快速失败的最大等待时长,并减少消息发送的超时时间,增加重试次数。
我们来看下具体做法。
- 增加 Broker 端快速失败的等待时长。这里建议为 1000。在 Broker 的配置文件中增加如下配置:
1 | maxWaitTimeMillsInQueue=1000 |
- 减少超时时间,增加重试次数。
你可能会问,现在已经发生超时了,你还要减少超时时间,那发生超时的概率岂不是更大了?
这样做背后的动机是希望客户端尽快超时并快速重试。因为局域网内的网络抖动是瞬时的,下次重试时就能恢复。并且 RocketMQ 有故障规避机制,重试的时候会尽量选择不同的 Broker。
执行这个操作的代码和版本有关,如果 RocketMQ 的客户端版本低于4.3.0,代码如下:
1 | DefaultMQProducer producer = new DefaultMQProducer("dw_test_producer_group"); |
如果客户端版本是 4.3.0 及以上版本,因为设置的消息发送超时时间是所有重试的总的超时时间,所以不能直接设置 RocketMQ 的发送 API 的超时时间,而是需要对RocketMQ API 进行包装,例如示例代码如下:
1 | public static SendResult send(DefaultMQProducer producer, Message msg, int |
总结
好了,我们这节课就介绍到这里了。
这节课,我首先抛出一个生产环境中,消息发送环节最容易遇到的问题:消息发送超时问题。我们对日志现象进行了解读,并引出了单一长连接支持多线程网络请求的原理。
整个排查过程,我首先判断了一下Broker写入PageCache是否有瓶颈,然后通过netstat命令,以Recv-Q、Send-Q两个指标为依据进行了网络方面的排查,最终定位到瓶颈可能在于服务端网络读写模型。通过研读RocketMQ的网络模型,我发现了两个至关重要的参数,serverSelectorThreads和serverWorkerThreads。其中:
- serverSelectorThreads是RocketMQ服务端IO线程的个数,默认为3,建议设置为CPU核数;
- serverWorkerThreads是RocketMQ事件处理线程数,主要承担编码、解码等责任,默认为8,建议设置为CPU核数的两倍。
通过调整这两个参数,我们极大地降低了网络超时发生的概率。
不过,发生网络超时的原因是多种多样的,所以我们还介绍了第二种方法,那就是降低超时时间,增加重试的次数,从而降低网络超时对运行时线程的影响,降低系统响应时间。
课后题
学完今天的内容,我也给你留一道课后题吧。
网络通讯在中间件领域非常重要,掌握网络排查相关的知识对线上故障分析有很大的帮助。建议你系统地学习一下netstat命令和网络抓包相关技能,分享一下你的经验和困惑。我们下节课见!
19|案例:如何排查RocketMQ消息消费积压问题?
作者: 丁威

你好,我是丁威。
我想,几乎每一位使用过消息中间件的小伙伴,都会在消息消费时遇到消费积压的问题。在处理这类问题时,大部分同学都会选择横向扩容。但不幸的是,这种解决办法治标不治本,到最后问题还是得不到解决。
说到底,消费端出现消息消费积压是一个结果,但引起这个结果的原因是什么呢?在没有弄清楚原因之前谈优化和解决方案都显得很苍白。
这节课,我们就进一步认识一下消费积压和RocketMQ的消息消费模型,看看怎么从根本上排查消费积压的问题。
RocketMQ的消息消费模型
在RocketMQ消费领域中,判断消费端遇到的瓶颈通常会用到两个重要的指标:Delay和LastConsumeTime。
在开源版本的控制台rocketmq-console界面中,我们可以查阅消费端的这两个指标:
- Delay指的是消息积压数量,它是由BrokerOffset(服务端当前最大的逻辑偏移量)减去ConsumerOffset(消费者消费的当前位点)计算出来的。如果Delay值很大,说明消费端遇到了瓶颈。
- LastConsumeTime表示上一次成功消费消息的存储时间。这个值如果很大,同样能说明消费端遇到了瓶颈。如果这个值线上为1970年,表示消费者当前消费位点对应的消息在服务端已经过期,被删除了。
那为什么消费会积压呢?要理解这个问题,我们首先要了解RocketMQ消费者的消费处理模型。核心流程如下图所示:
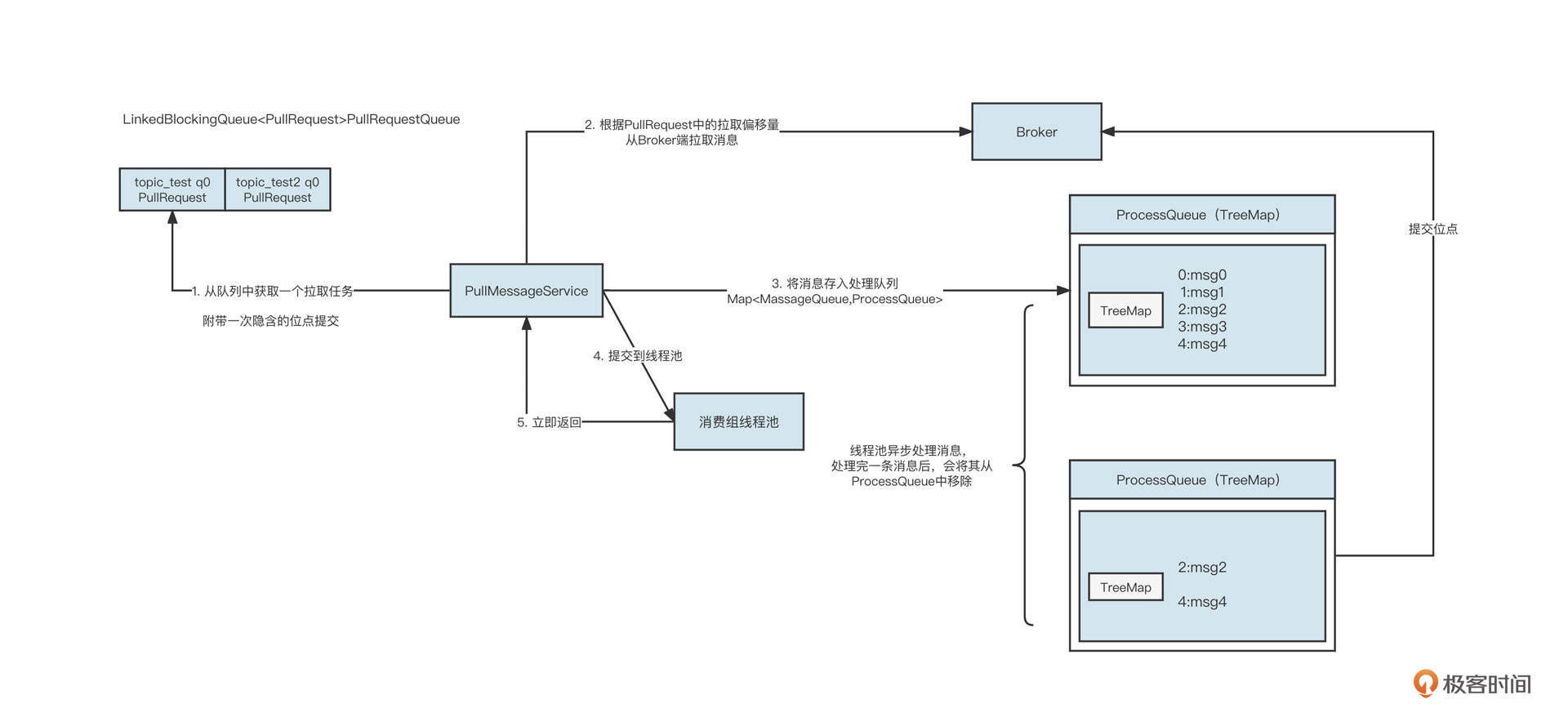
说明一下具体的工作流程。
- PullMessageService线程从拉取任务队列中获取一个待拉取任务PullRquest。
- PullMessageService线程根据PullRequest中的主题名称、队列编号、拉取位点向Broker服务器拉取一批消息。拉取到消息后,服务端会更新PullRequest中下一次拉取任务的偏移量,将其放到队列的尾部。
- PullMessageService线程将拉取到的消息存入到处理队列(ProcessQueue),每一个MessageQueue(Broker名称+主题名称+队列编号)对应一个处理队列。
- PullMessageService线程将拉取到的消息提交到线程池。
- PullMessageService线程将消息提交到线程池后,不会等这批消息处理完成,而是立即返回。然后PullMessageService线程重复步骤一到步骤五。
- 当消息提交到消费线程池后,进行异步消费。消息消费成功后,会将消息从处理队列(ProcessQueue)中移除,然后获取处理队列中的最小偏移量,提交消费位点。
从这个过程中可以看出,在RocketMQ的消费处理模型中,PullMessageService线程“马不停歇”地从拉取队列中获取任务,拉完一批消息后继续再将PullRequest(待拉取任务)放入到队列末尾,确保PullMessageService可以不间断地拉取消息,从而实现Push模式的效果。
从理论设计的角度,我们不难看出产生消费积压的原因可能有两个。
- 第一,Pull线程不拉取消息,那就无法消费消息,没有消费消息,消费位点自然不会提交。
- 第二,消费线程池中的线程因为某种原因阻塞,导致不消费消息,进而同样使得消费位点不提交。
针对第一点,Pull线程的run方法采用的是while(true)+try catch的模式,只要不主动关闭消费者,这个线程是不会停止的。具体的代码实现如下:
这么看来,消费积压基本都是消费线程池由于某种原因阻塞导致的。
在探究阻塞会发生在何处之前,你不妨思考一下,如果消费线程不干活,但拉取线程还一直在从服务端拉取消息,再将消息提交到消费线程池和ProcessQueue,这时会出现什么问题?
没错,内存溢出。所以,为了保护消费者进程,这个时候我们必须引入限流机制限制拉取线程的行为。
在RocketMQ中,我们主要通过三点来判断是否需要进行限流:
- 消息消费端队列中积压的消息超过 1000 条;
- 消息处理队列中积压的消息尽管没有超过 1000 条,但最大偏移量和最小偏移量的差值超过2000;
- 消息处理队列中积压的消息总大小超过100M。
RocketMQ一旦触发限流,往往会在${user_home}/logs/rocketmqlogs/rocketmq_client.log文件中打印对应的日志,如果日志中包含了关键字“so do flow control”,表明消费端存在性能瓶颈,这就是我们的突破方向。
如何排查RocketMQ消息消费积压问题?
那如何定位消费端慢在哪,又是卡在了哪行代码呢?
我们常用的排查方法是跟踪线程栈,利用jstack命令查看线程运行情况,以此探究线程的运行情况。通常可以使用下面的命令:
1 | ps -ef | grep java |
为了方便对比,我一般会连续打印五个文件,这样可以在五个文件中查看同一个消费者线程的状态,看它是否发生了变化。如果始终没有变化,说明该消费线程长时间阻塞,这就需要我们重点关注了。
在RocketMQ中,消费端线程以ConsumeMessageThread_打头,通过对线程的判断,可以发现下面这段代码:
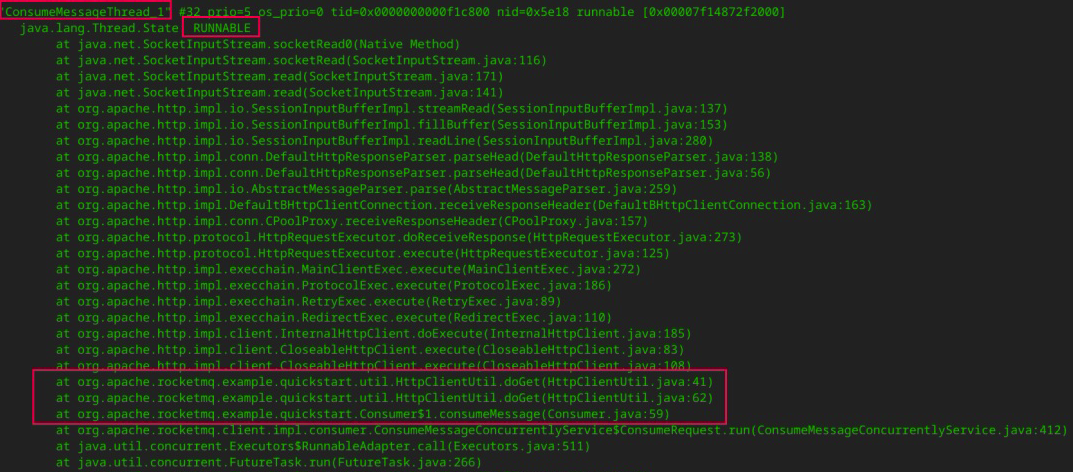
这些线程的状态为RUNNABLE,并且在jstack日志中状态一直没有发生变化,说明这些线程是有问题的。通过线程栈,我们可以清楚地定位到具体的代码行。
在这个示例中,通过对线程栈的分析,我们发现是调用HTTP请求时没有设置超时时间,这就导致线程一直阻塞,对应的消息始终没有处理完成。消息一直在处理队列(ProcessQueue)中,而RocketMQ采取的又是最小位点提交机制,消费位点无法继续向前推进,这才出现了消费积压。
至此,消费积压问题的根本原因就定位出来了。
最后,我还想跟你分享几个小经验。
结合我的生产实践,通常情况下,RocketMQ消息发送问题很可能与服务端有直接关系,而RocketMQ消费端遇到的一些性能问题通常与消费进程自身有关系。
另外,消费积压的时候,可以简单关注一下这个集群其他消费者的情况。如果其他消费者没有积压,只有你负责的消费组有积压,那就一定是消费端代码的问题了。
在这里最后再强调一遍,查看线程栈并不只是去查看线程状态为BLOCKED、TIME_WRATING的线程,RUNNABLE的线程状态同样需要查看。因为在一些网络操作中(例如,HTTP请求等待返回结果时、MySQL写入/查询等待获取执行结果时),线程的状态也是RUNNABLE。
总结
好了,今天就讲到这里。我们这节课主要是聚焦在RocketMQ消息消费积压这个核心问题上,这是消费端最常见的问题。
刚才,我简单地介绍了消费积压、和LastConsumeTime的计算规则,然后详细地介绍了RocketMQ消息消费的核心流程,探究了消费者的限流策略,最后介绍了精准定位消费积压的方法。
思考题
在课程的最后,我也给你留一道思考题。
我们这节课提到,RocketMQ在消费端主要通过三种方式来判断是否需要限流。其中,限制积压的消息条数和消息总大小这个很容易理解,因为这样可以避免内存溢出。可是,为什么还需要限制消息处理队列中最大与最小偏移量之间的间隔呢?
欢迎你在留言区与我交流讨论,我们下节课见!
20|技术选型:分布式定时调度框架的功能和未来
作者: 丁威

你好,我是丁威。
从这节课开始,我们将进入一个新的模块:定时调度中间件。
定时调度在业务开发领域的应用非常普遍,它通常会出现在数据清洗、批处理等应用场景中。我们这一模块总共分为三讲,首先,我们要来了解一下分布式定时调度框架的设计目标和未来,然后我会重点介绍一种基于ZooKeeper配置中心的编程模型,最后,我们会以一个实际场景串起分布式调度框架的要点。
定时调度框架要解决什么问题?市面上有哪些优秀的定时调度框架?定时调度未来的发展趋势又是什么?这节课我们就来聊聊这些问题。
定时调度功能需求
在大部分交易类场景下,比方说购物网站或者购票系统中,都会有一个特殊的业务规则:如果用户下单后超过指定时间未支付,平台将自动取消该订单。
定时延迟触发机制
要想实现这个功能,第一个必须具备的就是定时延迟触发机制。目前在定时调度领域,触发器都是基于cron表达式来定义的。cron表达式支持按日历的概念来定义定时语义。例如,每周五上午10点,每个工作日上午10点等。我们这节课不会详细介绍怎么编写cron表达式,因为现在很多网站都支持快速生成cron表达式。如果有需要,你可以看看这个网站。
一旦解决了定时任务的触发问题,要在用户没有支付时及时取消订单、释放库存的需求就变得比较简单了。我们只需要编写对应的订单超时逻辑,然后触发器就可以根据定义的cron表达式在指定的时间点调用业务执行器,完成业务逻辑。
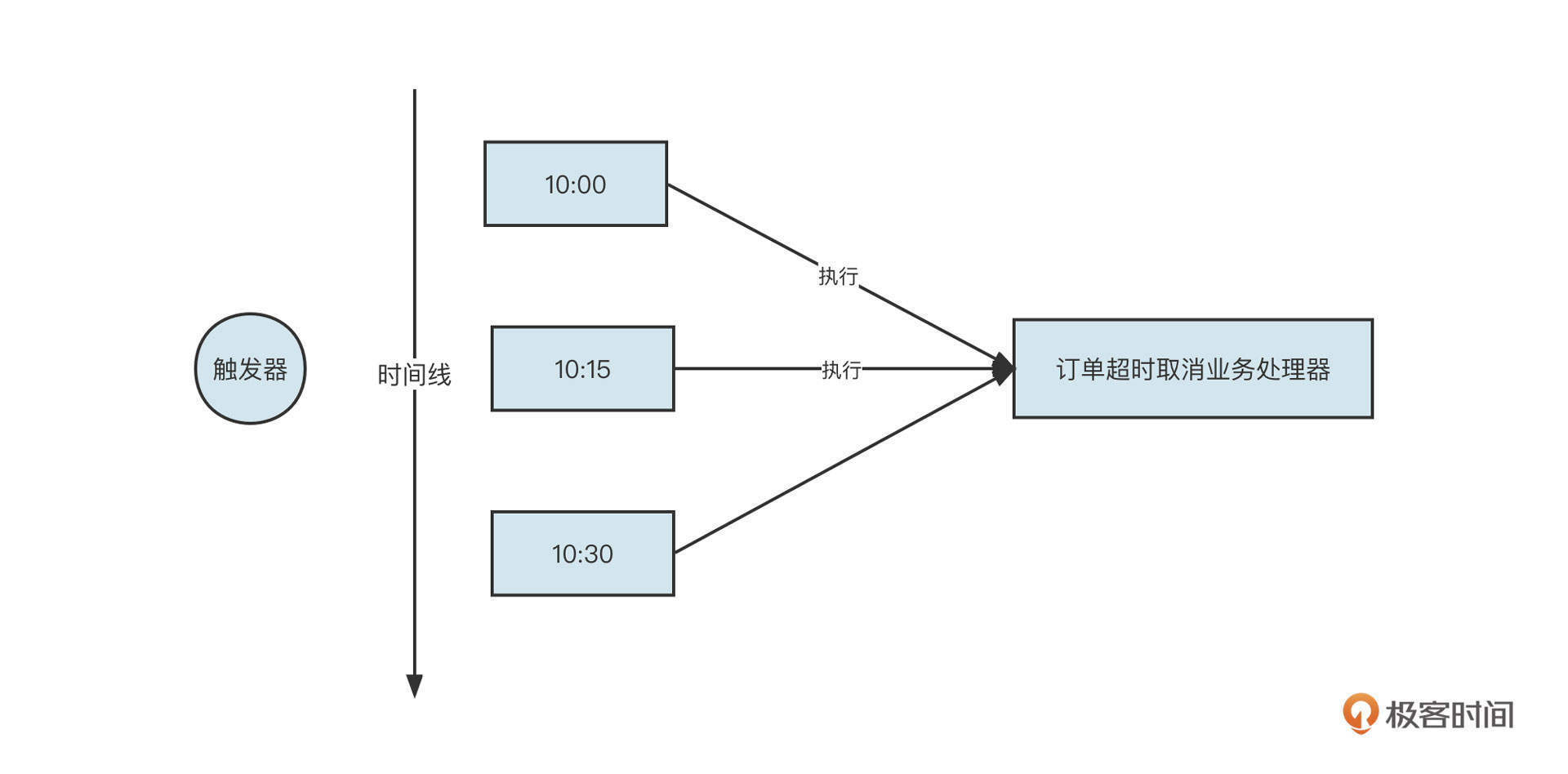
但一个项目中不可能只有一个任务,部门、公司更不可能只有一个任务,当需要管理的任务数量较多时,新的问题接踵而来:如何有效管理这些任务呢?
任务可视化管理机制
这样一来,定时调度又衍生了任务可视化管理需求,它通常包含:
- 任务的新建、编辑、查看;
- 任务的启动、停止、重启;
- 任务的调度历史、执行情况。
引入了任务可视化管理后,定时调度的架构基本是下面这个样子:
到这里,任务触发机制和任务可视化管理加起来,基本构成了定时调度框架的标配。它们可以帮助框架使用者方便地管理定时调度任务。但随着定时调度任务的逐渐增多,与之对应的是对可用性提出了更高的要求,也就是对触发器的分布式部署功能提出了更高的要求。支持分布式部署的架构如下图所示:
在分布式架构体系中,系统可以部署多个任务执行器,每一个任务执行器负责调度一部分任务。如果一个任务调度器宕机,任务可以转移到其他存活的调度器上去执行,从而实现高可用。
但随着业务的不断增长,单个定时调度任务需要处理的数据越来越多,单个任务执行的时长也逐步增加,这时,数据处理就容易出现较大延迟,当一个调度任务只在一个节点运行已经无法满足日益增长的数据要求时,提升性能就变得迫在眉睫了。
数据分片机制
为此,定时调度框架在分布式部署的基础上又引入了数据分片机制。调度触发器触发一次调度任务后,先计算本次调度需要执行多少数据,然后将这些数据按照分片算法切分成多份。这些独立的分片被包装为一个子任务,并被下发给不同的任务执行器。这样就实现了一个任务在不同进程之间的调度,从而提升了系统并发度。
错过执行任务重触发机制
通过分布式部署与数据切分后,定时框架就具备了高可用性、高性能和弹性扩缩容。不过在此基础上,定时调度框架还要提供错过执行任务重触发机制,这主要是为了避免任务调度次数丢失。
这个机制主要解决的是一个任务的执行时间大于任务调度频率的问题。例如,一个任务每隔5s调度一次,但如果一次调度期间业务的执行时间为15s,它的调度触发如表格所示:
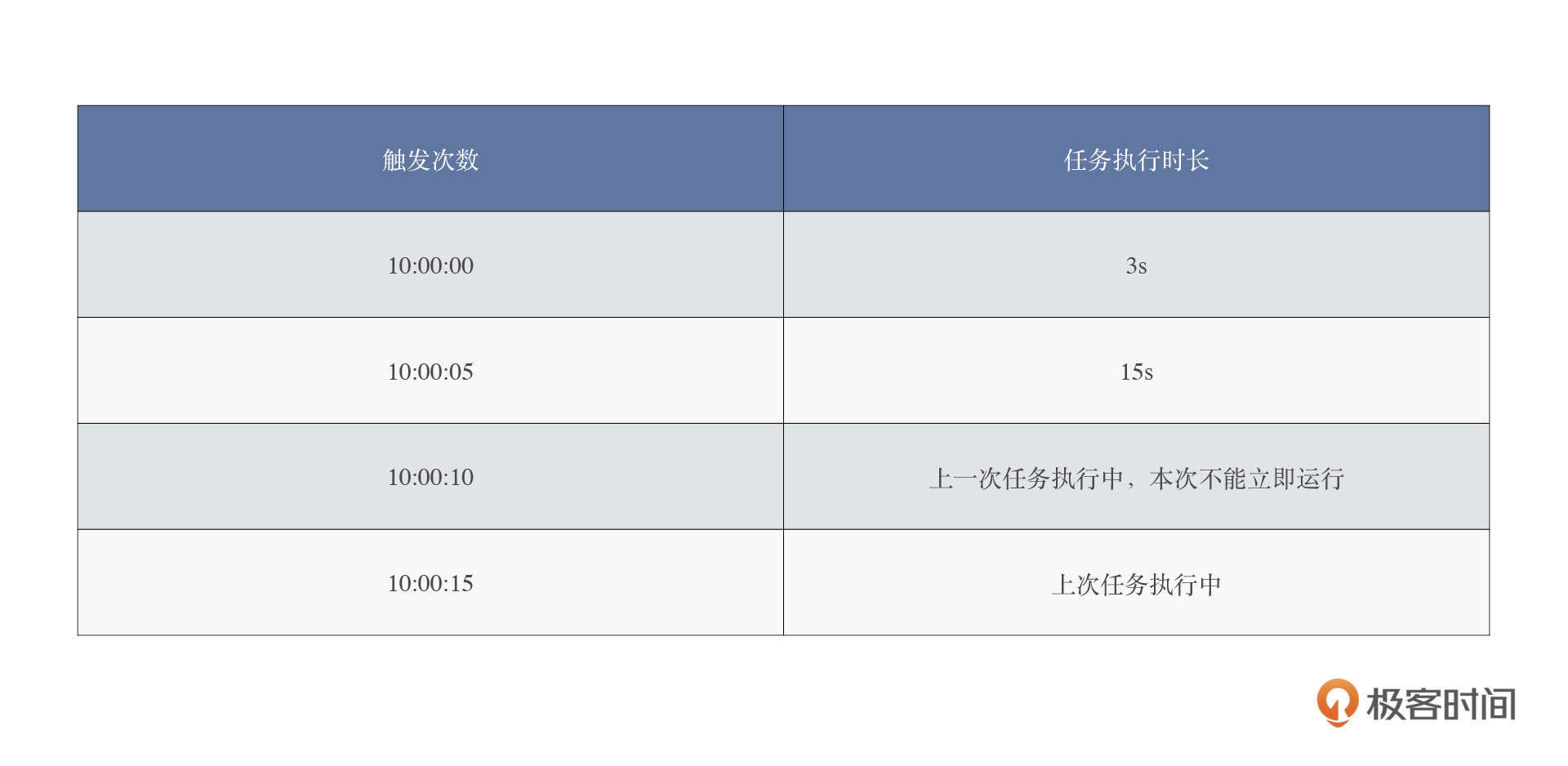
请你思考一下,错过执行的调度还需要继续执行吗?还是要等待下一次调度任务被触发呢?通常,定时调度应对这种情况应该提供一个参数供人选择。
当然,在实际业务中,还有一类定时调度任务更复杂,那就是有顺序要求的定时调度。只有执行完上一次调度任务之后,才能触发新的定时调度任务,通常的解决方案是,基于有向无环图(DAG)来定义作业之间的依赖。
定时调度框架发展与选型
了解了定时调度的基本功能需求后,我们再来看看市面上主流的分布式调度框架。
Quartz
互联网还没兴起时,Quartz是定时调度框架的王者。这是一个非常经典的分布式调度框架,它是基于数据库来实现任务的分配的。
Quartz集群部署如下图所示:
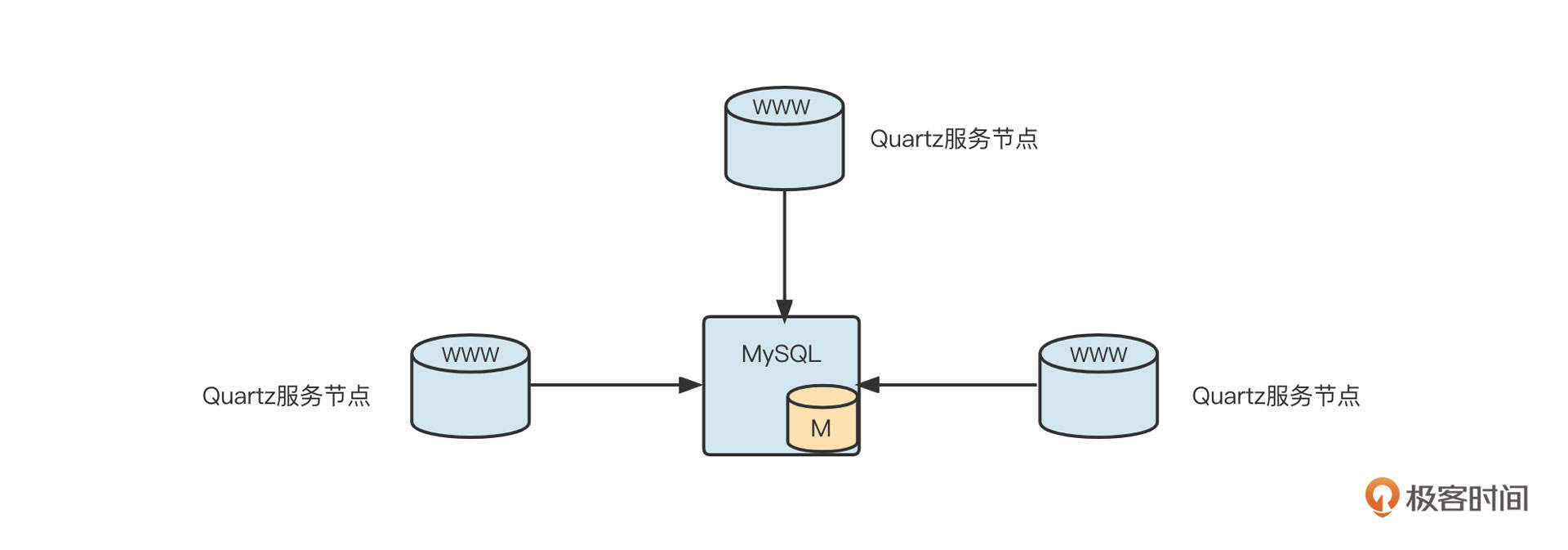
各个Quartz调度节点之间并不通信。
在Quartz中,节点默认每隔20s会查询数据库中的QRTZ_TRIGGERS,不断地去获取并和其他节点抢占Trigger。一旦该节点获取了Trigger的控制权,本次任务的调度就由调度器执行。
具体的抢占逻辑是,调度器尝试获取TRIGGER_ACCESS锁,成功获取锁的调度器执行本次调度,未获取锁的调度器进行锁等待,一旦获取锁的调度器释放锁,其他调度器就可以接管。具体的流程如下图所示:
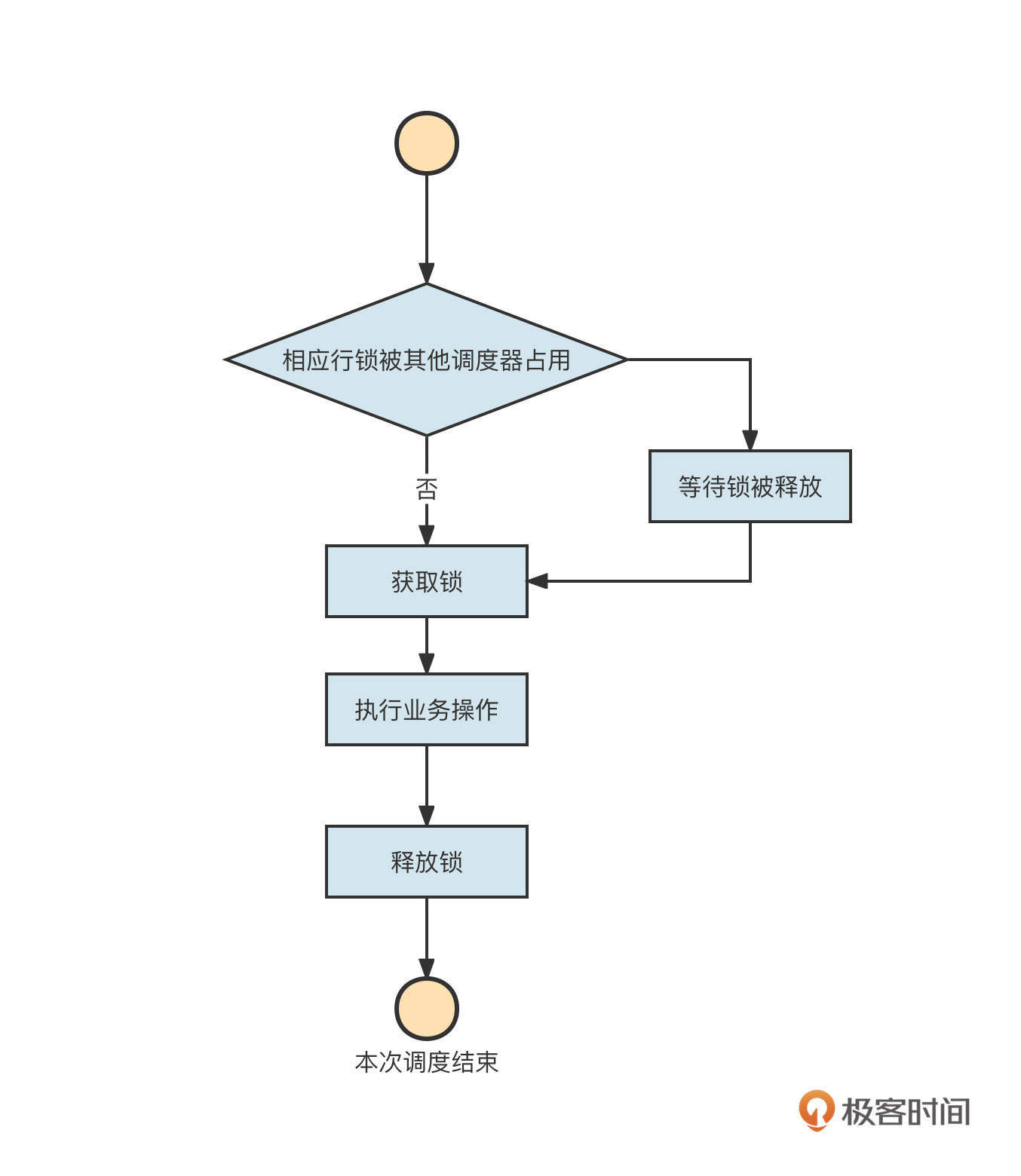
Quartz的使用方法非常简单,而且能够非常方便地支持Spring容器管理。但是如果需要管理的任务越来越多,特别是当触发周期很短的任务(例如每10s调度一次,每1min调度一次)越来越多时,基于数据库悲观锁的分布式调度机制就存在明显的性能瓶颈,无法支持快速发展的业务了。
伴随着互联网业务的不断扩大,互联网大厂都开源了自己的分布式调度框架,其中最典型代表就是ElasticJob和XXL-JOB。这两款调度框架的调度机制底层使用的都是Quartz。接下来我们就分别了解一下它们。
ElasticJob
ElasticJob 是一个分布式调度解决方案,最早由当当网开源,目前已经成为Apache ShardingSphere旗下的子项目。ElasticJob 由 2 个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成,但是因为目前市面上主要使用的是ElasticJob-Lite,所以接下来我们讲到的ElasticJob,主要指的就是这个ElasticJob-Lite。
ElasticJob的定位是轻量级的无中心化解决方案,其架构设计图如下:
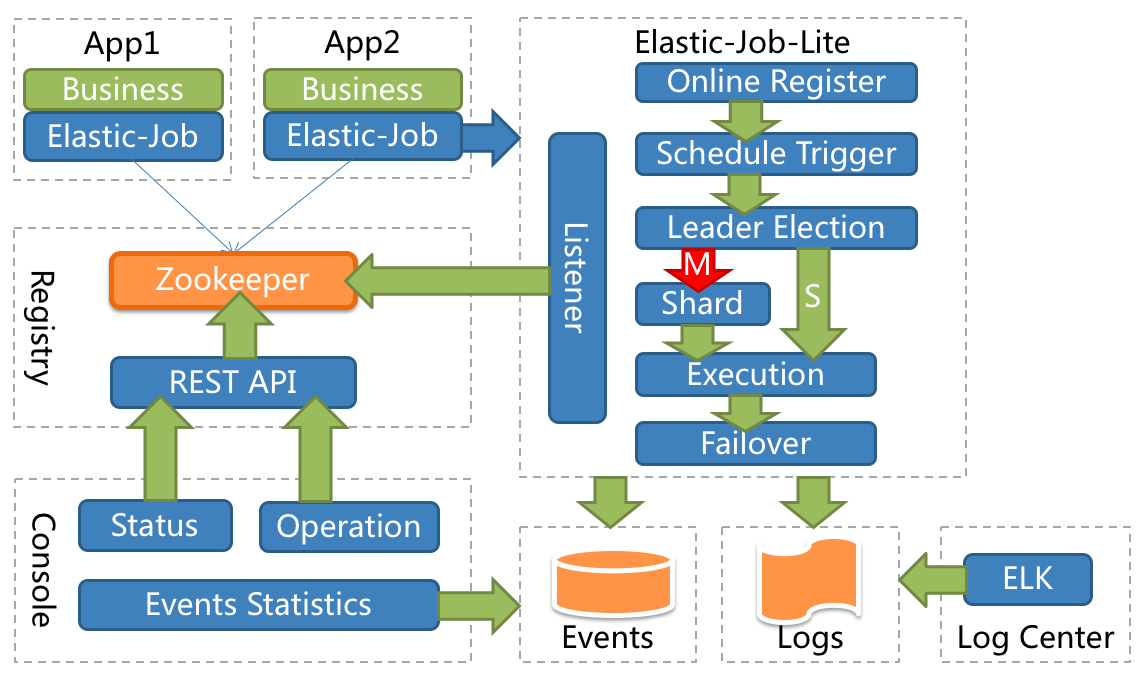
使用ElasticJob进行开发比较简单,通过在应用程序中引入ElasticJob的客户端Jar包,就可以完成定时调度任务业务逻辑。ElasticJob支持分布式部署、数据分片、弹性扩缩容、任务执行失败故障转移等高级特性。
启动ElasticJob的各个任务调度器后,当需要执行一个新的调度任务时,集群中所有的调度器会选举出一个Leader,后续的调度由Leader来统一承担。其他的调度器作为这个任务的备份。一旦Leader失败,其他备份调度器就会重新进行选举。
ElasticJob在功能维度也很丰富,它有下面几大亮点。
弹性调度
ElasticJob支持在分布式场景下的数据分片与高可用,支持水平扩展任务从而提高吞吐量,任务的处理能力可以随资源的配备进行弹性伸缩。
作业治理
ElasticJob支持分片失效转移、错过作业重新执行等特性。
可视化管控
ElasticJob提供了相对完善的运维作业管控端,支持作业历史数据追踪、注册中心管理等功能。
作业开放生态
ElasticJob提供了可扩展到作业类型的统一接口,能够与Spring依赖注入无缝整合。
稍显遗憾的是,ElasticJob对ZooKeeper具有强依赖,所有核心功能的实现都依赖ZooKeeper,并且调度与任务并未分离,一旦ZooKeeper出现问题,整个调度系统都可能瘫痪。
XXL-JOB
我们再来看看由大众点评开源的XXL-JOB分布式调度框架。
XXL-JOB的一个核心设计亮点是,它将调度行为抽象形成了“调度中心”公共平台,平台自身并不承担业务逻辑,而是由“调度中心”发起调度请求,实现了“调度”和“任务”之间的解耦合,它的核心架构设计图如下:
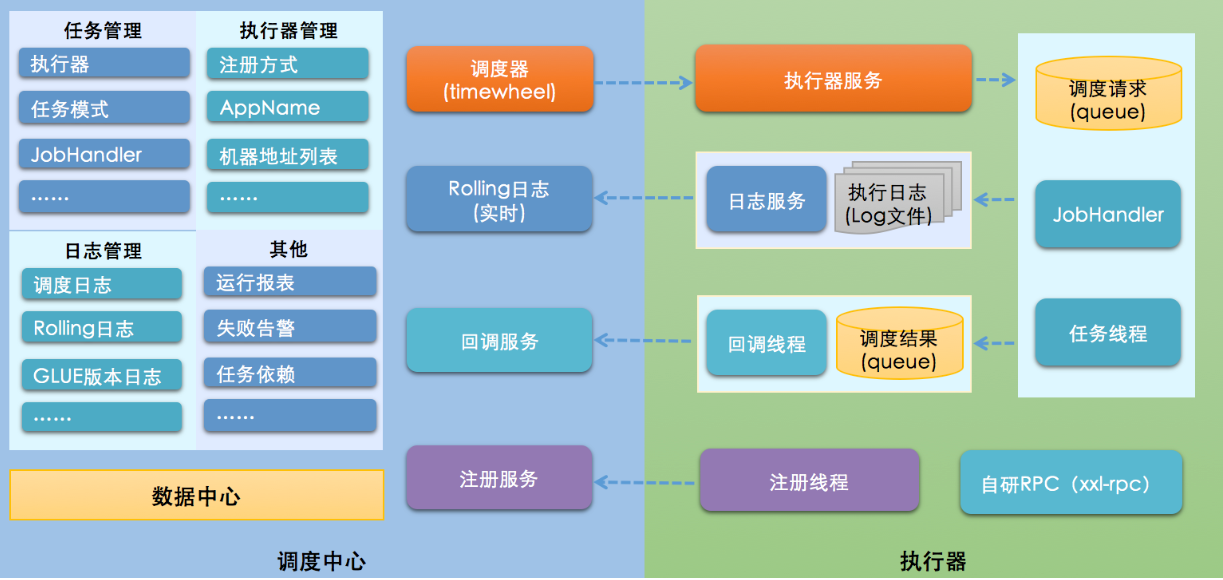
XXL-JOB的整体架构分为调度中心与执行器两个部分,我们简单说明一下它们的具体职责。
调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时,调度系统的性能不再受限于任务模块。
调度中心支持可视化,能够简单且动态地管理调度信息,这些操作包括任务新建,更新,删除,Glue开发和任务报警等,上面所有操作都会实时生效。同时,调度中心还支持监控调度结果和执行日志,支持执行器Failover。
执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效。
执行器的主要任务就是接收“调度中心”的执行请求、终止请求和日志请求等。
XXL-JOB与ElasticJob是两款非常优秀的分布式调度框架,我们针对分布式调度中的核心技术对它们做一个简单的对比:
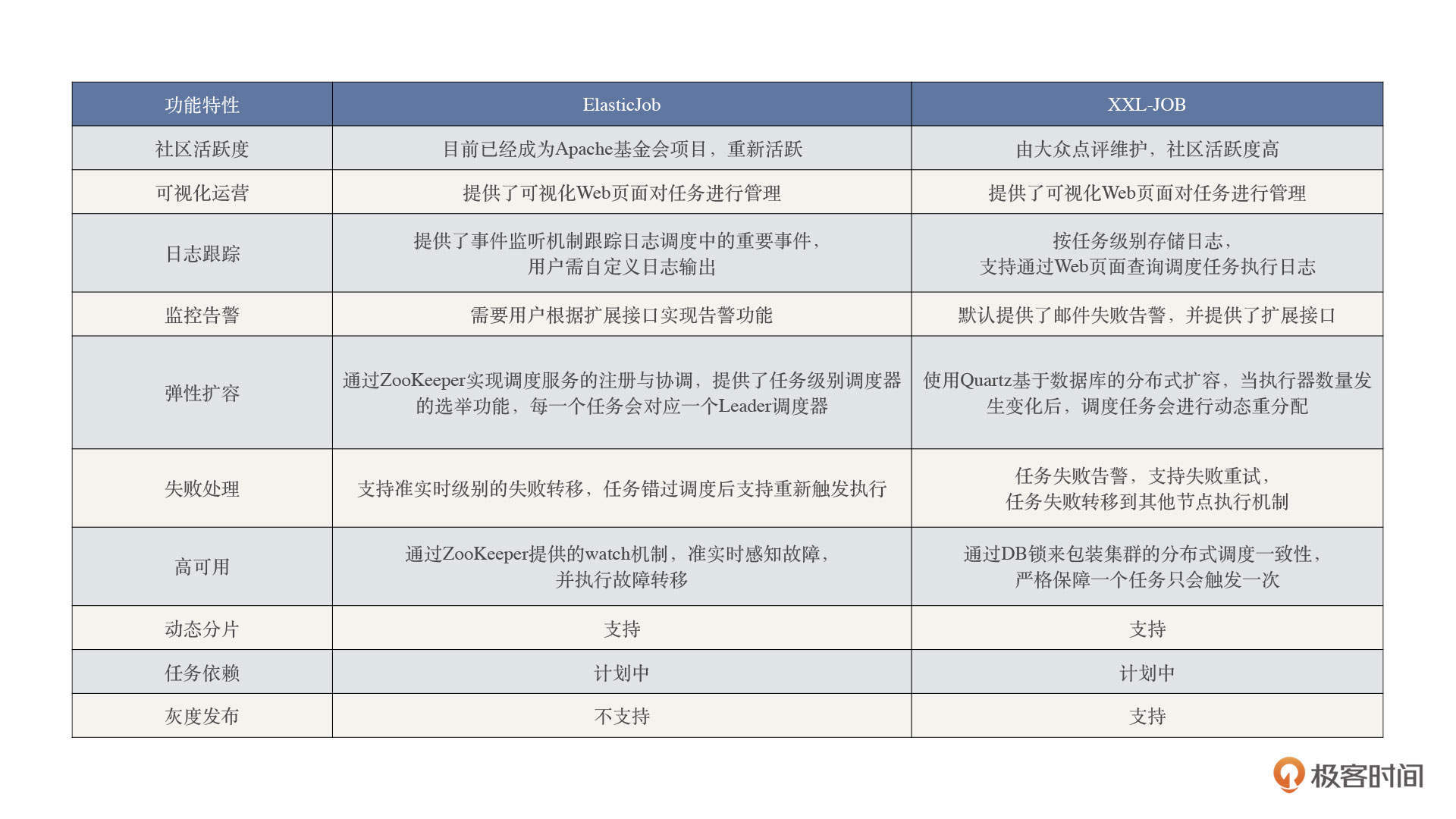
总的来看,XXL-JOB的集群、分布式调度是基于数据库的锁机制开发的,在处理数据量较大的任务时,还是会存在明显瓶颈。但XXL-JOB的应用类功能更加完善,并且在架构上采取调度与任务执行相分离的架构方案,扩展性更强。
ElasticJob更加关注数据,它的弹性扩容和数据分片机制更加灵活高效,能最大限度地利用分布式服务器的资源,性能强大。如果调度任务需要处理的数据量非常庞大,强烈推荐ElasticJob。
定时调度框架的自研思路
在这节课的最后,我想给你分享一下我们公司关于定时调度的自研思路。
我们前面看到的XXL-JOB和ElasticJob各有所长,你可能会想,如果能将它们的优点融合在一起就完美了。
不错,我们公司就是在充分调研了ElasticJob和XXL-JOB之后,决定自研定时调度框架。
我们重点吸收了XXL-JOB的“调度”和“任务”执行解耦合的思路。调度平台只负责任务的管理、触发,然后通过RPC等手段远程调度任务的执行,使得框架高度平台化。具体的运行效果如下:
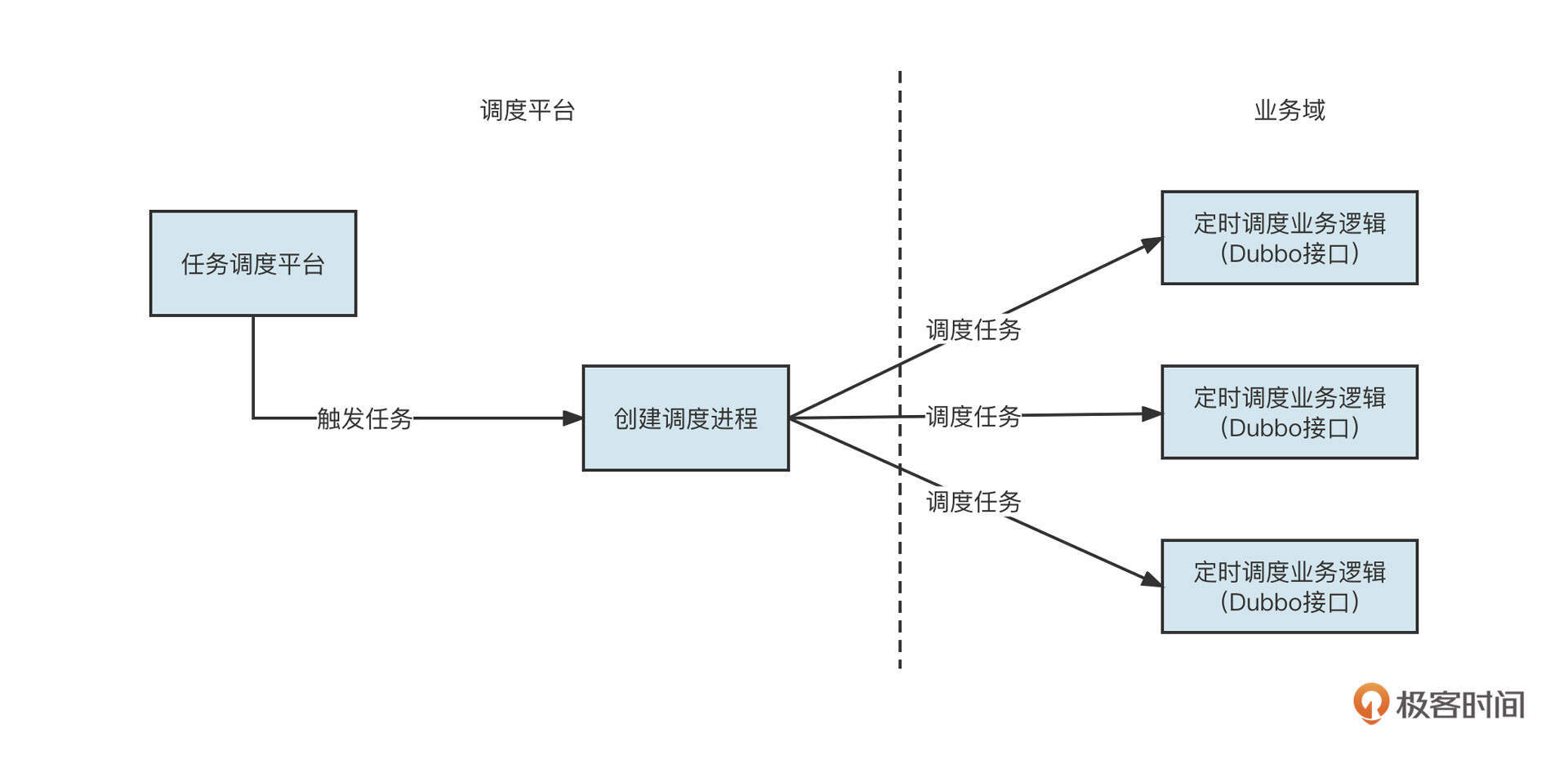
而我们调度器的数据分片、分布式调度、任务容错机制基本都参与ElasticJob进行,同时,我们还支持容器部署,使用容器部署能极大地提高资源利用率。
我们的定时调度框架通常有两类任务:批处理和定时调度。
批处理指的是在处理完一个批次后,如果有新的数据到达,就继续处理下一个批次。如果没有任务可执行,就休眠一段时间。
定时调度通常类似于每天凌晨几点定时执行这类任务。如果采用传统的虚拟机部署,这种任务一天只执行一次。但任务执行完成后,进程一直存活,虚拟机的资源一直被占用。但如果采用容器部署,执行完任务后,调度器就可以退出,等下一次触发时再创建新的调度器。
总结
好了,我们这节课就介绍到这里了。
在这节课的开始,我们从一个实际的使用场景出发,逐步引出了定时调度通常的功能需求,它们包括触发器、任务可视化管理、分布式部署、数据分片、故障转移、任务依赖等。
紧接着,我介绍了目前主流的分布式定时调度框架:Quartz、XXL-JOB和ElasticJob。我们重点对比了XXL-JOB和ElasticJob的差异。其中,XXL-JOB的一个显著的设计亮点是调度与任务执行的解耦合,而ElasticJob在分布式部署、数据分片等机制上的优势则非常明显,适合处理数据量较大的调度任务。
最后,我还简单介绍了我所在公司自研分布式调度框架的一些思路。如果你的公司有类似的需求,应该会给你一些启发。
课后题
学完这节课,我也给你留一道课后题。
分布式定时调度中一个最具亮点的功能应该就是数据分片机制了。那它是如何做到动态扩缩容的呢?在这里强烈建议你去研读一下ElasticJob在这方面的源码,一定会对你理解分布式调度框架大有裨益。
如果你在阅读源码上有一定难度,也可以参考我写的ElasticJob系列文章。欢迎你在留言区与我交流讨论,我们下节课再见!
21|设计理念:如何基于ZooKeeper设计准实时架构?
作者: 丁威

你好,我是丁威。
先跟你分享一段我的经历吧。记得我在尝试学习分布式调度框架时,因为我们公司采用的分布式调度框架是ElasticJob,所以我决定以ElasticJob为突破口,通过研读ElasticJob的源码,深入探究定时调度框架的实现原理。
在阅读ElasticJob源码的过程中,它灵活使用ZooKeeper来实现多进程协作的机制让我印象深刻,这里蕴藏着互联网一种通用的架构设计理念,那就是:基于ZooKeeper实现元信息配置管理与实时感知。
上节课中我们也重点提到过,ElasticJob可以实现分布式部署、并且支持数据分片,它同时还支持故障转移机制,其实这一切都是依托ZooKeeper来实现的。
基于ZooKeeper的事件通知机制
ElasticJob的架构采取的是去中心化设计,也就是说,ElasticJob在集群部署时,各个节点之间没有主从之分,它们的地位都是平等的。并且,ElasticJob的调度侧重对数据进行分布式处理(也就是数据分片机制),在调度每一个任务之前需要先计算分片信息,然后才能下发给集群内的其他节点来执行。实际部署效果图如下:
在这张图中,order-service-job应用中创建了两个定时任务job-1和job-2,而且order-service-job这个应用部署在两台机器上,也就是说,我们拥有两个调度执行器。那么问题来了,job-1和job-2的分片信息由哪个节点来计算呢?
在ElasticJob的实现中,并不是将分片的计算任务固定分配给某一个节点,而是以任务为维度允许各个调度器参与竞选,竞选成功的调度器成为该任务的Leader节点,竞选失败的节点成为备选节点。备选节点只能在Leader节点宕机时重新竞争,选举出新的Leader并接管前任Leader的工作,从而实现高可用。
那具体如何实现呢?原来,ElasticJob利用了ZooKeeper的强一致性与事件监听机制。
当一个任务需要被调度时,调度器会首先将任务注册到ZooKeeper中,具体操作为在ZooKeeper中创建对应的节点。ElasticJob中的任务在ZooKeeper中的目录布局如下:
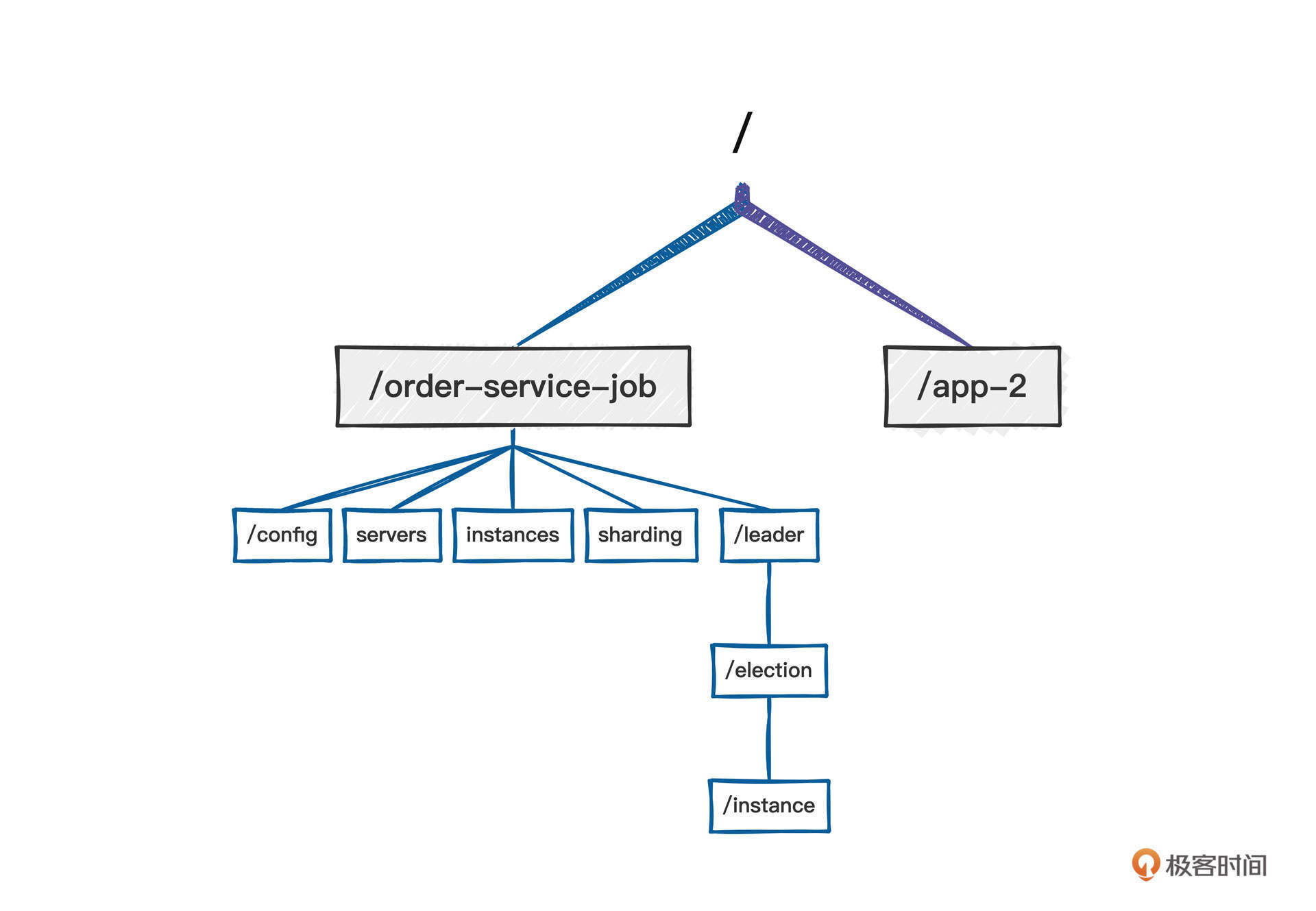
简单说明一下各个节点的用途。
- config:存放任务的配置信息。
- servers:存放任务调度器服务器IP地址。
- instances:存放任务调度器实例(IP+进程)。
- sharding:存放任务的分片信息。
- leader/election/instance:存放任务的Leader信息。
创建好对应的节点之后,就要根据不同的业务处理注册事件监听了。在ElasticJob中,根据不同的任务会创建如下事件监听管理器,从而完成核心功能:

我们这节课重点关注的是ElectionListenerManager的实现细节,掌握基于ZooKeeper事件通知的编程技巧。
ElectionListenerManager会在内部进行事件注册:
事件注册的底层使用的是ZooKeeper的watch,每一个监听器在一个特定的节点处监听,一旦节点信息发生变化,ZooKeeper就会通知执行注册的事件监听器,执行对应的业务处理。
一个节点信息的变化包括:节点创建、节点值内容变更、节点删除、子节点新增、子节点删除、子节点内容变更等。
调度器监听了ZooKeeper中的任务节点之后,一旦任务节点下任何一个子节点发生变化,调度器Leader选举监听器就会得到通知,进而执行LeaderElectionJobListener的onChange方法,触发选举。
接下来我们结合核心代码实现,来学习一下如何使用Zookeeper来实现主节点选举。
ElasticJob直接使用了Apache Curator开源框架(ZooKeeper客户端API类库)提供的实现类(org.apache.curator.framework.recipes.leader.LeaderLatch),具体代码如下:
1 | public void executeInLeader(final String key, final LeaderExecutionCallback callback) { |
我们解读一下关键代码。LeaderLatch需要传入两个参数:CuratorFramework client和latchPath。
CuratorFramework client是Curator的框架客户端。latchPath则是锁节点路径,ElasticJob的锁节点路径为:/{namespace}/{Jobname}/leader/election/latch。
启动LeaderLatch的start方法之后,ZooKeeper客户端会尝试去latchPath路径下创建一个临时顺序节点。如果创建的节点序号最小,LeaderLatch的await方法会返回后执行LeaderExecutionCallback的execute方法,如果存放具体实例的节点({namespace}/{jobname}/leader/election/instance)不存在,那就要创建这个临时节点,节点存储的内容为IP地址@-@进程ID,也就是说创建一个临时节点,记录当前任务的Leader信息,从而完成选举。
当Leader所在进程宕机后,在锁节点路径(/leader/election/latch)中创建的临时顺序节点会被删除,并且删除事件能够被其他节点感知,继而能够及时重新选举Leader,实现Leader的高可用。
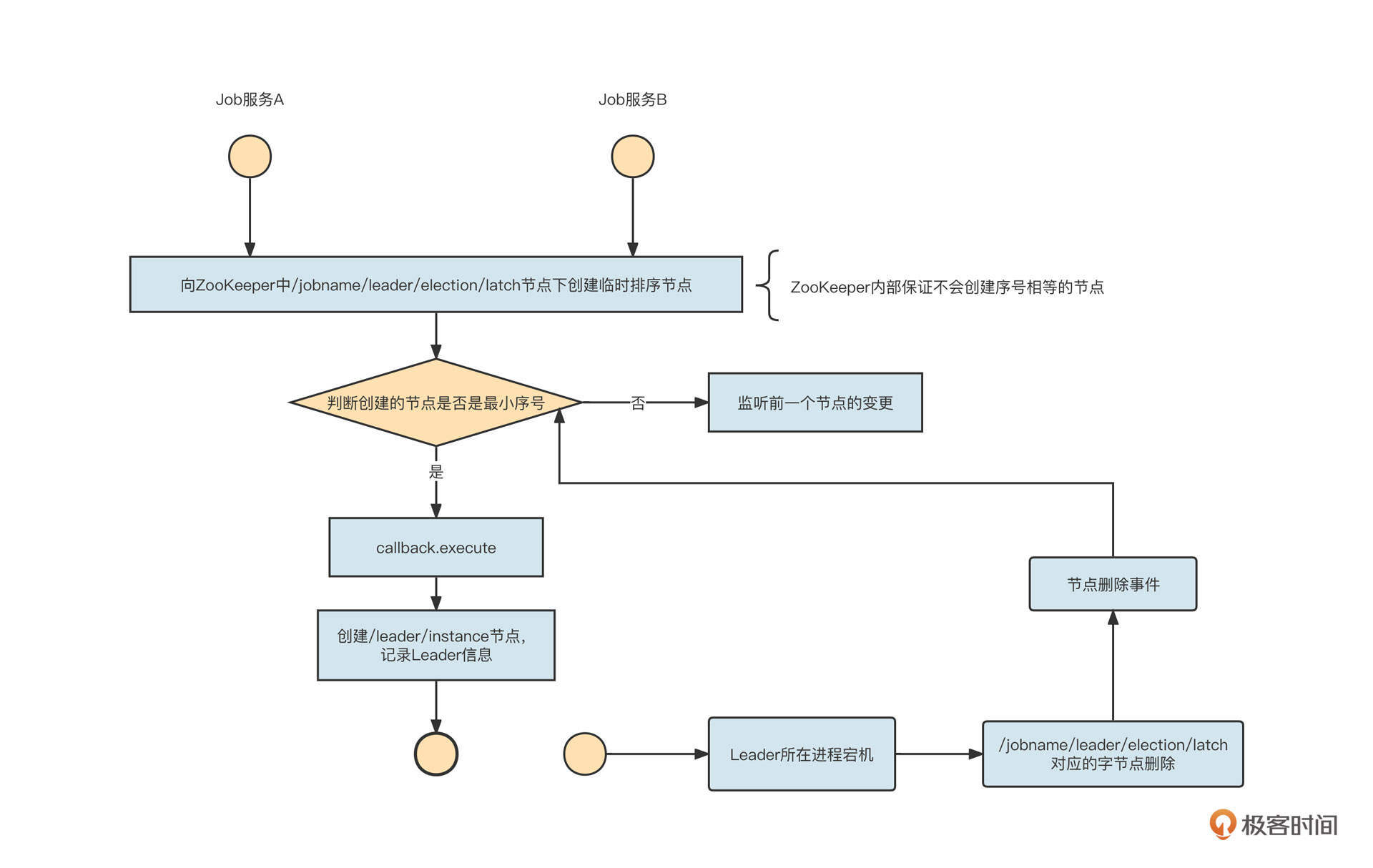
经过上面两个步骤,我们就基于ZooKeeper轻松实现了分布式环境下集群的选举功能。我们再来总结一下基于ZooKeeper事件监听机制的编程要点。
- 在Zookeeper中创建对应的节点。
节点的类型通常分为临时节点与持久节点。如果是存放静态信息(例如配置信息),我们通常使用持久节点;如果是存储运行时信息,则要创建临时节点。当会话失效后,临时节点会自动删除。
- 在对应节点通过watch机制注册事件回调机制。
如果你对这一机制感兴趣,建议你看看ElasticJob在这方面的源码,我的源码分析专栏 应该也可以给你提供一些帮助。
应用案例
深入学习一款中间件,不仅能让我们了解中间件的底层实现细节,还能学到一些设计理念,那ElasticJob这种基于ZooKeeper实现元数据动态感知的设计模式会有哪些应用实战呢?
我想分享两个我在工作中遇到的实际场景。
案例一
2019年,我刚来到中通,我在负责的全链路压测项目需要在压测任务开启后自动启动影子消费组,然后等压测结束后,在不重启应用程序的情况下关闭影子消费组。我们在释放线程资源时,就用到了ZooKeeper的事件通知机制。
首先我们来图解一下当时的需求:
我们解读一下具体的实现思路。
第一步,在压测任务配置界面中,提供对应的配置项,将本次压测任务需要关联的消费组存储到数据库中,同时持久到ZooKeeper的一个指定目录中,如下图所示:

ZooKeeper中的目录设计结构如下。
- /zpt:全链路压测的根目录。
- /zpt/order_service_consumer:应用Aphid。
- /zpt/order_service_consumer/zpt_task_1:压测任务。
- /zpt/order_service_consumer/zpt_task_1/order_bil_group:具体的消费组。
在这里,每一个消费组节点存储的值为JSON格式,其中,从enable字段可以看出该消费组的影子消费组是否需要启动,默认为0表示不启动。
第二步,启动应用程序时,应用程序会根据应用自身的AppID去ZooKeeper中查找所有的消费组,提取出各个消费组的enable属性,如果enable属性如果为1,则立即启动影子消费组。
同时,我们还要监听/zpt/order_service_consumer节点,一旦该节点下任意一个子节点发生变化,zpt-sdk就能收到一个事件通知。
在需要进行全链路压测时,用户如果在全链路压测页面启动压测任务,就将该任务下消费组的enable属性设置为1,同时更新ZooKeeper中的值。一旦节点的值发生变化,zpt-sdk将收到一个节点变更事件,并启动对应消费组的影子消费组。
当停止全链路压测时,压测控制台将对应消费组在ZooKeeper中的值修改为0,这样zpt同样会收到一个事件通知,从而动态停止消费组。
这样,我们在不重启应用程序的情况下就实现了影子消费组的启动与停止。
注册事件的关键代码如下:
1 | private CuratorFramework client; // carator客户端 |
事件监听器中的关键代码如下:
1 | class MqConsumerGroupDataNodeListener extends TreeCacheListener { |
案例二
在这节课的最后,我们再看一下另外一个案例:消息中间件SDK的核心设计理念。
我们公司对消息中间件的消息发送与消息消费做了统一的封装,对用户弱化了集群的概念,用户发送、消费消息时,不需要知道主题所在的集群地址,相关的API如下所示:
1 | public static SendResult send(String topic, SimpleMessage simpleMessage) |
那问题来了,我们在调用消息发送API时,如何正确路由到真实的消息集群呢?
其实,我们公司对主题、消费组进行了强管控,项目组在使用主题、消费组之前,需要通过消息运维平台进行申请,审批通过后会将主题分配到对应的物理集群上,并会将topic的元数据分别存储到数据库和ZooKeeper中。因为这属于配置类信息,所以这一类节点会创建为持久化节点。
这样,消息发送 API 在初次发送主题时,会根据主题的名称在ZooKeeper中查找主题的元信息,包括主题的类型(RocketMQ/Kafka)、所在的集群地址(NameServer地址或Kafka Broker地址)等,然后构建对应的消息发送客户端进行消息发送。
那我们为什么要将主题、消费组的信息存储到ZooKeeper中呢?
这是因为,为了便于高效运维,我们对主题、消费组的使用方屏蔽了集群相关的信息,你可以看看下面这个场景:
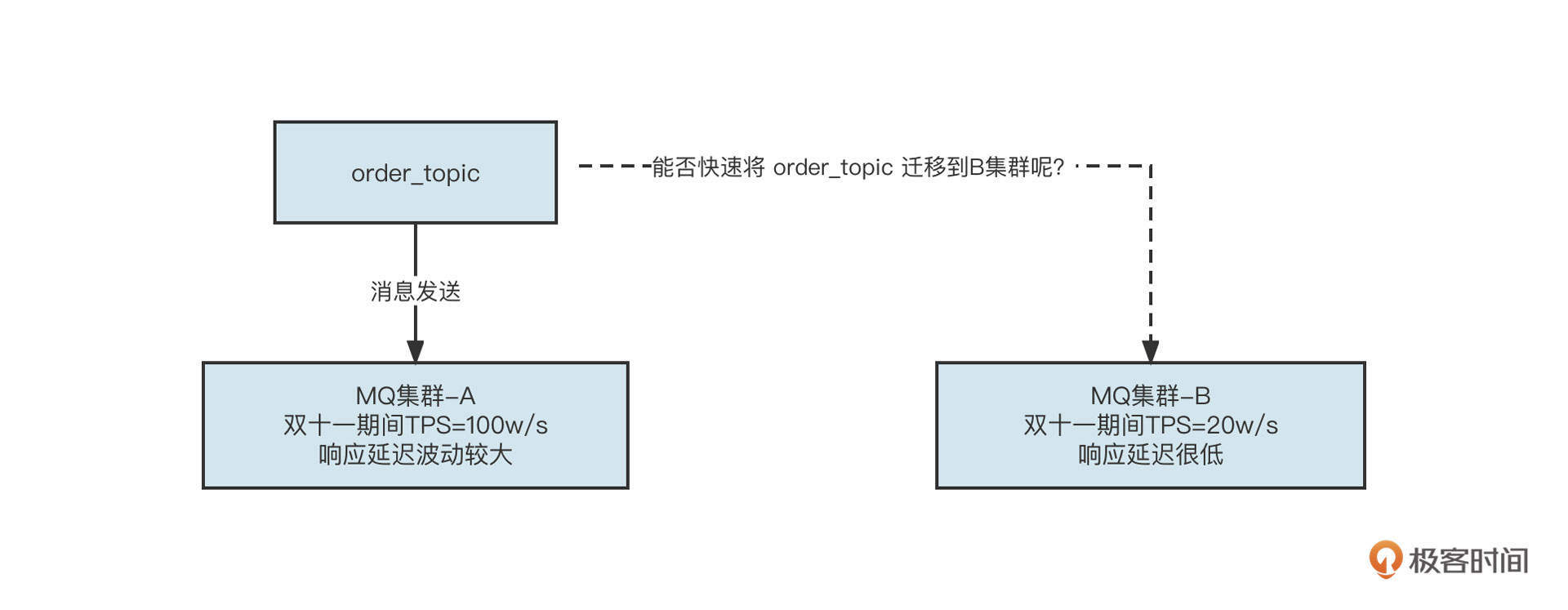
你能在不重启应用的情况下将order_topic从A集群迁移到B集群吗?
没错,在我们这种架构下,将主题从一个集群迁移到另外一个集群将变得非常简单。
我们只需要在ZooKeeper中修改一下order_topic的元信息,将维护的集群的信息由集群A变更为集群B,然后zms-sdk在监听order_topic对应的主题节点时,就能收到主题元信息变更事件了。然后zms-sdk会基于新的元信息重新构建一个MQ Producer对象,再关闭老的生产者,这样就实现了主题流量的无缝迁移,快速进行故障恢复,极大程度保证了系统的高可用性。
我们公司已经把这个项目开源了,具体的实现代码你可以打开链接查看(ZMS开源项目)。
总结
好了,这节课我们就介绍到这里了。
这节课我们通过ElasticJob分布式环境中的集群部署,引出了ZooKeeper来实现多进程协作机制。并着重介绍了基于ZooKeeper实现Leader选举的方法。我们还总结出了一套互联网中常用的设计模式:基于ZooKeeper的事件通知机制。
我还结合我工作中两个真实的技术需求,将ZooKeeper作为配置中心,结合事件监听机制实现了不重启项目,在不重启应用程序的情况下,完成了影子消费组和消息发送者的启动与停止。
课后题
最后我也给你留一道题。
请你尝试编写一个功能,使用curator开源类库,去监听ZooKeeper中的一个节点,打印节点的名称,并能动态感知节点内容的变化、子节点列表的变化。程序编写后,可以通过ZooKeeper运维命令去操作节点,从而验证程序的输出值是否正确。
欢迎你在留言区与我交流讨论,我们下节课再见。
22|案例:使用分布式调度框架该考虑哪些问题?
作者: 丁威

你好,我是丁威。
定时调度框架的应用非常广泛,例如电商平台的订单支付超时被取消时,数据清洗时等等。在中间件应用领域,定时调度框架通常和MQ等中间件组合使用,联合完成分布式环境下事务的最终一致性。
这节课,我们就一起来看看定时调度框架在消息发送领域的事务一致性设计方案和落地细节。
设计方案
不知道你还记不记得我在第13讲中提到的用户注册优惠活动的场景,为了实现用户注册主流程与活动的解耦合,我们引入了消息中间件,它的时序图如下所示:
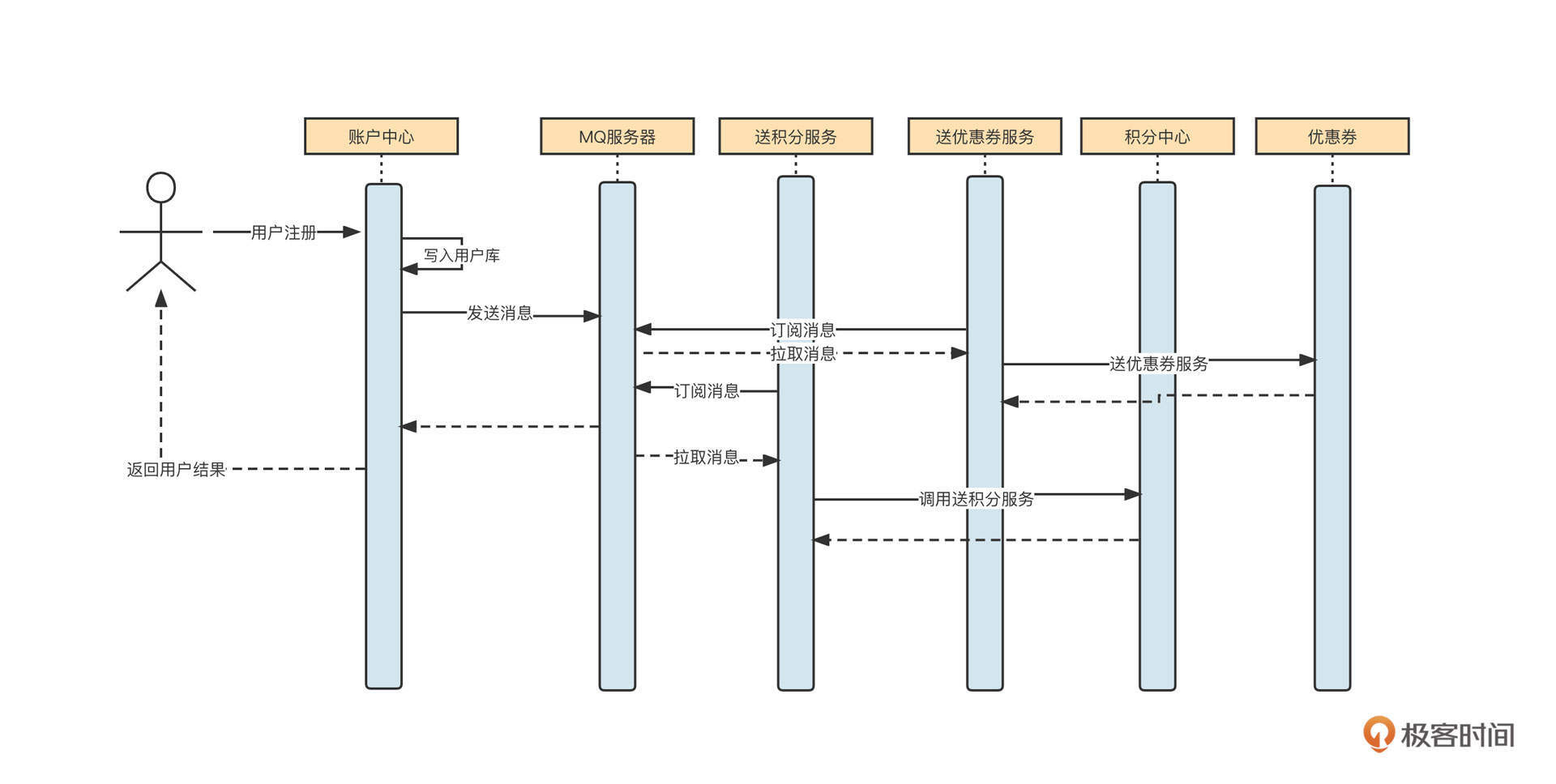
这里的核心指导思想是让账户中心完成用户的注册逻辑,将用户写入到账户中心数据库,然后发送一条消息到MQ服务器,再给返回用户“注册成功”。之后,引入两个消费者,分别对消息进行对应的处理,异步赠送优惠券或者积分。
这个方法的架构思路非常不错,但是我们还不得不思考一个问题:如何保证写入数据库与消息发送这两个步骤的一致性呢?我们希望这两个步骤要么一起成功,要么一起失败,绝不能出现用户数据成功写入数据库,但消息发送失败的情况。因为这样用户无法收到优惠券,容易产生一系列的投诉和纠纷。
这其实是一个分布式事务的问题,也就是要保证数据库写入和消息发送这两个分布式操作的一致性。
一种比较常见的解决方案就是:“本地消息表+定时任务”。
具体而言,我们首先需要在数据库创建一张本地消息表,表的结构大致如下:

创建了消息发送本地记录表之后,用户注册的流程将变成:
- 开启数据库本地事务;
- insert into user 表(用户注册表);
- insert into msg_send_record,并且存储账户的唯一编号、状态,其中状态的初始值为0;
- 提交本地事务。
这样做的目的是,保证user表和msg_send_record的事务一致性,如果用户信息成功存入user表,msg_send_record表中必然存在一条对应的记录,后续我们只需要根据msg_send_record表中的记录发送一条对应的MQ消息即可。
当然,为了保证msg_send_record的写入不至于带来太大的性能损耗,通常我们会采取下面几个措施。
- 如果在分库分表环境中,msg_send_record采取的分库策略与user表一致,我们要保证这个过程是一个本地事务,不至于出现跨库Join的情况。
- 为account_no、创建时间这两个字段添加索引。
- 定时清除msg_send_record表中的数据,这个表不需要保留太长时间,尽量控制单表数据量。
数据成功写入消息待发送表后,接下来我们需要引入定时调度程序,定时扫描msg_send_record中的记录,将消息发送到MQ中。
定时调度程序的数据处理策略主要有三步。首先,按照分页机制从数据库中拉取一批数据;然后,根据用户账户查询用户表,构建消息体(用户账户、用户注册时间);最后,将消息发送到消息服务器(这里必须提供重试机制)。
引入定时调度程序后,用户注册送积分的时序图变成了下面这样:
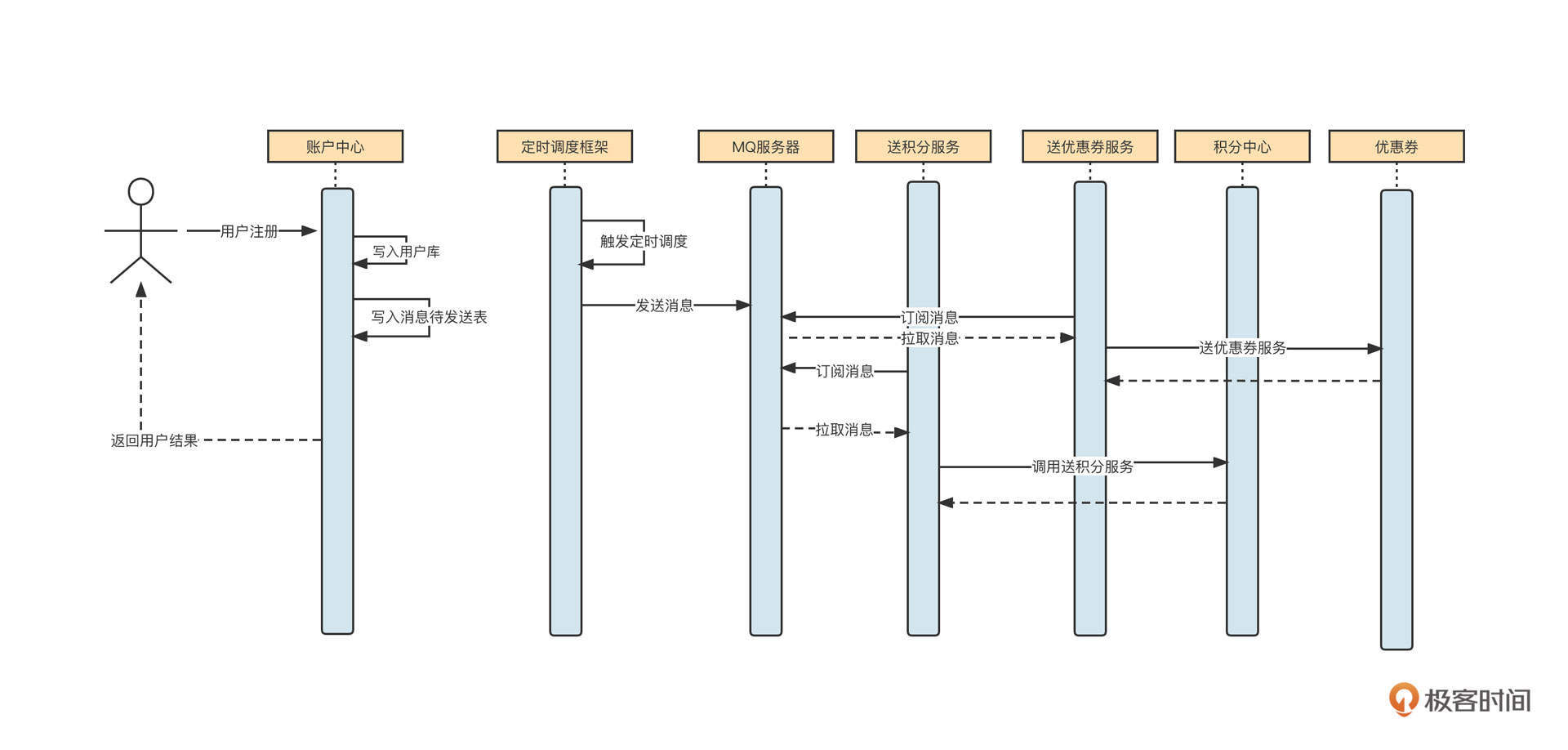
在计划执行这个方案时,还有一个非常重要的事情,就是要明确定时调度任务的执行频率。
因为定时调度任务的调度频率直接决定了消息发送的实时性,随着需要调度的任务越来越多,大部分定时调度框架对秒级别的定时调度都不太友好。这时的调度通常都是分钟级的,但分钟级的调度会给任务带来较大的延迟,这是大部分业务无法容忍的,怎么办呢?
ElasticJob可以通过支持流式任务解决这个问题。具体的思路是:将任务配置为按照分钟级进行调度,例如每分钟执行一次调度。每次调度按照分页去查找数据,处理完一批数据,再查询下一批,如果查到待处理数据,就继续处理数据,直到没有待处理数据时,才结束本次业务处理。如果本次处理时间超过了一个调度周期,那么利用ElasticJob的任务错过补偿执行机制会再触发一次调度。
在业务高峰期,这种方式基本上提供了准实时的处理效果。只有在业务量较少时,如果处理完一批数据后没有其他待处理的数据,这时新到的数据才会延迟1分钟执行。
综合来看,通过支持流式任务,我们可以极大地提高数据的处理时效。
消息领域定时调度框架的设计方案就介绍到这里了,我想你也许会问,RocketMQ不是已经提供了事务消息机制吗?这里能不能直接使用RocketMQ的事务消息呢?
当然可以。但是很多公司的内部都采用了多种类型的消息中间件,有的中间件并不支持事务消息这个功能。考虑到架构设计方案的普适性,我们通常不会依赖单个中间件的特性。
方案落地
了解了设计方案,我们就可以实现消息发送和数据库操作的分布式事务一致性了。光说不练假把式,接下来,我们就尝试落地这个方案。我会给出一些关键代码,方便你在生产环境中落地实战。
我会基于ElasticJob框架简单梳理一下关键代码。通过ElasticJob实现一个定时调度任务通常包含两个重要步骤。
首先,我们要实现ElasticJob的流式任务接口DataflowJob,这个接口主要完成定时调度任务的具体业务逻辑:
1 | public class UserSendMqJob implements DataflowJob<UserMsgSendRecord> { |
DataflowJob接口主要定义fetchData和processData接口,我们分别解读一下这两个接口的实现要点。
先说一下fetchData。
它主要用于拉取待处理数据,ElasticJob每触发一次任务调度,都会首先调用fetchData方法,尝试获取数据。如果该方法返回数据,ElasticJob将调用processData来完成具体的业务逻辑。处理完一批数据后,还会循环调用fetchData,看有没有待处理的数据。如果有,则继续调用processData,直到查询不到待处理数据时,结束本次业务调度。
这里有一个非常关键的点:我们可以通过ShardingContext来获取任务的分片信息。其中,shardingTotalCount是本次任务的总分片数量,shardingItem是当前任务所处理数据的分片序号。通常我们可以用这两个数和id取模,实现数据分片。你可以看看下面这张示意图:
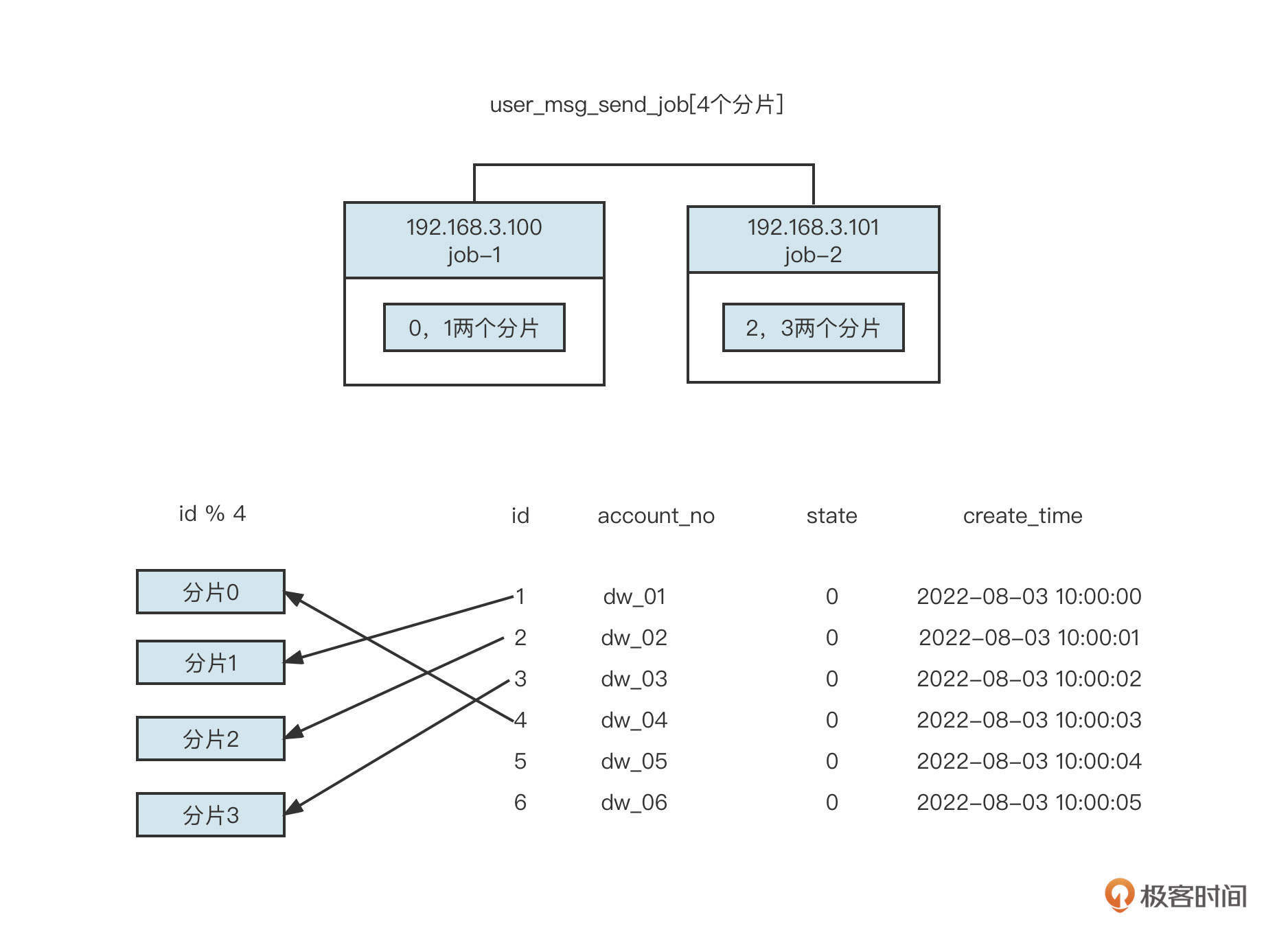
processData方法,顾名思义,就是用来处理业务逻辑的方法。通过fetchData方法查询到的数据会传入processData方法中执行,我们这个实例主要是根据待发送记录组装MQ消息,然后将消息发送到MQ服务器,更新待发送记录,最后将状态从待发送变更为已发送的过程。
不过在实际执行过程中,通常还会遇到另外一个问题。假设我们的业务逻辑要根据不同的类型发送不到不同的MQ集群中,部分主题可能一直发送失败,最后影响到其他主题的正常发送。具体的示意图如下:
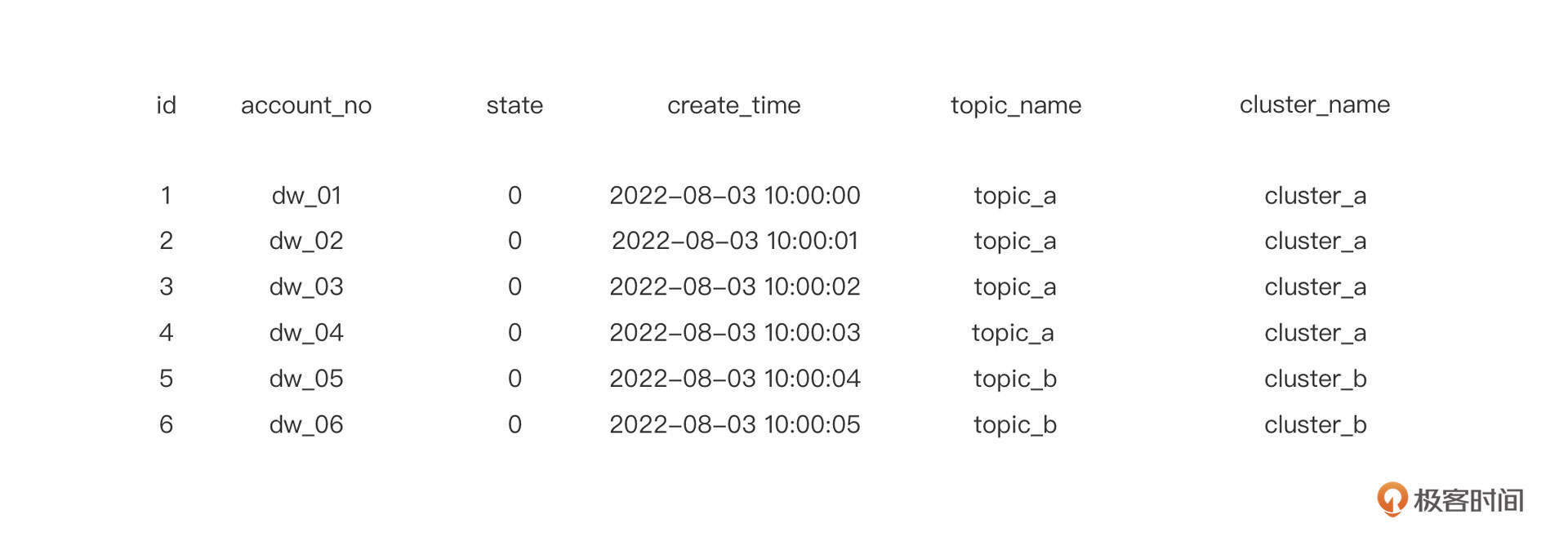
如果fetchData在获取数据时,每一次只拉取3条消息,那么它会一次取出id为1,2,3的三条消息,然后将这些消息发送到cluster_a集群的topic_a主题。如果某一时刻集群cluster_a发生故障,一段时间内无法发送消息,数据仍然被传入proccessData方法,就会发现fetchData每次拉取出的id都是1,2,3。因为这些消息在proccessData中没有处理成功,state的状态不会更新,需要发往集群b的消息也无法正常发送,这会导致严重的业务故障。
那我们如何解决这个问题呢?
第一步,我们要在消息待发送表(msg_send_record)中增加两个字段,一个是当前重试次数(retry_count),另外一个是下一次调度的最小时间(next_select_time)。增加了这两个字段的表数据是下面这样:

在处理数据时,如果第一次处理数据失败了,我们需要将重试次数加一,并设置下一次调度的最小时间。例如,用当前时间加一分钟,意味着一分钟内流式处理任务将不再拉取该数据,这就给了其他数据执行机会。
第二步,通过配置文件或者其他整合方式声明一个任务,我们这个实例是用Spirng方式整合了ElasticJob,所以我们需要在XML文件中配置任务,具体的配置代码如下:
1 | <job:dataflow id="UserSendMqJob" class="net.codingw.mq.task.UserSendMqJob" registry-center-ref="zkRegistryCenter" |
我们简要说明一下这些配置参数的含义。
- id:任务id,它是全局唯一的。
- class:调度任务逻辑具体实现类。
- registry-center-ref:ElasticJob调度器依赖的ZooKeeper Bean。
- cron:定时调度cron表达式。
- sharding-total-count:总分片个数。
- sharding-item-parameters:分片参数,用于定义各个分片的参数。在进入到fetchData方法时,可以原封不动地获取该值,方便地实现一些定制化数据切分策略。
- failover:是否支持故障转移。设置为“true”表示支持,设置为“false”表示禁用故障转移机制。
- streaming-process:是否启用流式任务,true表示启用流式任务。
关于使用ElasticJob的其他代码我在这里就不详细介绍了,如果你对使用ElasticJob的方法还不是太熟悉,可以看看官方提供的官方示例代码。
总结
好了,我们这课就讲到这里了。
这节课,我们围绕中间件领域如何实现消息发送与业务的分布式事务这个核心问题,详细展示了用ElasticJob开发定时调度任务的方法。
我们学习了目前业界解决分布式事务最经典的方案:定时调度+本地消息表。这个方案结合ElasticJob支持流式任务的特性,提升了任务的实时性。我们也总结了流式任务最常见的“坑”,给出了可行的解决方案。
课后题
学完这节课,给你留一道思考题。
你有没有在工作中遇到需要处理分布式事务的场景?你又是如何设计的呢?
欢迎你在留言区与我交流讨论,我们下节课再见!
23|案例:如何在生产环境进行全链路压测?
作者: 丁威

你好,我是丁威。
不知不觉,我们已经进入了专栏的最后一个板块。这节课,我想给你介绍一下我在全链路压测领域的一些实践经验,让你对中间件相关技术有一个全局的理解。
实际上,全链路压测也是我进入中通负责的第一个项目。当时,我们需要从0到1打造全链路压测项目,而我对主流中间件的深入了解,在项目的开发和启动过程中发挥了极大的作用,也让作为新人的我在新公司站稳了脚跟。
全链路压测概述
那什么是全链路压测呢?网上关于它的定义有很多,所以我在这里只给出一个可能不太全面,但是比较简单易懂的我的版本:全链路压测就是在生产环境对我们的系统进行压测,压测流量的行进方向和真实用户的请求流量是一致的,也就是说压测流量会完全覆盖真实的业务请求链路。
全链路压测的核心目的是高保真地检测系统的当前容量,方便在大促时科学合理地扩缩容,为合理规划资源提供可视化的数据支撑。
在介绍全链路压测之前,我们先来看一张简易的数据流向图,感受一下我们公司需要落地全链路压测的底层系统的布局情况:
首先,压测端通常采用JMeter构建压测请求(HTTP请求),全链路压测系统需要提供一种机制对真实的业务流量与测试流量加以区分,然后压测流量与真实流量分别进入接入层的负载均衡组件,最终进入接口网关。接口网关再发起HTTP或者Dubbo等RPC请求,进入到内部的业务系统。
内部系统A可能会访问MySQL数据库或者Redis,同时存在一些数据同步组件将MySQL的数据抽取到Elasticsearch中。接着,内部应用B可能会继续调用内部应用C,让C发送消息到MQ集群。下游的消费者应用消费数据,并访问Es、MySQL等存储组件。
我们可以用一张图概括一套完整的全链路压测的基本功能需求:
简单解释一下不同阶段的内涵。
压测前
主要任务是构建压测数据。全链路压测的核心目标是高保真模拟真实请求。但目前市面上的性能压测实践基本都是通过JMeter来人工模拟接口的数据最终生成测试请求的,这样无法反馈用户的真实行为。全链路压测最期望的结果是对真实用户请求日志进行脱敏和清洗,然后将其存入数据仓库中。在真正进行压测时,根据数据仓库中的数据模拟用户的真实行为。
压测运行时
主要包括请求打标、透传以及各主流中间件的数据隔离,这是全链路压测的基座。
压测后
压测结束后,我们需要生成压测报告并实时监控压测过程,一旦压测过程中系统扛不住,要立马提供熔断压测,避免对生产环境造成影响。
我这节课不会覆盖全链路压测的方方面面,而是主要介绍与中间件关联非常强的流量染色与透传机制和数据隔离机制。
流量染色与透传机制
我们首先来介绍流量染色与透传机制。其中,流量染色的目的就是正确地标记压测流量,确保在系统内部之间进行RPC调用、发送MQ等操作之后,能够顺利传递压测流量及其标记,确保整个过程中流量标记不丢失。
流量染色与透传机制的设计概要如下:
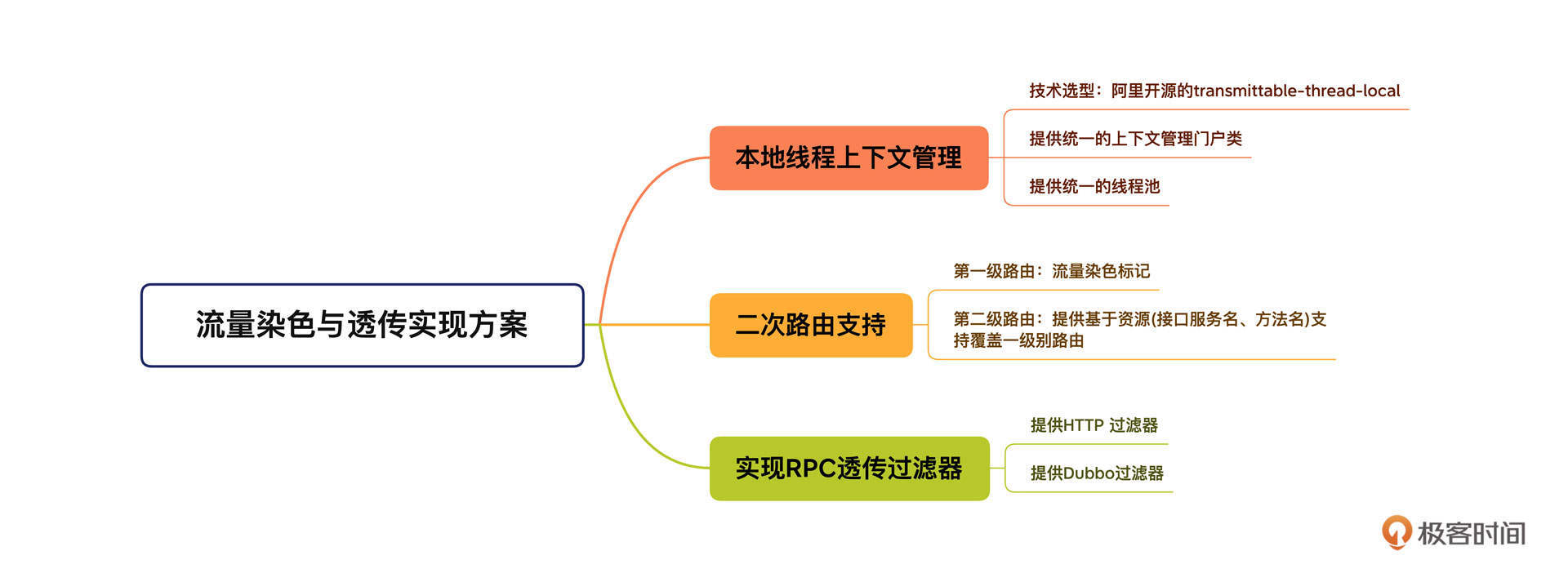
这个机制主要包含三部分,本地线程上下文管理、二次路由支持,还有实现RPC透传过滤器。先看第一部分,本地线程上下文管理。
由于流量染色标记需要在整个调用链中传播,在进行数据存储或查询时,都需要根据该标记来路由。所以,为了不侵入代码,把流量染色标记存储在本地线程上下文中是最合适的。
说起本地线程变量,我相信你首先想到的就是JDK默认提供的ThreadLocal,它可以存储整个调用链中都需要访问的数据,而且它的线程是安全的。
但ThreadLocal在多线程环境中并不友好,举个例子,在执行线程A的过程中,要创建另外一个线程B进行并发调用时,存储在线程A中的本地环境变量并不会传递到线程B,这会导致染色标记丢失,带来严重的数据污染问题:
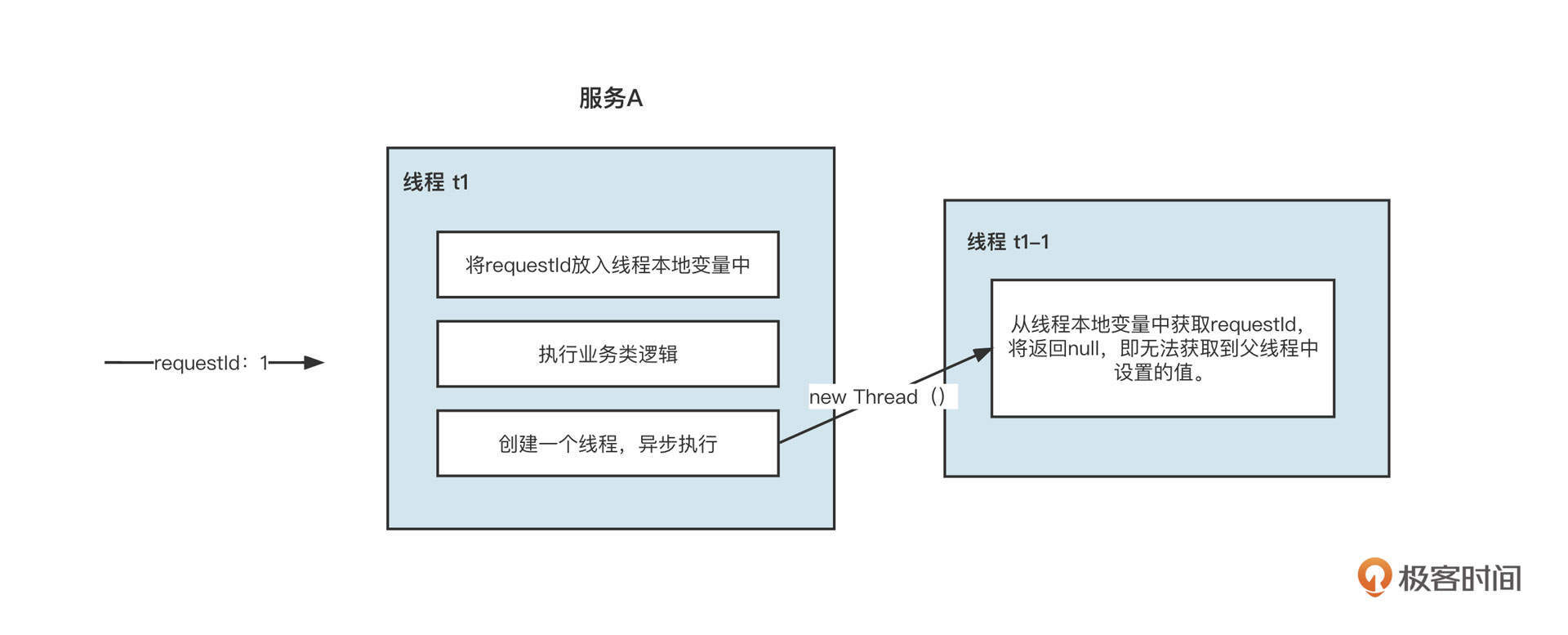
为了解决线程本地变量在线程之间传递的问题,阿里巴巴开源了transmittable-thread-local类库,它支持线程本地变量在线程之间、线程池之间进行传递,可以确保多线程环境下本地变量不丢失。
关于本地线程变量的详细调研情况、示例代码,你可以参考我的另一篇文章《线程本地上下文调研实践》。
流量染色与透传机制的第二部分是两次路由支持,它又细分为两级。
第一级路由主要是根据本地线程变量中是否存储了压测标记而进行的路由选择。但在全链路压测的一些场景中,某些服务(特别是像查询基础数据、地址解析这类基础服务)不需要走测试流量。而且测试流量也可以、并且也应该走生产流量,这样可以节省一大笔资源,这就说到了第二级路由。它指的是除了根据压测标记进行路由选择外,我们还需要提供另外一层的路由,即根据配置进行的路由选择,第二级路由的设计图如下:
流量染色标记存储到本地线程变量之后,第三步就是要对流量进行透传了。目前,RPC调用通常指的是HTTP请求与Dubbo远程调用。
我们来看一个远程RPC的服务调用。
我们要分别针对HTTP、Dubbo实现请求标记的透传。
先来说HTTP。HTTP中提供了Web过滤器机制,它允许我们在真正执行Controller层代码之前先执行过滤器。所以我们可以单独定义一个过滤器,从请求中将压测标记存储到本地线程变量中。然后,请求在真正执行业务代码时,就可以非常方便地从本地线程上下文获取染色标记了。示例代码如下:
1 | public class PtWebFilter implements Filter { |
这里,代码通过解析HTTP的Header,提取出流量染色标记,并将其存储到本地线程上下文中管理。
那怎样发起HTTP请求,将流量染色标记传递到下一个应用呢?
我们项目中是使用HttpClient类库实现的HTTP调用。HttpClient提供了拦截器机制,允许我们在发起HTTP请求之前,为HTTP请求设置对应的HTTP Header,具体的示范代码如下:
1 | /** |
在这里还有一个设计非常重要,那就是服务白名单机制。它的意思是,如果调用一个远程RPC服务,而当前流量是测试请求,那么只有白名单中配置的服务才可以发起调用。这主要是为了避免被调用方的服务如果没有接入全链路压测,会不具备流量识别功能,容易将测试请求当成正式请求处理,造成数据污染。
学完HTTP的流量透传机制,你可以结合我们讲过的Dubbo相关知识思考一下,在Dubbo中怎么实现流量透传功能呢?
没错,Dubbo同样提供了Filter机制,在发起或接受请求之前,都可以定义Filter来实现同样的功能。
消费者在调用一个RPC服务之前,需要将本地线程变量中的流量染色标记通过网络传输到服务端,具体的做法就是将标记放到RpcContext中:
1 | @Activate(group = {Constants.CONSUMER}, order = -2000) |
同样,在服务端真正开始处理业务逻辑之前,需要先从RpcContext中获取流量染色标记,将其放入本地线程变量中:
1 | @Activate(group = {Constants.PROVIDER}, order = -2000) |
数据隔离机制
了解了流量染色和透传机制,接下来我们重点看看各主流中间件的数据存储隔离机制,它是全链路压测的核心基石。
目前常用的数据存储中间件包括:关系型数据库(MySQL/Oracle)、Redis、MQ、Elasticsearch、HBase。
那压测数据和正式请求数据要采用哪种存储方式来避免数据访问混淆呢?这也是数据隔离要重点解决的问题。针对各种存储类中间件,业界已经给出了存储隔离的最佳实践,我总结了一下,画了下面这张思维导图:
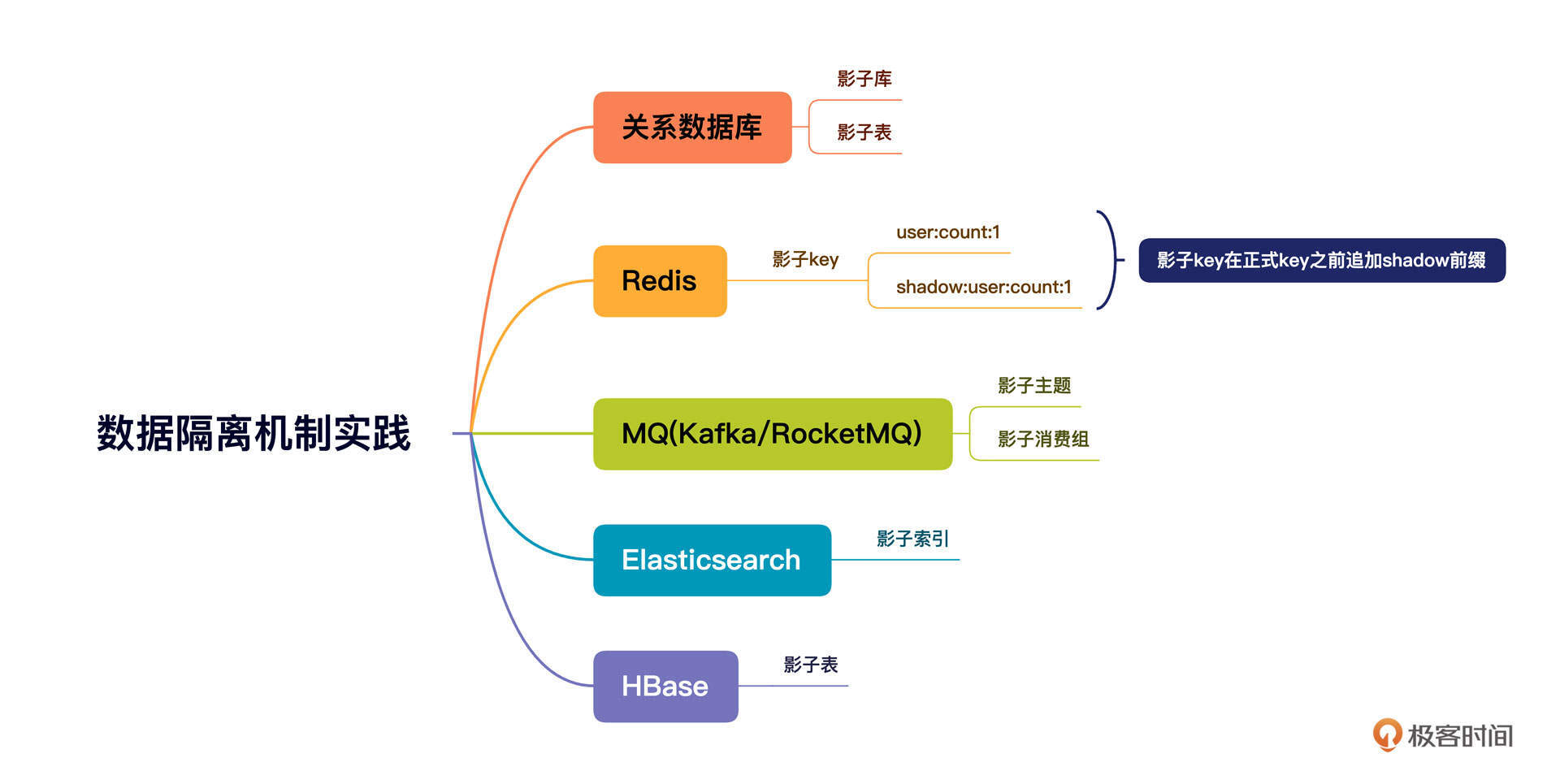
接下来,我们就挑选最具代表性,也是我们这个专栏重点介绍过的数据库、MQ这两个中间件来介绍一下具体的实现细节。其他的中间件也可以基于这种思路来实现。你可以根据不同中间件提供的客户端API,对数据请求进行拦截,并根据本地环境变量的值进行路由选择,确保正式请求访问正式资源,测试请求访问影子资源。
数据库层面,通常有两种数据隔离机制,一种是影子库,另外一种是影子表。
我们借着数据库这种场景简单来介绍一下什么是影子库和影子表。你可以先看看下面这张示意图:
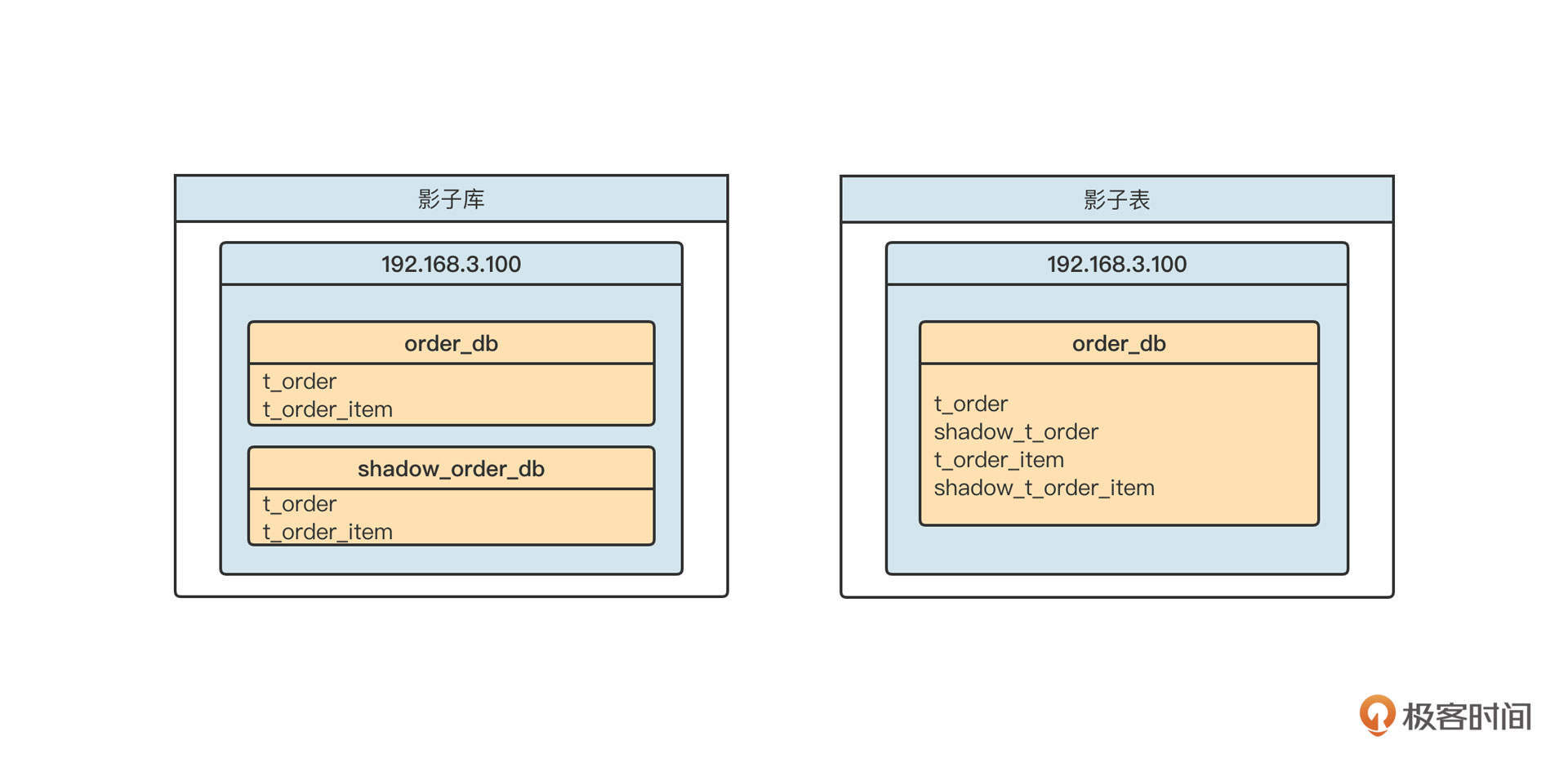
影子表是在同一个Schema下为每一个表再创建一个相同结构的表,测试请求访问的是shadow开头的表。
影子表的实现非常复杂,一般团队难以驾驭,因为它涉及到复杂的SQL语句解析和改写。例如,创建订单,最终写入数据库的SQL语句是下面的样子:
1 | insert into t_order(id,order_no,...) values (); |
如果判断出是测试请求,我们首先需要解析这条SQL语句中的所有表,并将表转化为影子表,再执行这条SQL语句。要是碰上连接、多层嵌套SQL,要正确解析语句会非常困难。
受到团队规模的限制,加上我对SQL解析还没有十足的把握,所以我们在实践全链路压测时并没有选择影子表,而是使用了影子库。
无论是MySQL,还是像Oracle这种关系型数据库,基本都是基于JDBC的数据源进行数据读写的。在JDBC中,每一个Schema对应一个数据源(Datasource),根据影子库的设计理念,我们通常需要创建两个数据源对象。如下图所示:
建好两个数据源之后,我们只需要根据当前线程本地环境中存储的流量标记,在需要执行SQL语句时选择相对应的数据源,创建对应的数据库连接,再执行SQL,就可以实现数据的隔离机制了。
那如何优雅地进行路由选择呢?
我们可以借助Spring-JDBC提供的AbstractRoutingDataSource路由选择机制。它的核心机制如下图所示:
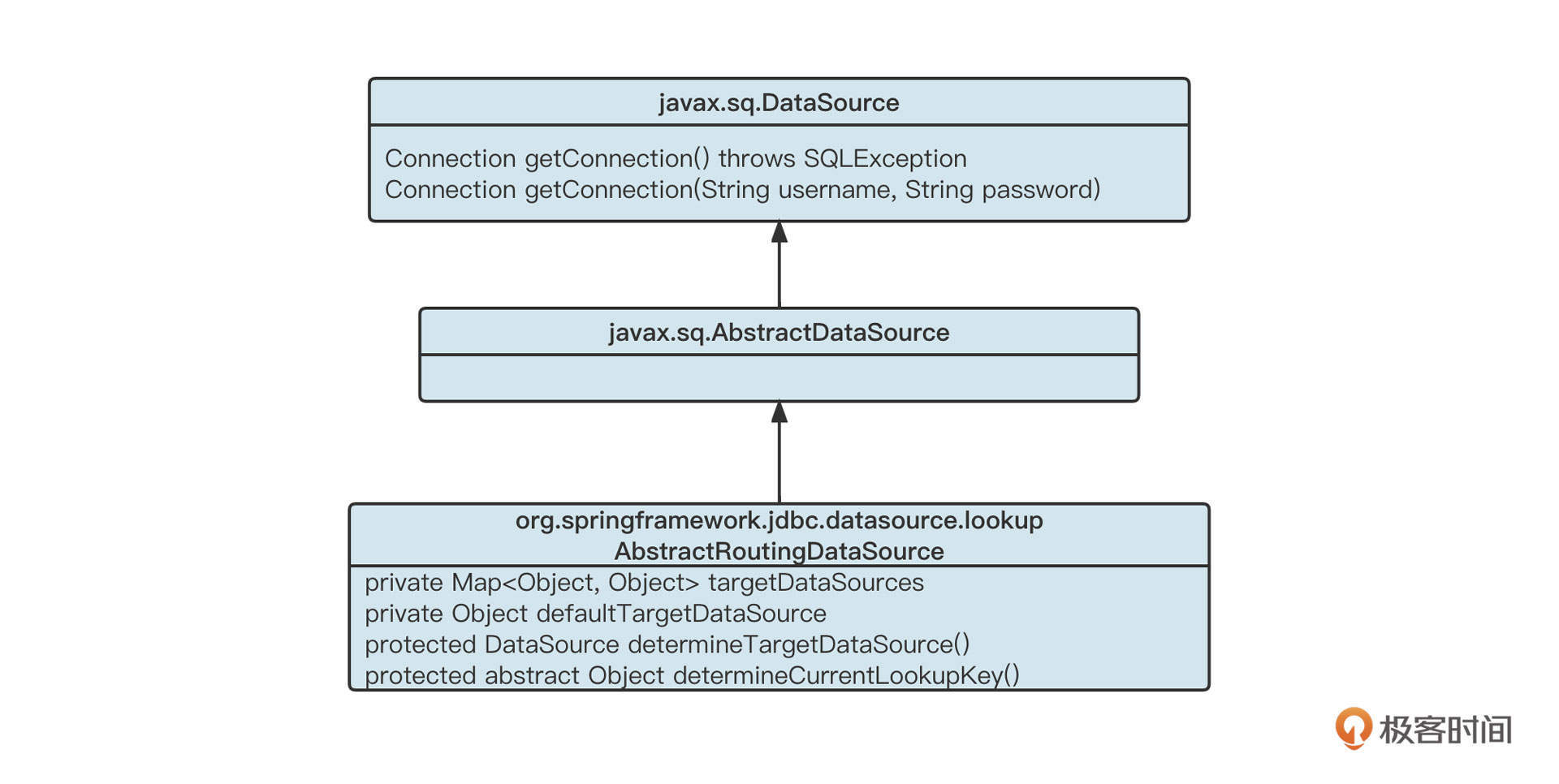
首先,我们会为项目中每一个正式数据源创建一个影子数据源。例如使用HikariCPDatasource,然后为它创建一个对应的影子数据源,把两个数据源存入到targetDataSources集合中,然后再根据本地线程上下文中的流量标记,选择对应的数据源。实现代码如下:
1 | private static final String ORIGIN_KEY = "originKey"; |
通过这种方法,我们就轻松实现了数据源的选择,完成了根据流量标记选择对应数据源的任务。
不过,这种方式会带来一个问题。那就是,在压测过程中,每一个正式的数据源会再对应生成一个相同配置的影子消费组,这样数据库服务端的连接数会翻倍。
我们再来看看MQ方面如何进行数据隔离。
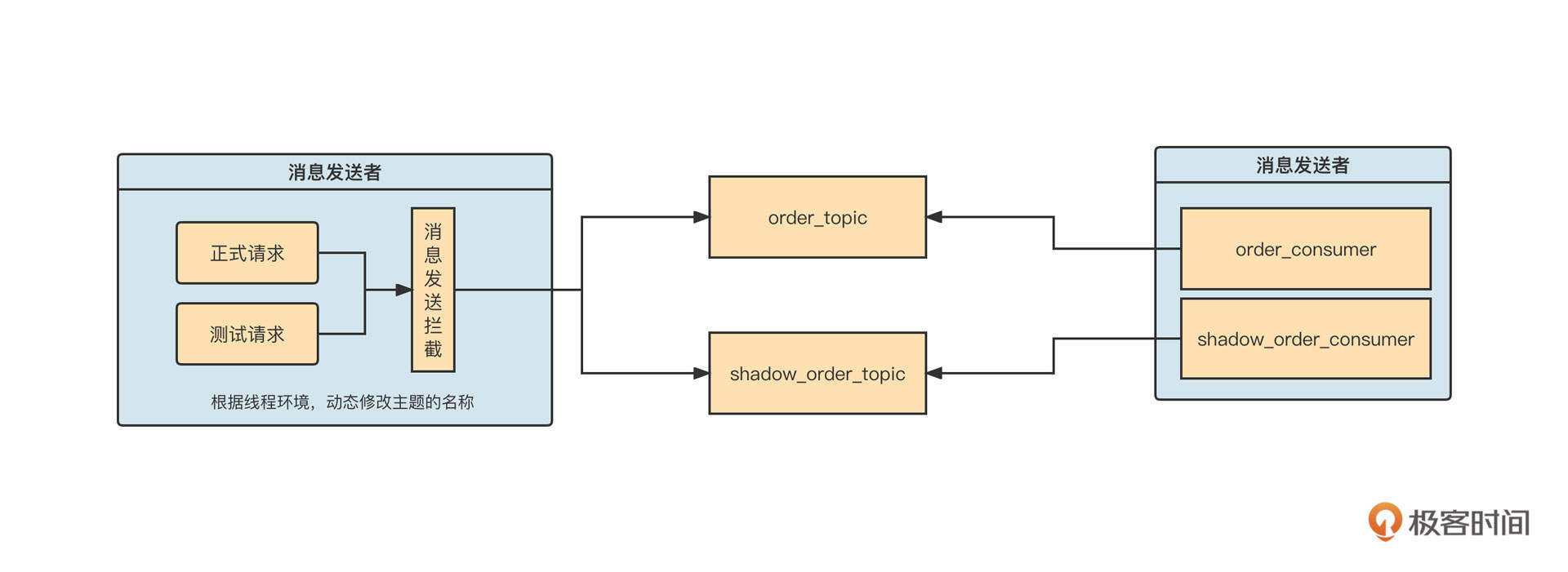
在消息发送端,我们通常通过对原生SDK进行封装,通过AOP等方法拦截消息发送API,根据当前流量标记来判断是否需要改写主题名称。如果当前流量标记为压测流量,我们要把主题的名称修改为压测主题,把消息发送到同一消息集群的不同主题中。
当消费端启动时,要为每一个正式消费组再额外创建一个影子消费组,订阅的主题为影子主题。这样,我们就在消费端实现了线程级别的隔离。影子消费组的线程本地变量默认为测试流量,然后沿着消息的消费传递影子标记。
在全链路压测这个场景,为了不影响没有接入全链路压测的应用,使用影子主题与消费组基本是唯一的解法。因为没有接入全链路的消费组是无法感知到影子主题中的消息的,这就把边界控制在了合理的范围中:
当上游消息发送接入全链路压测时,如果流量是测试请求,消息会发送到影子主题。但是下游如果有应用暂时未接入全链路压测,应用就不会自动创建影子消费组,也不会去订阅影子主题,避免了多余的影响。
总结
好了,我们这节课就讲到这里了。
我们这节课开篇就解释了全链路压测的概念。我还结合一张生产环境数据流向图,引出了压测前、压测运行时、压测结束三个阶段的功能需求,重点介绍了流量染色与透传机制和主流中间件的数据隔离机制。
在流量染色部分,我们重点提到了使用线程本地变量存储染色标记的方法,并采用阿里巴巴开源的transmittable-thread-local类库,在多线程环境下安全地传递了染色标记。然后,我们又分别针对HTTP请求与Dubbo RPC请求,讲解了让请求标记在进程之间传递的方法。
最后,我们还学习了主流中间件的数据隔离机制,了解了数据库影子库、消息中间件的影子主题、影子消费组的具体落地思路。
课后题
学完这节课,给你留一道思考题。
全链路压测中,一个最容易出现的问题就是流量标记的丢失。你知道为什么JDK自带的ThreadLocal无法在多线程环境中传递吗?那阿里开源的transmittable-thread-local又是怎么支持多线程环境下本地线程变量的自动传递的呢?
欢迎你在留言区与我交流讨论,我们下节课再见!
加餐 | 中间件底层的通用设计理念
作者: 丁威

你好,我是丁威。
我们都知道,开发中间件的技术含量是比较高的,如果能参加中间件的开发,可以说是朝“技术大神”迈了一大步。
但是,中间件开发并不是遥不可及的。通过对各主流中间件的研究,我发现了中间件底层的一些通用设计理念,它们分别是数据结构、多线程编程(并发编程)、网络编程(NIO、Netty)、内存管理、文件编程和相关领域的知识。
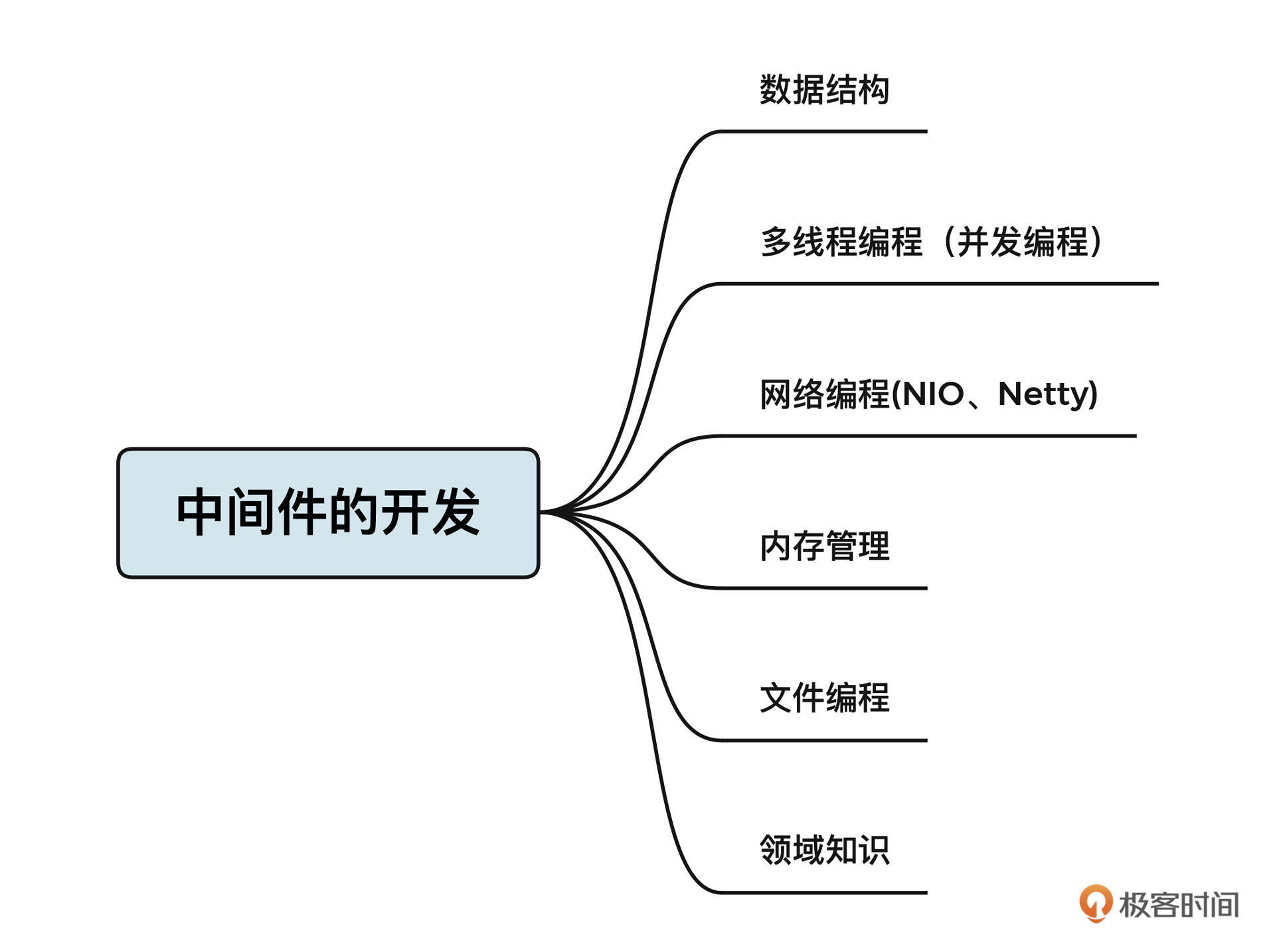
其中,数据结构、多线程编程和网络编程是中间件的必备基础,在前面的课程中,我也做了详细介绍。这节课,我会重点介绍内存管理和文件编程相关的知识,带你了解开发中间件的核心要点。
你可能会问,六大技能,那最后一个技能是什么呢?最后这个技能就是相关领域的知识,它和中间件的类型有很大关系,和你需要解决的问题密切相连。
举个例子,数据库中间件的出现就是为了解决分库分表、读写分离等与数据库相关的问题。那如果要开发一款数据库中间件,你就必须对数据库有一个较为深入且体系化的理解。想要开发出一款MyCat这样基于代理模式的数据库,就必须了解MySQL的通信协议。我们甚至可以将相关领域的知识类比为我们要开发的业务系统的功能需求,这个是非常重要的。不过这部分我没有办法展开细讲,需要你自己去慢慢积累。我们还是说回内存管理。
内存管理
Java并不像C语言或者其他语言一样需要自己管理内存,因为JVM内置了内存管理机制(垃圾回收机制),所以在编写业务代码的过程中,我们只需要创建对象,而不需要关注对象在什么时候被回收。
垃圾回收机制(GC)对于业务开发来说无疑是非常方便的,但对于中间件开发来说就有点力不从心了。因为垃圾回收器执行回收时会出现停顿现象(Stop-World),不同垃圾回收器只是停顿的时间长短不同。不可控的垃圾回收对中间件的性能、可用性带来了比较大的影响。为了应对这一问题,通常的做法是,从操作系统申请一块内存,由中间件本身来管理这块内存的使用。
我们用Netty的内存管理机制来进一步说明一下。之前在讲解NIO读事件处理流程时我们说,IO线程需要将网卡中读取到的字节存储到累积缓存区。这里就要注意了,累积缓存区是需要使用内存的。我们用一张图来说明内存管理的一些需求:
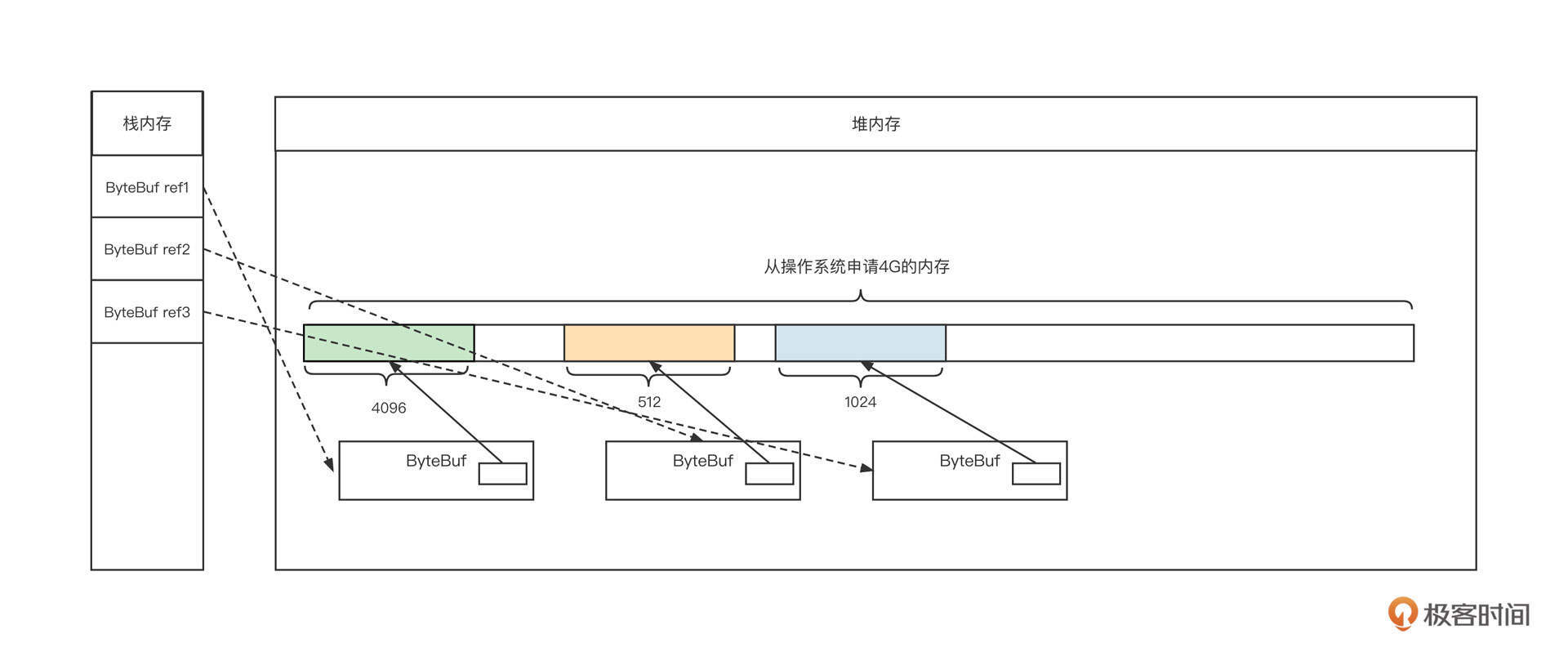
在这张图中,我们从JVM内存模型视角创建了3个累积缓存区,然后,我们需要在栈内存创建3个指针,并分别在堆空间中创建3个ByteBuf对象。每个ByteBuf对象内部都有一块连续内存,用于存储从网卡中接收到的内容。
那Netty框架会接管哪部分内存呢?
我们来简单思考一下,如果Netty直接使用Java的垃圾回收机制,那ByteBuf对象还有内部持有的内存(byte[])就会频繁地创建与销毁,而且这些对象都是朝生暮死的,这会导致频繁的GC,高性能、高并发基本就成为奢望了。
为了有效降低垃圾回收发生的频率,减少需要回收的对象,Netty采用了下面两个解决手段。
首先,Netty会单独管理ByteBuf内部持有的内存,在启动进程时就向操作系统申请指定大小的内存。这样,这部分内存会被独占,并且在JVM存活期间一直可达。垃圾回收器不需要关注这部分内存的回收,由Netty负责管理内存的释放和分配。
其次,对ByteBuf对象本身采用对象池技术,避免频繁创建与销毁ByteBuf对象本身。
提到内存管理,你不妨回忆一下自己最开始接触到的操作系统是什么样子。 目前流行的操作系统的内存管理基本都是段页式思想,笼统地说就是系统会对内存进行分段管理,每一段又包含多个页。
我们这节课主要通过学习Netty的内存管理机制来学习内存编程的通用设计理念。
在Netty中,内存的管理采取区(Area)-块(chunk)-页(page)的管理方式。每个区包含一定数量的块,而块又由多个页构成。Netty的内存结构如下图所示:
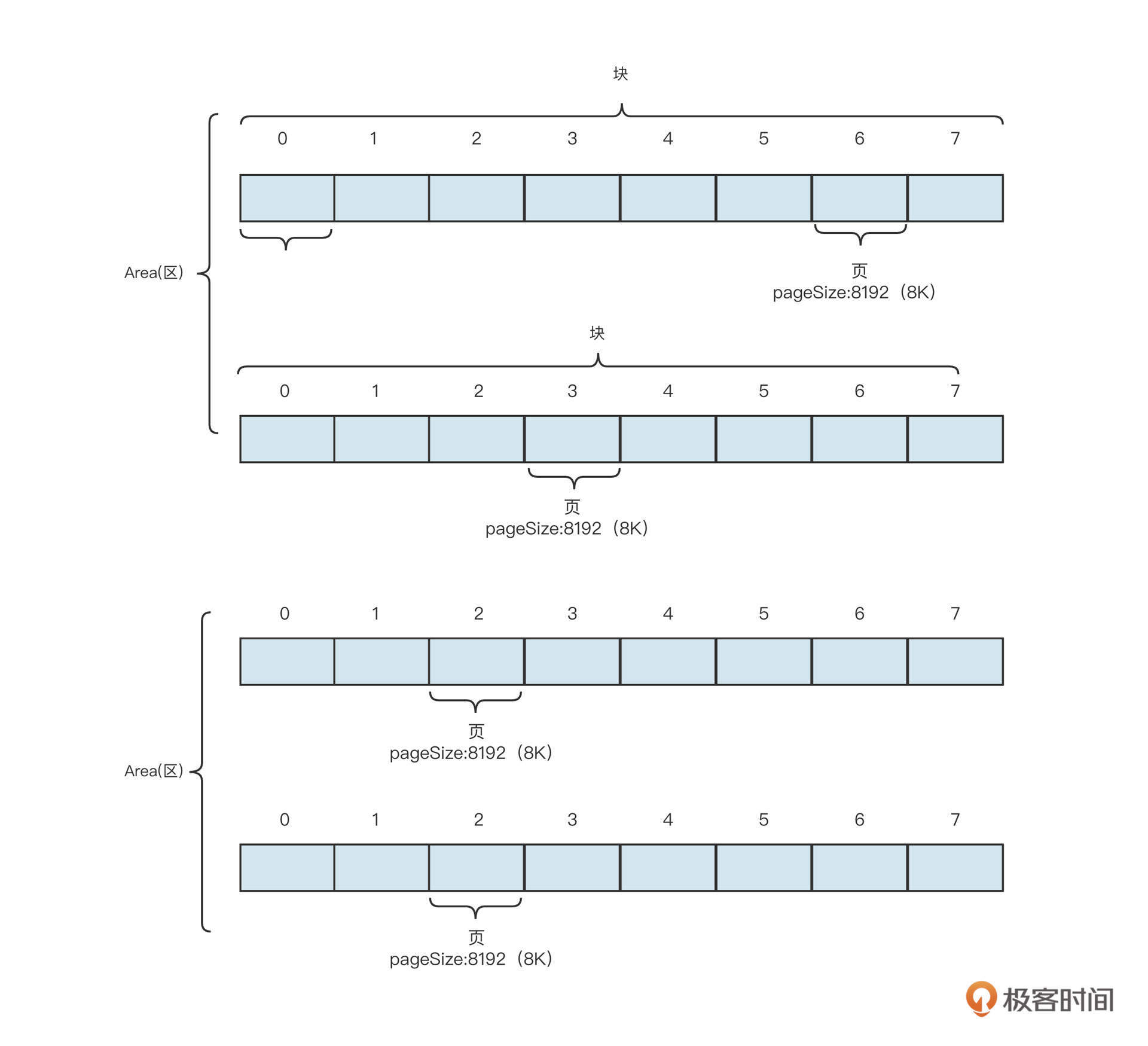
之所以划分成区、块,主要是为了提高系统的并发能力。这里简单解释一下,因为内存是所有线程共享的,线程从块中申请内存或释放内存时必须加锁。否则容易导致一个块的内存同时分配给多个线程,造成数据错乱,程序异常。
也就是说,恰当地管理块中的内存是内存管理的重中之重。在上面这张示意图中,一个块包含了8页,那怎么对这些页进行管理,怎么表示这些页是已分配还是未分配,怎么根据分配情况快速找到合适的连续内存呢?
Netty的解决之道是将这些页映射到一颗完全二叉树上。它的映射方式大致是下图的样子。
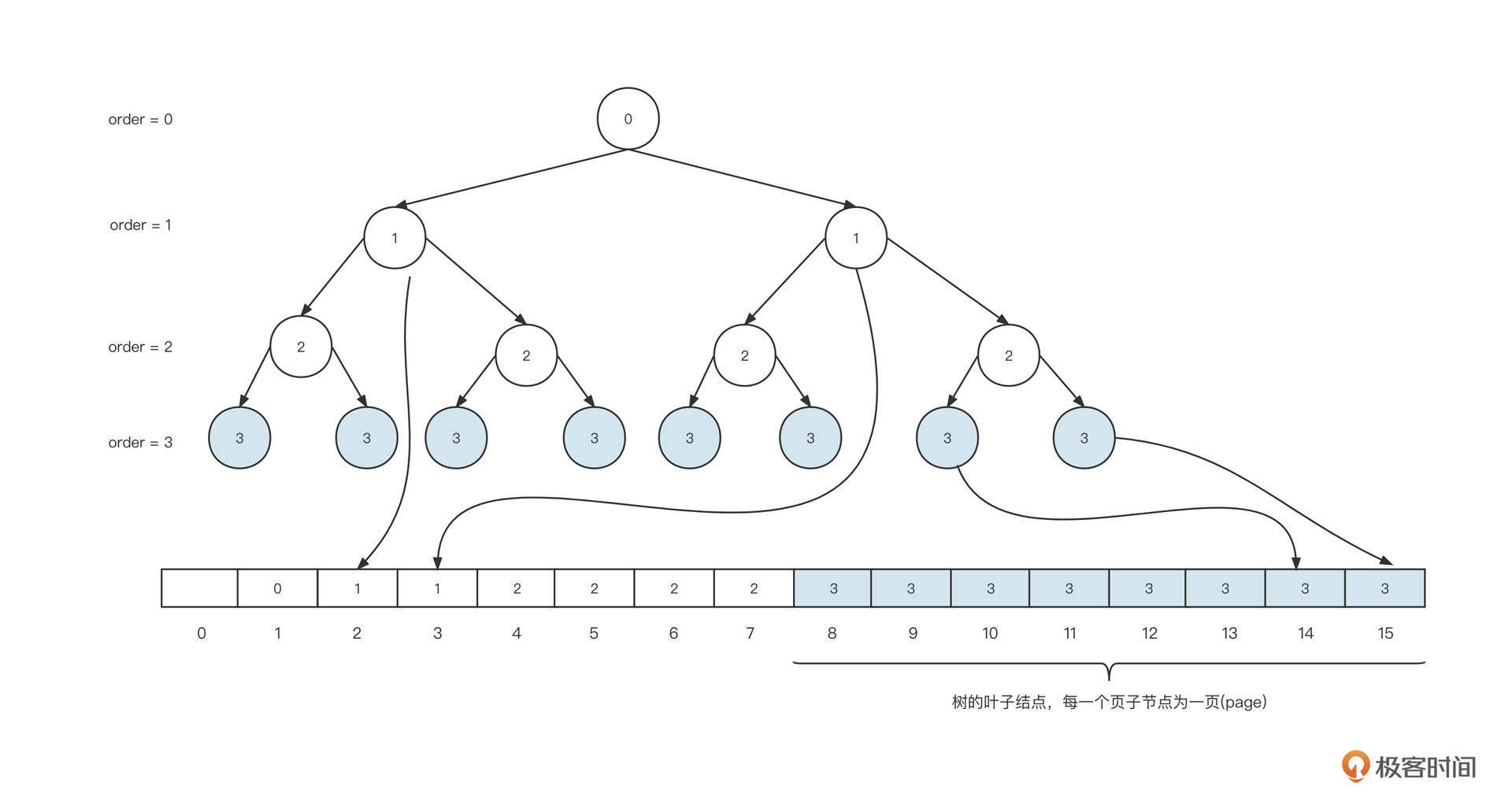
在这里,一个块的内存是8页,也就是2的3次幂,我们把3称作maxOrder,maxOrder的值越大,一个块中包含的页就越多,管理的内存就越多。
Netty为了能够高效管理maxOrder的页,会将其映射到一颗完全二叉树上,每一个叶子节点代表一页,二叉树最后会完全存储在数组中。
具体的映射方法是:创建一个数组,长度为叶子节点的2倍,然后将完成二叉树按照每一层从左到右的顺序依次存储在数组中。注意,第一个节点要空出来,这样做的好处是根据数组下标能很方便地计算出父节点和两个子节点的下标。
具体的计算方法是:
- 如果节点的下标为n,则父节点的下标 n>>1,即 n/2。
- 如果父节点的下标为n,则其左节点下标 n << 1,即2n,右节点下标 n << 1 + 1,即2n+1。
完全二叉树映射到数组中,每一个元素存储的内容为该节点在二叉树中的深度,也就是上图中的order信息。为了统一深度的定义,我们默认根节点的深度为0(order=0)。也就是说,根节点存储在array[1] = 0中,根节点的两个子节点分别存在array[2]和array[3]中,并且它们的值都为1,其他节点以此类推。
这种存储方式能够清晰地让我们看到这个节点能一次分配的最大内存。如果一个节点在数组中存储的值为n,那么从该节点出发,能找到的叶子节点的个数为2的 (maxOrder-n)的幂,而每一个叶子节点表示一页,所以能分配到的最大内存是 2 的 (maxOrder-n)的幂 * 每页大小(pageSize)。
基于这个存储结构,Netty就可以方便地进行内存分配了。我们来看下具体的步骤。
首先,我们需要申请8K的内容,从根节点出发,找到第一个可分配的节点,整个查找过程如下图。
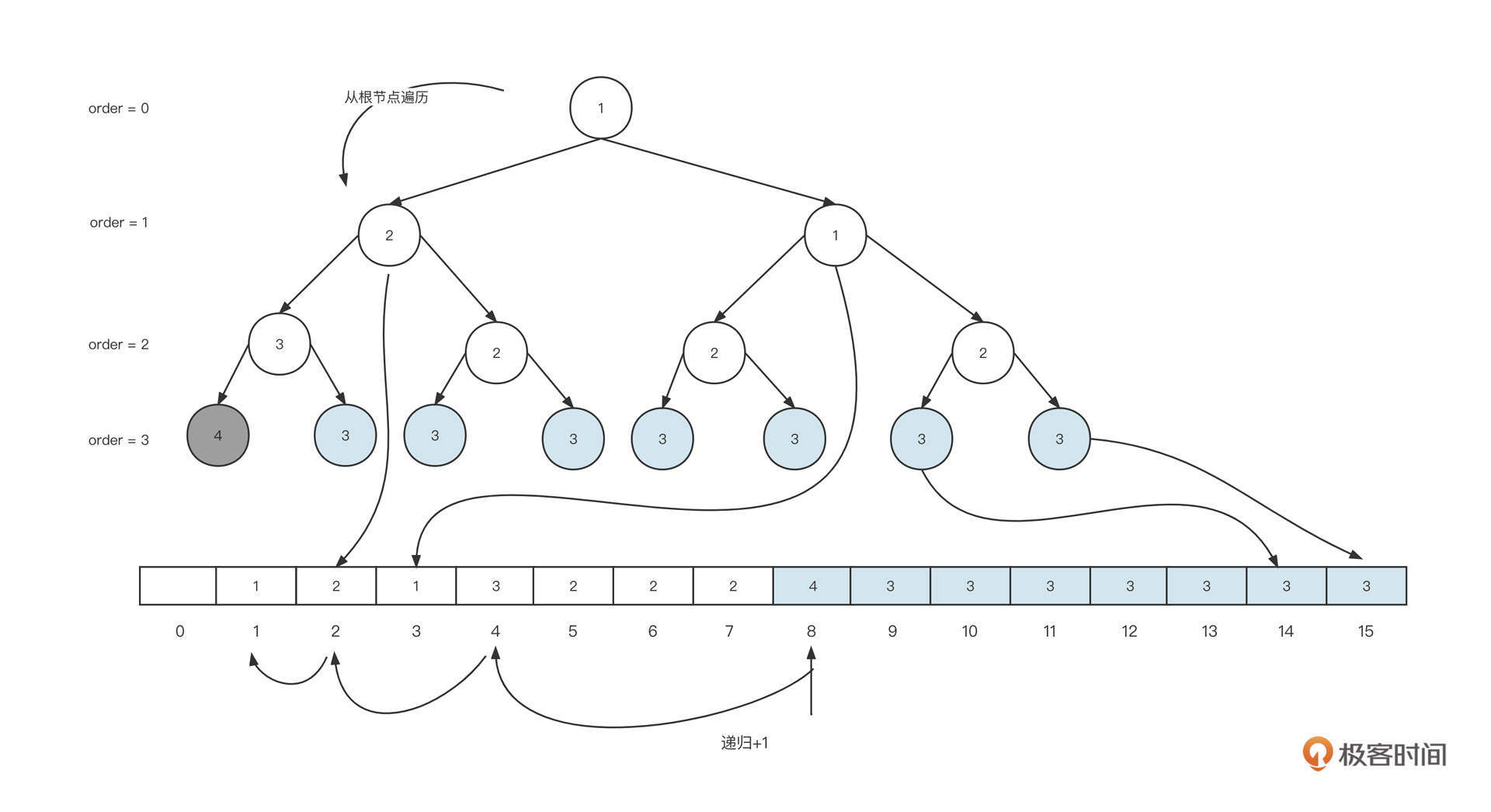
从根节点开始,优先遍历左子树,然后再遍历右子树,找到满足当前分配需求的最小节点,即从根节点,一直可以遍历到左边第一个叶子节点,将对应数组中的值array[8] 更新为 array[8] + 1 。在上面这个例子中,这个值从3变为了4。一旦存储的值大于maxOrder,表示该节点已被占用,无法继续分配内存。
与此同时,我们还要从当前节点向上遍历二叉树,依次通过n >> 1找到当前节点的父节点的下标, 将array[4]、array[2]、array[1]中存储的值依次加一。
这样,我们就完成了一次内存申请,在此基础上,如果我们需要再申请16K也就是2页的内存大小。查找过程如下图所示:
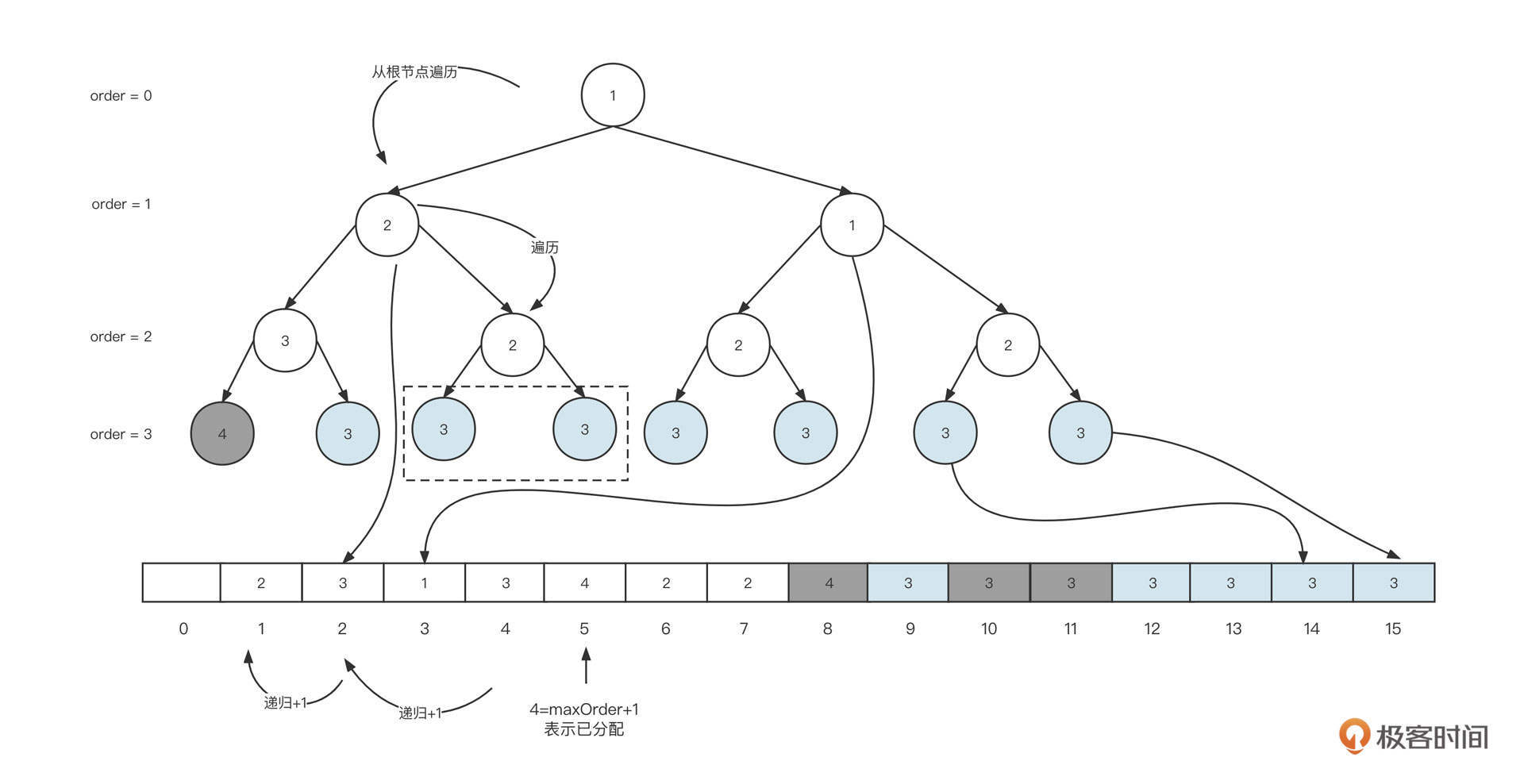
这里,我们还是从根节点开始遍历,当遍历到第一个左节点时,其存储的值为2,并且它的左节点存储3,右节点为2,因为这一次我们需要申请2页内存,左节点存储的值为3,能分配到的内存为2的(maxOrder[3]-order[3]),最终得出为1,即左节点只能分配1页的大小,故最终会定位它到右节点。从而将其右节点设置为(maxOrder+1),表示已分配,然后依次遍历父节点,其值加1。如果想要申请更多内存的话,重复上述步骤即可。
从这里也可以看出,内存的申请流程,基本都是从根节点开始遍历,先遍历左子树、然后遍历右子树,找到第一个大于指定内存最小内存的节点,把它设置为已分配,然后依次找到父节点并将相应在数组中的值减1。
内存的释放和内存的申请刚好相反。我们要从释放节点向上遍历,给数组中存储的值减1,因为这部分内容比较简单,这里我们就不展开讨论了。
文件编程
介绍完内存管理,我们再来看看如何基于文件进行高效编程。
之所以要讲文件编程,是因为文件可以比内存提供更加廉价、更大容量的存储。而且内存存储的时效性比较短,电脑关机后数据就会丢失。不过,虽然我说了文件存储这么多优点,但我还是得客观一点,毕竟它还是有缺点的。比方说,在性能上文件存储就远低于内存。
我们来看看怎么基于文件存储写出高性能的程序。
首先,我们需要为存储的内容设计存储协议。以消息中间件为例,RokcetMQ中消息的存储格式如下图所示:

从这张图里,我们可以看到文件存储设计的三个要点,也就是长度字段、魔数和CRC校验码。
长度字段
指的是存储一条消息的长度。这个字段通常使用一个定长字段来存储。比方说,一个字段有4个字节,那一条消息的最大长度为2的32次幂。有了长度字段,就能标识一条消息总共包含多少个字节,用len表示,然后我们在查找消息时只需要从消息的开始位置连续读取len个字节就可以提取一条完整独立的消息。
魔数
魔数不是强制的设计,设计它的目的是希望能够快速判断我们是否需要这些文件,通常情况下,魔数会取一个不太常用的值。
CRC校验码
它是一种循环冗余校验码,用于校验数据的正确性。消息存储到磁盘之前,对消息的主体内容计算CRC,然后存储到文件中。当从磁盘读取一条消息时,可以再次对读取的内容计算一次CRC,如果两次计算的结果不一样,说明数据已被破坏。
学到这里我猜你已经发现了,这个文件存储协议的设计理念和网络编程领域的通信协议设计有着异曲同工之妙。对头,这个文件存储协议的设计基本也遵循 Header+Body 的结构,并且Header长度固定,并且包含长度字段。
不过,文件存储协议和通信协议有一个非常关键的区别,那就是:文件存储协议必须设计校验和字段,但通信协议不需要。数据存储在这是因为磁盘文件中,数据并不可靠,发生错误的概率比较大。而网络通讯协议在网络传输底层有相应的应对机制,能够及时发现错误并重发,从而确保数据传输的正确性。
好了,说回文件存储。解决了存储格式的问题,接下来就要考虑怎么从文件中检索消息了。
就像关系型数据库会为每一条数据引入一个 ID 字段一样,基于文件编程的模型也会为每条数据引入一个身份标志:起始偏移量,也就是数据存储在文件的起始位置。
起始偏移量的设计如下图所示:
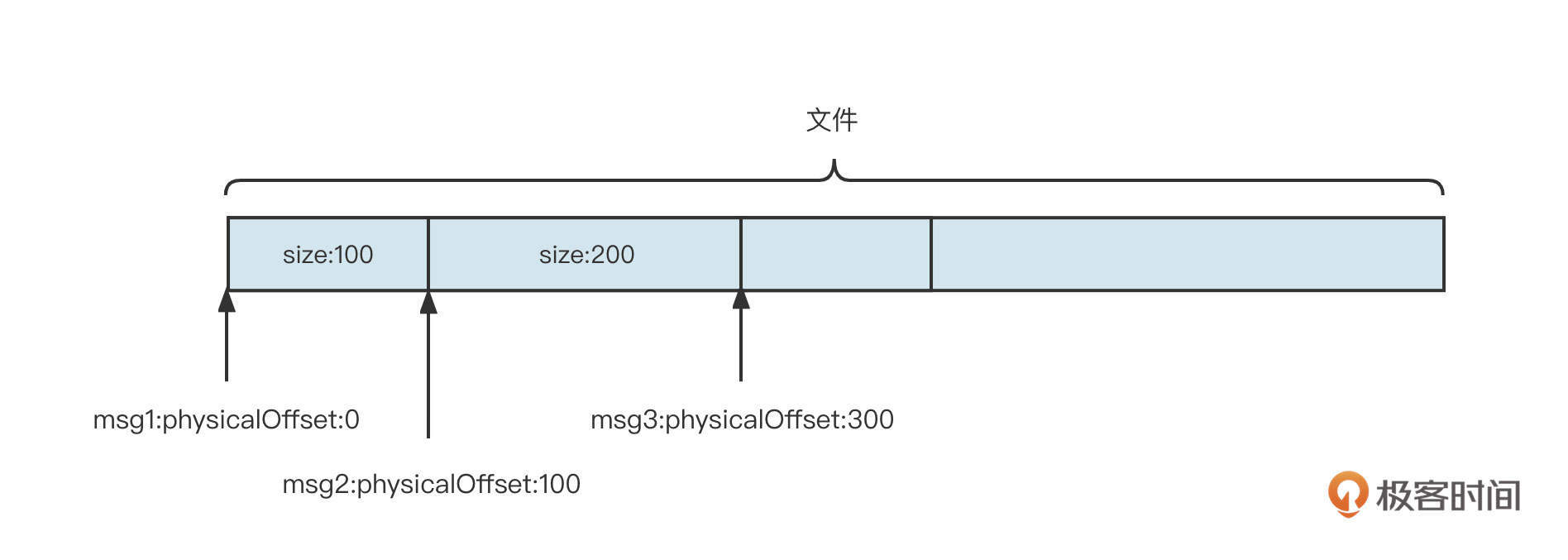
通过起始偏移量 + SIZE,要从文件中提取一条完整的消息就轻而易举了。
我们在查询数据时,往往需要从多维度展开。以数据库查询为例,一个order表包含主键ID、订单编号、创建时间等字段,我们不仅可以通过主键ID进行查询,还可以通过订单编号进行检索。
但是,如果订单表中的数据不断增加,根据订单编号查询订单数据变得越来越慢,这个时候我们该怎么优化呢?
答案是,为订单编号建立索引。
所谓的索引,就是将需要检索的内容(订单编号)与主键ID进行关联,在检索时,我们是先找到主键ID,然后根据主键ID就能快速定位到内容,从而提升性能了。它的原理你可以参考一下下面这张图片。
数据库作为一个基于文件编程的系统,就可以通过建立索引来提升检索性能。但由于是用C语言编程的,深入探讨比较困难。这时候,RocketMQ的存储就给我们演示了索引的设计方法。
在RocketMQ中,所有的原始消息会按照它们到达RocketMQ服务器的顺序存储到Commitlog文件中,但消息消费时需要根据主题进行消费。也就是说,我们需要按照主题查找消息。上面我们也说过了,包括RocketMQ在内,基于文件的编程模型只有根据起始偏移量才能快速找到消息,为了提升根据主题检索消息的效率,需要为主题建立索引。
RocketMQ具体的做法是,为每一个主题、队列创建不同的文件夹,例如/topic/queue。然后,在该文件夹下再创建多个索引文件,每一个索引文件中存储数据的格式为:8字节的起始偏移量、4字节的数据长度、8字节的tag哈希值。如下图所示:
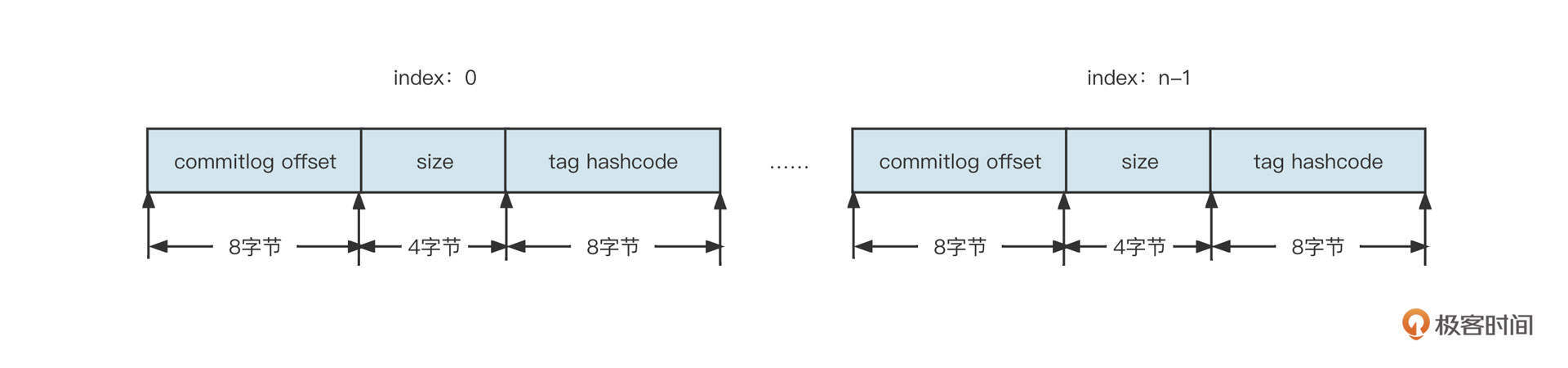
结合RocketMQ索引文件的构建规则,我们可以得出下面两个设计索引的关键点。
- 为了通过索引项快速查询到数据,索引项中包含了起始偏移量,并且为了支持快速根据tag进行过滤,索引项中也包含了tag的信息。
- 为了保证索引项的检索效率,索引项本身的查找机制必须非常高效。RocketMQ是根据主题、队列、消费进度三者快速找到消息的,所以索引项的设计借鉴了数组思想,将主题索引项设计为固定长度。
索引机制解决了文件层面的检索问题,但索引最后也是存储在文件中,索引自身的性能是没法提升的。为了提升访问文件的性能,我们还会使用另外一种优化手段:内存映射机制。
什么是内存映射机制呢?一言以蔽之,就是将文件直接映射到内存中,将直接操作文件的方式用操作内存的方式进行替换,从而提升性能。
在写入数据时,我们不是直接调用文件API,而是将数据先写入到内存,然后再根据不同的策略,将数据从内存中再刷写到文件。
在Java中,我们可以通过下面这段代码启动内存映射机制:
1 | FileChannel fileChannel = new RandomAccessFile(this.file, "rw").getChannel(); |
在 Linux 操作系统中,MappedByteBuffer 基本可以看成是页缓存(PageCache)。Linux 操作系统的内存使用策略是,最大可能地利用机器的物理内存并常驻在内存中,这就是所谓的页缓存。
只有当操作系统的内存不够时,我们才会采用缓存置换算法。例如,LRU会将不常用的页缓存回收,也就是说操作系统会自动管理这部分内存,无须使用者关心。如果从页缓存查询数据时未命中,会产生缺页中断,这时候操作系统自动将文件中的内容加载到页缓存。
将文件映射到内存中,数据写入时只是先将数据存储到内存,但这部分数据还没有真正写入到磁盘,需要采取一定的策略将内存中的数据同步刷写到磁盘中。我们知道,机器重启后会造成数据丢失,在平衡性能和数据可靠性时,通常会衍生出下面两种不同的策略。
- 同步刷盘。数据写入到内存后,需要立即将内存数据写入到磁盘,然后才向客户端返回“写入成功”。这会牺牲性能,但可以保证数据不丢失。
- 异步刷盘。数据写入到内存后,会立即向客户端返回“写入成功”,然后异步将内存中的数据刷写到磁盘。
“刷盘”这个名词是不是听起来很高大上,其实它并不是一个什么神秘高深的词语。所谓刷盘,就是将内存中的数据同步到磁盘,在代码层面其实是调用了 FileChannel 或 MappedBytebuffer 的 force 方法。
RocketMQ中实现MappedFile的刷盘的代码如下:
1 | public int flush(final int flushLeastPages) { |
总之,无论是同步刷盘还是异步刷盘,最终都是调用文件存储设备的写入API。目前,文件的存储媒介还是以机械硬盘为主,机械硬盘在写入数据之前,需要先进行磁道寻址,如果写入磁盘的数据位置比较随机,那么寻址需要花费的时间也会相应增多,所以业界又引入了一种设计思想:文件顺序写机制。
文件顺序写的设计理念应用非常广泛,数据库领域的redo日志的底层就运用了顺序写机制。你可以先通过这张图理解一下它的运作机制。
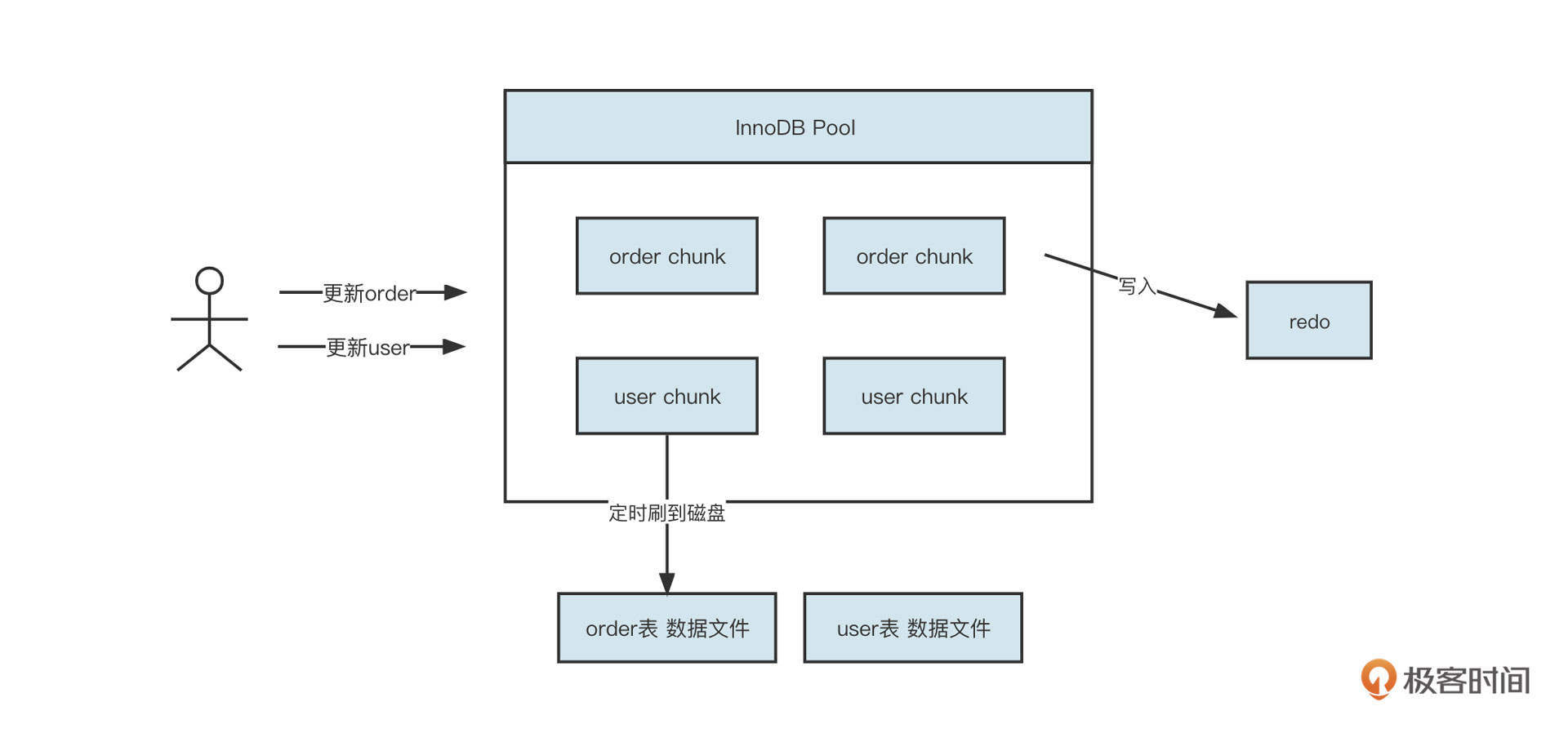
一个数据库中有很多表,每一张表都存储了很多数据,这些数据分布在磁盘不同的区域,而且用户在更新数据时也很分散。例如他们会时而更新订单表,时而更新用户表,那该怎么优化呢?
我们以MySQL为例。MySQL中的InnoDB引擎是首先维护一个内存池,同样使用内存映射机制将磁盘中的文件映射到内存,用户的更新操作会首先更新内存。但我们知道,对于关系数据库来说,数据不丢失是一个硬性需求,但如果为了确保这一点采用同步刷盘将数据写入到磁盘,又必然是一个随机写的过程,无法满足性能要求。
为此,InnoDB引入了一个redo文件。这样,数据写入到内存后,会先同步刷盘到redo文件,但写入redo文件是一个不断追加的过程,也就是说先顺序写入redo文件,然后再异步将内存中的数据刷写到各个表中。这样,就算MySQL宕机等原因导致内存中的数据丢失,还是可以通过回放redo文件将数据恢复回来。这就在保证数据库不丢失的情况下,提升了性能。
总结
这节课就讲到这里。刚才,我们从中间件开发的视角入手,简单介绍了中间件开发工程师必须具备的基础技能。我还重点介绍了内存管理、文件管理的一些编程技巧。
内存管理主要包括内存的分配与内存的回收,我们可以通过进程管理内存,从而减少垃圾回收的发生频率,提升系统运行稳定性。
文件编程领域首先要解决的就是数据以什么格式存储在文件中,然后再通过引入索引、内存映射、同步刷盘、异步刷盘、顺序写等手段优化文件访问的性能。
希望学完这节课,你能更深入地认识一些业务开发领域平时不怎么关注,甚至看起来有点高大上的功能。当然更重要的是,以此为起点,展开对中间件更深的探索。如果你有什么其他的疑问和发现,也欢迎随时跟我沟通。
课后题
最后,给你留一道思考题吧。
有人说,在Netty的内存分配机制中,数组中存储的值代表该节点当前拥有的剩余内存。你觉得这句话对吗,为什么?
欢迎在留言区写下你的想法。我们下节课再见。
开篇词|为什么中间件对分布式架构体系来说这么重要?
作者: 丁威
你好,我是丁威。
一名奋战在 IT 一线十多年的技术老兵,现任中通快递技术平台部资深架构师,也是 Apache RocketMQ 社区的首席布道师,《RocketMQ技术内幕》一书的作者。
不知道你有没有发现这样一个现状,深度实践分布式架构体系还得看大厂,他们所提供的高并发、大数据等应用场景更是众多研发工程师的练兵地,给出的薪资、待遇、发展潜力也远超小平台。但说句现实点的,绝大多数 Java 从业人员其实都在干着 CRUD 的工作,并没有机会去实践高并发。一边是大厂牛人岗位的稀缺,一边是研发工程师的晋升无门,怎么打破这个死循环,自开一扇窗呢?
结合我自己的经历,加上这些年我对研发工程师的职场发展的思考,我觉得中间件这个细分赛道或许可以奋力一搏。甚至可以说,学习它已经是进入大厂的必备条件了。
第一阶段:高效工作
对于刚开始接触系统架构的人来说,熟练掌握中间件是高效工作的前提。因为中间件是互联网分布式架构设计必不可少的部分,几乎每一个分布式系统都有一种乃至几种中间件在系统中发挥作用。
中间件的这种持续发展和系统的内部结构有关。可以结合你们公司的业务想一下,为了追求高并发、高性能、高可用性还有扩展性,是不是在对软件架构进行部署时,通常会采用分层架构思想,将系统架构分为接入层、基础层、服务层、数据存储层和运行环境,而每一层需要解决的问题各不相同。就像这样一个系统架构模型。
但单凭这个架构并不能解决所有问题。试想一下,如果一家公司每做一个项目都要自己去实现一套事务管理、一套定时任务调度框架,那么他们的业务交付效率一定会很低。这不但会给开发编码带来极大的技术挑战,同时系统也需要面临高并发、大流量的冲击。在这么多未知的挑战和不可控的因素当中,要想交付一套稳定的系统可以说是困难重重。
好在随着分布式架构体系的不断演变,越来越多的优秀中间件应运而生。我们无需再重复造轮子,可以直接在项目中使用这些优秀的中间件,把更多精力放在业务功能的开发上,在提高交付效率的同时也使得系统更加稳定,一举多得。
中间件的种类非常多,不可能尽数列举。但我把各个领域主流的中间件汇总在一起,做了一张思维导图,供你随时查看:
那随着中间件的逐渐增多,必然会出现一个现象:各个项目基本都会用到一个或多个中间件。为了更加出色地完成工作,掌握这些中间件的使用方法、设计理念,了解它们的设计缺陷就成了我们的必修课。
第二阶段:突破高并发
入行一段时间之后,认识高并发、突破高并发就成了我们每个人都要面对的问题。
中间件和高并发密切相关,这是因为每一款优秀的中间件几乎都是由各个行业中的头部企业贡献的。中间件的诞生几乎无一例外都是为了解决特定业务领域的技术挑战,需要满足高并发、高性能、高可用三大功能。也就是说,每一款中间件的设计理念、代码编码都会遵循高并发领域的一些常见理论。
例如,我们非常熟悉的消息中间件Apache RocketMQ,它承载了阿里“双十一”巨大的流量,那它具体是如何应对这一场景的?又采用了什么“牛逼”的技术架构?
尽管我们暂时没有机会参与阿里双十一这样的大流量场景,没法从第一现场了解这些问题,但我们可以通过深入学习和研究Apache Apache项目去体会高并发编程的魅力,让Apache RocketMQ 中的编程技巧成为我们的“经验”。这样一来,我们不就可以用最低成本轻松拿下高并发场景了吗?
再说回职场晋升,我相信你也和我一样,在准备面试时总会先背诵一下“零拷贝”相关的理论知识,因为它是一个非常高频的面试题。但你知道怎么在项目中实际运用零拷贝技术来提升系统的性能吗?
听到这个问题是不是没了思路?其实,RocketMQ作为一款文件存储领域非常知名的消息中间件,就运用了“零拷贝”技术,这部分内容也会在我的专栏中体现。我们要做的只是翻阅对应的源码,进行相应的练习和总结,就可以真正掌握“零拷贝”了。
讲到这里你应该也发现了,中间件是我们突破高并发的利器。它能够最大程度弥补我们缺少的高并发场景实战经验,为我们提供最优秀的项目实践机会。
第三阶段:防患于未然
那是不是只要能够熟练使用这些技术、框架就够了呢?
我认为,中间件的学习进程到这里还远没有结束。由于中间件在分布式互联网架构体系中占据着非常重要的位置,因此,很多故障都和中间件的使用不当有关。只有深入中间件的底层设计原理,读懂源码,才能将很多问题扼杀在摇篮中。
相反,如果故障已经发生了,哪怕你的故障排查能力和处理能力再强,一旦出了问题,就会对业务造成重大影响或者给公司带来资金损失,这些都是无法挽回的。
为了尽可能避免这类问题,很多公司都设置了故障追责机制。例如,阿里巴巴就有“325”,意思是,如果你的系统出现了一次比较大的故障,那么绩效得分为325,全年绩效为0。这样的问题我想是大家都不愿意看到的。
不过,只要我们加强对中间件工作机制的了解,提前发现系统的“病灶”,及时规避掉风险,就能防止公司和个人面临不可估量的损失。
课程设计
总结一下,学好中间件可以提高我们的工作效率、突破高并发瓶颈,还能防患于未然,极大地减少公司和个人的损失。如果你对这些问题感兴趣,那我的专栏就是为你打造的。
《中间件核心技术与实战》共分为六个模块。
在全局认知篇,我会介绍中间件在互联网分布式架构体系中的整体面貌,并重点对数据库、缓存等中间件的发展和选型依据做详细的介绍,帮助你更快掌握技术架构的发展方向,合理选择中间件。
在基础篇,我会系统讲解中间件必备的基础知识,主要包括Java常用数据结构、并发编程与网络编程。通过图解的方式,你可以更好地吸收这些原理,不再像背诵八股文一样学习理论知识,而是通过技术背后的设计理念,做到一通百通。
实战篇是我们全专栏最核心的内容,它分为微服务体系Dubbo、消息中间件和定时调度任务三个部分。我会按照设计理念、选型标准、实战演练的顺序展开。带你从理论到实践,解决实际生产中遇到的问题。
最后是综合案例篇,我给你提供了一个全链路压测的落地项目,方便你全方位地串起各个主流中间件,完成对中间件的综合应用。
学完这个专栏,你应该能够对中间件的主要分类有更宏观地了解,掌握微服务、消息中间件、定时调度框架的设计场景,灵活应对高并发场景。
写在最后
最后我想说,中间件是分布式架构绕不开的话题,对于主流的中间件,你可能早就听说或者使用过,但是,中间件始终在发展和迭代,为了适应未来的变化、从容应对庞大的数据量,我们应该走得更深、更扎实一些,打造自己难以被撼动的职场竞争力。
回想我自己10余年的奋斗经历,正是不断的学习让我实现了职位和技能的突破。在我职业生涯的前几年,因为没有良好的教育背景,又长期在传统行业从事电子政务相关系统的开发,我无缘接触高并发,成为了一名“CRUD工程师”。
好在,2017年我迎来了自己职业生涯的转折点。这一年,RocketMQ正式成为Apache顶级开源项目,通过研读RocketMQ的架构设计、编程技巧,我彻底突破了高并发门槛,找到了向大厂晋升的那扇窗。
在这期间,我也总结出了一套学习中间件的基本方法论,学完这些内容,如果你对其他类型的中间件也很感兴趣,可以用这个方法持续深挖,更高效、透彻地掌握其他类型的中间件。
- 了解这款中间件的使用场景、能解决什么痛点问题。
- 阅读官方架构设计文档,从整体上把握这款中间件的架构、设计理念、工作机制。
- 阅读官方用户手册文档,初步了解如何使用这款中间件。
- 搭建自己的开发调试环境,运行官方Demo示例,进一步掌握这款中间件的使用方法。
- 结合中间件的架构设计文档、亮点技术追溯源码,掌握落地细节并举一反三,结合使用场景进行理解。这是彻底掌握中间件的关键。
好了,说了这么多,我想最重要的还是迈出学习的第一步。如果你对中间件有所困惑,或者希望在高并发场景中游刃有余,那就和我一起开启这次学习之旅吧,我们下节课见!
期中测试 | 来检验一下你的学习成果吧!
作者: 丁威

你好,我是丁威。
不知不觉,我们的专栏已经进行到一半了。我们这个专栏的前半部分理论知识比较多,学起来比较枯燥,能坚持到这里,我首先要为你打Call。这也说明你是真正的热爱技术,真心希望通过学习中间件技术突破瓶颈,在职场上过关斩将。俗话说,温故而知新,在开始后面的课程之前,我想通过提问的方式再跟你一起回顾一下前面的知识点。
请你试着回答下面这些问题,检验一下自己的学习成果。下节课,我会一一给出答案。预祝你取得好成绩!
MyCat数据库中间件与ShardingJDBC在架构思想上有什么差异?
在订单中心有创建订单、查询订单两个微服务。其中,查询订单必须同时支持“按商家”和“按用户”两个维度。为了应对双十一这种大促场景,在数据存储和数据读写方面你会如何进行架构设计?
红黑树的左右旋转、染色其实是不需要死记硬背的。下面这棵二叉树,你会怎样操作让它符合红黑树的定义呢?

JUC定时调度线程池底层的实现原理是什么?如果要管理上万个定时任务,需要怎么处理呢?
如何复用线程?如何优雅地停止一个线程?
多线程编程中,线程与线程之间有两种主要的关系:互斥与协作。你能结合自己的实际工作场景分别举例说明吗?
锁的底层数据结构是什么?
为什么Object.wait方法会释放占用的锁?如果锁没有被释放,会产生什么影响?
什么是NIO?为什么NIO能轻松支持上万个连接同时在线?
我们在使用NIO构建的服务端时,如果服务端处理压力较大,可以在应用层采用快速失败拒绝连接。但是除此之外,在网络层,你还有什么办法限制服务端的流量呢?
通过NIO通道向网络中写数据之前,需要注册写事件吗?那什么时候需要注册写事件呢?
一个网络请求在发送端、接受端通常需要经历哪些步骤,Netty又是采用什么线程模型使这些步骤合理高效运作的?
期待你在留言区留下自己的思考和答案,我们下节课见!
期中测试答案 | 这些问题,你都答对了吗?
作者: 丁威

你好,我是丁威。
这节课我们来回答一下上节课的问题,希望通过梳理这些问题,可以进一步加深你对知识的理解。
1. MyCat数据库中间件与ShardingJDBC在架构思想上有什么差异?
MyCat数据库中间件的设计理念是代理模式,这是一种高度中心化的设计,所有的路由配置都会存储在MyCat数据库中间件中。具体的工作机制是,所有客户端将所有请求发送到MyCat,然后MyCat根据配置的路由规则将请求发送到真实的后端数据库。
这种架构模式在数据量较少的情况下确实能提升性能,但如果请求数继续增加,就有可能出现问题,你可以先看看下面这张图片:
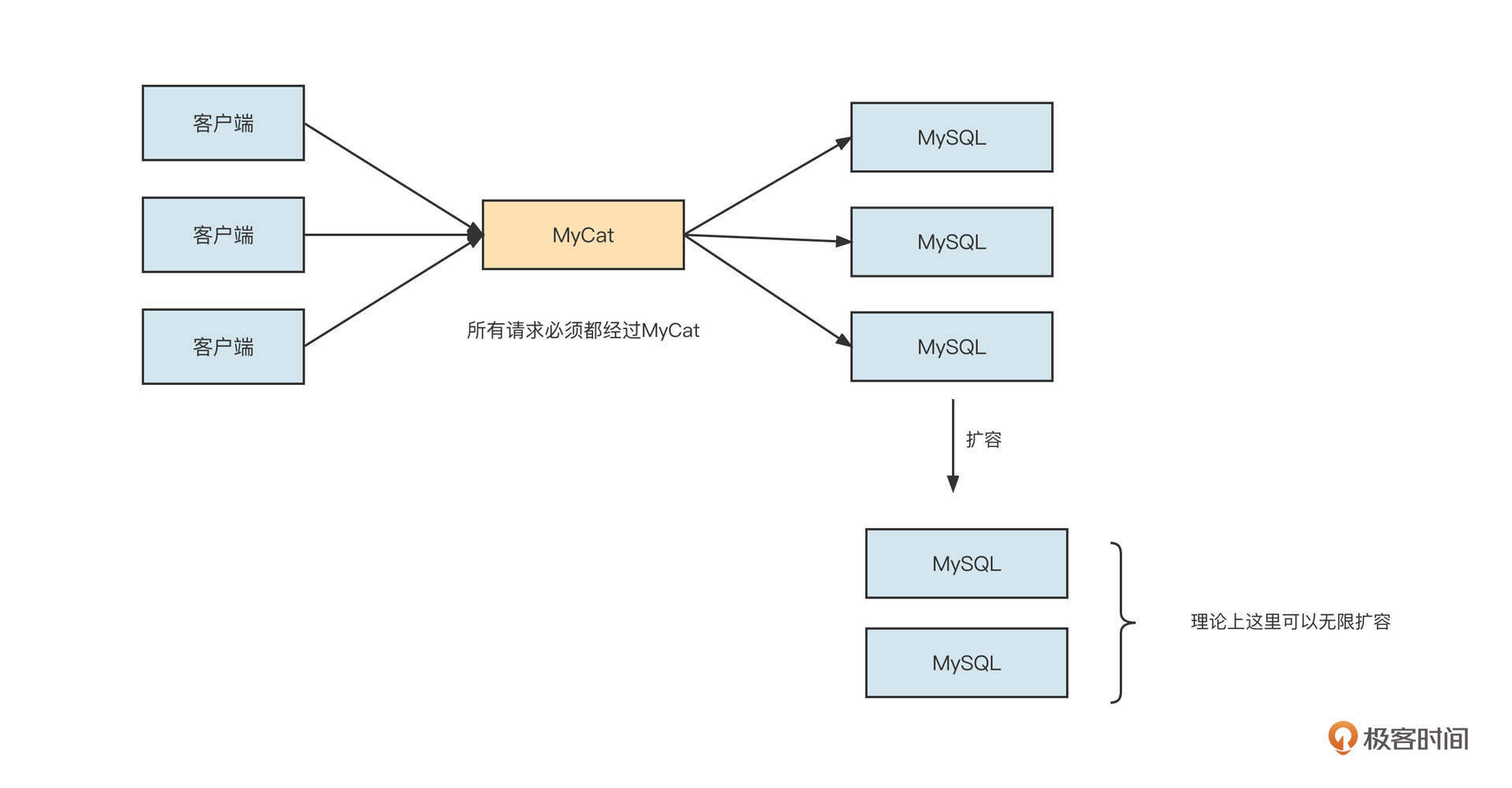
如果数据库需要存储的数据逐步增加,我们就要对后端数据库进行扩容,这个无可厚非。但如此一来,存储的数据会越来越多,基于代理模式,所有的请求都必须经过MyCat这个中心节点。一旦这个节点出现故障,将导致系统不可用。
而ShardingJDBC采取了去中心化的设计,系统架构如下图所示:
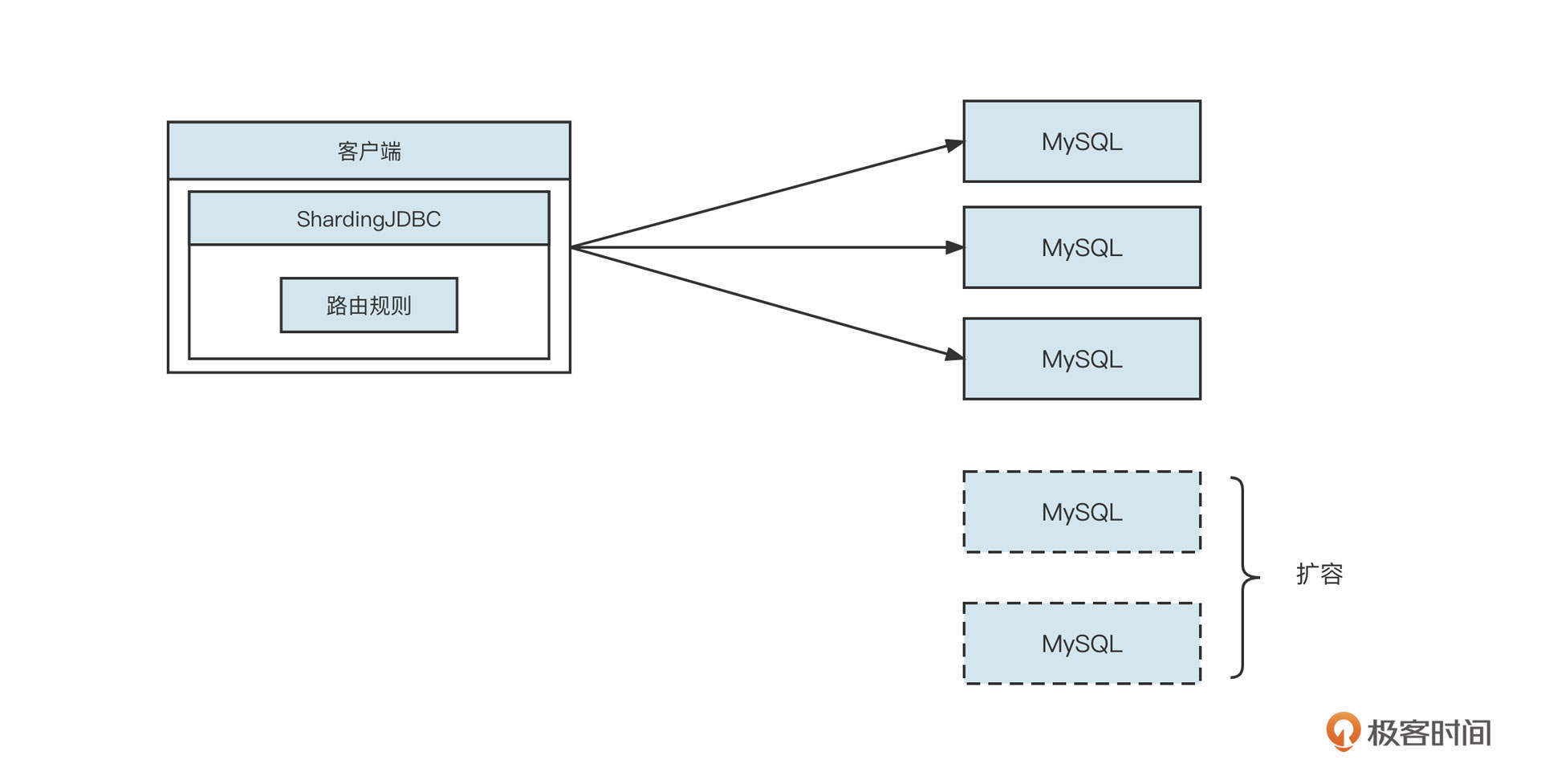
从这张图可以看到,ShardingJDBC是将所有的路由信息嵌入到应用进程中,在客户端进行路由计算,然后连接后端真实的数据库。如果要对后端数据库进行扩容,只需要更新一下路由注册信息就可以了,不会带来额外的资源损耗,也不存在单点故障。
2. 在订单中心有创建订单、查询订单两个微服务。其中,查询订单必须同时支持“按商家”和“按用户”两个维度。为了应对双十一这种大促场景,在数据存储和数据读写方面你会如何进行架构设计?
通常为了应对流量高峰,我们会首先在入口流量引用MQ,然后在数据库存储领域引入分库分表。同时,为了避免查询请求对写入性能的影响,会引入读写分离机制。但是我们不能简单地在数据库层面使用读写分离,因为分库分表后,使用Join等复杂语句通常会遇到性能瓶颈,所以应该将数据库数据实时同步到Elasticsearch中,最后的架构设计大概如下所示:
3. 红黑树的左右旋转、染色其实是不需要死记硬背的。下面这棵二叉树,你会怎样操作让它符合红黑树的定义呢?
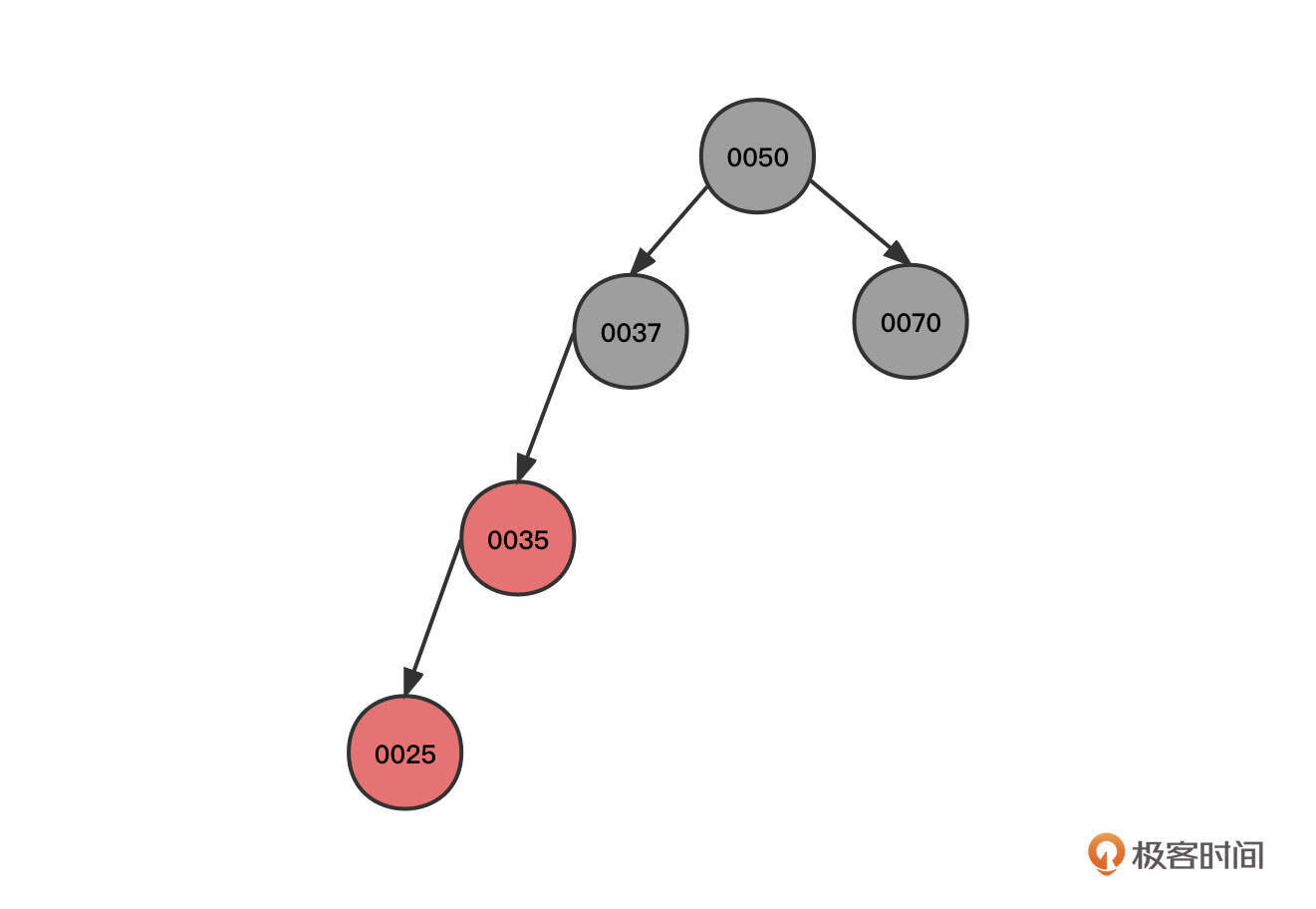
红黑树的染色和左右旋转是有窍门的。
我们先看染色,需要变换染色的情况,通常是相关的三个节点组成的结构是一个父节点带两个节点,我们需要将其中一个黑色的叶子结点的颜色传递到父节点。
然后再来谈左旋和右旋。其实它们的原理就是通过降低树的高度来实现平衡,但调整后需要确保根节点比左节点大,比右节点小。左旋或者右旋的触发场景为:连续两个红颜色节点。
我们说回到这道题。0037的左节点为0035,0035的左节点为0025,那这三个节点,从0025视角来看,有3“层”,我们要把它们变成两层。一个简单的方法就是我们从这3个节点中找到中间值节点,这里是0035节点,然后把比中间节点小的节点(0025)放入到0035的左节点,把比中间件节点大的节点(0037)放入到中间值节点(0035)的右子树即可。
经过旋转后,我们可以得到下面这张图:
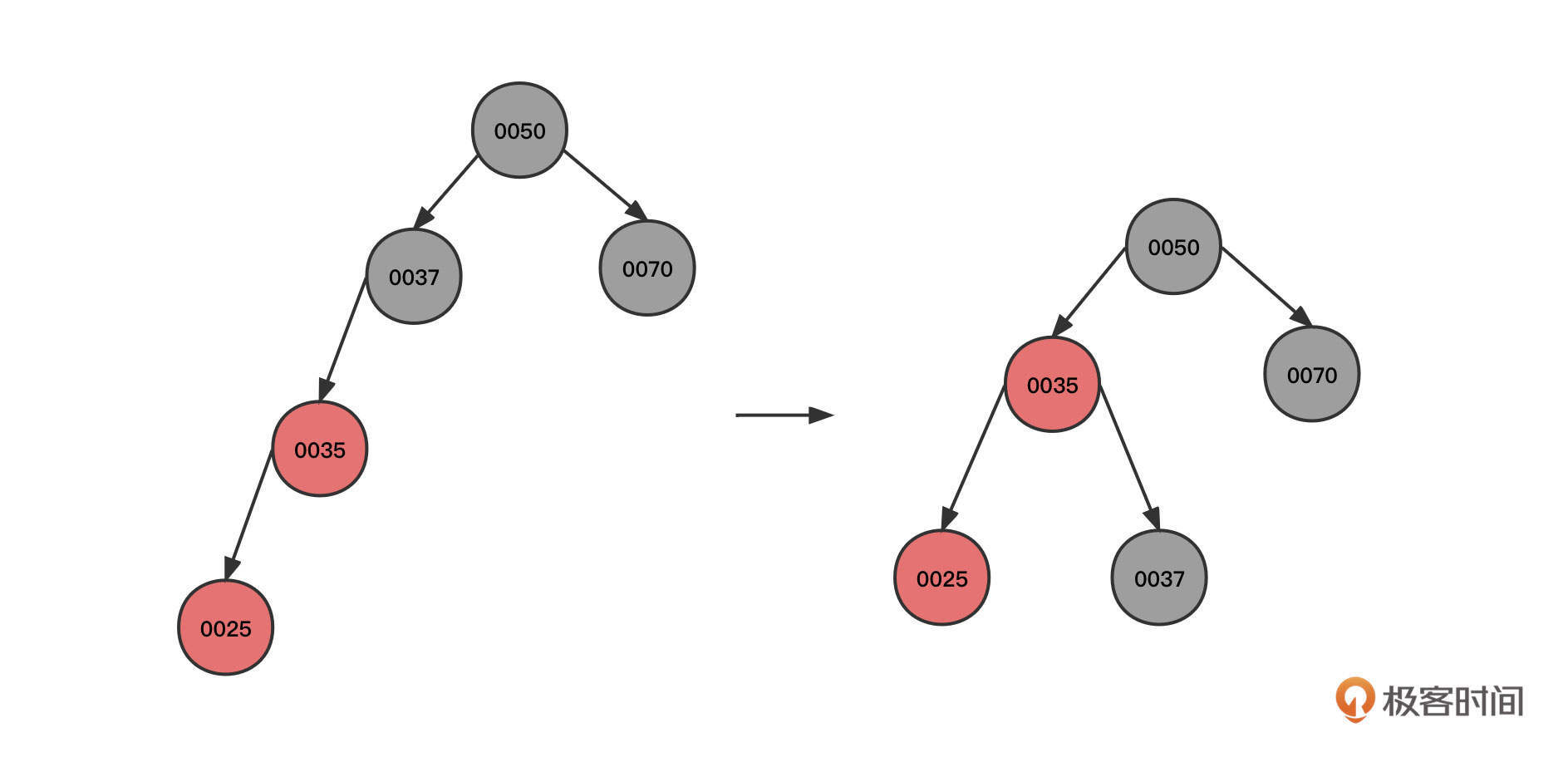
但这个时候还是有两个连续的红色节点,这样会导致每条链路的黑色节点数量不一致。又因为0025,0037这两个节点已经在同一层次了,这个时候我们可以调整节点的颜色让它符合红黑树的定义,我们只需要将0037的颜色传递给它的父节点就可以了,最终为:
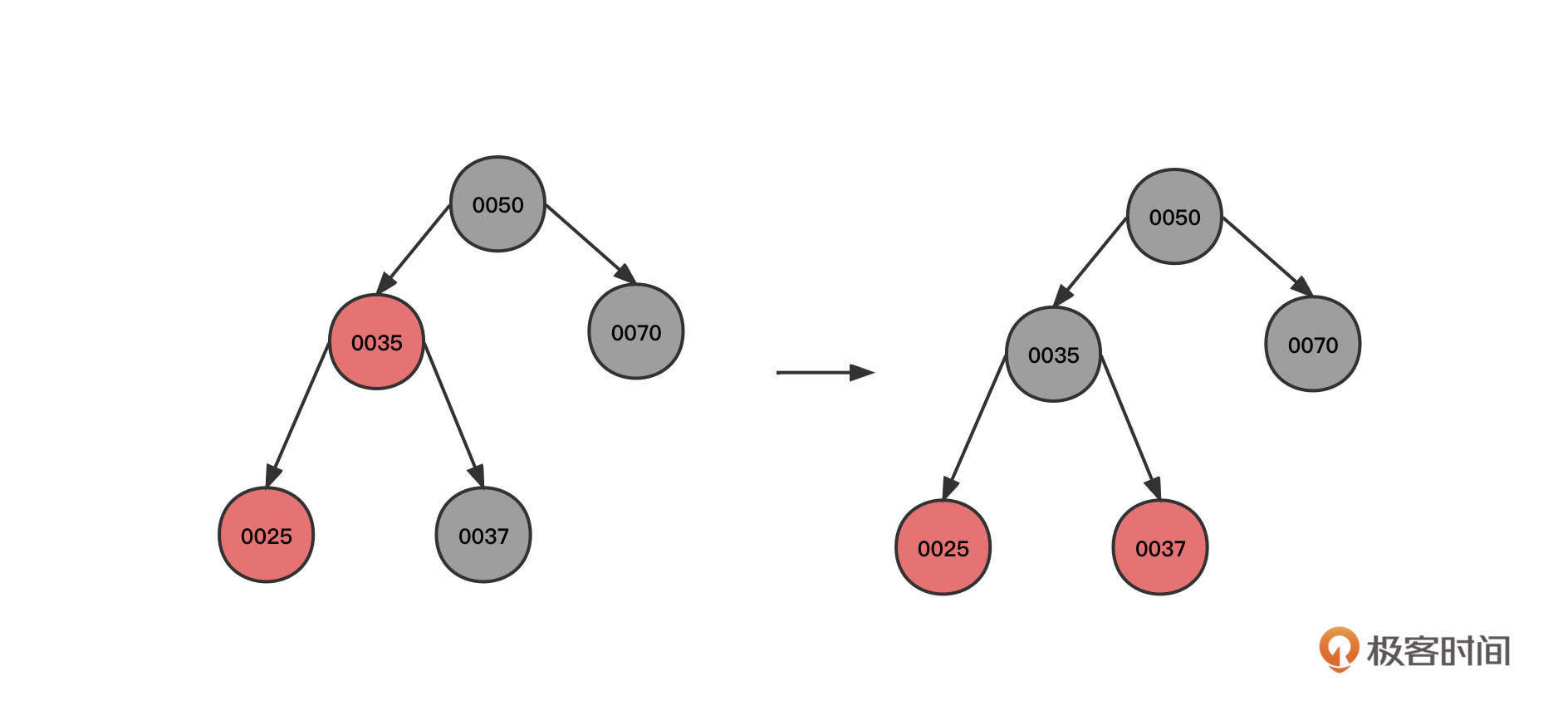
4. JUC定时调度线程池底层的实现原理是什么?如果要管理上万个定时任务,需要怎么处理呢?
JUC的线程调度底层的队列存储结构是PriorityQueue,又叫做最小堆,它的具体的实现原理如下。
在将调度任务提交到线程池之前,首先计算出下一次需要执行的时间戳,通过时间戳来计算优先级,将其存入最小堆中,这样就确保了最先需要执行的调度任务位于最小堆的顶部(也就是根节点)。
然后开一个定时任务,拿队列中第一个元素和当前时间进行比较: - 如果下一次执行时间大于等于当前时间,则将队列中第一个元素(调度任务)从队列中移除,投入线程池中执行。
- 如果下一次执行时间小于当前时间,则不处理,因为队列中最小的待执行任务都还没有到执行时间,其他任务一定也是这样。
但是如果需要调度的任务很多(例如上万个),这些任务的触发时间只相隔个几秒,这种通过一个线程一个一个检测任务的方式,很容易导致任务调度执行不精确。
为了解决这个问题,业界引入了时间轮算法,它的意思是引入时间轮,每一个轮代表一个时间刻度,如下图所示:
例如,图中每一个刻度代表1s。因为有8个格子,就代表8秒,也就是说,这个时间轮可以管理延迟调度时间在8s内的任务。如果想要增加延迟调度的时间范围,只要增加格子的数量即可。
具体怎么操作呢?
- 首先计算要调度的任务的延迟时间,将它换算成相应的刻度放到指定的格子里,每一个格子都会维护一个任务列表。
- 然后使用一个线程(类似于钟表中的秒针)以固定频率(单个格子代表的时间长度)驱动指针,指针指向的格子内所有的任务到期后,一次性出发所有的定时任务,执行精度并不会随着要触发的任务数量增加而发生变化。
5. 如何复用线程?如何优雅地停止一个线程?
一个线程走向消亡的触发条件是线程的run方法的结束,因此,要复用一个线程的方法是不让run方法结束。我们通常采用的方法是:“while(true) + 从阻塞队列中获取任务”。因为如果阻塞任务中没有任务可执行,线程会阻塞,不会浪费CPU资源;而一旦阻塞队列中有新的任务加入,就能立马唤醒线程执行对应的任务了。
要停止一个线程,我们不能直接调用线程的stop方法,而是需要在run方法加入中断检测机制。在run方法中如果检测线程中断位被设置,则跳出循环,结束run方法的运行,从而达到停止线程的目的。
6. 多线程编程中,线程与线程之间有两种主要的关系:互斥与协作。你能结合自己的实际工作场景分别举例说明吗?
互斥,通常是在多个线程要访问同一个公共资源,而这个公共资源又不允许多个线程同时访问时出现。这个时候需要引入锁来保护共享资源,达到多线程串行访问的效果。这在实际生产中非常常见,例如,多个线程要更新数据库中的同一行数据时,就涉及到锁的使用。
协作其实看出是对一个任务进行步骤拆解,然后让这些步骤可以并行执行,以此提升性能。
例如,MQ的消息拉取线程与队列负载均衡这两个线程就是典型的协作模式。这两个线程共同完成MQ消息的拉取,它们使用一个公共的阻塞队列相互协作。负载均衡算法负责计算队列的负载情况,向阻塞队列中生产任务;而消息拉取线程负责从阻塞队列中获取任务,并执行具体的消息拉取动作。如果阻塞队列中没有任务,那么消息拉取线程就要阻塞,在生产出新的拉取任务后,负载均衡线程会再通知消息拉取线程。这两者之间是相互协作,相互制约的关系。
7. 锁的底层数据结构是什么?
它包括锁的持有者线程、锁的重入次数、阻塞队列和条件等待队列。
锁的持有者线程拥有对被保护资源的操作权,而且在整个过程中,支持对锁进行多次锁定。
同步阻塞队列存放的都是竞争锁失败的线程,主要表征的是线程之间的竞争和互斥。
条件等待队列中存储的是因为某一个条件不满足而需要阻塞的线程,通常需要被其他线程主动唤醒,主要表征的是线程的协作。
8. 为什么Object.wait方法会释放占用的锁?如果锁没有被释放,会产生什么影响?
我们用前面讲的面包工程的例子加以说明。例如下面一段代码是面包生产者向仓库中生产面包的代码实现:
1 | public void put(Bread bread) throws InterruptedException { |
生产者线程调用put方法后,是因为仓库(具体是List breads)中没有容量,所以被阻塞。但如果不释放锁,就没有线程能从breads中取出元素,这会导致breads一直没有剩余空间。所以只能是生产者自己释放锁,让其他协作线程(消费者线程)有机会运行。
9. 什么是NIO?为什么NIO能轻松支持上万个连接同时在线?
NIO的全名是同步非阻塞IO模型。NIO能轻松支持上万个连接同时在线,这得益于它的事件选择机制。NIO只需要少量IO线程(每一个IO线程内部会创建一个事件选择器)就可以服务上万个连接。因为每进行一次事件就绪选择,IO线程需要处理的只有那些就绪的连接,在IO层面没有就绪的连接是不需要进行处理的。这就节省了大量的线程资源,不会像BIO那样,一个连接不管当下是否有数据读写,都必须占用一个线程。
10. 我们在使用NIO构建的服务端时,如果服务端处理压力较大,可以在应用层采用快速失败拒绝连接。但是除此之外,在网络层,你还有什么办法限制服务端的流量呢?
在网络层,我们可以暂时停止注册读事件,这样这个连接就不会从网卡中读取数据了,数据会停留在底层Socket的读缓冲区。由于TCP内部拥有拥塞控制,如果接受端没有从网卡中读取数据,也就不会发送ACK确认到源端了。源端无法写入更多数据,这就在网络层实现了拥塞控制,实现了限流。
11. 通过NIO通道向网络中写数据之前,需要注册写事件吗?那什么时候需要注册写事件呢?
写数据之前不需要注册写事件,写事件一般是等底层NioSocketChannel的底层缓存区满了,无法再向网络中写入数据时,再注册通道的写事件,等待缓冲区空闲时通知应用程序继续将剩余数据写入到网络中。
12. 一个网络请求在发送端、接受端通常需要经历哪些步骤,Netty又是采用什么线程模型使这些步骤合理高效运作的?
一个网络请求发送与接收响应结果通常涉及编码、往网络中写数据(Write)、从网络中读取数据(Read)、解码、业务逻辑处理、发送响应结果和接受响应结果等步骤。过程图如下:
Netty的线程模型采取的是业界的主流线程模型,也就是主从多Reactor模型:
它的设计重点主要包括Netty Boss Group、Nettty Work Group、Business Thread Group线程组这三个线程组。 更详细的说明你可以参考第8讲。
好了,我们本节课的答疑就到这里了,如果有其他问题,欢迎留言与我互动,我们下节课再见。
期末测试 | 来赴一场满分之约吧!
作者: 丁威

你好,我是丁威。
专栏《中间件核心技术与实战》已经结课了。非常感谢你一直以来的认真学习和支持!
为了帮你检验自己的学习效果,我特意给你准备了一套结课测试题(可以重复体验:) )。一共 20 道选择题,考点都来自我们前面讲到的重要知识。点击下面按钮开始测试吧!

希望你能够将自己在这个专栏的所得扎扎实实地用在工作中,也预祝取得一个好成绩!
结束语|坚持不懈,越努力越幸运
作者: 丁威

你好,我是丁威。
不知不觉,我们已经一起学完了专栏的所有内容。虽然学习的步伐远没有结束,但我们却是时候说再见了。今天这最后一节课,我想结合我的一些从业经验,分享我的一些职场感悟。
我是多数普通开发者的一个缩影
其实,那些业界的“大神”终究只是少数,我想,绝大多数的开发者都没有那么多光环。
十年前,我只是一名普通二类本科的毕业生,毕业后在一家小公司一呆就是四年。我当时主要从事的是电子政务方面的业务,虽然我很努力,解决工作中的问题也显得得心应手,受到了同事和领导们的认可。但受到所在平台和公司规模的限制,我的薪资待遇并不理想,技术水平似乎也在原地踏步。这样一来,我就有了离开的想法。
但我始料未及的是,我满怀信心地出去找工作,却备受打击地回来了。阿里系企业问的很多问题直接把我秒杀。比如:HashMap的内存结构是什么?HashMap为什么不是线程安全的?对大数据、高并发这些场景有多少了解?很多问题都是我连想都没有想到过的。
我才发现,在我职业生涯的前6年压根就没有机会接触高并发、大数据等技术场景,这导致我的求职屡屡碰壁。
2015年,随着“互联网+”理念的兴起,很多传统公司开始了IT信息化改造。部分拥有互联网经验的人才流入了传统行业,我也乘着这股浪潮入职了雅居乐地产公司的科技信息中心,参与了雅居乐地产智慧物业相关系统从0到1的系统的打造。
尽管“互联网+”相关企业的并发量依然不高,但它们的技术架构、技术思想都借鉴了互联网企业,让我在一定程度上开了眼界,我的职业前景开始有些明朗了。
研究源码,打造技术影响力
在雅居乐地产公司任职期间,我们部门的首席架构师看中了我的技术热情和技术能力,询问我是否愿意参加MyCat开源社区,为MyCat开源社区贡献自己的一份力量。
说实话,当时我根本没意识到,这样一件事会给我的职业生涯带来前所未有的助力,当时我只是觉得有一个技术大牛认可你,那就无需想太多,直接干就对了。
我仔细研读了MyCat的官方文档,逐渐对分库分表中间件的工作原理有了一些较为深入的了解和思考,很快就开始在MyCat官方群中回答群友们的问题。
但我意识到,要代表MyCat官方社区为企业做一些MyCat咨询相关的工作,只看官方文档是不够的。这时候我们还需要阅读源码,理解中间件底层的实现细节,为开源社区编写更多更细的文档。也就是说,必须从一个文档使用者转为一个文档创造者。
于是我做出了一个非常重要的决定:阅读MyCat项目源码。不过,刚开始阅读MyCat源码的时候我还是举步维艰。这么大一个工程,我完全不知道如何下手。像无头苍蝇乱撞了两周之后,就有些坚持不下去了。
但我并没有彻底放弃,而是意识到自己确实是一个“技术菜鸟”,Java基础薄弱,必须补齐。
我分析了一下各类主流的分布式架构,决定先研读Java基础数据结构、JUC(Java并发框架)和Netty(NIO框架,网络通信基础框架)。
你可以看一下我的学习时间轴:
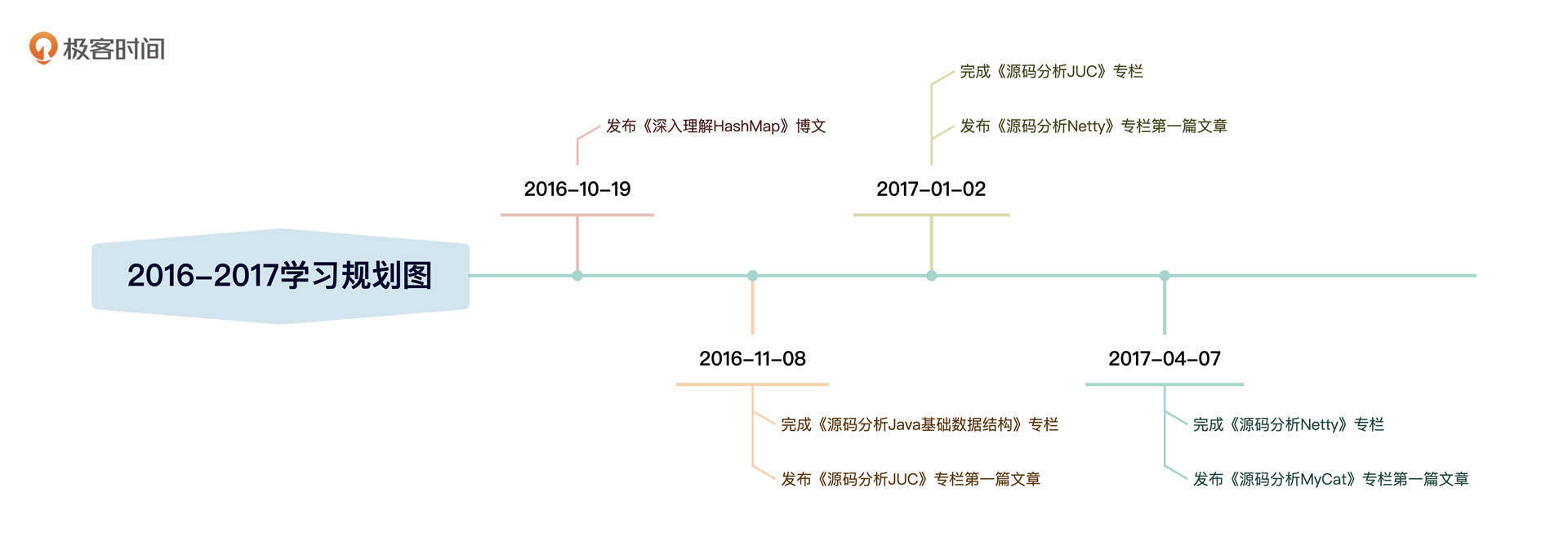
2016年10月,我开始学习Java数据结构,学习的过程中,我会把知识点和自己的思考记录下来。到2017年4月,我完成了分析Netty源码的专栏。整个基础学习阶段大概持续了半年。这之后,我再次尝试阅读MyCat源码已经没有任何阻力了,于是接下来我又发表了《源码分析MyCat》系列文章。
发布《源码分析MyCat》专栏之后,我在MyCat开源社区的知名度越来越大。后来,在MyCat开源社区的引荐下,2017年11月,我入职了上海优速物流公司,这也终于给了我在生产环境中处理高并发、大数据量的机会,我开始正式接触互联网分布式架构,薪酬也直接翻倍了。
为什么学完基础知识再读MyCat源码就这么轻松了呢?我想主要有下面两方面原因。
- 基础技能逐渐提升,知识盲区渐渐补齐。
- 过往的源码学习经验让我总结提炼出了一套适合自己的源码学习方法论。
我也把这套阅读源码的方法分享给你。
- 了解这款软件的使用场景、以及它在架构设计中将承担的责任。
- 寻找官方文档,从整体上把握这款软件的设计理念。
- 搭建自己的开发调试环境,运行官方提供的Demo示例,为后续深入研究打下基础。
- 先研究主干流程再专注分支流程,注意切割,逐个击破。
坚持不懈,越努力越幸运
回顾这段经历,我觉得最难能可贵的是坚持。因为阅读源码是非常枯燥的,这半年中我遇到了无数难题,有很多次想要放弃。
我记得有一次我阅读Netty源码,当时刚刚写完Netty的内存泄露检测,准备开始研究内存分配机制。但这部分非常抽象,涉及到的数据结构特别复杂,需要掌握二叉树与数组之间如何映射,还牵扯到大量的位运算。这让我在探究Netty内存分配机制时寸步难行。
当连着一周、两周都无法取得突破时,我们很容易为自己找一个借口:这样持续投入时间,又没有进展,也没有回报,这不是在浪费时间吗?
当时我确实想过放弃。但转念一想,放弃后我会做什么呢?玩游戏?看电视?这不更是浪费时间吗?想清楚这一层后,继续攻关、突破就成了我唯一的选择。
每攻克一个难题,我都能得到极大的满足,技术攻关能力也越来越强。
我接连发布了RocketMQ、Kafka、ElasticJob、Dubbo、Sentinel、MyBatis、Canal等源码分析专栏,形成了较为完备的中间件知识体系(如果你想要获取这些源码分析专栏,可以关注“中间件兴趣圈”公众号,回复对应的关键字即可,例如回复RocketMQ即可获取RocketMQ专栏系列文章):
在这个过程中,又发生了一件我意料不到的事情,出版社邀请我出版一本书。
写书,这是我连想都不敢想的事情。因为我高中阶段的语文成绩一直在及格线徘徊。但在编辑老师的帮助下,《RocketMQ技术内幕》一出版就受到了大家的认可。
这本书也逐渐打开了我的知名度,让我顺利进入物流行业的头部企业中通快递担任资深架构师。这份工作需要负责日均消息流转量超万亿级别的集群,让我能够将理论与实践相结合,极大提升了我对消息中间件的理解和把控能力。
回首这些年的工作经历,正是坚持不懈的努力让我获得了今天的成绩。反过来,也正是我收获的这些正向反馈让我有了持续学习的动力,让我坚定地拥抱开源,走技术分享的道路。不要怀疑,越努力真的会越幸运。
中间件研发的两条技术成长路线
不过也许你会问:你对RocketMQ这么熟悉,为什么没有成为RocketMQ的Committer呢,为什么没有参与RocketMQ的代码贡献呢?
要回答这个问题,我们要先理清中间件研发的两条技术成长路线。
第一条路线:成为开源项目的创造者,也就是走代码贡献路线,成为开源项目的Committer。
中间件的细分领域非常多,例如微服务、消息中间件、缓存、搜索、数据库分库分表等。而选择成为Commiter,通常意味着需要选择其中一个方向深耕。这样做的难度一般会比较高,但一旦取得突破,成为这方面的专家,在行业中的地位就会比较稳固,薪资待遇当然也不会差。
但这条路的缺点是职位选择范围会越来越窄,也就是宽度不够。一旦无法突围,失败的概率就会比较大,毕竟这类工作的岗位需求量还是比较少的。
第二条路线:专注于中间件的应用,成为中间件领域的应用专家、技术架构师。
我选择的是这第二条路线。要实现这个目标,通常的做法就是学习市面上主流的中间件,深入研究各个中间件的源码,深入理解设计者的架构思想,在生产环境中灵活运用各类中间件解决实际业务问题,并且能利用中间件及时规避故障,快速排查故障。
这有助于我们成为多个中间件的技术应用专家。与此同时,研究中间件的实现细节也能帮助我们理解分布式架构,为我们成为技术架构师储备知识。不过,选择了宽度自然容易丧失深度,让人缺乏亮眼的标签。所以我的建议是,达到一定广度后,还是要选择一两个中间件重点攻破,形成自己的金刚钻。

总之,不管是想要走代码贡献的道路,还是专注于中间件的应用,都需要我们的努力和持续的输出。相信我们只要坚持不懈,积极分享,一定可以突破职场瓶颈,拥有自己的社区影响力。我们一起加油!